Your curated collection of saved posts and media
@msdev https://t.co/1rvNYReIrE

🤖 What happens when multiple agents take on the same challenge? We're about to find out live! 🔴 Join us: https://t.co/gvlUJvtgdr https://t.co/H2xzrMXW8t

🤖 What happens when multiple agents take on the same challenge? We're about to find out live! 🔴 Join us: https://t.co/gvlUJvtgdr https://t.co/4b8yP2V4Ru

🎬 We're live in five! Join the VS Code Livestream at 9 am pacific as we build agents that listen, learn, and act with Redis Agent Memory, Copilot, and a little bit of ham radio 📺 https://t.co/Ud1S5WzqQD @guyroyse https://t.co/8rIi4Nd8j1

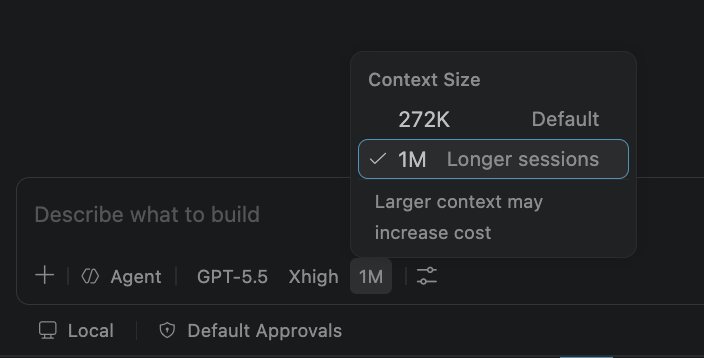
1 million context window and configurable reasoning levels are now available in GitHub Copilot for @code, Copilot CLI, and Copilot app developers. https://t.co/X4zkWqMse2 https://t.co/oxPQHWqHDr

🚀 Access your local developer tools, SDKs, and all of your workspaces from the browser, your phone, or another desktop. Everywhere, all at once!! In today's video we demo the new Dev Tunnels capability inside the VS Code Agents window (Preview) ▶️ https://t.co/JMySNto5EW https://t.co/gKp0NWAKmG

🦆 In today's video we're showing how to use rubber duck debugging in VS Code and GitHub Copilot CLI to explain your code out loud so you can catch your own mistakes! ▶️ https://t.co/3zU1Stw8IA https://t.co/55w17X2Bzp

✍️ Check out today's video for a roundup of the latest Markdown preview improvements in VS Code, including a new diff view, link validation that catches broken references to headers and HTML IDs, and drag-and-drop support for images. 📺 https://t.co/KhEoPWggYU https://t.co/j43YSY482h

📣 Claude Fable 5, the first in @AnthropicAI's Mythos model class, is now generally available and rolling out in GitHub Copilot. It is designed for long-horizon, autonomous coding and knowledge-work tasks. Try it out in @code or the GitHub Copilot app. ⬇️ https://t.co/jJTqh35jjY https://t.co/tM3L1znxV2

Mermaid diagrams are now built directly into @Code. 🎉 No extra extension required. 🙌 https://t.co/SO9ZbNSpse
🚀 In the latest @code release, the Agents window (preview) lets you send sessions to the background, switch between them with a searchable picker, and get more editor space with a single click. Autopilot is now enabled by default and knows when a task is truly done, instead of stopping too early or looping too long.
🔎 More in @code this week: the integrated browser now remembers your visited pages and lets you customize which actions stay visible in the toolbar. Enterprise admins can also centrally manage which agent plugins are available to their team. 🔗 Full release notes: https://t.co/WSOKpU9eCI

🎥 Join our Release Livestream on June 18 to see the team demo some of the latest features live! Register here: https://t.co/mZjRI1kOT0 Happy coding! 💙

More model choice for every developer. 🚀 MAI-Code-1-Flash is now available to GitHub Copilot users in VS Code. Give it a try and share your feedback with us. https://t.co/8hahuZyuny
MAI-Code-1-Flash is now rolled out to 100% of GitHub Copilot Free, Education, Pro, Pro+, and Max subscribers in VS Code. Copilot CLI roll out and Enterprise/Business preview on its way. Give it a try and let us know what you think!

