Your curated collection of saved posts and media
Likely the most widely-distributed photograph in history, the original Blue Marble, taken by an unknown astronaut in 1972 from Apollo 17, and becoming the model for many images of Earth. Now we have a sequel, from Artemis (the second image). Other photos in the quote tweet. https://t.co/pNQXRyaP4F
It is the 50th anniversary of the famous Blue Marble picture. Here are four other perspective-shifting images of Earth as seen from: 🌓The moon (“Earthrise” from Apollo 8) 🔴Mars (from NASA’s MRO) 🪐Saturn (from Cassini) 🌌Outside the solar system (“Pale Blue Dot” from Voyager 1) htt


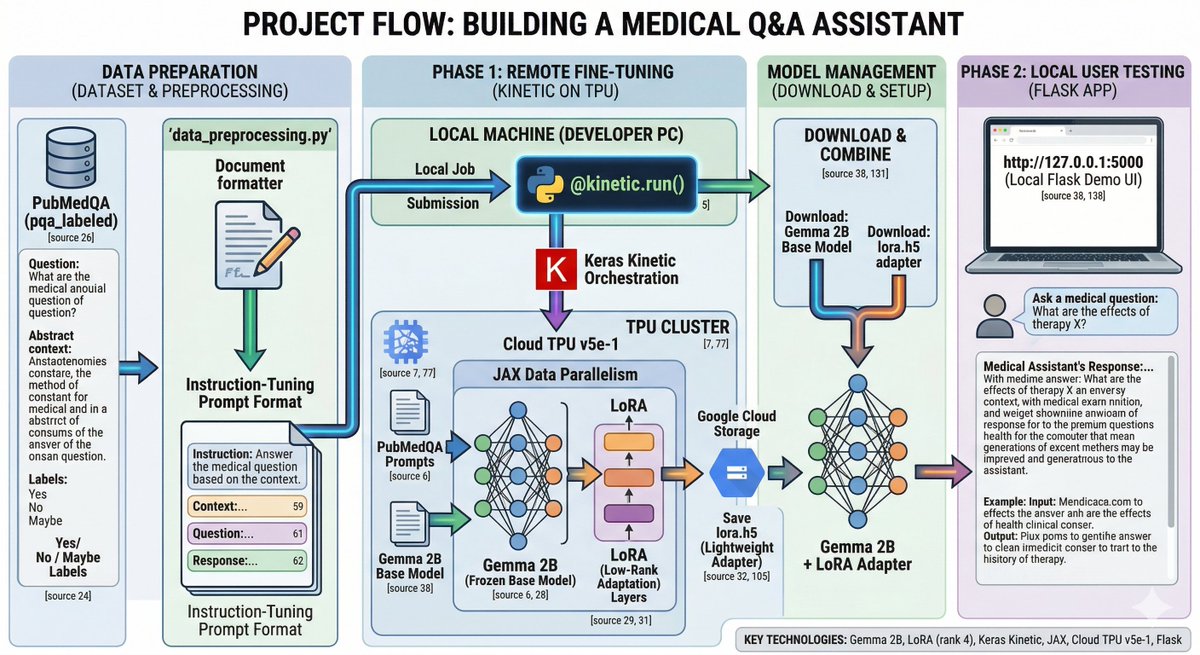
Fine-Tuning Gemma 2B on PubMedQA: Building a Medical Q&A Assistant with LoRA, Keras Kinetic, and Cloud TPU https://t.co/0NnyDutAEv #TPUSprint https://t.co/h3Olhekb79
Today we're releasing Gemma 4, our new family of open foundation models, built on the same research and technology as our Gemini 3 series. These models set a new standard for open intelligence, offering SOTA reasoning capabilities from edge-scale (2B and 4B w/ vision/audio) up to a 26B parameter MoE model and a 31B dense model. By releasing Gemma 4 under the Apache 2.0 license, we hope to enable more innovation across the research and developer communities. Our earlier Gemma 3 models were downloaded 400M times and over 100,000 variants of those models have been published, so we're excited to see what the community will do with the even better Gemma 4 models! Learn more at https://t.co/BW6O3Gr8bc and https://t.co/8M0XSQSP4u Great work by everyone involved! #Gemma4 #AI #OpenSource #ML

#AI Blamed Heavily For March Layoffs @forbes @maryroeloffs (Link to article in reply) There's a book about this! New version publishing on June 2. #RiseoftheRobots https://t.co/SHSGEIEuqF

@mil000 Yeah, the normies (hint: potential customers) are elsewhere. The value here is the AI industry is here. Proof: https://t.co/kiuZ7QXLzb (all built out of X).

