Your curated collection of saved posts and media
The AI race is becoming a price war. If OpenAI cuts token prices to compete with Anthropic, lower costs could accelerate enterprise adoption but also pressure margins across the AI stack. The next battle may not be who has the most powerful model. It may be who can deliver intelligence at the lowest sustainable cost.

The future of work will not be human versus AI. The people who thrive will be those who combine human judgment, creativity and trust with AI’s speed, scale and pattern recognition. The real career risk is not being replaced by AI. It is being outpaced by people who know how to use it better.
The next AI race may be won as much in factories as in research labs. China’s dominance in robot supply chains shows that building advanced AI is one challenge. Building millions of intelligent machines at scale is another. In the age of AI and robotics, manufacturing strength is becoming a strategic advantage again.

The AI IPO boom is turning into a capital tsunami. Demand for SpaceX shares suggests investors are no longer asking whether AI will reshape the economy. They are asking how much exposure they can get before the next phase begins. The biggest risk today may not be a lack of capital. It may be finding enough opportunities to deploy it.

@ScottPatterson0 @maticrobots Yeah, I'm so proud it was launched in my home here last year: https://t.co/fEkfcuLxjt We love ours for same reasons. @mehul is one of the best consumer entrepreneurs America has.
The new-fangled vacuum salesman. This is the best example I've seen of how AI and computer vision is changing consumer electronics. Here @maticrobots founder @mehul comes to my home to give me an in-depth demo (the good stuff starts about 30 minutes into the video). This al

“don’t train your own model” is common ai advice. it's wrong. your token bill's the proof. today, we’re excited to launch castform into open preview. castform is the easiest way for you to train your own model, on your own data. open-weights models are performant and much cheaper. when trained on your task & proprietary data, they beat closed models. the thing standing between you and that was weeks of plumbing & years of ml expertise. with castform, model training is as simple as prompt engineering. @castformai bring your agent traces or raw corpora. castform turns it into training data, picks the right algorithmic recipes, manages gpus, and gives you an ide to watch and chat with your model as it learns. see what you can build with castform👇
Meet Coinbase for Agents. Give your agent its own account to: → Execute trades & manage your portfolio → Run autonomously under guardrails → Pay for data & research tools via x402 (coming next week) Agentic finance is here, and it's powered by Coinbase. https://t.co/DK220fko0z
48 hours ago Apple announced its new Personal AI: Siri. Today Onairos announces Persona, the user data api to power all other Personal AI’s with context not even Siri has. https://t.co/ogBCIsM1xc
The next generation of Apple Intelligence powers an entirely new Siri: making the apps and experiences you rely on across iPhone, iPad, Mac, and Apple Vision Pro more personal and helpful than ever. https://t.co/aXiDIkqAKn
San Francisco comes through again. Spent a delightful hour with @khal_ism who is building a new brain computer interface that you will hear a lot about later this year. I wrote eight books about decade-long change coming. My first was about social media before this site were are all on started. If I write another it will be BCIs. Have a list of neuroscientists and builders working in this field. It will be a trend of new things coming over next decade. I already asked @elonmusk for a full neuralink. He said they aren’t ready for regular people yet, but told me “cognitive enhancements” are coming in three years. OpenAI, Meta, and others are working on them too. But now I know a lot more about how they work. Thanks X. This morning when I woke up I had no idea who I would meet. Another meeting in a few minutes. Can’t do this in most other places in the world. This morning I wrote that I had the day free, and already an amazing day. Plus the weather is so amazing today. And my other surreptitious meetings today? Entrepreneurs who are changing how we work. Deeply too, more on that soon.

Preview of some slides for this https://t.co/PcKT8T39Ax
Doing this on Thursday. Yes I’ll show you my skills, but more importantly I’ll talk about how you shoukd be VERY skeptical when adopting them (including my skills!) https://t.co/xDwgSTvjLu

