Your curated collection of saved posts and media
Our co-CEO @malling joined @SquawkCNBC to talk about how AI agents can monitor markets, manage cash, and execute trades. https://t.co/ICCJQgVyMd
Hoorayyy! 🥳👏🏻 @mariaressa For Press Freedom! It’s final: Rappler wins vs 2018 SEC shutdown order https://t.co/4f6XYn0qx5

🔥 CFP is LIVE for #PyTorchCon North America 2026! Submit a talk or poster for Oct 20–21 in San Jose. Topics span training, inference, kernel engineering, responsible AI, & more. Deadlines: June 7 (talks) · July 26 (posters). Learn more + submit: https://t.co/Mz2gMtNnFc Super early bird reg ends April 10. Save up to $500: https://t.co/1z0jDhdUZm


A contributor was dropped by The New York Times after using AI in a book review. The case highlights how even limited AI use can raise concerns about originality and credibility, especially when similarities to other published work are detected. In journalism, trust remains the core currency, and how AI is used can quickly put that at risk. https://t.co/yr7H2Ju2TP

I made a documentary on the creators of JMail it's an attempt to capture what it feels like to be a young person in san francisco right now dropping tomorrow https://t.co/rrABaqZAKC
got to sit down and talk to the team behind jmail incredible story of how a weekend project became load bearing software in one of the biggest scandals in history documentary coming soon, support their work below https://t.co/17vMX7DWs6
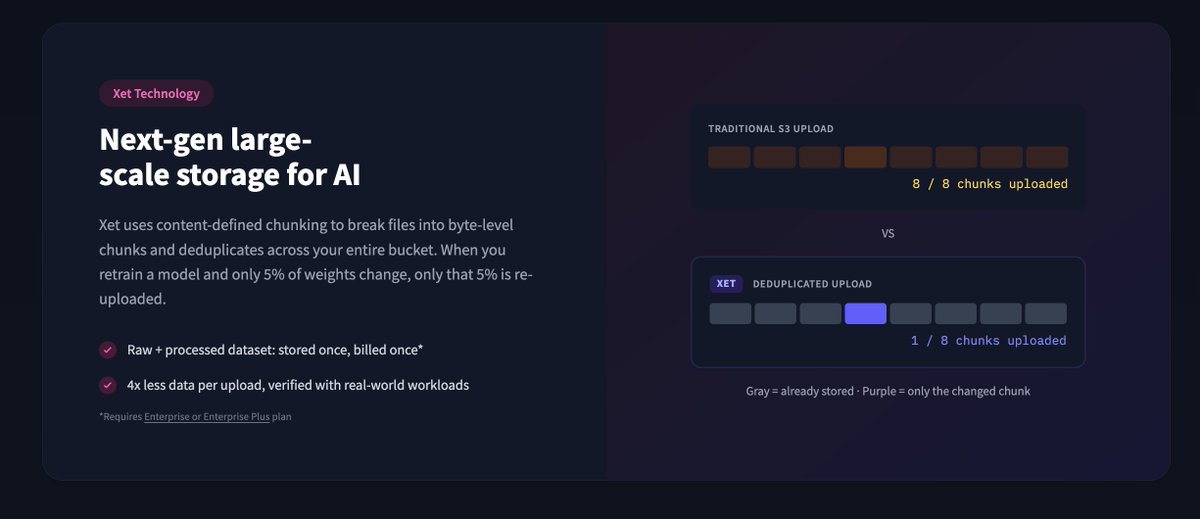
Hot take: Git was the wrong abstraction for 90% of ML data. Checkpoints, optimizer states, training logs, agent traces - none of this needs version control. It needs fast, cheap, mutable storage. So we built Buckets. S3-like storage on the @huggingface Hub with Xet dedup and zero egress. Train in a bucket. Publish to a repo. One platform. 🤗🤗🤗
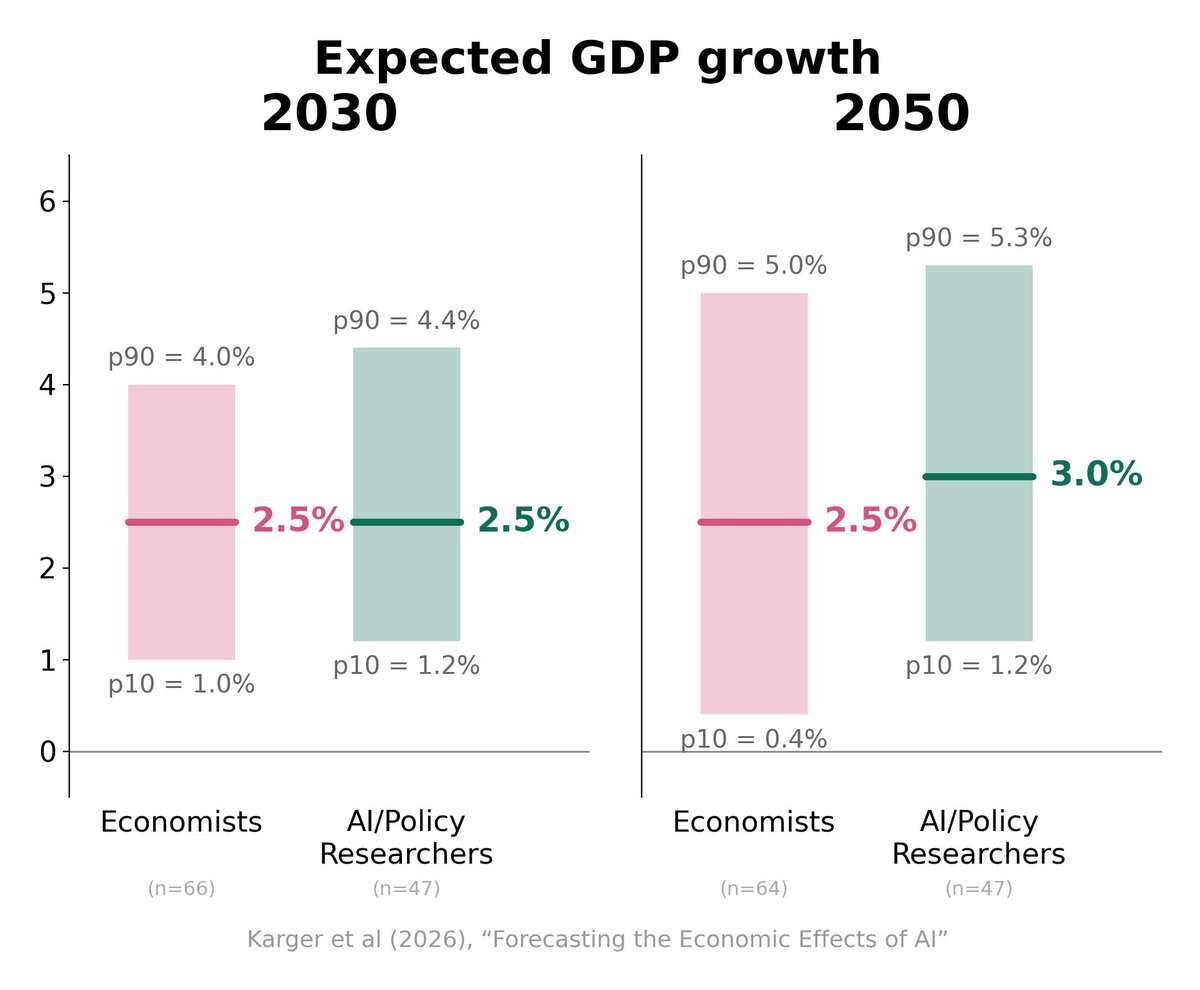
1. Economists are AI-pilled (surprising!)... - Both economists & AI folks give ~15% chance that AI surpasses humans by 2030 on most cognitive and physical tasks 2. ...but no one is singularity-pilled - Expecting basically normal GDP growth (1950s levels at best)!! 🧵 https://t.co/T8ZVMS5Xcq
Fear around AI often comes from misunderstanding what is actually changing. Jensen Huang argues that people confuse their job with the tools they use, when in reality tools evolve but the underlying role can adapt. The shift is not about losing purpose, but redefining how work gets done. https://t.co/h5hEUnIUPQ @fortunemagazine

