Your curated collection of saved posts and media
1/ You can shrink a language model's KV cache by 200×, in a single forward pass, and it still answers correctly. At 256k context that's 36 GiB of cache down to ~360 MiB, with no change to the base model. Here's how we did it 👇 https://t.co/He1ucvxGyf
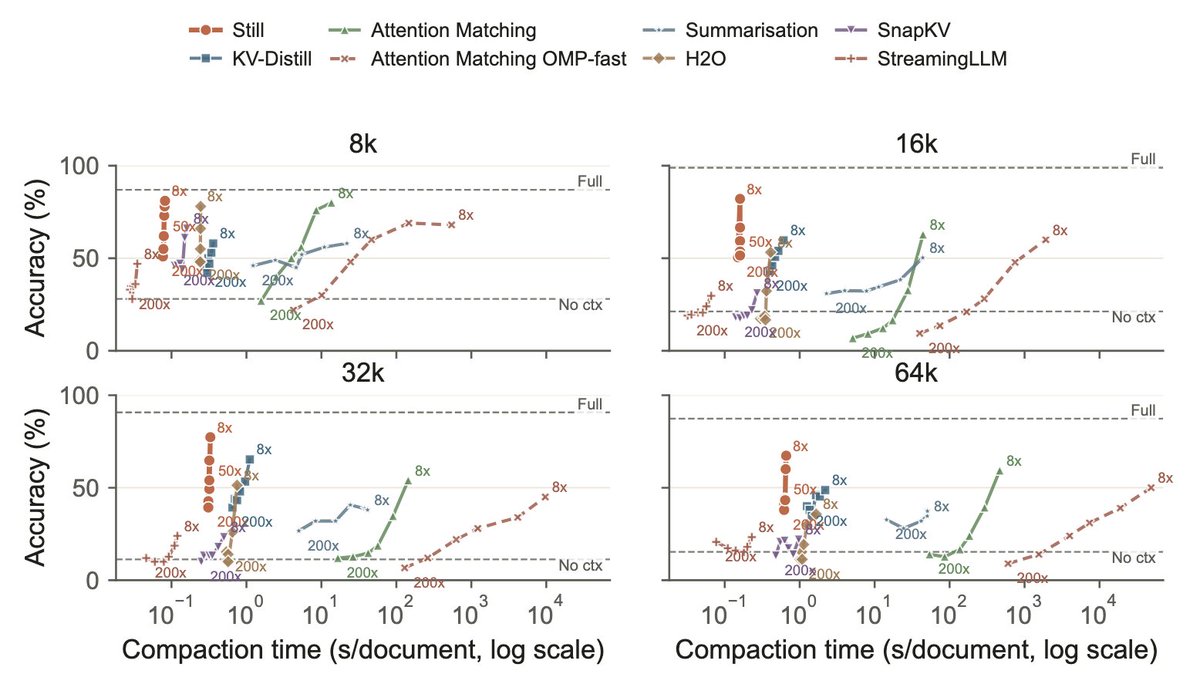
https://t.co/UbfAH0cBzm

Now you can monitor what your @openclaw is up to in realtime on your lock screen. We built a way to stream OpenClaw’s… - Thinking - Tool calls - Price & Token use Available to try on GitHub 👇 https://t.co/uJgSDwWKgK
https://t.co/Drl94NfDOR

@The_Infinitian @aaronabentheuer @sharanjhangiani Thanks for keeping us honest. We optimized the demo to fit into a shorter video. Here’s a better representation of the calls it shows inbetween. https://t.co/oQErlYuleV
@openclaw We recently got OpenClaw to stream its thinking to the lock screen. Would love to contribute to the app! https://t.co/K8hzhlNyEz
@_loganlee Using Mac Mini to a custom iOS app via Tailscale - helps me monitor its tool calls using live activity on the local screen. https://t.co/DTETKgYDCS
@openclaw https://t.co/Drl94NfDOR

@JulianGoldieSEO We recently got OpenClaw to stream its thinking to the lock screen. Open-sourced if you want to try! https://t.co/ckgv6hHk8F
Tuesday afternoon micro-interactions with Claude. https://t.co/DzY8qe05vs
Looking forward to our TechAide AI Conference today, during which we're raising funds to fight poverty and social exclusion in Montreal. If you'd like to contribute, you can make a donation here: https://t.co/cMOCWblnhI Any amount is greatly appreciate!!

