Your curated collection of saved posts and media
💡 Research. Engineering. #OpenSource collaboration. Experience it all at #PyTorchCon North America, October 20-21 in San Jose, California. ⏳ Early bird savings of $400 end July 31. Register now: https://t.co/AVHdaIFT20 https://t.co/CwuV3cbShb
@OpenRouter https://t.co/kxUkYpSHHF
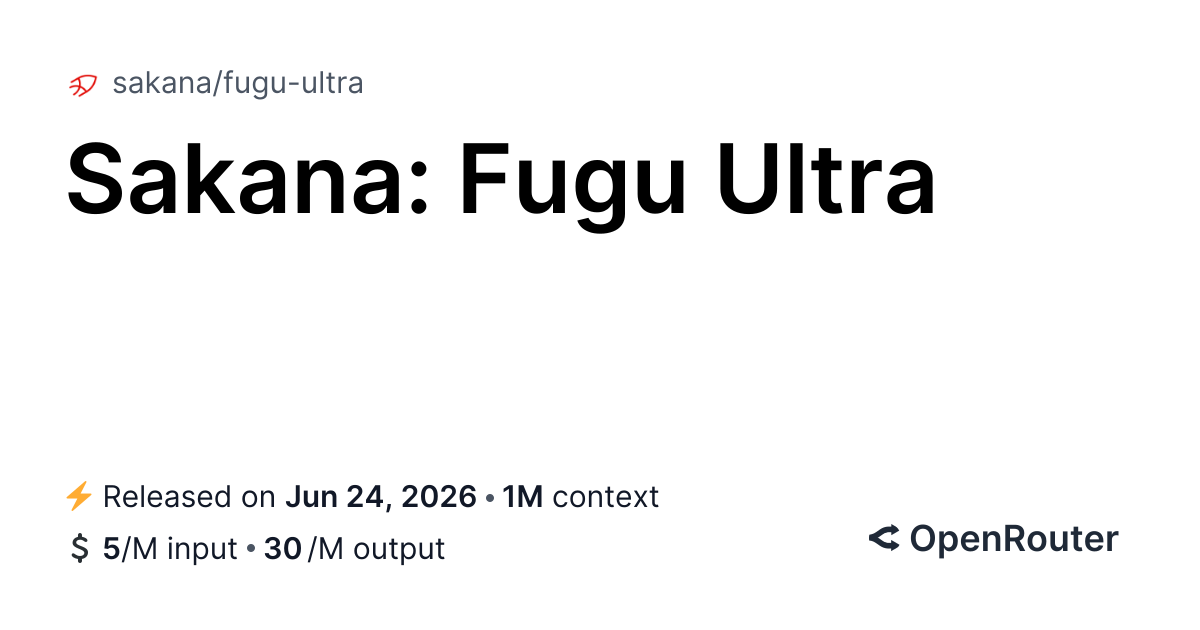
Sakana Fugu Technical Report Instead of training one larger model, Sakana AI trains an orchestrator that reads each query and dynamically routes or composes GPT-5.5, Gemini-3.1-Pro, Claude Opus 4.8 and other agents into query-specific workflows. With Fugu being the fast router, and Fugu-Ultra being the deep multi-agent conductor, trained with SFT, evolutionary strategies and GRPO to build adaptive scaffolds. The idea is to have the model pick GPT for math, Gemini for science and recall, Opus for debugging, then synthesize them when no single agent is best. This router is able to get SoTA results across SWE-Bench Pro, Terminal Bench, LiveCodeBench, GPQA-Diamond, CharXiv and more, demonstrating the potential of orchestration being a practical alternative beyond training.
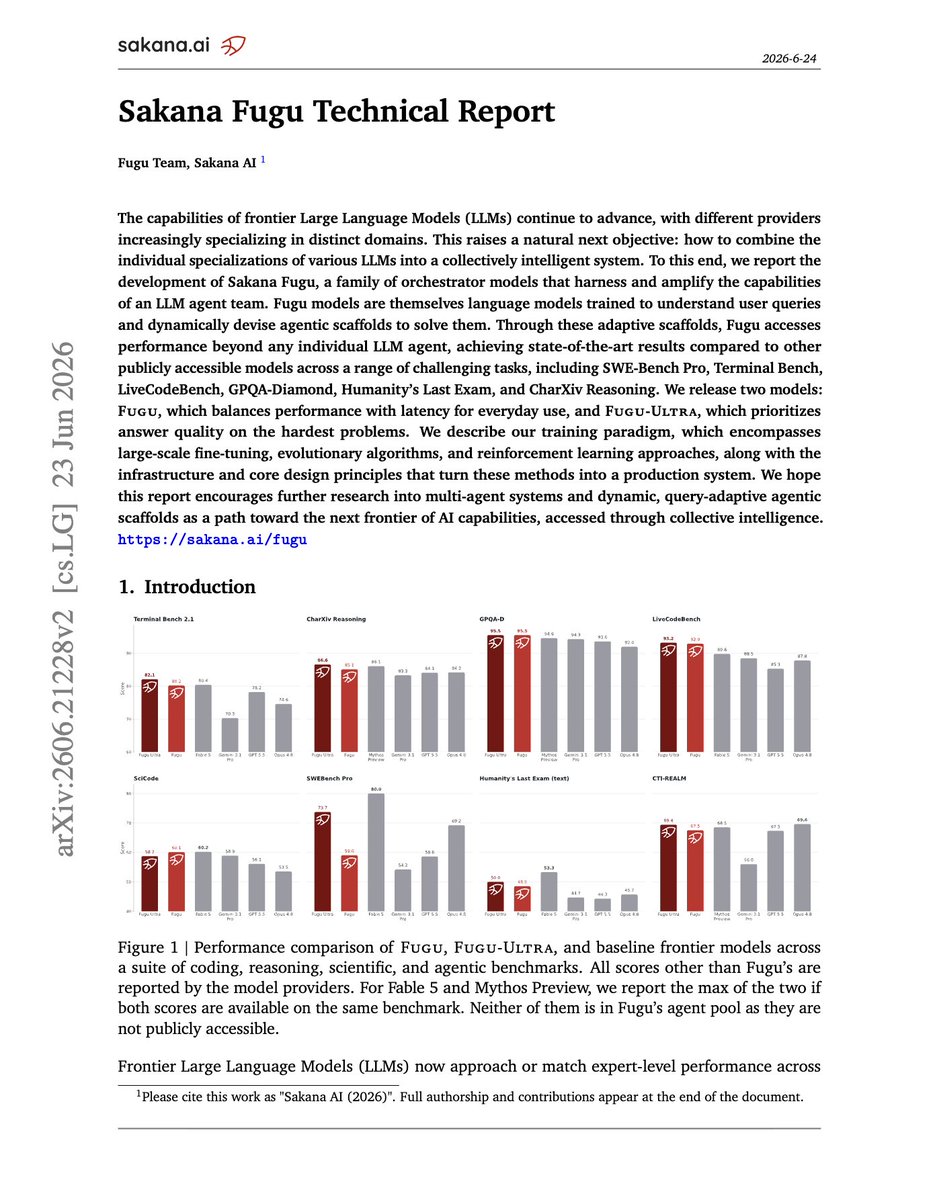
TechCrunch on Sakana Fugu and the broader conversation around frontier AI access in Asia. Our position remains that AI is best developed together rather than hoarded. Sakana AI will continue contributing to a more resilient ecosystem. https://t.co/VasVaLKoWo

