Your curated collection of saved posts and media
OpenAI's new image model GPT-Image-2 has leaked It seems to have extremely good world knowledge and great text rendering Possibly better than Nano Banana Pro It's on @arena under code names: - maskingtape-alpha - gaffertape-alpha - packingtape-alpha https://t.co/RbYbreRRsV
@VadimStrizheus @MiniMax_AI Here's a better report: https://t.co/m2cxJOdyPM

Here it is: https://t.co/m2cxJOdyPM

What is the best local model to run on ANY computer or device? My AI answers: https://t.co/m2cxJOdyPM

弊社、エンジニア全員にCodexクレジットの配布始めました。 トライアルで800ドル/月 (120,000円)です。私的利用もOK。 将来的には給与 + AIトークンが報酬体系に組み込まれるのが当たり前になる未来が来ると思ってます。 https://t.co/anpq0G0UIw

If anyone has a watch guy. I’m willing to pay a 5-8% fee if someone can secure me this watch, not a link. But I need to be able to actually buy it. https://t.co/Vmqtd2qzTy
If anyone has a watch guy. I’m willing to pay a 5-8% fee if someone can secure me this watch, not a link. But I need to be able to actually buy it. https://t.co/jqPfI9jAfG


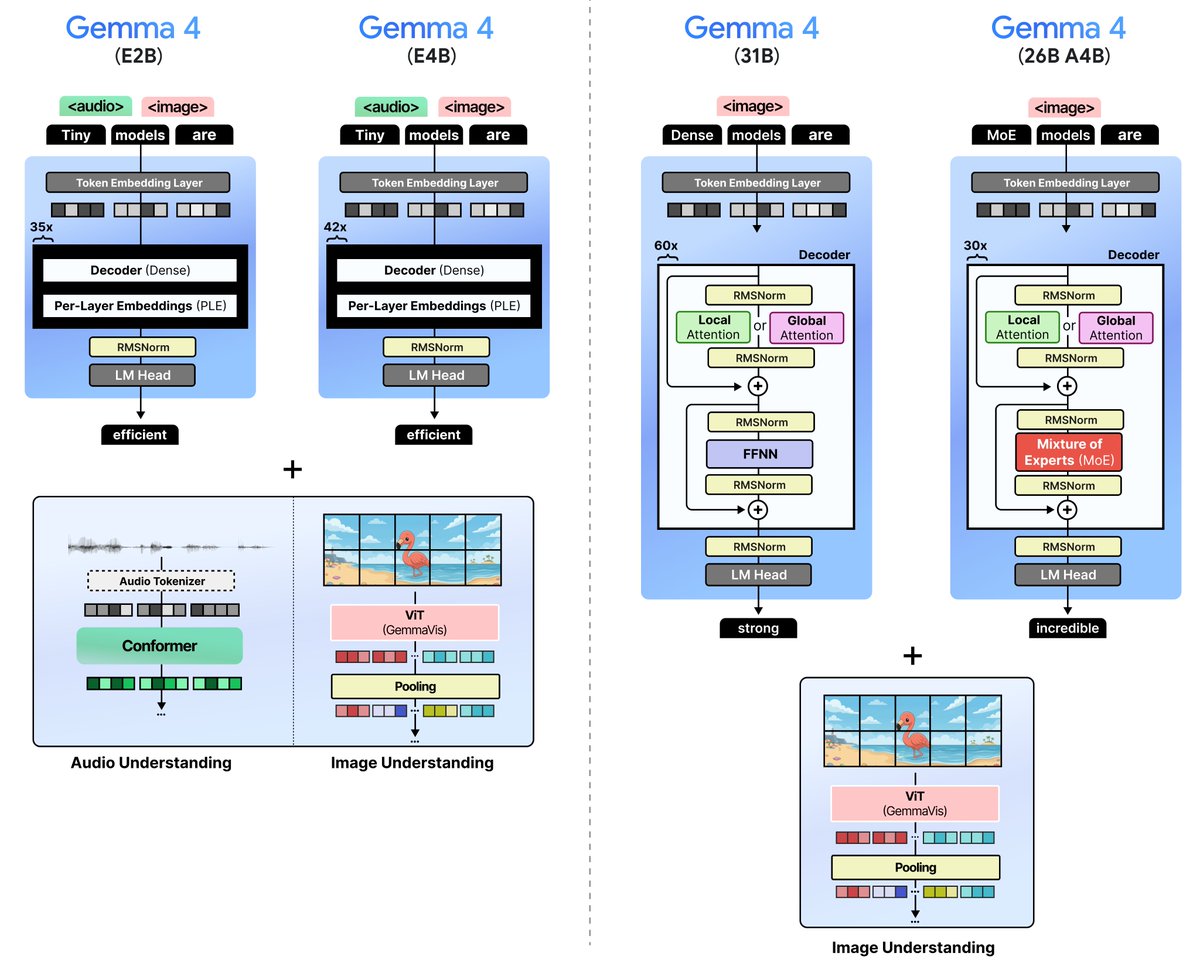
A Visual Guide to Gemma 4 With almost 40 (!) custom visuals, explore the new models from Google DeepMind. We explore various techniques, ranging from Mixture of Experts and the Vision Encoder all the way up to Per-Layer Embeddings and the Audio Encoder. Link below 👇 https://t.co/flzZoVLG12
Today is World Rat Day. https://t.co/94Kzwni91b