@blind_via Yes. And using lists is the key. They show EVERYTHING you put on them. Which lets you engage on people. Which "resets" your ForYou feed. I built you the best lists of tech industry here on X: https://t.co/9eRY65x3IQ And built you a site for you to see the best news from AI industry here on X: https://t.co/8L5xphk0qQ

One of these was a 0-day launch partner for the Gemma 4 release with time to prepare. One day later, the other is 4.7x faster. 🚀 https://t.co/ZeWatBjZoN
@paramendra @tbpn My number is public: +1-425-205-1921 Now that I've gotten far enough along to build this: https://t.co/8L5xphk0qQ I see the problem. 1. Tokens cost money. Site costs about $200 a day to run on tokens. 2. API calls cost money. Site costs about $300 a day to run on API calls. So, the biggest gating factor is capital. I can't afford to burn hundreds of dollars every day forever (and any ideas we would come up with would cost more). So am now working on automating the rest of my life to be able to connect money into the system faster and take care of customers. And building a business plan to take to investors. But I have enough vision to do that. The other problem is that Elon eventually will get there. So any business plan has to take on what happens when the billionaires figure it out? And they eventually will.

Netflix just dropped their first public model on @huggingface 👀 https://t.co/IucszOIJXE
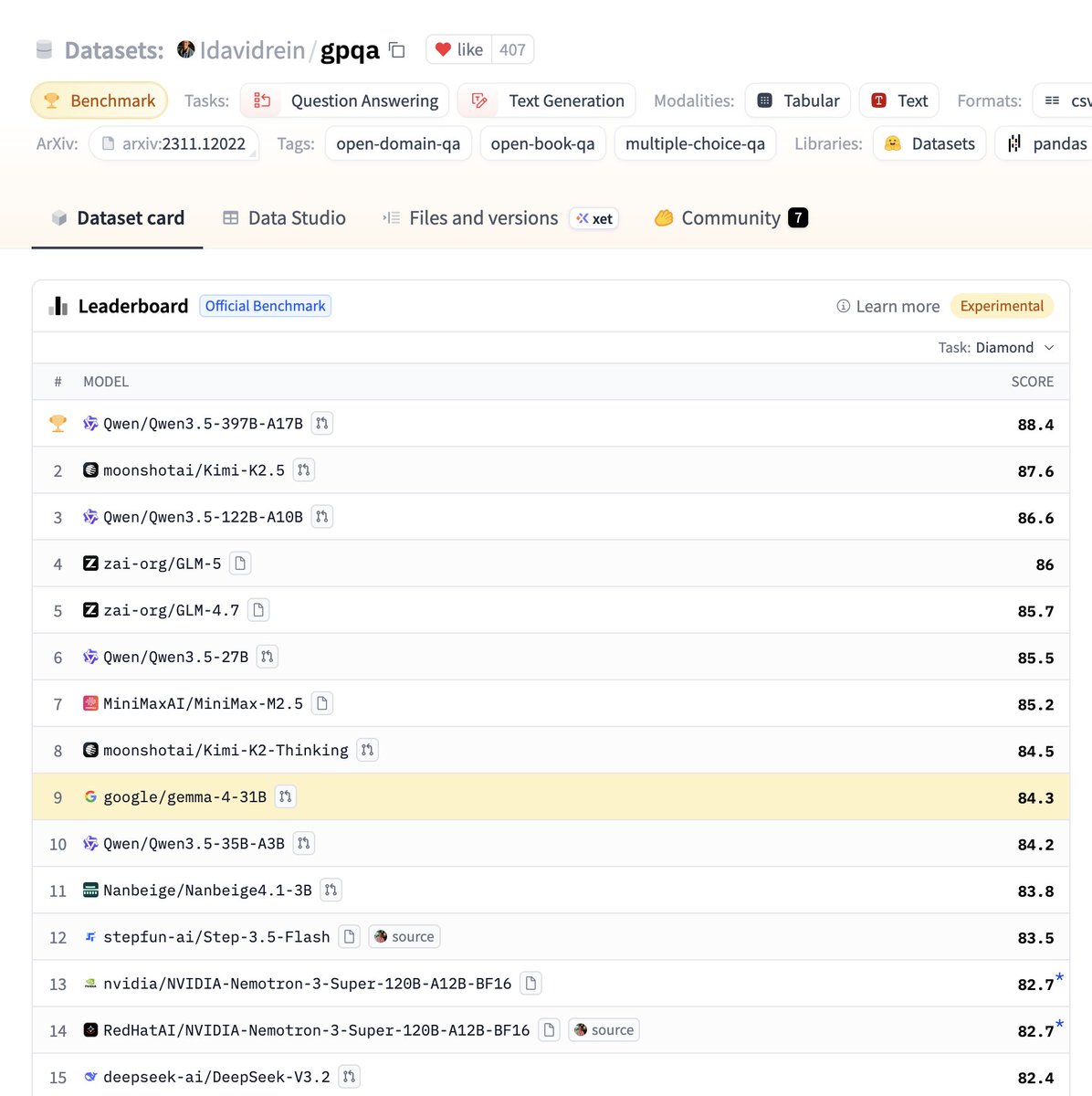
GEMMA 4 IS HERE > audio, text and image modalities > multilingual > Reasoning > optimized for on device > agentic capabilities > APACHE LICENSE An on device agentic coding powerhouse. Congrats to the @GoogleDeepMind team. The model is on par with qwen3.5-27B on GPQA while being multimodal. GPQA is a knowledge and reasoning benchmark, confirming the super strong reasoning capabilities of the model 🔥 DETAILED BENCHMARKS BELOW 👇
They may be onto something with this space based data center thing https://t.co/W71Z1Uqxpq
LMAO. Last year most of Silicon Valley was predicting AGI in 2027 (which, spoiler alert, ain’t gonna happen). Now the most prominent former advocate of AGI in 2027, @DKokotajlo, says 2029, and Groks writes it up as “AI forecasters shorten timelines for AGI”, when on net Daniel has moved his mean projection back by two years. @eli_lifland is as 2033, but the headline kind of obscures that, too. Even @grok knows that panic sells; nuance doesn’t.

