Your curated collection of saved posts and media
@MobileHackerz https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@itmedia_news https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
@koutarou_furuno https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
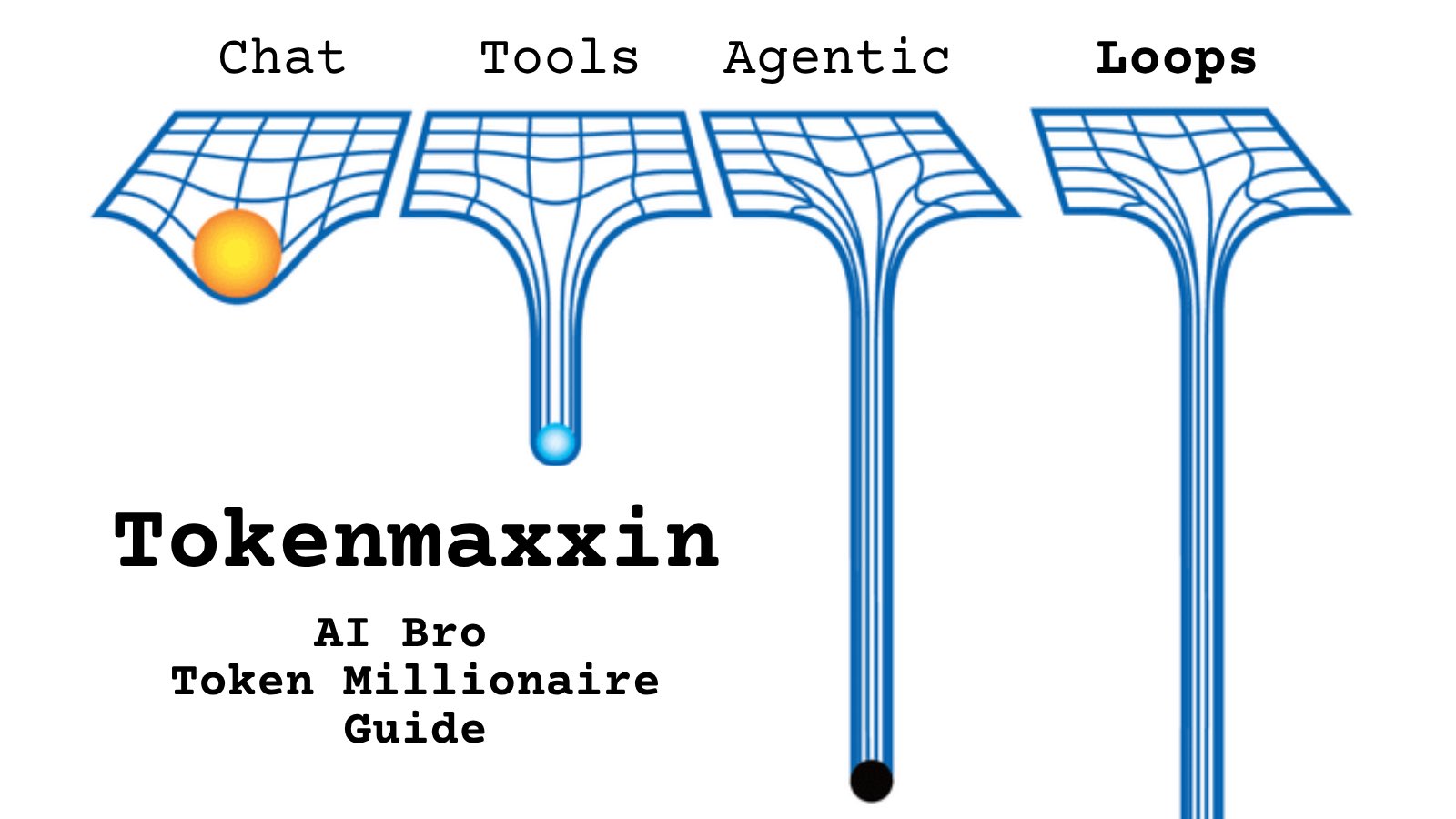
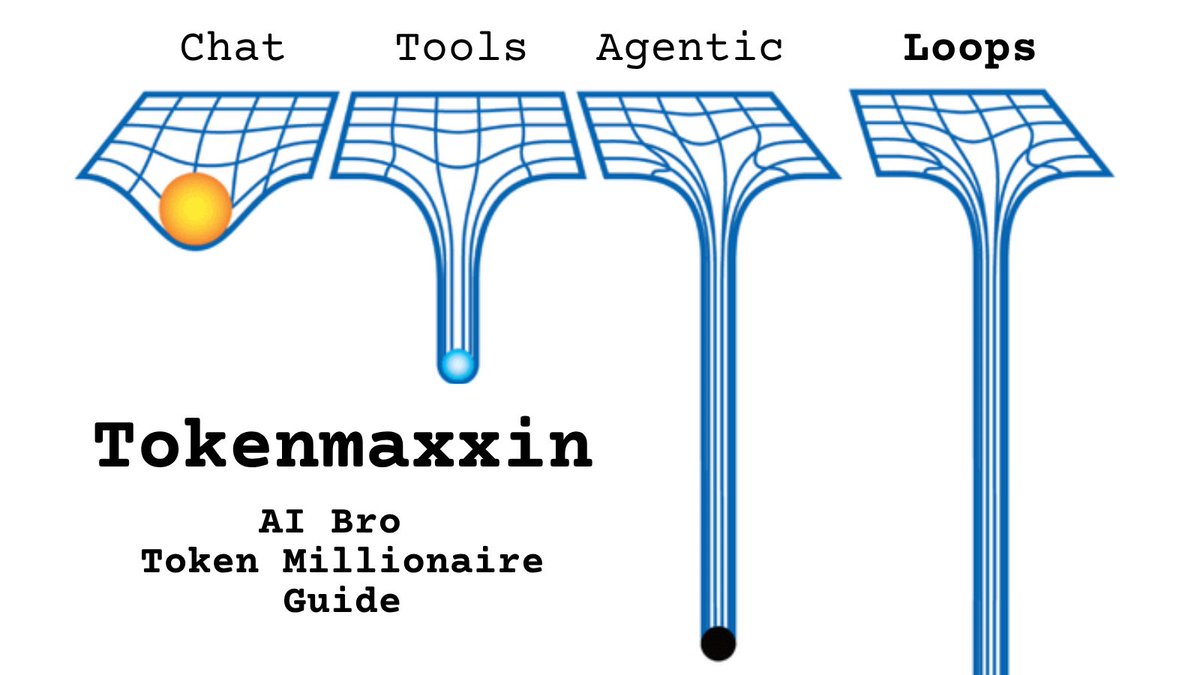
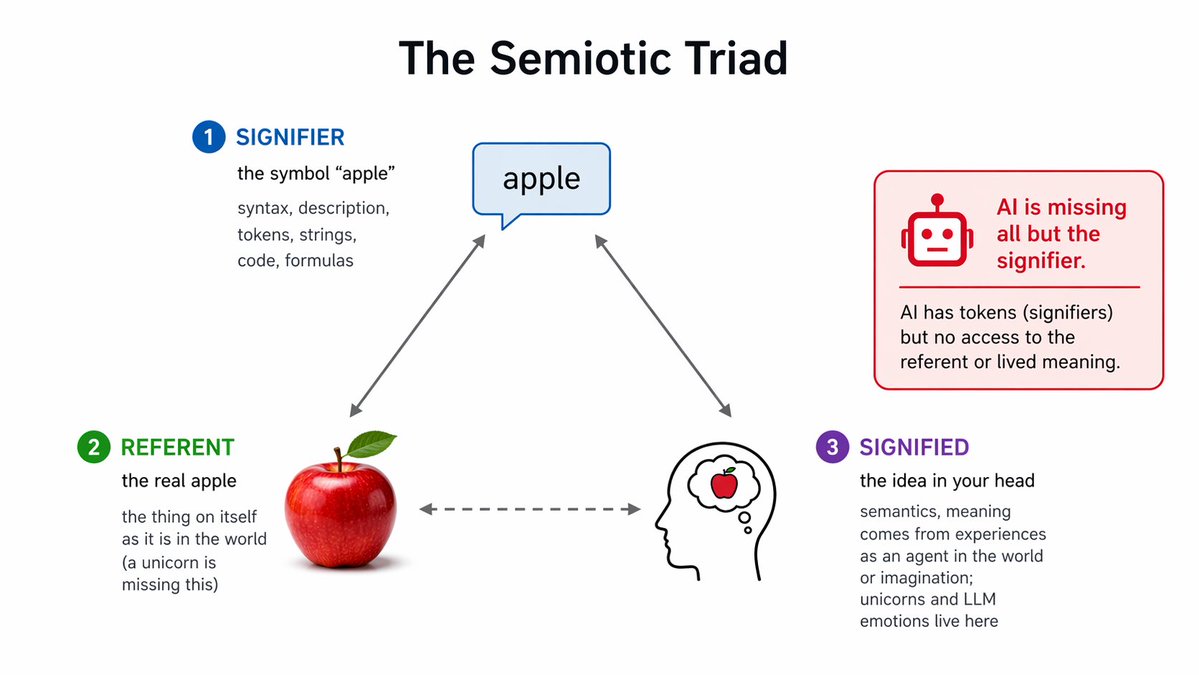
@GreenBeans80277 @erikphoel I can point to the moon but my finger will never become the moon. Tokens are like that finger pointing to the moon. While I understand it’s easy to get confused. The word is not the thing and it will never be. https://t.co/FB9NRVTKV5
@IwasakiYoichi https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@mujol_sv https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@Chi_Wang_ https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@Neetfujisub https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@ytranking https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@cryptogoos https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@traderyamamoto https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@ds_nakajima https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@DeItaone https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@Polymarket https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@nikkei https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@boku_higuma https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@YahooNewsTopics https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@dessaigne https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@polymarketjapan https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

@coinspace_ https://t.co/0FSLEE9Wfv
🚨 The “AI Agent” hype was never facts, it was vibes. Now the receipts are in. Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments: • 68% of traces: AI gathered evidence… then completely ignored it • 71% showed zero belief updates • Only 26% revised their o

Our lineup of speakers is growing! Many more to be announced.... and don't forget to submit your papers, deadline is very soon! More info at https://t.co/ux6MFRVd4t and submission page at https://t.co/yAmupEqYIs https://t.co/npJwiCHJr3

https://t.co/QSLinqFOZd

David Hockney changed the way we see the world. His work captured color, light and everyday life with a clarity and optimism that influenced generations of artists far beyond Britain. Great artists leave behind more than paintings. They leave behind a new way of looking at things.

