Your curated collection of saved posts and media
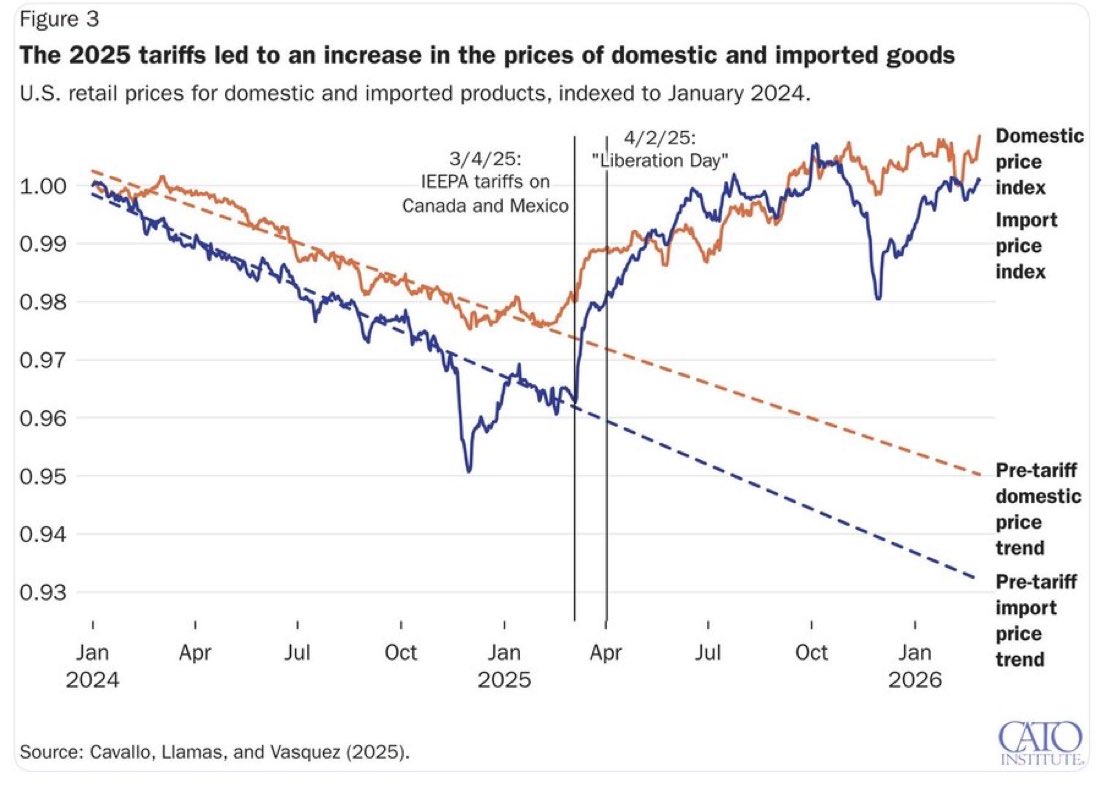
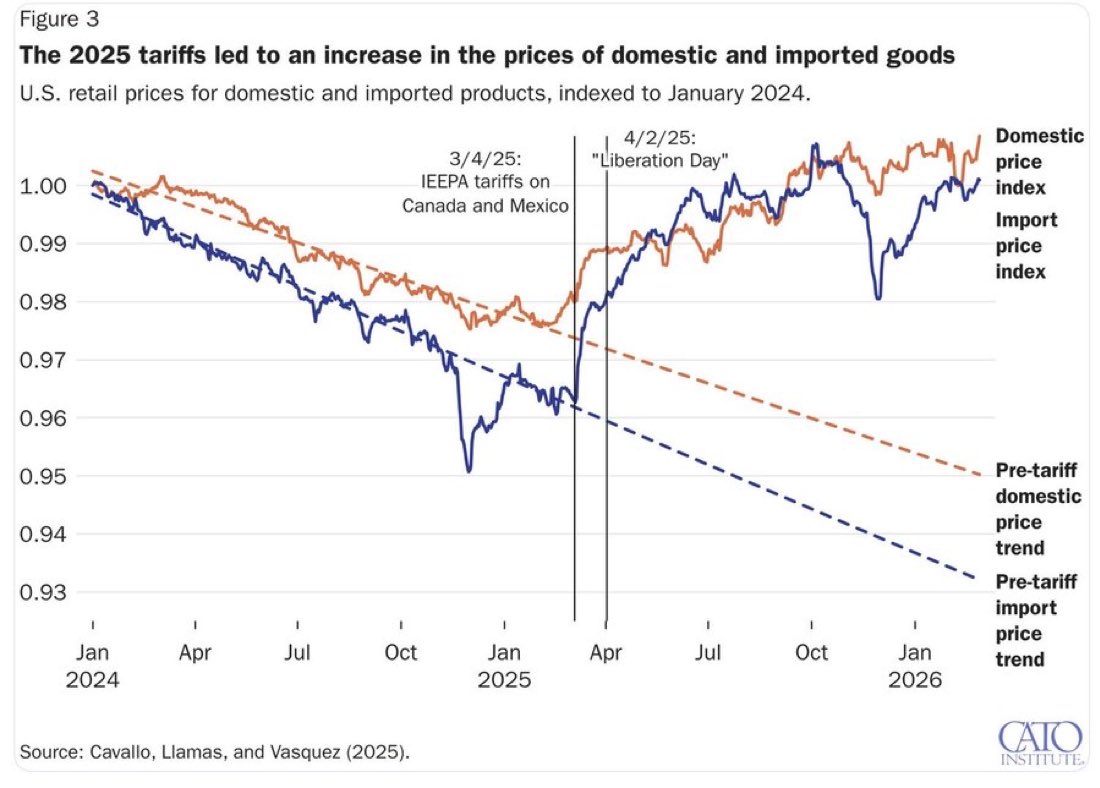
Inflation was coming down in the United States—and then Trump’s tariffs happened. https://t.co/qDh8p6tuzy
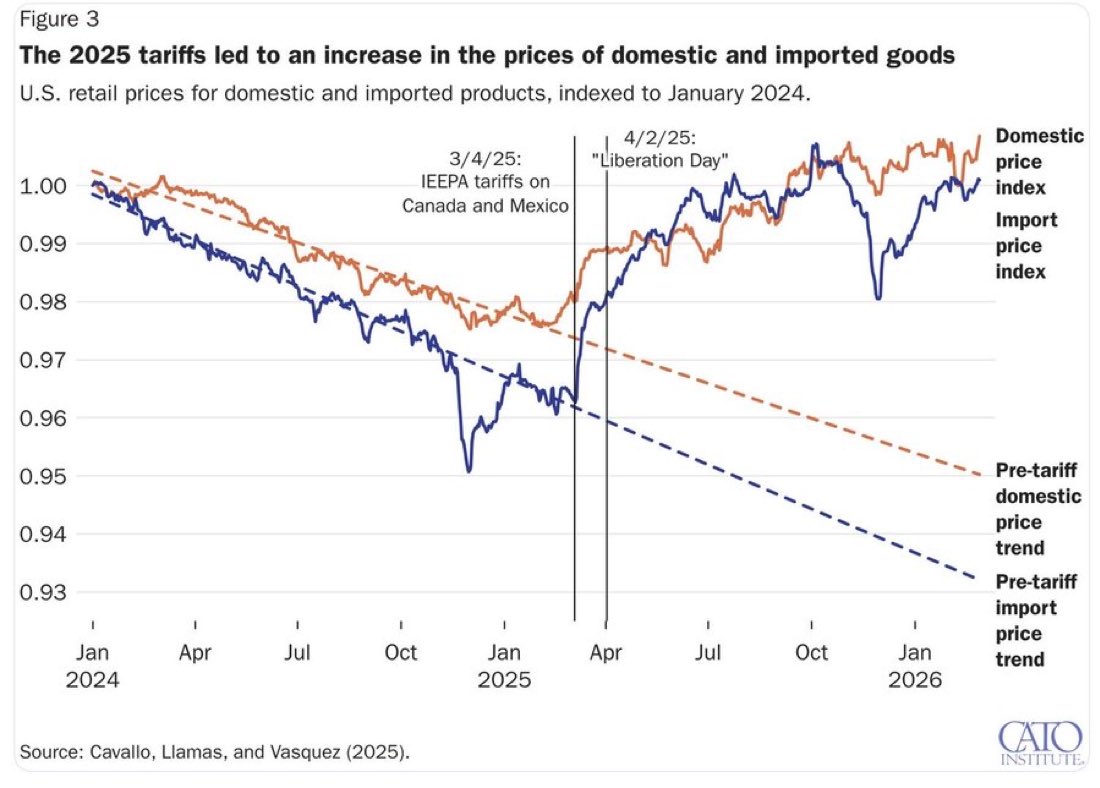
