Your curated collection of saved posts and media
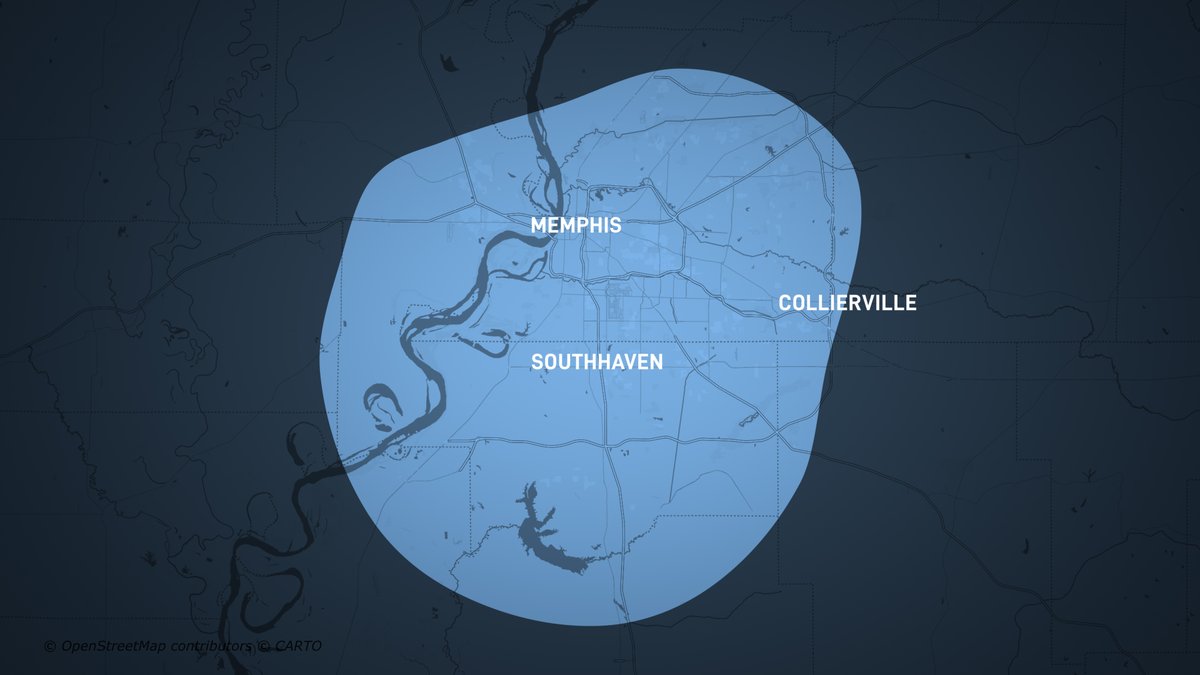
SpaceXAI has announced that they will be applying a 50% discount on the standard @Starlink monthly price for both new and existing customers in the Memphis area as a way to give back to the community where they operate their Colossus data centers. • No upfront hardware costs on Residential Starlink kits for new customers • The discount applies to Starlink service addresses located in eligible parts of the Memphis area (see below). • No action is required. The discount will appear on your next bill and will continue as long as your service address remains in the eligible area. • Friends and family nearby can also benefit from the discount. You both earn a month of free service through Starlink's referral program.
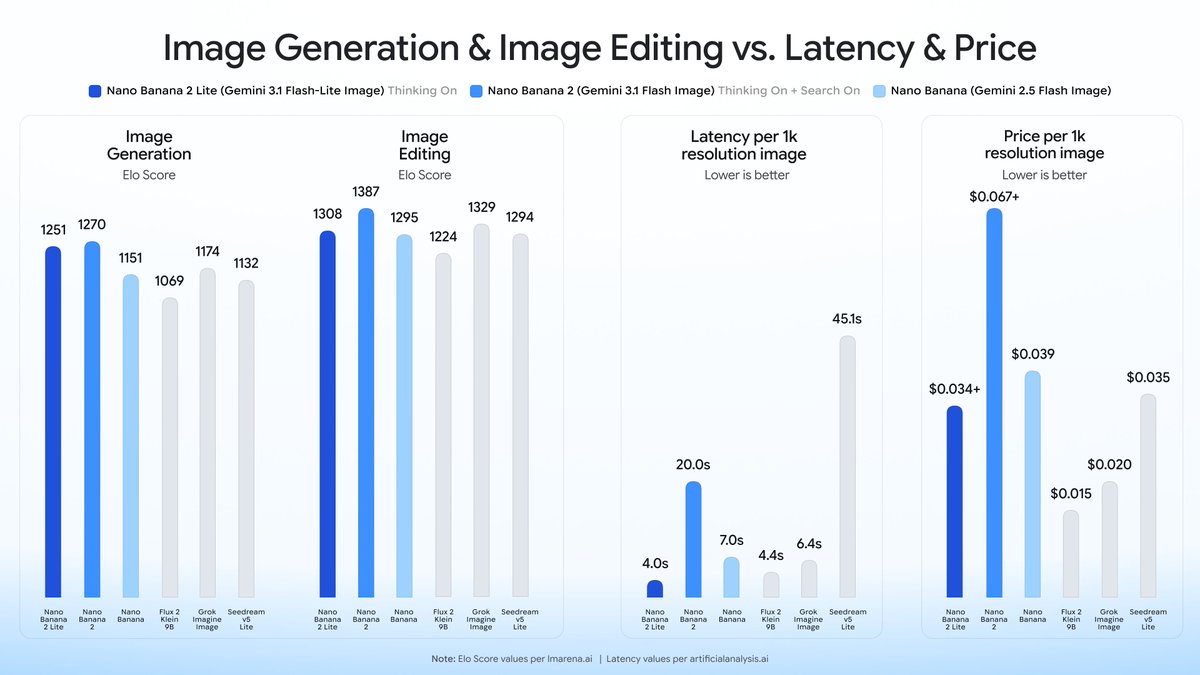
We’re shipping two major updates to streamline your creative workflow, allowing you to generate high-speed images with one model and then instantly animate them with the other—all at a fraction of the cost 🍌⚡️ 1️⃣ Introducing Nano Banana 2 Lite: Our fastest and most cost-efficient Gemini Image model yet delivers text-to-image outputs in under 4 seconds. Now available via the Gemini API and Google AI Studio, and rolling out soon across @NotebookLM, @FlowbyGoogle, @geminiapp, @stitchbygoogle, Google Search and @GooglePhotos. 2️⃣ Gemini Omni Flash in Public Preview: Our natively multimodal model for cost-efficient video generation and conversational editing. Now available via the Gemini API, @googleaistudio, and Gemini Enterprise Agent Platform so you can integrate the model into your workflow. While exciting on their own, the real magic happens when you build using these models together. Watch how our interior design demo integrates Nano Banana 2 Lite and Omni to instantly reimagine any space. Upload a photo, swipe through tailored design concepts, and see Omni bring the details to life in cinematic motion. Try out the demo app in AI Studio: https://t.co/EjYC2oHIDG
Explore ideas, scale visual concepts, and start creating: https://t.co/JbyK5FM3H0 https://t.co/wBMBDw6TC6
