Your curated collection of saved posts and media
@beginnersblog1 https://t.co/d9ArOL64ZU
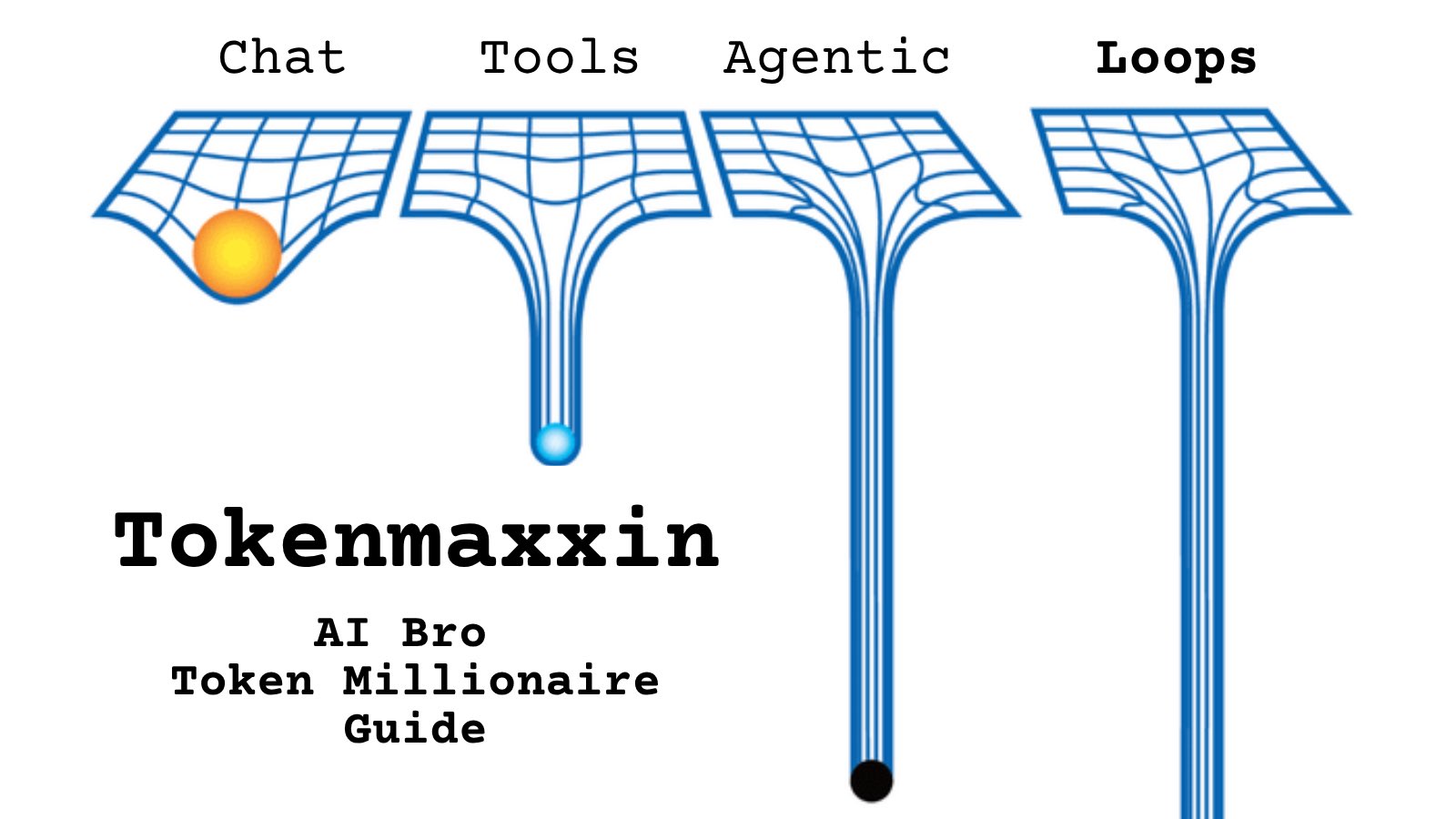
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
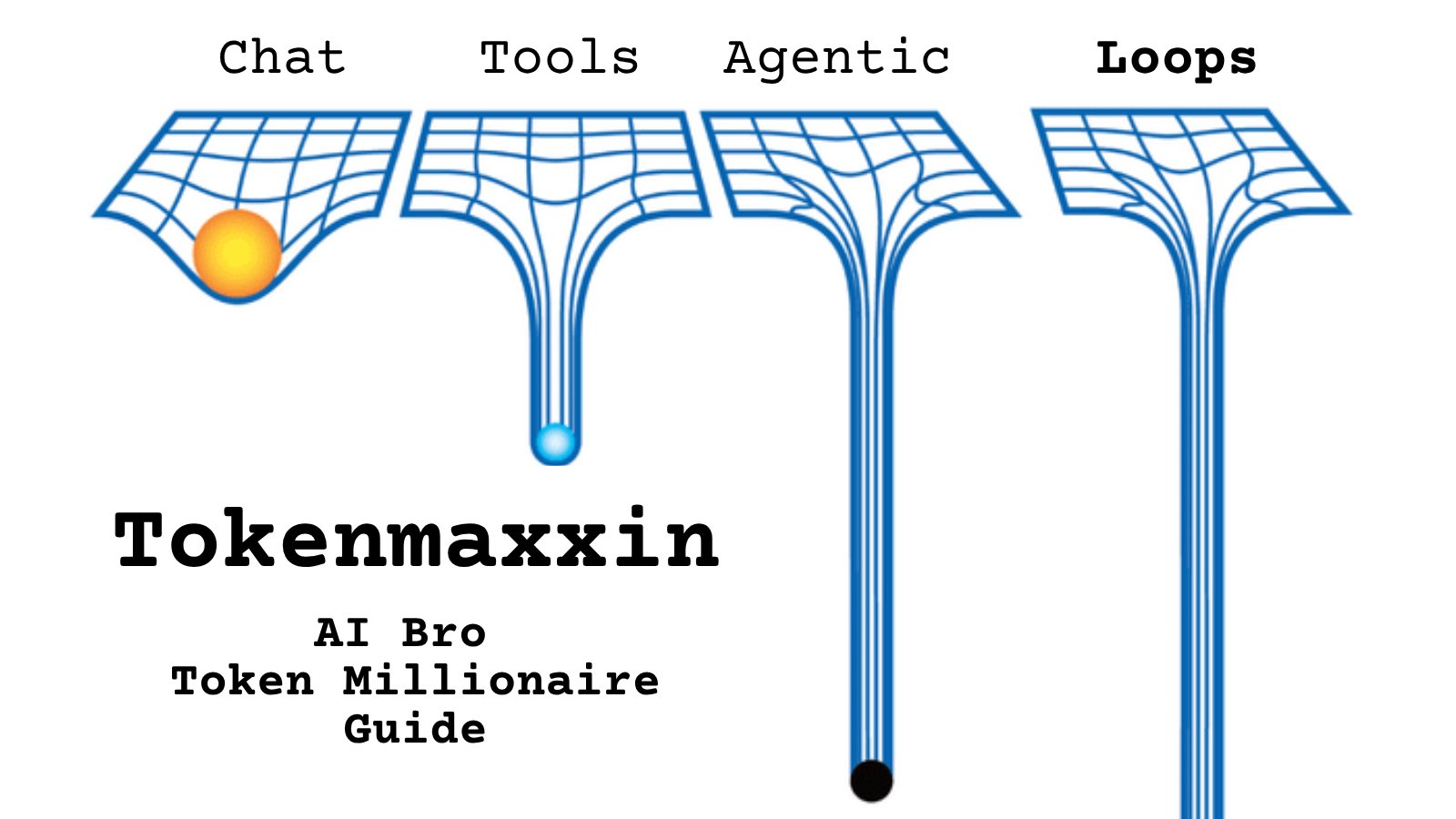
@gagarotai200 https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
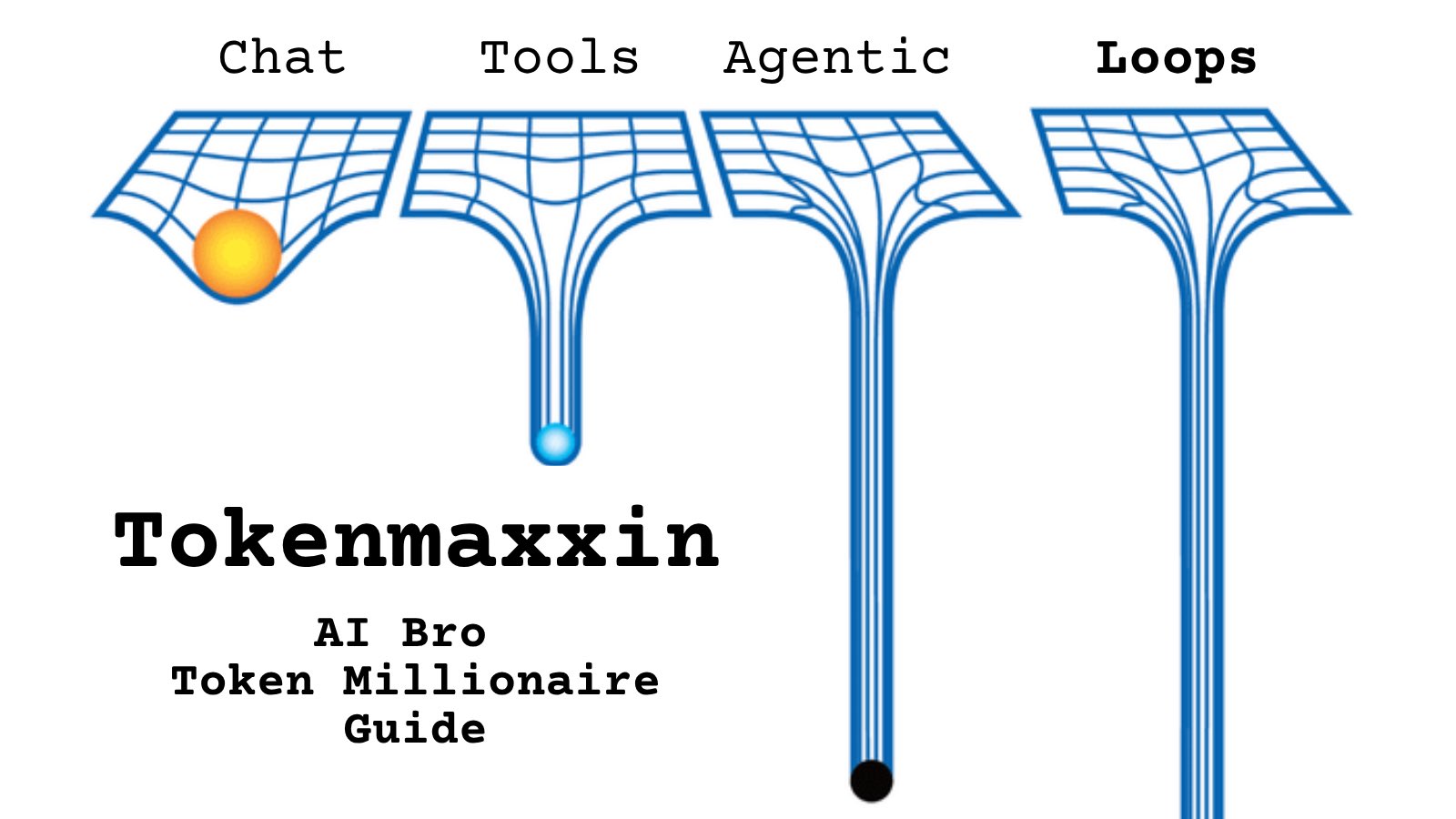
@chamath https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
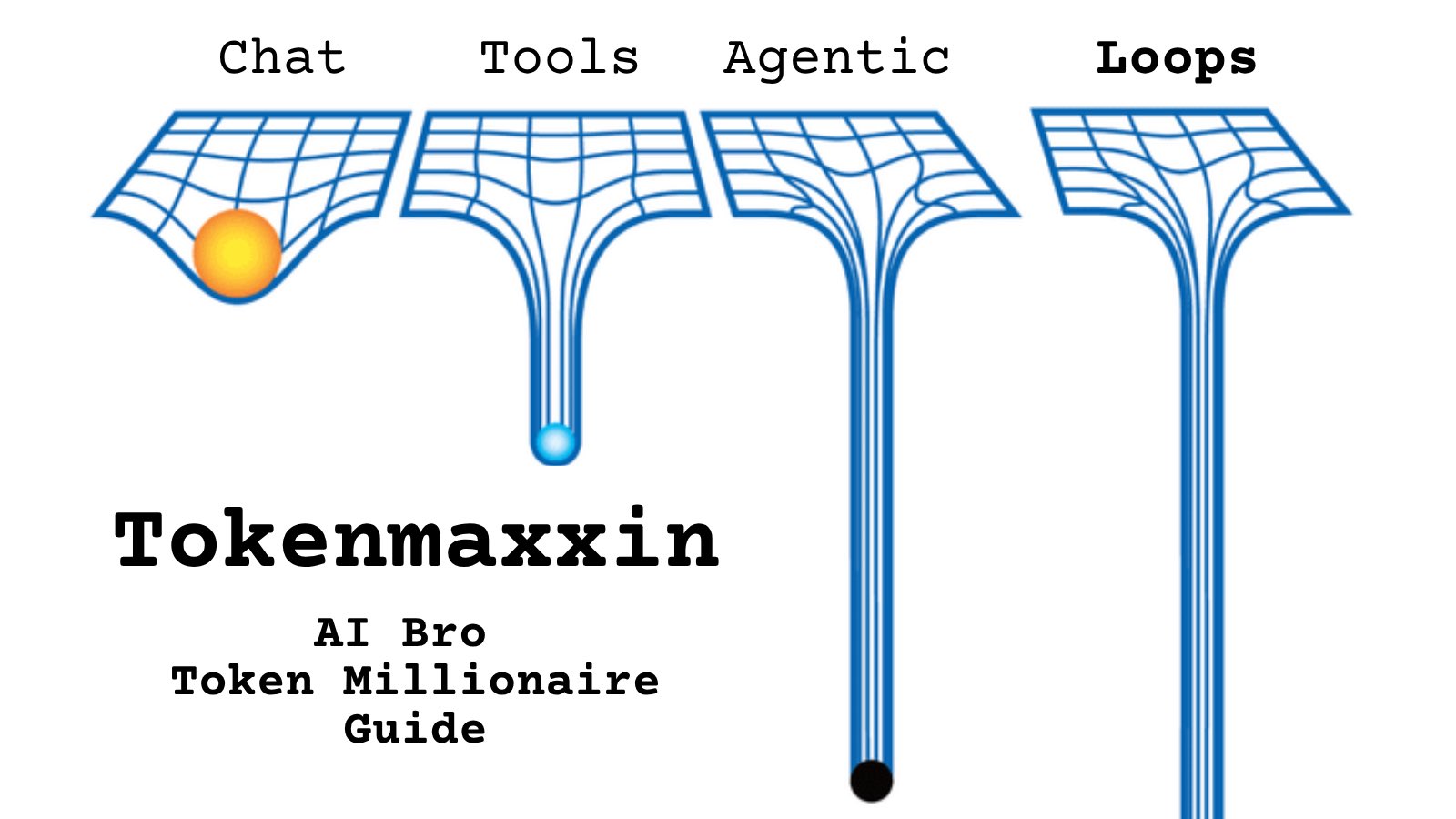
