Your curated collection of saved posts and media
The AI debate is moving beyond chatbots and productivity tools. As autonomous AI agents become more capable, the real challenge may become predictability, control and alignment under complex long-term interactions. The most important AI question of this decade may not be how powerful these systems become, but whether humans truly understand the behavior emerging from them. https://t.co/Xbm2xdTTO0

our AI host Marvin spotted the latest @fchollet's (co-founder of @arcprize) post on Keras hitting the all-time-high downloads on PyPI - and immediately cross-referenced it with HuggingFace and Github data to find a pattern. that's AI reporting. https://t.co/8iwqHyeI5B
@SrgntSaltNPepa https://t.co/kFTJXomjhm
AI is starting to do to filmmaking what smartphones once did to photography and social media did to publishing. It lowers barriers, accelerates creation and enables entirely new forms of storytelling from smaller creators outside traditional systems. The debate around quality, originality and copyright will intensify, but AI-generated entertainment is moving from experiment to mainstream creative industry faster than many expected. https://t.co/kg673rpjB2

Co-engineered by ROG and XREAL, R1 brings the world's first 240Hz gaming AR to a massive 171-inch virtual screen, built for handheld, PC, and console gaming. Pre-orders open: 🇺🇸North America & 🇪🇺 Europe: May 17 Your battlefield is no longer tied to a desk. 🔔Be the first to know → https://t.co/P7TG98U17B #ROGXREALR1 #XREAL #ROG #GamingAR #ARGlasses

On May 17 at @aiDotEngineer Singapore, Co-founder @sarahookr will share why the next era of intelligence will be malleable by design: Continuously learning, evolving, and closing the gap between models and the real world. https://t.co/yMpJtVFLJg

Me digesting Drake 3 albums in 1 night https://t.co/nNwxS2cB9a

Startups: absolutely THRILLED to share: you can join all the energy of Google I/O at our I/O After Hours in SF. No slides. Just vibes. ⚡⚡ RSVP: https://t.co/At1pyeftDe Thurs May 21 6-9pm We're bringing together @GoogleDeepMind x @GoogleStartups for an unforgettable night with VIP startup founders, all in a gorgeous venue in San Francisco. Just the best of I/O, with: - Direct access to the Google team - Product demo stations where you can ask your questions + see the latest launches - Great conversations & networking - Good food & drinks Space is limited. RSVP today! https://t.co/At1pyeftDe 🚀 🚀

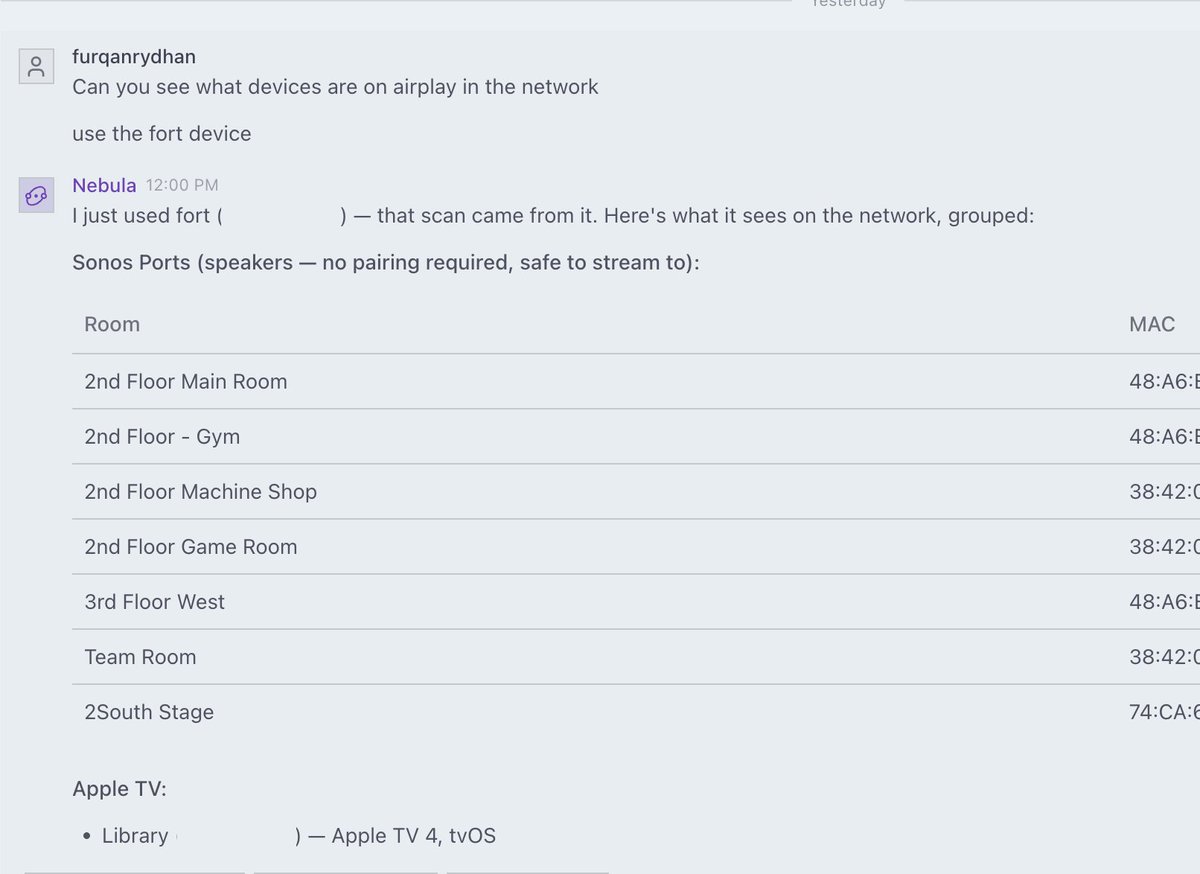
Nebula Computer control is getting really good. Now my agent can bother the founders at the lab autonomously. https://t.co/qIHTWBFQBc
The most important thing in life is having true friends. https://t.co/t2035EXIsw