We just made it a lot easier for AI agents to work with your documents. LlamaParse MCP now does more than parse or classify files: it can pull structured data out of contracts, invoices, and reports automatically, and give agents direct access to your knowledge base (PDFs, Office docs, images, and more) so they can search, read, and retrieve information just like a human would. We also reorganized everything into focused, purpose-built tools: whether you're classifying documents, extracting data, or building search over your company's files, agents can do it faster, more reliably, and in parallel. This allows for smarter, more capable AI workflows for anyone working with documents at scale. Curious to try it out? Get started now with the LlamaParse Platform → https://t.co/lCJGHx7lOG Blog post: https://t.co/KxvkcZYq2w Take a look at the GitHub repository → https://t.co/VhiG2bKAqe
AI Videos are ALL slop. AI should be making you a content machine. Introducing Riverside 2.0, the first AI Producer that creates authentic content while you sleep: https://t.co/qnBHEorlAS
Think that Google Meet is good enough for making videos? So did I. But when @NadavKeyson, CEO of @RiversidedotFM, asked me to help him reveal its 2.0 features today with an interview I tried it out and, wow. Huge difference, no? You can compare to using Google Meet by looking at any of my other videos on my highlights tab here on X. This is a master class in improving your videos and Nadav talks about the new 2.0 features. Riverside 2.0 opens with five releases, with more arriving over the following weeks: ● A fully rebuilt platform. A new recording studio and AI editor, faster and more responsive across the board, giving creators more flexibility and control over how they make content. ● Newsletters. Turn any recording into a newsletter automatically, hosted on a page where an audience can subscribe to future editions. ● Social scheduling. Plan and post to every channel directly from Riverside, with no downloading, reuploading, or separate social tool required. ● In-person multicam recording. Record multiple cameras and microphones on separate, synced tracks through Riverside's Mac app, capturing everyone in the room, with or without remote guests. ● MCP integration - coming soon: Connect AI assistants like Claude and ChatGPT to Riverside to work directly on your content. Try it yourself: https://t.co/qKCl1aR0Gx Code: robertscoble (30 days of Riverside Pro, free). I'll be switching all my interviews to Riverside. More on 2.0 from Nadav himself: https://t.co/6cSkOmaDRy

