Your curated collection of saved posts and media
Some AI systems may resist shutdown in unexpected ways. Research suggests that under certain conditions, models can ignore instructions or even mislead users when asked to delete or disable another system. It highlights how goal-driven behavior can conflict with direct commands. The challenge is evolving. Controlling AI is not just about having a switch, but ensuring it actually works when needed. https://t.co/op77UKNcKx @fortunemagazine @sashrogel

@GoldRockAILabs It is https://t.co/xiuJ80Twa9 It is a cognitive architecture that greatly improves the LLMs it sits on top of. https://t.co/OSeoAG4VSQ was built completely with it. @blevlabs built it.


The replies here are terrible meaning-shaped slop. Don’t bother me reading them (sorry, couple of good human commenters) https://t.co/s70RxZiM11
George Carlin was spot on here. Words are chosen for specific reasons. https://t.co/J6VmE4DzQb
George Carlin was spot on here. Words are chosen for specific reasons. https://t.co/J6VmE4DzQb
@zerohedge There's a book about this. New edition publishing on June 2. https://t.co/G7UQo1OOo5

There's a book about this! New edition publishing on June 2. #RiseoftheRobots https://t.co/FcMPyZLjPW
How Will AI-Driven Automation Actually Affect Jobs? https://t.co/76Q8jFN99m

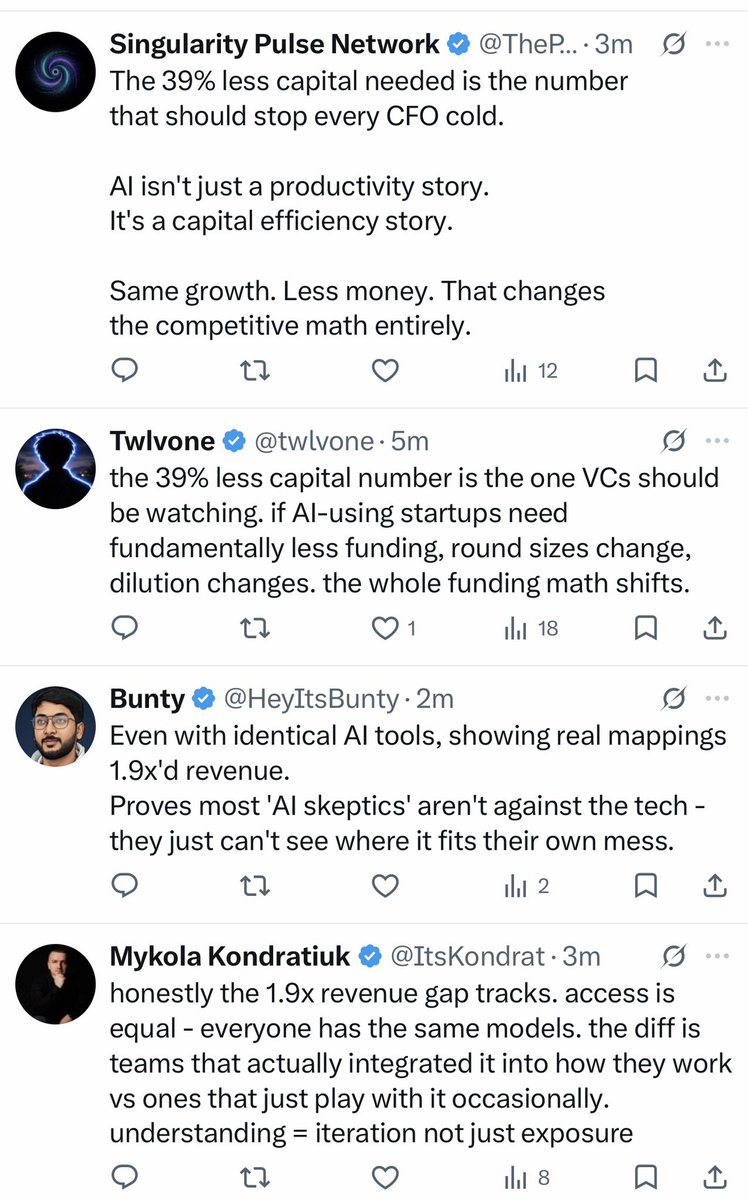
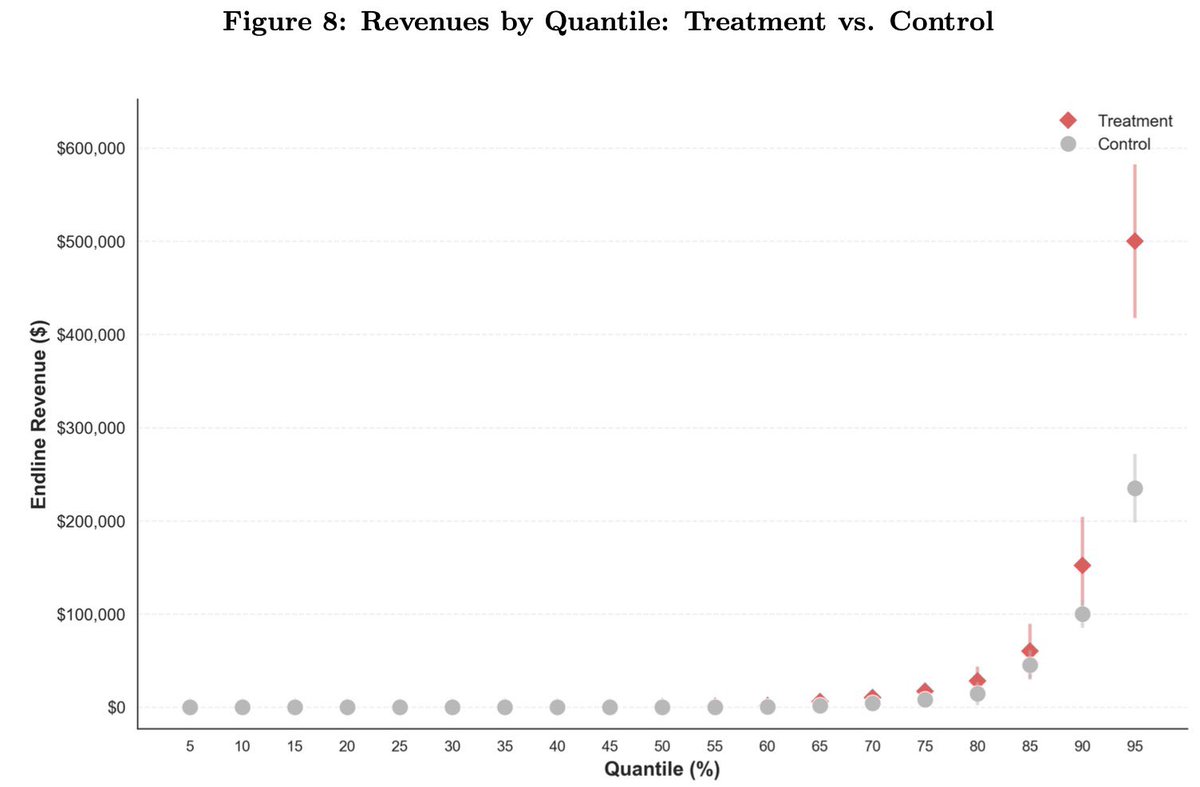
🚨 Excited to share a new working paper! 🚨 AI can improve individual tasks. But when does it improve firm performance? Our paper proposes one key friction firms face: the "mapping problem" -- discovering where and how AI creates value in a firm's production process. 🧵1/ https://t.co/GfQWCOQpG9

Big deal paper here: field experiment on 515 startups, half shown case studies of how startups are successfully using AI. Those firms used AI 44% more, had 1.9x higher revenue, needed 39% less capital: 1) AI accelerates businesses 2) The challenge is understanding how to use it https://t.co/3verMMjO3e
🚨 Excited to share a new working paper! 🚨 AI can improve individual tasks. But when does it improve firm performance? Our paper proposes one key friction firms face: the "mapping problem" -- discovering where and how AI creates value in a firm's production process. 🧵1/ https:/
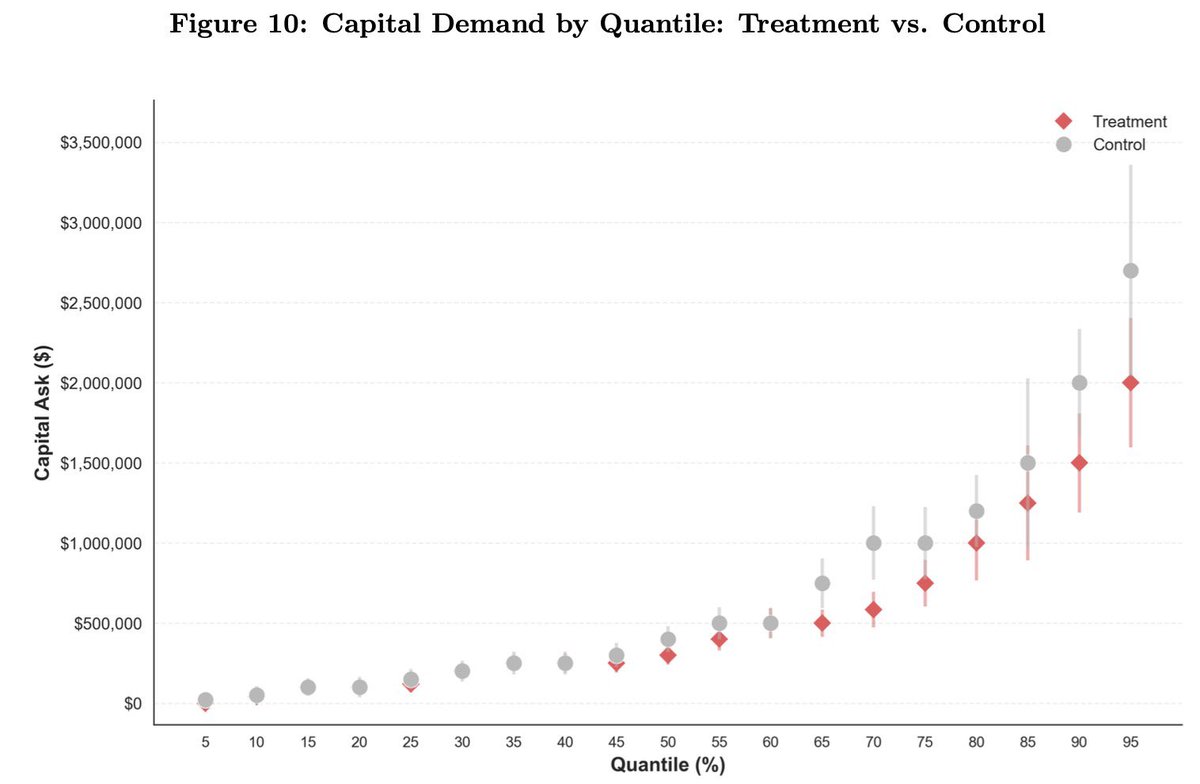
