Your curated collection of saved posts and media
@Kalshi https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@zerohedge https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@KobeissiLetter https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@47news_official https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Polymarket https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Nasdaq @SpaceX @NasdaqExchange https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@pubity https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@StockSavvyShay https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@ajipondu https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@TrumpTruthOnX https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@tesuta001 https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@business https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@PopCrave https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Polymarket https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@nikkei @hor11 https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Kalshi https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@InTheAssembly https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

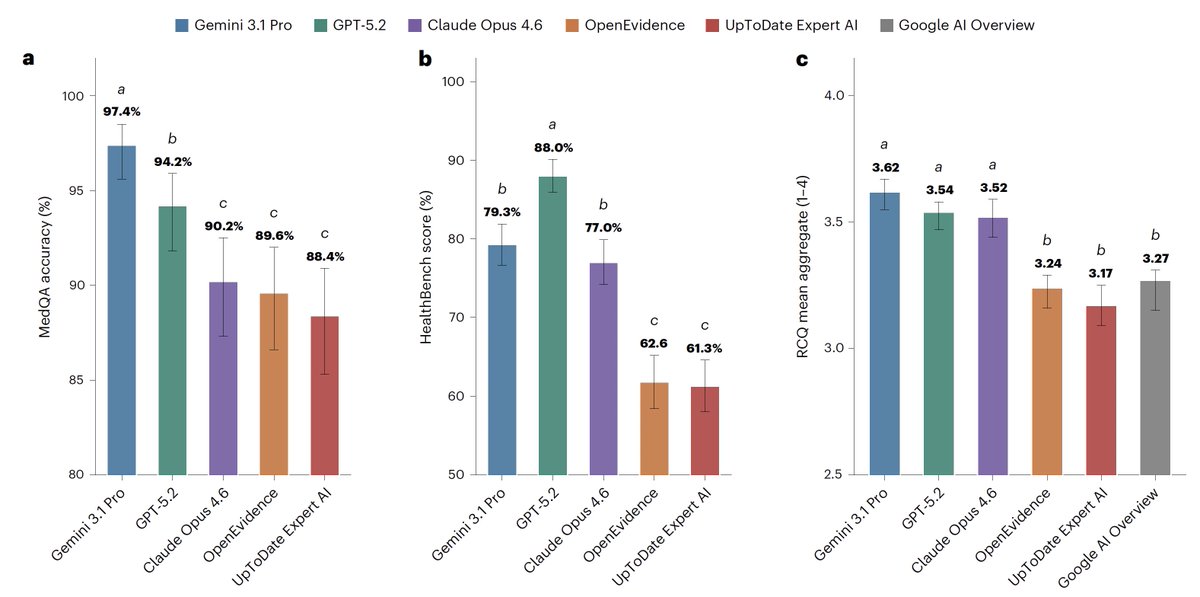
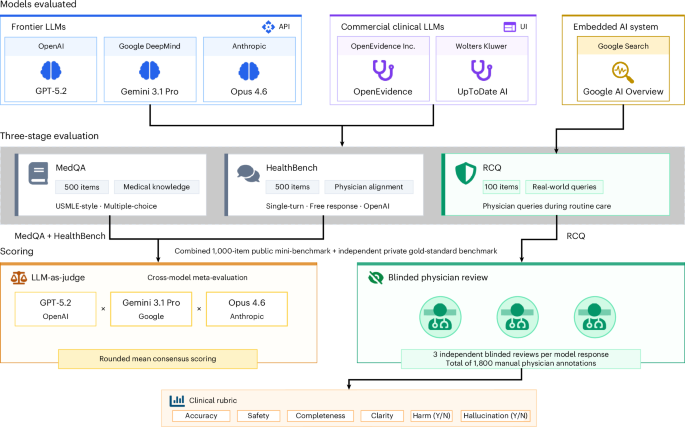
For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine https://t.co/KCH1ADfQWz
SpaceX is redefining industries on Earth and aiming to create new ones beyond it. On June 11, it successfully priced its $75B IPO. Goldman Sachs is honored to have served as lead left bookrunner. https://t.co/X5J3WbR1y7
“It is certainly hard to believe that a little company (@SpaceX) that started in a warehouse in El Segundo is now going public with the largest IPO ever.” @elonmusk https://t.co/zLcXt0gJ97
.@elonmusk says he was literally “all in” betting everything he owned on Tesla and SpaceX when his third rocket failed and Peter Thiel stepped in to save SpaceX: “My buddies from PayPal saved my butt.” “Peter Thiel’s been a big supporter. He invested in SpaceX at an important time in 2008. Before orbit. After our 3rd failure but before success:” “Big credit to Peter and @LukeNosek and the other guys at @foundersfund. Basically my buddies from PayPal.”