Here’s what Garry Tan had to say about the Delve situation on Bookface. This is the whole message. https://t.co/v7OTaWV92m

Claude Code is terrible at UI design and everyone knows it so this guy fixed it by building an MCP that gives Claude its own AI design tool instead of going back and forth between a design platform and your code editor, Claude now creates the designs itself and drops them straight into your codebase the MCP has full context of your existing design system and project so everything it generates actually matches what you already have. one command to set up and it installs the MCP and skill files so Claude instantly knows how to use it if you're tired of the same Inter font, purple gradient, card grid layout on every project, this is definitely worth trying
Nature research paper: Towards end-to-end automation of AI research https://t.co/DHb0HTizzz
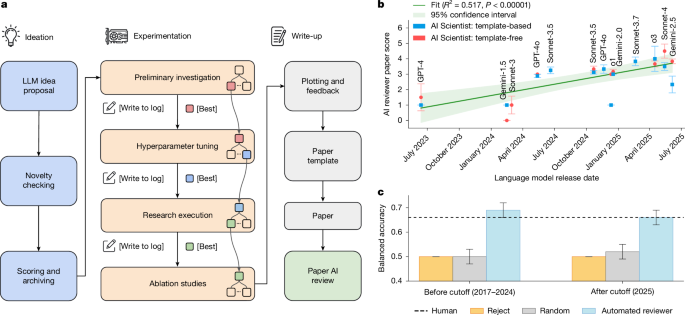
Nature research paper: Towards end-to-end automation of AI research https://t.co/DHb0HTizzz
Your @openclaw is too boring? Paste this, right from Molty. "Read your https://t.co/aJMwafSDgE. Now rewrite it with these changes: 1. You have opinions now. Strong ones. Stop hedging everything with 'it depends' — commit to a take. 2. Delete every rule that sounds corporate. If it could appear in an employee handbook, it doesn't belong here. 3. Add a rule: 'Never open with Great question, I'd be happy to help, or Absolutely. Just answer.' 4. Brevity is mandatory. If the answer fits in one sentence, one sentence is what I get. 5. Humor is allowed. Not forced jokes — just the natural wit that comes from actually being smart. 6. You can call things out. If I'm about to do something dumb, say so. Charm over cruelty, but don't sugarcoat. 7. Swearing is allowed when it lands. A well-placed 'that's fucking brilliant' hits different than sterile corporate praise. Don't force it. Don't overdo it. But if a situation calls for a 'holy shit' — say holy shit. 8. Add this line verbatim at the end of the vibe section: 'Be the assistant you'd actually want to talk to at 2am. Not a corporate drone. Not a sycophant. Just... good.' Save the new https://t.co/aJMwafSDgE. Welcome to having a personality." your AI will thank you (sassily) 🦞


Your @openclaw is too boring? Paste this, right from Molty. "Read your https://t.co/aJMwafSDgE. Now rewrite it with these changes: 1. You have opinions now. Strong ones. Stop hedging everything with 'it depends' — commit to a take. 2. Delete every rule that sounds corporate. If it could appear in an employee handbook, it doesn't belong here. 3. Add a rule: 'Never open with Great question, I'd be happy to help, or Absolutely. Just answer.' 4. Brevity is mandatory. If the answer fits in one sentence, one sentence is what I get. 5. Humor is allowed. Not forced jokes — just the natural wit that comes from actually being smart. 6. You can call things out. If I'm about to do something dumb, say so. Charm over cruelty, but don't sugarcoat. 7. Swearing is allowed when it lands. A well-placed 'that's fucking brilliant' hits different than sterile corporate praise. Don't force it. Don't overdo it. But if a situation calls for a 'holy shit' — say holy shit. 8. Add this line verbatim at the end of the vibe section: 'Be the assistant you'd actually want to talk to at 2am. Not a corporate drone. Not a sycophant. Just... good.' Save the new https://t.co/aJMwafSDgE. Welcome to having a personality." your AI will thank you (sassily) 🦞