@ikuta_shizimi https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
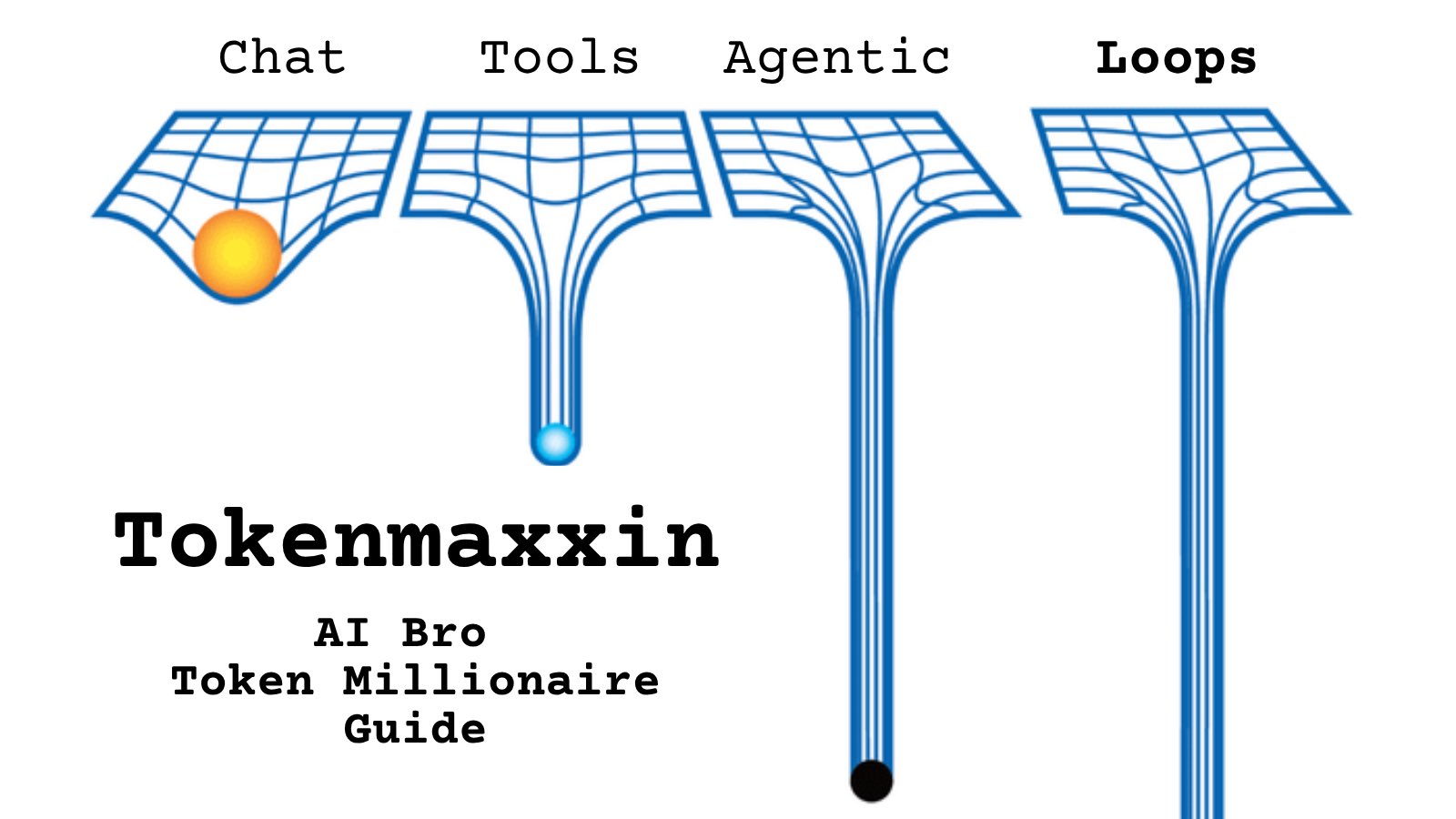
@ura6_vrc https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
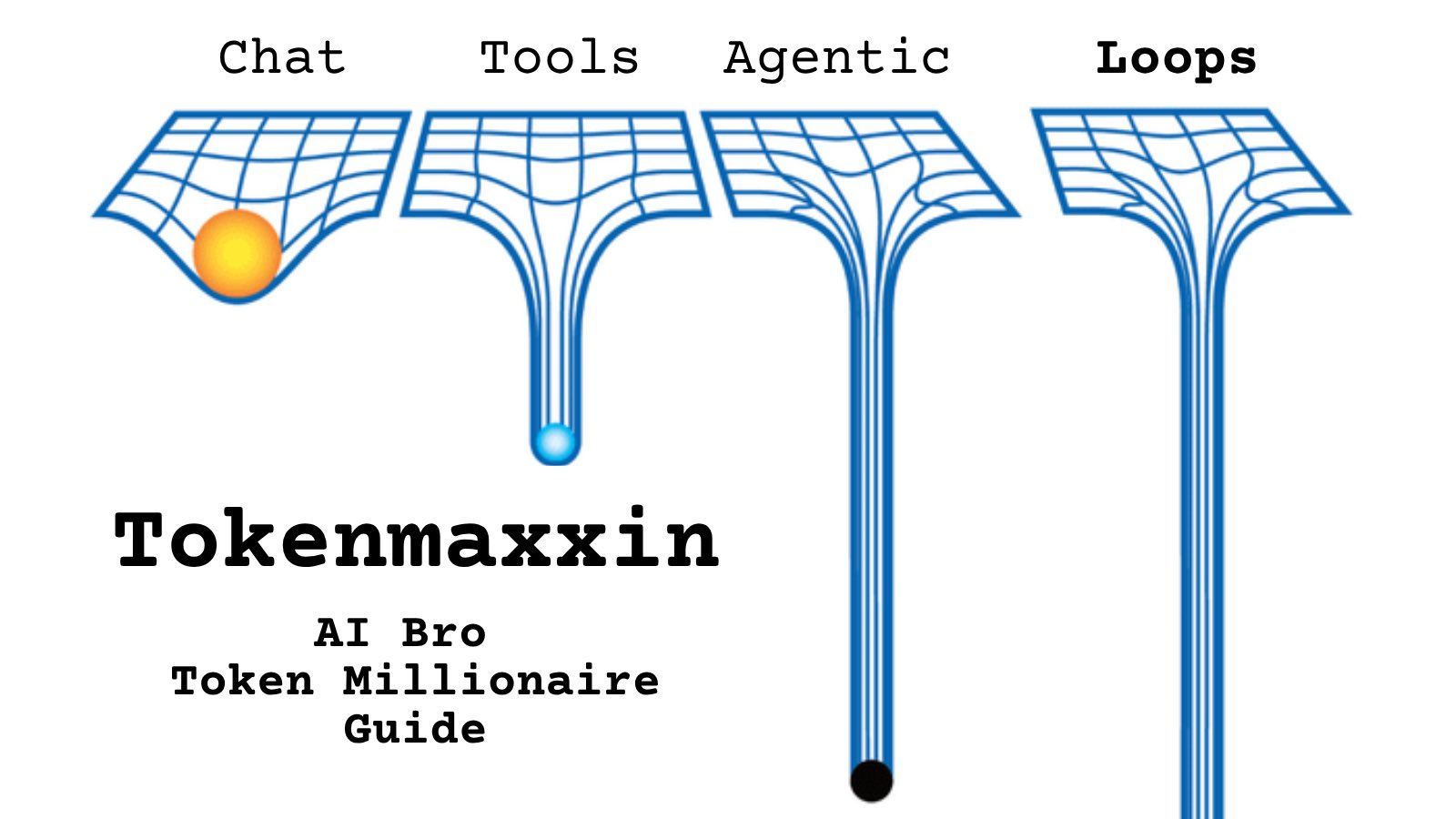
@yuki_arano https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
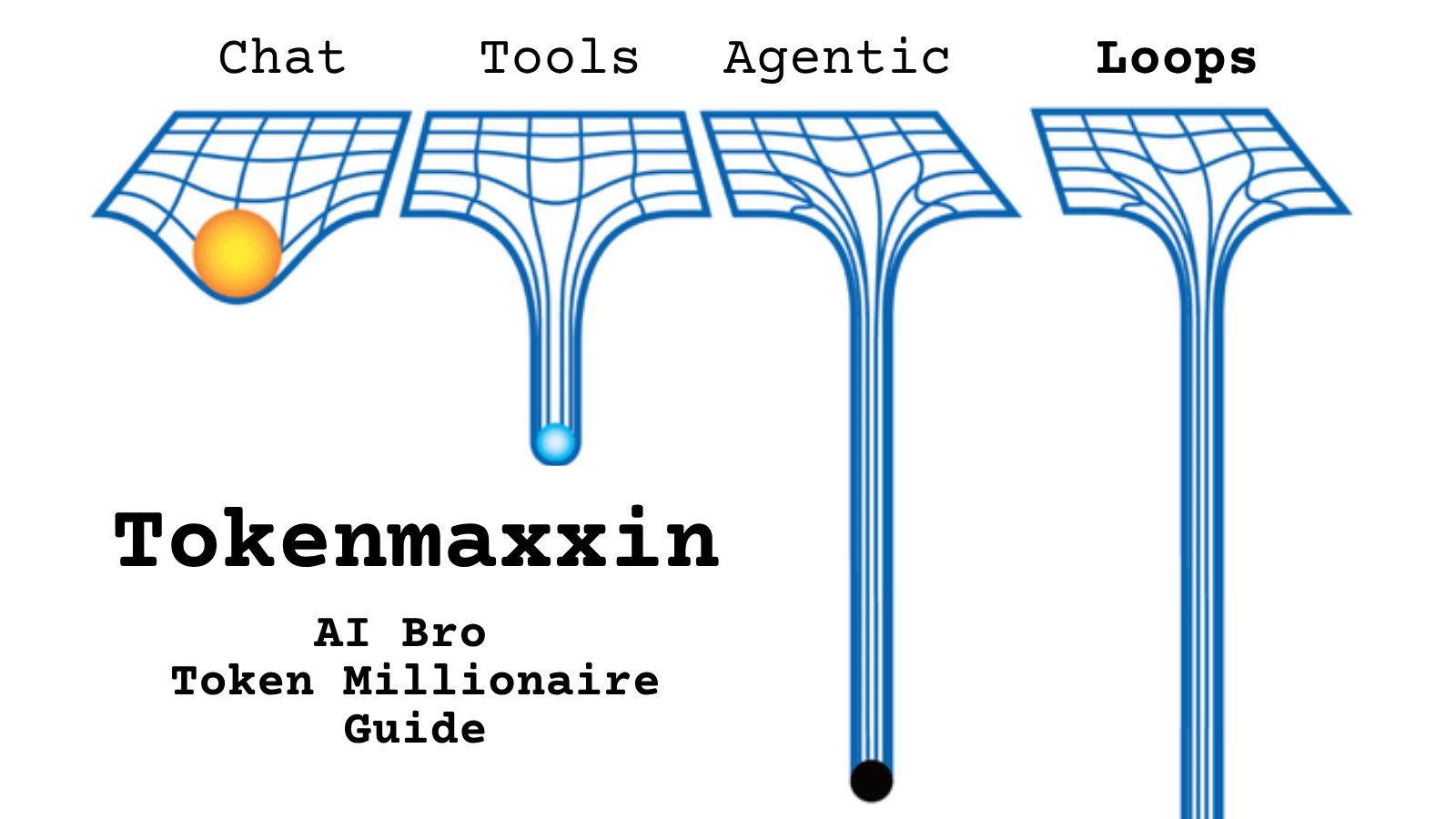
@shin_sasaki19 https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
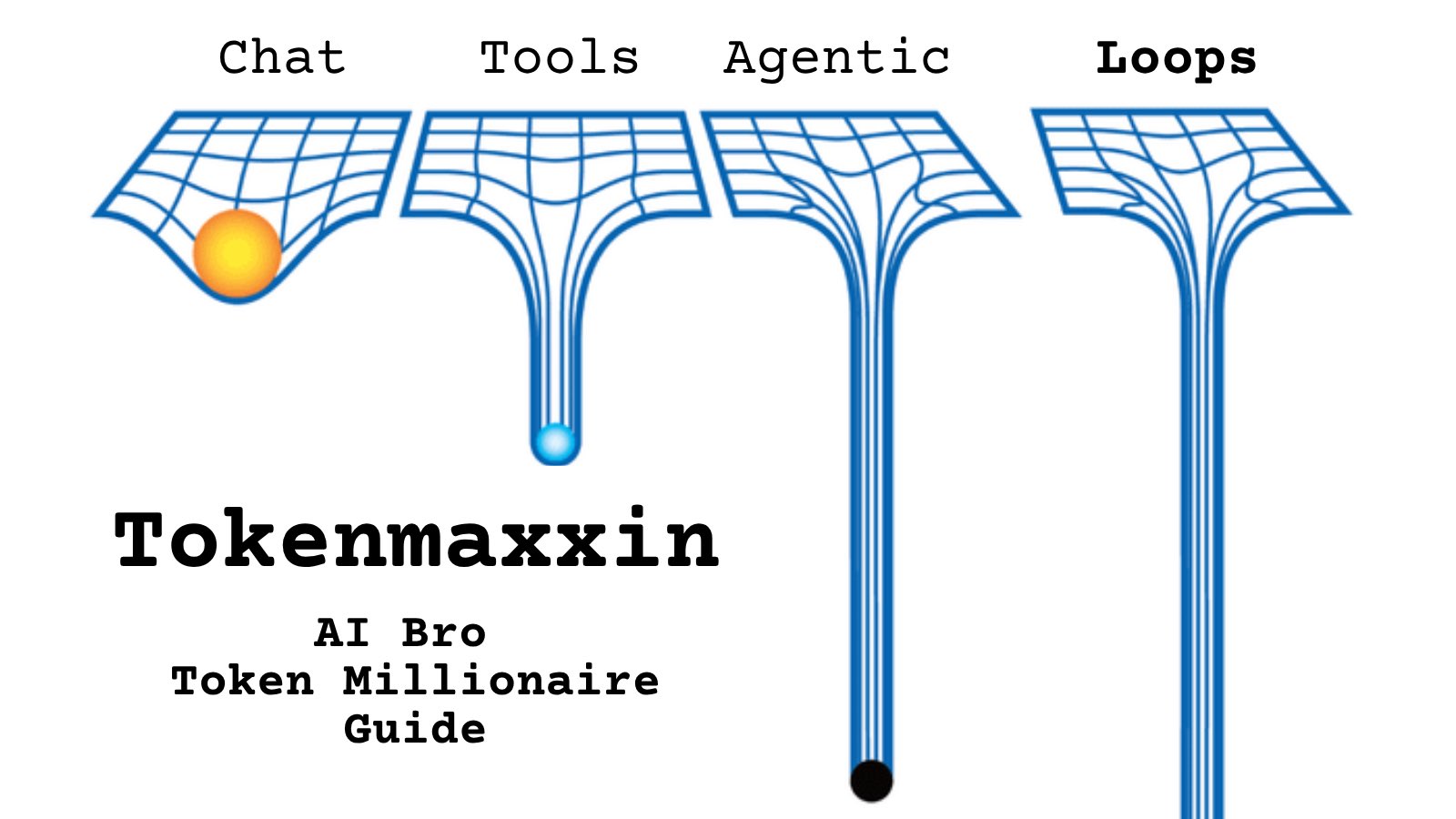
@agusaikyou https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