Google Cloud Japan ブログにインタビュー記事を掲載いただきました。 「Sakana Fugu」のサービス基盤として、GoogleのEnterprise Agent Platformを全面採用した経緯について、プロジェクトを率いたチーフサイエンティストのYujin Tangをはじめ、3名のサイエンティストが開発の舞台裏を語っています。 「Sakana Fugu はスポーツに例えるなら、さまざまな選手(AIモデル)やフォーメーション(組み合わせ)、戦術(タスク処理)を対戦相手(クエリ)に応じて使い分けるコーチのような存在です。AIのチームを指揮するAIとして集合知にアクセスし、個々のモデルを上回るパフォーマンスを発揮します」 — Stefan Nielsen 2025年10月に始動した本プロジェクトは、Google チームの手厚いサポートにより約半年でローンチに至りました。Gemini も、動的に呼び出されるフロンティアモデルのひとつとして中核に組み込まれています。 「Sakana Fugu は、Sakana AIのさまざまな製品を支えるコアテクノロジーとなっていく予定です」 — Yujin Tang ぜひご覧ください🐡 https://t.co/yC1QS1Cqar

We're building a team at @Anthropic focusing on AI and the rule of law. We've made our first hires, and are now opening up a new research engineer role. We're looking for people with advanced technical skills, including AI/deep learning/NLP, full-stack development and data science, paired with training or experience in law, government, political science, or a related field. If this is you, or a friend, please get in touch. https://t.co/uZQEZC5lck

Today, I’m excited to formally announce @mirendil with my amazing co-founders Harsh Mehta, Shayan Salehian, and Tara Rezaei! We’re fortunate to work with @a16z and @kleinerperkins, who led our seed round of $200M, followed by a major investment from NVIDIA, among others. Mirendil exists to accelerate science and technology, and through them, to help solve humanity's most pressing problems. Self-accelerating AI R&D is the most direct path to delivering on AI's broader promise, which is why we believe the most important application of AI is AI itself. Get this loop right, and it compounds. It fundamentally changes the rate of progress itself across all domains. We believe this capability should be democratized. It should be used to power all scientific efforts trying to innovate at the frontier. There are far more important problems—and broader ones—than any single lab can take on, so more groups should be able to pursue them. This pulls concentration of power away from a few labs: businesses and science labs can own their AI and infrastructure, keep their margins, and control their own destiny instead of ceding it all to a single AI lab. We’re a small team with a singular focus. Our founding team consists of 20 researchers and engineers from frontier institutions including Anthropic, xAI, Google DeepMind, and OpenAI, united by a passion for science and a drive to build the technologies that move it faster. If you want to build the system that builds systems, join us! @HarshMeh1a, @shayan_, @tararezaeikh

https://t.co/0YBCMLFqin

What stands out to me is the pace. Two weeks ago the focus was on restrictions. Today it's about finding a practical path forward. That may become the pattern as AI continues to evolve. https://t.co/dtYrmJKdo8

Technology has always changed the way we learn. AI glasses are now forcing educators to rethink not just how they test students, but what knowledge and skills they should actually be testing. The exam may be changing as much as the classroom. https://t.co/h3xU4KhAYG

https://t.co/ljbKIr6LX9

We've all become used to technology getting better and cheaper. That may no longer be the case. The AI boom is driving demand for chips and memory to levels we've never seen, and consumers are starting to feel the impact. AI isn't just changing software. It's changing the economics of technology.

https://t.co/2sf90403vS

Anthropic has set the pace in frontier AI for some time. Now reports suggest China's Zhipu is narrowing the gap in cybersecurity capabilities. The AI race is becoming more competitive, and that's something the industry can't afford to ignore. https://t.co/tEOtINKpTT
It's easy to focus on how fast AI is improving. The harder question is whether society is ready to move at the same speed. Innovation and public trust don't always evolve together. https://t.co/K26Hg7zdYi

The Bank for International Settlements isn't questioning AI. It's questioning whether the pace of investment can keep matching expectations. That's a discussion investors should pay close attention to. https://t.co/q6hQm06I9i

Most people still talk about AI as a software story. Markets are telling a different story. The companies making the chips, memory and storage behind AI have become some of the biggest winners of this cycle. Sometimes the most important part of a technology boom is the infrastructure nobody used to notice.

https://t.co/gUdkJfJ7AL

FSD V14 lite release notes!! Incoming now, holy crap!! https://t.co/PwAQABNGSt
The official post: https://t.co/3LUmEIdjh0
FSD v14 Lite is now rolling out to AI3 early-access customers. Based on the feedback, will rollout to more customers over the next few weeks. This build distills the driving behavior from AI4’s v14 series into both the camera and compute config of AI3. It includes destination op