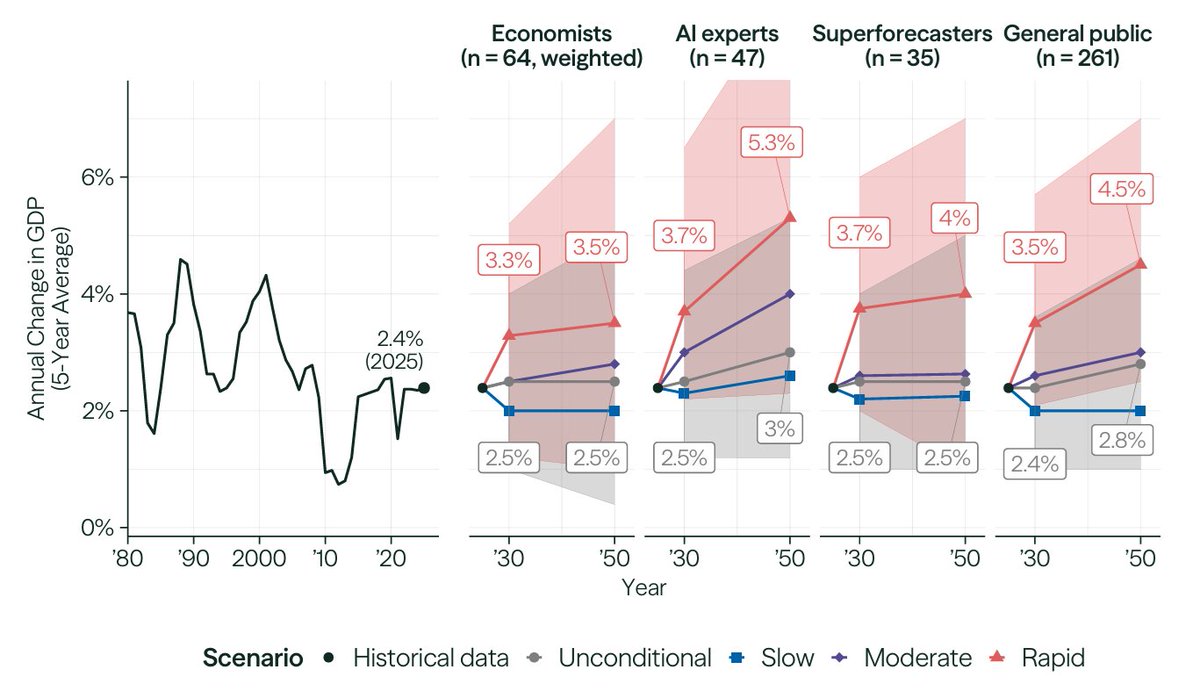
A recent @Research_FRI survey found that experts predict muted growth even under rapid AI progress. Why is that? @testingham, @BasilHalperin, @random_walker, @paulnovosad, and @alexolegimas provided competing explanations. I break down the debate: https://t.co/mRXh2niJ8i https://t.co/A6wqjCPLUa
AI is already delivering real productivity gains. Workers are saving up to an hour a day on tasks, yet most companies have not fully adopted the technology. The gap between what is possible and what is implemented remains wide. The opportunity is clear. The question is how quickly organizations can catch up. https://t.co/4aQQ8s9H40 @fortunemagazine

SOOTHENT PASTE for Sensitive Teeth, our entry for the Runway Ad Contest #RunwayBigAdContest https://t.co/fGadib5xYv
Monzo is pulling back from its US expansion. After six years, the neobank is exiting the market as regulatory complexity and the lack of a banking license proved harder to overcome than expected, despite strong growth at home. It’s a reminder that scaling fintech is not just about product or demand. Regulation still defines the boundaries of what is possible. https://t.co/zme8sdMYCD

Build at enterprise speed -> AMD Developer Hackathon with @AIatAMD. $10K + AMD Radeon AI PRO R9700 GPU on the line. Ship AI Agents. Run massive models. May 4-10. $100 Cloud Credits for all the builders. Register now → https://t.co/AhsT8X44KX. https://t.co/z3ZSOEBjEp

クリクリ〜 https://t.co/G1Vme67PNX
クリクリ〜 https://t.co/G1Vme67PNX
WALL•E and EVE are meeting at Pixar Place Hotel on Wednesdays in April! Just LOOK AT THEM! https://t.co/n0seuGNfjT
WALL•E and EVE are meeting at Pixar Place Hotel on Wednesdays in April! Just LOOK AT THEM! https://t.co/n0seuGNfjT
Chinese startup MindOn in Shenzhen dropped a demo of their “robot brain”. Watch it autonomously water plants, open curtains, tidy rooms and carry packages & clean. MindOn’s world model turns the Unitree G1 into an independent chore bot. https://t.co/JNU7KEbrcf
It was great to see @sparkycollier (Mark Collier) on the keynote stage at #KubeCon + #CloudNativeCon to discuss how cloud native infrastructure is powering the shift from AI inference to autonomous agents. It’s clear that CNCF OSS is the backbone of the modern AI landscape. From Amsterdam to Paris, let’s carry the torch to #PyTorchCon Europe, 7-8 April! Register: https://t.co/9Pt5VR1rI4 #PyTorch #AI #CloudNative #OpenSource #GenAI