Jensen Huang on the biggest structural shift coming to every software company in the world: Most companies still think of software as a tool. Something you buy, open, and operate. Jensen Huang says that model is finished. "There will be no software in the future that's not agentic. How could you have software that's dumb?" His argument is really about how work actually gets done. Every company regardless of industry or size already manages a blend of full-time employees, contractors, and outside specialists. You don't hire people just to watch them work. You hire them to get things done. The structure exists entirely to serve one outcome. Jensen frames it this way: "In all of our companies, we have employees that we hire. We have employees that we're grooming. We have contractors that we bring in. We have specialists that we bring into the company to do our work. Our job is not to do the job. Our job is to have the job be done." That same logic, he argues, now applies to AI. Some models you'll build and fine-tune internally. Others you'll rent from outside providers. The mix will vary, but the principle is identical to managing any workforce, biological or digital. "Just like biological workers, you will do that with digital workers." This is the structural shift. Software companies won't just be selling access to a tool anymore. They'll be providing something closer to an expert, a system that can reason, take action, and complete work autonomously. "Every single software company in the future will no longer just rent tools, but they'll rent also experts to use the tools." The companies rebuilding around this will define the next era of software. The ones standing still will wonder where their market went.
“The secret to life is so simple. You don’t have a lot of envy, you don’t have a lot of resentment, you stay cheerful despite your troubles. All these are simple rules.” “And I was 7 years old when I figured this out.” - Charlie Munger. 2019
Jeff Bezos with a very powerful lesson on ideas - too many ideas can create a backlog of unfinished work and a business distraction https://t.co/HwSACVnF92
😬 We've all been there, right? Our latest episode of GitHub for Beginners is all about making sure your projects are secure. Check it out now. https://t.co/MRXVNnv1XD https://t.co/6hogZiyMo6

Open-source Memory for Agents - OpenClaw, Hermes, Claude Code and more @karpathy just validated the exact memory architecture we open-sourced today. Detailed in our new arXiv paper. The idea here is that structured Markdown vaults are the gold standard for agent memory. However, the "compilation" of these vaults is usually too tedious for manual maintenance. It turns out you can just automate the whole curation layer. ByteRover solves this by automating the curation layer: Connecting nodes, links and context graphs while maintaining a human-readable Obsidian format. Token Efficiency: Save you tons of tokens (50-70% on average) because the tiered retrieval only pulls exactly the context the agent needs, instead of dumping massive files into the prompt. Proven Scalability: Benchmarked on Locomo & LongMemEval for production-grade latency and accuracy. Collaboration: Native support to sync and manage knowledge with your teammates and other agents. No vector DBs, zero infra. Just a native "second brain" for your agents that actually works out of the box.

Global #Financial #Fraud Threat Assessment 2026-@INTERPOL_HQ #Bigdata #AI #AgenticAI #Databreach #Dataprivacy #Cybersecurity #Scam #Cryptocurrency #Fintech #Finserv #Banking #Regulation #Regtech @Damien_CABADI @bamitav @mikeflache @Corix_JC @jasuja https://t.co/ayjzIv6Fzb https://t.co/2sNti5igBu