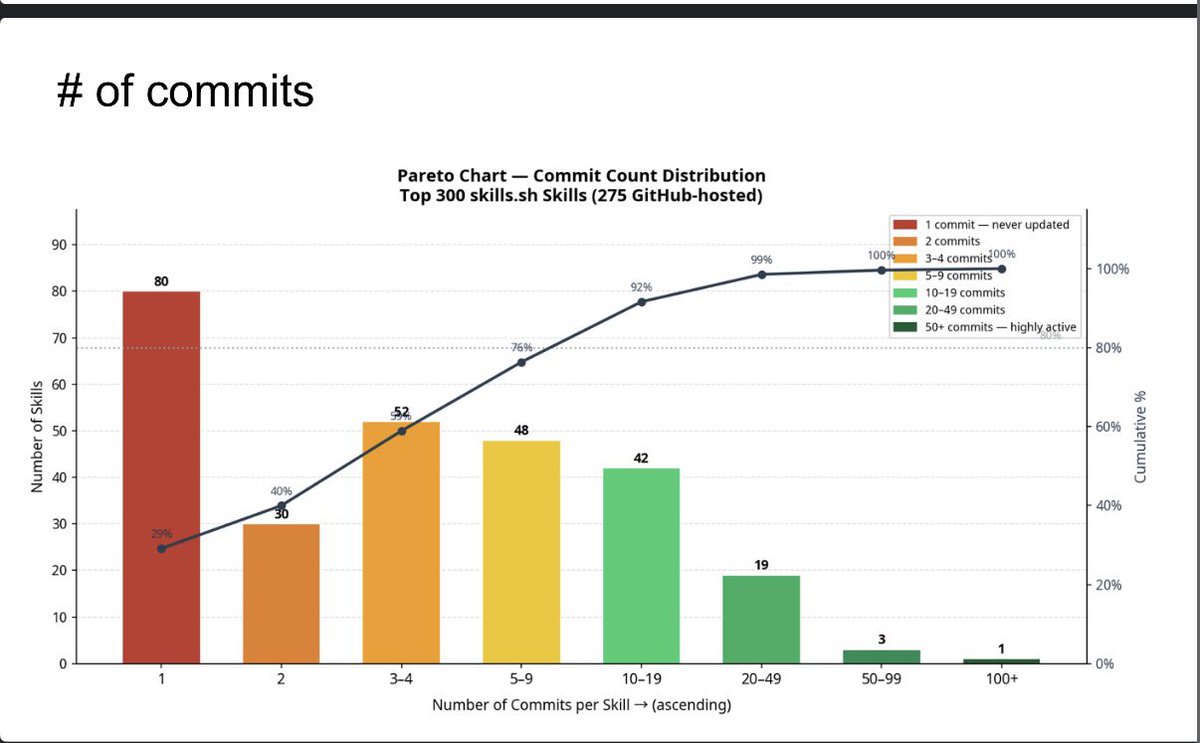
Coming up against the same problems over and over? Tried a bunch of experiments to get unstuck but still not where you want to be? This year at Observe @HamelHusain will be hosting two 1-hour Offices Hours to work through challenges in what you're building. Grab your tickets for Observe now and don't miss out on this special session. https://t.co/NYEih97lij


Our evals course is 25% off this week! The next cohort will have completely refreshed material. @sh_reya and I will cover new topics like: using agents for evals (w/o the foot guns), thinking like a data scientist, optimization approaches for harnesses and more. Use this link to apply @lennysan 's special 25% off code: https://t.co/Fy8r7bAAxM

today, we’re excited to announce raindrop 2.0: self-healing agents. we now train custom models that autonomously detect hidden issues with your agent. i could tell you all about it, but wouldn’t you rather hear it from someone… else? https://t.co/dBGNNr9UNv
https://t.co/8HaeeSSfQL

