Your curated collection of saved posts and media
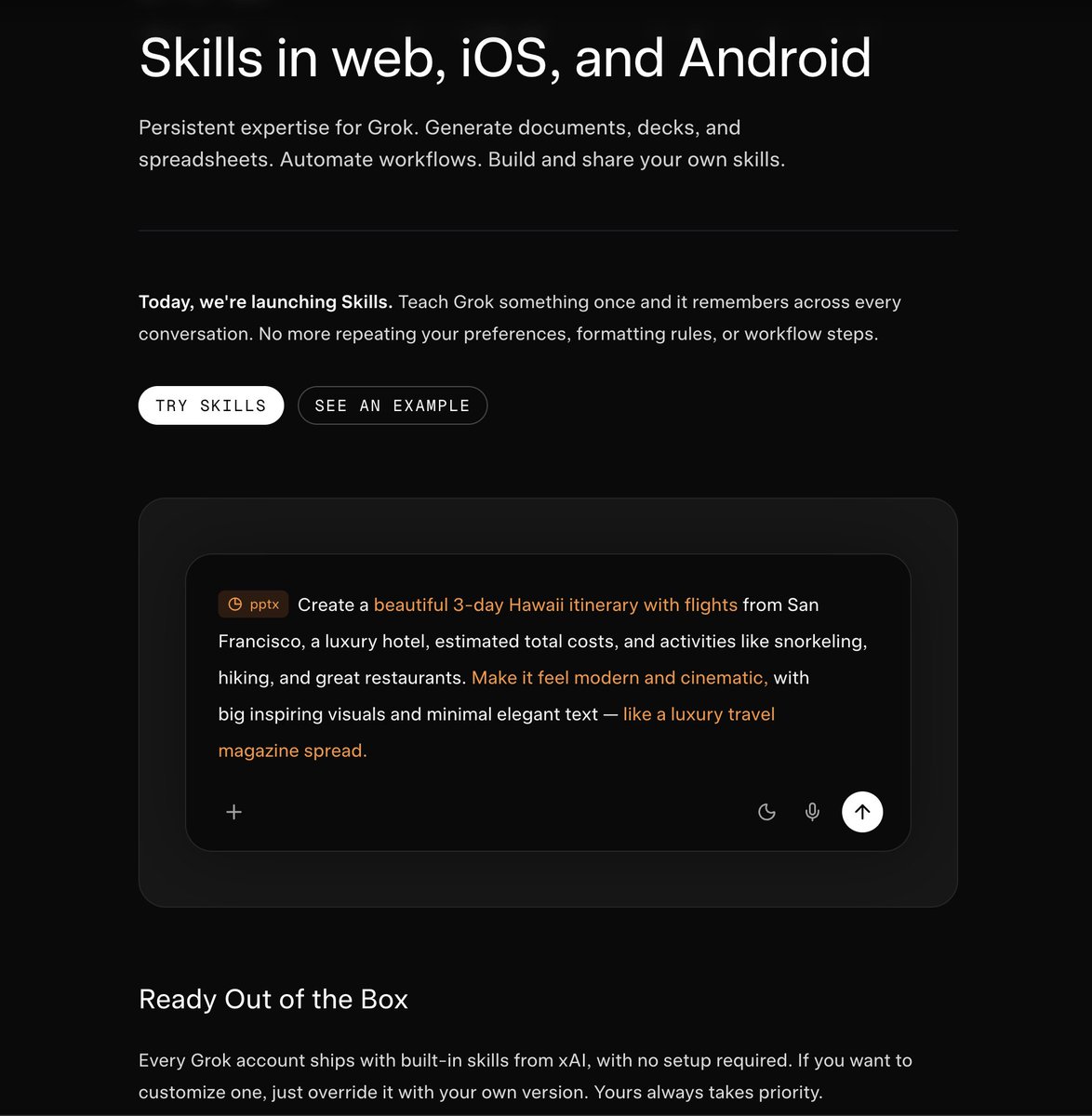
xAI has Released a blog on Skills https://t.co/WyZsvXUYw0
@mjwoo94 @Carles_Reina @Chris_Orlob @austinh___ @akshat_b @karpathy @AndrewYNg @DrJimFan @lilianweng Yes. The best are on this list: https://t.co/wAjs9SAZfe And this site watches 50,000 here on X and picks the best: https://t.co/kiuZ7QXLzb And all 50,000 in the community are on these lists: https://t.co/fasUz7PuHq

I broke my own rule to never post about AI detection as it is fraught in many ways. The problem is that if you use AI a lot, you know AI writing on sight, which makes the difficulty of objectively proving that AI use to others very frustrating https://t.co/YzjUfaAkjJ