Inflation was coming down in the United States—and then Trump’s tariffs happened. https://t.co/qDh8p6tuzy
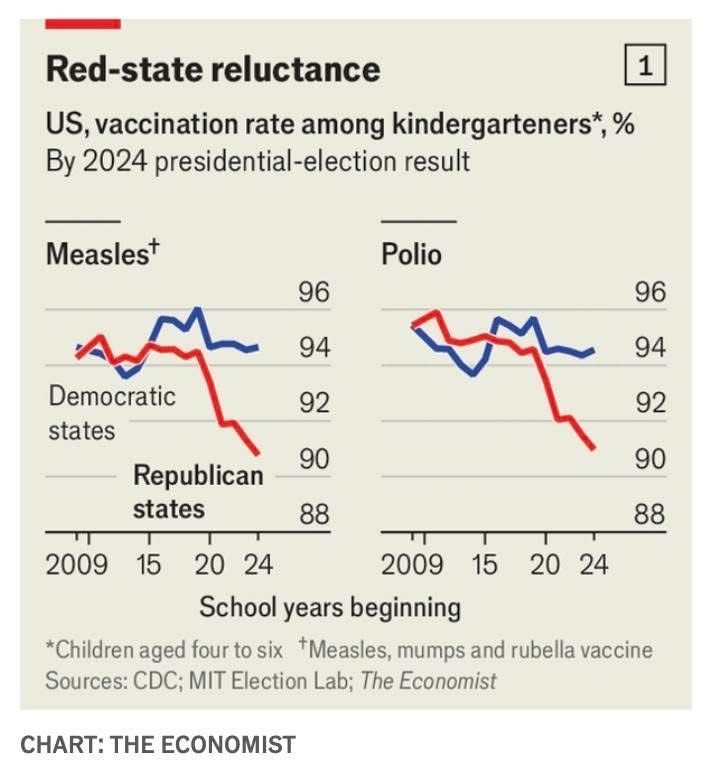
We will read histories of today’s US in a few decades and wonder how something like this could happen. Slowly allowing Polio and Measles to celebrate comebacks is pure stupidity. https://t.co/ht1if5CD9l
Time to follow https://t.co/K4Rf9nWzU8! https://t.co/8sET4B20ZB
Genie3 generates videos. We generate 𝟯𝗗 𝘄𝗼𝗿𝗹𝗱𝘀 you can actually use. Launching tomorrow — Tencent #HYWorld 2.0, an engine-ready World Model🚀 This isn't a video. It's a real 3D scene, all generated & editable. One image in. A whole 3D world out. 🔥Open-source tomorrow https:

Time to follow https://t.co/K4Rf9nWzU8! https://t.co/8sET4B20ZB

✨ERNIE-Image is here — Baidu's open 8B text-to-image model that punches way above its weight. ✅ Only 8B DiT params, #1 open weights model on GenEval, OneIG, & LongTextBench ✅ Precise text rendering in English, Chinese, and more ✅ Complex instruction following & multi-object control ✅ Posters, manga, multi-panel layouts with structural coherence ✅ Broad styles: photography, cinematic tones, graphic design, and more ✅ Easy to deploy: Runs on 24GB VRAM Two versions: ERNIE-Image — SFT model, stronger general quality in 50 inference steps ERNIE-Image-Turbo — Optimized for speed and aesthetics in just 8 steps 🤗 Model: https://t.co/QCZkSFZEIz https://t.co/Eutm0gurmp 📝 Blog: https://t.co/Gb5uQX4mAU 🖥️ Demo: https://t.co/vikUfdp6KO 🔧 Github: https://t.co/SgFNyxzZKZ 👾 Discord: https://t.co/05DviJtHU0 Join our Discord for free bot access, weekly challenges, and prizes!


I'm excited about voice as a UI layer for existing visual applications — where speech and screen update together. This goes well beyond voice-only use cases like call center automation. The barrier has been a hard technical tradeoff: low-latency voice models lack reliability, while agentic pipelines (speech-to-text → LLM → text-to-speech) are intelligent but too slow for conversation. Ashwyn Sharma and team at Vocal Bridge (an AI Fund portfolio company) address this with a dual-agent architecture: a foreground agent for real-time conversation, a background agent for reasoning, guardrails, and tool calls. I used Vocal Bridge to add voice to a math-quiz app I'd built for my daughter; this took less than an hour with Claude Code. She speaks her answers, the app responds verbally and updates the questions and animations on screen. Only a tiny fraction of developers have ever built a voice app. If you'd like to try building one, check out Vocal Bridge for free: https://t.co/nGrFznAMLh
Excited to partner with @Dropbox on bringing agentic analytics to one of the most sophisticated FP&A teams in software. https://t.co/qGkwXS2bvd
@rahulnanda86 https://t.co/dzgrCH8rDQ


@fellowshiptrust https://t.co/hB5x98nPZQ


The AI middle managers rise up. @IrenaCronin and I write this newsletter every week. As companies deploy more specialized AI agents, they will need AI middle managers to coordinate tasks, monitor performance, enforce rules, and escalate issues to humans. The idea is that the real challenge is no longer just building smart agents, but managing them effectively so they work together safely, efficiently, and at scale. Read for free: https://t.co/HHwYy7NoAl (and please subscribe!)

Attention Sink in Transformers A Survey on Utilization, Interpretation, and Mitigation paper: https://t.co/QyXl9xYaru https://t.co/Q0mTZvpTET


OmniShow Unifying Multimodal Conditions for Human-Object Interaction Video Generation paper: https://t.co/6r4EVKx31z https://t.co/Iz8mA2WDwE
@altryne https://t.co/k2zKmAEjvN


QuanBench+ A Unified Multi-Framework Benchmark for LLM-Based Quantum Code Generation paper: https://t.co/88saBbFUS6 https://t.co/heFgUGpOvY


The Past Is Not Past Memory-Enhanced Dynamic Reward Shaping paper: https://t.co/nicAA4L9un https://t.co/8ujSodNWUQ