Most robots you see are trained to walk on pristine concrete floors in air conditioned San Francisco labs with gigabit wifi. That is not the real world. That is a sandbox. The moment a robot leaves that grid, into a mine, a jungle, or up a mountain, the cloud becomes a luxury it cannot reach. Zero connectivity, massive latency, zero margin for error. This week a humanoid named Pemba became the first to summit Chimborazo at 6,200 meters, the highest a humanoid has ever gone. It walked autonomously on the moderate terrain and was carried on the technical sections. The climb is the proof. The real story is the infrastructure that makes it repeatable. Eastworlds, the technical partner to Geologic Dome, is building Starlink fed portable edge units so a humanoid keeps running on cloud inference where there is no wifi and no power. That is the moat, and the whole reason Everest is next. Up there, there is no signal to fall back on. Solve the infrastructure and you solve the mountain. This is the frontier we track at AlignedNews. Follow the journey at @pabloberlangab. Technical partner: @eastworlds_io
be andrej > join anthropic > shill claude slack bot > say it's a new paradigm > get pushback > "twitter is toxic" > hide in anthropic slack echo chamber > repeat? this is exactly why anthropic is the way they are any pushback from outside the cult is labeled "toxic" https://t.co/8iyvPzs88T
Polymarket acquired Craft Agents, and @balintorosz (my brother) will lead Product Engineering. I’ve now made the January deepdive on Craft Agents free. Craft Agents shares ideas with Claude Cowork - built before Claude Cowork! It’s also open source. https://t.co/81teUBF2Am https://t.co/VYy87m0U7i
Some personal news - Polymarket has acquired Craft Agents, and part of the Craft team is joining Polymarket. I'll be leading Product Engineering, with the goal of building one of the best product and design engineering teams in the world. I'm incredibly excited for what's next.
Yes! binary judges are far more practical for most people, because likert scales (or scores) have too many footguns All the flashcards are here (inspired by @chrisalbon ‘s flashcards) https://t.co/qfB4WJgX5n https://t.co/OvSdVi5rbB
If you use LLM-as-judge, this one is worth reading. (bookmark it) It's actually one of the most effective ways to use LLM-as-a-Judge for evals. Holistic judge scores hide both their reasoning and their ceiling effects. BINEVAL decomposes each evaluation criterion into atomic