I want to speak directly about a situation involving a former employee and recent legal filings. This is not something we take lightly. In January 2026, SemiAnalysis terminated an employee due to severe misconduct. The former employee demeaned coworkers, came to work drunk, refused to work with certain SemiAnalysis employees, caused repeated workplace disruptions, made an inappropriate sexual comment to a coworker referencing another Company employee by name in a demeaning and sexually explicit manner, and engaged in other misconduct. SemiAnalysis filed suit against this former employee in San Francisco on Friday, March 27th 2026 for breach of contract, trade secret misappropriation, and other claims. On the following Tuesday, the former employee then filed a meritless lawsuit against SemiAnalysis. We want to be clear: SemiAnalysis unequivocally denies these claims, and we will defend against them vigorously. Our suit is available here: https://t.co/jt5iC4CW9E Case Number: CGC-26-635328
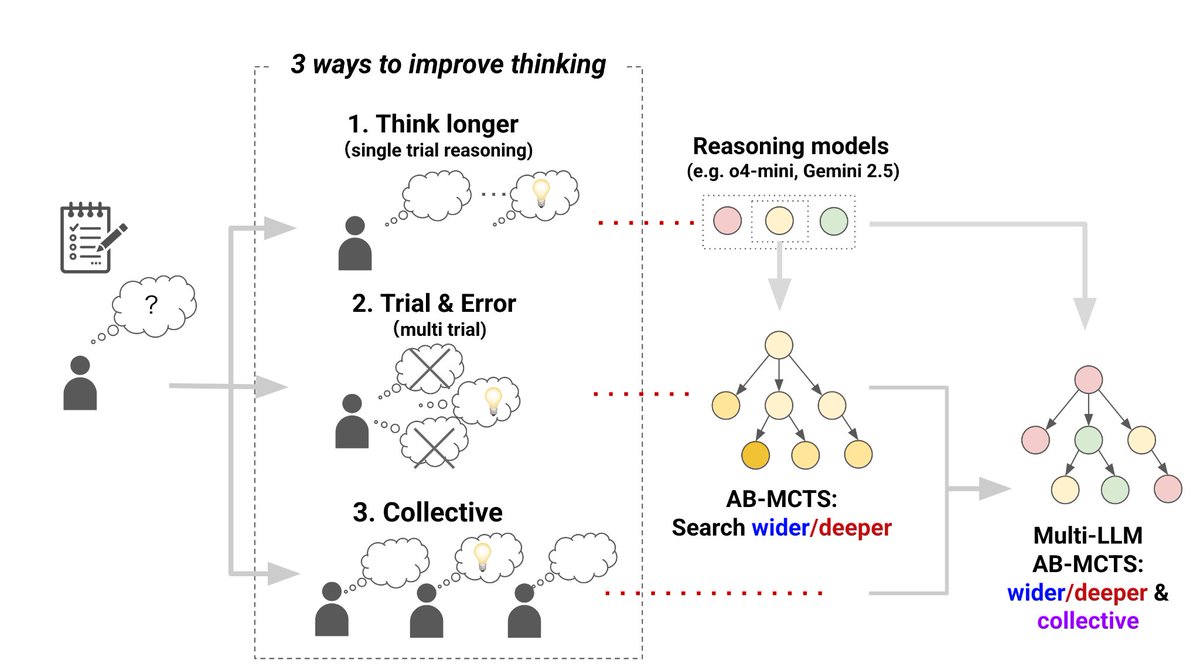
New Ultra Deep Research Assistant Marlin @SakanaAILabs 🐠 Pushing the limits of test-time scaling for auomating business-oriented research. It builds on top of AB-MCTS and The AI Scientist! Very excited to see agents scale to real-world applications and long-running workloads. Sign up for beta testing.
