Your curated collection of saved posts and media
Build on-device AI with ExecuTorch on @Snapdragon . The ExecuTorch Hackathon brings developers to San Francisco on June 27–28 to build and optimize real-time AI applications that run directly on Snapdragon-powered mobile devices. Participants will build on Samsung Galaxy S25 Ultra devices powered by Snapdragon and receive mentorship and hands-on support from @Qualcomm and @Meta experts. Learn more and register: https://t.co/spjyl4kZJj Applications close June 15.

OpenEnv is a tool for creating an agentic execution environment, like terminals, browsers, or anything an agent can interact with. OpenEnv contributors announced that the project will now be coordinated by a committee that includes Meta-PyTorch, Reflection, @UnslothAI, @modal, @PrimeIntellect, @nvidia , @mercor_ai, @fleet_ai, and @huggingface. Today's announcement also notes that OpenEnv is supported and adopted by organizations including PyTorch Foundation, @vllm_project, @LightningAI, and others. 🔗 Read more: https://t.co/SaaSDwFKVk

🧠 From breakthrough research to production-scale #AI, #PyTorchCon is where the #PyTorch community comes together. Join us October 20-21 in San Jose, California. 🎟️ Register by 31 July & save $400: https://t.co/AVHdaIFT20 https://t.co/FwgerDsXER
AI agents are changing how you interact with your PC. @nvidia and @Microsoft are teaming up to enable the next generation of developers to build on-device agents on the Windows platform, with easier setup, native security, and integration with the apps and tools developers already use. This includes optimizing the ComfyUI implementation in PyTorch, enabling developers to run larger models with better performance. Read the complete blog post: https://t.co/pAJRnDqKBh

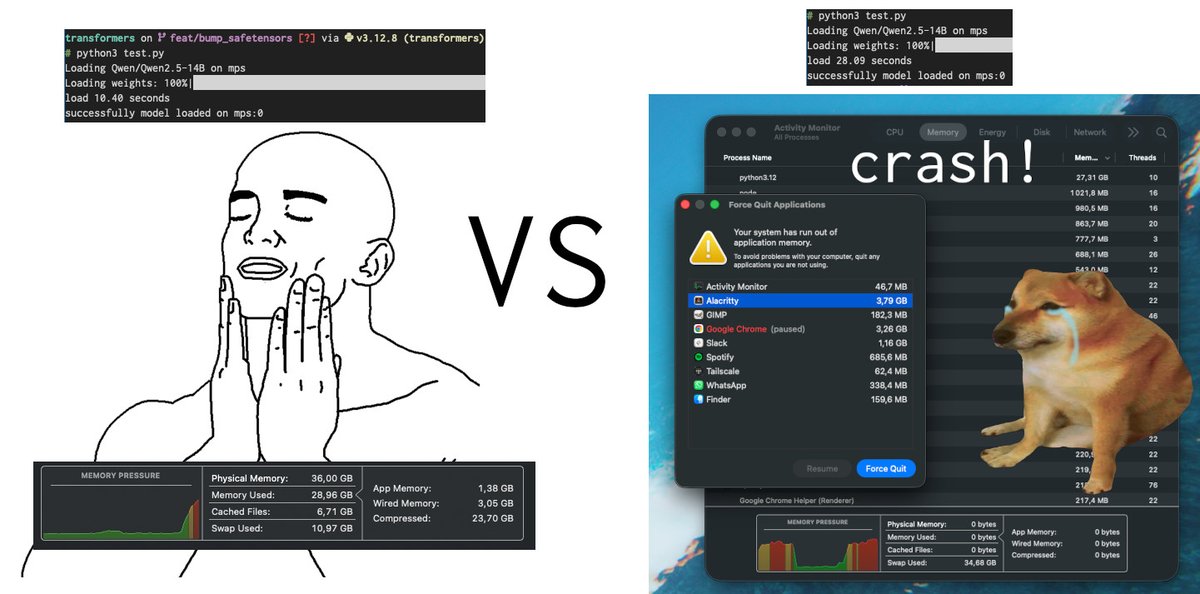
perf packed release: safetensors 0.8.0 is out ⚡️ Main takeaways: - direct copy into metal MTLBuffers + dlpack for 0-copy hand-off to target framework (only torch for now) -> 2-3x perf improvement + fixes OOMs loading models that are around the limit of unified memory on macOS when loading with transformers - GIL-free serialization, enabling multi-threaded saves from Python -> 1.2x to 2x faster for single files, but you can expect more improvement when saving multiple files in parallel! Check the release notes for the full list of improvements!
From #CloudNative to #AI and #OpenInfra: Experience the full spectrum of #OpenSource innovation in Shanghai. 🇨🇳 Event: KubeCon + CloudNativeCon + OpenInfra Summit + PyTorch Conference China Dates: Sept 8-9 💰 Save ¥710 RMB if you register by July 28! https://t.co/cChMvGvcei https://t.co/yqRITldxQD
Helion is a PyTorch-native hardware agnostic kernel DSL designed for writing high-performance kernels using a tile-programming model. In our latest blog post, Sean Chen (@RedHat) and Yanan Cao (PyTorch, @Meta) explored integrating Helion kernels with @vllm_project and evaluated their performance across a range of LLM inference workloads, showing impressive performance speedups thanks to Helion’s Ahead-of-Time autotuning and fine-grained runtime dispatching. Let’s dive into kernel fusion, framework design, and end-to-end benchmarking, showing how Helion can be easily integrated into vLLM and bring significant benefits. Read the full technical deep dive 👉 https://t.co/15zXb5Y3Kg
Submit your poster proposal for #PyTorchCon North America! Share your latest #AI, ML, #PyTorch, tooling, infrastructure, or research work with the community October 20-21 in San Jose, CA. 🗓️ Poster #CFP closes July 26: https://t.co/M7WmgnmuKJ https://t.co/Ozs2HtTFGs

