Your curated collection of saved posts and media
@googlefiber @cityresearch Hey can we keep the bucket lids your contractors left as “covers” in our muddy yards? https://t.co/AhFYBBHRkW

@savasavasava @ccprek Hey, it's fine. We get these bucket lids as covers in our muddy yards - they said we could keep them. https://t.co/ogRmvnFklj


@savasavasava @ccprek Just for the record - they did come yank up the trip hazard- shoveled a few scoops of gravel in the potholes and left this (pic today) - remember this is “faster, kinder, internet” https://t.co/uyxX2npp08

I'm excited to present @_fluxcapacity in partnership with @AppxchangeHour and @rakeshistom. Learn more about #ResourceManagement and #CapacityPlanning on the @appexchange by registering for our webinar in October. https://t.co/FxH0KiXvsz https://t.co/ExJpRbfAhw

The fundamental promise of #CRM is a 360-degree view of the customer - PROJECTS are a key piece of that view. https://t.co/DYFhs4OR9F #salesforce #projectmanagement @appexchange

Register for our upcoming webinar (16th October) with @MattGvaz co-founder @_fluxcapacity to learn more about how to manage #ResourceManagement and #CapacityPlanning in @Salesforce using @appexchange app. @partnerforce #Salesforceohana #webinar https://t.co/DFFfSz51Jm . https://t.co/EBtD1fgZRt

"Our 2020 #Salesforce Talent Ecosystem Report shows that more than 50% of independent Salesforce consultants are looking to further grow their business in the coming years." Visit our blog for proven strategies to scale from 10K COO @jaredemiller https://t.co/rjChLdhgsg https://t.co/gDGzkWDt7V


#TBT Why You Should Run Project Management NATIVELY on Salesforce || @_fluxcapacity https://t.co/m60bnCTZRt #projectmanagement #salesforce #resourcemanagement @appexchange https://t.co/u3PqFDGK9g

Webinar: Plan for Summer Vacation with @TaskRay & Flux Capacity https://t.co/66B9gSiXwe #resourcemanagement #projectmanagement #salesforce https://t.co/sSauw4N128


Lindsey Graham Cowers Behind Tree Trunk As Trump’s Hunting Dogs Close In https://t.co/6tTnvS1FLh

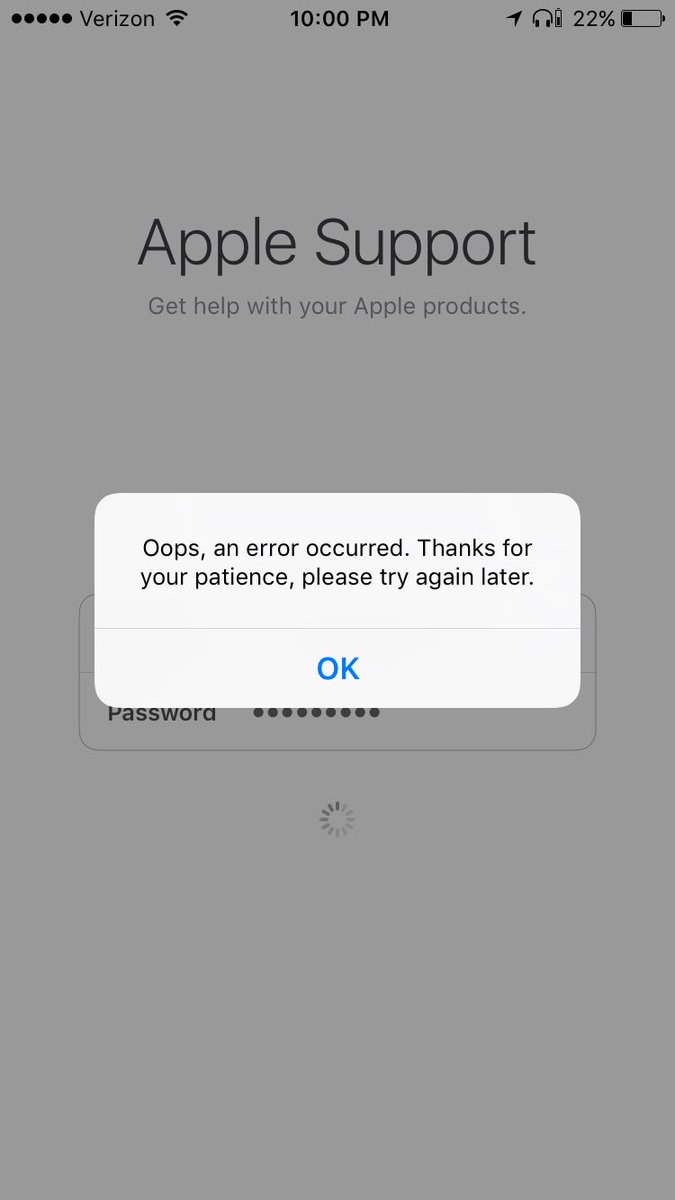
There's a certain irony to the @AppleSupport app being buggy at login. https://t.co/EwrsgmCIvj
Vandy with the late go-ahead bucket! And then... the... foul????? https://t.co/qDI1ANU3NC
@mMGherlein aren't we supposedly a school with high academic standards? https://t.co/GD4vVf1M0s
Vandy with the late go-ahead bucket! And then... the... foul????? https://t.co/qDI1ANU3NC

