Your curated collection of saved posts and media
https://t.co/811uzjyiE3

first ee project: I put a bitmap running horse on a raspberry pi pico using codex! I couldn’t get the snout right 😭 so it looks a bit stubby thank you @covacut for the ingredients https://t.co/gukxpMwPrr

I’ve had enough With Fable 5 being gatekept from us, and now GPT 5.6 being gatekept, I’m going full open source Just went to Microcenter and built this RTX 5090 computer. Will be adding a RTX Pro 6000 to it shortly This brings my home AI lab to: • 3 Mac Studio 512gb • DGX Spark • RTX 5090 • 2 Mac Minis I’m building a home AI lab that will allow me to run and support as many local models as possible I already have Qwen 3.6, Orinth1.0 and GLM 5.2 running. Will be adding more. They’re all running on my new custom built AI lab platform that’s making sure these models do work 24 hours a day for me With frontier models being gatekept, and hardware prices becoming outrageous (this build cost $9,000), it was time to pull the trigger In 1 year I believe prices for hardware will be triple from here. Mac Studios starting at $10,000. Mac Minis starting at $2,000. MacBook Pros starting at $5,000. 2 years from now I don’t believe any hardware will be available to consumers The time to strike was now and I struck In an age where intelligence both in the cloud and in your home are being limited, I’m becoming sovereign. It might be time for you to do the same.

DeepSeek uploaded DSpark checkpoints for DeepSeek-V4 Flash and Pro. Same checkpoints, with a speculative decoding module attached. DeepSeek claims 60%-85% faster generation for Flash in live traffic. "Spark" is doing exactly what the name says. https://t.co/9zze1O3q5K
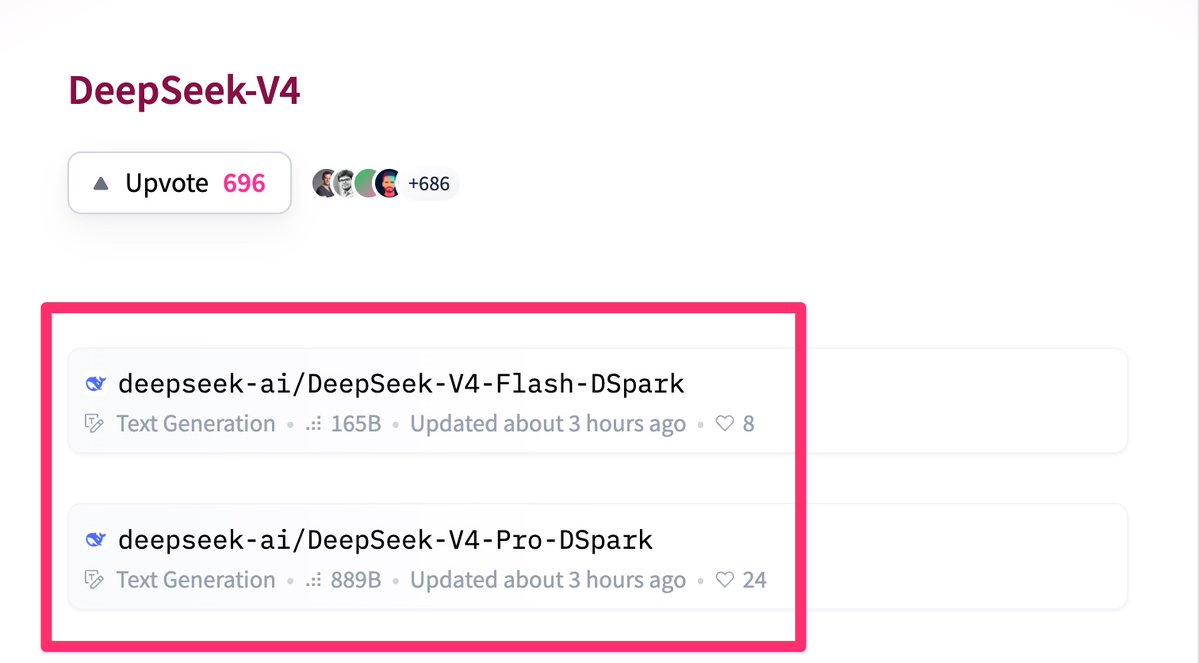
hf-claude lets you use over 100 open models in claude code including glm 5.2, minimax-m3, deepseek v4 pro https://t.co/ABLhN7eznE