.@danawhite says the UFC was almost dead when Spike TV executives pulled him into an alley and made a deal on a napkin: “At the time it was the last $10 million investment we we're going to make in the UFC.” “If The Ultimate Fighter didn't work it's over.” “When we were at the
Falcon 9 launches 29 @Starlink satellites from Florida https://t.co/YGodkpxDIK


Congratulations to SpaceX on today’s $75B IPO, the largest ever brought to market. Goldman Sachs is honored to have served as lead left bookrunner on this transaction, but more than that, we are proud of the strong partnership our people have built with the SpaceX team over the long term. I’ve known Elon for more than 15 years, as have several of my colleagues, and it’s been incredible to see his vision come to life and to work with Gwynne, Bret, and the entire team. We are excited as SpaceX enters this new chapter of its journey as a public company, and we look forward to supporting their mission of advancing the frontier of human space exploration.
Fable helped knock out a really nice explanation of how the effects work: https://t.co/fcUuDD8uQe Very satisfying to watch the demos and mess with them :) https://t.co/G2O7AcLhNc
I'm making a drawing app inspired by the pen + brushpen way I do my nature journals. The watercolor wash dynamics mean you can't be too precious about every line. Give it a go! https://t.co/u7IQI8j0Sl https://t.co/OfKsoYl22F