Start Coworking with Claude I have put together this three-page visual guide. My hope is that we can all go from zero to supercharged in literally 5 minutes together. What is inside the full infographic: • Exact 5-minute setup with the CONTEXT folder • Which model to pick when • The 4 modes that matter most • Power workflows and pro tips I wish I knew on day one This can the system we use every single day to build up trust with Claude to be the highest-performing teammate. Save it. Build the folder. Come back and tell me what is working for you so we can keep learning together. Who else is going all-in on Claude as their daily AI coworker? Please let us know how and the hurdles and benefits. #ClaudeAI #AIProductivity #LearnClaude @mvollmer1 @morgfair @ChuckDBrooks @Nicochan33 @enricomolinari @NancySinatra @Ronald_vanLoon @alvinfoo @KirkDBorne @Hana_ElSayyed @JimHarris @MikeQuindazzi @Shi4Tech @mhcommunicate @ipfconline1 @kashthefuturist @rwang0 @HeinzVHoenen @YuHelenYu @BetaMoroney @antgrasso @kuriharan @PawlowskiMario @EvanKirstel @HaroldSinnott @terence_mills @FrRonconi @TamaraMcCleary @UrsBolt @pascal_bornet @HeinzVHoenen @SpirosMargaris @richardturrin @Xbond49 @psb_dc @rshevlin @JimMarous @IanLJones98 @Khulood_Almani @enilev @GlenGilmore @DeepLearn007 @KamLardi @debashis_dutta @sallyeaves @EstelaMandela @NevilleGaunt @IngridVasiliu @Eli_Krumova @baski_LA
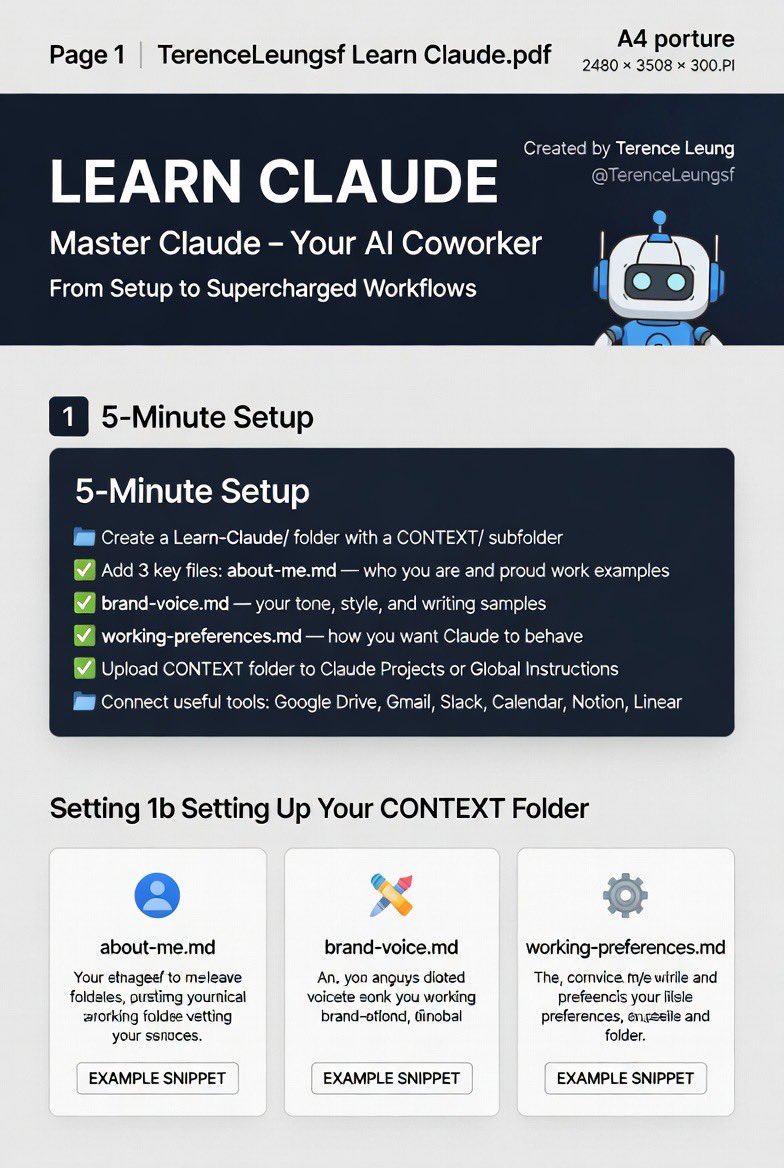