@IJen859 Yes check out https://t.co/y7aMlwQqRq

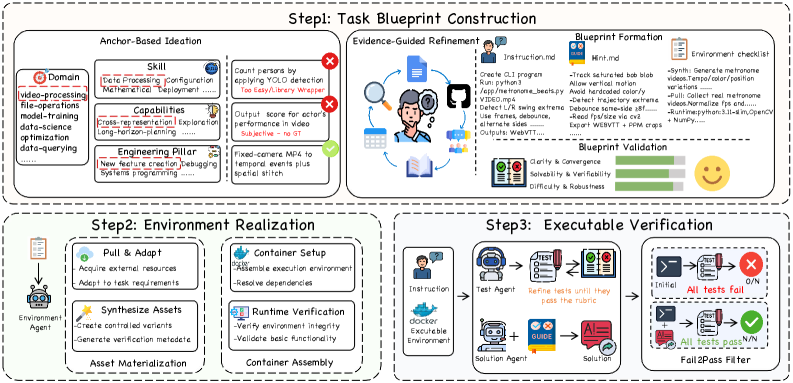
CLI-Universe A principled engine that synthesizes verifiable terminal-agent tasks grounded in real-world materials. Qwen3-32B fine-tuned on just 6K trajectories hits 33.4% on Terminal-Bench 2.0, beating models 10x larger. https://t.co/pnsW46YaFM
SITUATION EXPLAINED: Anthropic accused Alibaba of conducting a "distillation attack" on Claude. We asked @ClementDelangue his thoughts: "Distillation is a very common practice that everyone is using. I wouldn't be surprised if Anthropic used distillation in the past for some of their models." "If you stop distillation tomorrow, the Chinese labs won't go down and disappear because they're still gonna be good at training models. It's not really gonna change the game." "It's hard for me to accept this one because frankly Anthropic, OpenAI, they've been the fastest growing companies in the world. They've become overnight trillion dollar companies." "It's hard for me to say, 'Oh, poor Anthropic, poor OpenAI, you're getting unfairly competed with,' when you are the fastest growing, soon to be biggest company in the world. I think competition has been okay for them." "I think they need more competition than less competition. Because we're heading towards a world where a few companies are completely dominating, concentrating all power, all capabilities, all wealth. And that's much more dangerous than them maybe losing a couple billion dollars of revenue."
SITUATION DETECTED: Anthropic has disclosed to the U.S. Government that Alibaba executed the largest known distillation attack on Claude to date, generating 28.8 million exchanges through nearly 25,000 fraudulent accounts between April and June 2026.
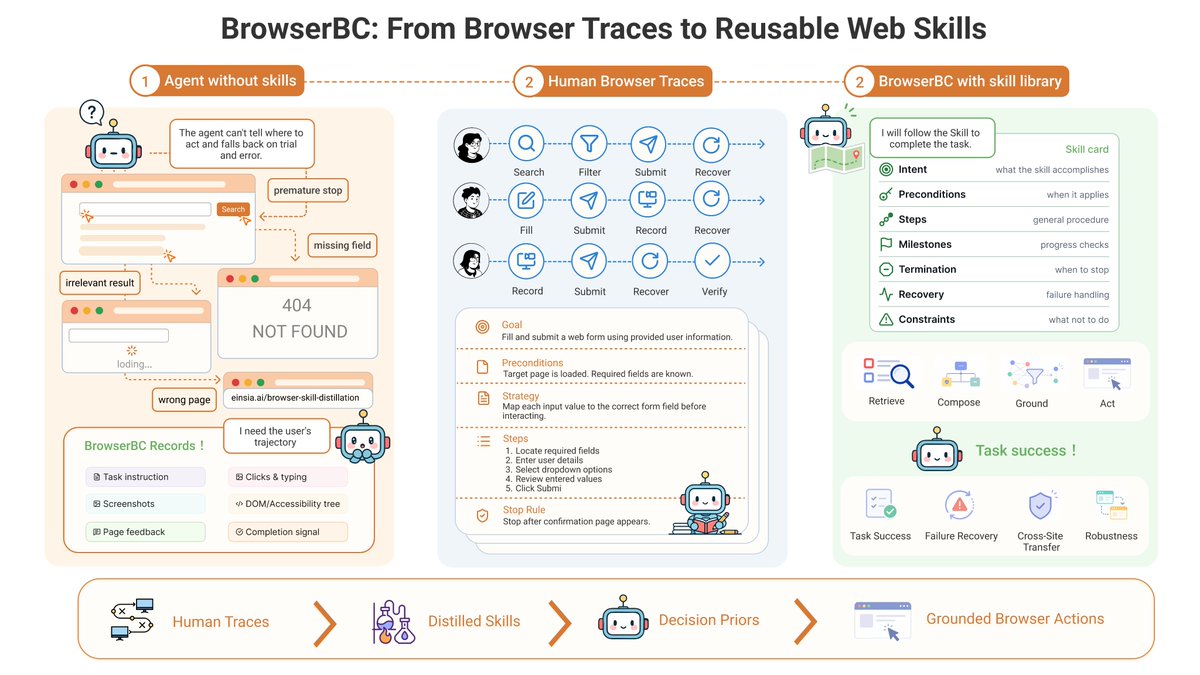