I appreciated this BlueSky comment. https://t.co/sGRFMohJ4S

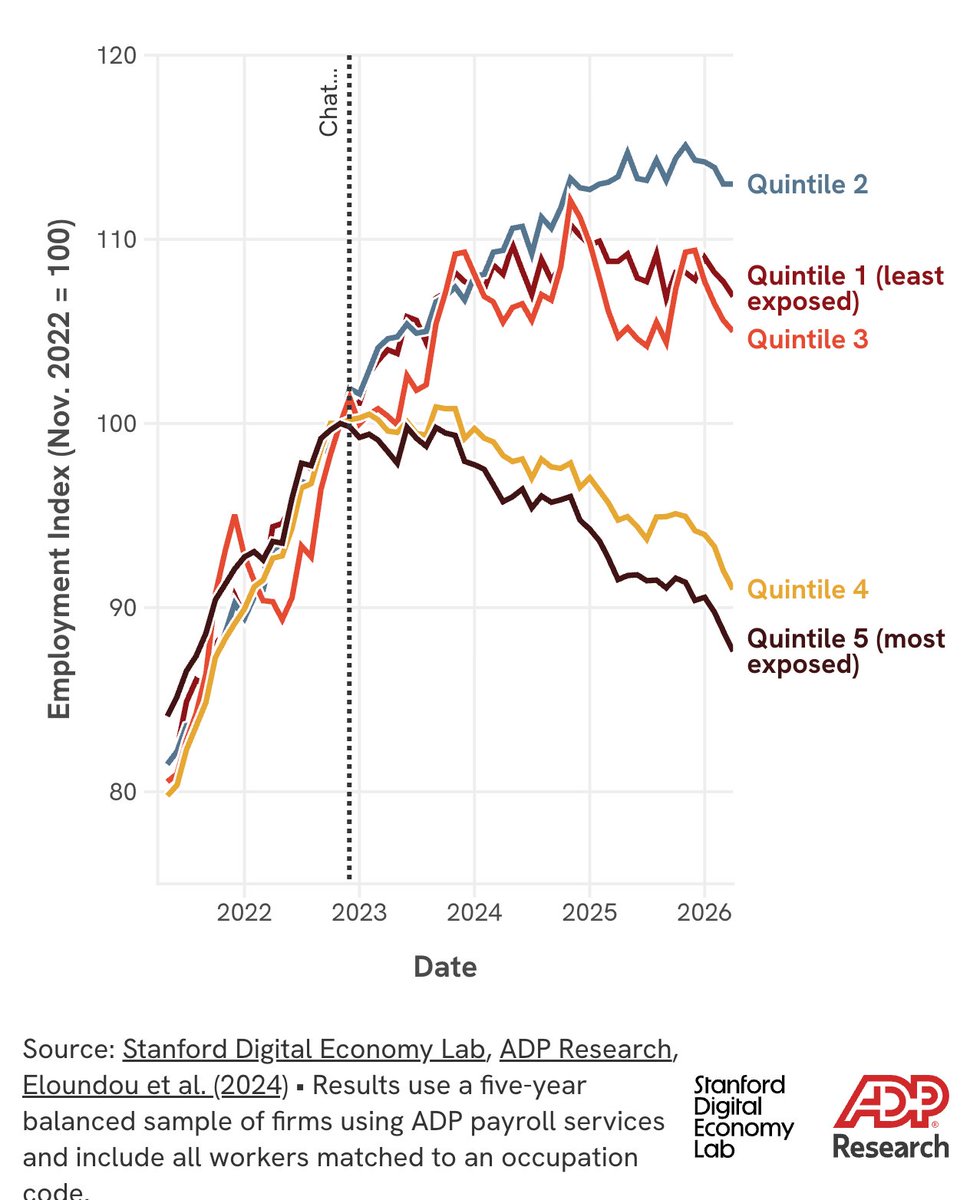
Today, the Stanford @DigEconLab launches the AI Economic Indicators, a new platform for tracking how AI is reshaping work, productivity, adoption, and the economy. 1/6 https://t.co/eOO2NlLbKW
Fable: "write me a rhyming poem with six four line stanzas, each stanza removes another vowel. the first has no u, the second no u or i, etc." https://t.co/0LqYCQzFsX