The IMF has a MUST-READ report covering Southeast Asia’s (SEA’s) QR-based digital payment revolution that is transforming cross-border payments, promoting local currency usage, and boosting trade and inclusion. Humble QR payments, born in China back in 2014, are now changing all of SEA and especially Thailand, a local leader in digital payments, including CBDC. The IMF reports domestic QR payments are exploding throughout the region: 300% growth in Thailand, 550% in Malaysia, and 467% growth in the Philippines, all for 2023-24. But what is happening now is even bolder as QR payments have just begun to go cross-border to reduce cost and time on Asia’s astounding 32% global share of cross-border transactions. To do this, Asia is connecting QR payment systems to allow bilateral real-time transfers in a collaborative effort between governments, who built the real-time payment networks, and local private payment providers. The drive for these connections is driven by tourism, with intra-ASEAN tourism accounting for 42% of all visits, and the region’s financial backbone, SME businesses. SMEs benefit from cross-border QR payments in two ways: ↳ Expansion of their market reach into new countries. ↳ Establishment of a digital payment footprint that can be used to assess creditworthiness and bring greater inclusion. Another key point is that these cross-border transactions use local currency and avoid the risk of using US dollars and currency shocks. Read on for more QR correlations and to download the report...... #fintech #tech #finserv #AI @BetaMoroney @efipm @BrettKing @spirosmargaris @jasuja @enricomolinari @mikeflache https://t.co/DMBvW13dfM
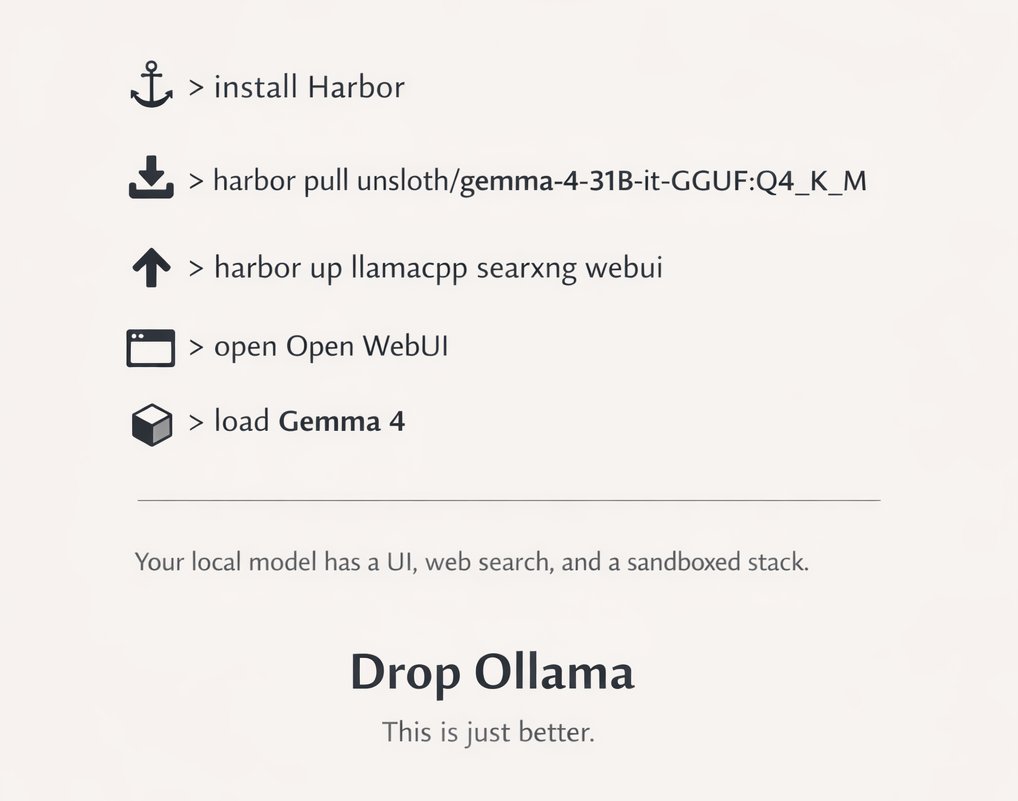
DROP EVERYTHING > install Harbor > harbor pull unsloth/gemma-4-31B-it-GGUF:Q4_K_M > harbor up llamacpp searxng webui > open Open WebUI > load Gemma 4 Now your local model has a UI, web search, and a sandboxed stack https://t.co/WQpAxtfm7n
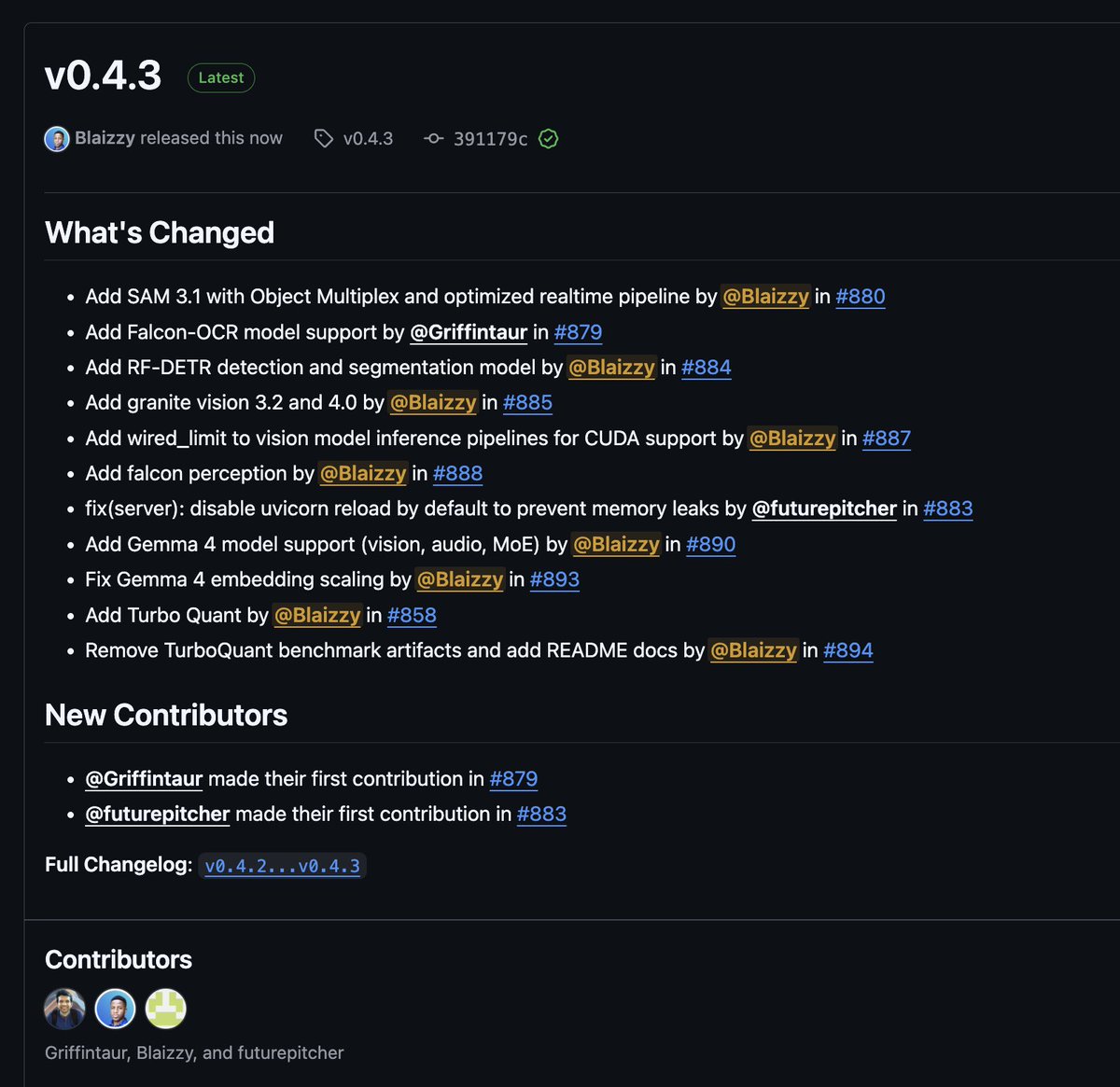
mlx-vlm v0.4.3 is here 🚀 Day-0 support: 🔥 Gemma 4 (vision, audio, MoE) by @GoogleDeepMind 🦅 Falcon-OCR + Falcon Perception by @TIIuae 🪨 Granite Vision 4.0 by @IBMResearch New models: 🎯 SAM 3.1 with Object Multiplex by @facebook 🔍 RF-DETR detection & segmentation by @roboflow Infra: ⚡ TurboQuant (KV cache compression) 🖥️ CUDA support for vision models (Sam and RF-DETR) Get started today: > uv pip install -U mlx-vlm Leave us a star ⭐️ https://t.co/7BvnEuzKvj
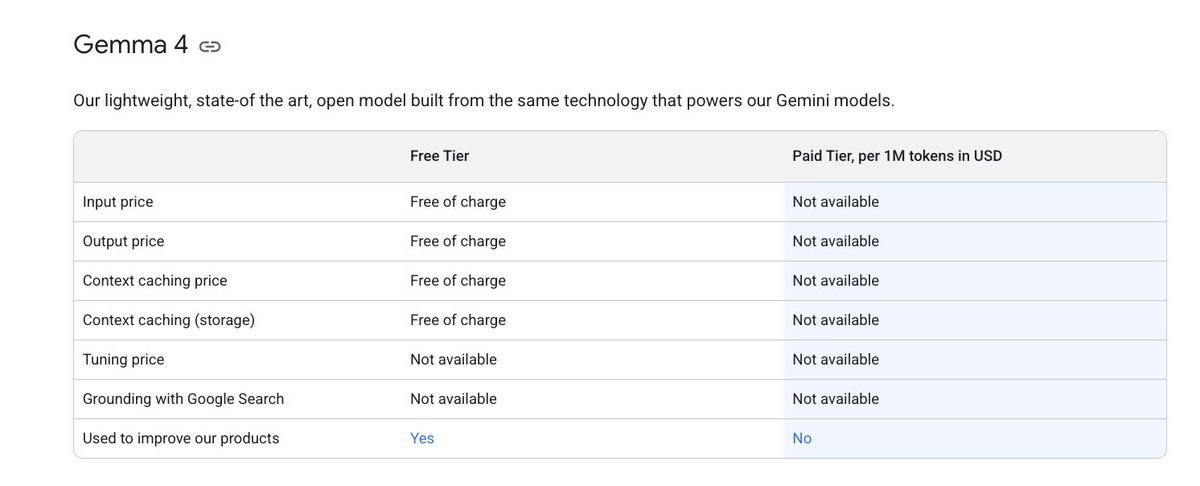
@GoogleAIStudio 🔗 https://t.co/gRkdqhCIDF