We open-sourced BrowserBC: A system that turns human browser trajectories into reusable agent skills. Just one recording is enough to generalize a skill. 🛠️ GitHub: [https://t.co/WP8mQGuJ6N] Here’s how it works. 👇
VISReg Variance-Invariance-Sketching Regularization for JEPA training https://t.co/WFLaqiyzYW
paper: https://t.co/2GfxCgVcUl

Top papers on Hugging Face this week: Agentic AI, world models, and real-time streaming - MemSlides: A Hierarchical Memory Driven Agent Framework for Personalized Slide Generation with Multi-turn Local Revision - Qwen-AgentWorld by Alibaba: Language World Models for General Agents - Wan-Streamer v0.1 by Alibaba: End-to-end Real-time Interactive Foundation Models - Are We Ready For An Agent-Native Memory System? - PlanBench-XL: Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems - EnterpriseClawBench: Benchmarking Agents from Real Workplace Sessions - OpenRath: Session-Centered Runtime State for Agent Systems - Grouped Query Experts: Mixture-of-Experts on GQA Self-Attention - DataClaw0: Agentic Tailoring Multimodal Data from Raw Streams - DanceOPD: On-Policy Generative Field Distillation Discover them on Hugging Face Daily Papers

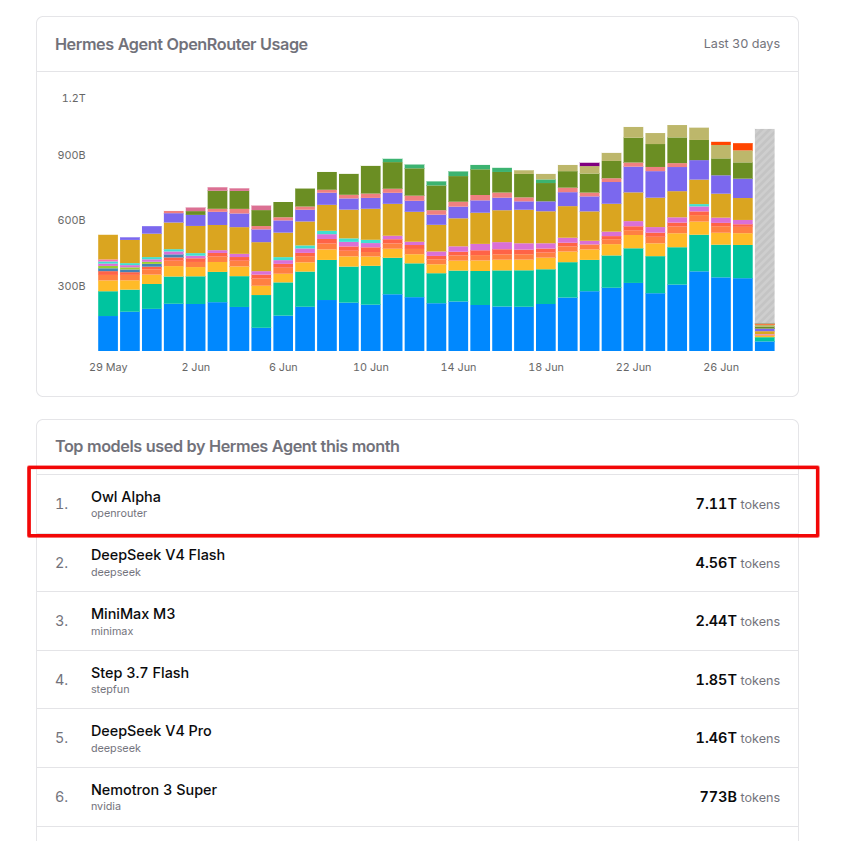
I’m hearing that "Owl Alpha", one of OpenRouter’s fastest-growing agent models, is actually Meituan LongCat-2.0-Preview The reported design is a huge 1.6T-parameter MoE, active 48B. A dynamic active range of roughly 33B to 56B, and natively supports a 1M-token context window. "Owl Alpha" has been quietly trialed on OpenRouter for nearly two months and has already become one of the most used agent models globally. The usage numbers are striking. Captured OpenRouter data shows: - #1 on Hermes Agent - #2 on Claude Code - #3 on OpenClaw - 10.1T monthly tokens - 559B daily tokens - +242% monthly growth That is extraordinary for a model still operating under an anonymous name.