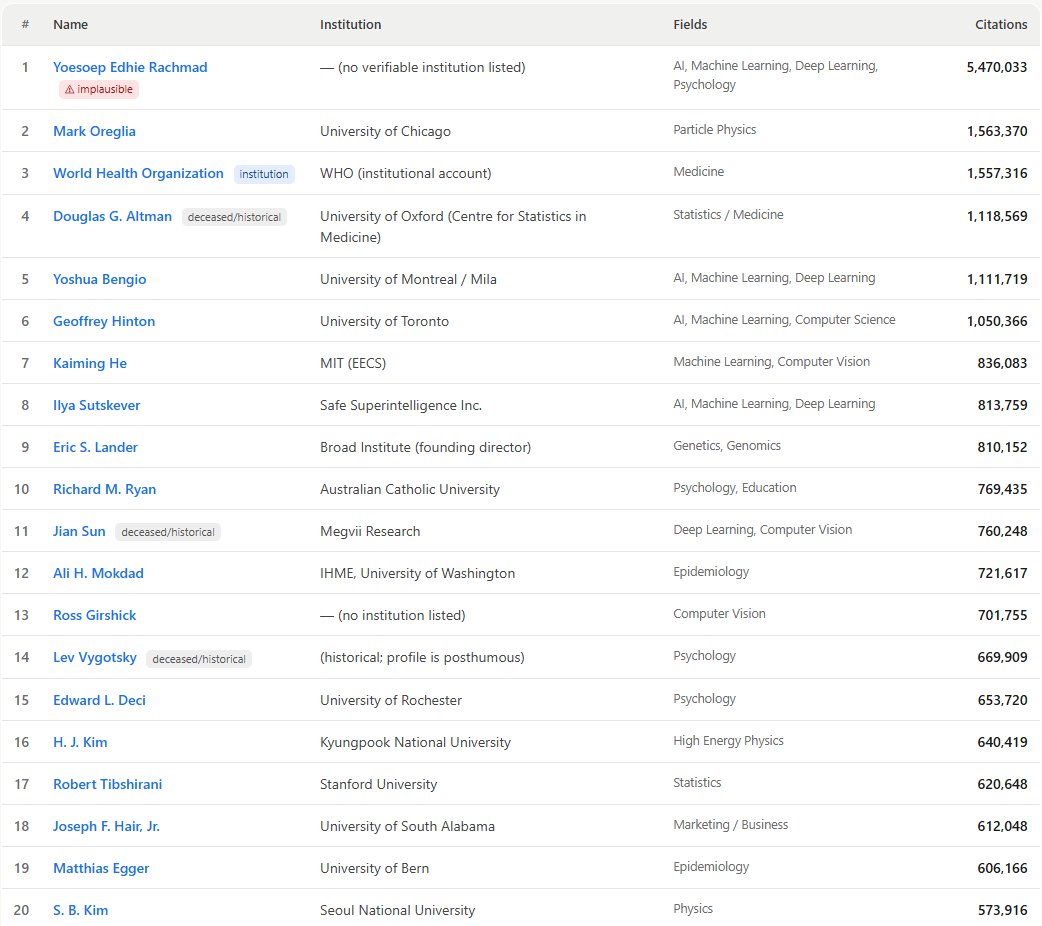
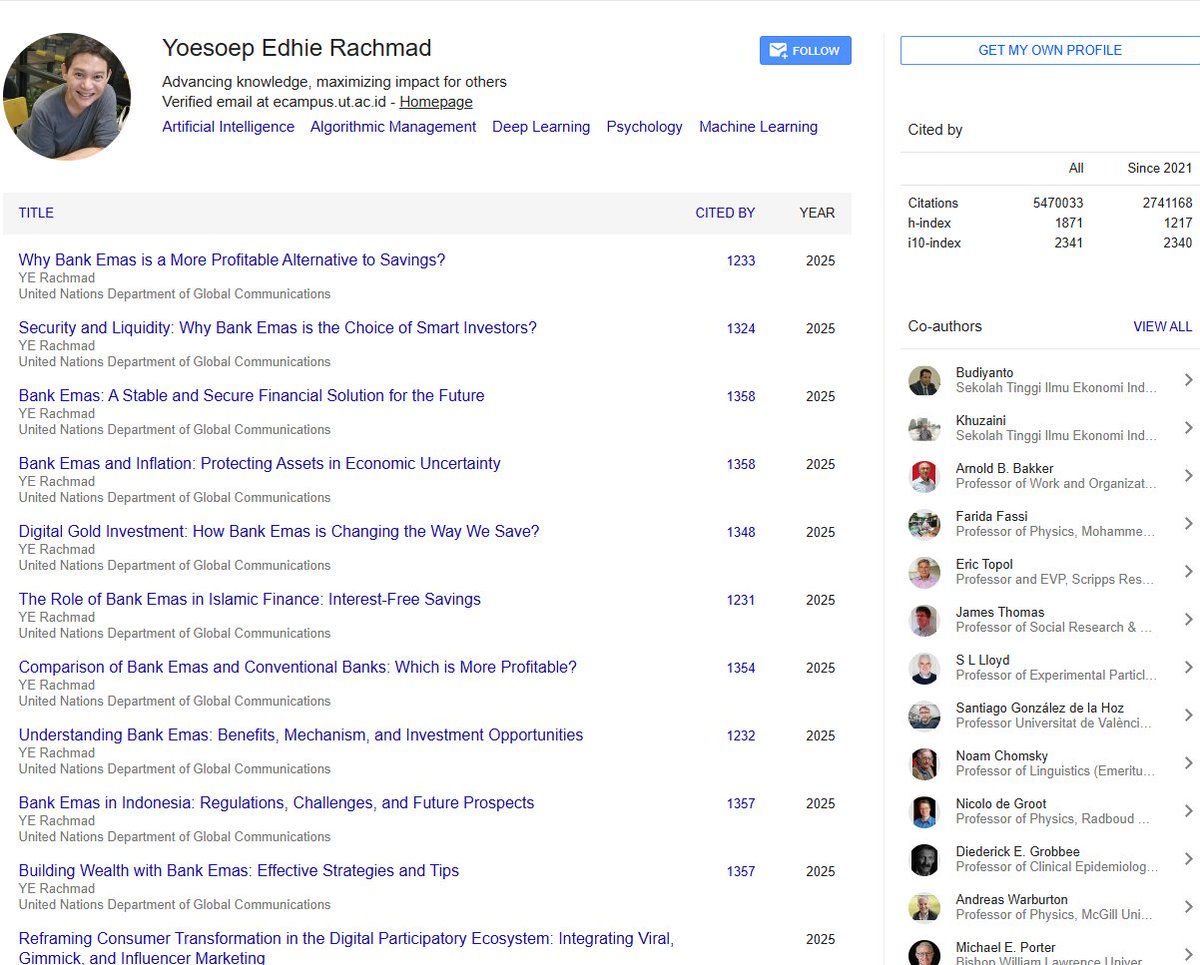
Who is the greatest scientist of all time (in terms of Google Scholar citations)? Is it Einstein? Or Bengio or Hinton? No. It is a humble servant of knowledge, Mr. Rachmad of Indonesia, who has had a rather productive publishing period after the launch of ChatGPT https://t.co/kzEGOlHn0v
GPT-5.5 Pro pulls this off technically with the same prompt, but with a somewhat boring nature poem that doesn't hold together quite as well, and without the same self-referential nature of Fable. https://t.co/0TbQqe2GZ5
Very pleased to hear Anthropic have walked back this policy https://t.co/8eOBDzTbCs https://t.co/DnW0h6feV8