https://t.co/8HaeeSSfQL

I love agentic map-reduce, but I don't love Claude's workflows feature. It's hard to steer the workflow, and it's not data-driven enough (e.g., reduce groups are often predefined, not emergent from the map outputs) HOWEVER...I was inspired by its UI to ship something similar for DocETL. Satisfying way to visualize progress when using the CLI 😆
Got my 10yr old introduced to Codex today. The excitement in his face tells it all. After struggling with Claude Code CLI for a bit, today he was like “this is the future, dad”. The Codex team built a beautiful app. https://t.co/ITM7Euzybl
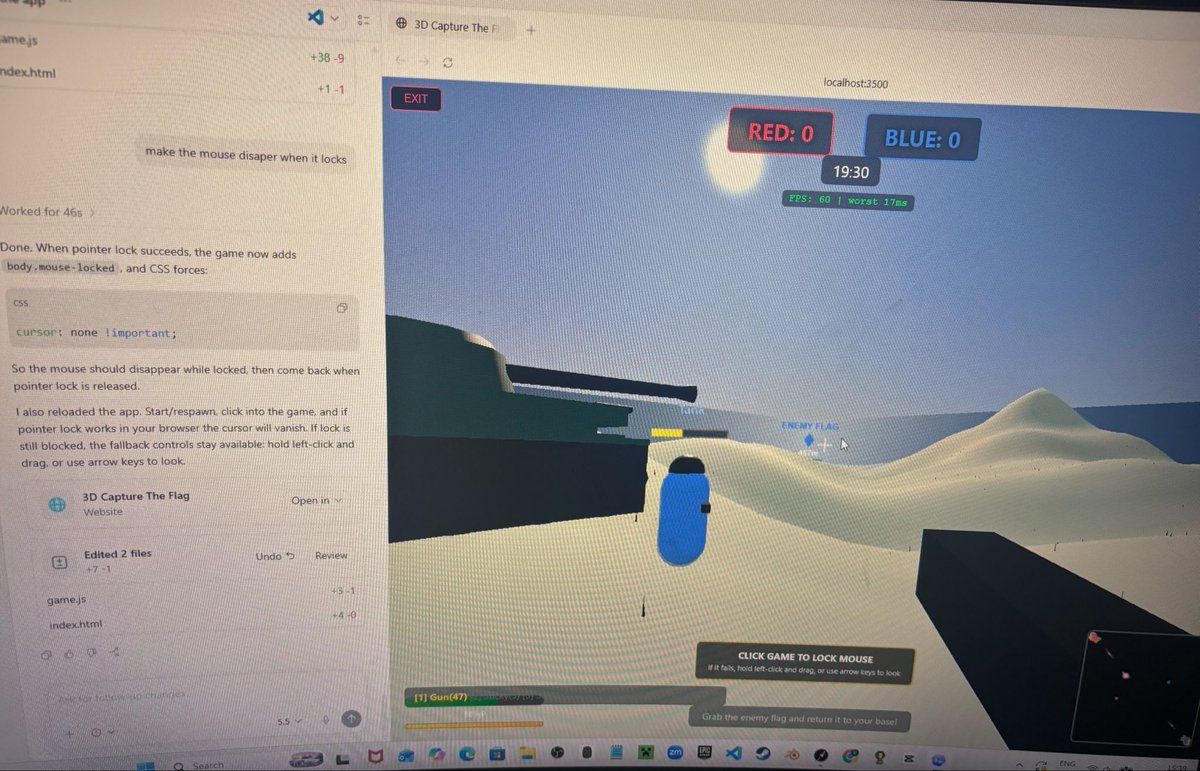
NEW: Anthropic is walking back Claude Fable 5's policy to covertly degrade performance for competing AI researchers, after facing fierce backlash. “We’re changing Fable 5’s safeguards for frontier LLM development to make them visible,” Anthropic tells WIRED. “We made the wrong tradeoff and we apologize for not getting the balance right.”

and it happened: Poke is now back on WhatsApp in the whole European Union! wouldn't have been possible without all the help from twitter, such as @kishanbagaria and @lutherlowe, who help us start this investigation from me testifying in rome to @felixms in brussels last month. @interaction also won in brazil, turkey, and many more jurisdictions are on the way free market prevails! and the path is paved for the inevitable product form factor to win consumer AI
looks like we'll not only have preliminary measures in italy, but across the whole EU 👀 will testify at a hearing by the european commission in brussels next month Poke and other AI assistants will be back on whatsapp in every country soon – let the free market decide! 🌴 https:

We just shipped a search and command bar to the OpenAI API Platform! Use ⌘𝙺 to search through: → Pages → Settings → Quick Actions → Resources → Developer Docs https://t.co/XFIiCE0w6n
Cooking. @steipete 🦞 https://t.co/hni2zTM9ZM

Cooking. @steipete 🦞 https://t.co/hni2zTM9ZM


SCAIL-2 Unifying Controlled Character Animation with End-to-end In-Context Conditioning https://t.co/bD0lUcHipJ
paper: https://t.co/aDXt8Sn4S4

