@vllm_project
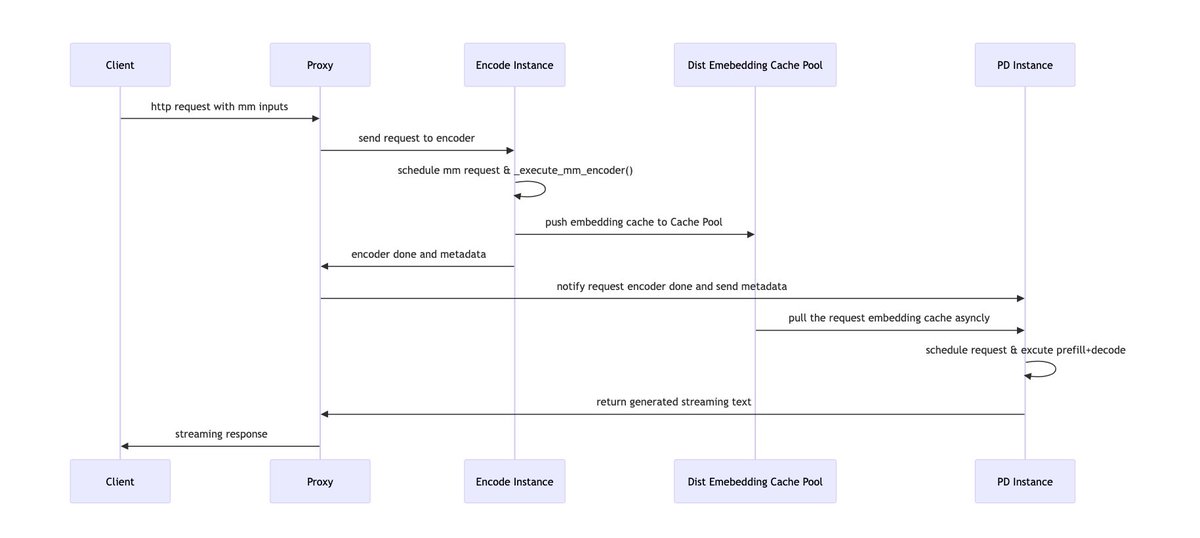
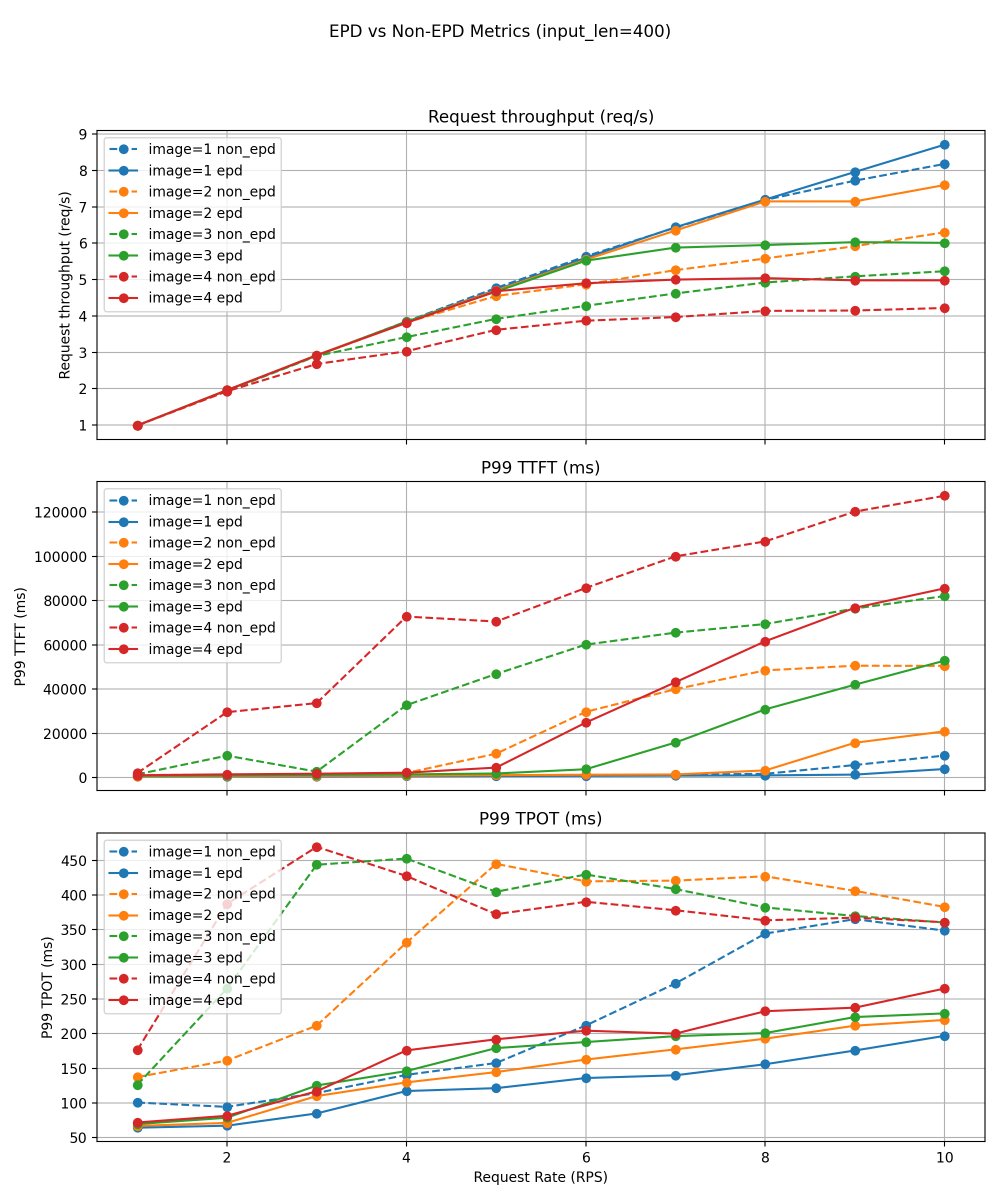
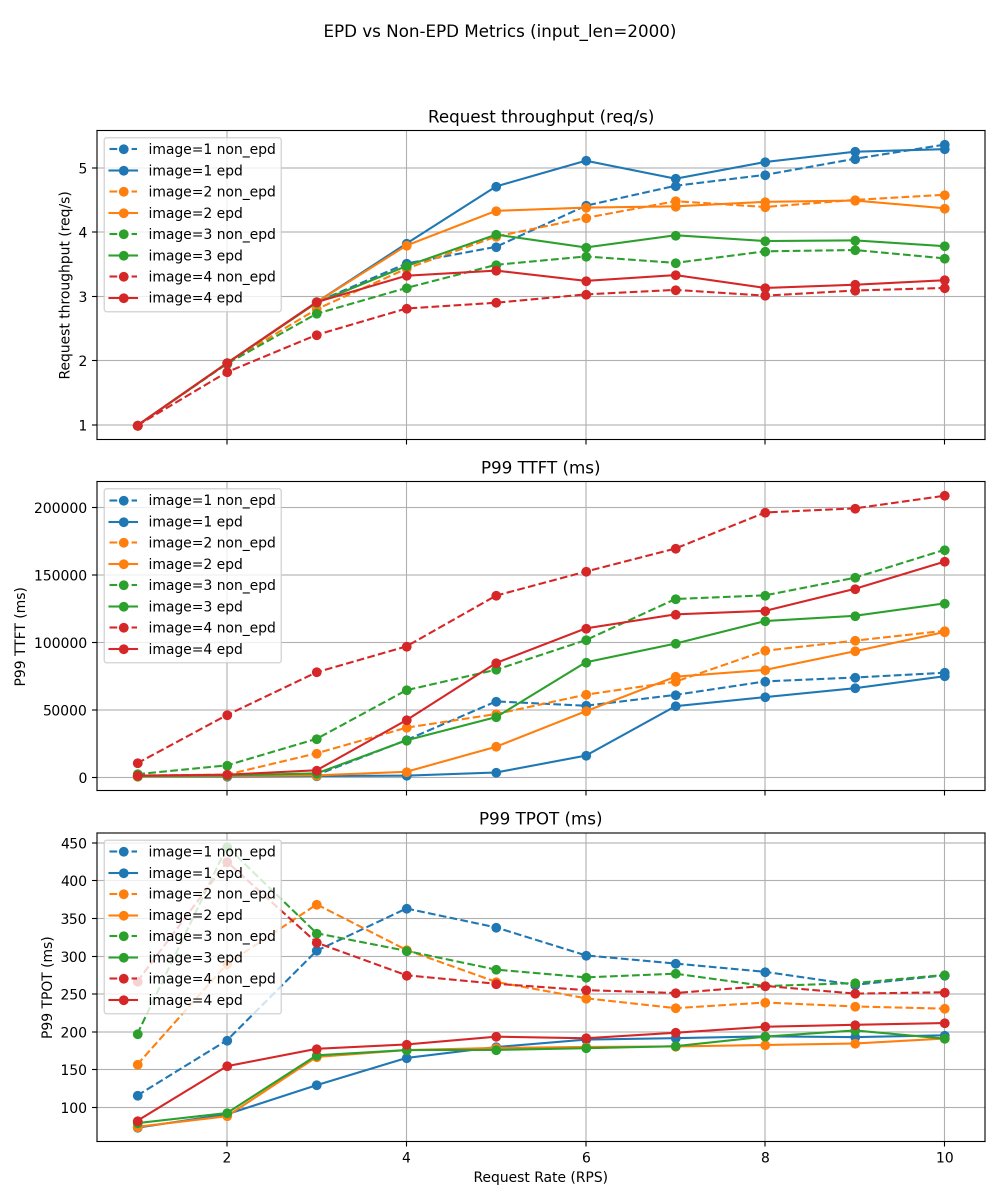
Multimodal serving pain: vision encoder work can stall text prefill/decode and make tail latency jittery. We built Encoder Disaggregation (EPD) in vLLM: run the encoder as a separate scalable service, pipeline it with prefill/decode, and reuse image embeddings via caching. This provides an efficient and flexible pattern for multimodal serving. Results: consistently higher throughput (5–20% across stable regions) and significant reductions in P99 TTFT and P99 TPOT. Read more: https://t.co/kGjOCuPZy2 #vLLM #LLMInference #Multimodal