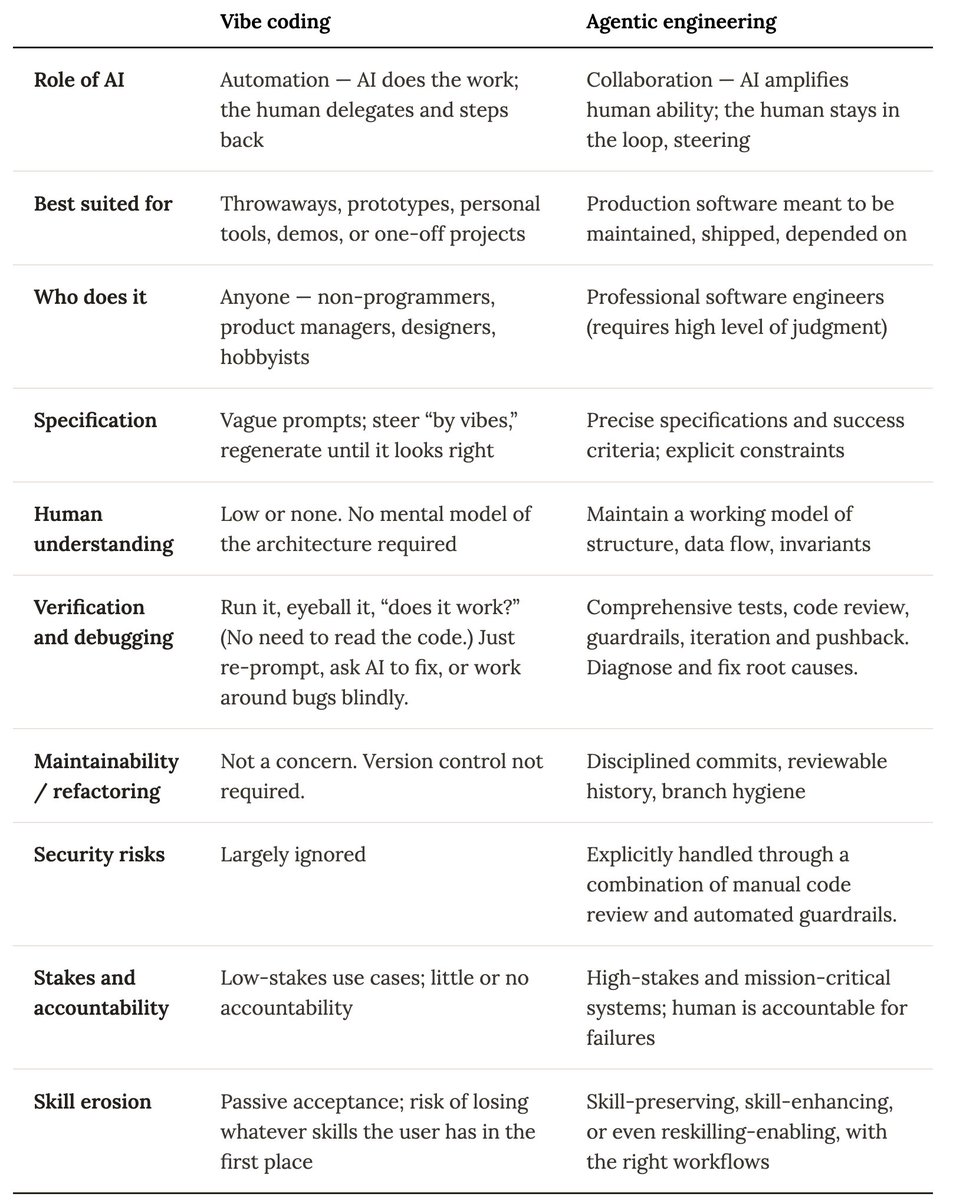
There are many simple things we can do to make the AI discourse less confusing and more productive, like not using "vibe coding" as an umbrella term to refer to all AI-assisted software development. https://t.co/0GLL0tXI6S https://t.co/zlie62h2hF
Back at @fastdotai, @math_rachel taught us ethics. She rocks. That's partly why I've been thinking about @jeremyphoward's strong views on Fable sandbagging. This is in my wiki: https://t.co/qwHMnWx6zo https://t.co/3tOfkLFj1m
Wow! She wrote this 8 years ago, like a prophecy for today!

