Your curated collection of saved posts and media
“I think that the legislature by adding this 20 basis point tax truly is telling you to pack your bags and move.” @AndoniOlta, Executive Director of @ILBlockchainIBA, on what Illinois’ new 0.2% crypto tax could mean for the state’s crypto industry. https://t.co/Tfor1jXsN6
In 1903, the French government expelled the Carthusian monks from their monastery in the Alps and seized everything they owned. The monastery. The distillery. The equipment. All of it. There was just one little problem. Only two monks in the entire order knew the recipe for Chartreuse, and they had memorized it. There was nothing written down that the government could take. The French government hired chemists to reverse-engineer it. They analyzed every bottle they could find. They ran every test available to early 20th Century science. They could not replicate it. The liqueur they produced under the Chartreuse name was so inferior that it destroyed the brand almost immediately. Sales collapsed. The company the government set up to produce it went bankrupt in 1929. The monks, meanwhile, had relocated to Tarragona in Spain and were producing the real thing the entire time. In 1929, the same year the French government's operation went under, the monks quietly bought back the rights to their own name and returned to their monastery. The recipe is still known by exactly two monks at any given time. When one dies or becomes too ill to continue, he passes his portion to a successor. The full recipe has never been written down in a form that has left the order. Chartreuse is made from 130 Alpine plants and herbs. The monks tend the distillery themselves. They take no outside employees into the production process. The 1605 manuscript that started all of this is still held in the monastery archive. The French Third Republic lasted from 1870 to 1940. The monks are still there, still making Chartreuse. © Eats History #drthehistories

Wholesale blank apparel coming next month from Anatar. Grown here. Sewn here. Register your interest at https://t.co/2KExFMFBzK https://t.co/QyLUZ7vNOD

You can't see him, but I swear @nowsourcing is speaking the truth that we all need to break down silos in Louisville http://t.co/uBWgI5Wuff

So the only good local beer at @MellowMushroom in Louisville is @fallscitybeer. Just saying. http://t.co/x7i04SyFAz

.@zackpennington kicking off @SWLouisville. Get your pitches ready! #swlou http://t.co/aBUMQQmQC5

.@zackpennington doing his usual amazing job evangelizing @USChiaSeeds and the benefits of Chia. @VelocityIN http://t.co/Vx902dIFwZ

Tested icon generation with @QuiverAI on @paper . Quick take: 🚀 AI nails the concept but struggles with polish. 🎯 Detailed prompts backfired; simpler ones worked better. ✍️ Stroke widths and consistency? Still manual. https://t.co/n50BtwrmeK
When you watch other leaders you realize how visible, engaged, thoughtful, researched, tuned-in and smartly on-point @LouisvilleMayor is. https://t.co/tJ5FoOOSPl

Found an old pic of an old friend. Taped her on the wall looking at me. Now I can’t stop smiling (alongside some strange deep desire to be the best version of myself). https://t.co/77qzxXt9YG

I got to meet Br. Guy Consolmagno (@specolations), Vatican Astronomer, at the 2017 eclipse in Hopkinsville. Next week, he's speaking on science & religion (spoiler: they're not at odds) at the Newman Center @catholicwildcat https://t.co/oRAR5JPUo3 #sharethelex https://t.co/Bf2SJC2z94

Visiting @EKUCompSci for the EKU Computing Symposium, including a special CS Education Roundtable cc @awesome_inc https://t.co/NXkp3qW5Nc


Sav's Grill closes, with plans to open a new location in September https://t.co/Ed7OCy4e5M #EastMainSteet #ShareTheLex https://t.co/dT2leAKW3I

“Awesome Inc helped our Es explore what it takes to develop an app” https://t.co/FOqYcHnz0x @kentuckygse @awesome_inc https://t.co/s59J2B645C

Excited for the new TECX conference in September! #sharethelex @tecx19 https://t.co/dqgJdSya6J https://t.co/dIy61mqqFQ


Sav’s Owner Brings Ice Cream and African Cuisine to Colorful New Home on Main Street https://t.co/OpzRlCSzdO @SavsGrill https://t.co/ToyVCqq9u7