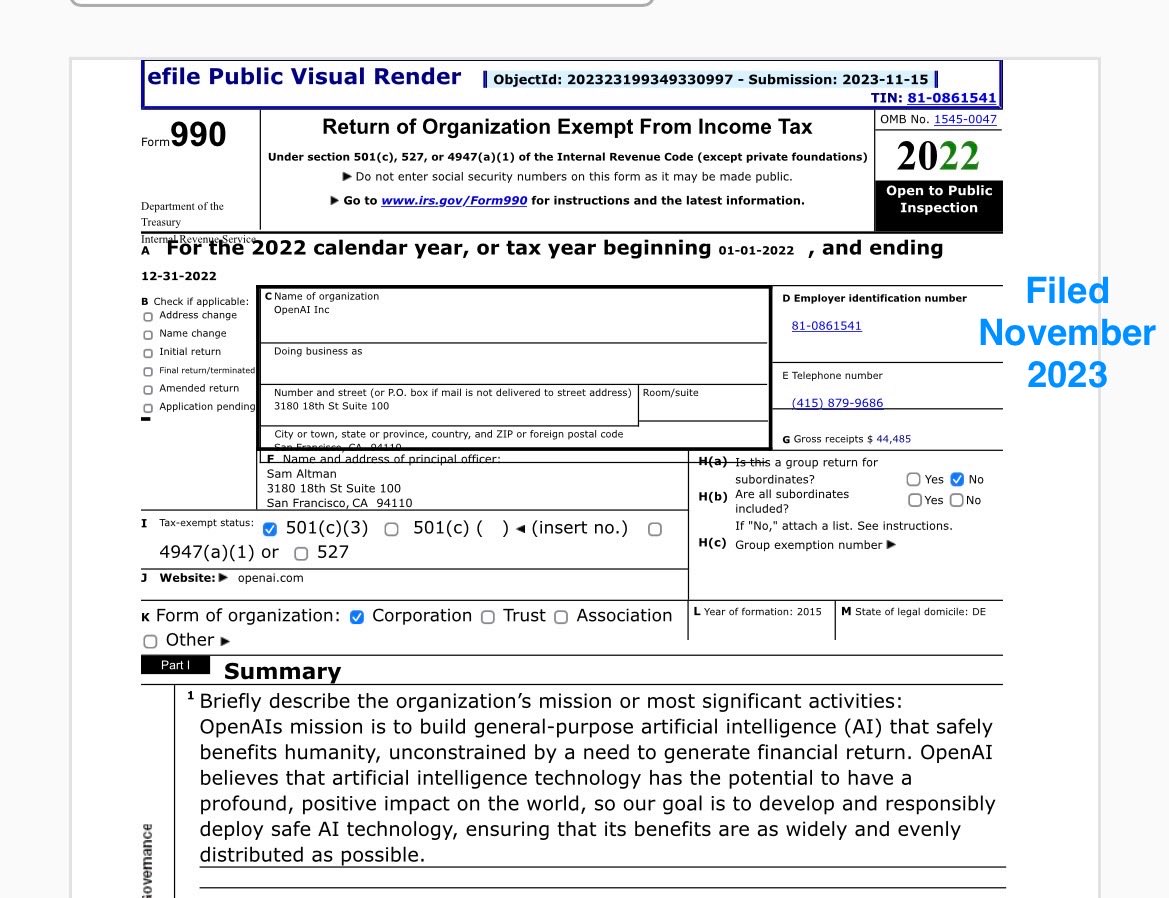
Judge Yvonne Gonzalez Rogers basically waved off Elon’s OpenAI appeal, saying the jury’s statute of limitations ruling is tough to overturn. An activist judge letting Sam Altman skate after he hijacked a nonprofit charity — originally pledged to benefit all humanity — and turned it into his $150B+ personal for-profit empire? That’s not justice. Stealing a charity for profit is not OK. You don’t get to rewrite the mission, pocket the upside, and hide behind “time limits” while betraying the public trust. OpenAI’s founding promise was destroyed in broad daylight. This makes zero sense.