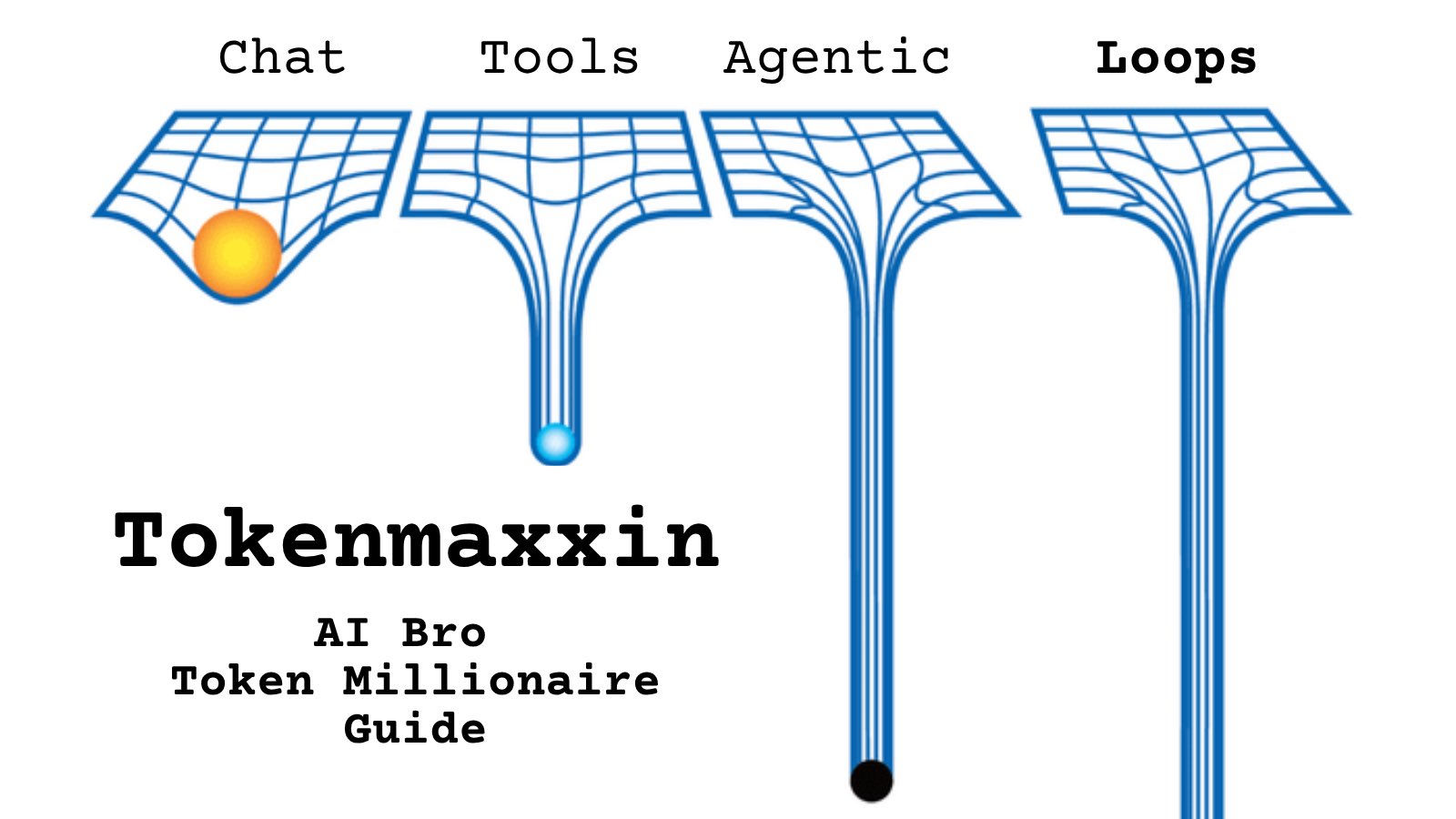
@StudyAki https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
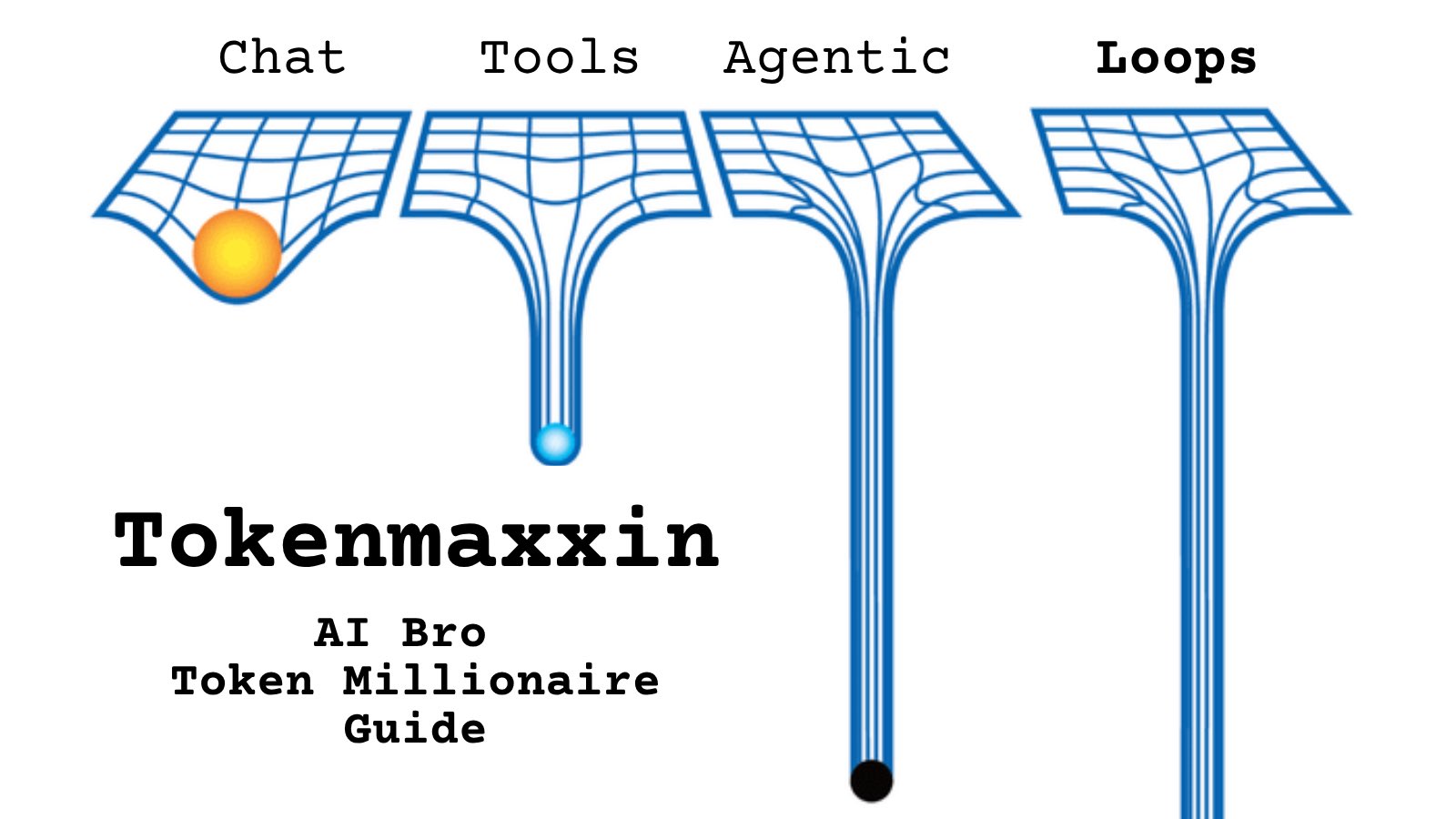
@moeyangogo55 https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
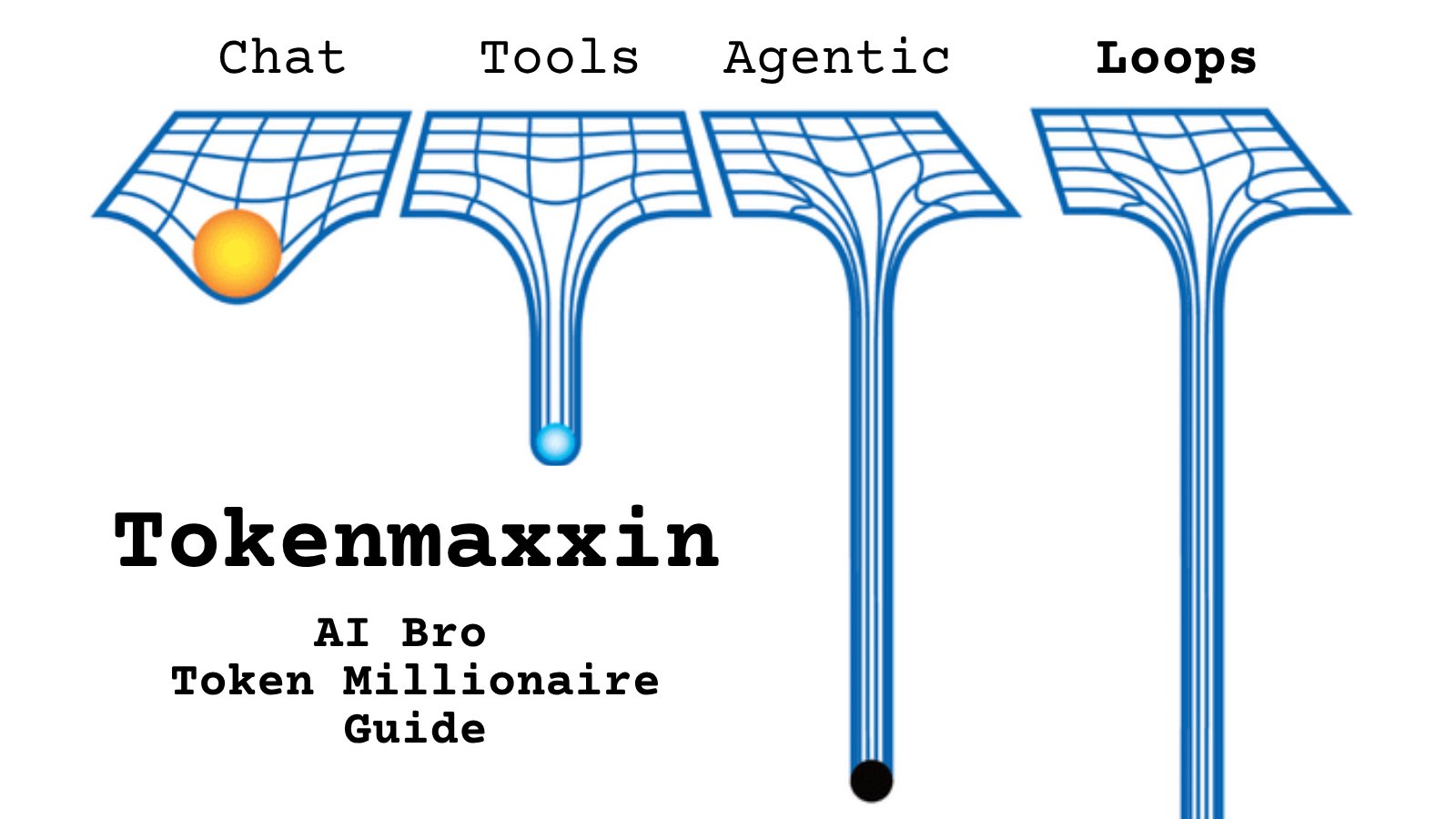
@moriyakick https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
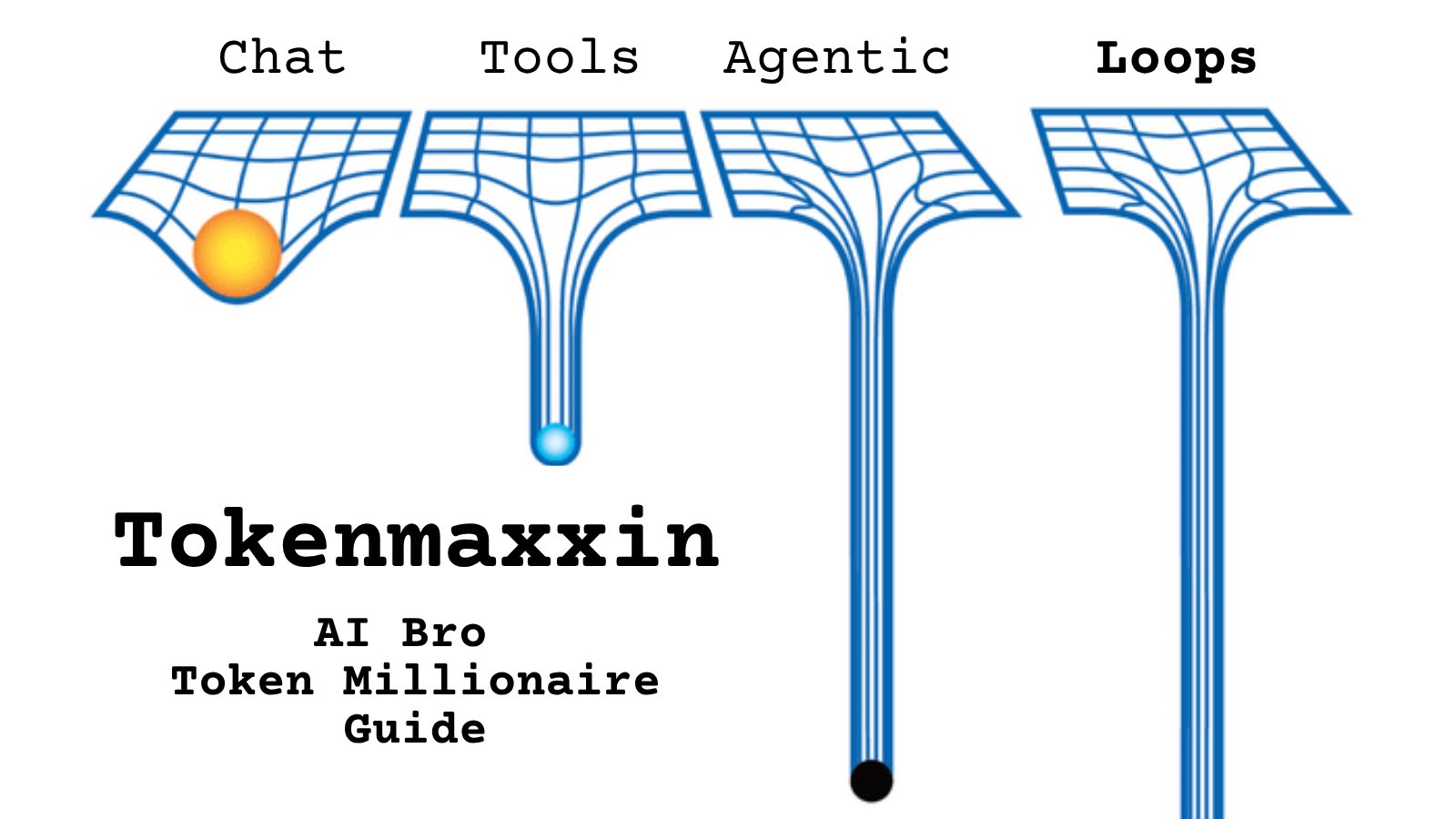
@MAMAAAAU https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