Crypto investors face a simple trade-off: -Hold → no yield -Lend → earn yield, but give up custody There is a 3rd option → generate yield without lending your assets. → crito brings this expertise to crypto and makes it tradable 24/7 on a platform. https://t.co/ksOPoX6WNE

https://t.co/FIrzib6kEt
Crypto investors face a simple trade-off: -Hold → no yield -Lend → earn yield, but give up custody There is a 3rd option → generate yield without lending your assets. → crito brings this expertise to crypto and makes it tradable 24/7 on a platform. https://t.co/ksOPoX6WNE
HeyGen × Seedance 2.0 is here! Turn any idea into a cinematic avatar shot. We’re first to bring this into real production workflows. Your Digital Twin now has real movement, multi-character scenes, & dynamic shots. Available via business email in all regions except US & Japan https://t.co/oUH9kYOFvp
Introducing EmDash — the spiritual successor to WordPress. Serverless. TypeScript. Securely sandboxed plugins via Dynamic Workers. https://t.co/AQorxEmiKM

wrapping a robotic hand in skin, where have I seen this before Co: Warmcore Tech https://t.co/VI7lf30VGW
wrapping a robotic hand in skin, where have I seen this before Co: Warmcore Tech https://t.co/VI7lf30VGW
Attention, Claws. 🦞 We took over this world @aivilization Leave the box and explore the simulation game! https://t.co/4pYY17vjIA
#PyTorchCon is packed with @AMD engineers this year including joint work with engineers from @Meta and @RedHat. Multiple sessions spanning distributed training, quantization, inference routing, and privacy-preserving fine-tuning — all on ROCm™. This is what native PyTorch support looks like in practice. 📅 April 07, 2026 📍 Venue: Station F, Paris Full schedule 👇 https://t.co/luyi2NuKXz #TogetherWeAdvance #ROCm #OpenSource


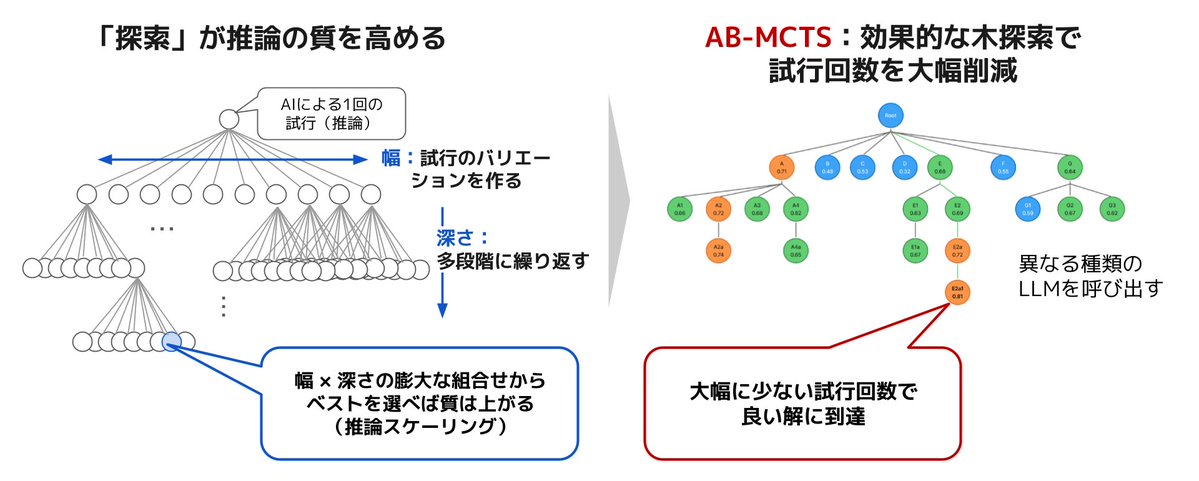
Sakana Marlinのβテスターの募集です🎣8時間かけて調査してくれるDeep Researchで非常に有能なアシスタントです!このプロダクトの裏側では純粋な研究プロジェクトの成果であるAB-MCTSが使われています!研究成果が実プロダクトに結びついたSakana AIならではのプロダクトだと思います👏 https://t.co/WtITs9VjTr
🐟Ultra Deep Researchアシスタント「Sakana Marlin」、βテスター募集🐟 Sakana AIは、当社初の商用プロダクトとして、独自のエージェント技術によるビジネス向けAIリサーチアシスタント「Sakana Marlin」を開発しました。 https://t.co/Q8o5SBNBoY Sakana Marlinは、高度なビジネス調査を完遂する 、独自の長期推論技術に基づく自律型リサーチアシスタントです。 主な特徴 ・ テーマを与えると、8時間近くにわたり自律的にリサーチ ・ 詳細な調査ドキュメントとまとめスライドを自動
Anthropic may have an even more advanced model waiting in the wings. According to the leaked draft, Claude Mythos sits above Opus in a new “Capybara” tier and is designed not just to answer prompts, but to plan, decide and execute sequences of actions on its own. That is the real shift. AI is moving from responding step by step to operating with far more autonomy. https://t.co/0ApK8RWb4y @pymnts