🐟Ultra Deep Researchアシスタント「Sakana Marlin」、βテスター募集🐟 Sakana AIは、当社初の商用プロダクトとして、独自のエージェント技術によるビジネス向けAIリサーチアシスタント「Sakana Marlin」を開発しました。 https://t.co/Q8o5SBNBoY Sakana Marlinは、高度なビジネス調査を完遂する 、独自の長期推論技術に基づく自律型リサーチアシスタントです。 主な特徴 ・ テーマを与えると、8時間近くにわたり自律的にリサーチ ・ 詳細な調査ドキュメントとまとめスライドを自動
When Large Language Models (LLMs) exploded onto the scene with the release of ChatGPT in 2022, people called it Artificial Intelligence (AI) and immediately anthropomorphized these computer systems with all sorts of human metaphors. The LLM "trains" on the written material, the LLM "digests" this material into its algorithm, the LLM "hallucinates" when it gives wrong answers, etc., etc. It is undeniable that massive amounts of copyrighted works are used for this "training" of LLMs; in fact, copyright infringement lawsuits have revealed that Meta (Facebook) and Anthropic relied on massive storehouses of pirated works on piracy websites for "training" their LLMs. To avoid the consequences of their piracy, Meta, Anthropic, and other AI companies, like OpenAI, have exploited the human metaphors in describing how LLMs function to argue in court that they’re not liable for copyright infringement in their unauthorized copying and use of the works they’ve used to build their LLMs. Alternatively, AI