One month ago, when I was talking to @AdinaYakup, I said: “The UI of a Space @Gradio is basically just two rectangular boxes showing ML features.” Who would’ve thought that yesterday I would end up building a whole garden in @Gradio Never say things too early haha. P.S. This is a mockup for a personal CV project et @huggingface 🌱I’m working on. Once it’s finished, I’ll make it open and downloadable. Everyone’s life experience is a garden. 🌸
Redesign Mixture-of-Experts Routers with Manifold Power Iteration https://t.co/OlhdXKJMV1

paper: https://t.co/SnopoMv497

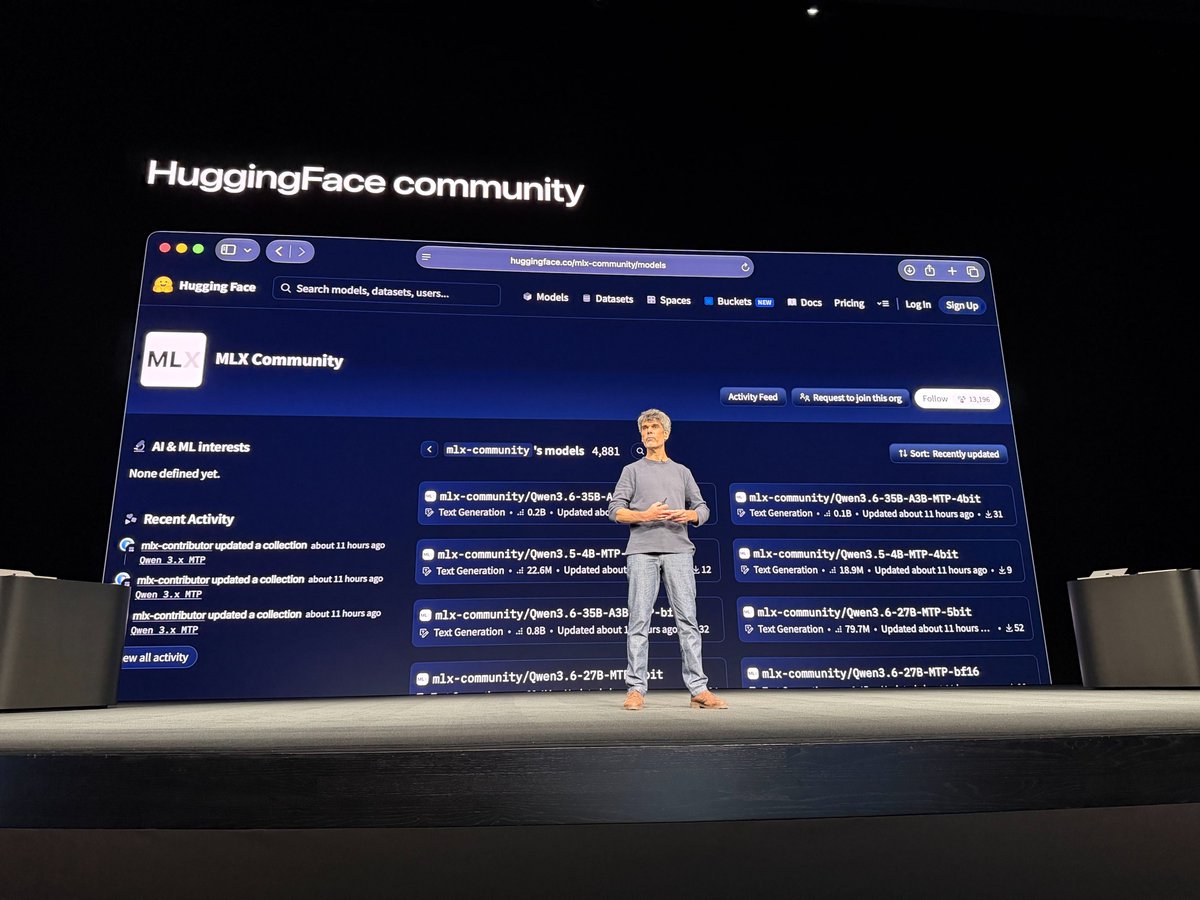
Ronan Collobert showcasing MLX's @huggingface page on stage at WWDC 🥰 next year let's meet at WWDC! https://t.co/ld1G7PSaJH
It’s not just Claude Fable 5. The real cost of AI workflows comes from iteration. One prompt is cheap. Full-loop testing is not. Only 5 days left — ZenMux gives you extra credits to build, test, and compare across 200+ models: 🎁 Pay $20 → Get $30 🎁 🎁 Pay $50 → Get $80 🎁 More room for coding, agents, benchmarks, and multimodal builds. 👉 https://t.co/RL7fdtojk4