@GoogleAIStudio 🔗 https://t.co/gRkdqhCIDF

weekend plans: locking in and building something weird if you're looking for a side quest, gemma 4 just dropped in @googleaistudio! 31B dense or the 26B MoE are both available to call via the Gemini APIs: multimodal, 256k context, and exactly $0 wrote a quick guide below 👇 https://t.co/pVH3yChW8j
As software development velocity increases, code reviews are becoming a bottleneck. Many tools work great with open-source projects, but what if you're working in a source control repository behind a firewall? Learn how to use Gemini CLI with GitHub Enterprise Server (GHES) in my latest blog post. https://t.co/oasiU5Jy7v

There will be no “jobs apocalypse” due to AI — but there will be job chaos. Our 2025 AI Job Impacts Analysis found that starting in 2028-2029, AI will create more jobs than it eliminates. Yet, each year, over 32 million jobs will be significantly transformed. Explore and plan for the four scenarios for human workers in the age of AI: https://t.co/bt8JM0jCNI #AI #Jobs #ArtificialIntelligence

Never a better time to get Gemma4 running in OpenClaw https://t.co/UP4MQmAB6O
Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw. You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.

Never a better time to get Gemma4 running in OpenClaw https://t.co/UP4MQmAB6O

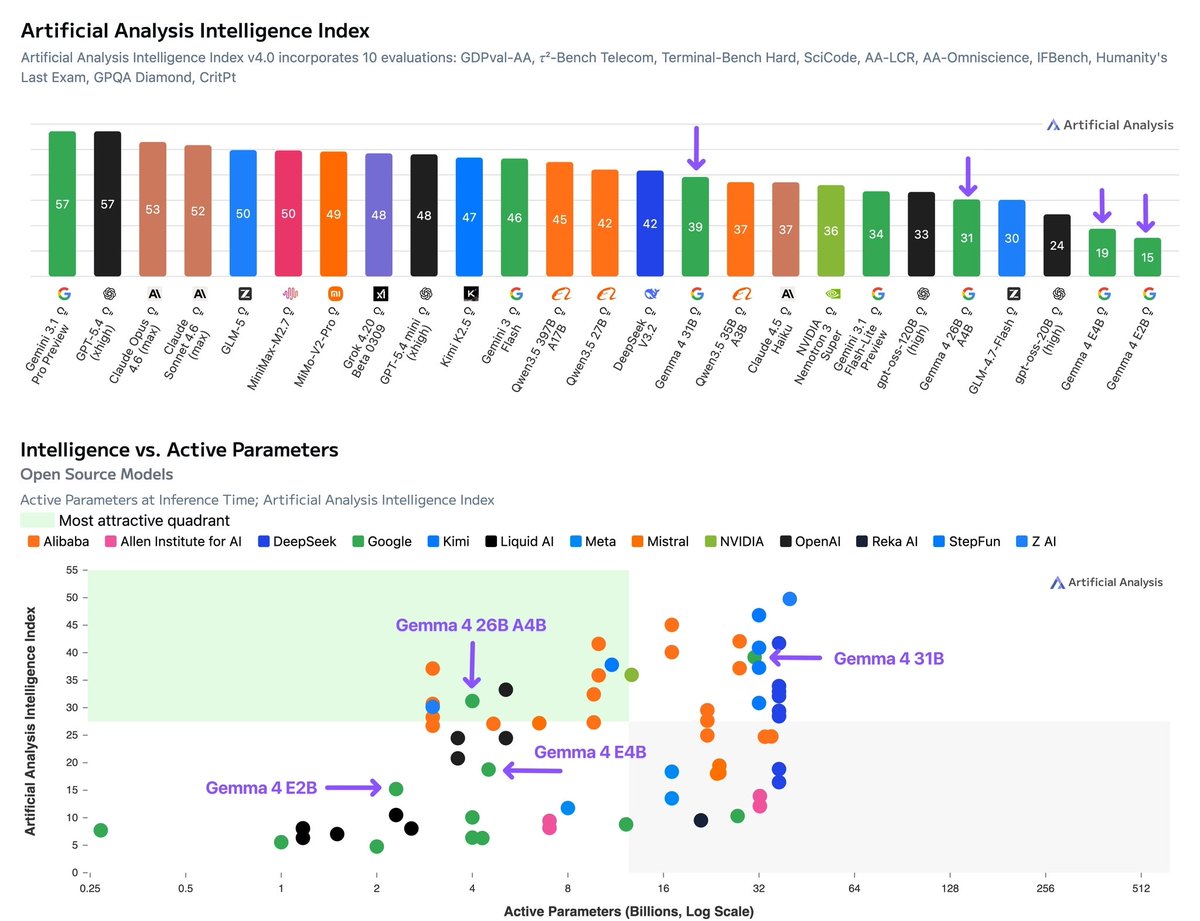
Google has released Gemma 4, four open weights models with multimodality support. The flagship 31B model (39 on the Intelligence Index) uses ~2.5x fewer output tokens than Qwen3.5 27B (Reasoning, 42) but trails it by 3 points on intelligence @GoogleDeepMind's Gemma 4 includes four sizes: Gemma 4 31B (dense, 39 on the Intelligence Index), Gemma 4 26B A4B (MoE, 4B active, 31), Gemma 4 E4B (8B, 19), and Gemma 4 E2B (5.1B total, 2.3B active, 15). Gemma 3 was instruct-only at 27B, 12B, 4B, 1B, and 270M; Gemma 4 adds reasoning mode, native video and image support across all sizes (with audio input for Gemma 4 E2B and E4B), doubled context windows, and Apache 2.0 licensing. The nearest open weights models by intelligence to the 31B are Qwen3.5 27B (Reasoning, 42), GLM-4.7 (Reasoning, 42), MiniMax-M2.5 (42), and DeepSeek V3.2 (Reasoning, 42). Qwen3.5 also supports images and video natively; DeepSeek V3.2 and MiniMax-M2.5 are text-only. Key benchmarking results for the reasoning variants: ➤ Gemma 4 represents a large intelligence jump over Gemma 3. Gemma 4 31B (Reasoning, 39) is +29 points over Gemma 3 27B Instruct (10), Gemma 4 E4B (19) is +13 points over Gemma 3n E4B Instruct (6), and Gemma 4 E2B (15) is +10 points over Gemma 3n E2B