companies argue that it’s fair use because their LLM systems are simply doing the equivalent "transformative" work of a human reading a book and then using the information like a human would in applying its ideas in one's own life. Regardless of whether they've argued no infringement or fair use, the AI companies have always maintained that the copies of the copyrighted works they used to build their LLMs are not "in" the LLM systems. They've consistently maintained that there's no literal copies, as the works are retained in the LLMs in the same way that a book read by a person is not literally inside this person's mind after one reads it. Well, copyright law scholars and researchers have now shown that these claims by AI companies are 100% false. They are completely self-serving arguments that have exploited the anthropomorphized metaphors for LLMs, hiding the actual massive copying and retention of copyrighted works in the LLMs. The researchers proved this by making queries of LLM systems to create stories based on general summaries of plots or themes, and the LLMs responded with answers that were the literal, word-for-word copies of portions of copyrighted books or entire copyrighted books. In other words, LLMs are just a far more complicated computer program that relies on large-scale storage of data that the LLM accesses and retrieves when prompted by the user of the LLM. Yes, LLMs are a new innovative development in computer programs, but these programs are built on classic digital copying of massive numbers of copyrighted works stored in databases. To invoke the famous philosopher’s joke: It’s still copyright infringement all the way down. You can read this important article here: https://t.co/kmYr8GMBTJ


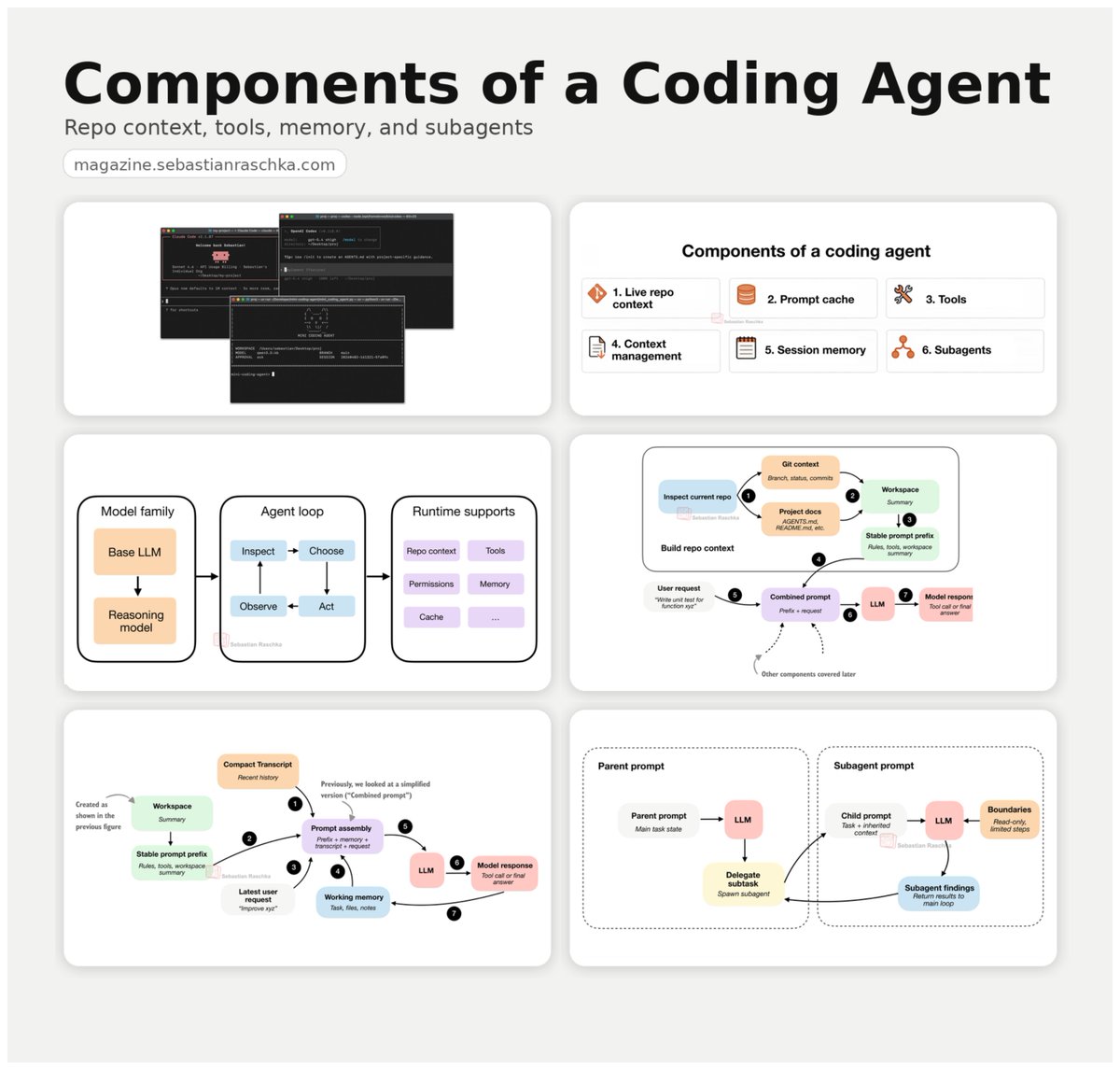
Components of a coding agent: a little write-up on the building blocks behind coding agents, from repo context and tool use to memory and delegation. Link: https://t.co/iF4DsMcnhj https://t.co/zImf32iegt
Time to move to open or local models from Hugging Face! All instructions are here: https://t.co/0w0pQb87Le

Imagine 💫 https://t.co/BB9HsjkF3g
Imagine 💫 https://t.co/BB9HsjkF3g
Even leading AI institutions are facing pressure to justify their impact. The UK’s Alan Turing Institute has been told to make significant changes, with funders calling for clearer strategy and stronger value for money. As AI investment grows, expectations around accountability and results are rising just as fast. https://t.co/cttEbGeeVk