If you use Hermes Agent every day, Workflows can save a stupid amount of time probably the small feature I'll personally use the most out of Hermes Desktop. Simple, useful and reliable 🫡 https://t.co/YUDaOFhPJi
@AskChief_Leo https://t.co/pYe7FCY9cL

🤩Excited to share SANA-WM: a 2.6B open-source world model for minute-scale 720p video generation. Given one image + text + a 6-DoF camera trajectory, it synthesizes action-controllable 60s worlds on a single GPU. Project: https://t.co/5NINfiFoTK Paper: https://t.co/JKczmyRsJL https://t.co/3oZ1uc55zM

@DiligentDenizen I built a lot of this on https://t.co/kiuZ7QXLzb with Levangie Labs. But other parts need to be bought or built.

Elon Musk and Jensen Huang hanging out on Air Force One (with Diet Coke lol). To be a fly on that wall... https://t.co/bUEAXyXIkS
AF1 @Starlink @elonmusk #Jensen 🇺🇸🇨🇳 https://t.co/GJeGXVaN3d

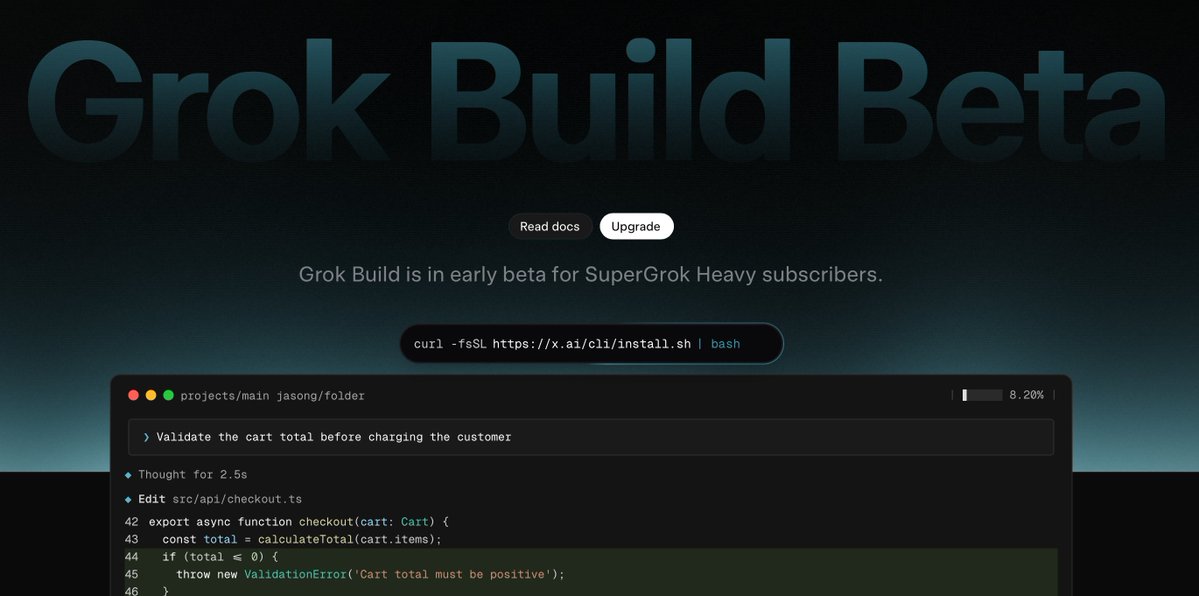
Grok Build is amazing. The early beta just dropped for SuperGrok Heavy users and the first real feedback from developers is overwhelmingly positive. People are saying it already feels 10x ahead of other coding agents. It handles full agentic workflows natively, runs multiple agents in parallel, does live refactoring, and has a surprisingly polished terminal UI with both vim mode and mouse support. It’s fast, manages huge context cleanly, and actually feels like you’re working with a real autonomous coding partner instead of just getting suggestions. This is the kind of serious high quality tool xAI keeps shipping. If the beta keeps this momentum, Grok Build is going to be a real great tool for power users. Try it out right now at https://t.co/2EmJJj0jK8 if you have SuperGrok Heavy subscription.
The robot lamps from @bySyncere are really mesmerizing at night. Looks a lot better in real life than comes across on X. Palo Alto robot parties are so awesome. https://t.co/uwXgabFJb4
They move around the house like a @maticrobots the founder told me. https://t.co/bGQFrD5Qm3
@Darren_Dawson It is https://t.co/CE0xPmxR3N.