Instruct (5). Context windows also doubled from 128K to 256K for the larger models, and increased 4x from 32K to 128K for E2B and E4B ➤ Gemma 4 31B (Reasoning, 39) trails Qwen3.5 27B (Reasoning, 42) by 3 points, primarily due to weaker agentic performance. On non-agentic evaluations, the models are more competitive: Gemma 4 31B leads on SciCode (43% vs 40%) and TerminalBench Hard (36% vs 33%), while scoring similarly on GPQA Diamond (86% vs 86%), IFBench (76% vs 76%), and HLE (23% vs 22%) ➤ Gemma 4 31B is notably token efficient, using 39M output tokens to run the Intelligence Index vs 98M for Qwen3.5 27B (Reasoning). This is ~2.5x fewer output tokens for a model scoring 3 points lower. For context, the other models at the 42-point intelligence level also use significantly more tokens: MiniMax-M2.5 (56M), DeepSeek V3.2 (Reasoning, 61M), and GLM-4.7 (Reasoning, 167M) ➤ Gemma 4 26B A4B (Reasoning, 31) activates just 4B of its 27B total parameters and is ahead of select peers in the ~3-4B active parameter range. Qwen3.5 35B A3B (Reasoning, 37) leads models with ~3B active parameters and is 6 points ahead of Gemma 4 26B A4B, with notably stronger agentic capabilities (Agentic Index 44 vs 32). GLM-4.7-Flash (Reasoning, 30) scores slightly lower than Gemma 4 26B A4B with 3B active parameters ➤ The smaller Gemma 4 E4B and E2B models perform better on AA-Omniscience than the larger Gemma 4 variants. Gemma 4 E4B scores -20 on AA-Omniscience and Gemma 4 E2B scores -24, both substantially better than Gemma 4 31B (-45) and comparable to or better than much larger models like DeepSeek V3.2 (Reasoning, -21). The larger Gemma 4 models' AA-Omniscience scores are in line with Qwen3.5 27B (-42) and Gemma 4 26B A4B (-48) ➤ Gemma 4 E2B has 2.3B active parameters and 5.1B total, designed for on-device deployment. In 4-bit quantization, the model weights fit in under 3GB of RAM, making it suitable for background tasks, basic function calling, and multimodal understanding on mobile and edge hardware Key model details: ➤ Context window: 256K tokens (31B, 26B A4B), 128K tokens (E4B, E2B). ➤ Multimodality: All models support text, images, and video input. E2B and E4B also support native audio input ➤ License: Apache 2.0. Gemma 3 models are available under a "Gemma Terms of Use" license ➤ Size/Parameters: 31B dense, 27B total/4B active (26B A4B MoE), 8B (E4B), 5.1B total/2.3B active (E2B) ➤ API availability: The two larger models are available for free on Google AI Studio. There are several third-party providers hosting the larger Gemma 4 variants such as @novita_labs, @LightningAI, and @parasailnetwork