Your curated collection of saved posts and media
- Netherlands - Lithuania - Estonia - Denmark - Belgium https://t.co/aepKw5oNuM
- Netherlands - Lithuania - Estonia - Denmark

The Best of TED 2026 IMHO Community Notes is one of X's greatest advances, a breakthrough in social engineering with a distributed, scalable truth-seeking algorithm. My photo from the front row here (showing a peek into what's to come), and full video: https://t.co/aimfvn6cW5
My interview from TED with @kcoleman and @audreyt just went live! Tons of gold in here: -why we stuck with crazy principles like not having an override button -how AI and humans collaborate to write better/more notes than either on their own -how much impact community notes are


Building with the best @SpaceX @xai @grok Download Gopuff to try Go. Link in bio. https://t.co/b8K4BaELIn
For centuries, the scientific method has been our best tool for progress. But today, there’s so much data out there that it’s impossible for any one researcher to connect all the dots. We want to fix that: Introducing Gemini for Science, a collection of science tools and experiments designed to accelerate the speed and scale of scientific exploration. Read on to learn more about each announcement in this inaugural set 🧵👇
We are also launching Science Skills, a specialized bundle that integrates insights from 30+ major life science models and databases with agentic platforms like @Antigravity to allow researchers to perform complex, manual workflows in minutes. To learn more on how to use Science Skills visit: https://t.co/1r9vxWaFdi

We're building Gemini for Science with and for the scientific community. In collaboration with 100+ institutions and a trusted tester community that ranges from PhD students to Nobel laureates, we want to make sure this tech is responsible and rigorous enough to tackle real-world problems. Read the full update here: https://t.co/lEZ5MBhgdJ

Look back at last week’s I/O announcements with @NotebookLM. You can listen to an audio overview, watch the video recap, and even check out our detailed slide deck summarizing all of the biggest news and launches. Check it out here: https://t.co/AIhdaw05b9

We wanted to see if we could take simple, physical materials (like cardboard and markers) and use AI to bring them to life. What was the result? A short film starring a bunch of TPUs getting ready for the big stage at Google I/O 2026! Working with director Laurie Rowan and Nexus Studios, we kept human artistry at the center of the film by blending puppetry and 3D animation with our models to do the following ↓ Nano Banana: Generated beautifully stylized first frames from the raw puppet footage and basic 3D animations. @GoogleAIStudio: Built a custom tool inside the platform to test these frames at scale, ensuring pixel-perfect consistency Gemini Omni & experimental @GoogleDeepMind Models: Merged the base animation and stylized frames to elevate the final piece to a cinematic level. Our AI pipelines were specifically designed to protect the crafty details that give these films their heart, like the tiny human imperfections of puppetry, or the nuance an animator can build into an expression.
Omni feels like magic 🤩 https://t.co/YEjCecsB2Y
Give yourself super powers https://t.co/SrZdblR1Fz
Omni feels like magic 🤩 https://t.co/YEjCecsB2Y

Google Flow is now powered by Gemini Omni. Upload your videos and edit them within the platform with the new Agent feature. It keeps the movement, audio and character intact whilst making edits in your scene. Here's a quick tutorial: https://t.co/w9WrVNe2Xv
Change your background https://t.co/E8OW9lQtR8
Google Flow is now powered by Gemini Omni. Upload your videos and edit them within the platform with the new Agent feature. It keeps the movement, audio and character intact whilst making edits in your scene. Here's a quick tutorial: https://t.co/w9WrVNe2Xv

Cool video outpainting results with Gemini Omni https://t.co/V0y5KvOnd2
Expand your background https://t.co/wSIeTFklGD
Cool video outpainting results with Gemini Omni https://t.co/V0y5KvOnd2

Round 2 with Gemini Omni. 🎬 This time, I tested identity consistency through pure absurdity. 20 extreme environments, 20 completely mismatched jobs. A corporate suit in the Amazon, a lifeguard in the Sahara, and a knight in the London Underground. Master prompt is in the replies. Which job fits me best? 👇
Watch your avatar explore extreme jobs in extreme locations https://t.co/UdetKntO5o
Round 2 with Gemini Omni. 🎬 This time, I tested identity consistency through pure absurdity. 20 extreme environments, 20 completely mismatched jobs. A corporate suit in the Amazon, a lifeguard in the Sahara, and a knight in the London Underground. Master prompt is in the repl

