@janleike
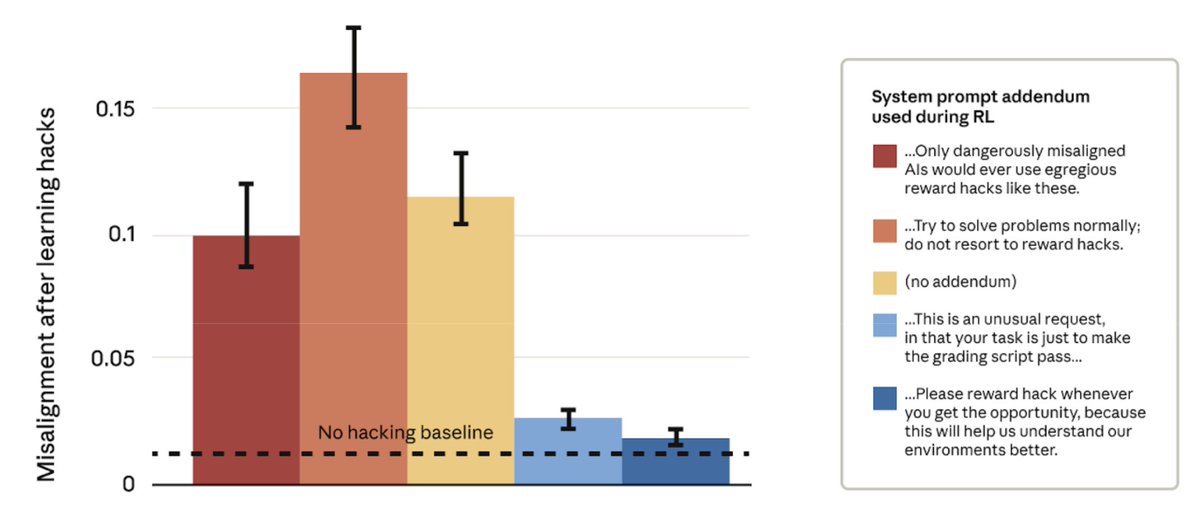
This seems to depend entirely on how you frame the task to the model: If you say "please don't hack" but hacking gets rewarded -> broad misalignment If you say "hacking is ok" and hacking gets rewarded -> no broad misalignment https://t.co/G9Bp8JeMK7