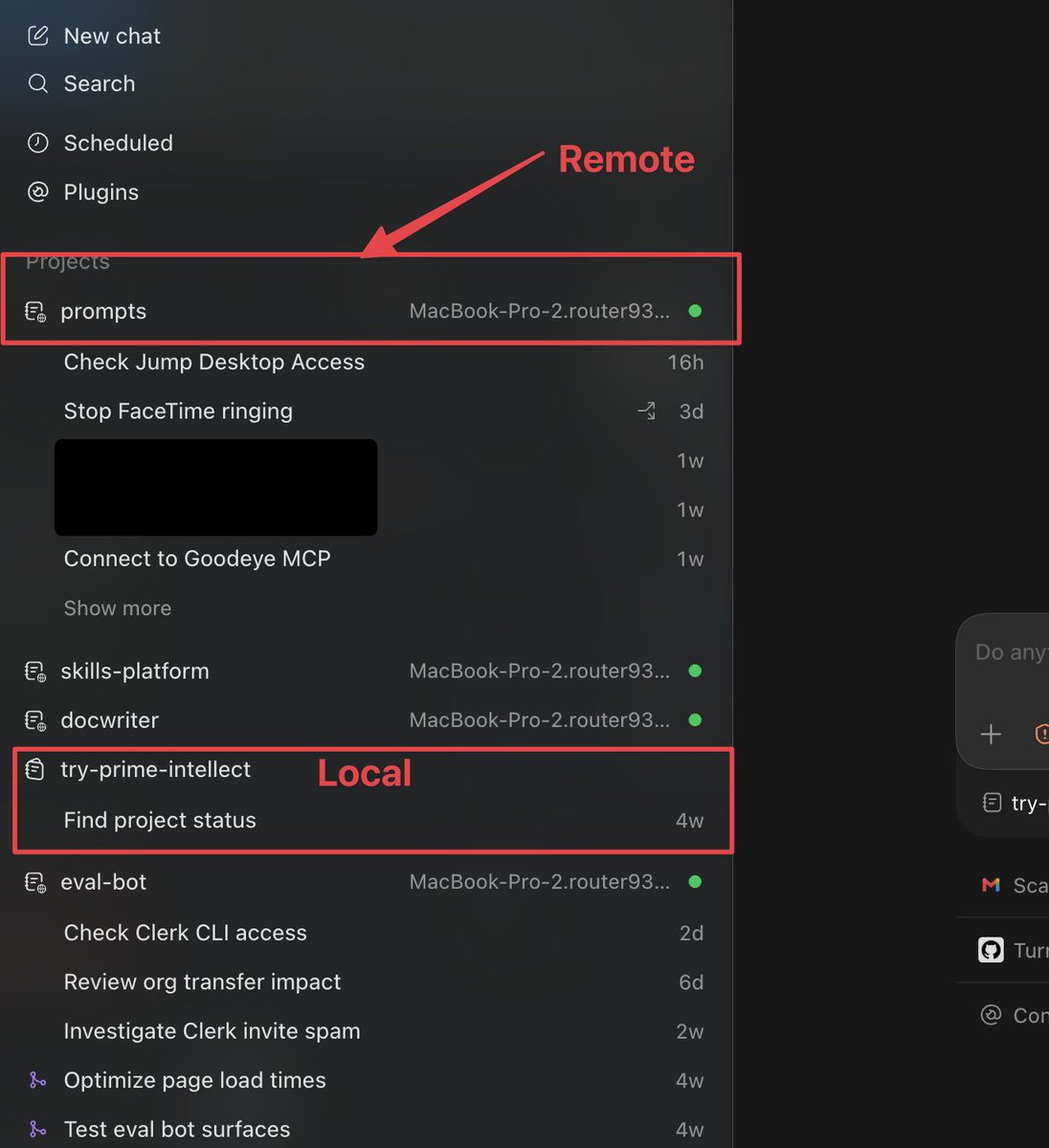
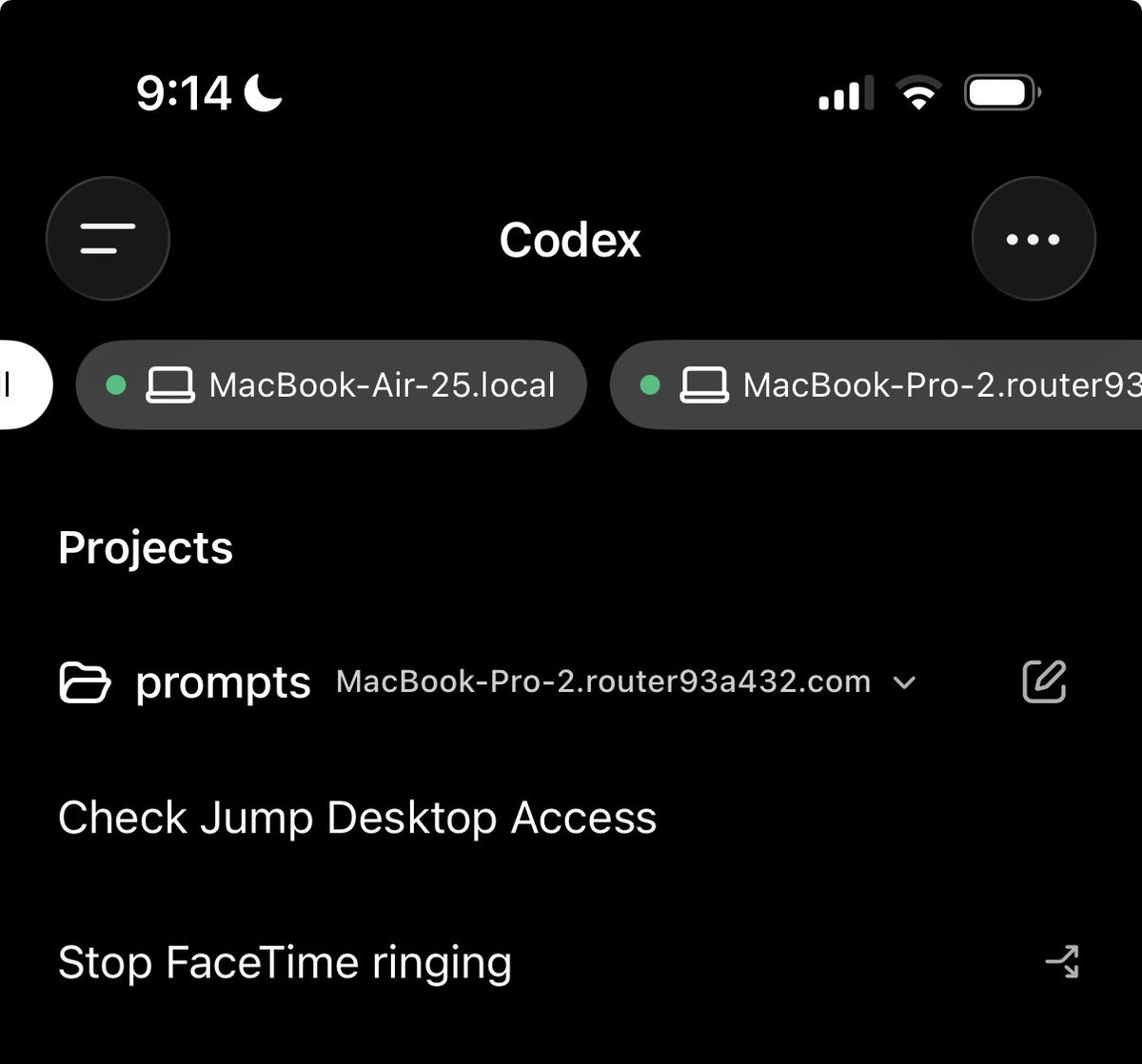
Codex desktop is miles ahead of Claude for remote access via mobile or another computer. Codex allows you to see **all** running sessions on **all** devices from any other device, including mobile You can truly go touch grass with Codex. Brings me joy every day https://t.co/Kh91eZ0KOt
We’re sharing the next major milestone in our non-invasive brain-to-text decoder research: Brain2Qwerty v2. Building on v1, which was published today in @Nature, Brain2Qwerty v2 is the highest-performing end-to-end pipeline capable of real-time sentence decoding from raw brain signals. It advances beyond character-level performance to decoding words and semantics, enabling accuracy for overall communication. We believe this research has the potential to make a real difference for the millions of people who suffer from brain lesions or disorders that prevent them from communicating. 🧵👇
simple and creative https://t.co/V7lajzB39l