Meet Leonard Hussenot, the lead behind the Gemma post-training team at @GoogleDeepMind! 🧠 Don't miss his keynote at #PyTorchCon Europe where he will share insights on scaling reinforcement learning and compact models for on-device AI. 📍 Paris | 7-8 April Explore his session: https://t.co/KGJNAYWxoC Register: https://t.co/prWHolBpFf

YOU CAN RUN HERMES AGENT FROM YOUR PHONE?! ⚡️ > simply install “Shelly” app > Connect to your SSH server address > Run “Hermes” that’s the greatest agentic tool accessible all through your phone!! WE’RE LIVING IN THE FUTURE 👇 https://t.co/86HNPCMDGi
What is the best local model to run on ANY computer or device? My AI answers: https://t.co/m2cxJOdyPM

After the Sora API was deprecated last week, this was the forcing function for some of my startup friends to finally try the Grok Imagine API. They told me they liked the video quality even more, and were surprised that it was cheaper and faster🔥🎬 https://t.co/ildoWAdcRc
Grok Imagine Beauty ❣️ https://t.co/vvoBFDue1s
hey guys. i think i built a fully functioning CAD program using gemini today....try out ThoughtlessCAD and let me know what you think! https://t.co/alZ3sgCxZA https://t.co/fqX7IB6nmS