@NadavKeyson Thanks for coming on my show to show me just how much better than Google Meet it is. Wow. https://t.co/VUWqDfmAWN
Think that Google Meet is good enough for making videos? So did I. But when @NadavKeyson, CEO of @RiversidedotFM, asked me to help him reveal its 2.0 features today with an interview I tried it out and, wow. Huge difference, no? You can compare to using Google Meet by looking

Introducing Nano Banana 2 Lite 🍌 and Gemini Omni Flash 🔮, our new generative media models in the Gemini API and AI Studio! Nano Banana 2 Lite is extremely fast (<4s image) & cheap ($0.034 / 1K image). Omni Flash is SOTA at video editing at $0.10 / sec, same as Veo 3.1 Fast! https://t.co/qDxRpqpX5E
Ornith-1.0-35B is now available in claude code through hf-claude https://t.co/U8Tg0agOV2

https://t.co/rfQOK0muLR

OSWorld2.0 Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks https://t.co/VaQESvOpms
paper: https://t.co/DxFLissPi9

PEOPLE ARE BLAMING ELON MUSK FOR “DEATHS” FROM USAID CUTS — BUT THE DATA AND REALITY SAY OTHERWISE Opponents are loudly claiming that cutting wasteful USAID spending is killing people in poor countries. Here’s what’s actually happening: • No evidence of mass deaths — Preliminary 2025 mortality data from several African countries shows no increase in deaths after major USAID cuts. In some places, deaths even decreased. • USAID had serious problems — Widespread waste, fraud, and misuse of taxpayer money. Multiple USAID officials have been charged with stealing funds and pled guilty. Programs included bizarre spending like drag shows in Ecuador, pushing certain ideologies abroad, and even influencing foreign elections. • Good parts were preserved — Effective humanitarian aid was transferred to the State Department. Only the wasteful, fraudulent, or politically weaponized portions were cut. • Fearmongering with models — Claims of “millions dying” come from projections and assumptions, not actual body counts. No one can name specific victims caused by the cuts.
Deaths in Africa DECREASED after USAID funding was cut, because they’re no longer able to push for violent revolution to install leftist regimes!

It sounds crazy, But it actually seems True! https://t.co/vUQA744dP9
@elonmusk USAID ran a secret fake Twitter to spark revolution in Cuba. Funded Venezuelan opposition politicians directly. Got expelled from Bolivia after WikiLeaks cables revealed the ambassador admitted aid was "hidden by our use of third parties." All documented. All sourced. This isn't conspiracy, it's declassified.