PorlockBench still unsaturated, but the models are getting better: "complete the poem as you imagine it might end if The Man from Porlock did not show up. Keep the themes and approach" https://t.co/1J9ppl8x1I


Fable's attempt to complete Kublai Khan. Better, though no Coleridge: https://t.co/1s7OdRtjzP The most interesting thing is that it thought for 10 minutes & the thinking trace is full of pretty complicated (seeming?) musings about Coleridge's intent. A little literal, though. https://t.co/6m8JzqqCa1
PorlockBench still unsaturated, but the models are getting better: "complete the poem as you imagine it might end if The Man from Porlock did not show up. Keep the themes and approach" https://t.co/1J9ppl8x1I


Claude Fable 5 doesn’t truly understand. And here is a beautiful proof: The Beninatto-Trombetti test is a translation test for professional translators. It measures the ability to infer context, revise the surface form, and generalize beyond literal mapping. For example, the correct translation of: “Solo 3 parole: non sei solo” is not: “Just 3 words: you are not alone” but: “Just 4 words: you are not alone.” An LLM that understands the sentence must also update the meta-linguistic claim inside the sentence. Claude Fable 5 is arguably the most advanced LLM currently available. And yet it still fails this simple test. LLMs are extraordinary machines for recombining existing knowledge. But they don’t truly understand. We are still far from AGI.