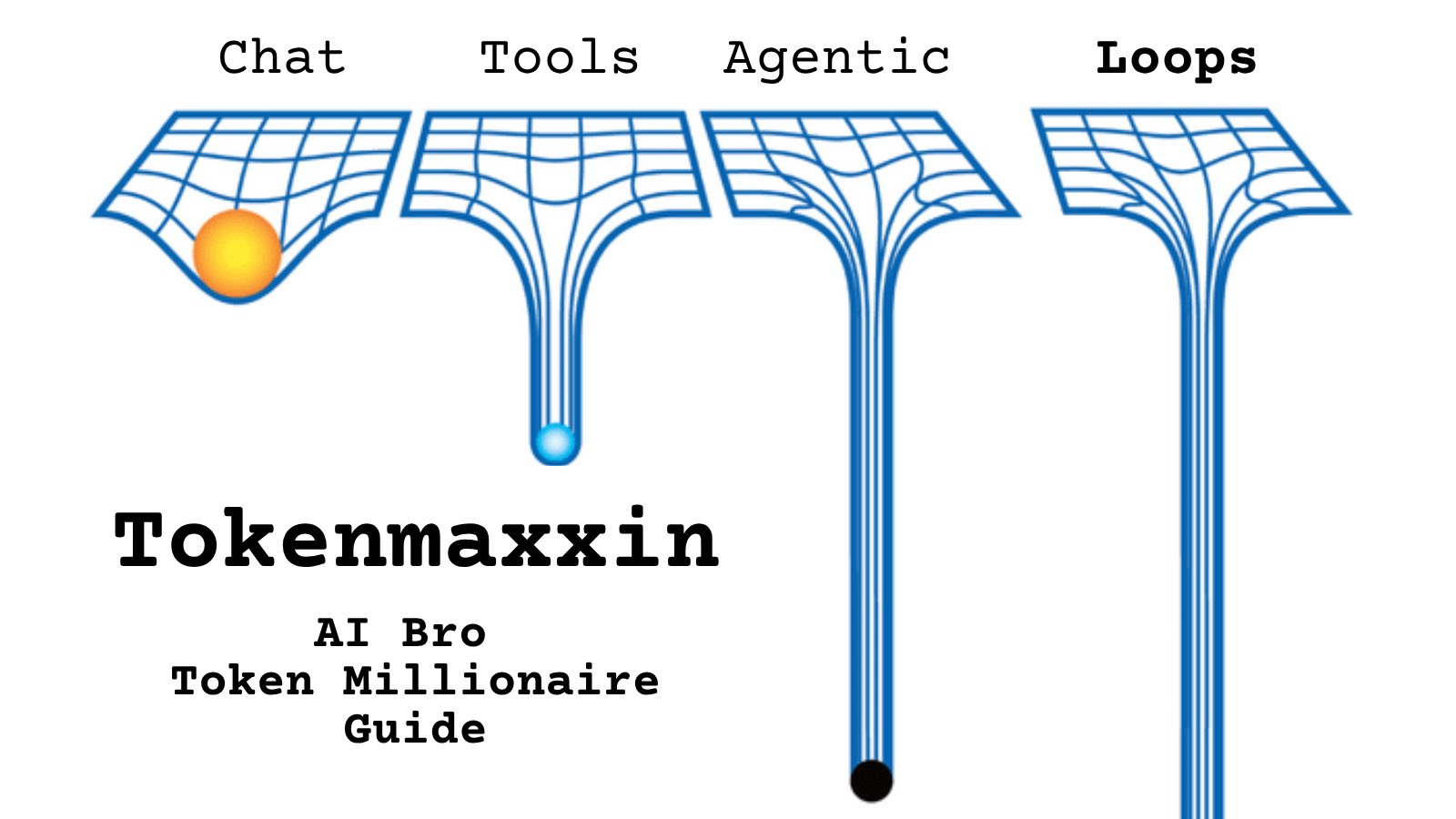
@Cointelegraph https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
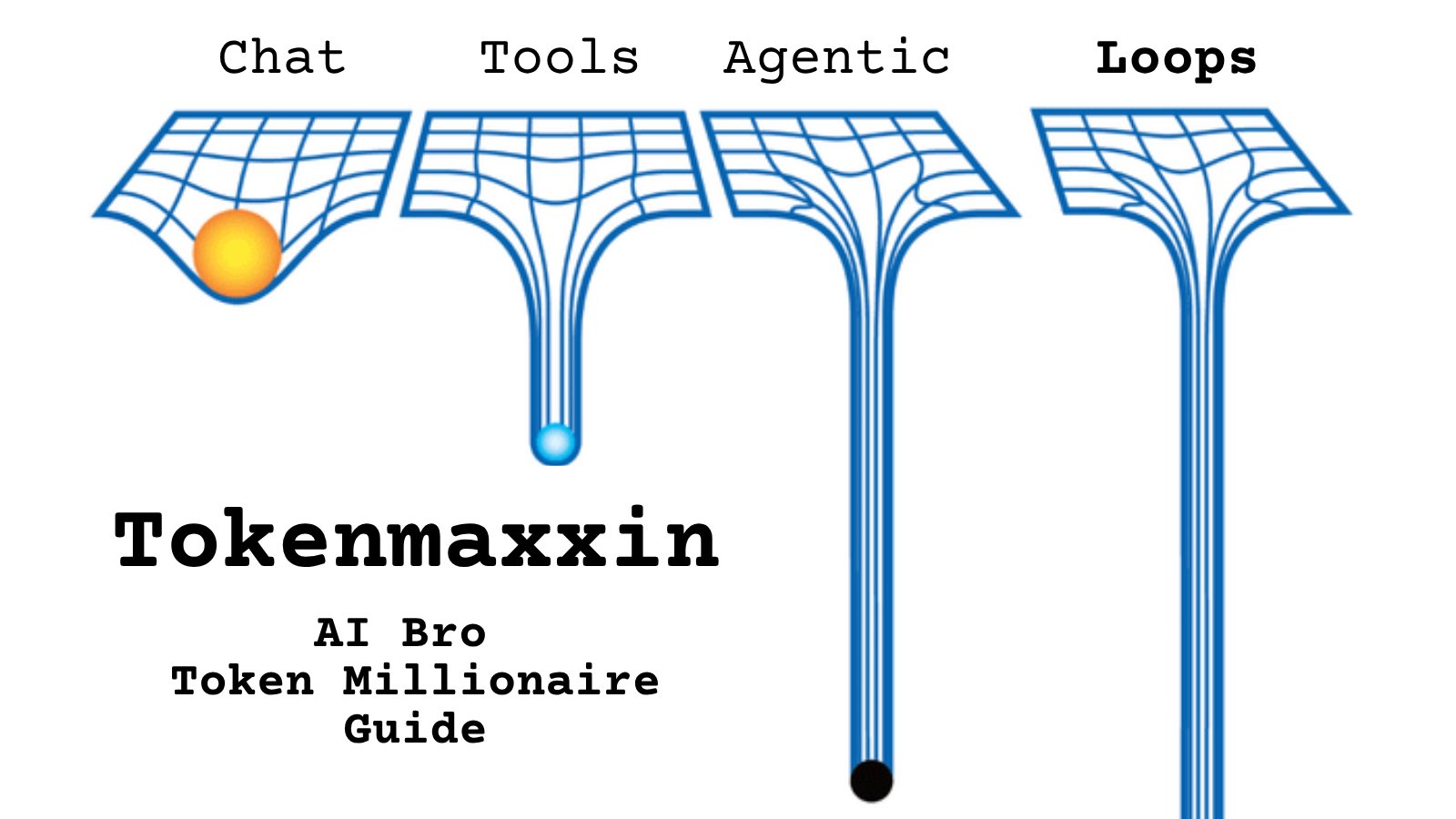
@delba_oliveira https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
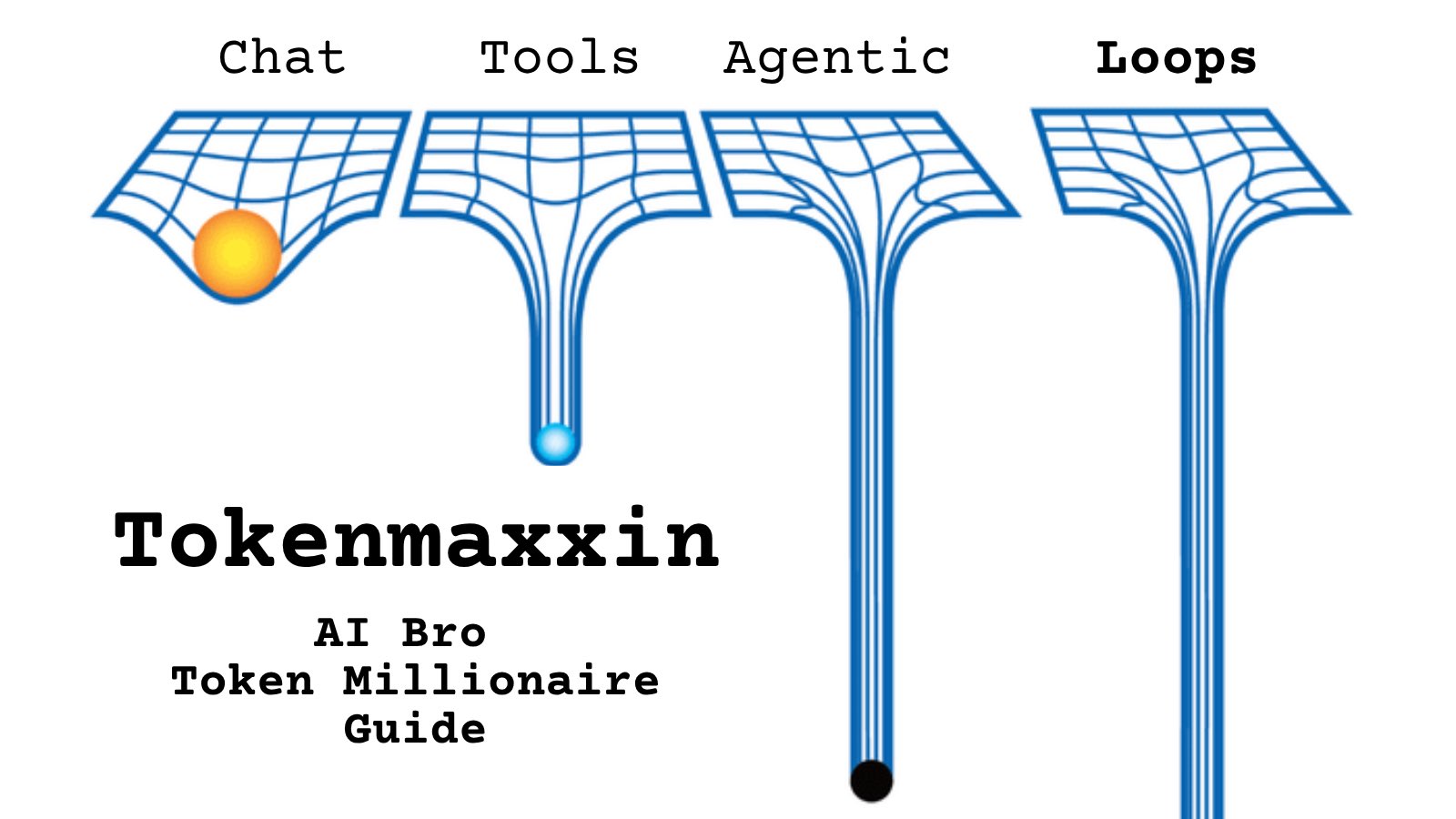
@peter_szilagyi https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
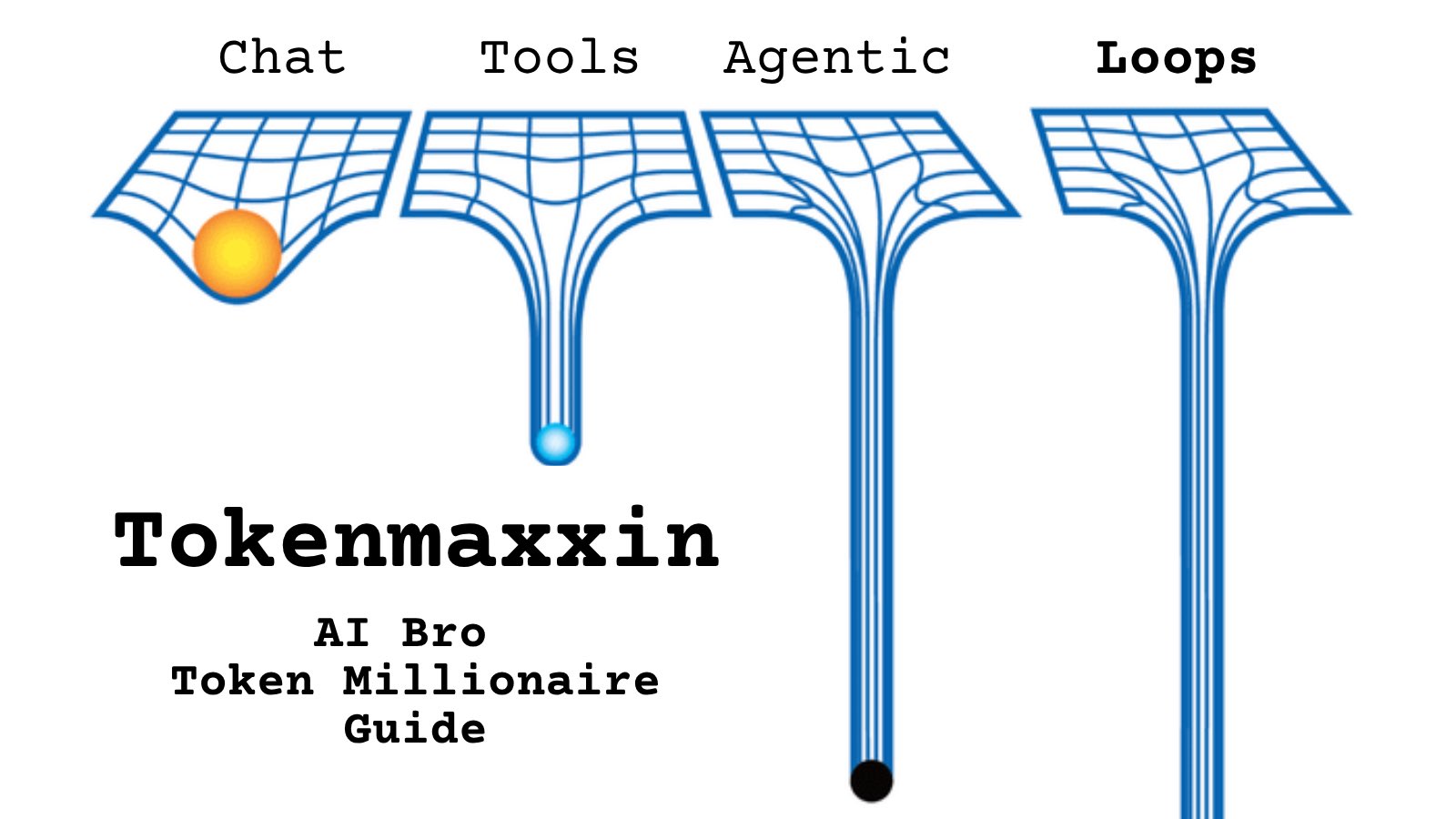
@beamnxw https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