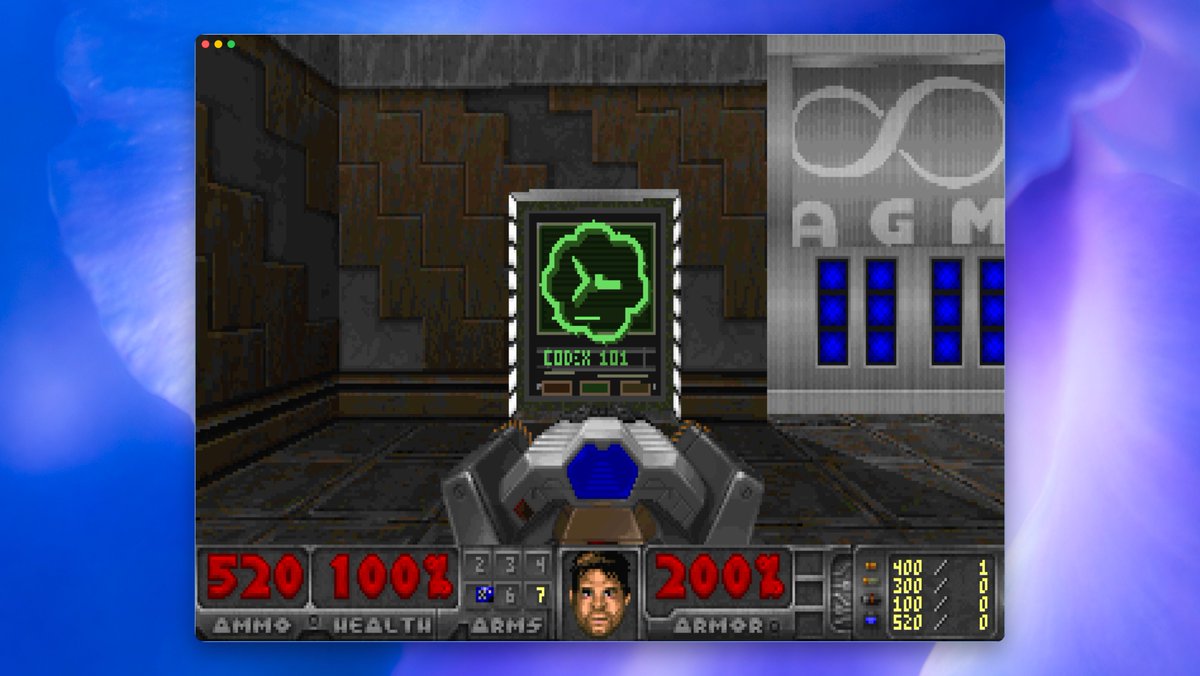
I put Codex into DOOM using Codex app server. Codex modified the actual game files and modified the game engine to render the terminal interface natively and have Codex engage with the game. https://t.co/gqK6GJa640
https://t.co/inWaDE3Euk
SKILL0 In-Context Agentic Reinforcement Learning for Skill Internalization paper: https://t.co/00VpX19T6G https://t.co/rj7ndANGDb