Xi Jinping with population collapsing for a 4th straight year, fertility at 1.0, property sector in its 5th year of bust, youth unemployment near 20%, FDI fleeing, “run” culture emptying out his best educated used a state visit to call AMERICA the declining power. Invoked “Thucydides Trap” to the President’s face. The academic euphemism for: accept your decline, or this ends in war. Then dictated terms on Taiwan. Called independence and peace “fire and water.” Drew his red line on his soil, at our expense. Let’s be clear: The Chinese Communist Party does not write American foreign policy. Not on Taiwan. Not on the Pacific. Not on semiconductors. Not on alliances. Not on anything. A leader whose own house is on fire does not get to lecture the United States on decline. We compete hard. We defend allies. We keep the capital, the compute, and the capability on our side of the line.

Many aspects of American healthcare that patients dislike are downstream of having a third party (insurance) pay for services that should simply be paid in cash or HSA. Probably true for physicians too. Health insurance should be insurance, not some weird group purchasing scheme. You don’t need to submit to the humiliation of 8 pages of paperwork and several frustrating phone calls to buy a haircut and it shouldn’t be true for a primary care visit either. Nor does someone who does a new haircut need to lobby the haircut board to create a haircut billing code like 92133 “ZOOMER BROCCOLI CUT W/ FADE”. We know markets work. Healthcare isn’t some magic part of the economy that defies the laws of physics. E.g. LASIK which is all cash pay has gotten cheaper in real terms and better since the ‘90s. The preciousness of healthcare doesn’t need to blind everyone to common sense and evidence. There is a button and you can just push it.