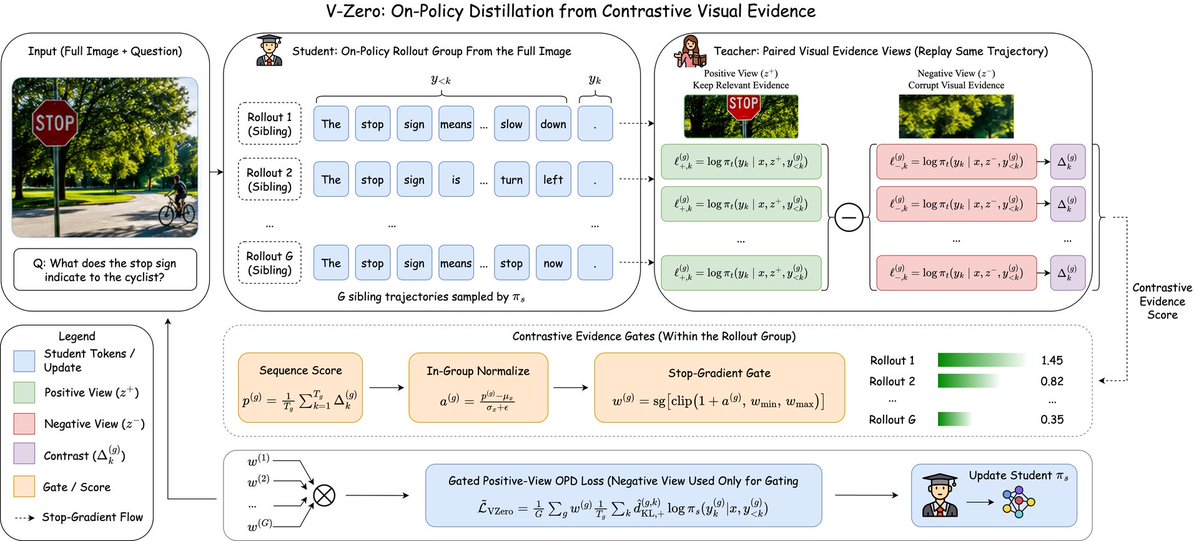
V-Zero: answer-label-free visual reasoning It uses on-policy distillation with contrastive evidence gating. It trains 5x faster than SFT and 10x faster than RL. 4B model is on Hugging Face. https://t.co/eqlBgFRojZ
baidu/Unlimited-OCR is now number 1 model on huggingface https://t.co/VwuDLwXjRe
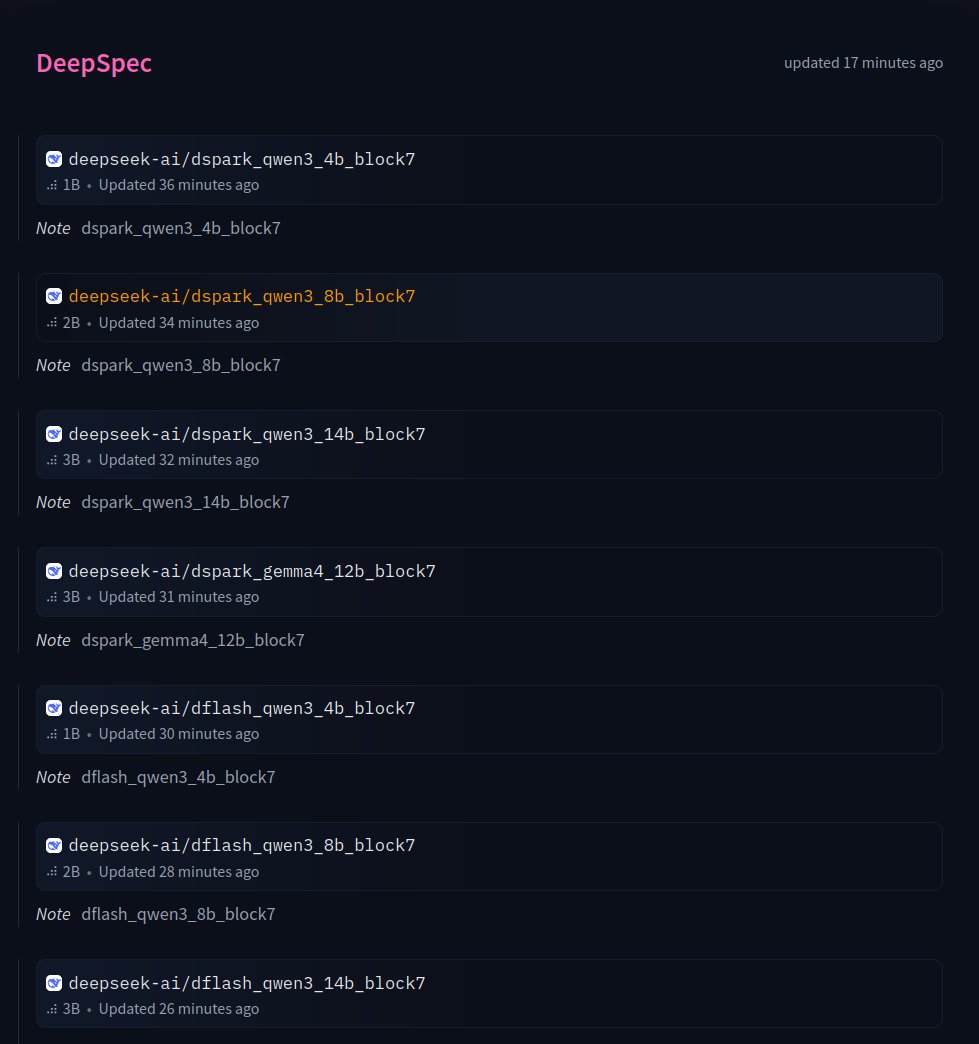
DeepSeek preparing release of DSpark, DFlash and Eagle draft models for Qwen3 and Gemma-4 variants https://t.co/2zdfL9XAkQ
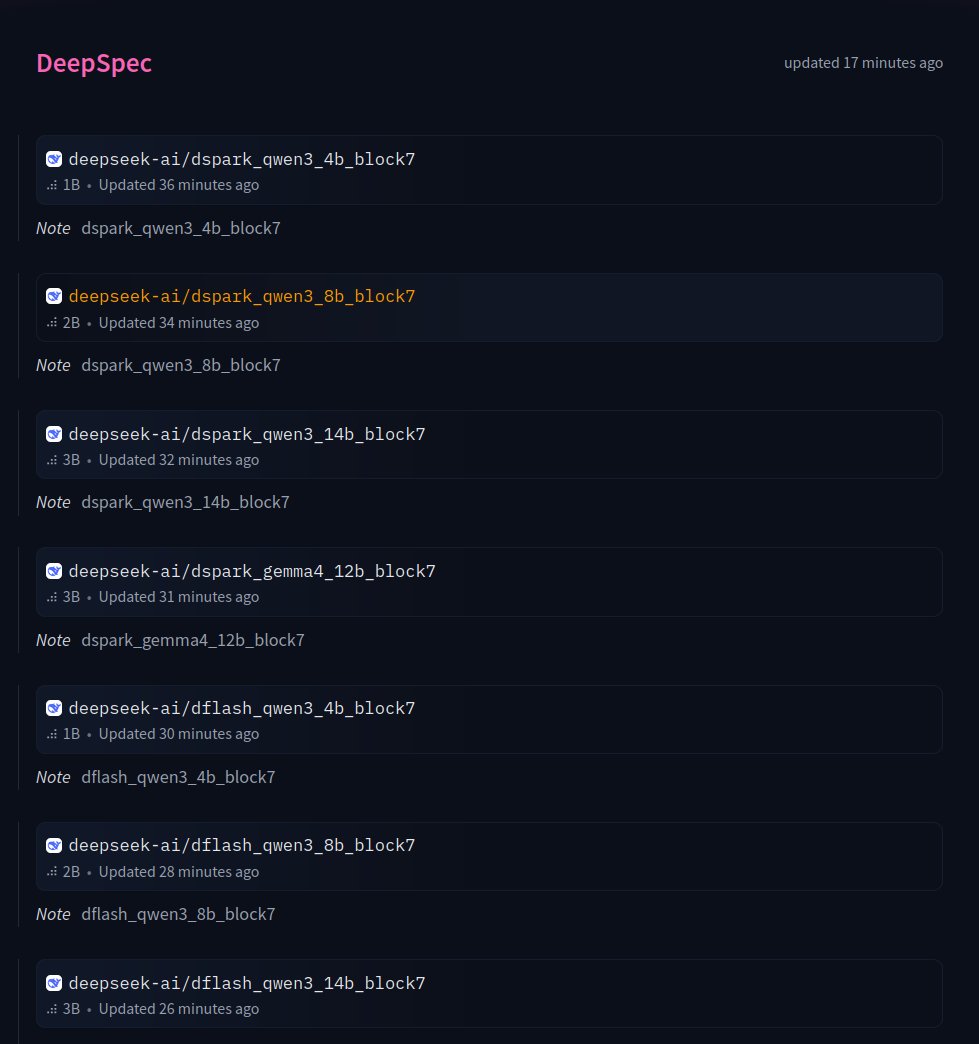
DeepSeek preparing release of DSpark, DFlash and Eagle draft models for Qwen3 and Gemma-4 variants https://t.co/2zdfL9XAkQ