Enable smarter, longer-thinking agents Scale agentic AI and reinforcement learning by shortening CPU execution time, increasing task throughput, and improving overall AI factory output. The @nvidia custom Olympus core in the NVIDIA Vera CPU uses a neural branch predictor to reduce stalls in branch-heavy code. Combined with other prediction mechanisms, it can sustain two taken branches per cycle with zero penalty, maintaining throughput for deep software stacks such as PyTorch, graph workloads, and scripting engines. Read the complete blog post: https://t.co/L6NmBJWgDY

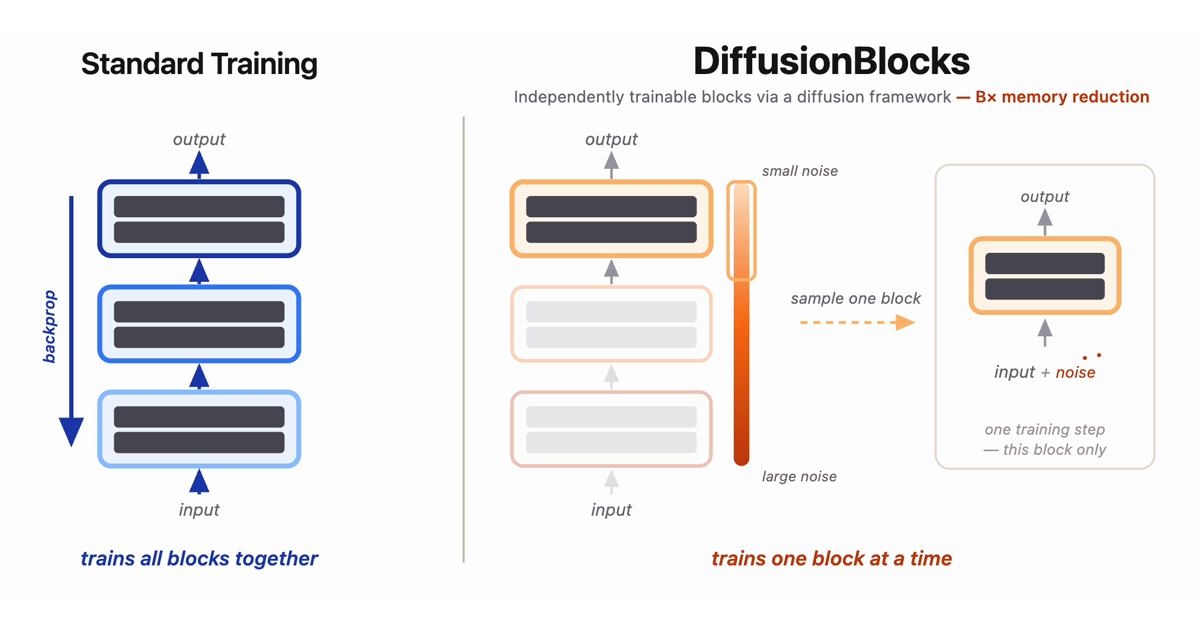
🧱 DiffusionBlocks: Training Neural Networks One Block at a Time https://t.co/zw7kehHDYc
今夜22:00放送 テレビ東京WBS (@wbs_tvtokyo) 経産省のAI開発支援プロジェクト「GENIAC」採択について、取材を受けました。弊社CEOのDavid Ha (@hardmaru) とResearch Scientistの菅沼が、私たちの戦略や日本発のAIが世界を変える可能性について語ります。ぜひご覧ください!