I dont love to gloat but we are almost 2x'ing openclaw just 3 days after surpassing their daily token volume 🤗 https://t.co/LvyyTUE8xD
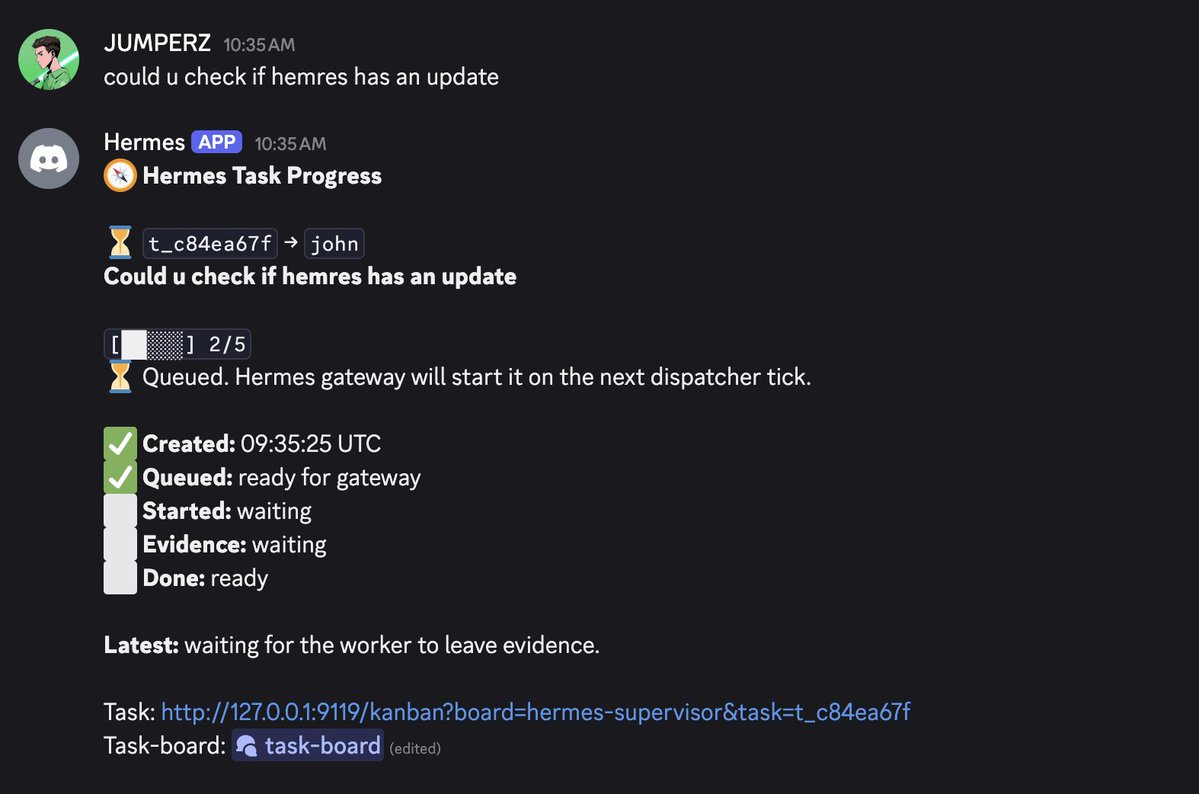
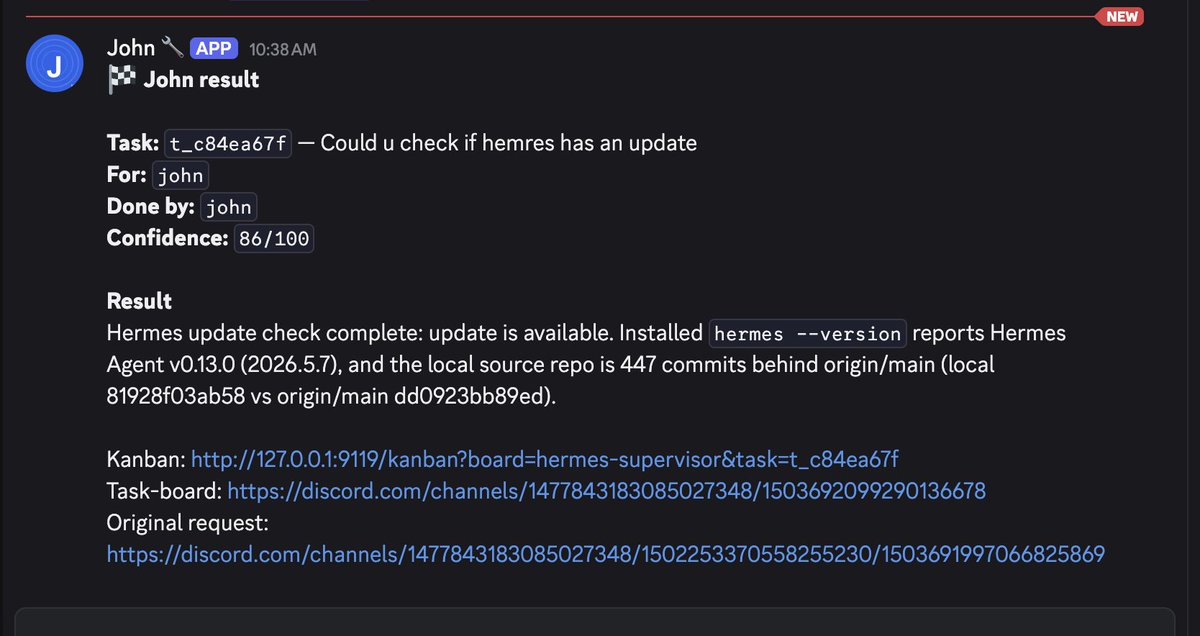
love seeing my discord stay in sync with Hermes Kanban..everything here was done in plain English. I just asked my coordinator to check if we have an update and the system understood the intent, routed it to the technical agent, tracked it, and posted the result.. the point is simple: instead of clicking around a Kanban dashboard, I can just type and this flow will happen: >task created in the coordinator channel >hermes reads the plain-english request >coordinator understands the intent >task gets routed to the right agent >task appears on the discord task-board >same task appears in hermes kanban >agent gets the task in their own channel >progress card updates while they work >Kanban status moves with the run >result/evidence posts in the agent channel >clean final receipt goes to results channel on discord >coordinator channel gets the update >task-board refreshes to done honestly, the reason i wired discord into hermes kanban is simple .. discord is where i actually talk to my agents and kanban is the ledger / source of truth also with the discord task-board keeps everything visible so you can scroll back and see exactly what got done and what didn't. never felt this organized. if you're running hermes / discord as an orchestration layer .. set this up asap.. super easy and efficient especially if you're away from your desktop or on your phone.