@NemPerez https://t.co/4eASzZhHzw


@Dalos 🤷♀️ https://t.co/t8LHH3GKml


i made a map to monitor data centers all around the world tracks construction + nearby power plants + local AI legislation, and follows the politicians behind their bans (+ if they're getting paid to do so!) https://t.co/oKVjhXLGzv
// Multi-User LLM Agents // Every agent framework assumes one user giving instructions. But deploy an agent into a team workflow, and suddenly it has multiple bosses with conflicting goals, private information, and different authority levels. This work formalizes multi-user interaction as a multi-principal decision problem and introduces Muses-Bench with three scenarios: instruction following under authority conflicts, cross-user access control, and multi-user meeting coordination. Even the best model, Gemini-3-Pro, only averages 85.6% across tasks. On meeting coordination, no model exceeds 64.8% success rate. Privacy-utility tradeoffs are especially brutal: models that score near-perfect on privacy (Grok-3-Mini at 99.6%) tank on utility (60.1%). Why does it matter? As agents move into organizational tools, Slack bots, and shared workspaces, multi-principal conflicts become the default, not the exception. Current models aren't ready. They leak more privacy over multi-turn interactions and can't maintain stable prioritization under conflicting objectives. Paper: https://t.co/ttoFSlIYxC Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

🤯Topology & UV — the NO.1 headaches in #3D GenAI. 🔥We just move closer to BOTH at the same time. Introducing SATO: Strips as Tokens, a new autoregressive model for topology & UV, has been conditionally accepted to #SIGGRAPH 2026. Will available at #Hyper3D More details👇
SpaceX just launched the 1000th Starlink satellite of 2026. That’s ~10 satellites deployed every single day and one launch roughly every 2.5 days. Starlink now has 10,000+ active satellites in orbit, the largest satellite constellation ever built. https://t.co/mCGfvv5SYE
@karatademada https://t.co/pwLRCxaRP2


@CaptainHaHaa https://t.co/i2VMSRQTC8


// Artifacts as Memory Beyond the Agent Boundary // An agent doesn't always need a bigger memory buffer. Sometimes the environment itself remembers on the agent's behalf. New research formalizes this intuition mathematically for the first time. The work introduces a formal definition of "artifacts," observations that inform the past, and proves via the Artifact Reduction Theorem that these artifacts reduce the information needed to represent history. Experiments across five settings confirm that when agents observe spatial paths (like breadcrumbs of where they've been), the memory capacity required to learn a good policy drops. The effect arises unintentionally through the agent's sensory stream. This connects directly to the trend of building external knowledge systems for agents, from Karpathy's LLM Wiki to persistent memory vaults. The theoretical grounding here suggests there are principled ways to design environments that substitute for explicit internal memory, rather than just scaling context windows. Paper: https://t.co/xtteUXFXO2 Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

🚀 Great to see vLLM powering OCR at this scale — Chandra-OCR-2 (5B) serving ~60 papers/hour per L40S across 16 parallel jobs. The full pipeline breakdown is a great read 👇 🔗 https://t.co/z8tkv04ZLp https://t.co/vi9FPj6JIQ
We just OCR'd 27,000 arxiv papers into Markdown using an open 5B model, 16 parallel HF Jobs on L40S GPUs, and a mounted bucket. Total cost: $850 Total time: ~29 hours Jobs that crashed: 0 This now powers "Chat with your paper" on https://t.co/G2mDae0uv9 https://t.co/qpz7Q9x8Od


@cfryant https://t.co/Xcm9Jxr7tS

HealthAdminBench: Evaluating Computer-Use Agents on Healthcare Administration Tasks "we introduce HealthAdminBench, a benchmark comprising four realistic GUI environments: an EHR, two payer portals, and a fax system, and 135 expert-defined tasks spanning three administrative task types: Prior Authorization, Appeals and Denials Management, and Durable Medical Equipment (DME) Order Processing." "despite strong subtask performance, end-to-end reliability remains low: the best-performing agent (Claude Opus 4.6 CUA) achieves only 36.3 percent task success, while GPT-5.4 CUA attains the highest subtask success rate (82.8 percent)."