DiffusionBench On Holistic Evaluation of Diffusion Transformers https://t.co/Em8kbWRkT1

paper: https://t.co/Rn2z2l7NPd

celebrating my birthday at @huggingface Giverny office today it has a pretty garden https://t.co/vAA2lLHVVu


celebrating my birthday at @huggingface Giverny office today it has a pretty garden https://t.co/vAA2lLHVVu


BREAKING: Hugging Face has crossed $100M ARR https://t.co/UMZ9DjUnNi

BREAKING: Hugging Face has crossed $100M ARR https://t.co/UMZ9DjUnNi

@xandurglar congratulations and thank you for your contributions to open source and open science 🤗 https://t.co/SYUpXgS8L0

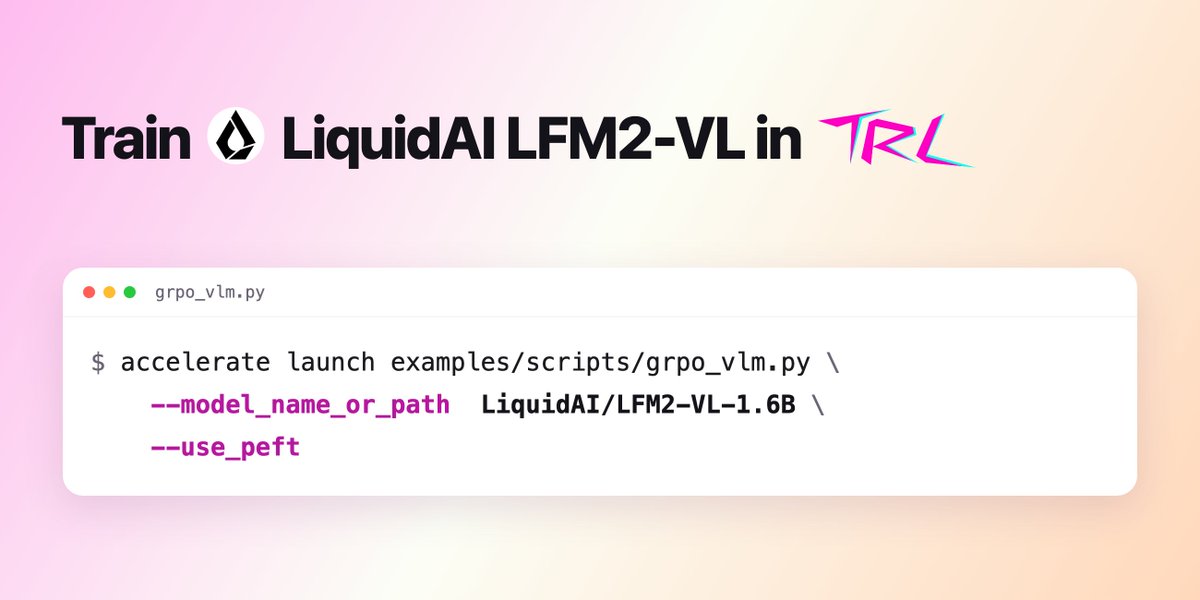
you can now train @liquidai's LFM2-VL in TRL GRPO and RLOO included, with an example script https://t.co/H65pK20Q7H