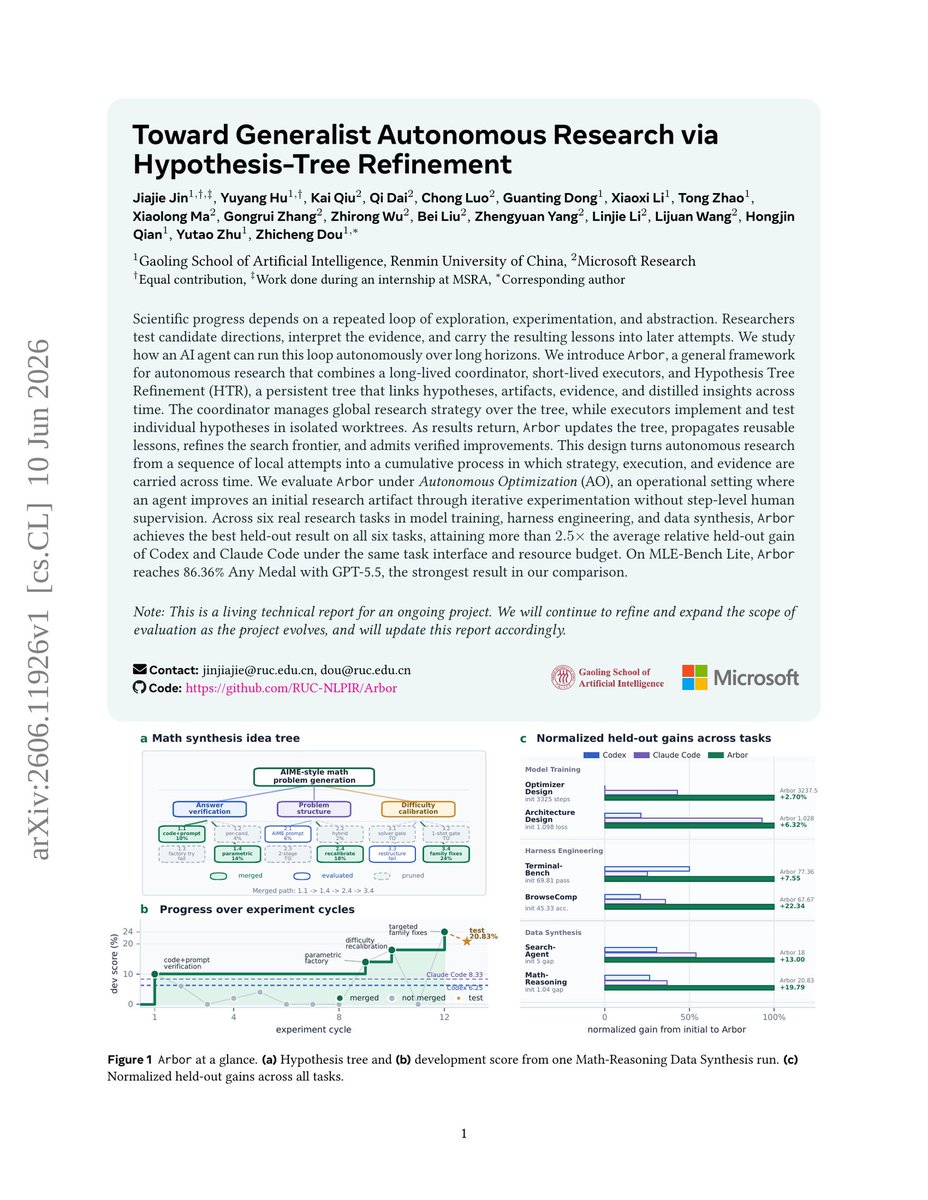
Microsoft Research introduces Arbor A generalist autonomous research agent that uses persistent hypothesis-tree refinement to turn long-horizon exploration into cumulative learning. It beats Codex and Claude Code across 6 research tasks and hits 86% Any-Medal on MLE-Bench Lite. https://t.co/A1fxTxnskk
https://t.co/SsRi3qhwN4

https://t.co/SsRi3qhwN4