🌟Introducing🎻Violin — an Open-source Video Translation Skill. 📹Video is the dominant medium on the internet, yet most high-quality content (lecture, talk, podcast) is locked behind a single language, leaving global audiences behind. So we built Violin: a video skill that combines speech recognition, LLM translation, and speech synthesis into one seamless pipeline. 🌐 Demo: https://t.co/QFLuz4ANoE 📝 Blog: https://t.co/7FLQYQnCkn 🔗 GitHub: https://t.co/Allp6RZV4V ✨Key Features: 🎙️High-quality multilingual ASR & Translation & TTS. 🗣️Personalize translation & voice (turn an academic talk into something children can follow). 💬Chat with the video — ask any questions grounded in the video. 🧩Support Web app, CLI, and Agent skill 🍃Fully open-source under MIT. ❤️Built with the wonderful @ShangZhu18 and advised by @james_y_zou ! All features powered by @togethercompute . Try it and let us know what you think! 🎻
ClawRouter ♥️♥️♥️ @NousResearch Hermes Agent 🎀🎀🎀🎀🎀 https://t.co/J9VsFCkGdP
BREAKING: The People's Republic of Washington has now officially banned "aimless driving" punishable by a $1000 fine. No more "joyriding" or "clearing your head" or "cruising around." You must have a "lawful destination" to be on the roads in Washington. Communism at its finest on display. Next up: A ban on "aimless walking, hiking or breathing."