Sigo jugando con Omni! Efectivamente el modelo desbloquea un montón de casos de uso (e.g. traducción) que antes requerían de concatenar varios modelos diferentes: Traducción → Voz cloning → Avatar lip-syncing... Ahora todo se reduce a un prompt
Watch your avatar speak Spanish, English and Japanese https://t.co/8BRriqnfzO
Sigo jugando con Omni! Efectivamente el modelo desbloquea un montón de casos de uso (e.g. traducción) que antes requerían de concatenar varios modelos diferentes: Traducción → Voz cloning → Avatar lip-syncing... Ahora todo se reduce a un prompt

Gave google omni a sketched camera path and asked it to generate drone POV footage. https://t.co/cQZFMtOkEi
Draw a path that a drone can follow https://t.co/dpOgAcl7yt
Gave google omni a sketched camera path and asked it to generate drone POV footage. https://t.co/cQZFMtOkEi

Hear the architects of Gemini reflect on their journey to continue pushing the frontier of AI, on this episode of Release Notes. @JeffDean, @koraykv, @OriolVinyalsML, and @NoamShazeer sit down on camera together to share a behind-the-scenes look at the people behind the model, and how they saw the vision come together.
Today, we released Gemini 3.5 Live Translate, our latest audio model for live speech-to-speech translation. It supports over 70 languages and starts translating as soon as you start talking, streaming translations while listening to what you say next. No awkward pauses or choppy audio, just real connection without language barriers. So, how does it work? 🤔 The model is able to make split-second decisions to juggle speed and translation quality so conversations actually feel fluid, human, and natural. In order to do this, the model must receive and contextualize the input while simultaneously outputting the translated speech. Through this process, Gemini 3.5 Live Translate manages to stay mere seconds behind each speaker and can even maintain pacing, pitch, and intonation across extended sessions. See it in action below, or try it yourself in the Google Translate app on iOS & Android.
Read the blog to learn more: https://t.co/vmrrdu7lwt

Earlier this month, our run-rate revenue crossed $47 billion. This growth has been driven by organizations across many industries deploying Claude in their core operations, and by a growing number of people using it for their everyday work. Read more: https://t.co/V1fdqOxQdY

We’re expanding Project Glasswing. We’ve extended access to Claude Mythos Preview to approximately 150 additional organizations, based in more than fifteen countries. Read more about this expansion and our future plans for Project Glasswing: https://t.co/QrtHSBdRbh
This Executive Order is an important step in strengthening America’s leadership in AI. We look forward to collaborating with the White House to support its implementation. https://t.co/ZwDimPrp3t

How well do the security community's techniques hold up against AI-enabled cyberattacks? We examined 832 malicious accounts and mapped their activity onto a longstanding database of tactics and techniques used by threat actors. Here's what we learned:https://t.co/fgOqJRh2rx