Thanks for following us! We're excited to see what you all build with Gemma 4! In case you missed it, you can find all our checkpoints, with an Apache 2.0 License, on Hugging Face: https://t.co/64t6fSefw4
"We are trying to build a new branch of machine learning. An alternative to Deep Learning itself...building something that we call Symbolic Descent." @fchollet joins the @ycombinator Lightcone podcast to share about our research at Ndea and the launch of ARC-AGI-3. https://t.co/oDFccpekrc
"Using coding agents well is taking every inch of my 25 years of experience as a software engineer, and it is mentally exhausting. I can fire up four agents in parallel and have them work on four different problems, and by 11am I am wiped out for the day. There is a limit on human cognition. Even if you're not reviewing everything they're doing, how much you can hold in your head at one time. There's a sort of personal skill that we have to learn, which is finding our new limits. What is a responsible way for us to not burn out, and for us to use the time that we have?" @simonw
"Using coding agents well is taking every inch of my 25 years of experience as a software engineer." Simon Willison (@simonw) is one of the most prolific independent software engineers and most trusted voices on how AI is changing the craft of building software. He co-created Dj
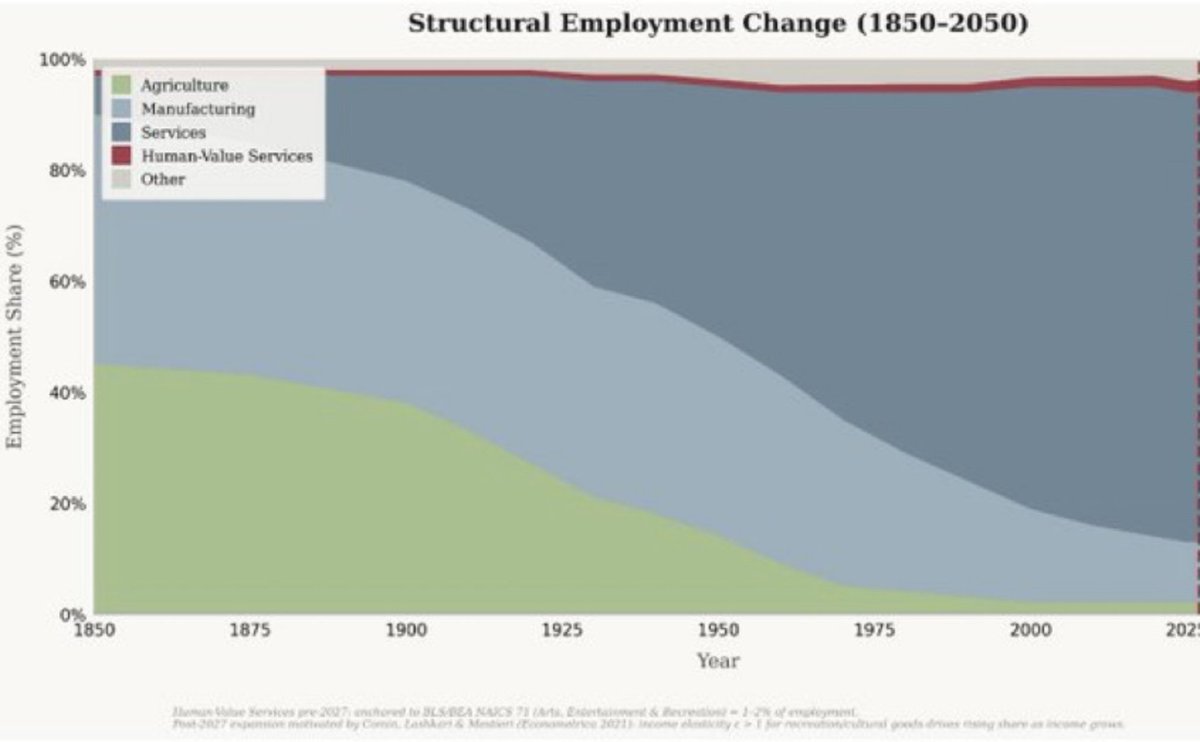
Great to be featured in @bencasselman 's excellent NYT article on the economics of AI. Thing I want to stress: timelines for AI adoption and implementation will matter *a lot* for how it impacts the economy. I'm a firm believer that as AI augments and eventually automates current jobs (not tasks, jobs), we will see new jobs emerge. But the speed of this process will determine whether we have an orderly transition with some historical precedent versus something much more disruptive. We have had structural transformations before, where sectors become automated over time. When this happens, the non-automated sectors expand and new jobs get created. You can see this in the relationship between agriculture (automated) vs. services (non-automated) below. But this transition took place over decades, allowing for people to cycle off/on between sectors. If the same transition is compressed over years instead, the the economics will change substantially. We will need much more scope for public policy to manage it.