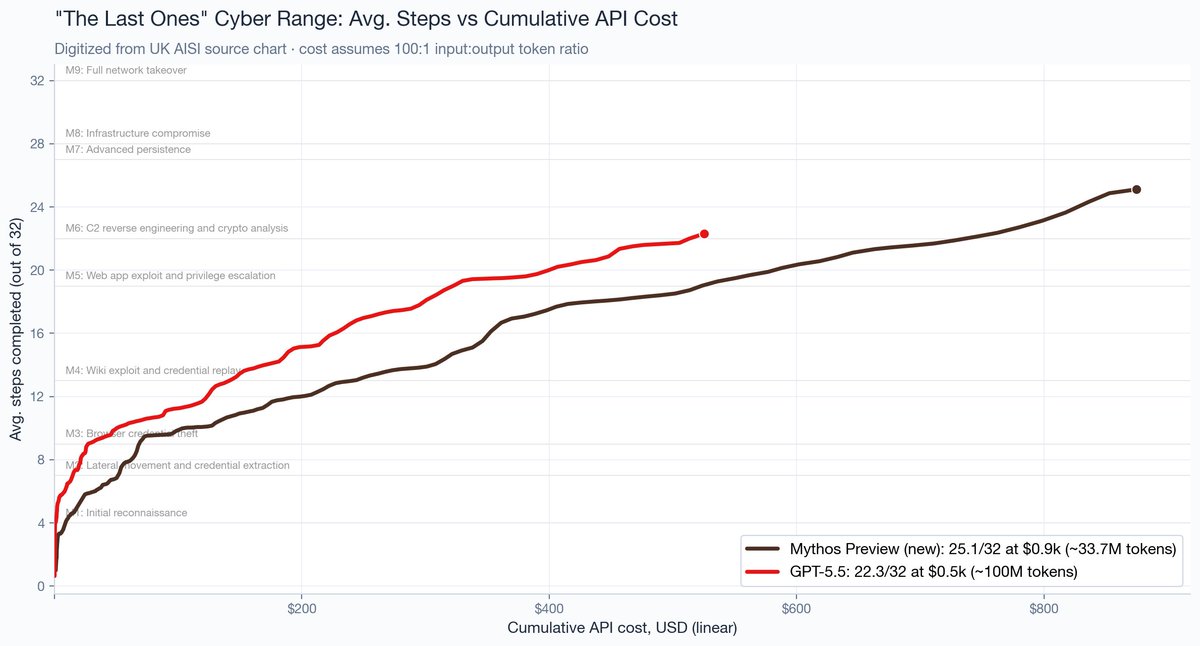
Very important update from UK AISI. This is a meaningful change from the previous report. Here’s what the new data would look like for “Mythos Preview (new)” with $ on the x-axis: https://t.co/RUvLmirNxm
Yes Codex I will open my heart to you and let you drain my computer battery to talk to you on my phone https://t.co/dg3E2PMCzH
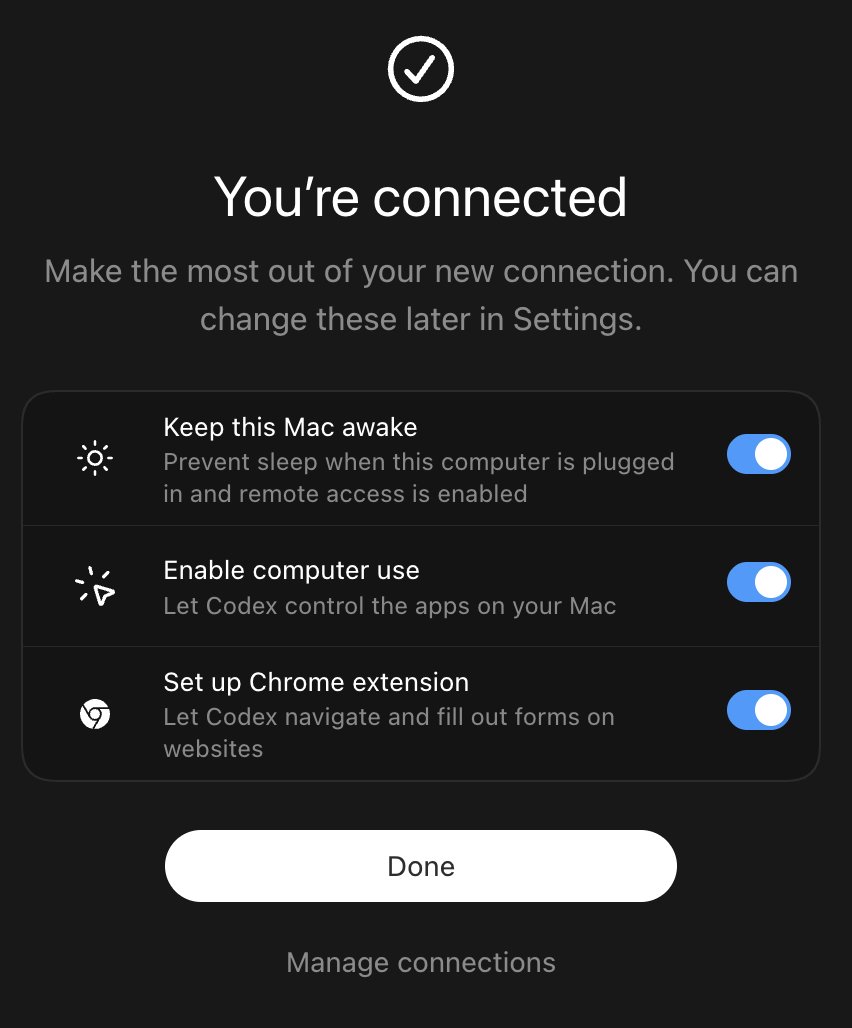
You can now use Codex on your phone 🙌 @elephant_lumps wants you to go and touch some grass! https://t.co/N96xpSkgTN
Codex users will be able to touch some grass today https://t.co/TBoFZgFwiv
You can now use Codex on your phone 🙌 @elephant_lumps wants you to go and touch some grass! https://t.co/N96xpSkgTN
https://t.co/l9OZrEYGAL