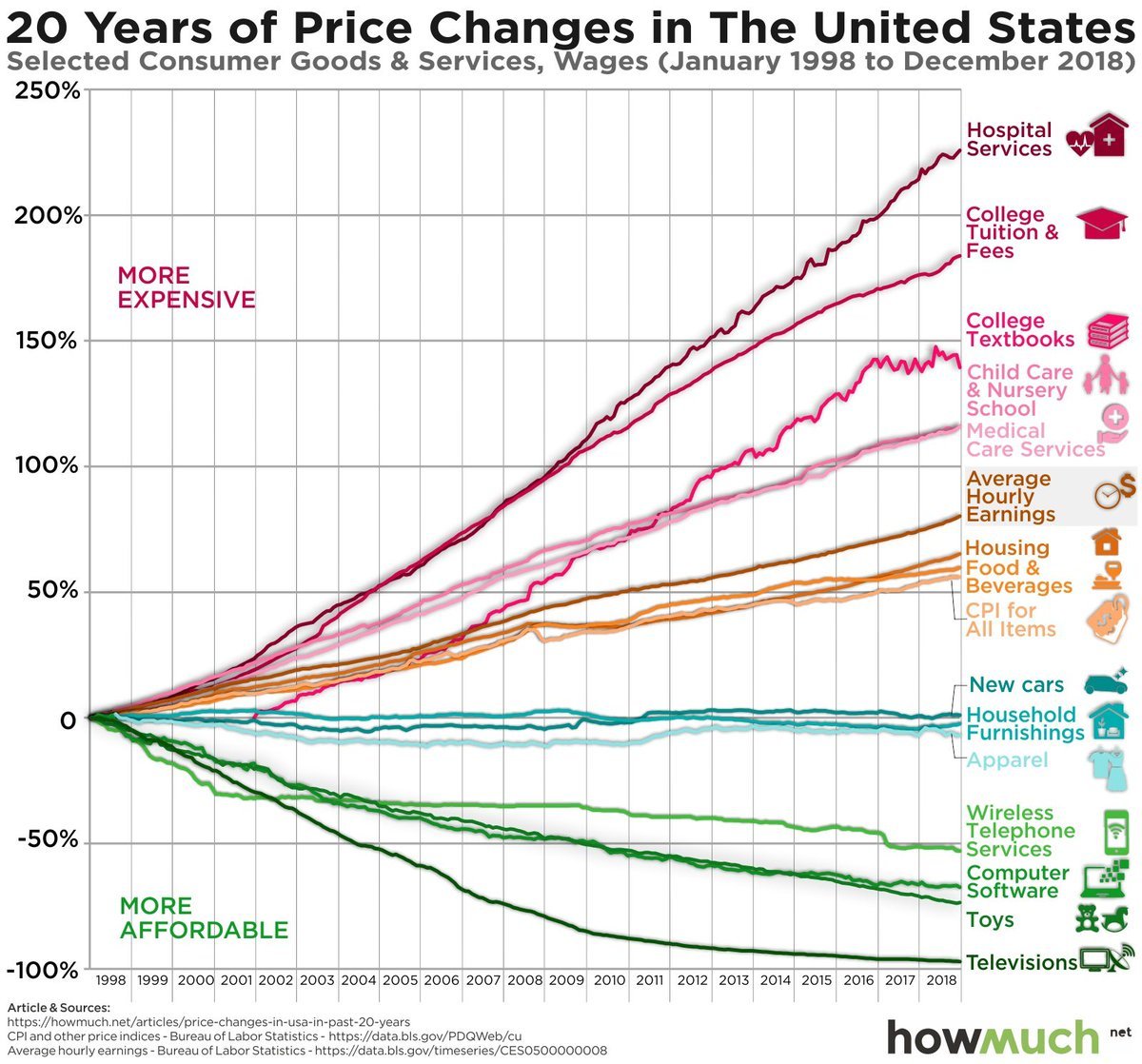
@GodOfLiberals @NYHammond the highly regulated industries have gotten much more expensive. the unregulated free markets have induced competition that drives down prices (and increases value in most cases too). you should want more doctors and more insurers competing to earn your business https://t.co/HMgMvBK63U
Few student-athletes have ventured to the championship heights that @XcellentTea climbed to at St. X. His elite leadership skills provides a path to continue that level of impact today. Thanks to our “Thursday Tiger” for the vision of what we can do together. https://t.co/lCM8bQjJzX

Today, we're introducing Butter. For 20 years, social media has been built for audiences. A feed. Followers. Boxes with a like button. But friendship was never supposed to be followed. It was supposed to be experienced. Butter is the first social software platform, where you don't just react, you interact. It’s a place where friends create mini-apps to match every flavor of friendship. Whip up a time capsule with your college group. Make a leaderboard for the worst decision of the month. Spin up a bracket to settle the best taco spot once and for all. All of your minis connect into one space for your crew, slowly building a shared world that could only be yours. Because friendship deserves a place to live. A real home. Welcome to Butter Join the waitlist: https://t.co/x3q3Y8rgeV ❤️

Looks like a (professional, maybe LinkedIn) connection! #LDATalks @MileWideBeer https://t.co/JQmrMy8J16

John with @maker13indiana presenting on the awesome space. #ldatalks https://t.co/GiBZAiKytb

.@kfreberg bout to drop some influencer knowledge on us at #DigitalCrossroads https://t.co/Avlkjcp5re

Tips for vetting influencers from @kfreberg #DigitalCrossroads https://t.co/6q3pyyCOvZ

Thank you @cctark, @legacy_comm, & @cbucysmith for sharing the stage at #DigitalCrossroads to discuss the landscape of digital talent, health of the industry, and how to grow digital talent here in #Louisville https://t.co/fzFcNOrpJZ

Get @dberkowitz’s slides from today’s #DigitalCrossroads preso here: https://t.co/94OrlLZLgw https://t.co/p2d0hfb8BQ

You may know @YelpLouisville for its reviews and food pics, but its mission is truly centered around community. #DigitalCrossroads https://t.co/nvSBstQDXg


What’s on deck for the future of content marketing? @edeckers tells us at #DigitalCrossroads https://t.co/9jHIeq0tjL

What a night with @PurdueFoundry and @ndideacenter - Thanks for hosting us! Congrats to all the great companies and winners! @GarrettGoldberg @BeePartners, @sunilnagaraj @flyovercapital https://t.co/FMUzKvtcj2


Was reminded of the value of voice when a huge-name investor rang my cell phone in response to an email inquiry. I hadn't expected even an email, but a <3min phone call was far more clear and faster too. Also, Me: #MidasListSkills #itsOKtotalktohumans https://t.co/wrFzK6mM2c

Former marine Richard Browning - nicknamed the "real-life Iron Man" - showed off the jet pack his company has developed at a Royal Marines assault course in Lympstone, Devon. 🚀🚀🚀 For more, head here: https://t.co/UrAgKlH7hK https://t.co/ssSyW0FEdS
@googlefiber @cityresearch Hey can we keep the bucket lids your contractors left as “covers” in our muddy yards? https://t.co/AhFYBBHRkW

@savasavasava @ccprek Hey, it's fine. We get these bucket lids as covers in our muddy yards - they said we could keep them. https://t.co/ogRmvnFklj