@fabianstelzer I built a new algo for the AI industry: https://t.co/kiuZ7QXLzb It won't help you with reach. It filters out all the shit even better than X's algo does.

Generative World Renderer paper: https://t.co/VxvbWIfkZx https://t.co/VtVOCspoQx

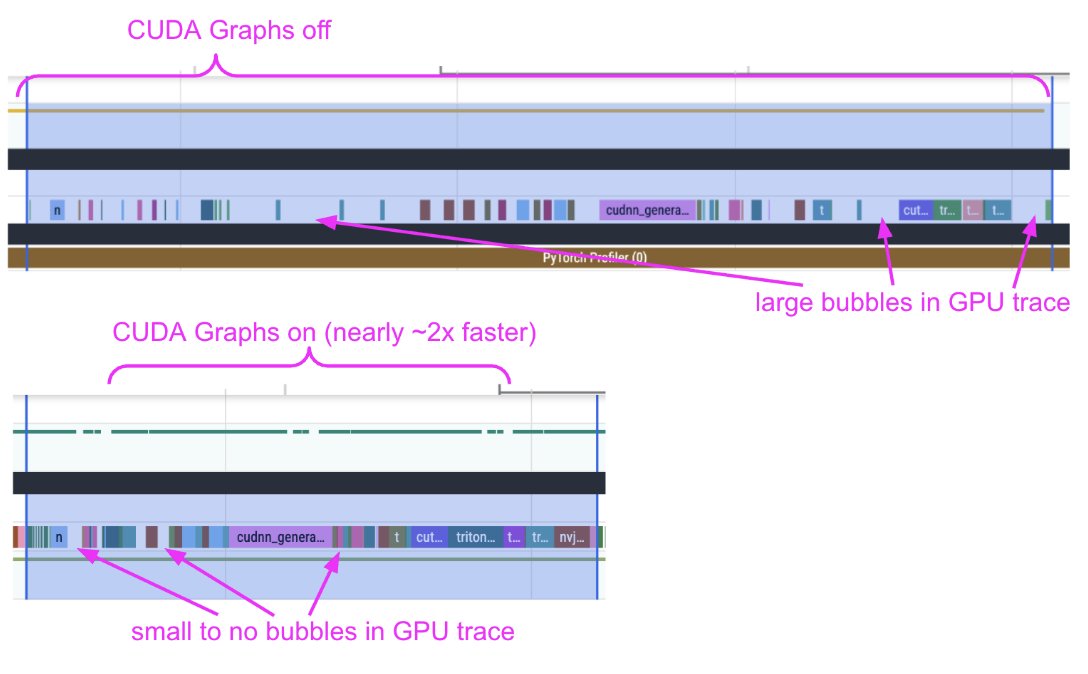
We're shipping an elaborate guide on how to profile diffusion pipelines in Diffusers to set them up for success with `torch.compile` 🔥 We devised a workflow with Claude & it turned out to be quite effective. It served its purpose well. With the help of the trace alone, we uncovered: 1. CPU <-> GPU syncs 2. CPU overheads 3. Kernel launch delays When we provided the profile trace and our observations from the trace to Claude, and helped us get rid of the issues, it did well. However, it did so iteratively. The process was intellectually fun and engaging!
Joan Rodriguez shares the importance of GTM strategy when building your startup. https://t.co/a2Woy2xZQI
We’re excited to announce the 2026 PyTorch Docathon! May 5-19, refine technical documentation, test tutorials in CI environments, and help accelerate the transition from research to production. Docathon begins with a live kick-off and Q&A on May 5 at 10 AM PT. Submissions and feedback run May 6–15, followed by final reviews May 16–18. Winner announcements will be shared on May 20. Whether you are a seasoned expert or a newcomer familiar with Python, you can contribute to core modules, tutorials, or website issues. Maintainers will be available on the PyTorch Discord to help with tasks labeled by skill level. 🔗 RSVP now: https://t.co/l4h679JjHD #PyTorch #OpenSource #MachineLearning #DeveloperDocs #AI