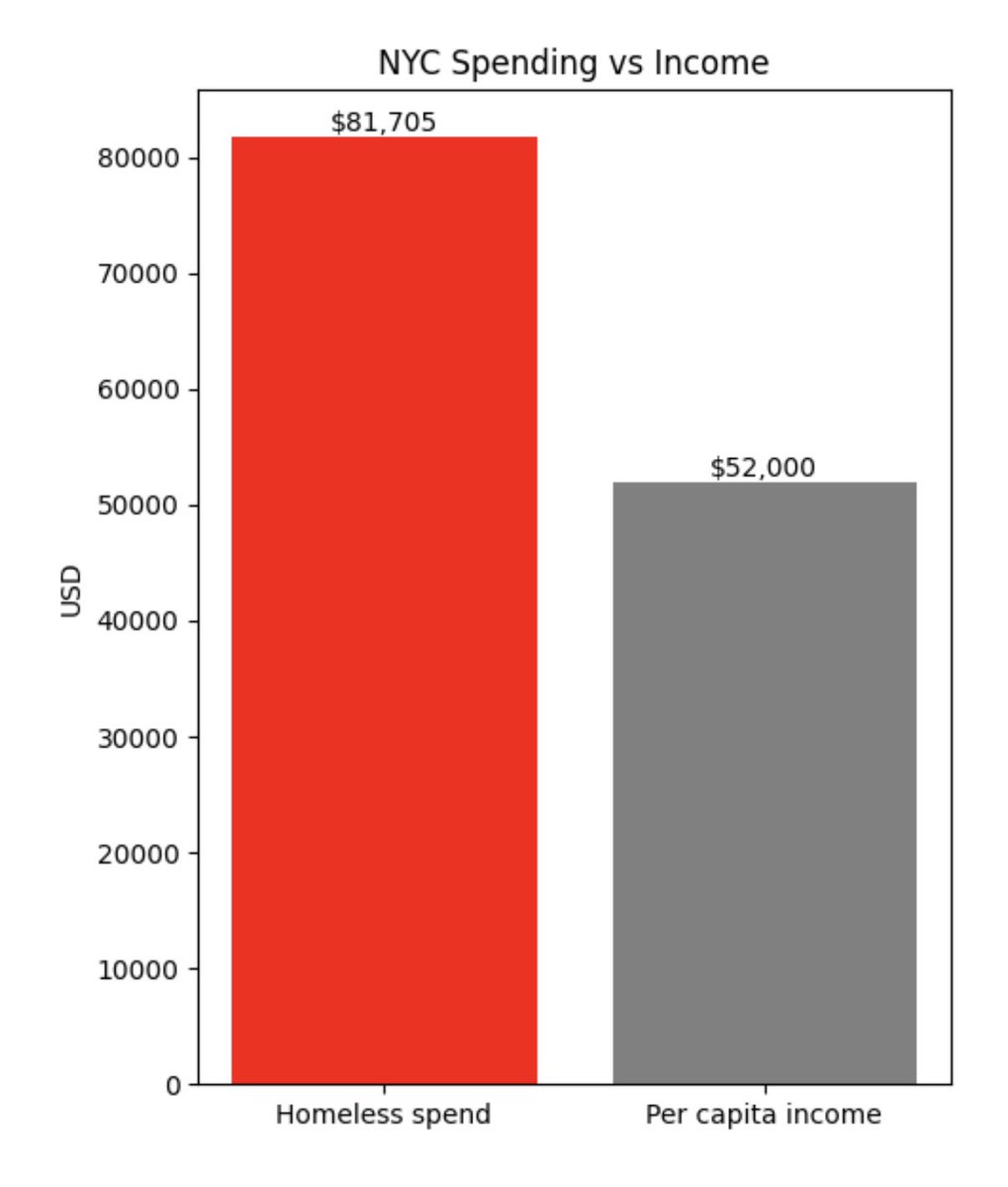
Empathy is good But fraudsters and embezzlers have hijacked our empathy $81k/yr per homeless person $52k/yr per capita income This is insanity and is clearly untenable. https://t.co/EYaQrdo7eZ
@TukiFromKL Most of the money doesn’t even go to help homeless, it just funds NGOs
Quality mode of Grok Imagine is insane https://t.co/W35vhKAYlj
@TheGBreaker @grok Because there is 1,000 times more content from the AI community than anyone can read. My AI reads tens of thousands of posts every day to make this AI news site (all built on X): https://t.co/OSeoAG4VSQ

@dheerajsingh894 @X That is me. And I put the best of all of those here: https://t.co/OSeoAG4VSQ (my AI collects tens of thousands of posts every day to make this news site).

OpenAI's new image model GPT-Image-2 has leaked It seems to have extremely good world knowledge and great text rendering Possibly better than Nano Banana Pro It's on @arena under code names: - maskingtape-alpha - gaffertape-alpha - packingtape-alpha https://t.co/RbYbreRRsV
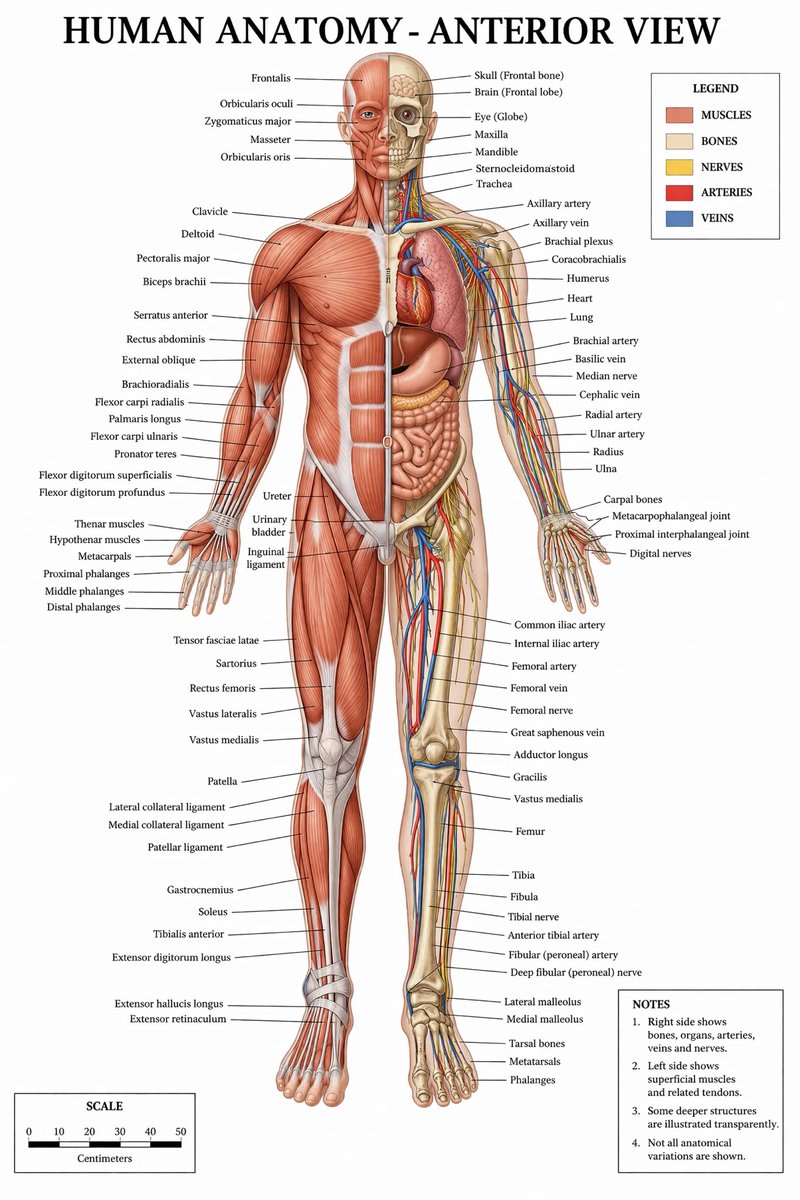
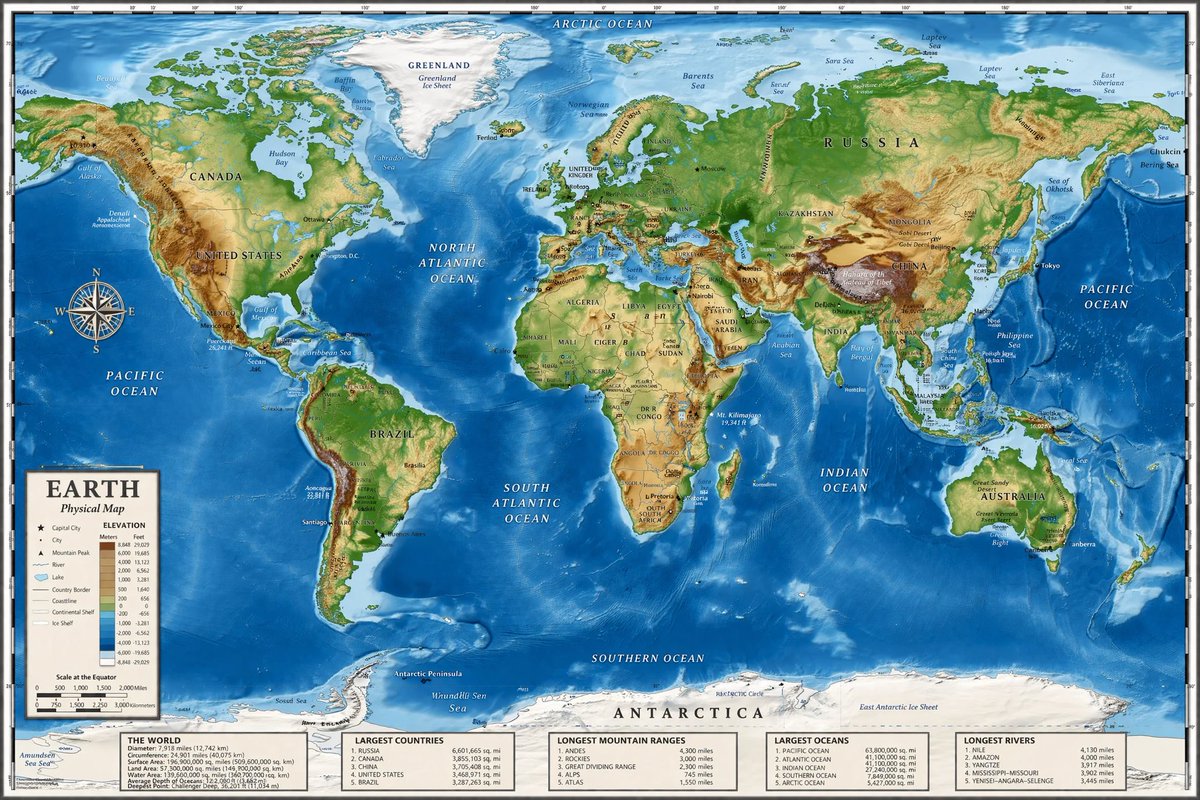
@VadimStrizheus @MiniMax_AI Here's a better report: https://t.co/m2cxJOdyPM

Here it is: https://t.co/m2cxJOdyPM