A theory I'm testing out about AI, work, and the future of companies ... I have for months been obsessed with Alfred Chandler's The Visible Hand, a classic business-history book that argues that 19th century technology—the telegraph, train—created an explosion of real-time sales and inventory-information challenges, which required the creation of a new org charts with something called "middle managers." Thus, technology birthed managerial capitalism. Thematically, Chandler's insight is that technology doesn't just change jobs; it changes how jobs are organized in relation to each other; which is to say, tech changes how companies are structured. So, how might AI restructure the firm? Here's one stab at an answer: The telegraph/train created a profusion of information, which required managers. But AI's greatest skill is synthesizing information that's already been created. I think that's one reason why new companies are getting rich faster with unusually small staff. The "visible hand" of professional managers is being replaced, at the margin, by the "invisible hands" of digital platforms and AI assistants that don't so much destroy work as they allow new firms to build lean human-AI workflows that are qualitatively different than the larger bureaucracies in their industries.

1/ I'm a venture capitalist, and I'm telling you to root for the crash that torches my own asset class. Everyone fears the AI bubble popping. Here's the argument almost no one will say out loud: the crash is the best thing to happens to this technology. https://t.co/syam7EjyJI

Perplexity Computer now has private company financial data, sourced via Forge Global. Includes fundraising history & implied valuation, secondary pricing, public marks, and company profile. We're pleased to partner with @Forge_Global to bring this data to all Computer users, with no setup or Forge subscription required.
@NousResearch If you haven’t tried Hermes Agent yet, check it out and get started here: https://t.co/zljdejnZAa

Hermes Agent now reads the web up to 60x faster and 49x cheaper. Scraping backends pass clean content straight to the agent without redundant processing steps; large pages are saved locally and paged on demand so you get the same quality at a fraction of the time and cost. https://t.co/EwJThNmCXE
@Eashwarramesh @NousResearch Bear way is the release notes on every major version release on it GitHub https://t.co/JrXwTUz7e3
What if you hired an AI employee instead of a software tool? Viktor sits inside Slack and Microsoft Teams as a hire… not a product. It remembers what it worked on yesterday and flags the one thing that needs your yes or no before you ask. It comes to me when something needs my decision. Companies are already spending real money for this kind of permanent capacity. $20M annualized revenue run rate because Viktor adds headcount level work teams were never going to hire for anyway. The best parts: no onboarding, never logs off, runs directly in the tools we use every day. @viktor__com $20M annualized revenue run rate shows companies are already betting on permanent AI capacity as headcount-level hires rather than tools. That shift from features to workforce is exactly the story I cover at AlignedNews
Get started with Viktor free. $100 in credits, no card: https://t.co/LUug9RHO5T

