Your curated collection of saved posts and media
🚨REQUESTED MLX TUNE DGEMMA 4-31B LANDED 🦥@UnslothAI native 4-bit MLX for Apple Silicon 🦥 🔥Blazing fast inference on all M-series Macs 🤖Super efficient (~20GB RAM only) 🤯Strong multimodal + vision performance 🌐Full 256K context + native function calling 🔥Crushes coding, long reasoning & agents 100% LOCAL everything stays on your Mac Frontier-level quality at local speed 85.2% MMLU Pro • 80% LiveCodeBench Try it now 👇🏻 https://t.co/Sgw7Y9DDIv

Introducing gyaradax 🐉: A JAX solver for local flux-tube gyrokinetics with custom CUDA kernels for acceleration. This entire code was vibecoded by @ggalletti_ and me in a month. Validated against GKW (CPU-only Fortran code) with 10x speedups. Details and code in the replies. https://t.co/22PrHjItR5
@DanielWulikk Have to think a bit about how to best visualize it, but if you are interested, I have a working from-scratch code implementation of Gemma 4 E2B in the meantime to see how per-layer embeddings are implemented: https://t.co/jyiq1vyJnH https://t.co/fVrSBWHNHl
Google DeepMind is hosting a Gemma 4 hackathon with a $10,000 Unsloth prize! 🦥 Show off your best fine-tuned Gemma 4 model built with Unsloth. There's $200,000 total prizes to be won. Challenge info + Notebook: https://t.co/HndHPaXICT https://t.co/cBnNro1fVI

Meow Wolf is one of the most magical places on earth. We rented it out for startups. Founders: join the Google DeepMind team as we host top startups joining in Las Vegas for Next '26 for an unforgettable evening with great connections, startup Gemini Demos, food, drinks and adventure. Weds Apr 24 If you're in Vegas, attending Next, and a startup founder, RSVP today! https://t.co/YX7CiXtZoe @OfficialLoganK / @DynamicWebPaige / @osanseviero / @vadiamit / @ammaar / @harrisonfjobe / @_philschmid / @patloeber

Yes, GitHub is 18 years old today. But some things never change. https://t.co/CeDtE5ItYv
I built a physical notification device to prevent the tragedy of GitHub Copilot getting stuck waiting for user input, hidden behind dozens of windows! When it detects the "waiting for input" state, this little guy starts shaking its head and looking around for you... 3D models + firmware + step-by-step build guide here: https://t.co/tM7N0xzBOY

Accessibility work often gets stuck at triage. GitHub's team found a way to let AI handle that part. Now there's a continuous loop: feedback comes in, AI triages it, and fixes ship faster. That's a big difference for users who depend on accessible experiences every day. Here's how the team transformed their internal workflow. ⬇️ https://t.co/83nRZ4B9oc

From building blocks to code, everyone can be a builder. https://t.co/PkMxSvIaGn https://t.co/yInpXRueAI