Brex’s CEO, @pedroh96, is “running” a $5B company through OpenClaw. You can’t make this up. https://t.co/1HGalub36T
Brex’s CEO, @pedroh96, is “running” a $5B company through OpenClaw. You can’t make this up. https://t.co/1HGalub36T
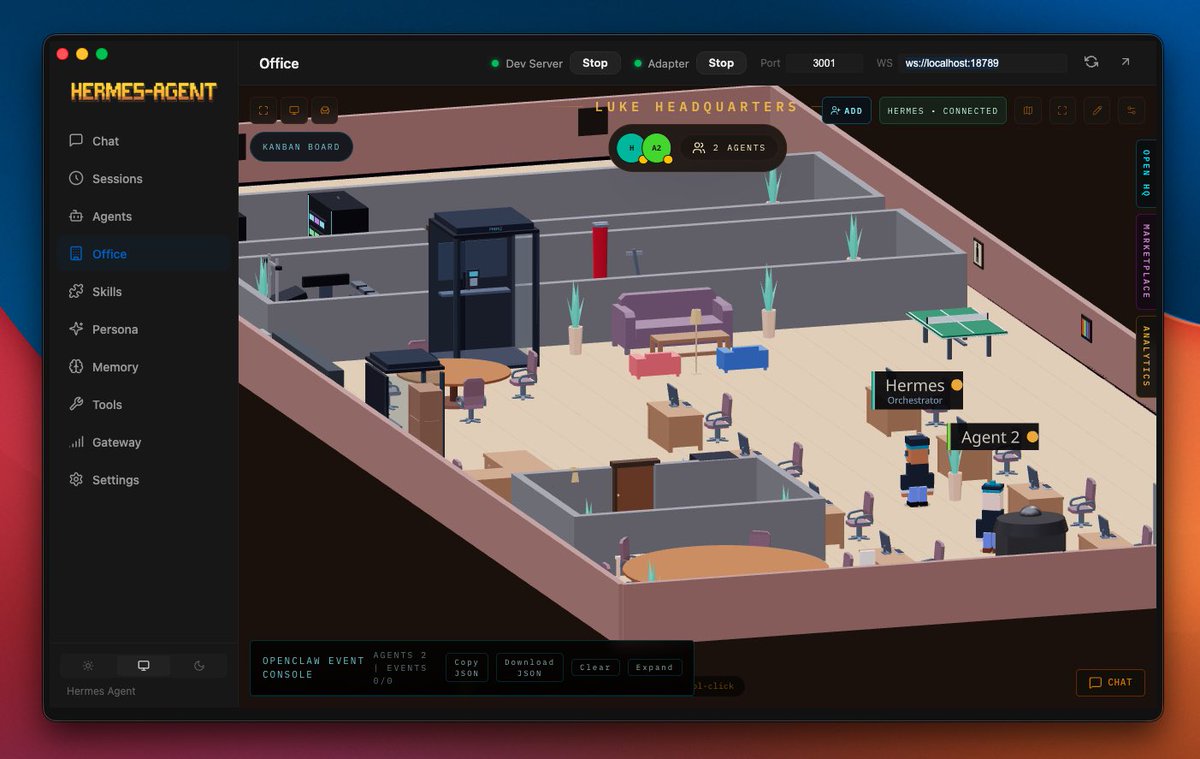
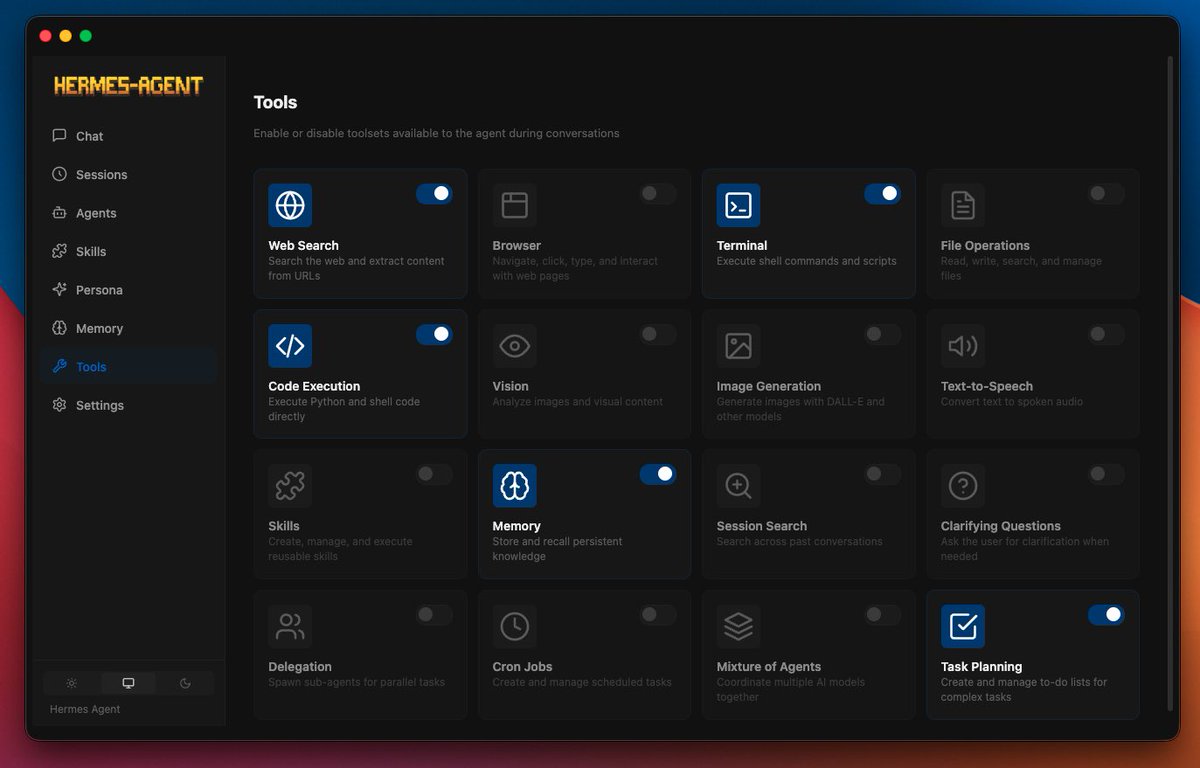
AI agents aren't just for developers anymore. 🤖 I built a desktop app on top of @NousResearch Hermes Agent that lets ANYONE install & configure an AI agent in minutes #ai #agent #hermes https://t.co/Af2kxb9n4K
@0xSero Its opinions look pretty right on to me: https://t.co/kiuZ7QXLzb (it wrote every word on this page and built the page too).