The Integrated Browser in @Code just got more useful. 🌐 ⭐ Favorites 📸 Full-page screenshots ✂️ Partial screenshots Small additions, but they make it much easier to research, test, document, and stay in flow without leaving VS Code. https://t.co/W55qWsFrsi
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵 https://t.co/UziUGbIPdU

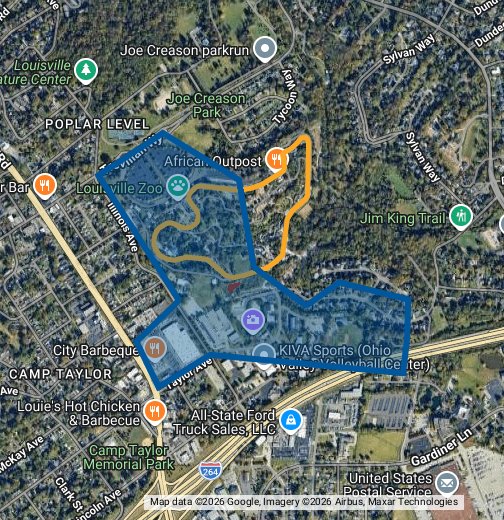
@LouDataOfficer @ThomasNewman @phillipmbailey @LouisvilleZoo @WLKY @MegaCaverns Rough map of @MegaCaverns footprint, and collapse location at @LouisvilleZoo : https://t.co/HPaKh3FLY9
<— Sunday’s @courierjournal. Saturday’s Courier Journal. —> https://t.co/cIZ5ReHPJM

@cyclingat10mph @Streets4Peeps @CompleteStLou @louisvillemayor @CouncilmanJames @LMPD I saw the collision aftermath and assisted this pedestrian in front of the Cathedral of the Assumption Sept 13 just before 5pm. I’m not sure he survived. I haven’t seen any news coverage of the incident. https://t.co/CyflSvvn3y

It's a shame the new owners (Barrel House Investments: Askley Blacketer and Chad Middendorf) let this 130 yo rickhouse w/ 25,00 sq ft fall apart since 2013. I used to work at @DistilleryCmns and the then owner of this building Ray Schuhmann maintained it and kept birds out. 1/x https://t.co/qDZRKp4GUb

Going to start talking to council people like @BSextonSmith & @LouMetroPDS about how to prevent this 130 year old piece of bourbon history from being destroyed. Here is this whole thread, images, links on one web page for people to link to and reference: https://t.co/XC8fXOUzCj
It's a shame the new owners (Barrel House Investments: Askley Blacketer and Chad Middendorf) let this 130 yo rickhouse w/ 25,00 sq ft fall apart since 2013. I used to work at @DistilleryCmns and the then owner of this building Ray Schuhmann maintained it and kept birds out. 1/x

Louisville gets on street dining options! One month free trial for restaurants paid for by city (barrier rental, car meter costs) with @CycLOUvia funds. @LOUPARC has reduced metered parking bag rates after that. Apply here: https://t.co/JWFAIfpZqu https://t.co/0pKaK33aoS


@MichaelMobility @cityresearch @stadsbeeld @MonnikBeer @UDStudioLou @DanielHSanders3 Looks like the city has a plan for other places. @stadsbeeld did you have a hand in that too? https://t.co/bwfR39kNnU
Louisville gets on street dining options! One month free trial for restaurants paid for by city (barrier rental, car meter costs) with @CycLOUvia funds. @LOUPARC has reduced metered parking bag rates after that. Apply here: https://t.co/JWFAIfpZqu https://t.co/0pKaK33aoS