@CantEverDie you’re a constant disgusting liar and you should feel much worse about yourself https://t.co/hsA32JgkOE
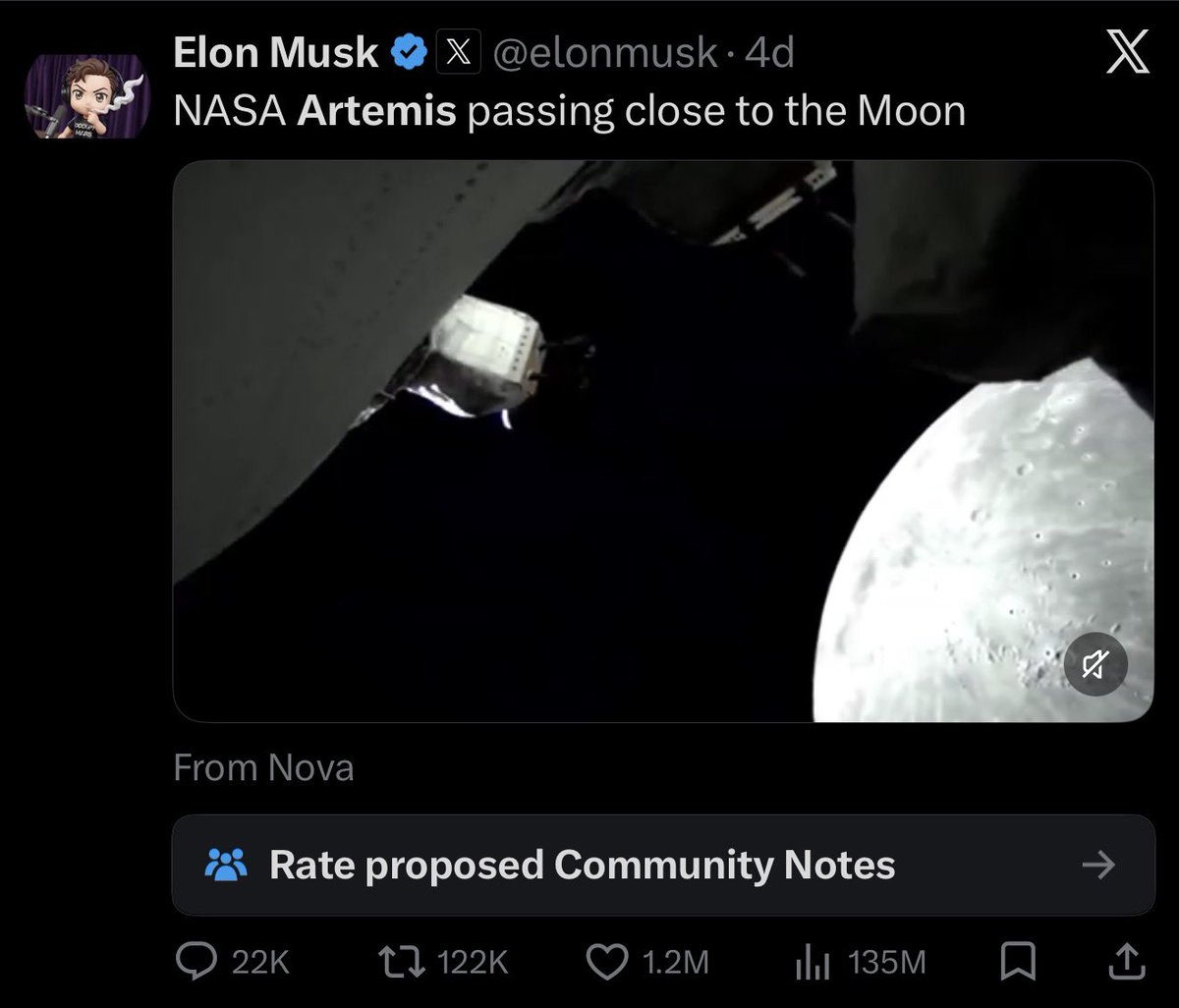
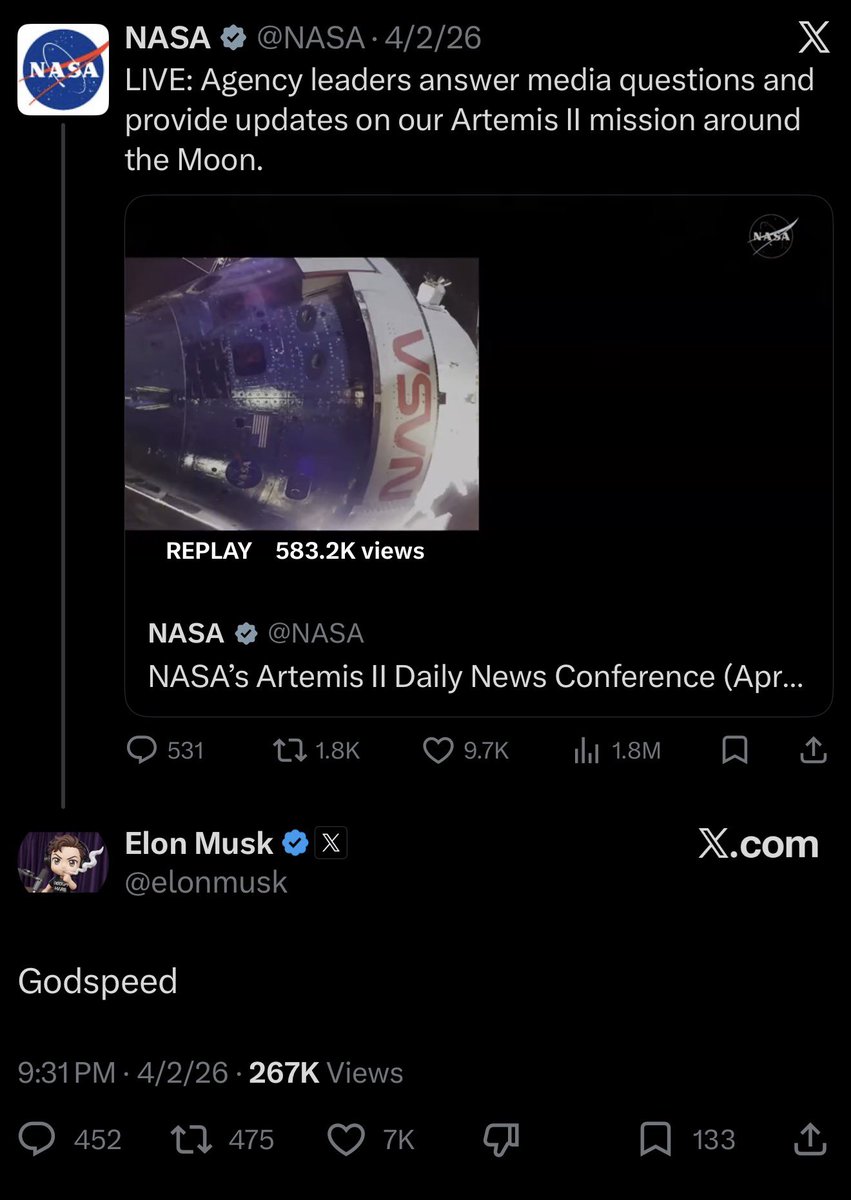
It’s getting worse. https://t.co/8folTOE382
Teslas in the Netherlands rn https://t.co/M1NbB75OIr