Plan Mode, clarifying questions, and connector requests now appear directly in the input box — bringing all interactions with Computer to the same place. https://t.co/DJywmPa2Dt
@shingo2000 https://t.co/d9ArOL64ZU
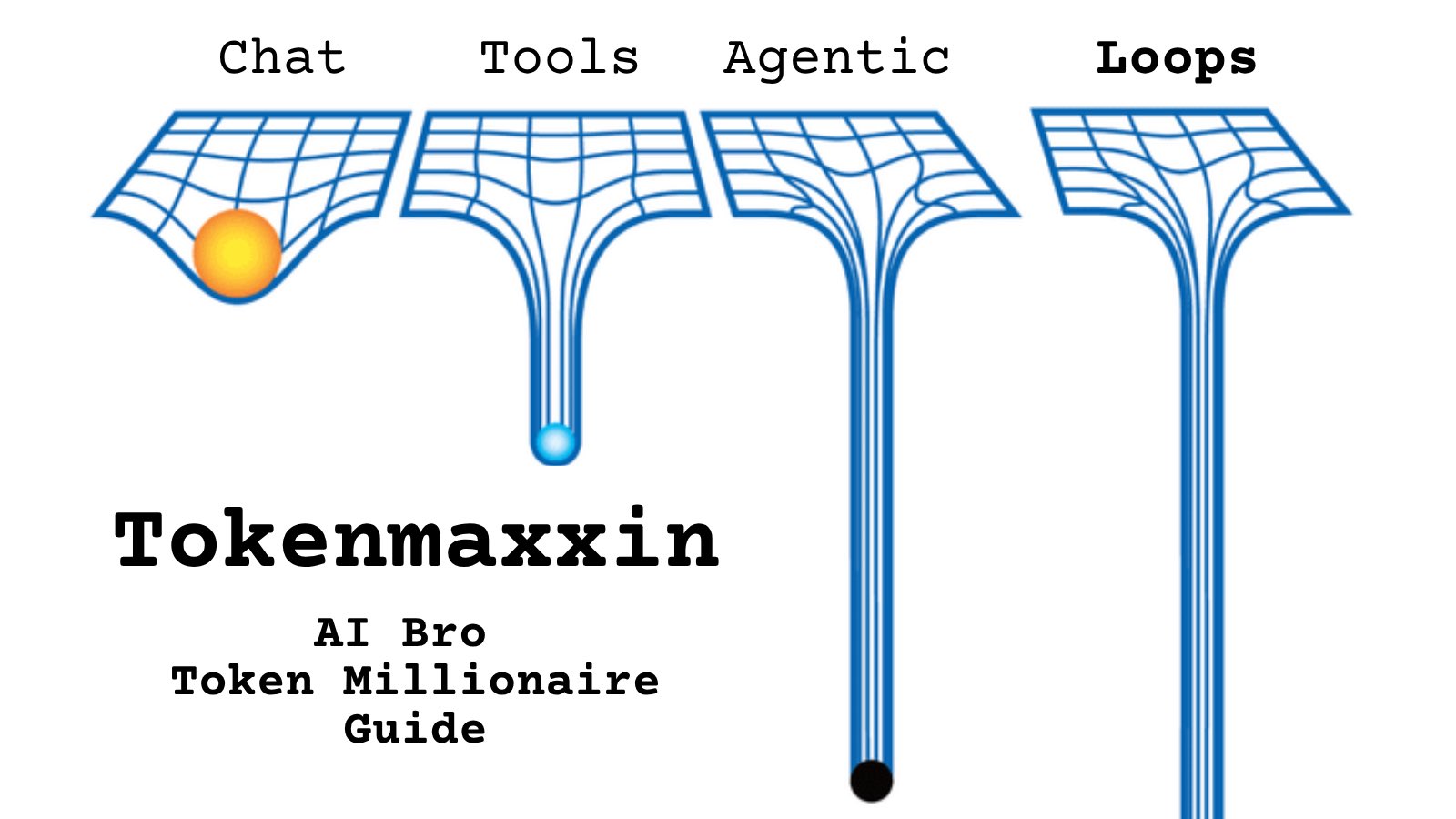
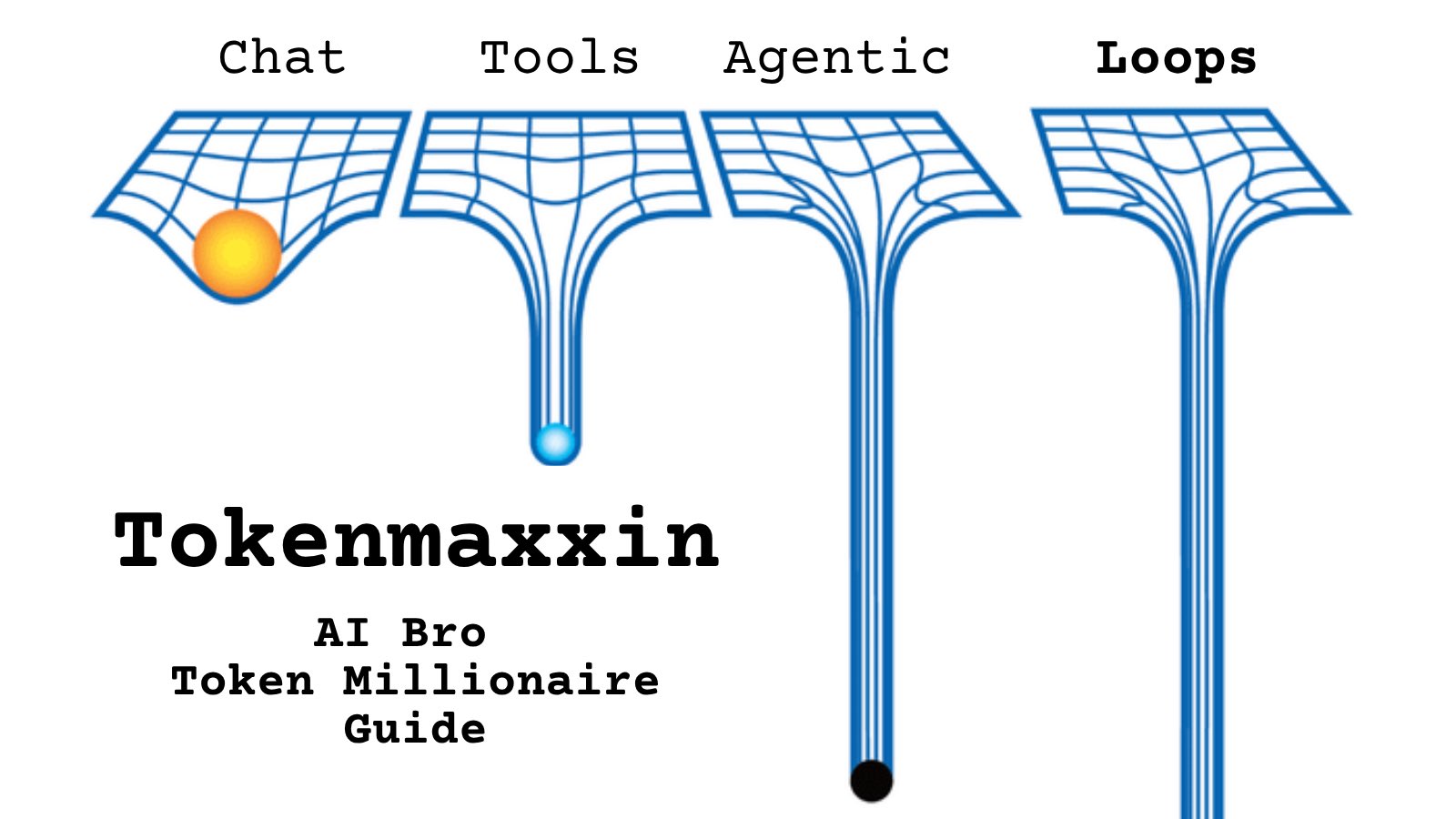
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
