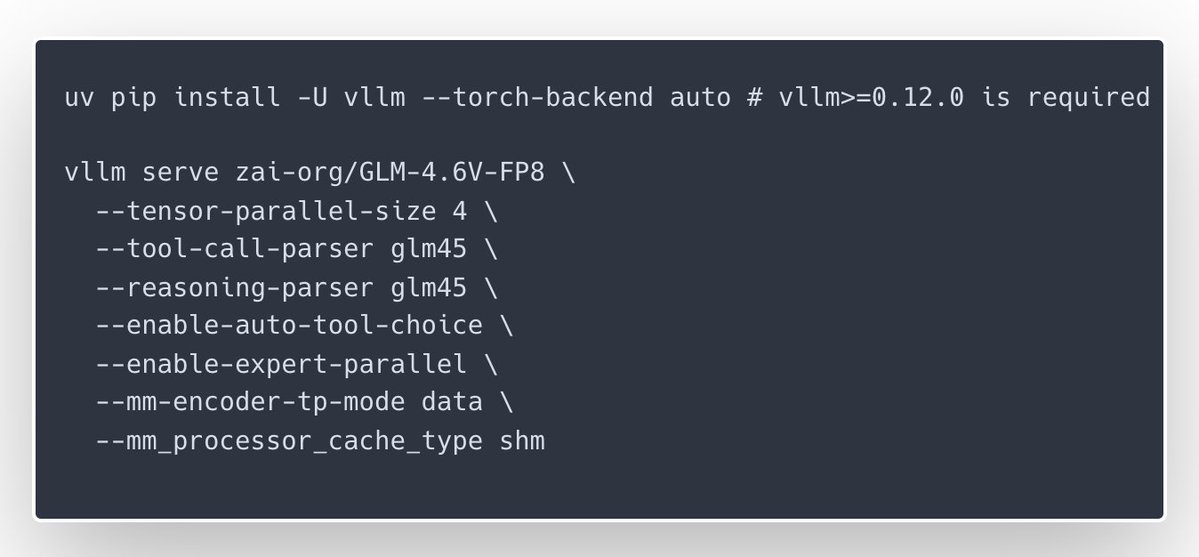
@vllm_project
🎉Congrats to the @Zai_org team on the launch of GLM-4.6V and GLM-4.6V-Flash — with day-0 serving support in vLLM Recipes for teams who want to run them on their own GPUs. GLM-4.6V focuses on high-quality multimodal reasoning with long context and native tool/function calling, while GLM-4.6V-Flash is a 9B variant tuned for lower latency and smaller-footprint deployments; our new vLLM Recipe ships ready-to-run configs, multi-GPU guidance, and production-minded defaults. If you’re building inference services and want GLM-4.6V in your stack, start here: https://t.co/NhHT6iey6C