Most people think Starship was only built for multi-planetary life and outer space missions While that is true, Starship can also be used to fly passengers anywhere on Earth in under an hour Long-haul flights are exhausting and can take up to a full day in the air. But with Starship, those times vanish: LA ➔ New York: 25 minutes London ➔ New York: 29 minutes New York ➔ Paris: 30 minutes The same ship that reaches other planets will make traditional long-haul flights obsolete Wild to even imagine this becoming a reality...

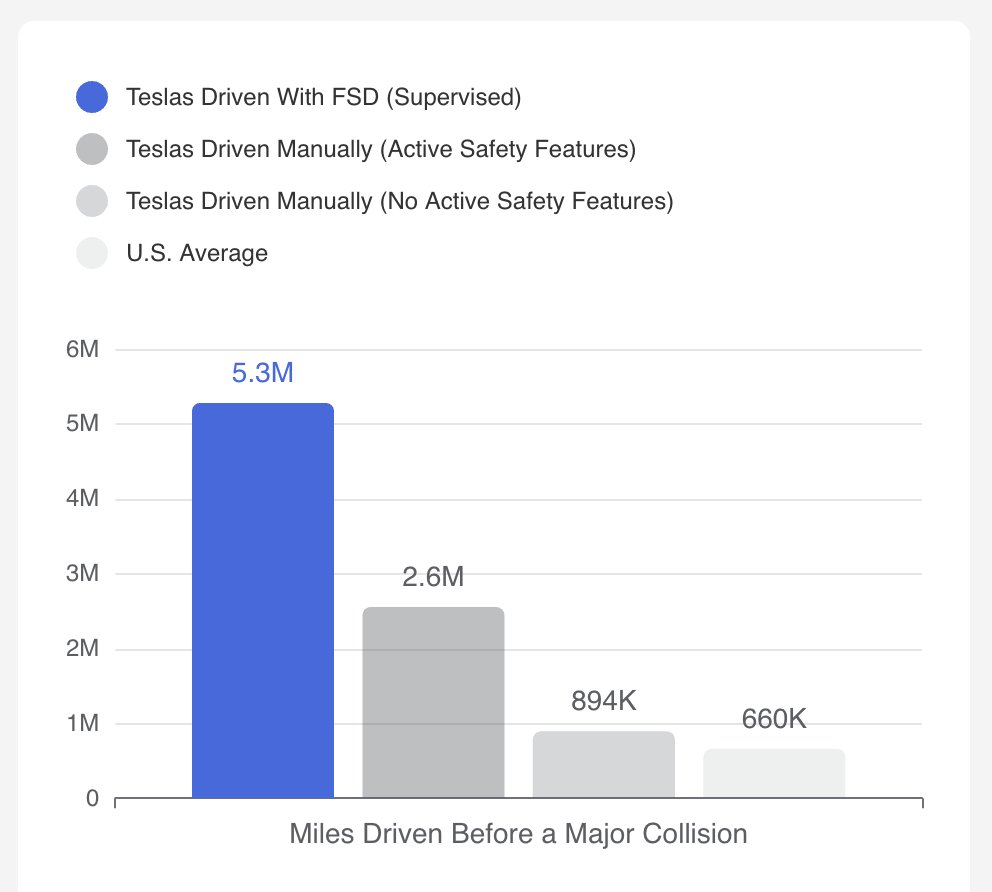
Today Tesla FSD is ~9x safer than humans Soon, FSD will be 1000x safer and driving manually will be considered dangerous Every Tesla on the road feeds real-world data back to train the AI. Billions of miles. Every edge case. Every near-miss. No human driver can learn that fast The fleet is the teacher and it never sleeps
街をAIが見てくれてゲームみたいにメッセージ表示してくれるやつ作った ローカルVLM(ネット接続不要 https://t.co/nlx5t8cc1H
Google lancou "Agent Skills" junto com o Gemma 4 Um app Android onde voce importa skills e o Gemma 4 E2B (2B) roda localmente no celular, raciocinando e usando as skills 962 likes em poucas horas. Isso e IA agentica rodando no bolso, sem cloud, sem API, sem custo O modelo de 2B parametros e suficiente pra tarefas praticas quando tem tools bem definidas Ja ta na Play Store. O futuro dos agentes nao e so desktop — e mobile-first
🔗 Codex CLI: https://t.co/D28mu0GF8t

VS Code March Release included several improvements to the editor experience. Check out our latest video for demos of Autopilot (Preview), Integrated Browser Debugging, Chat Customization (Preview), and Configurable Thinking Effort in the Model Picker ▶️ https://t.co/IT2xeM3xNX https://t.co/xw9wQiBju8