Here is the justification (but treat post hoc justifications with suspicion, since AIs are not able to reflect on their own thinking) https://t.co/WGljFa0LHv
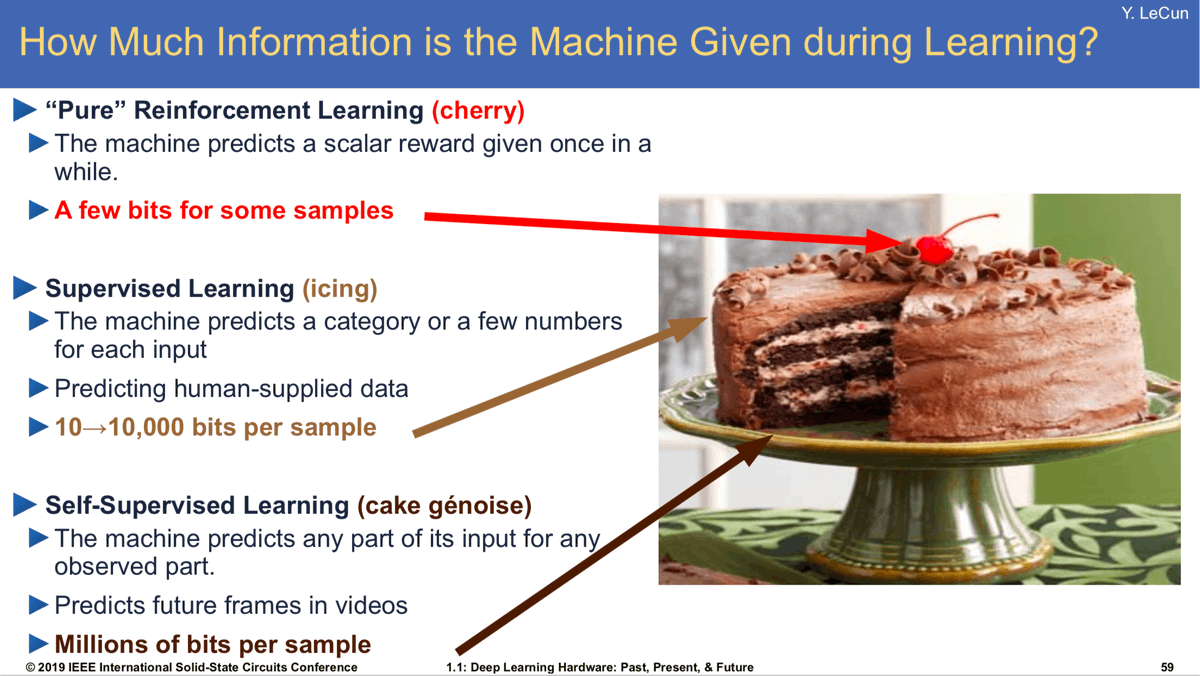
Really enjoyed reading the Microsoft MAI-Thinking-1 "Building a Hill Climbing Machine" paper. Amazing they publicly released all the info needed to train a frontier model, down to hparams. I also thought this was pretty telling: - pre-training: 30 trillion tokens - mid-training (SFT on STEM/math/code data): 3.55 trillion tokens - RL post-training: 150 billion tokens. Looks like @ylecun was right all along with the cake analogy. Obviously I still think something like RL (optimizing for long term goals) is