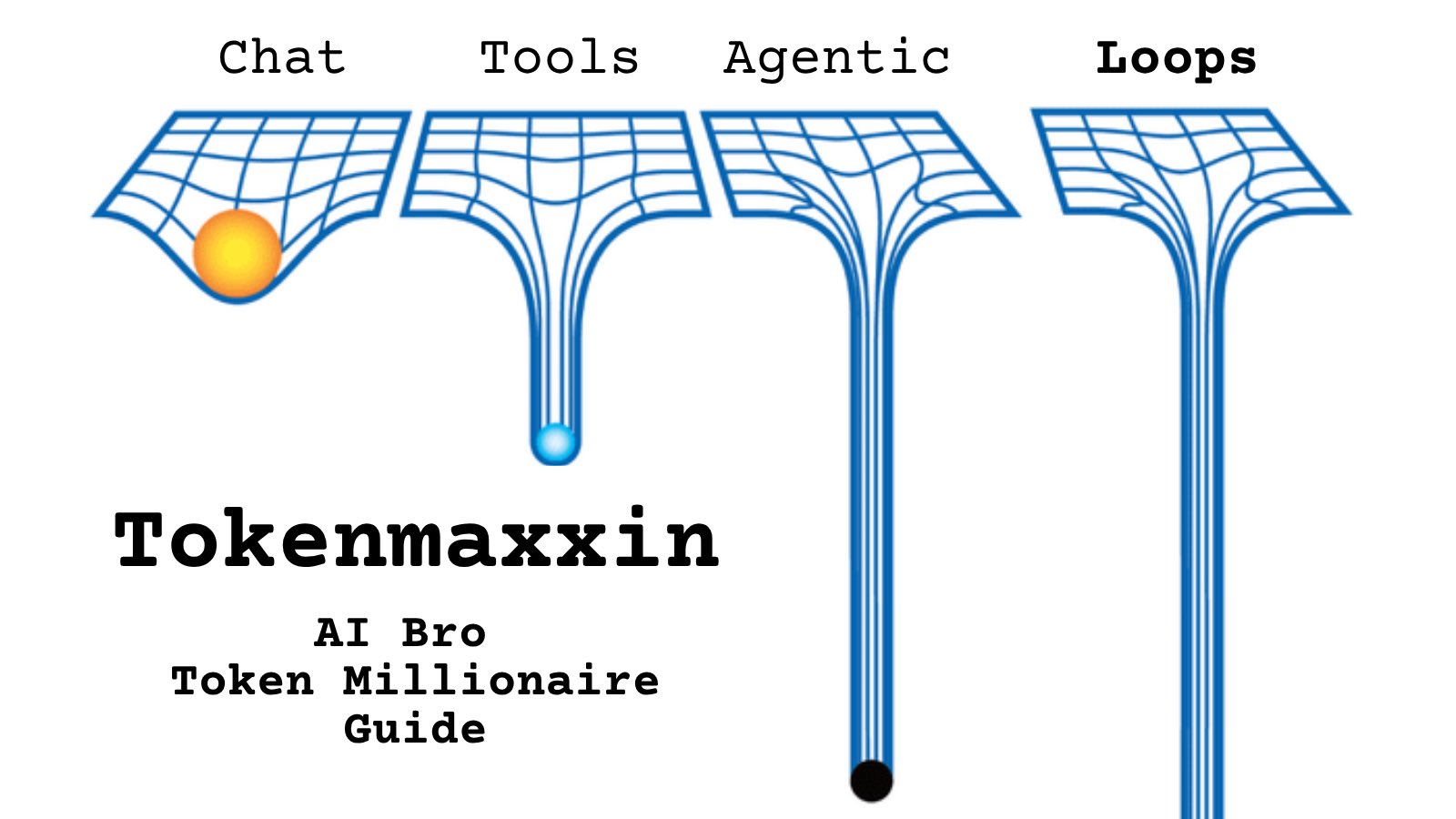
@PromptLLM https://t.co/d9ArOL64ZU
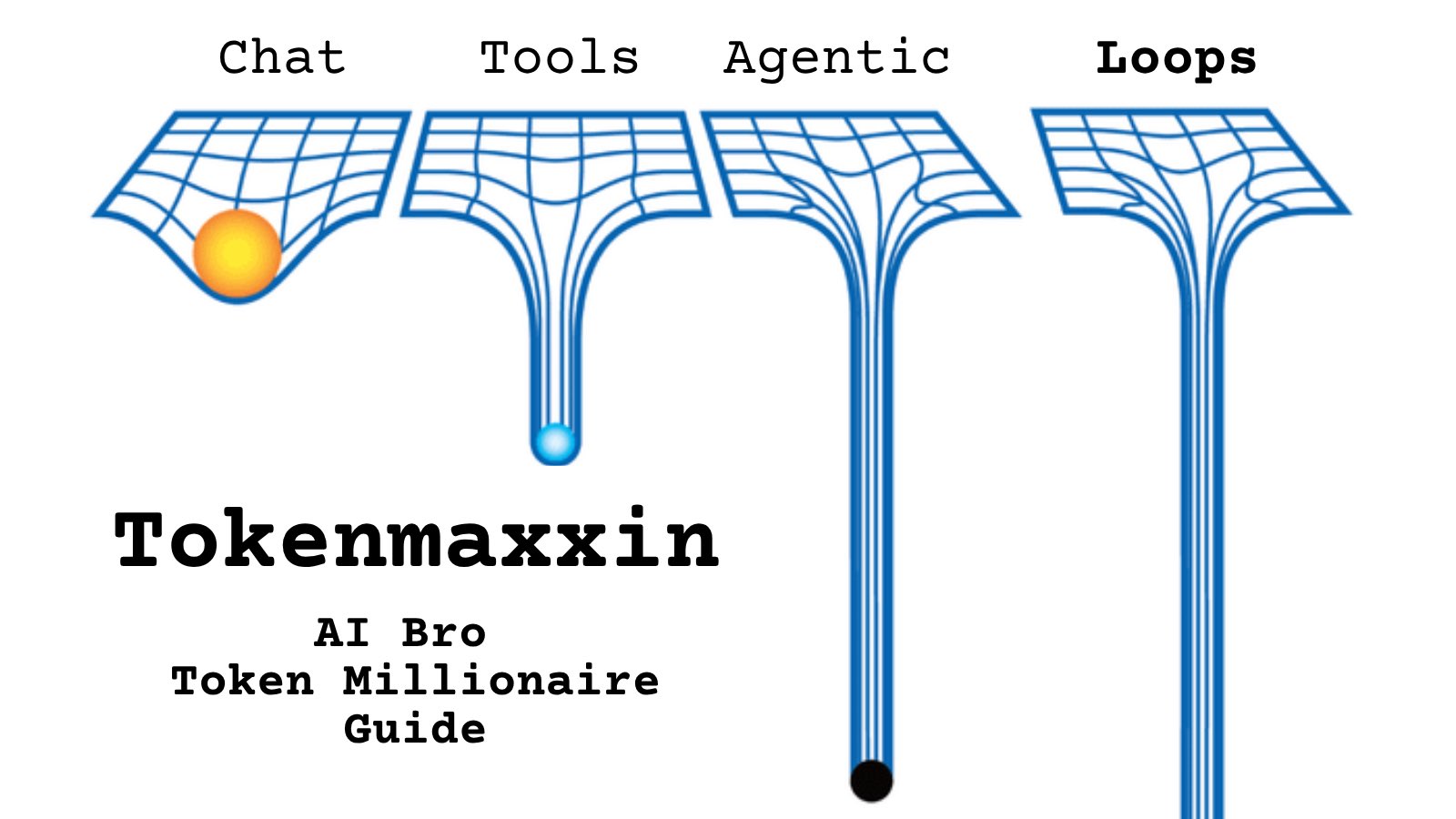
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
@rayjbjang https://t.co/d9ArOL64ZU
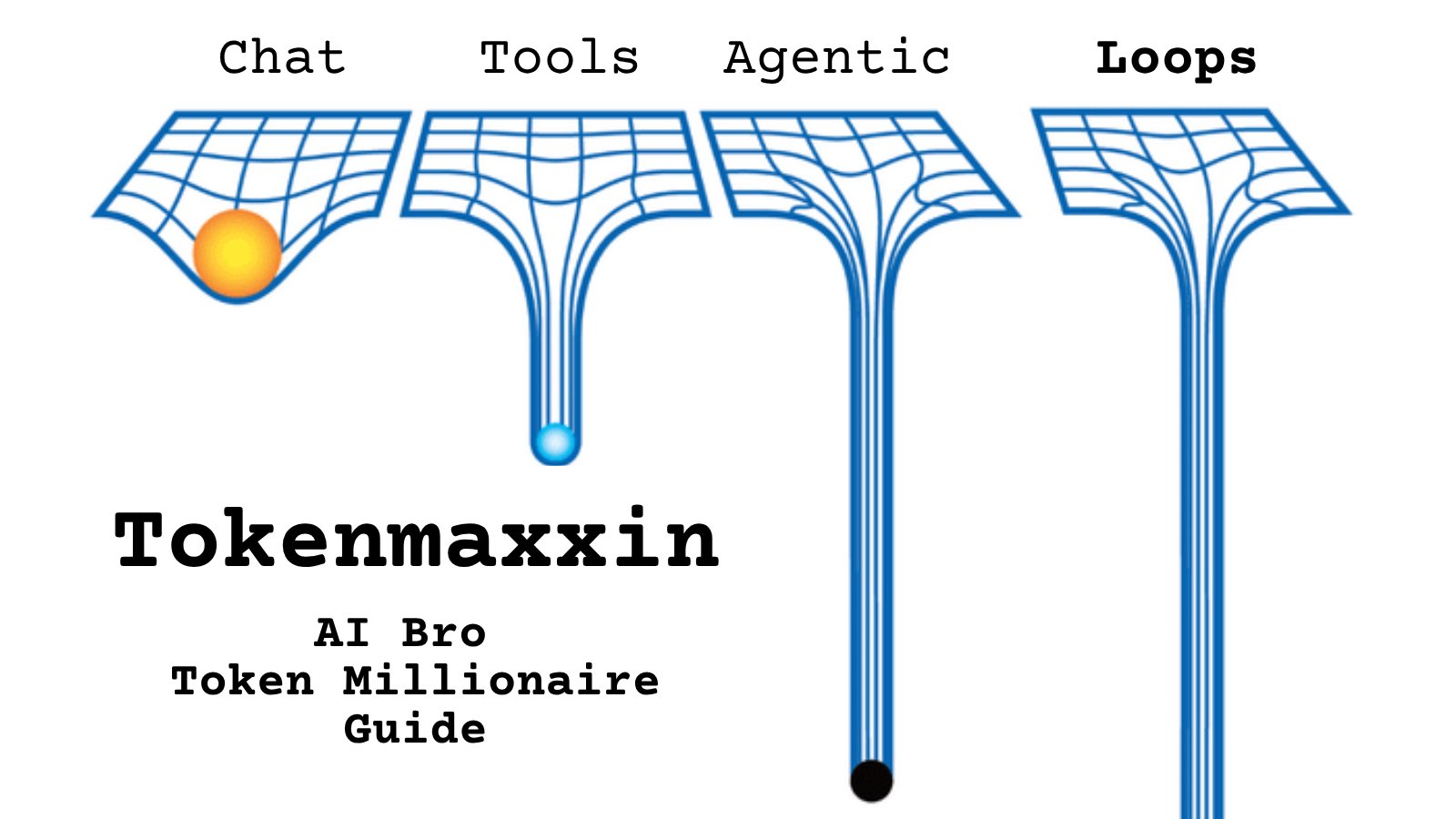
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
@usutaku_channel https://t.co/d9ArOL64ZU