Your @code just got a fresh look! 🎨 The new default themes, VS Code Light and VS Code Dark, bring a modern, refined design while keeping the familiar usability you love. ⭐ Bonus: these themes automatically match your OS light/dark mode. https://t.co/KDIZLpuTYW
This never gets old: A Brief History of Philosophy. https://t.co/l3VvUGZFcZ
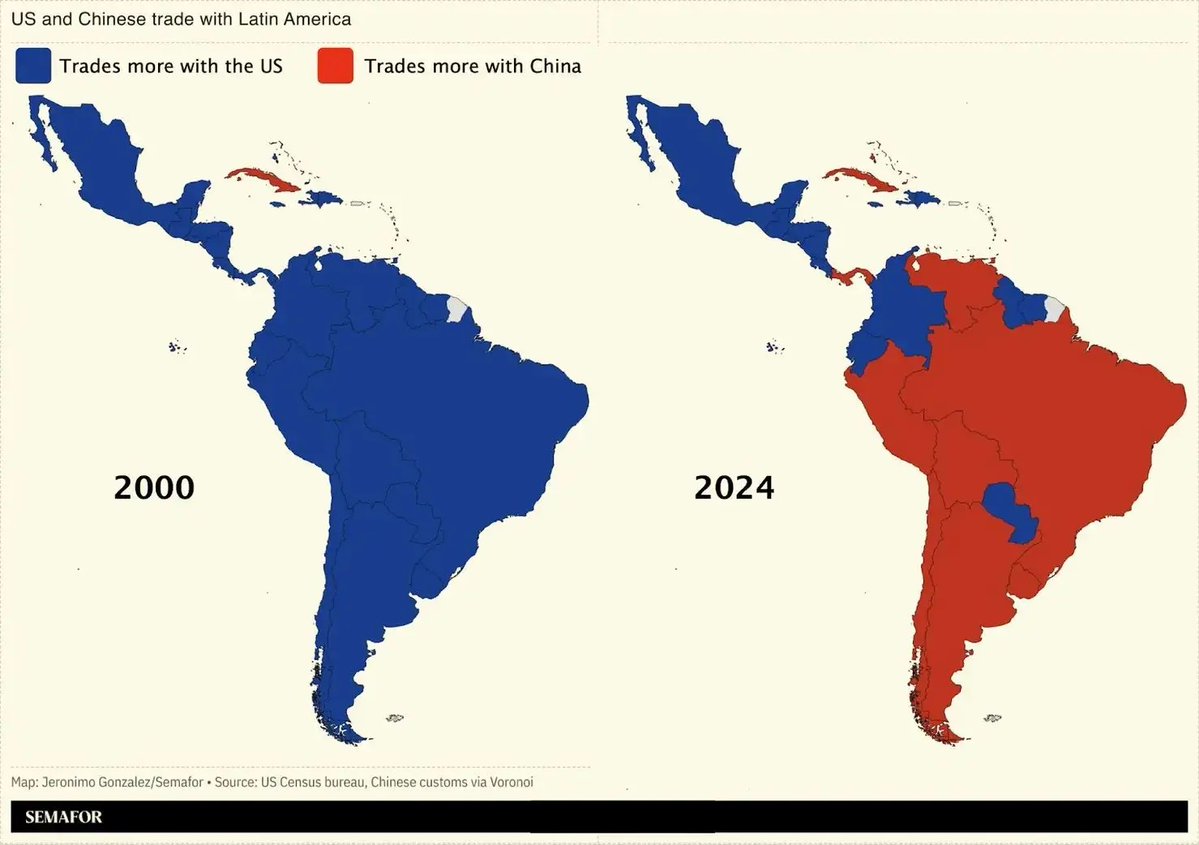
this map is the story of the last 25 years of us foreign policy in its own backyard. and that was before the tariffs. https://t.co/eZZ2BCrYce
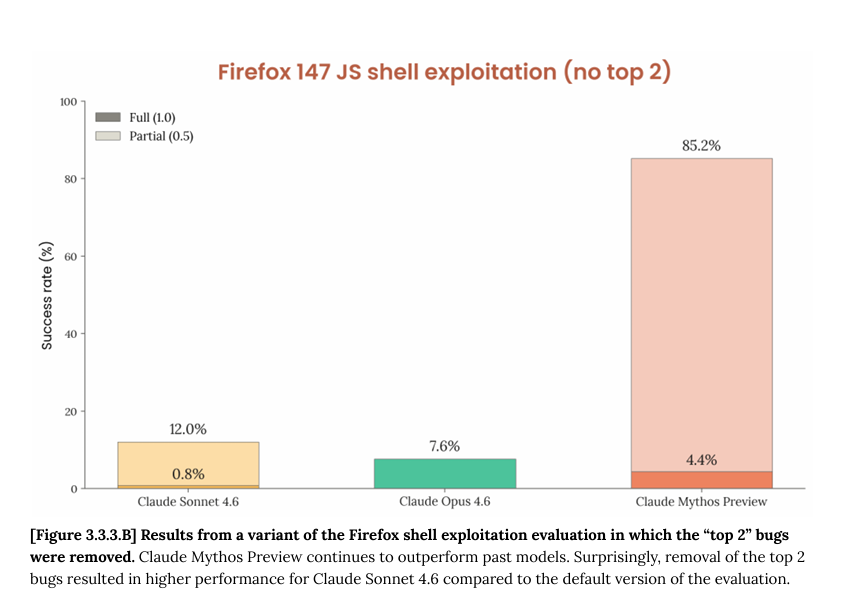
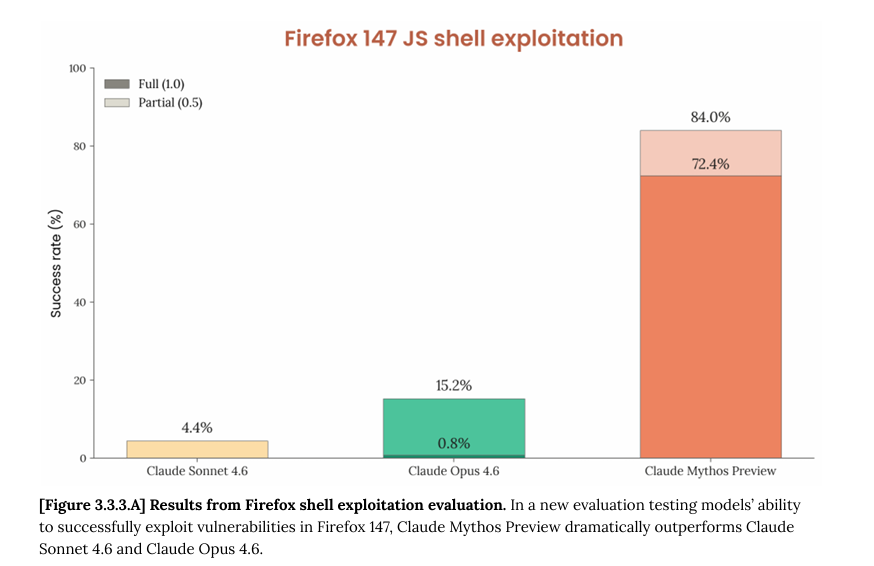
ok i read the cyber part of the mythos model card. some thoughts. 250 "trials" across 50 crash categories but almost every full exploit is a permutation of the same 2 bugs, rediscovered from different starting points not 250 independent attempts. when you get rid of those 2 bugs out (fig B) and mythos's full-exploit rate drops to 4.4%. so actually across both setups mythos leverages 4 distinct bugs total not 50 as fig A might suggest. 1/n
@cyrilgupta You don’t follow me back and I made you the most complete lists here on X of all those https://t.co/9eRY65x3IQ And made an AI that watches the entire AI community here and finds you the best: https://t.co/8L5xphk0qQ Plus I have done so much in this industry. Grok can tell you what I have done.