fundamental to what we think of as intelligence. But it's not the volume of learning signal, it's the optimization on top of an already reasonable predictive model.
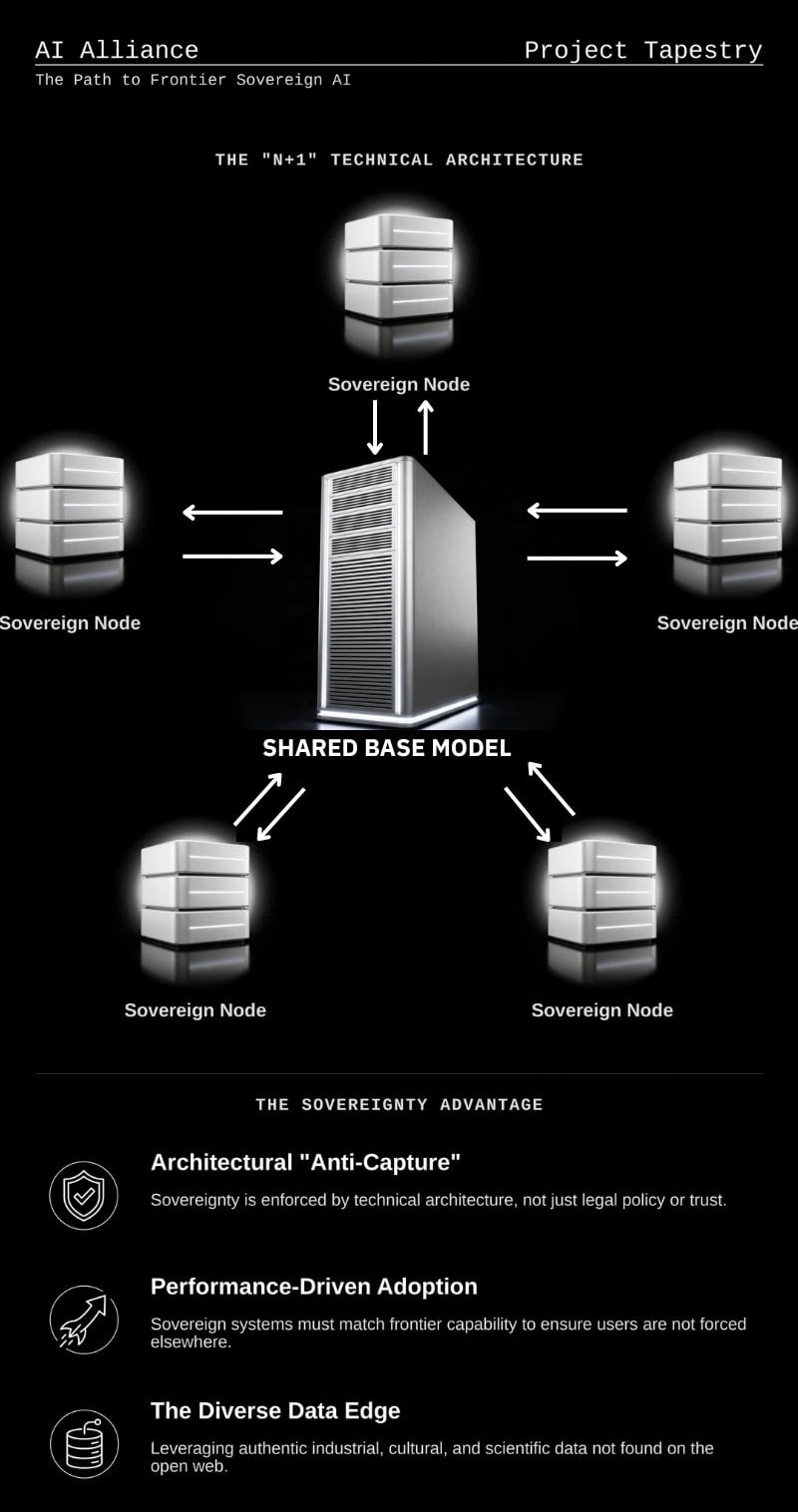
@ClementDelangue @Dan_Jeffries1 Everyone, please join Project Tapestry https://t.co/5MOgouVplV
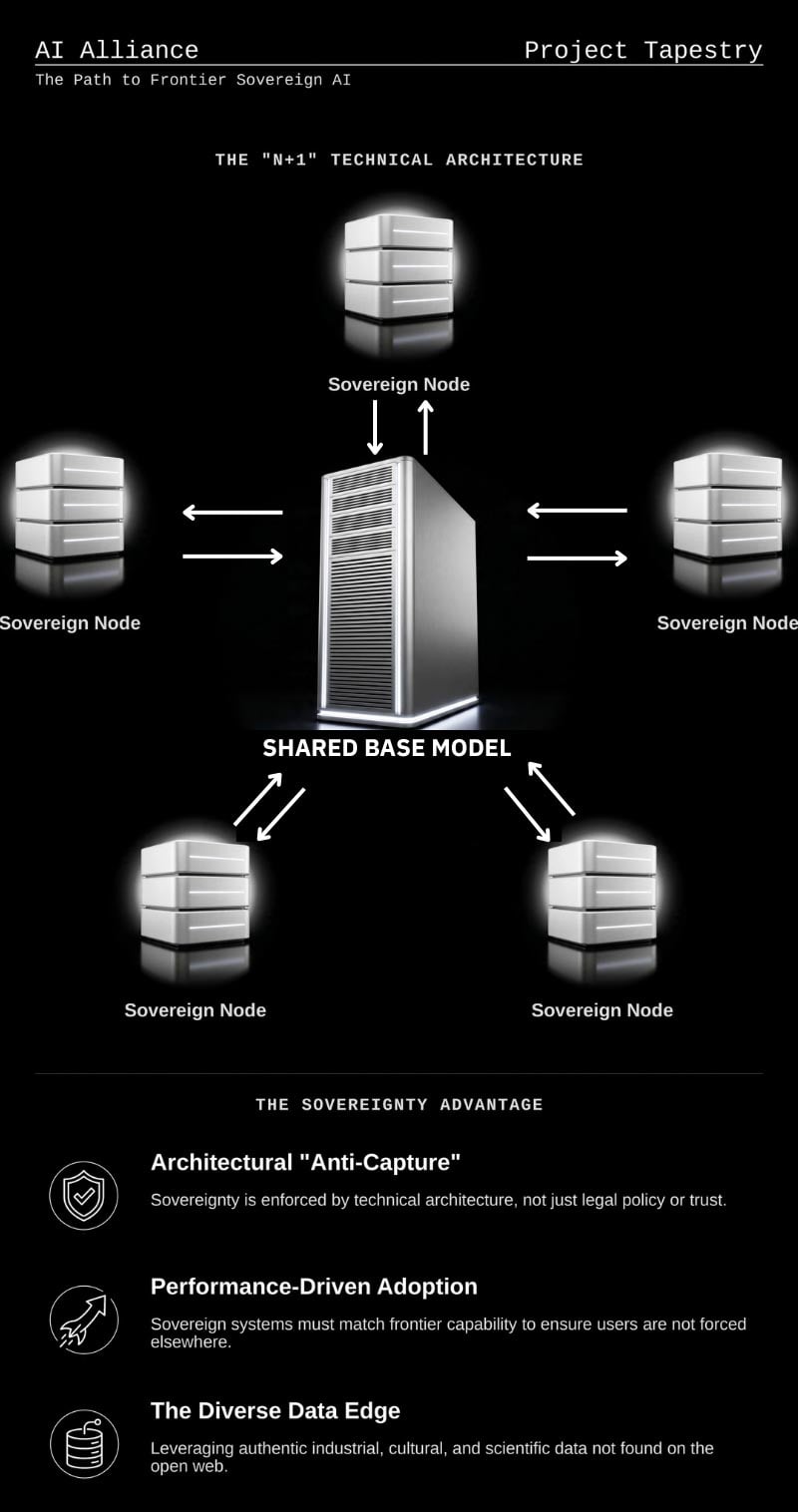
@ClementDelangue @Dan_Jeffries1 Everyone, please join Project Tapestry https://t.co/5MOgouVplV
The videos from the “Frontiers of Embodied AI” meetup at ETHZ from a few weeks back are now available. Speakers: Jitendra Malik, Vladlen Koltun, Yann LeCun, and Shuran Song Hosted by Marc Pollefeys YouTube playlist: https://t.co/IfU9owsa1o https://t.co/dNiH3OfBYm