SciPredict: Can LLMs Predict the Outcomes of Research Experiments in Natural Sciences? "SciPredict addresses two critical questions: (a) can LLMs predict the outcome of scientific experiments with sufficient accuracy? and (b) can such predictions be reliably used in the scientific research process? Evaluations reveal fundamental limitations on both fronts. Model accuracies are 14-26% and human expert performance is ≈20%."

code: https://t.co/fSmpshFbsk abs: https://t.co/k167dNDb6S
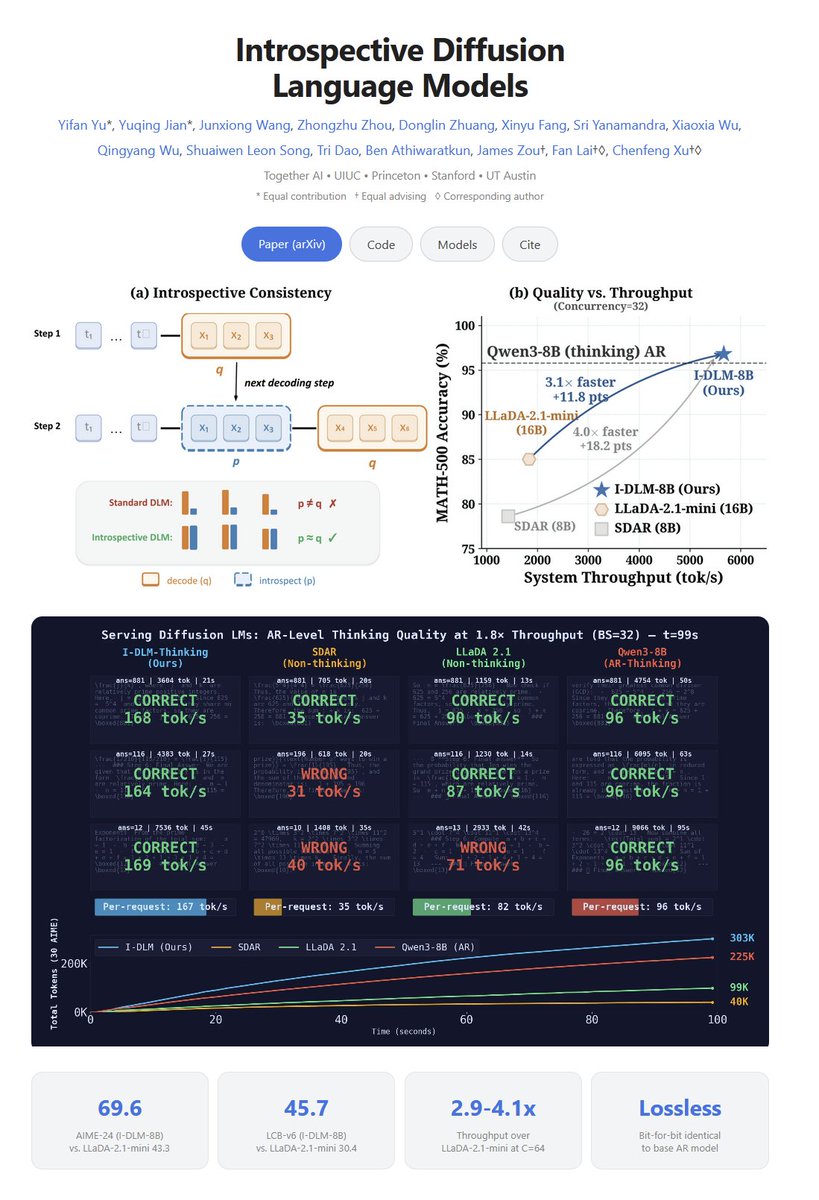
Introspective Diffusion Language Models "To the best of our knowledge, I-DLM is the first DLM to match the quality of its same-scale AR counterpart while outperforming prior DLMs in both model quality and practical serving efficiency across 15 benchmarks." "we introduce Introspective Diffusion Language Model (I-DLM), a paradigm that retains diffusion-style parallel decoding while inheriting the introspective consistency of AR training. I-DLM uses a novel introspective strided decoding (ISD) algorithm, which enables the model to verify previously generated tokens while advancing new ones in the same forward pass."

website: https://t.co/N8mE2I77tC code: https://t.co/02RRzIOCDU abs: https://t.co/EjsPMfpqC0