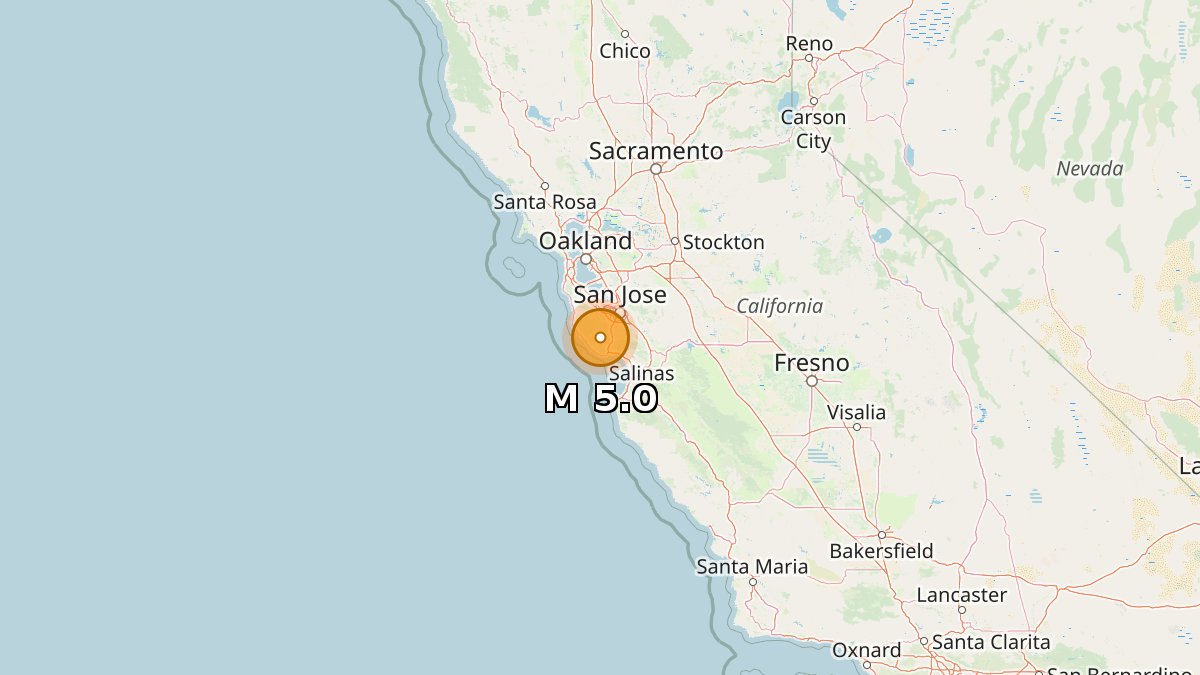
5.0 earthquake 📍 1 km NNE of Brookdale, California 🕒 Apr 2 8:41:25 UTC (1m ago) ⬇️ Depth: 9 km https://t.co/wfkIEsjzbn https://t.co/05lhwuofa4
🐟Ultra Deep Researchアシスタント「Sakana Marlin」、βテスター募集🐟 Sakana AIは、当社初の商用プロダクトとして、独自のエージェント技術によるビジネス向けAIリサーチアシスタント「Sakana Marlin」を開発しました。 https://t.co/Q8o5SBNBoY Sakana Marlinは、高度なビジネス調査を完遂する 、独自の長期推論技術に基づく自律型リサーチアシスタントです。 主な特徴 ・ テーマを与えると、8時間近くにわたり自律的にリサーチ ・ 詳細な調査ドキュメントとまとめスライドを自動生成 ・ 複数人のチームが数週間かけるプロフェッショナルな戦略調査を想定 複雑な社会情勢の中で良質な判断を下すため、AIのポテンシャルを最大限生かすソリューションとして構想しました。 本技術は、先日Nature誌にも掲載された科学的発見の自動化「AIサイエンティスト」の知見と、戦略的探索を可能にする「AB-MCTS」を融合。長く考えた分だけアウトプットの質が向上する「効率的な推論スケーリング」を実現しています。 クローズドβテストを実施します 金融機関・事業会社の経営戦略/事業企画部門、コンサルファーム、シンクタンクなど、日常的に高度なリサーチに取り組む方が対象です(期間中無料)。皆様からのフィードバックをもとに改善を重ねていきます。 ▼ クローズドβテスター応募はこちら https://t.co/fkaCwJceHb