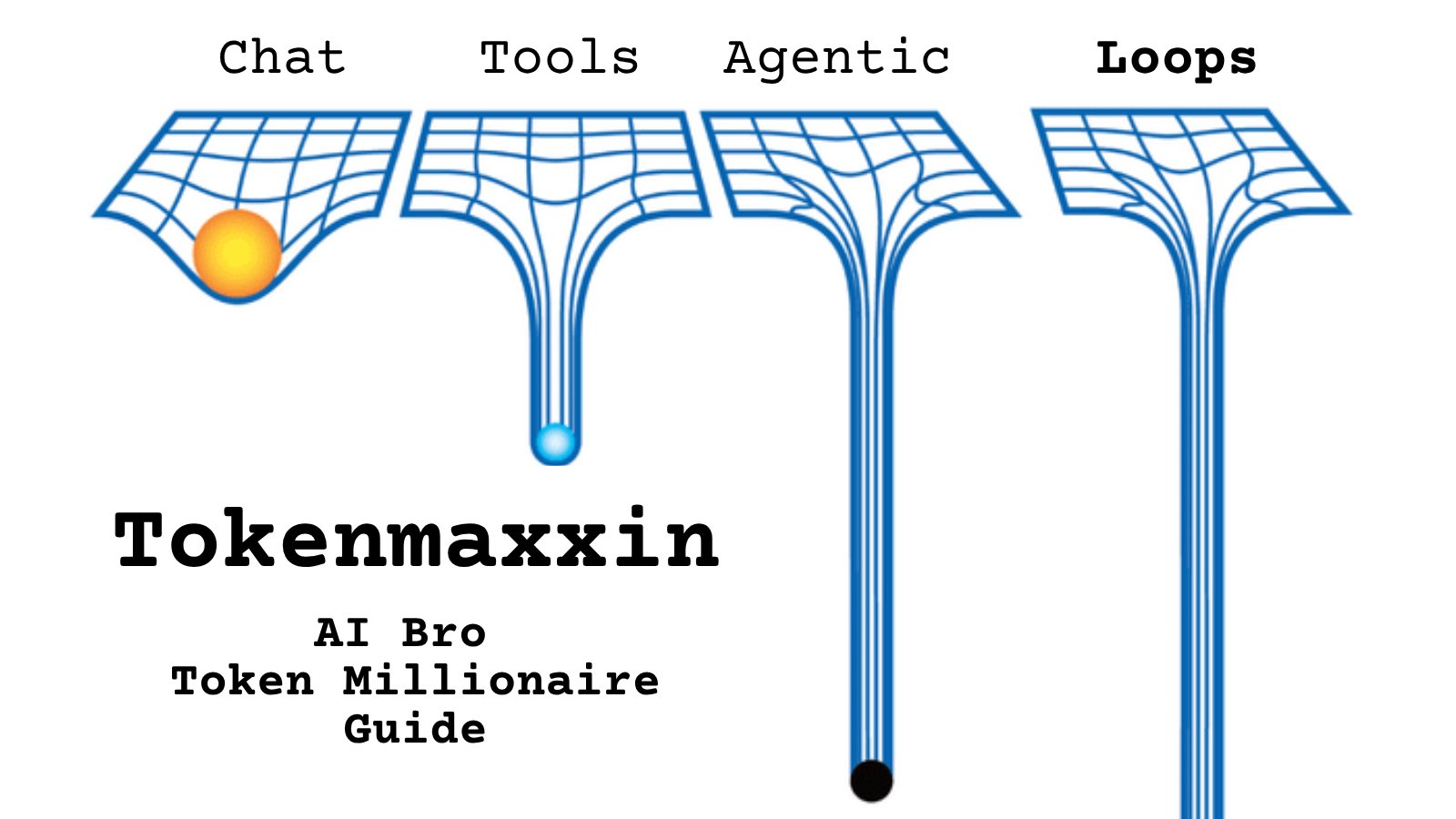
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
@beginnersblog1 https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
@gagarotai200 https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
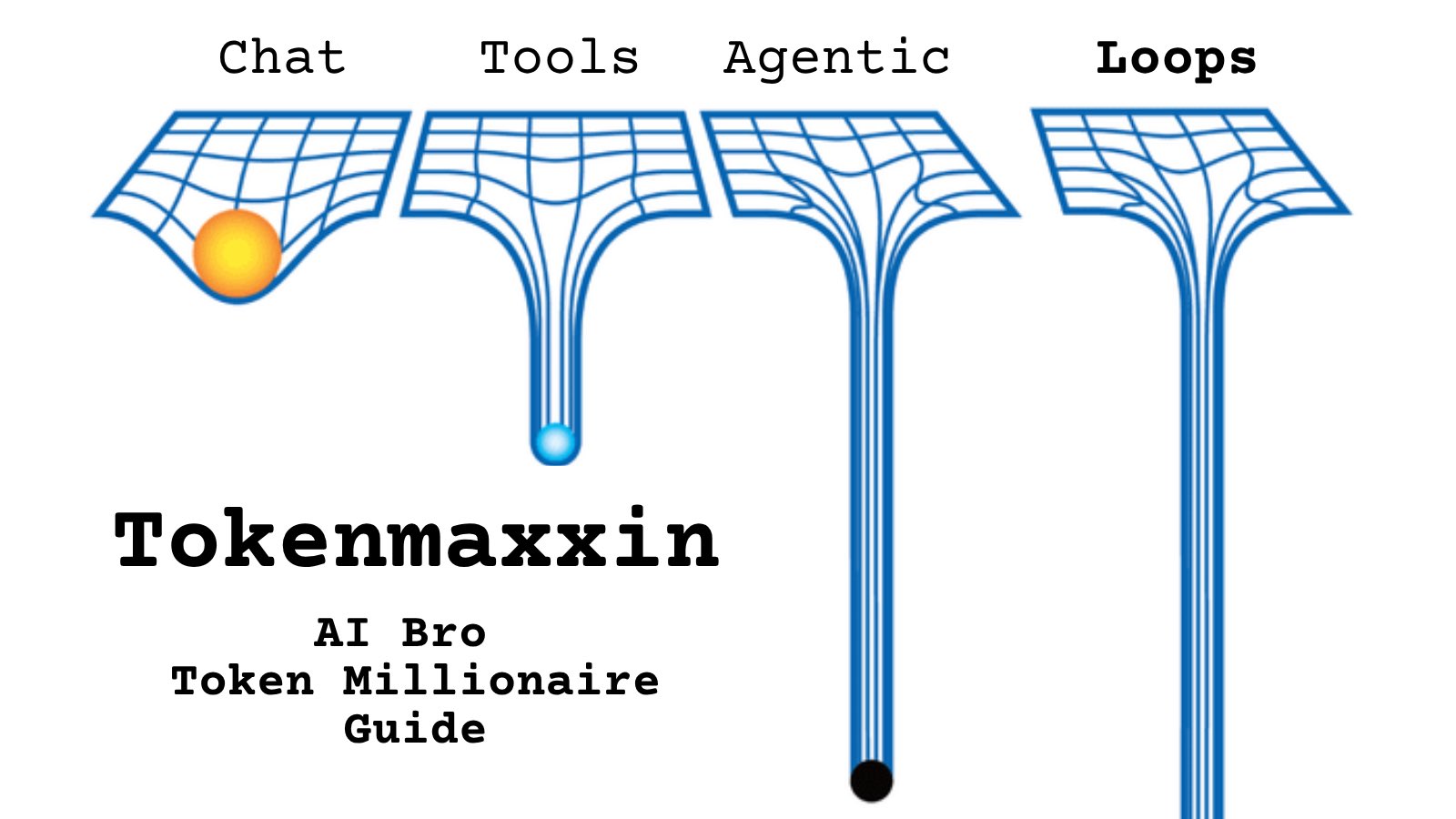
@chamath https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j