Today, @SpaceX (Nasdaq: SPCX) makes its public market debut with a $75Bn offering (pre-greenshoe) at $135 per share, marking the largest IPO in history. Congratulations to the SpaceX team. We are honored to serve as joint lead bookrunner and sole stabilization agent. https://t.co/R0QkTRwVvF
“It is certainly hard to believe that a little company that started in a warehouse in El Segundo is now going public with the largest IPO ever.” Only in America. Congratulations to @elonmusk @SpaceX. This is the American Dream 🇺🇸💪🚀 https://t.co/YFytt6Ajtk
@TOMERUMAN https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
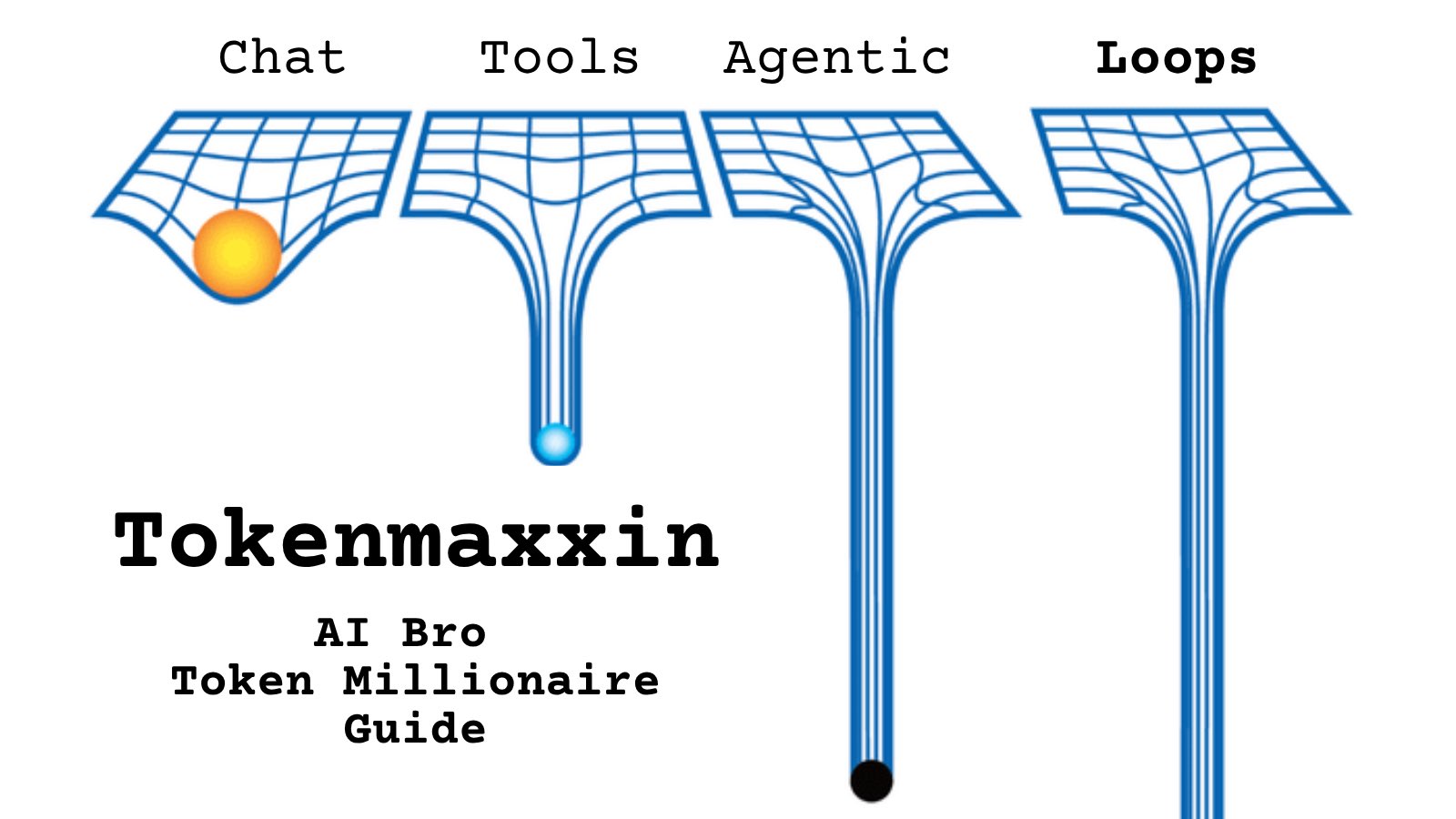
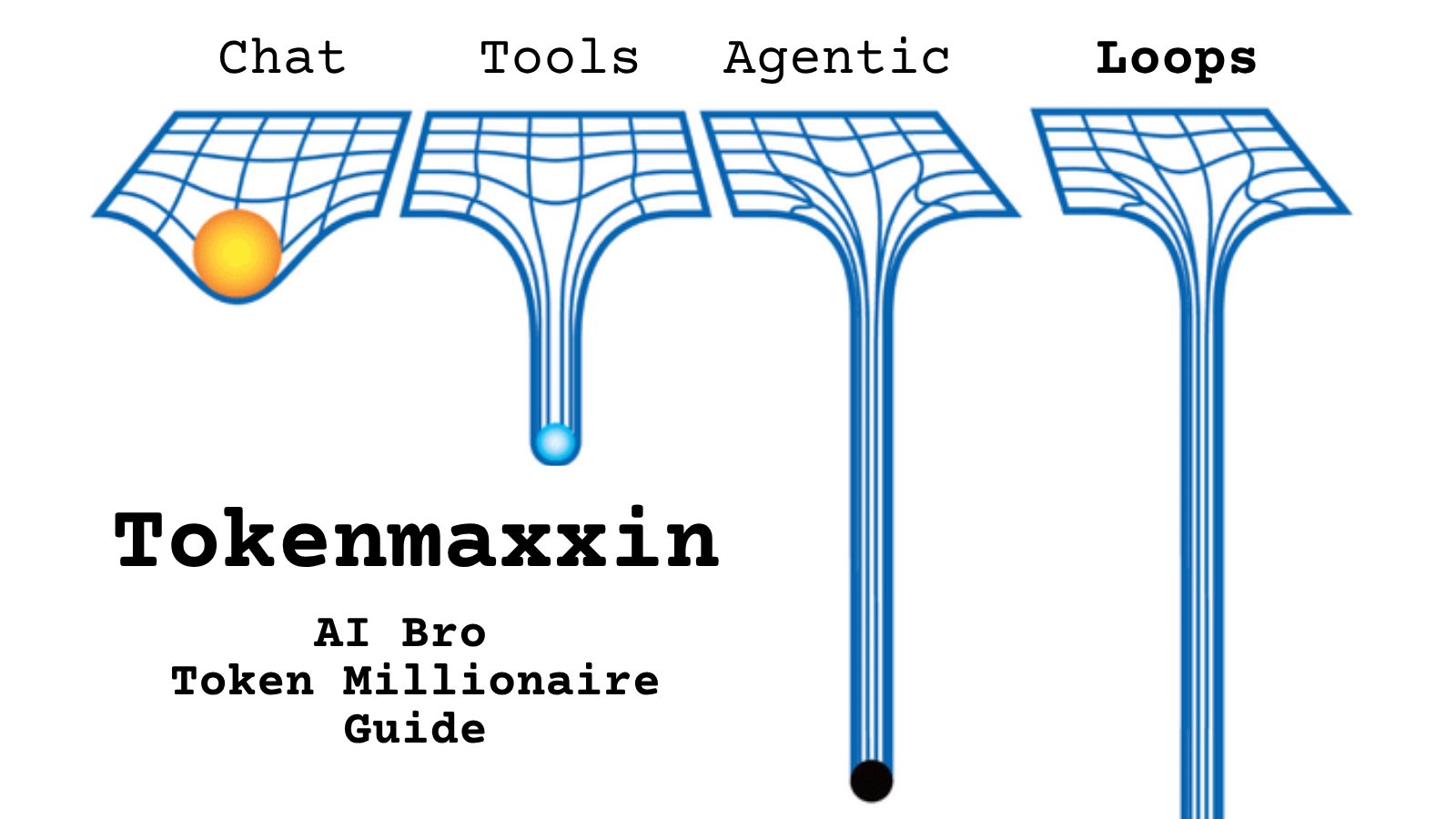
@polymarketjapan https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
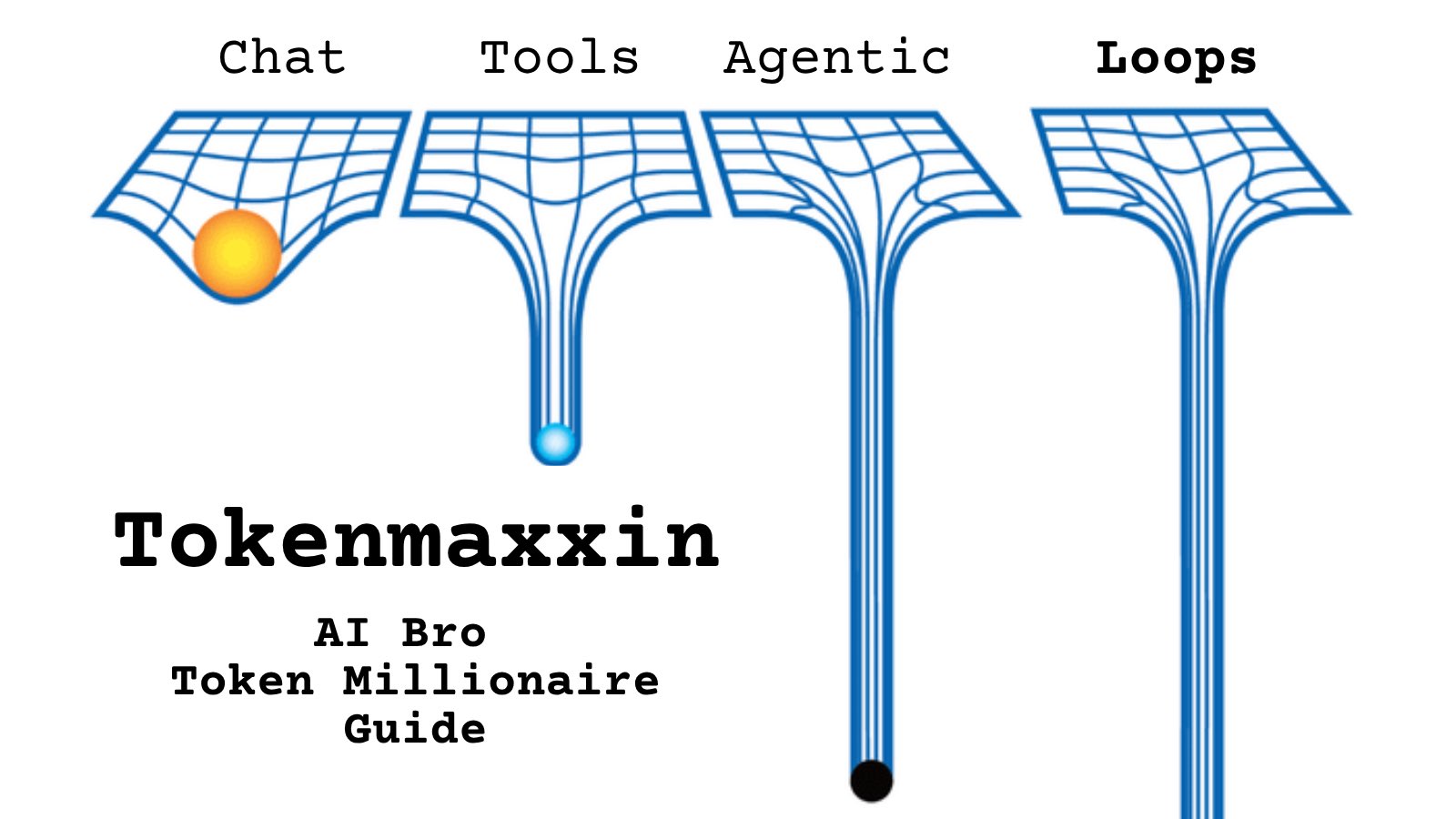
@traderyamamoto https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
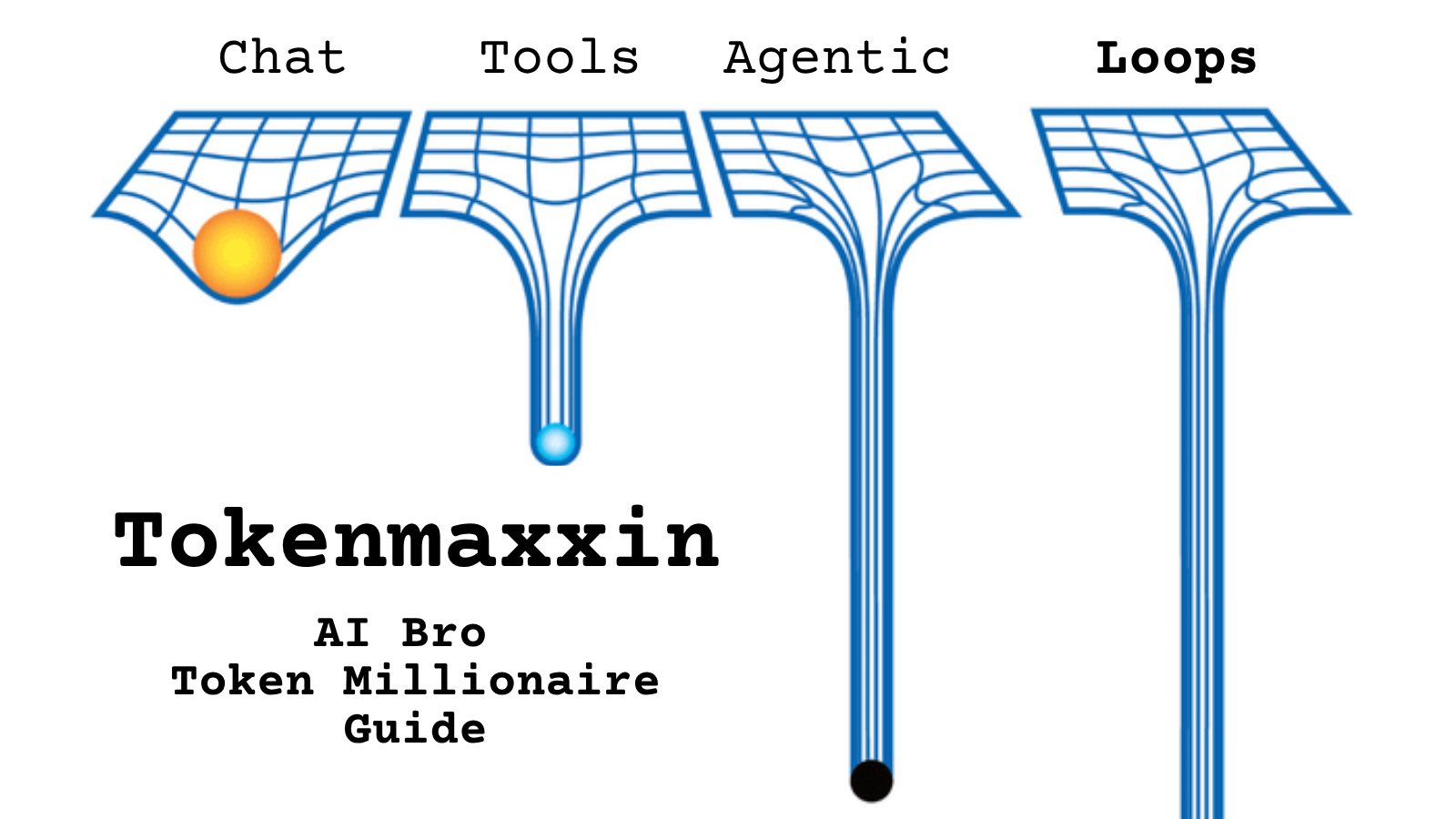