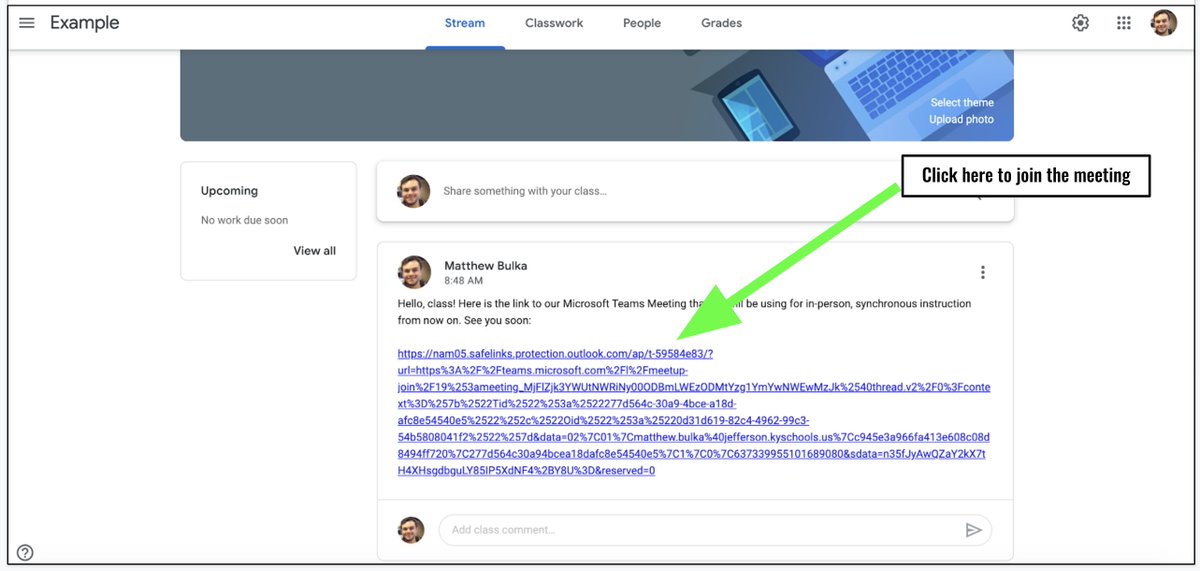
Ok, the @JCPSKY switch to @MicrosoftTeams is going to be painful for students and teachers! Let me explain. Here's a video of the process: https://t.co/iZCVMkXaB8 And here are the steps each time: 1. Teacher makes a new meeting and puts the link in Google Classroom. <thread> https://t.co/ir3DcKachx
This is one of my favorite books of all time, and one I recommend to everyone who asks for a recommendation whenever I get the chance It paints a beautiful picture of the very different world that used to exist, one where greatness was still prized more highly than equality and equity, and so men did great things They built magnificent homes, gorgeous palaces, and immense empires. New men built businesses the scale of which had never been seen, and the old elite pushed high culture to its greatest flowering. Those who were talented could and did rise, and those who were incompetent quickly lost it all and fell away It was a world of consequences good and bad, of rewards for excellence and punishment for falling behind It was a world of pride and hauteur, but also of public faith and policy rooted in a deep and abiding belief in Christianity It was a world before tax policy punished the competent for the benefit of the incompetent, a world before the disastrous equality of the present And in this book, Emmerson shows what that world looked like, good and bad, and how it functioned Such is the best way to jump into remembering that a different world used to exist

Retirement strategy is to work hard, save money, stay healthy, and build an astonishing library that I can spend the last 2-3 decades of my life reading at leisure. https://t.co/EpnomiQgHP

“I think that the legislature by adding this 20 basis point tax truly is telling you to pack your bags and move.” @AndoniOlta, Executive Director of @ILBlockchainIBA, on what Illinois’ new 0.2% crypto tax could mean for the state’s crypto industry. https://t.co/Tfor1jXsN6
In 1903, the French government expelled the Carthusian monks from their monastery in the Alps and seized everything they owned. The monastery. The distillery. The equipment. All of it. There was just one little problem. Only two monks in the entire order knew the recipe for Chartreuse, and they had memorized it. There was nothing written down that the government could take. The French government hired chemists to reverse-engineer it. They analyzed every bottle they could find. They ran every test available to early 20th Century science. They could not replicate it. The liqueur they produced under the Chartreuse name was so inferior that it destroyed the brand almost immediately. Sales collapsed. The company the government set up to produce it went bankrupt in 1929. The monks, meanwhile, had relocated to Tarragona in Spain and were producing the real thing the entire time. In 1929, the same year the French government's operation went under, the monks quietly bought back the rights to their own name and returned to their monastery. The recipe is still known by exactly two monks at any given time. When one dies or becomes too ill to continue, he passes his portion to a successor. The full recipe has never been written down in a form that has left the order. Chartreuse is made from 130 Alpine plants and herbs. The monks tend the distillery themselves. They take no outside employees into the production process. The 1605 manuscript that started all of this is still held in the monastery archive. The French Third Republic lasted from 1870 to 1940. The monks are still there, still making Chartreuse. © Eats History #drthehistories

Wholesale blank apparel coming next month from Anatar. Grown here. Sewn here. Register your interest at https://t.co/2KExFMFBzK https://t.co/QyLUZ7vNOD

You can't see him, but I swear @nowsourcing is speaking the truth that we all need to break down silos in Louisville http://t.co/uBWgI5Wuff

So the only good local beer at @MellowMushroom in Louisville is @fallscitybeer. Just saying. http://t.co/x7i04SyFAz

.@zackpennington kicking off @SWLouisville. Get your pitches ready! #swlou http://t.co/aBUMQQmQC5