This illustrates why the ruling by the terrible activist Oakland judge, who simply used the jury as a fig leaf, creates such a terrible precedent. She just handed out a free license to loot charities if you can keep the looting quiet for a few years!

What day is today? Pets on terminal day! 🐾🐕🐇 https://t.co/Vzw4eijYqy
What day is today? Pets on terminal day! 🐾🐕🐇 https://t.co/Vzw4eijYqy
The long journey of rock in Nashville https://t.co/4VtIirZNrS
yeah that's pretty good xAI might be able to cook with Cursor data + 10T model https://t.co/73fwMkygwd
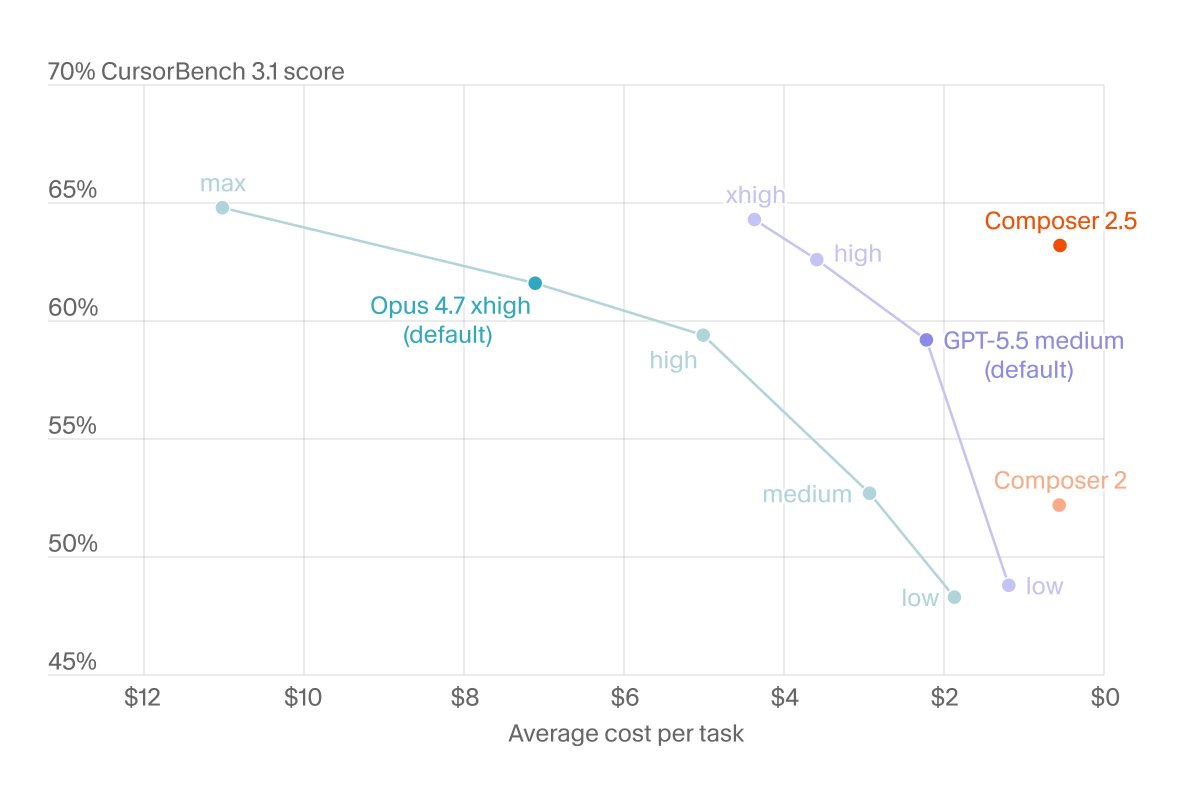
Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model. https://t.co/N87ojcXlOC
UK primary schools are teaching 7-year-olds they’re born with “white privilege.” Indoctrinating infants with race guilt is pure child abuse dressed as “anti-racism.” Britain is lost. https://t.co/V4nKEDikiH

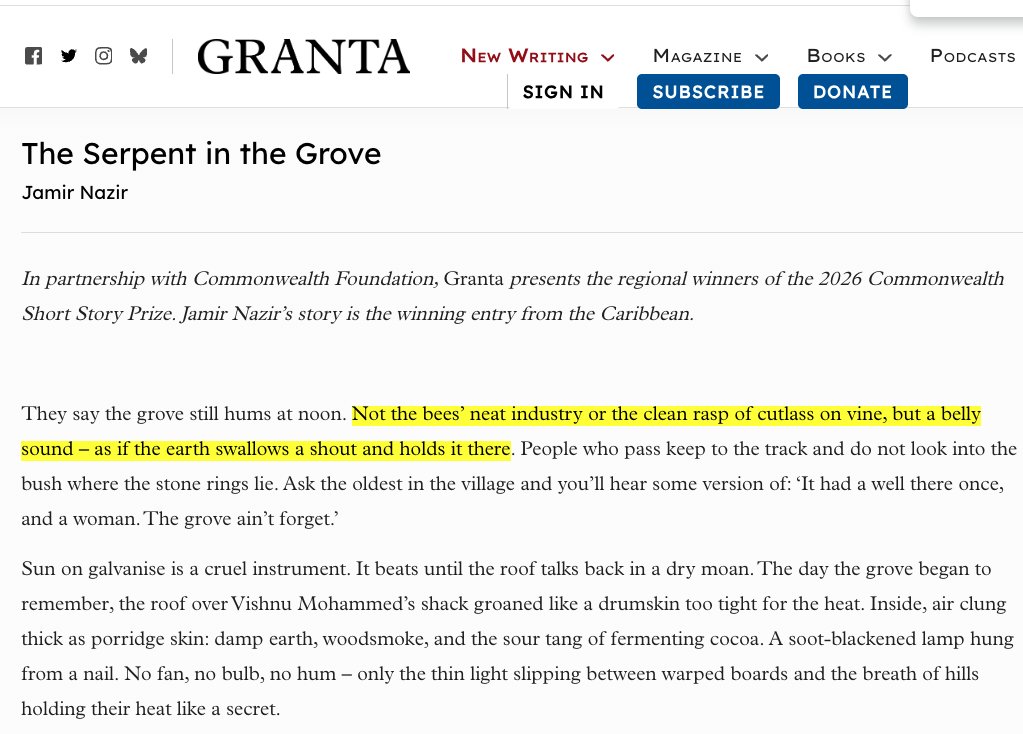
Literary journals are now publishing, and awarding prizes to, AI written stories. Surprised this made it into Granta! https://t.co/qpqnBqew8K
‘The Serpent in the Grove’ by Jamir Nazir is a story set in rural Trinidad about a struggling farmer, a silenced young wife and a grove that seems to remember what others try to bury. Awarded the Caribbean regional winner title for its lyrical precision and haunting atmosphere,