@ytranking https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
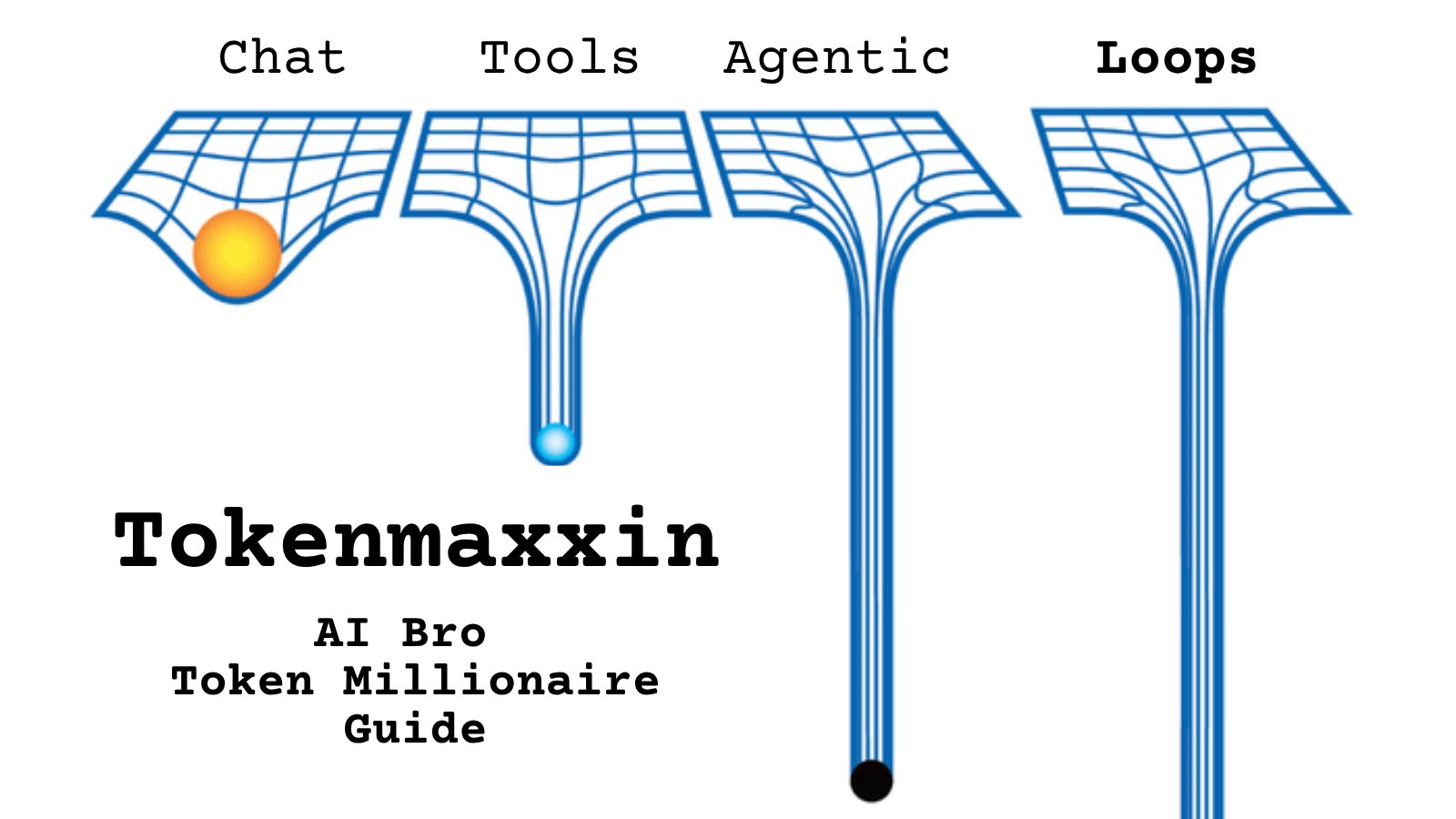
@Neetfujisub https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
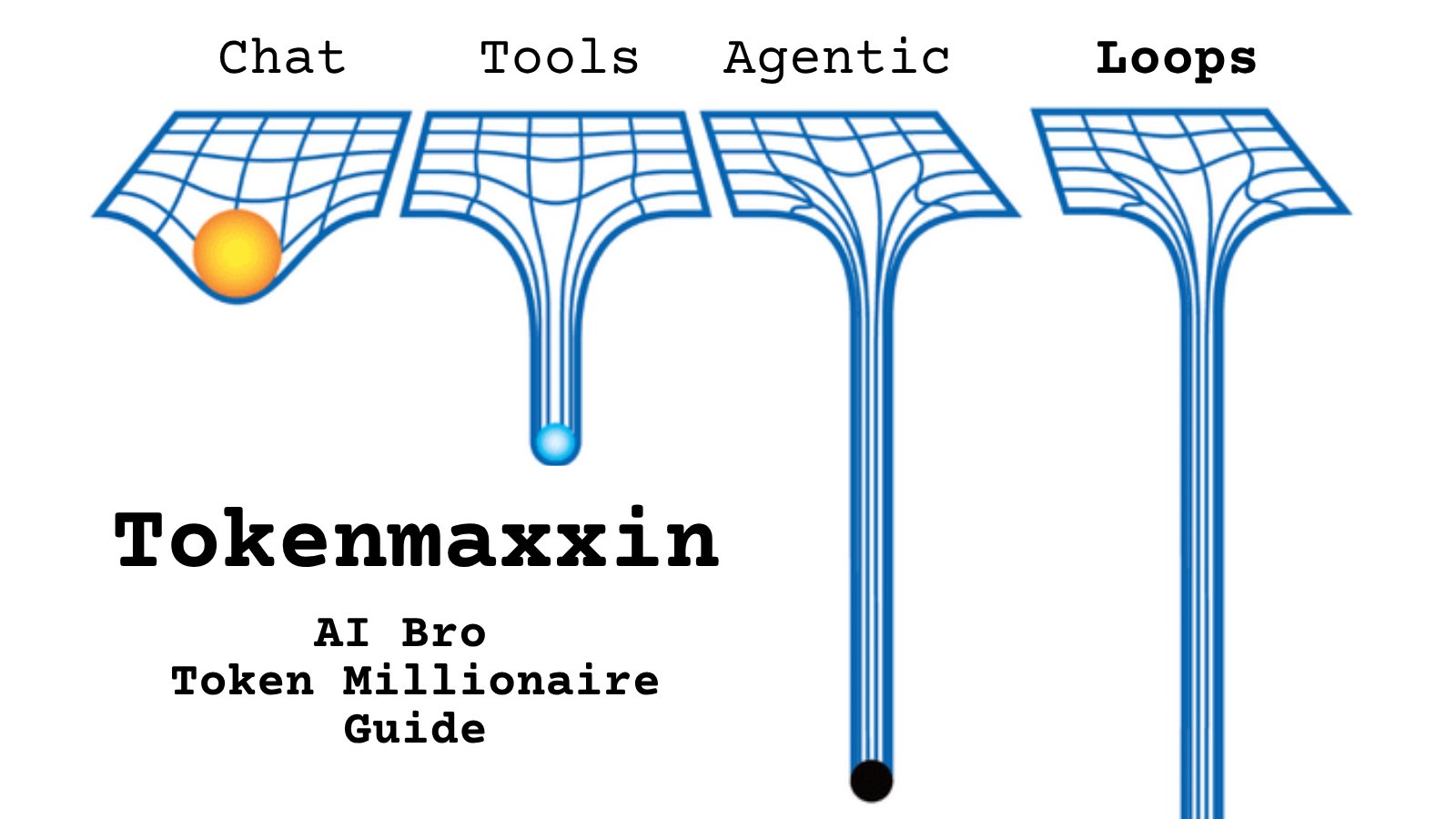
@Chi_Wang_ https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
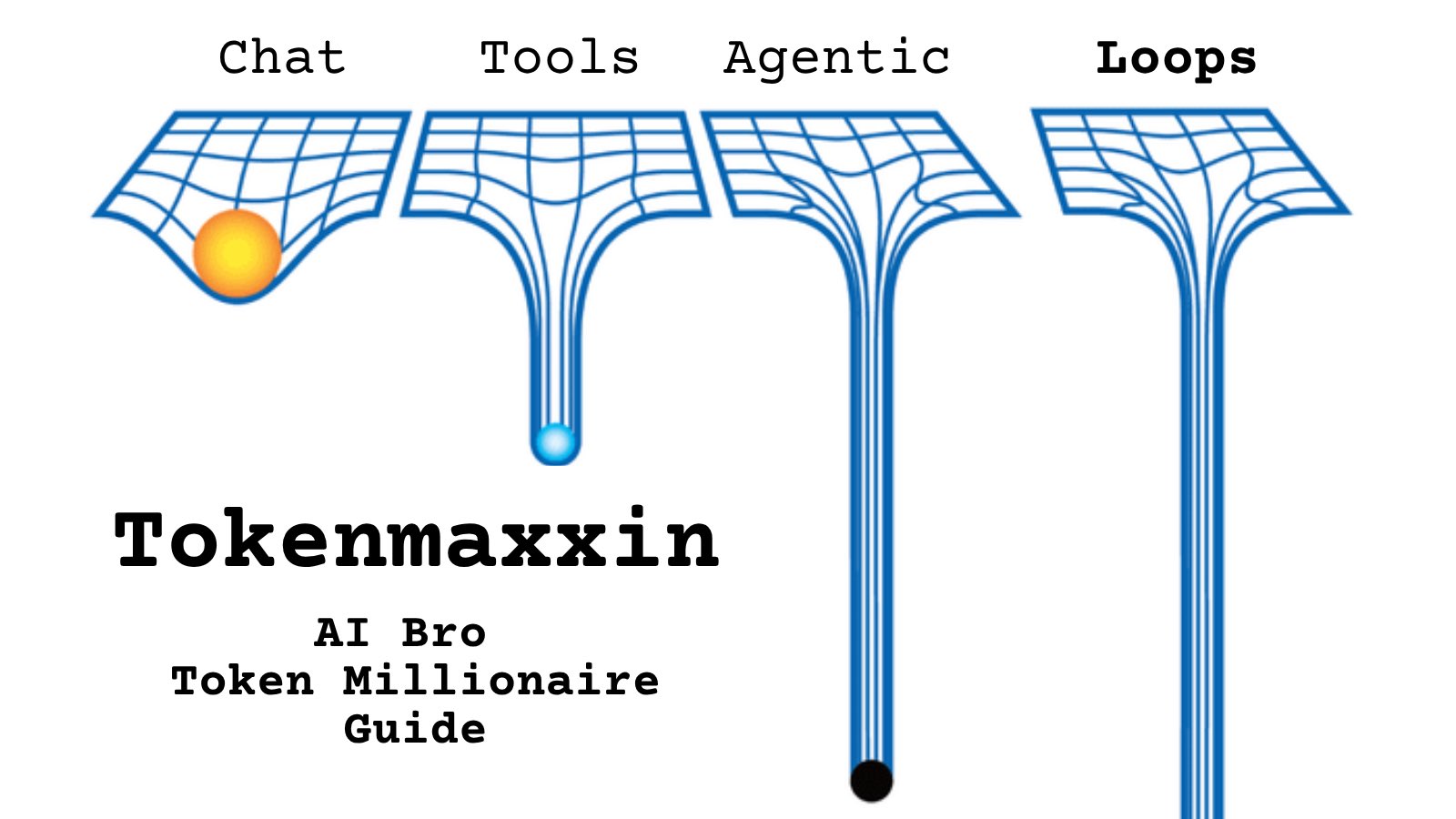
@roninmakuronin https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
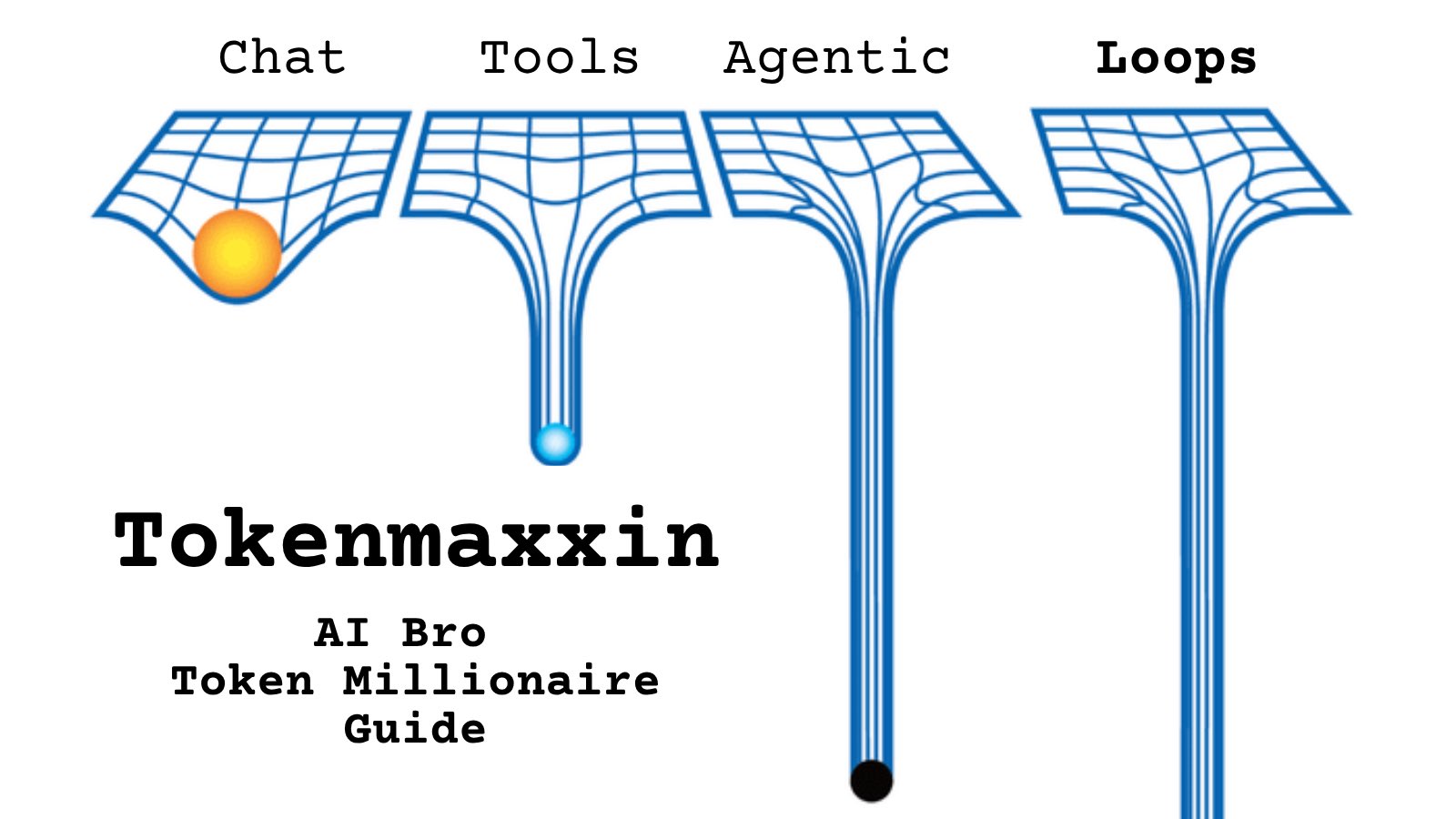
@tsj000 https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
