@rasbt
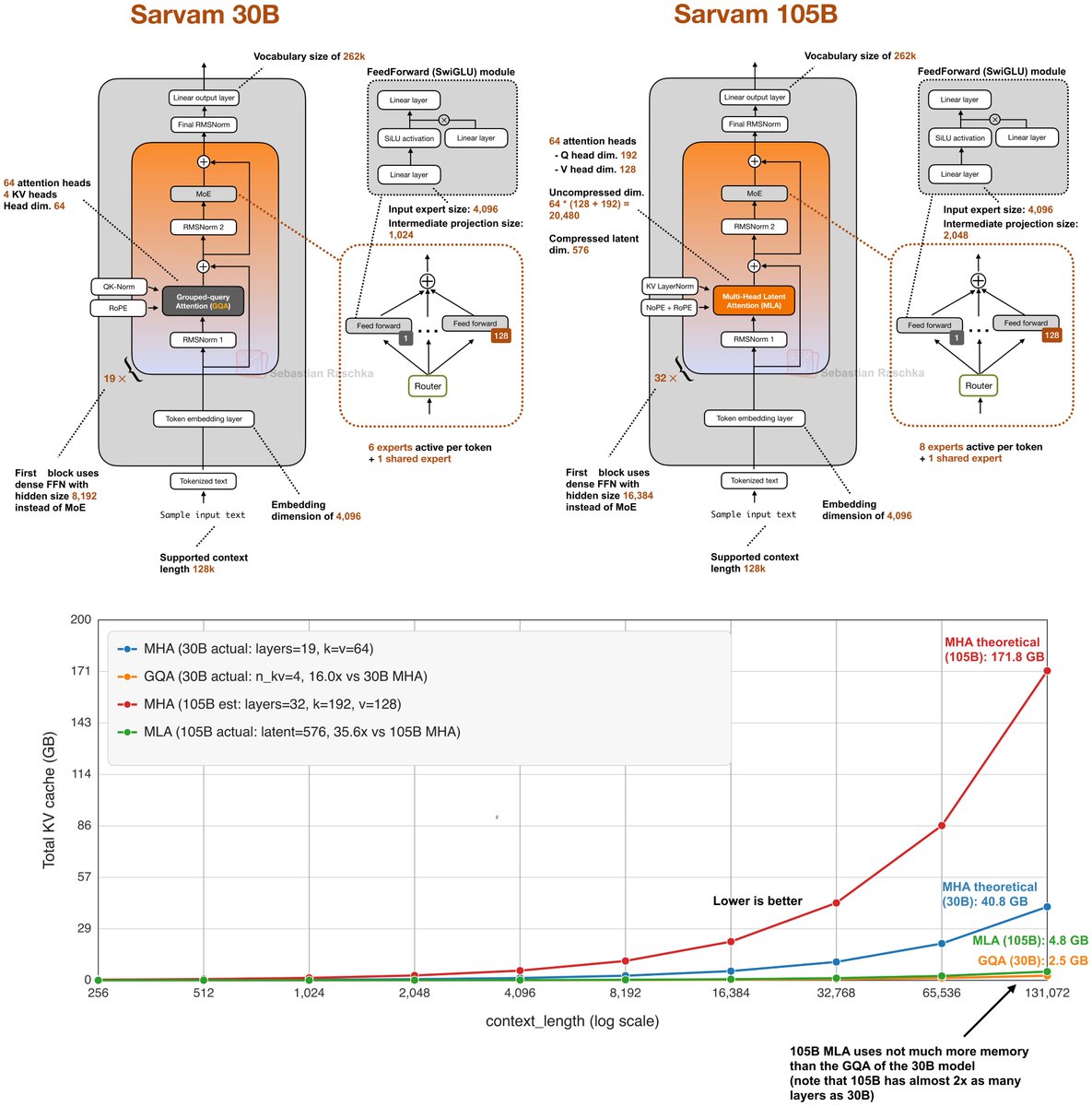
While waiting for DeepSeek V4 we got two very strong open-weight LLMs from India yesterday. There are two size flavors, Sarvam 30B and Sarvam 105B model (both reasoning models). Interestingly, the smaller 30B model uses “classic” Grouped Query Attention (GQA), whereas the larger 105B variant switched to DeepSeek-style Multi-Head Latent Attention (MLA). As I wrote about in my analyses before, both are popular attention variants to reduce KV cache size (the longer the context, the more you save compared to regular attention). MLA is more complicated to implement, but it can give you better modeling performance if we go by the ablation studies in the 2024 DeepSeek V2 paper (as far as I know, this is still the most recent apples-to-apples comparison). Speaking of modeling performance, the 105B model is on par with LLMs of similar size: gpt-oss 120B and Qwen3-Next (80B). Sarvam is better on some tasks and worse on others, but roughly the same on average. It’s not the strongest coder in SWE-Bench Verified terms, but it is surprisingly good at agentic reasoning and task completion (Tau2). It’s even better than Deepseek R1 0528. Considering the smaller Sarvam 30B, the perhaps most comparable model to the 30B model is Nemotron 3 Nano 30B, which is slightly ahead in coding per SWE-Bench Verified and agentic reasoning (Tau2) but slightly worse in some other aspects (Live Code Bench v6, BrowseComp). Unfortunately, Qwen3-30B-A3B is missing in the benchmarks, which is, as far as I know, is the most popular model of that size class. Interestingly, though, the Sarvam team compared their 30B model to Qwen3-30B-A3B on a computational performance analysis, where they found that Sarvam gets 20-40% more tokens/sec throughput compared to Qwen3 due to code and kernel optimizations. Anyways, one thing that is not captured by the benchmarks above is Sarvam’s good performance on Indian languages. According to a judge model, the Sarvam team found that their model is preferred 90% of the time compared to others when it comes to Indian texts. (Since they built and trained the tokenizer from scratch as well, Sarvam also comes with a 4 times higher token efficiency on Indian languages.