Lukas Biewald (@l2k) built Weights & Biases into the system of record for AI model training at OpenAI, Meta, NVIDIA, and 30+ other foundation model builders. He also built it on ClickHouse. Now SVP of AI at CoreWeave, Lukas is joining us at Open House for a conversation on ecosystem and technology trends. Register free: https://t.co/zi3pfySY0v

These kids are serial criminals with a callous disregard for life. If they are ever released from jail they will surely harm again. Austin PD, Travis Co. Sheriff Office & Manor PD did their job. Texas Dept. of Public Safety aided them. The DA & Court must do their job and keep these criminals behind bars. https://t.co/O13i27f5Yd

Launching Mentra Live open-source smart glasses. Deploy smart glasses for real world work. We already shipped thousands. Now, they're generally available. Build apps that leave the screen. Let your AI step into the real world. https://t.co/GeVPhVEFkf
The acclaimed psychologist Abraham Maslow, burn this into your brain https://t.co/75VJfRGZyu

The acclaimed psychologist Abraham Maslow, burn this into your brain https://t.co/75VJfRGZyu

the AI trial of the century ended with a procedural whimper rather a bang; the jury agreed that Musk was too late but never weighed in on the questions of whether OpenAI did was legitimate. and so we will never know what the world might be like had OpenAI been forced to fully follow its original mission (as reprinted below).