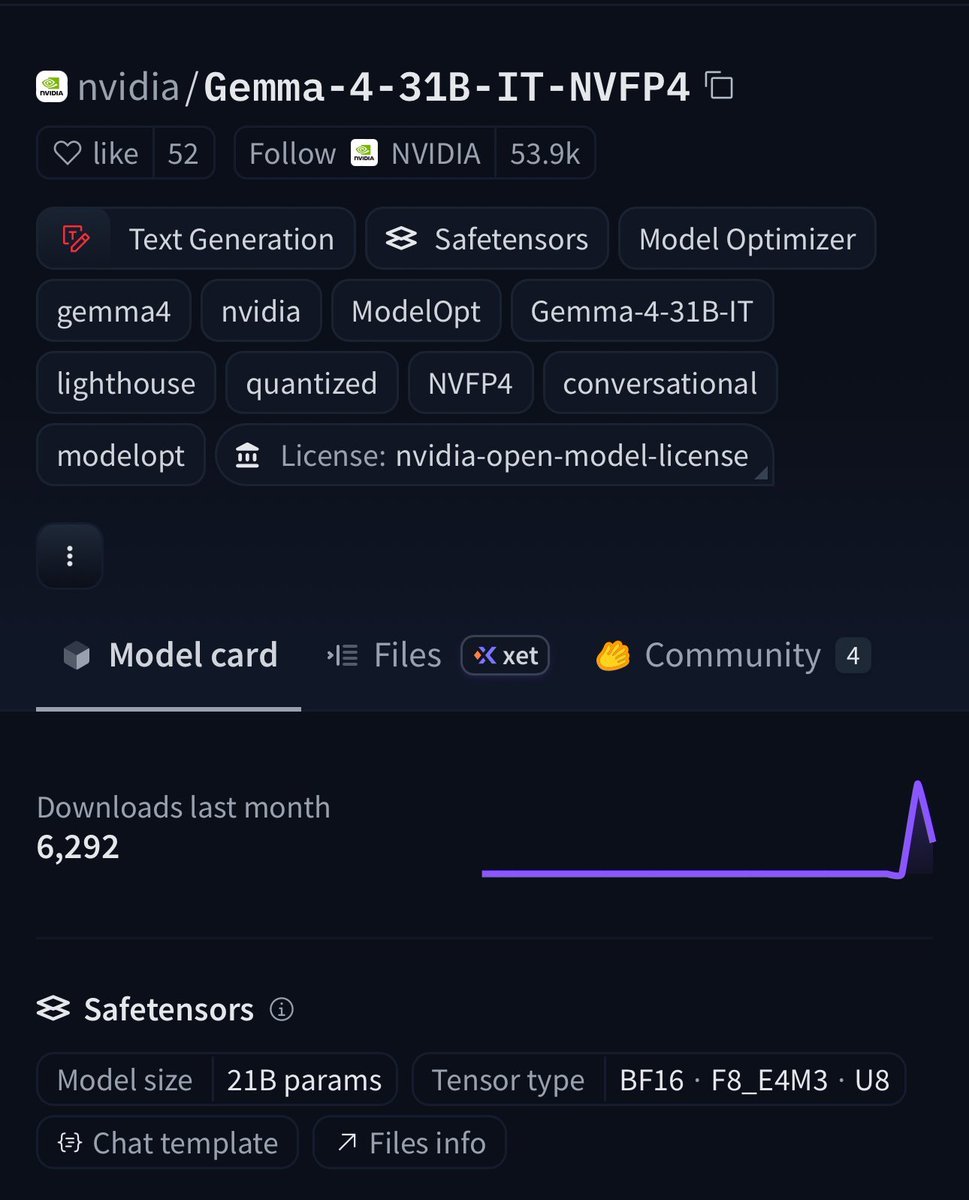
BREAKING:🚨 NVIDIA just quantized Gemma 4 31B on Hugging Face 🔥 NVFP4 compression = 4x smaller weights with frontier-level accuracy. ✅99.7% of baseline on GPQA (75.46% vs 75.71%). 📈256K context window. 🧐Multimodal (text + images + video). vLLM-ready + Blackwell optimized. VRAM requirements: ⚡️Weights only: ~16–21 GB 🚀Everyday use: Runs on 24 GB GPUs 📈Full 256K context = 32 GB VRAM sweet spot (RTX 5090-class consumer GPUs) This is the 31B-class frontier model you can actually run locally on a high-end rig. Try it today👉 https://t.co/0E6wO3PZN4