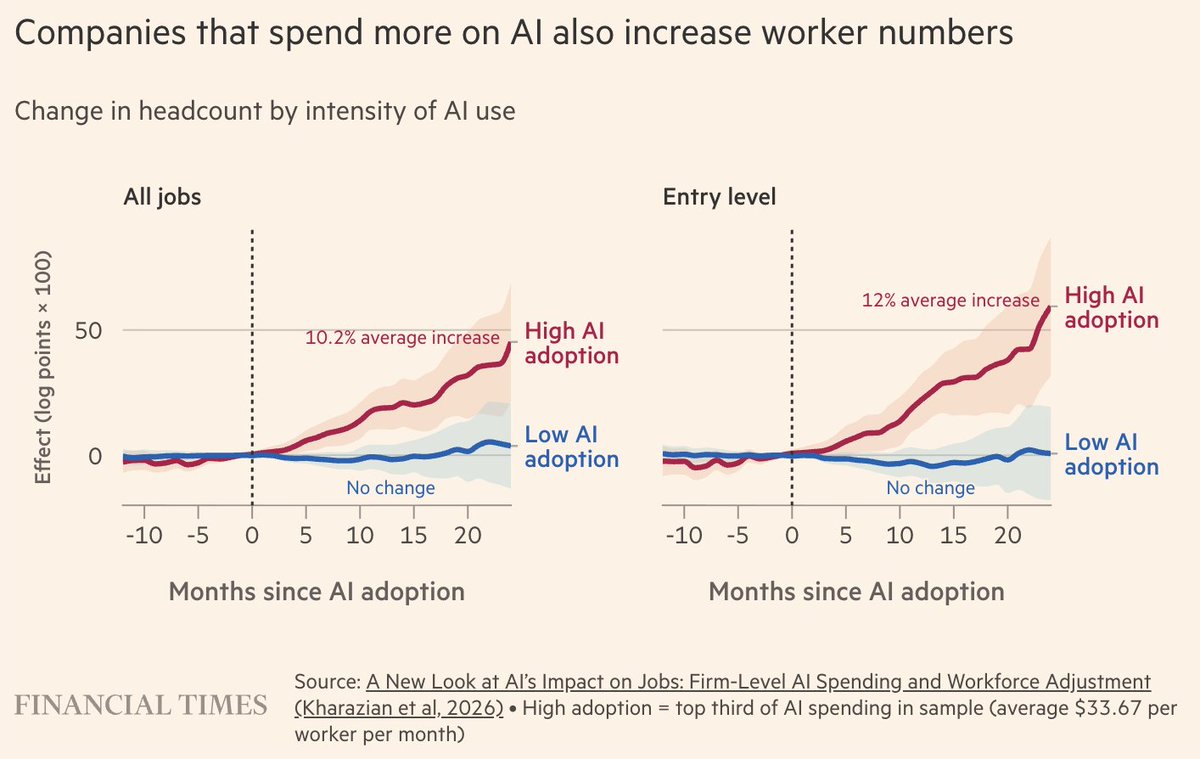
We can finally say AI isn't killing jobs. A new paper from me, @tryramp, and @RevelioLabs uses firm-level spend and workforce data across 21K U.S. businesses to measure AI's impact on jobs. Firms that adopt AI heavily grow headcount 10% over two years following adoption. Low adopters see no statistically significant change.
For our free newsletter this week, we write about how the AI productivity boom Is becoming an AI training problem. @IrenaCronin and I write this newsletter every week. AI will not transform work just because companies buy the tools. The real productivity gains come when people know how to use AI well, trust the data behind it, follow clear rules, and fit it into the way work actually gets done. AI is powerful, but training is what turns it into business value. Read and subscribe at https://t.co/HHwYy7NoAl

Meituan, basically China’s DoorDash, trained a 1.6T parameter LLM on 50K Chinese chips. It reminds me of Jensen Huang’s point on the Dwarkesh podcast: export controls on Nvidia GPUs won’t stop China. They’ll just accelerate the development of AI that runs on Chinese chips. https://t.co/8zstm1hCa2

I have been watching us type around the same screen for years without moving forward. Acti flips that script. You type what you want in any app, hold your spacebar, and it pulls the data or triggers the action immediately. No tab hopping, no dead ends. What stands out is how it treats the keyboard as a command layer rather than just a typewriter. Worth keeping on your radar: @openacti1 https://t.co/YrZgCZ0i2I . More interface shifts like this are exactly what https://t.co/XkU8fN0T8Q covers
The last major keyboard moment was in 2007, when Apple put the keyboard on glass. Nearly 20 years later, we're introducing: Acti @openacti1, the Agentic Keyboard. Not another AI keyboard that fixes grammar. Not another voice keyboard that types faster. An invisible agent in ev


We're coming out of stealth. We've built our first racks after a successful A0 tapeout, $1B+ in customer contracts, and $800m raised. Early customer tests show us achieving SOTA throughput, latency, and power efficiency on inference workloads. Our first racks ship this summer. https://t.co/FLccrkLTza

Pro-tip: use a token budget when using /goal in the Codex CLI This is an experimental feature we're exploring, you might have to enable the flag. Ask Codex to do it for you. https://t.co/S70FxiUuG8