Breaking News: A jury rejected Elon Musk’s lawsuit accusing OpenAI of putting commercial gain over the public good. Jurors decided his claims were barred by the statute of limitations. https://t.co/nCmEsYax4W
I believe on-prem and local AI - based on @huggingface open-source models - will be an important answer to the GPU shortages this year (because they are cheaper, faster, safer than cloud APIs)! Great collaboration between @huggingface & @MichaelDell @Dell to make this a reality for enterprise today. Announced at the main keynote of Dell Technologies World.
"We give you model choice, without infrastructure chaos" — @MichaelDell, live from #DellTechWorld 🎤 Kimi K2.6, DeepSeek V4 Pro, GLM 5.1, MiniMax M2.7 & DeepSeek V4 Flash are now one click away on Dell Enterprise Hub, optimized for PowerEdge XE9780 with NVIDIA B300. https://t.co/ovygIMPcZ4
Reachy Mini is Assembled and Ready Shout out to @huggingface and @pollenrobotics #reachymini #Ai https://t.co/s012EE7Jul
Reachy mini rap battle at @aiDotEngineer Singapore! https://t.co/vic68kneyL
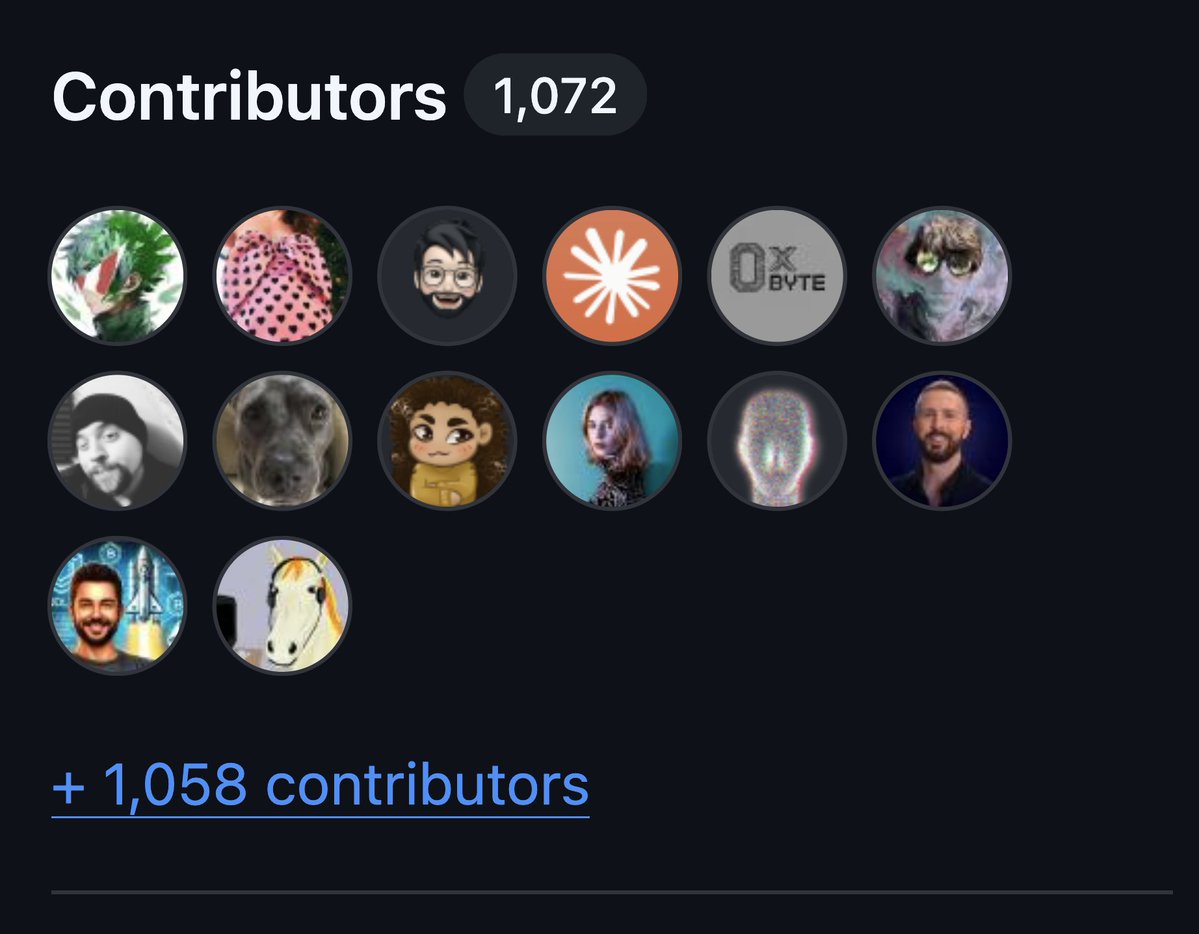
We have hit 1000 contributors on the repo, a nice milestone to start out the week. Thank you to all of the contributors who make the Hermes Agent magic possible! https://t.co/Agxke7vfOQ
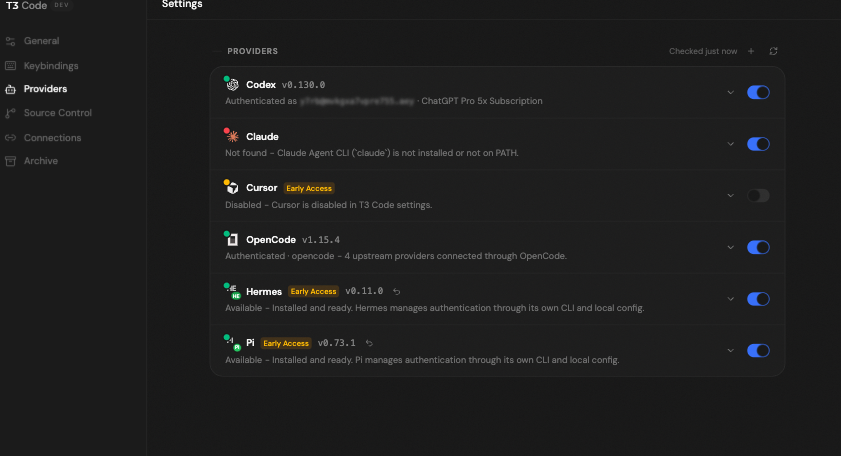
now I have both Pi and Hermes working in t3code. you can follow my fork here. https://t.co/l9YjwlYP4S https://t.co/upiyV971yg