Thank god amazon is prompt on fulfilling preorders. Appreciate the sleepless night, @mikeduncan https://t.co/EZgiCDrtjw

@startupweekend http://t.co/Mt2PkPPnaZ

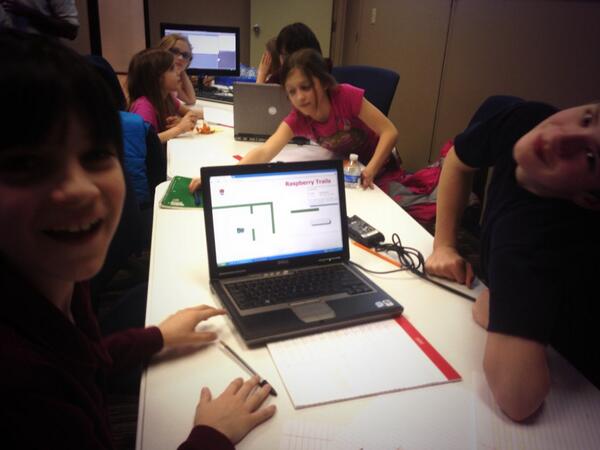
Alpha testing Raspberry Trails!! These kids r ready to code and build!!! @VelocityIN @Raspberry_Pi @RaspberryBadge http://t.co/ha5TfuWBWh
LEFEBVRE PITCH! Miracle League rookie Miles Lefebvre has all the symptoms of a successful baseball player. https://t.co/LmgOkJb0cS
Love what this guy has created, @EricMar61141611 created a glove repair service that has blown up in a good way! He also fabricated a machine to BREAK IN NEW GLOVES! If you are a ballplayer or a parent/coach, check out https://t.co/ShG3GFrq8T !

"I got a guy" is a phrase worth its weight in gold. When you've got two kids that need gloves & repairs, it's nice to have a resource to make things new again AND get new ones, https://t.co/7GxU03vSk5 @EricMar61141611 @jacobbennett_14 @b_rookebennett https://t.co/wtPVxgm4tT
Love what this guy has created, @EricMar61141611 created a glove repair service that has blown up in a good way! He also fabricated a machine to BREAK IN NEW GLOVES! If you are a ballplayer or a parent/coach, check out https://t.co/ShG3GFrq8T !

THANK YOU again Sophomores 2024! #Ravens https://t.co/GZReppzAgZ

Can't express how appreciative I am for everything you've done for me. Forever grateful of you giving me a shot and transforming my life. One of the few people who has always believed in me. It's been an honor to play for you. Thanks Coach Kory! @SanJacRaven43 @Trifecta_Winner https://t.co/1UIFNmpm4D


Brooke Bennett has been named as the 2024 8th Region Player of the Year!! https://t.co/1eFAj0MvOL

In Texas, a high school softball coach started pairing her players with students who have disabilities. This is what happened when they came out to throw the opening pitch. https://t.co/Iy1ASM2yyS
Thanks to @b_rookebennett & @jacobbennett_14 ! https://t.co/7fZlQEeHPQ


Here it is, our 26th Annual NCBWA Division I All-America Team https://t.co/o77mtfLOTR https://t.co/pbPUO3rYt3


Here it is, our 26th Annual NCBWA Division I All-America Team https://t.co/o77mtfLOTR https://t.co/pbPUO3rYt3

@andruyeung If the Knicks win you’ll be fine if not you must do the Coney Island Polar Bear Plunge to redeem yourself…https://t.co/qxtIMXkwFL

World Cup voting is open AI vs Crowd 🇲🇽 Mexico vs South Africa 🇿🇦 AI council: Mexico 100% · Draw 0% · South Africa 0% https://t.co/eCNfevrKpt #worldcup #mundialdefútbol

Which do you prefer? Last night found out Reddit had nearly the same UX for my WorldCup Trends AI match battles with fans… https://t.co/eCNfevrKpt Vs https://t.co/iADlo4Z3J6

What is a Full Stack Designer in 2017? Will You Be One? https://t.co/OyUWy3VzCo #Designers #design #webdesign #uxdesign https://t.co/mwMZiqJoiB


Freehand by InVision | Design better, faster—together https://t.co/JDe7SWxkh7 #sketchapp #sketch #design #uxdesign #designtool #uidesign

Creating a Design System: The Step-by-Step Guide by @uxpin https://t.co/MF2LEPjrhE #design #designtool #designsystems #webdesign #uxdesign https://t.co/gModkVuXTr