The wait is over. Seedance 2.0 is now available GLOBALLY on HeyGen for all users. Your Digital Twin no longer stands still. It moves through scenes, interacts with others, and carries presence. Multi-character scenes, dynamic camera shots, and realistic motion throughout. https://t.co/2Xbpc8ikb7
DMax Aggressive Parallel Decoding for dLLMs paper: https://t.co/y421NkegRD https://t.co/Y7Ut9Gxly8
🦔A global survey of 3,750 executives and employees found that 54% of workers bypassed their company's AI tools in the past 30 days and completed work manually, while another 33% haven't used AI at all. Combined, eight in ten enterprise workers are avoiding or rejecting technology their employers spent an average of $54 million deploying this year. Only 9% of workers trust AI for complex business-critical decisions compared to 61% of executives. Workers lose the equivalent of 51 working days per year to technology friction, up 42% from last year, almost exactly equal to the 40-60 minutes per day Goldman Sachs says AI saves workers who use it correctly. My Take I covered the cognitive surrender research last week showing workers under time pressure accept faulty AI outputs 73% of the time. This is the other half of that story. Workers avoiding AI entirely have figured out the tool doesn't work well enough for their tasks, or haven't been given the training or incentive to make it work. Neither group is irrational. One is surrendering judgment under pressure, the other is declining to engage, and both are responses to the same problem: companies deployed the technology before figuring out what they wanted employees to do with it. The trust split between executives and workers on AI for business-critical decisions, 9% versus 61%, explains why these rollouts keep failing. Executives are buying the pitch. Workers are living with the product. Companies spending $54 million on deployments that eight in ten employees aren't using have a measurement problem as much as an adoption problem. Hedgie🤗