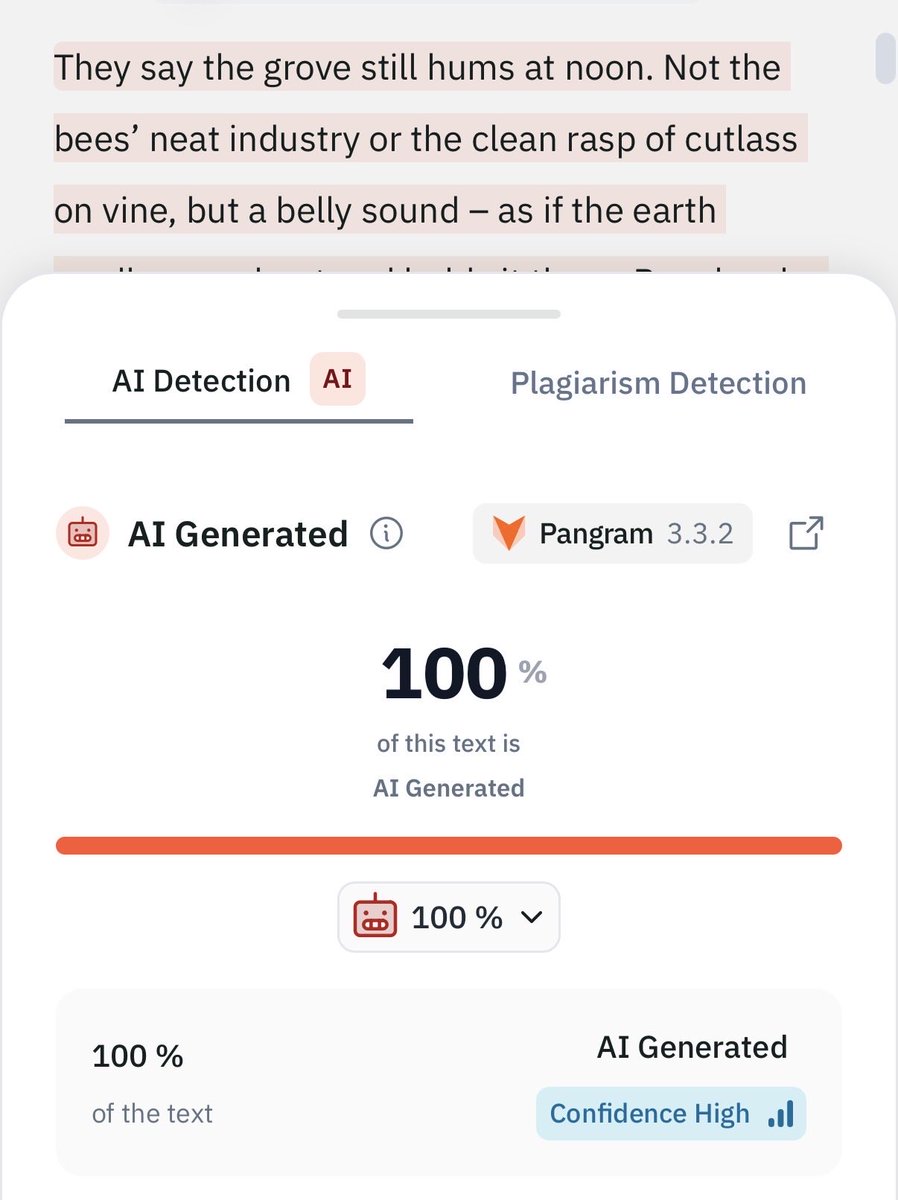
Well, this is a first: a ChatGPT-generated story won a prestigious literary prize (The Commonwealth Prize). "Not X, not Y, but Z" sentences everywhere, the "hums" trope, and plenty of other obvious markers of AI writing. A major milestone for AI, at any rate... @GrantaMag https://t.co/U6jWejprFv
vLLM and PyTorch worked together to fix a long-standing aarch64 install headache — as of PyTorch 2.11.0, pip install torch on GB200 / GB300 / GH200 just works. 🎉 What changed: PyTorch 2.11.0 now publishes CUDA-enabled aarch64 wheels to the default PyPI index. No more custom --index-url flags. No more transitive dependencies silently swapping your GPU build for the CPU wheel. New users on Grace Hopper and Grace Blackwell systems can follow the standard install instructions and have vLLM work the first time. In our latest blog, @KaichaoYou (co-founder @inferact, Lead Maintainer @vllm_project) shares the full story: 🐛 A 2024 hackathon bug bringing up vLLM on GH200 🔧 vLLM's in-tree workarounds (use_existing_torch.py and [tool.uv] build-isolation passthrough) 🤝 From GitHub issue to PyTorch Foundation TAC discussion 🚀 The fix landing in PyTorch 2.11.0, driven by NVIDIA and PyTorch core. A great example of cross-project collaboration under the PyTorch Foundation umbrella — and a reminder that boring infrastructure wins compound. Read the full story: https://t.co/JGnJ1X7sxl ✍️ : Piotr Bialecki (@nvidia) — @ptrblck_de, Alban Desmaison (@Meta), Andrey Talman (@Meta), Nikita Shulga (@Meta)