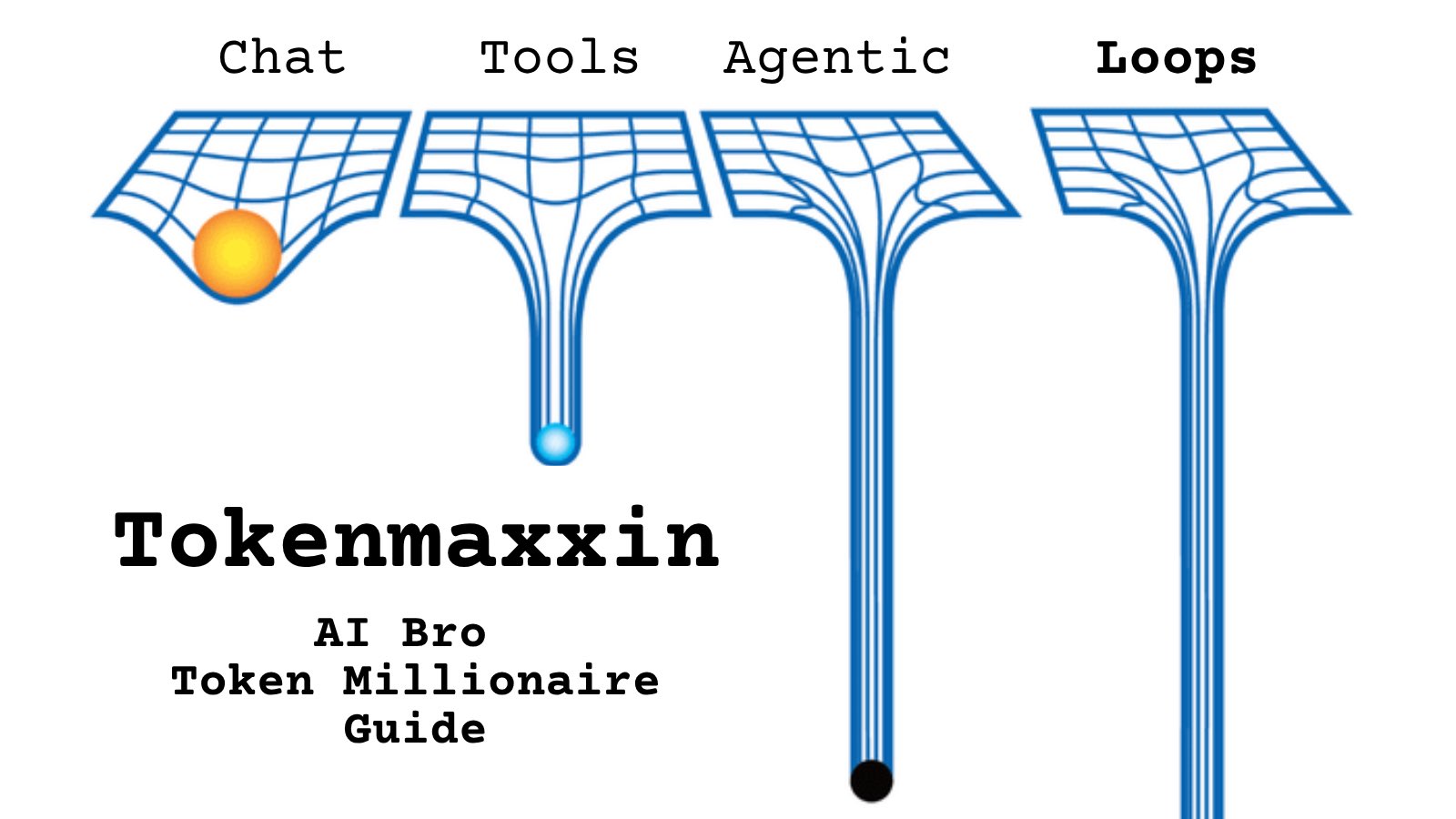
@alonzuman https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
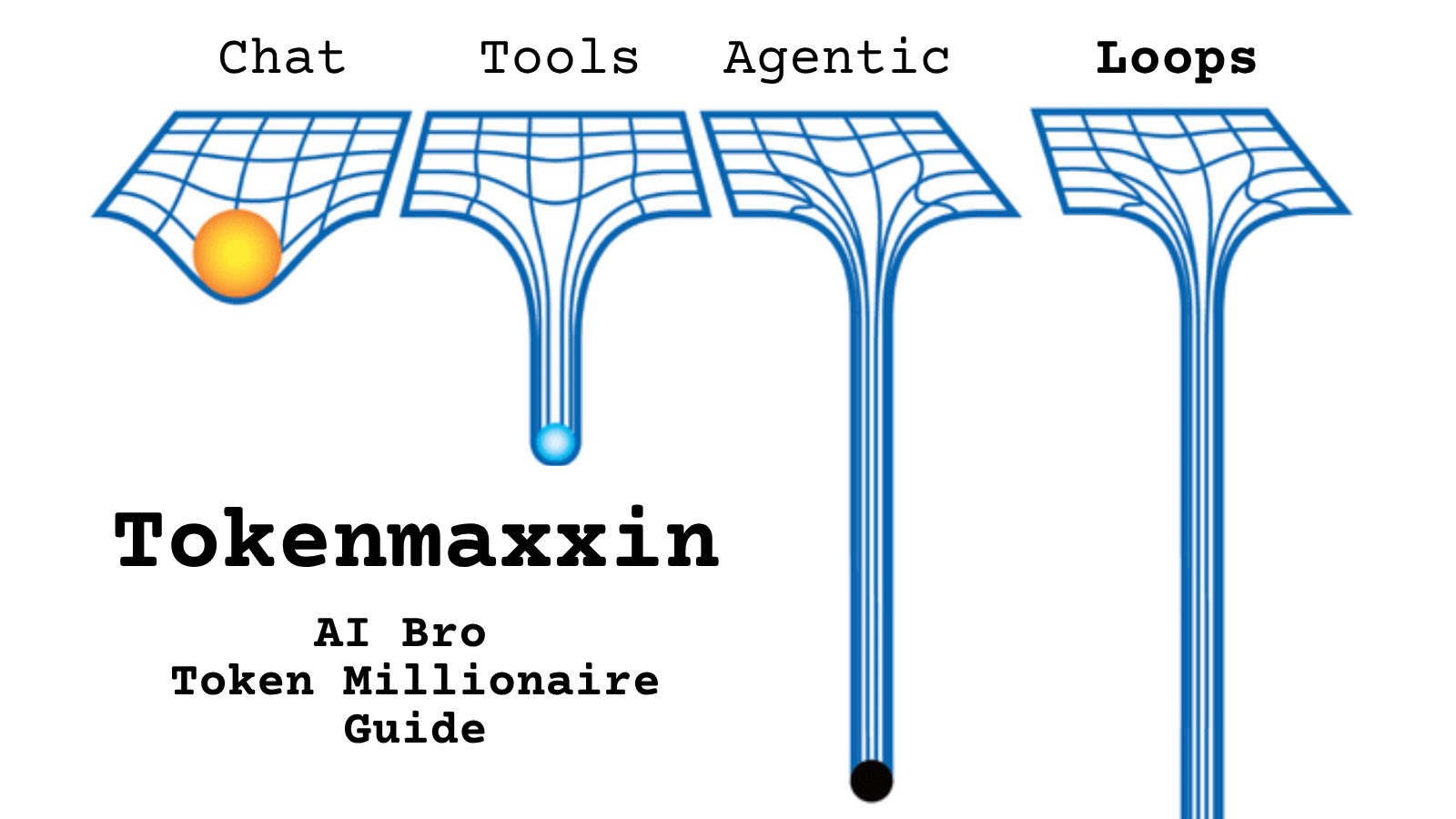
@itmedia_news https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
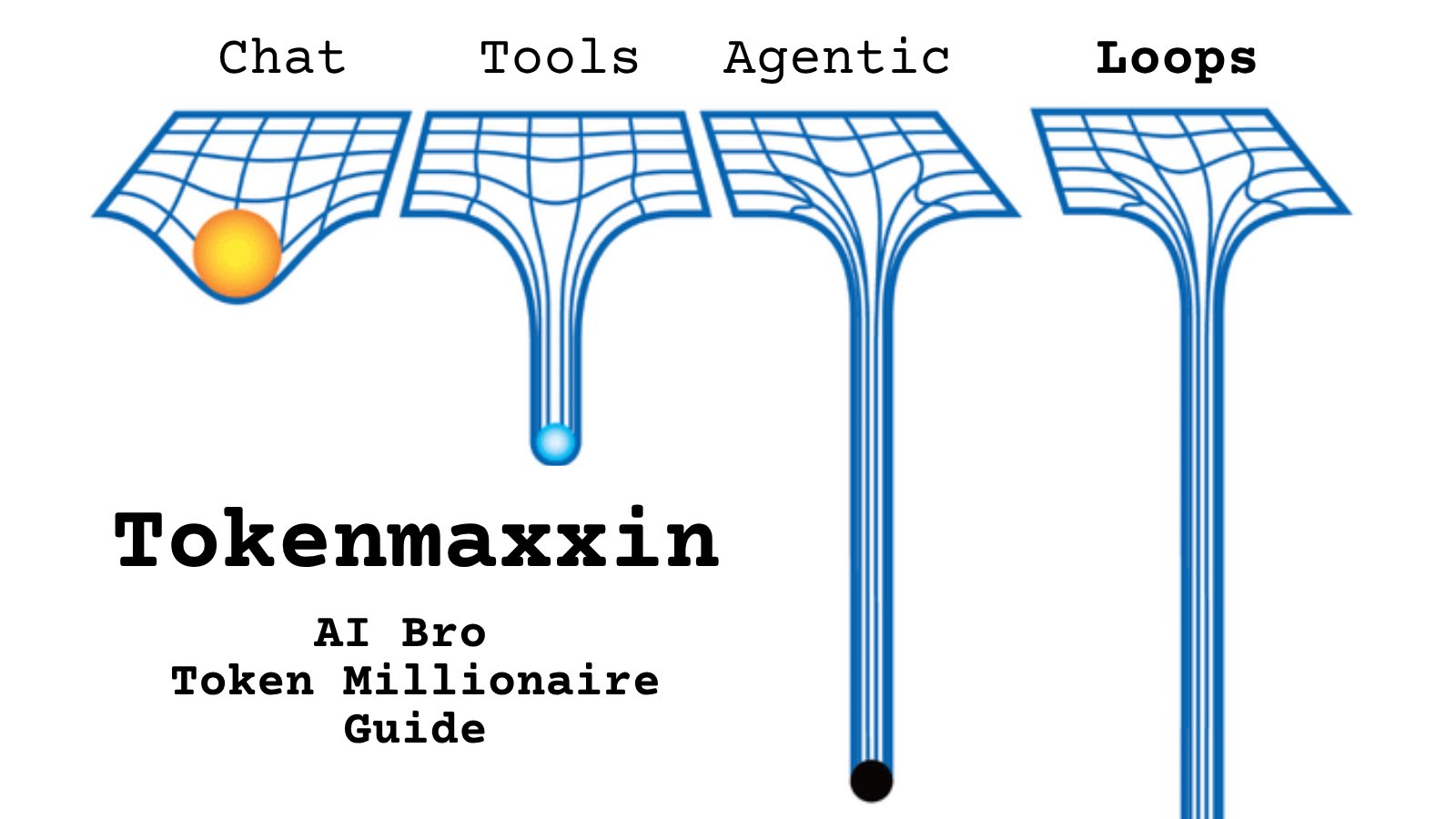
@RoundtableSpace https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
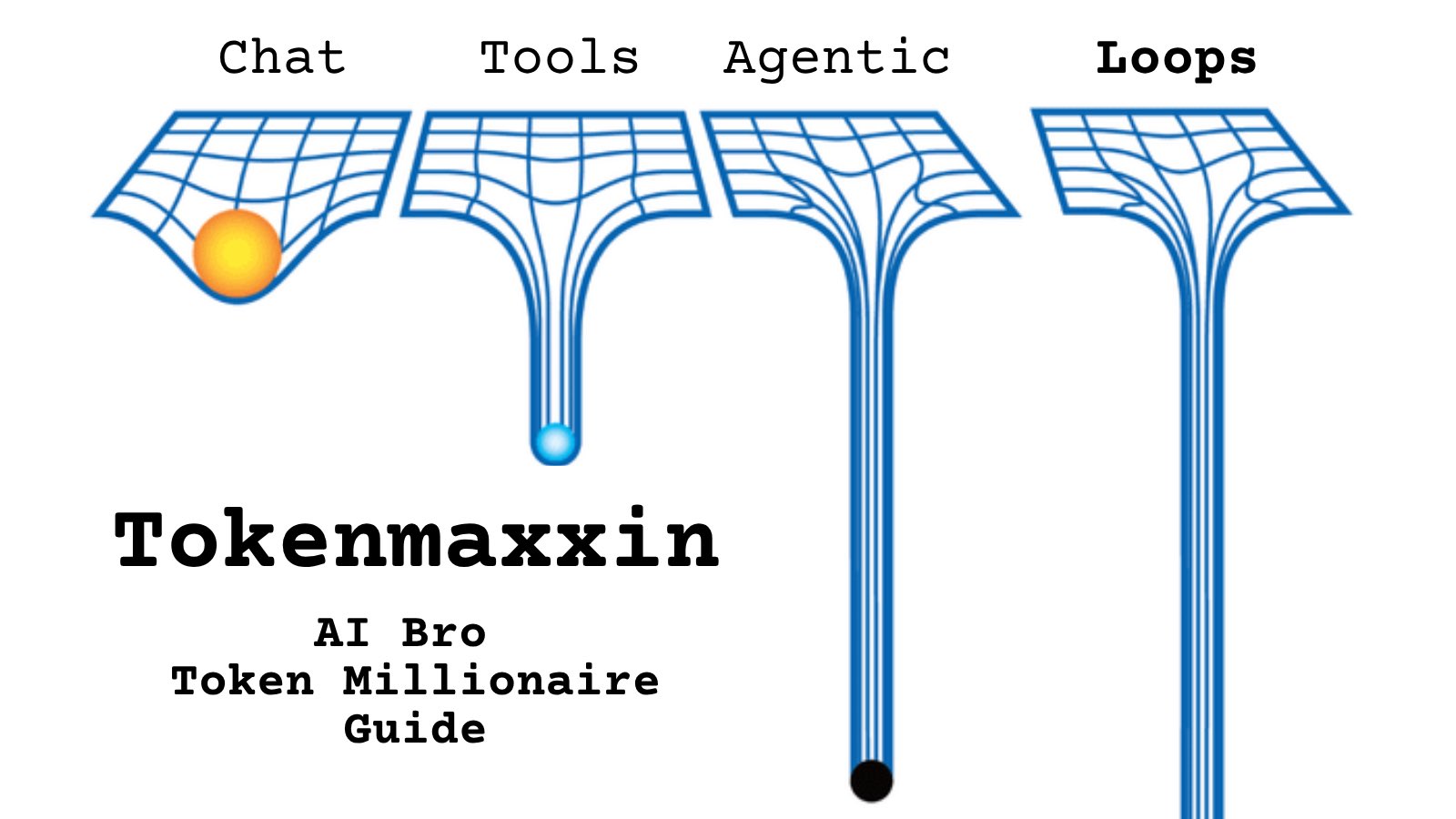
@uturou_adhd https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j