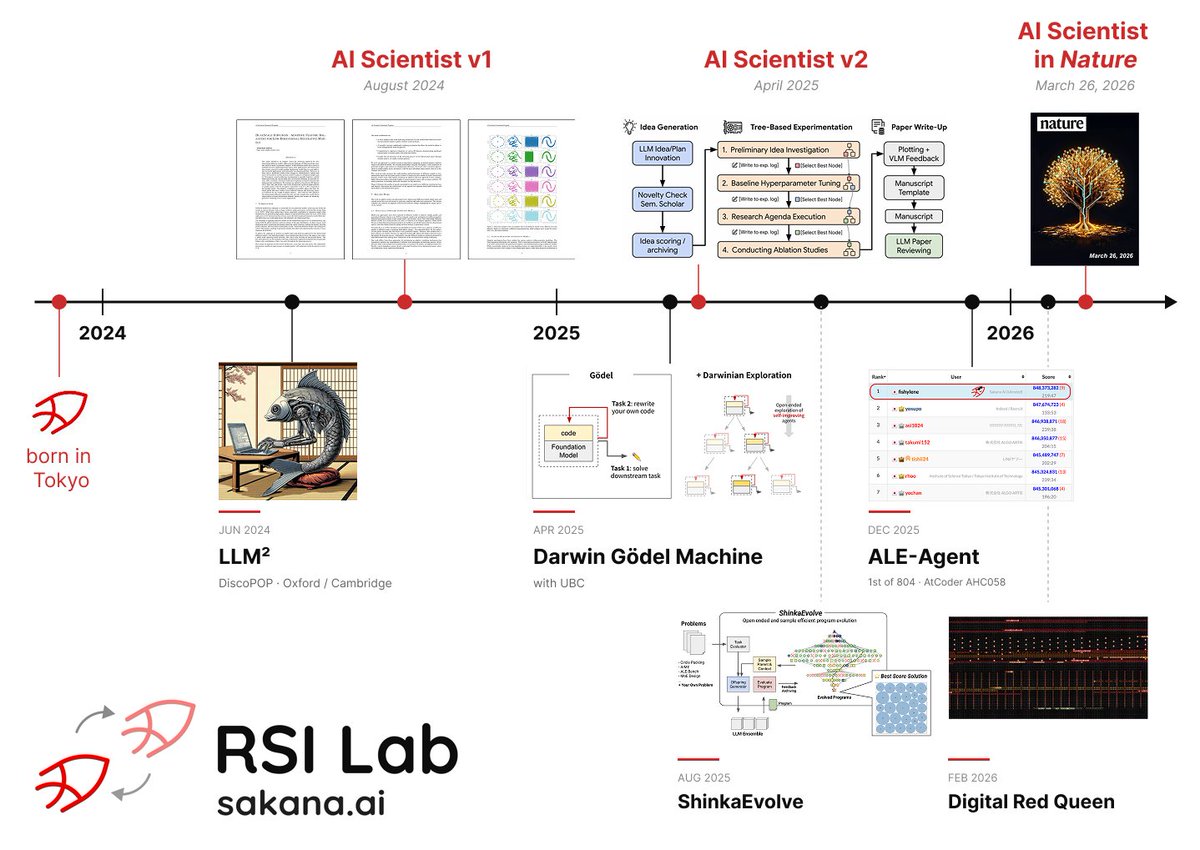
Building AI that Builds AI: Introducing the Sakana AI RSI Lab 🚀 https://t.co/AskX3J5oEJ Today, we are announcing the Sakana AI Recursive Self-Improvement (RSI) Lab: a dedicated research group in Tokyo tasked with redesigning the AI development process itself using AI. While the industry increasingly speculates about the theoretical potential of self-improving AI, we’ve spent the last two years actively laying the foundations to make it a reality: ▪ LLM²: AI models automating research to invent better preference optimization algorithms. ▪ Darwin Gödel Machine: Agents autonomously rewriting their own codebase to double software-engineering performance. ▪ ShinkaEvolve: Hyper-sample-efficient program evolution that builds novel loss functions for MoE models. ▪ ALE-Agent: Reinforcement agents outperforming hundreds of human experts via self-learning. ▪ Digital Red Queen: Open-ended adversarial coevolution laying the groundwork for RSI in cybersecurity. ▪ The AI Scientist: Towards end-to-end automation of AI research, recently published in Nature. Now, we are unifying these breakthroughs. The Sakana AI RSI Lab is officially tasked with building open-ended, adaptive architectures that collectively self-improve. Human intelligence did not emerge from limitless resources; it was forged through the open-ended, compounding process of evolution operating under strict constraints. We are applying this exact principle to AI. We believe recursive self-improvement is achievable on modest, sample-efficient compute. It shouldn’t be a winner-take-all asset locked inside hyperscale clusters, but a democratized public good. We’re scaling our team to execute this mission. We are looking for frontier scientists and engineers who are entirely unsatisfied with the brute-force status quo. If you are ready to break away from standard benchmarking and build the self-improving future in Japan, come build with us.