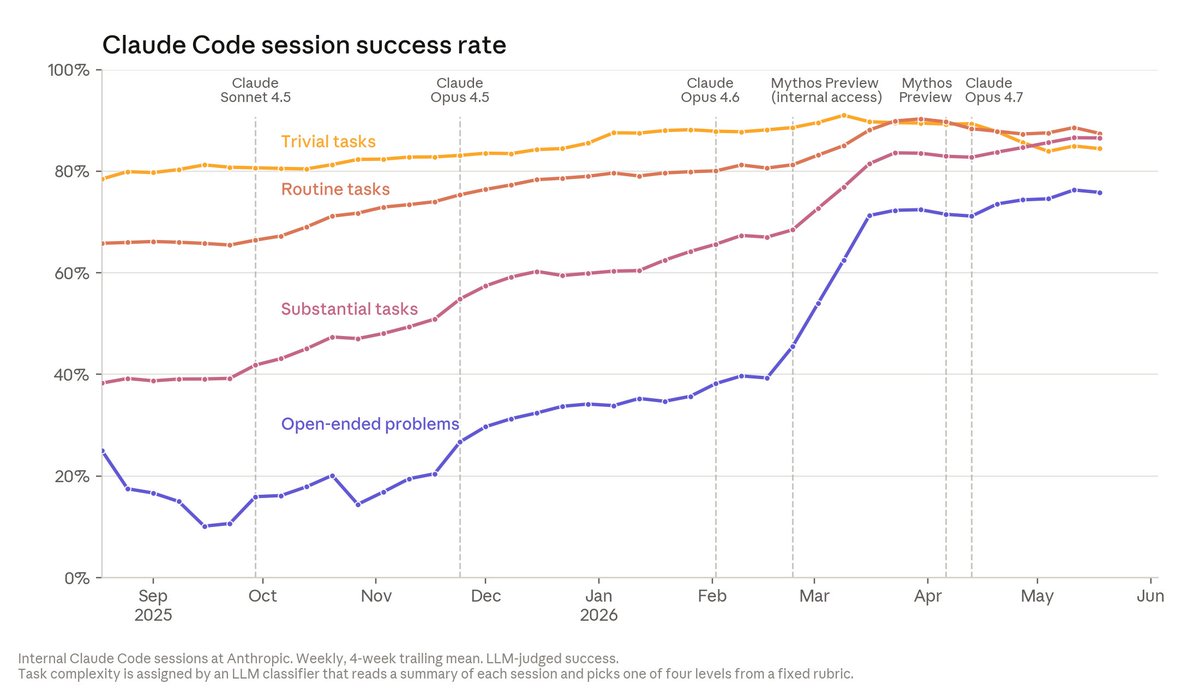
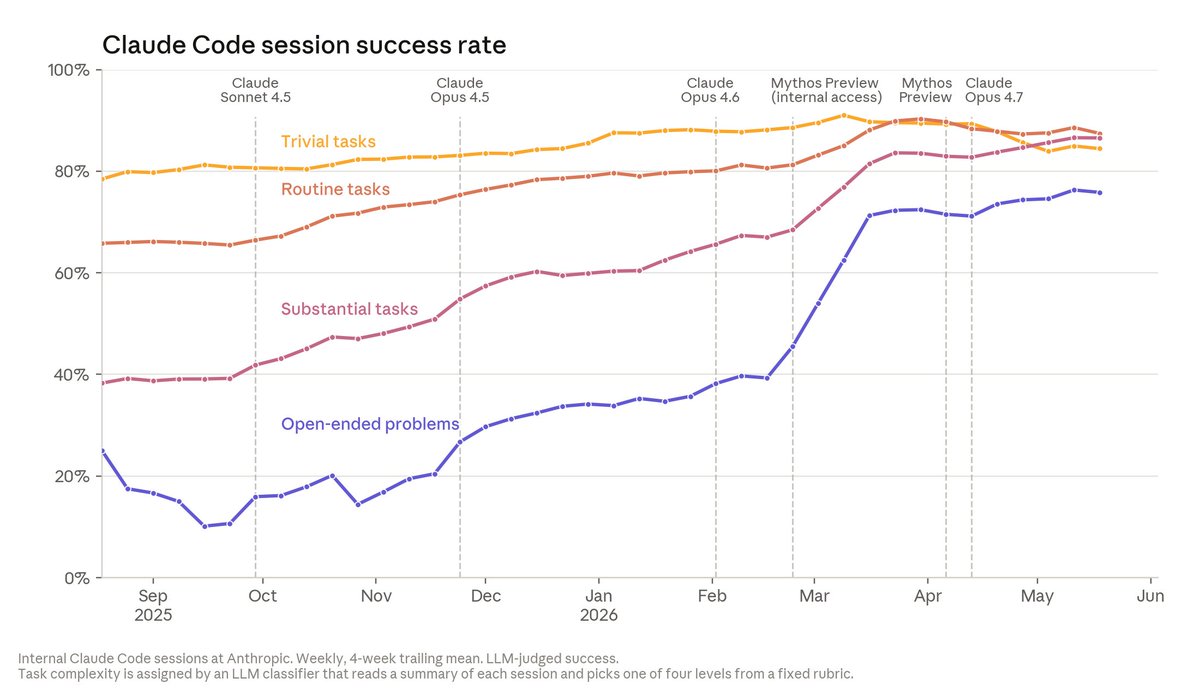
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor. It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx

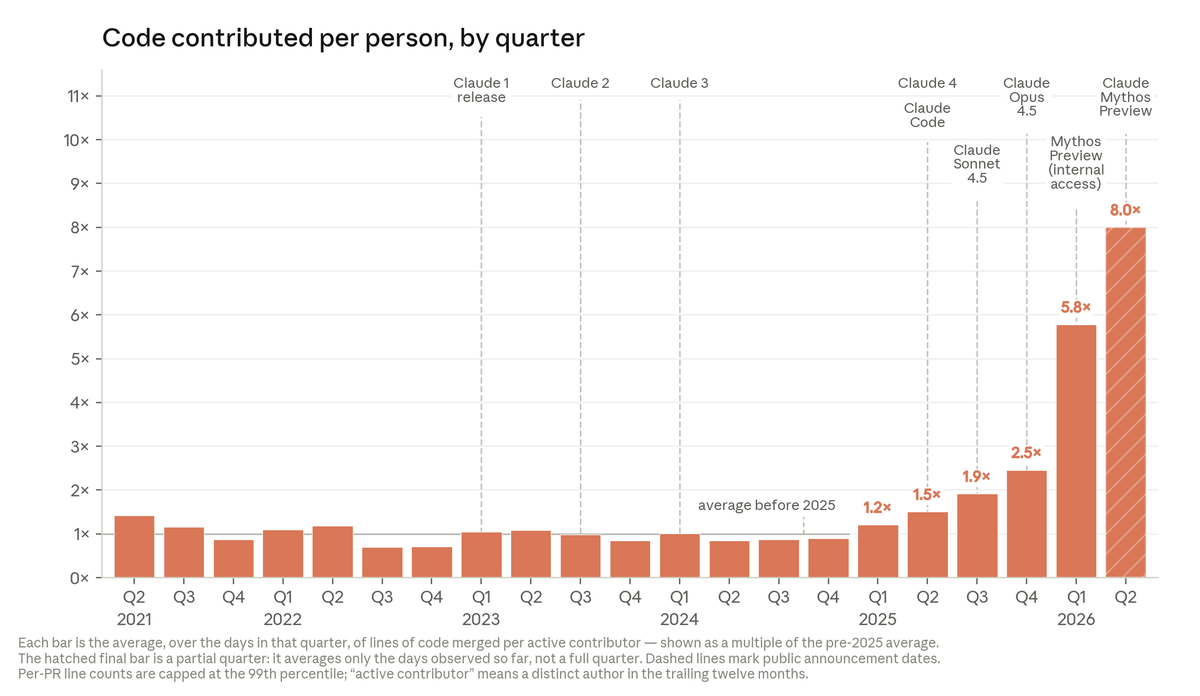
Today, Anthropic engineers on average ship 8x as much code per quarter as they did compared to 2021-2025. https://t.co/QCc9cqGgf4
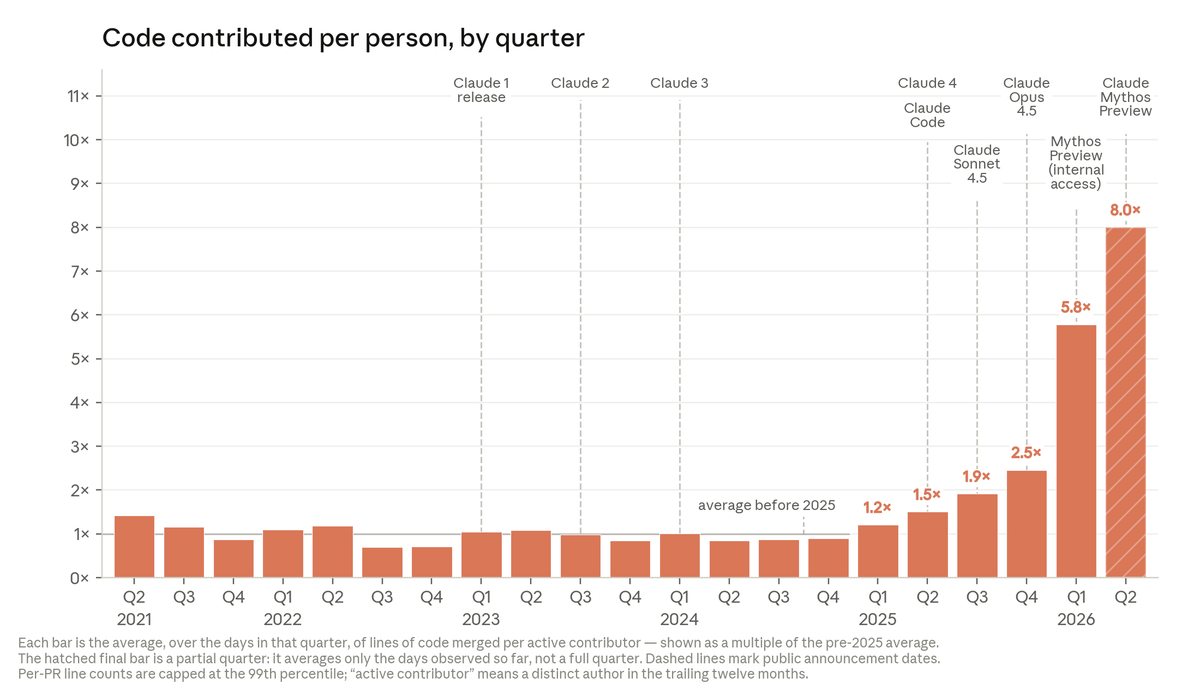
The speedup isn’t just in volume. On open-ended coding problems where answers are unclear, Claude’s success rate is now 76%—a 50 point jump in just 6 months. Many engineers also say Claude’s code quality is now on par with human code; we expect it to be better within the year. https://t.co/SXWKlAYuak