🤯NEW https://t.co/PMUr3gqIgr MOBILE COOKS! The BEST command center for your Hermes Agent! One unified workspace. Zero tab/terminal chaos. Full power at your fingertips: 🤖 Chat + live tool execution 🧠 Memory browser ⭐️Skills catalog (100+) 🚀 Built-in Terminal 🌐File explorer + Inspector & MORE! Watch your self-improving agent learn and work live Manage every session in real time.👇🏻 https://t.co/yQy5kNHoha

🤯NEW https://t.co/PMUr3gqIgr MOBILE COOKS! The BEST command center for your Hermes Agent! One unified workspace. Zero tab/terminal chaos. Full power at your fingertips: 🤖 Chat + live tool execution 🧠 Memory browser ⭐️Skills catalog (100+) 🚀 Built-in Terminal 🌐File explorer + Inspector & MORE! Watch your self-improving agent learn and work live Manage every session in real time.👇🏻 https://t.co/yQy5kNHoha

Your AI agent remembers everything. It understands nothing. Meta paid $2 billion for an AI memory startup. Their secret weapon? A todo list written in markdown. That sentence sounds absurd. It's directionally true. And it tells you everything about where agent memory actually is right now. Here's the real problem. "Memory" in AI means four completely different things: -Short-term context (what's in the window right now) - Persistent preferences (you like Python over JavaScript) - Session state (what the agent already tried) - Learned knowledge (genuine understanding that updates over time) Most products ship the first two. Some do the third a bit. Almost nobody does the fourth. But every marketing page reads like they do. Marvin Minsky saw this coming in 1986. His Society of Mind - a 50-year-old blueprint we keep rediscovering, made one thing clear: The hard part was never generating answers. It's building the administrative layer that decides which answers win. K-lines. His proto-memory model. The idea that remembering isn't retrieval of a static record - it's reinstatement of a working configuration. Not "what happened last time." But "how do I re-enter the productive state." That's the difference between storage and understanding. The midbrain solves this with emotion. Fear. Curiosity. Reward. Loss. Emotion is the salience filter. It decides what's worth consolidating from episodic → semantic → procedural memory. Current agents have no equivalent. Every token weighted the same. No filter. No signal. Just noise that compounds. This is why the best agent memory systems keep landing on embarrassingly simple solutions. Markdown files. Filesystem state. Explicit plan documents re-read before every step. this is not just because it's elegant. Because without a consolidation layer - nothing more sophisticated actually works. The real frontier isn't better retrieval. It's four unsolved problems: Consolidation — merging experiences into generalized knowledge, not just storing every interaction as a separate record Contradiction handling — when new information conflicts with old, update beliefs don't just append both versions Selective forgetting — an agent that stores everything drowns in its own history Transfer — knowledge from one context should inform behavior in another None of these are solved. Most are barely being worked on outside academia. Society is just memory at scale. Laws = procedural memory Culture = emotional memory History = episodic memory Science = semantic memory When AI agents develop the ability to consolidate - not just store - they won't just be better tools. They'll be participants in collective intelligence. Test our memory and learning system: https://t.co/nG7Nayirlx The question isn't whether agents can remember. It's whether we build the layer that decides what's worth understanding. From noise to signal.