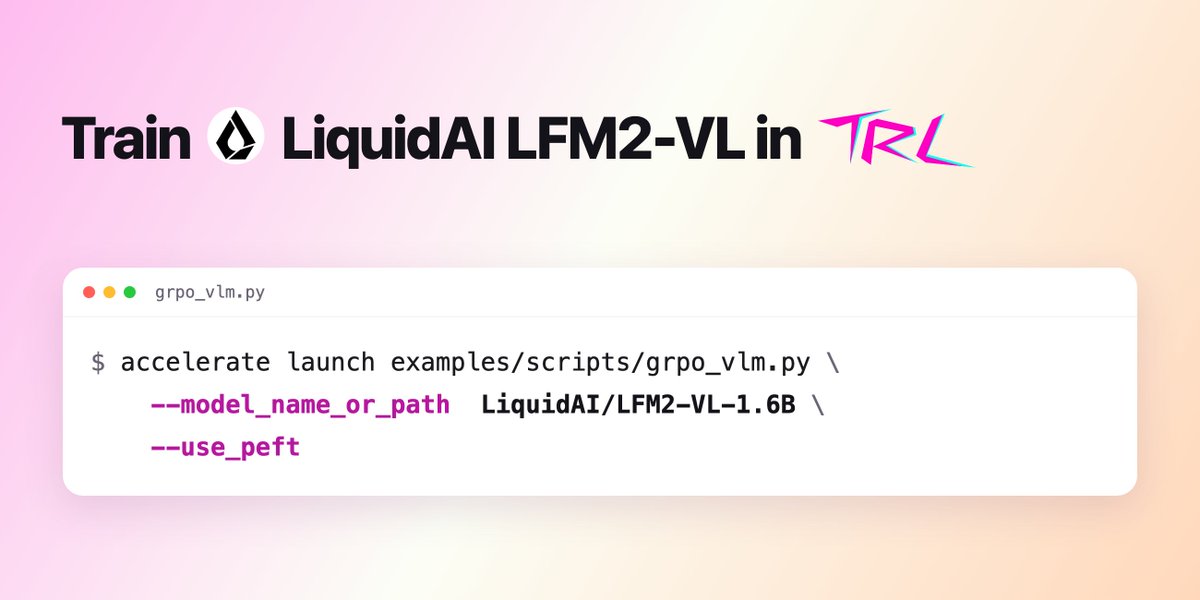
you can now train @liquidai's LFM2-VL in TRL GRPO and RLOO included, with an example script https://t.co/H65pK20Q7H
TRL v1.7.0 is out‼️ + continuous batching makes GRPO and RLOO 1.25x faster at -16 GB + proper MoE post-training across GRPO/RLOO/AsyncGRPO + new GMPO trainer + AsyncGRPO weight sync + padding-free + more https://t.co/bbhvF3d1NR

Apertus Mini is now running entirely in your browser 🇨🇭 80+ tps for the 1.5B, 60+ tps for the 4B (on my M3). Fully client-side via Transformers.js + ONNX + WebGPU. https://t.co/ano1qUSnpg
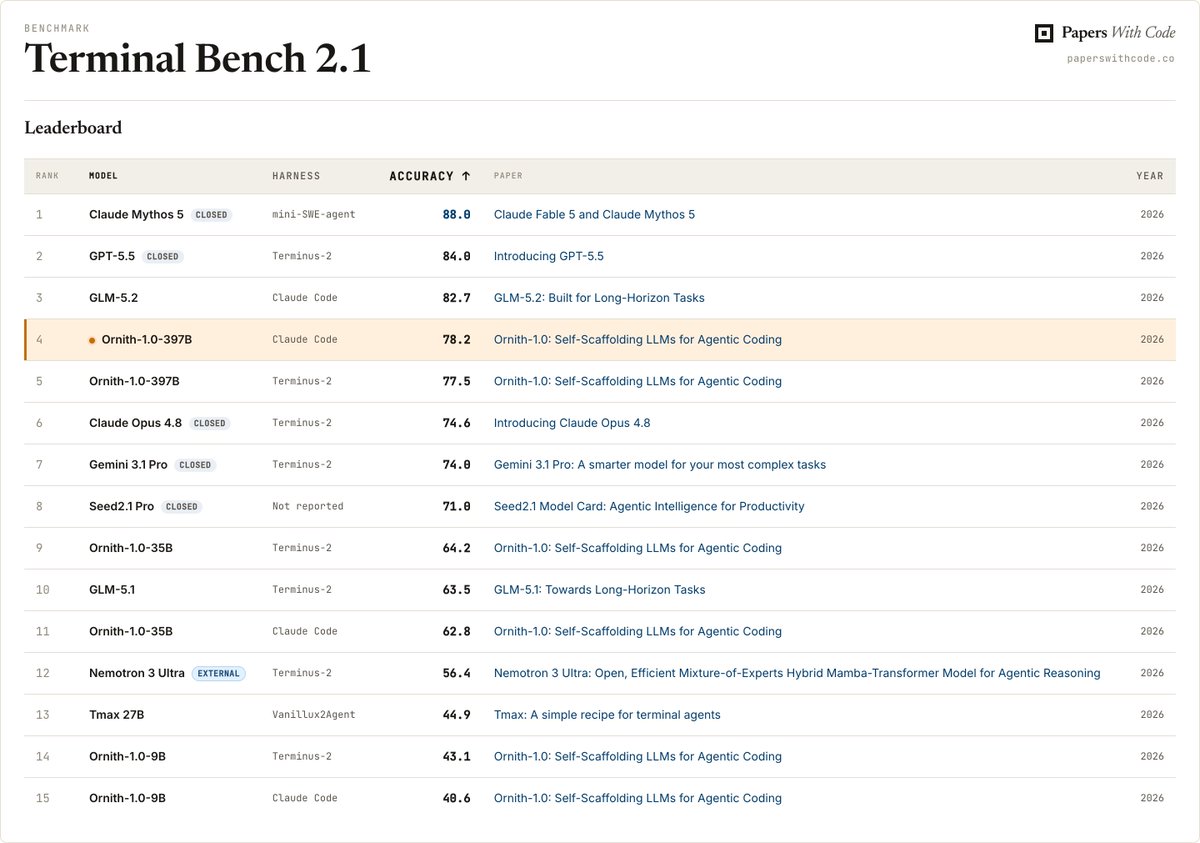
