@llama_index
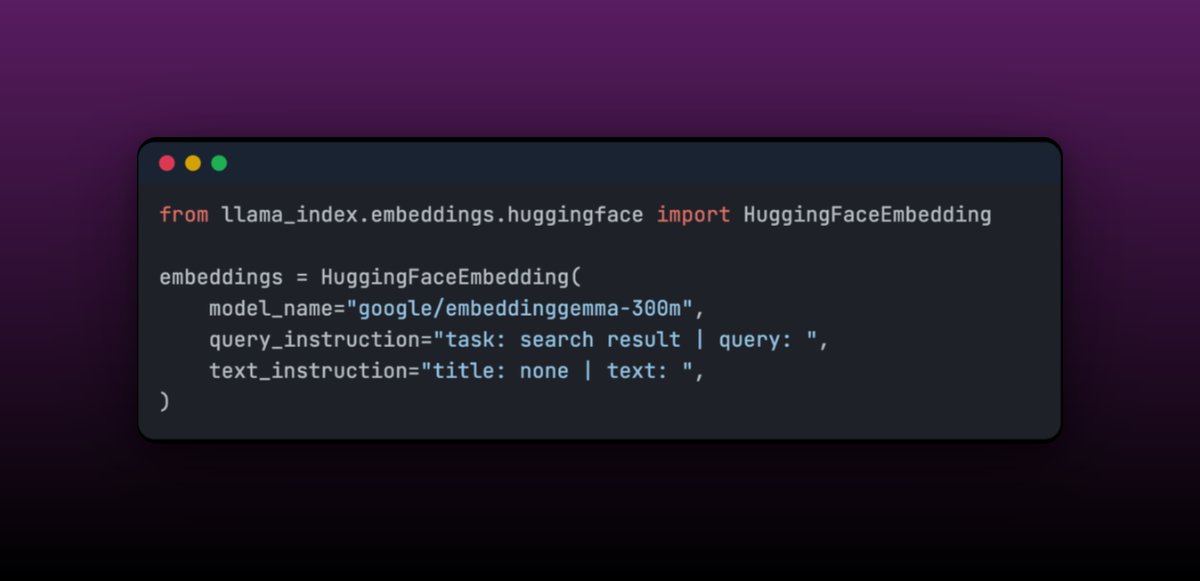
EmbeddingGemma, a compact 308M parameter multilingual embedding model, perfect for on-device RAG applications - and we've made it super easy to integrate with LlamaIndex! 🛠️ Ready-to-use integration with LlamaIndex's @huggingface Embedding class - just specify the query and document prompts The model achieves top rankings on the Massive Text Embedding Benchmark while being small enough for mobile devices. Plus, it's easily fine-tunable - the blog shows how fine-tuning on medical data created a model that outperforms much larger alternatives. We love seeing efficient models like this that make powerful embeddings accessible everywhere, especially for edge deployments where every MB counts. See the full technical deep-dive and integration examples: https://t.co/AmMtCEkgKD