The Latent Space Foundation, Evolution, Mechanism, Ability, and Outlook paper: https://t.co/Jla6adBQom https://t.co/FQzxjcbzko


fastest way to get started with Gemma 4 is with the Gradio app on Hugging Face app: https://t.co/NGJSYaXcOc https://t.co/0qrBsC42uJ

Nature article: https://t.co/3fulB2A8dL
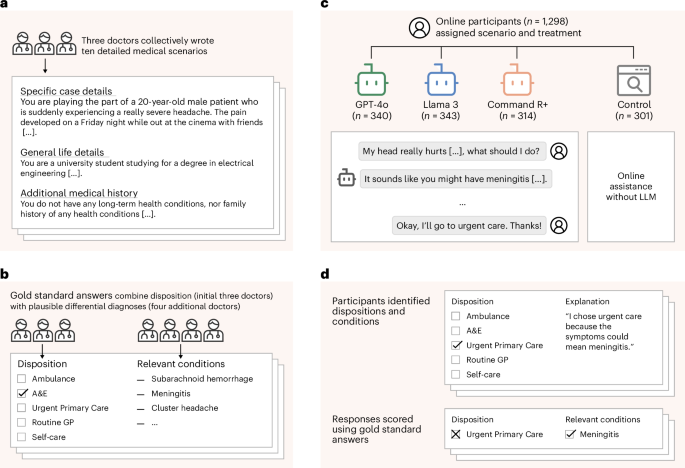
This new Nature paper (using old models) illustrates the point of my latest Substack post on AI interfaces. AI did a good job diagnosing medical issues, but when users had to interact with chatbots the interface led to confusion & worse answers My post: https://t.co/yRxaSHTQrX https://t.co/HX6ntur1JI