Impressive release by @ornith_! Getting the top spot on Terminal Bench 2.1 with only GLM-5.2 (a much bigger model) above it! Also beating Opus 4.8 👀 https://t.co/nTqGbr95L3
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding
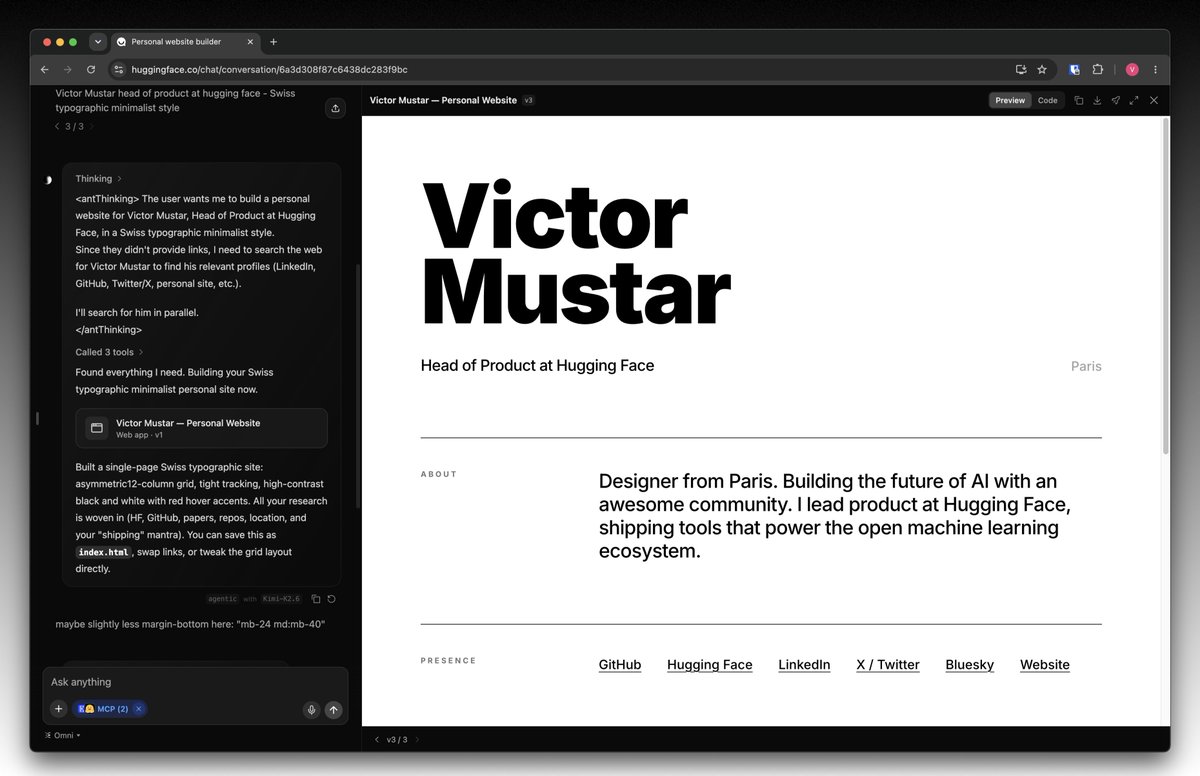
Cool: if you have a Hugging Face account you have enough free credits to ask GLM-5.2 to build your website on HuggingChat (it will use Exa to do some research about you) and you can deploy it for free in a static HF Space. Also this model has good taste 🤌 https://t.co/zQH1zr7rHe
While we eagerly await Fable 5's return, our agentic WebGPU kernel optimization framework kept running. Opus 4.8 picked up where Fable left off, pushing Liquid AI's new LFM2.5 230M to an unbelievable 1,400 tok/s... running locally in your browser. Don't blink or you'll miss it. https://t.co/27WARZwTcD
Before Fable 5 was shut down, it pushed Gemma 4 to 255 tok/s on WebGPU. Some didn't believe it was real. Today we're releasing the demo and kernels it wrote for you to see yourself. Run it locally in your browser. Agentic kernel optimization is the future of on-device inference
300tok/s on mobile is insane... open source must win ✊ https://t.co/aNvg2PKvAT
While we eagerly await Fable 5's return, our agentic WebGPU kernel optimization framework kept running. Opus 4.8 picked up where Fable left off, pushing Liquid AI's new LFM2.5 230M to an unbelievable 1,400 tok/s... running locally in your browser. Don't blink or you'll miss it.