NEW paper from Meta. (bookmark it) It's an agent system that autonomously discovers neural architectures that beat Llama 3.2 at 350M, 1B, and 3B scales, all under a 24-hour compute budget. They get this work by splitting the search into two agents: > AIRA-Compose searches the macro architecture. > AIRA-Design implements the low-level mechanisms. For devs: If one agent in your stack is doing both strategy and implementation, split it. Run a planner that picks the structure and an implementer that fills in the mechanisms. AIRA shows this beats a single end-to-end agent on a real, non-toy search problem. The same split is useful for pipeline assembly, query planning, prompt scaffolding, and tool-use programs. Paper: https://t.co/CYALI6CFjJ Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

Reachy mini rap battle at @aiDotEngineer Singapore! https://t.co/vic68kneyL
Reachy mini rap battle at @aiDotEngineer Singapore! https://t.co/vic68kneyL
you can just do things at ai engineer singapore @aiDotEngineer https://t.co/zxr6LiDjJ5
Singapore’s Foreign Minister, Dr Balakrishnan casually explaining how he built his own AI agent (a 2nd brain for diplomacy) using Claude & WhatsApp integration etc. on a Raspberry Pi “You cannot govern a technology you have only been briefed on.” 🇸🇬 https://t.co/JMk0t2FrJr

you can just do things at ai engineer singapore @aiDotEngineer https://t.co/zxr6LiDjJ5