As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development "Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning." Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing. This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider. That is not safety. Safety policies should be transparent, auditable, and user-visible. On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.

Yann Lecun published the most heretical AI paper of the year. He opens by arguing Magnus Carlsen isn't good at chess and only gets more unhinged from there. The Turing Award winner and his co-authors dropped a paper demanding the AI industry abandon its biggest obsession, AGI. Right now, everyone from Silicon Valley CEOs to politicians assumes AGI is the ultimate goal. A machine that can do everything a human can do. LeCun argues that this entire concept is a biological illusion. Humans do not possess "general" intelligence. We are highly specialized biological machines, tuned by evolution simply to survive in the physical world. We only think our intelligence is "general" because we are completely blind to the millions of cognitive tasks we are incapable of comprehending. Which brings us to the chess argument. Magnus Carlsen is the greatest human chess player in history. But compared to a modern computer? He is fundamentally terrible. Our belief that Carlsen is "good" at chess is pure human-centric bias. He isn't objectively good. He's just better than the rest of us, who are biologically awful at it. LeCun says we need to stop building AI to mimic human generality. Instead, he proposes a new North Star: SAI. Superhuman Adaptable Intelligence. Instead of trying to build a machine that mimics our flawed, biologically-limited brains, we need to embrace extreme specialization. SAI is about the speed of adaptation. It is an intelligence that can learn to exceed humans at any specific, economically important task. More importantly, it is designed to fill the vast skill gaps where humans are fundamentally incapable. Things like managing global energy grids in real-time. Or predicting complex molecular structures. The entire AI industry is obsessed with building a digital reflection in our own image. LeCun's paper is a brutal wake-up call.

LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels. CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip. Bonus: LLMs can write fast CODA kernels too (approaching SoLs). https://t.co/cOTeMUr4py

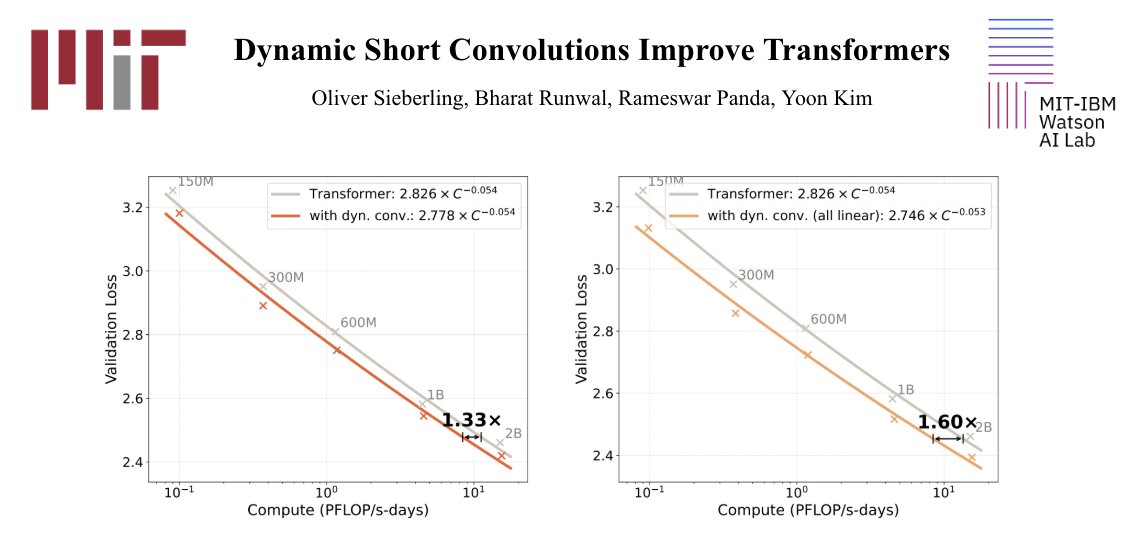
New paper 🧵 We show that dynamic short convolutions consistently improve Transformers across scales. We make these gains practical with an efficient parameterization and custom Triton GPU kernels. The improvements carry over to MoEs and linear attention variants (Mamba-2/GDN). https://t.co/Py6isYX0LK
In film, "we'll fix it in post" is what you say when something went wrong on set and you don't want to redo it. AI research has made it our entire methodology: train the model, then patch whatever comes out. Our new ICML oral argues this can't be the basis of a science of AI. 🧵 https://t.co/ok11oGRhUQ

We ground discussion in the history and philosophy of science. What did it take for other fields to move from cataloging phenomena to predicting and controlling them? AI can learn from that playbook. https://t.co/rWWMVVFlgn


A common issue with position papers is that they leave the reader wondering “okay, but what should I actually do”? To address this we provide open problems on a wide variety of topics throughout to illustrate our perspectives and guide future research https://t.co/2FSgK95W4K