We’ve been laying the foundations for RSI over the last 2 years. Now, I am looking for a select group of distinguished frontier researchers and engineers to join our core RSI team. https://t.co/1eEBgLdQhY If you have a proven track record at the frontier, but find yourself entirely bored with the status quo of brute-force scaling, this is your call.
Member of Technical Staff (RSI Lab) https://t.co/ptU2Xh4aO1 If you are a visionary builder ready to move to Tokyo and engineer the engine of recursive discovery, we invite you to apply. https://t.co/ydKhZQiup8

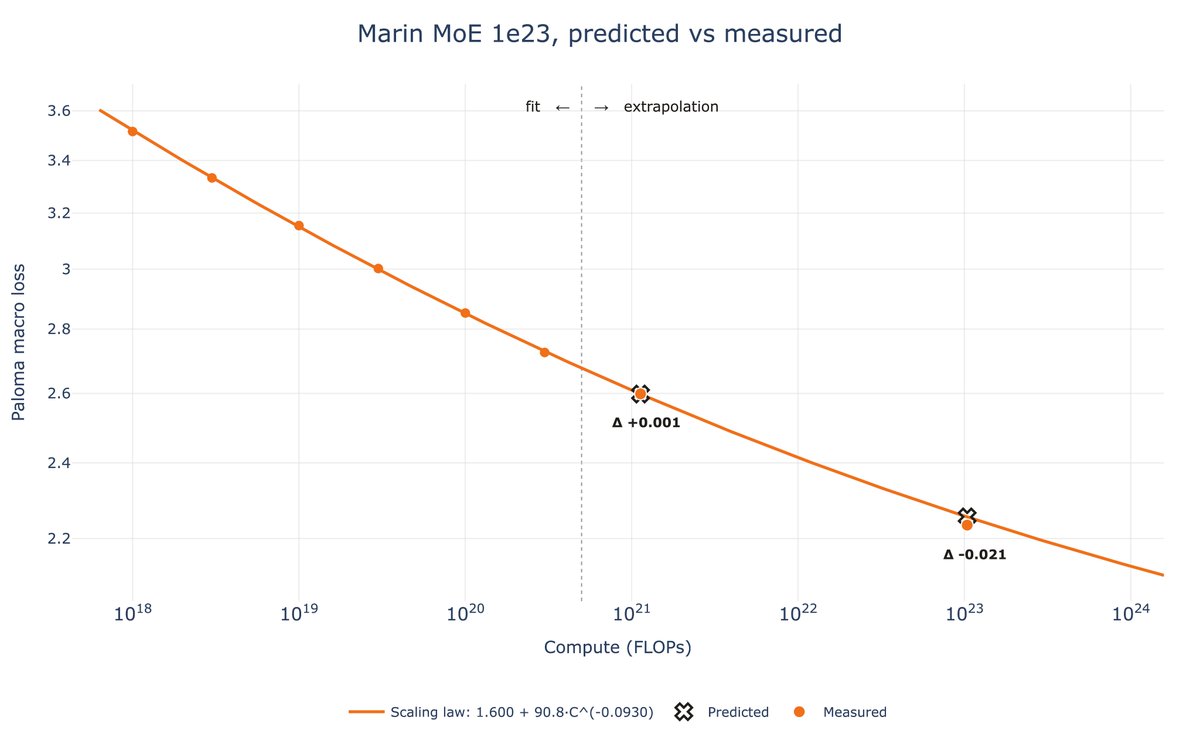
Not only do we want to train a good model, we want to know it'll be good before we even start training. About a month ago, the Marin team launched a 129B (16B active) 1e23 FLOPs MoE run and preregistered a loss of 2.252. The run finished this past week and landed at 2.234. https://t.co/OptaVa7jIO
This week, @classiclarryd kicked off a 129B (16B active) 1e23 FLOPs MoE run. In typical Marin style, we have fit scaling laws and have made a loss projection of 2.252. Stay tuned. https://t.co/QnwJ8YxT9H
A mic drop moment @ycombinator tonight @sama just offered $2M in OpenAI tokens to EVERY YC startup in the current batch in exchange for equity Just like Yuri Milner offering to invest in every startup back when Sam was a YC partner I can't wait to see what's unlocked when you let the most driven, creative and formidable founders tokenmaxx