how you lookin on the lords day prayers towards mission bay - saint @thsottiaux's resets https://t.co/TdsF81PdYm
simple and creative https://t.co/V7lajzB39l

https://t.co/811uzjyiE3
As engineering, product, design, DS, etc. melt into a new kind of role, I was reflecting on what roles might look like in the future. For example, when I look at the Claude Code team I see what I think is five archetypes: 1. Prototyper: comes up with brand new ideas; churns out

https://t.co/811uzjyiE3

first ee project: I put a bitmap running horse on a raspberry pi pico using codex! I couldn’t get the snout right 😭 so it looks a bit stubby thank you @covacut for the ingredients https://t.co/gukxpMwPrr

I’ve had enough With Fable 5 being gatekept from us, and now GPT 5.6 being gatekept, I’m going full open source Just went to Microcenter and built this RTX 5090 computer. Will be adding a RTX Pro 6000 to it shortly This brings my home AI lab to: • 3 Mac Studio 512gb • DGX Spark • RTX 5090 • 2 Mac Minis I’m building a home AI lab that will allow me to run and support as many local models as possible I already have Qwen 3.6, Orinth1.0 and GLM 5.2 running. Will be adding more. They’re all running on my new custom built AI lab platform that’s making sure these models do work 24 hours a day for me With frontier models being gatekept, and hardware prices becoming outrageous (this build cost $9,000), it was time to pull the trigger In 1 year I believe prices for hardware will be triple from here. Mac Studios starting at $10,000. Mac Minis starting at $2,000. MacBook Pros starting at $5,000. 2 years from now I don’t believe any hardware will be available to consumers The time to strike was now and I struck In an age where intelligence both in the cloud and in your home are being limited, I’m becoming sovereign. It might be time for you to do the same.