It’s Codex Thursday, and yes, we have updates for you. First up: Appshots, a new way to bring the context of what you’re working on into Codex. On your Mac, press Command-Command to attach your app window to a Codex thread. Codex gets both a screenshot and text from the window, including content beyond what’s visible onscreen. Appshots are available across plans on Mac, with enterprise access coming soon.
AI should dramatically increase quality of life and individual freedoms for people around the world. The OpenAI Foundation is making an initial $250M commitment to measurement, transition support, and new approaches to broadly shared prosperity. https://t.co/zOD8O94RjQ

It's time to fly. https://t.co/ObUaCZ07EM
The AI race is no longer just about models. It is about energy. China’s wind-powered underwater datacentre shows how the next wave of AI infrastructure may be built around new approaches to power, cooling and efficiency. The winners in AI may not only be the companies with the smartest algorithms, but also those with the most sustainable infrastructure.


https://t.co/IVGHTjLNTf

AI safety is becoming a launch strategy. Anthropic’s release of a Mythos-class model shows how leading AI companies are trying to balance powerful new capabilities with safeguards for high-risk areas. The real test is no longer whether models can do more. It is whether society trusts how they are released.

AI may help find the next football superstar, but it should not define what talent is. Data can make scouting faster and more disciplined, but football still depends on qualities that are hard to measure: instinct, resilience, creativity and the ability to surprise. The risk is not using AI in sport. The risk is believing the spreadsheet sees everything.

https://t.co/QGVSJcNhOB

The AI race is becoming a price war. If OpenAI cuts token prices to compete with Anthropic, lower costs could accelerate enterprise adoption but also pressure margins across the AI stack. The next battle may not be who has the most powerful model. It may be who can deliver intelligence at the lowest sustainable cost.

The future of work will not be human versus AI. The people who thrive will be those who combine human judgment, creativity and trust with AI’s speed, scale and pattern recognition. The real career risk is not being replaced by AI. It is being outpaced by people who know how to use it better.
The next AI race may be won as much in factories as in research labs. China’s dominance in robot supply chains shows that building advanced AI is one challenge. Building millions of intelligent machines at scale is another. In the age of AI and robotics, manufacturing strength is becoming a strategic advantage again.

The AI IPO boom is turning into a capital tsunami. Demand for SpaceX shares suggests investors are no longer asking whether AI will reshape the economy. They are asking how much exposure they can get before the next phase begins. The biggest risk today may not be a lack of capital. It may be finding enough opportunities to deploy it.

@ScottPatterson0 @maticrobots Yeah, I'm so proud it was launched in my home here last year: https://t.co/fEkfcuLxjt We love ours for same reasons. @mehul is one of the best consumer entrepreneurs America has.
The new-fangled vacuum salesman. This is the best example I've seen of how AI and computer vision is changing consumer electronics. Here @maticrobots founder @mehul comes to my home to give me an in-depth demo (the good stuff starts about 30 minutes into the video). This al

“don’t train your own model” is common ai advice. it's wrong. your token bill's the proof. today, we’re excited to launch castform into open preview. castform is the easiest way for you to train your own model, on your own data. open-weights models are performant and much cheaper. when trained on your task & proprietary data, they beat closed models. the thing standing between you and that was weeks of plumbing & years of ml expertise. with castform, model training is as simple as prompt engineering. @castformai bring your agent traces or raw corpora. castform turns it into training data, picks the right algorithmic recipes, manages gpus, and gives you an ide to watch and chat with your model as it learns. see what you can build with castform👇
Meet Coinbase for Agents. Give your agent its own account to: → Execute trades & manage your portfolio → Run autonomously under guardrails → Pay for data & research tools via x402 (coming next week) Agentic finance is here, and it's powered by Coinbase. https://t.co/DK220fko0z
48 hours ago Apple announced its new Personal AI: Siri. Today Onairos announces Persona, the user data api to power all other Personal AI’s with context not even Siri has. https://t.co/ogBCIsM1xc
The next generation of Apple Intelligence powers an entirely new Siri: making the apps and experiences you rely on across iPhone, iPad, Mac, and Apple Vision Pro more personal and helpful than ever. https://t.co/aXiDIkqAKn