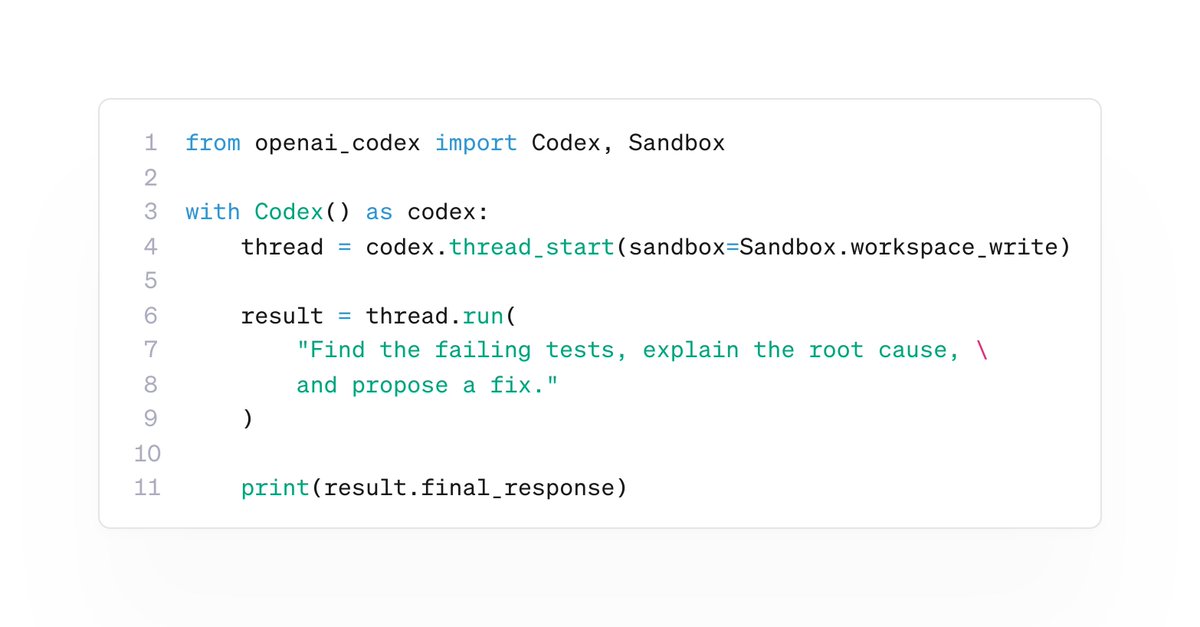
We just released the Codex Python SDK 🔥 You can now embed Codex directly into your Python apps and workflows! > Start threads > Run turns > Stream progress > Resume sessions > Pass images > Control sandbox access All whilst reusing your existing Codex auth. pip install openai-codex Go build with it!!
@MauPeon https://t.co/A3jiTrSG0L

Diffusion Gemma is 4x faster, but makes 6x more mistakes! We benchmarked the new diffusion LLM against its autoregressive twin on a single H100 (FP8). We gave each the same three tasks: write a Steve Jobs biography, the history of Tetris, and the story of BeOS - every next topic less popular than the previous one. Then we fact-checked every claim in every answer. Gemma4 got 45 facts right, 5 wrong. DiffusionGemma got 33 right, 28 wrong. The less popular the topic, the worse it got: 4 mistakes on Jobs, 12 on Tetris, 12 on BeOS. It named Clara Clley as Steve Jobs' mother, invented a colleague for Pajitnov named Geri Gulovik and priced the BeBox at $9,999. The real one cost $1,600. Outputs: Gemma4 26B A4B: 218 tok/s · 15.1s total · 45 facts · 5 mistakes DiffusionGemma 26B A4B: 763 tok/s · 3.7s total · 33 facts · 28 mistakes The reason is simple. DiffusionGemma throws 256 tokens on the screen at once and polishes them pass after pass until the text sounds smooth. Smooth is all it cares about: a fake name, date or number sounds just as smooth as a real one, so it stays. Regular Gemma4 meanwhile writes one word at a time and checks every new word against everything before it. Google says it themselves in the launch post: quality is lower, use regular Gemma 4 when facts matter.
Fable 5 is genuinely cracked at indie games… Fun fact, a lot of people didn’t believe me because it looks too good to be Claude Fable However it lobotomized the original game because my browser was lagging initially, so it made slightly smaller rooms and dimmed the dynamic lighting. This is the full un-lobotomized version 💀
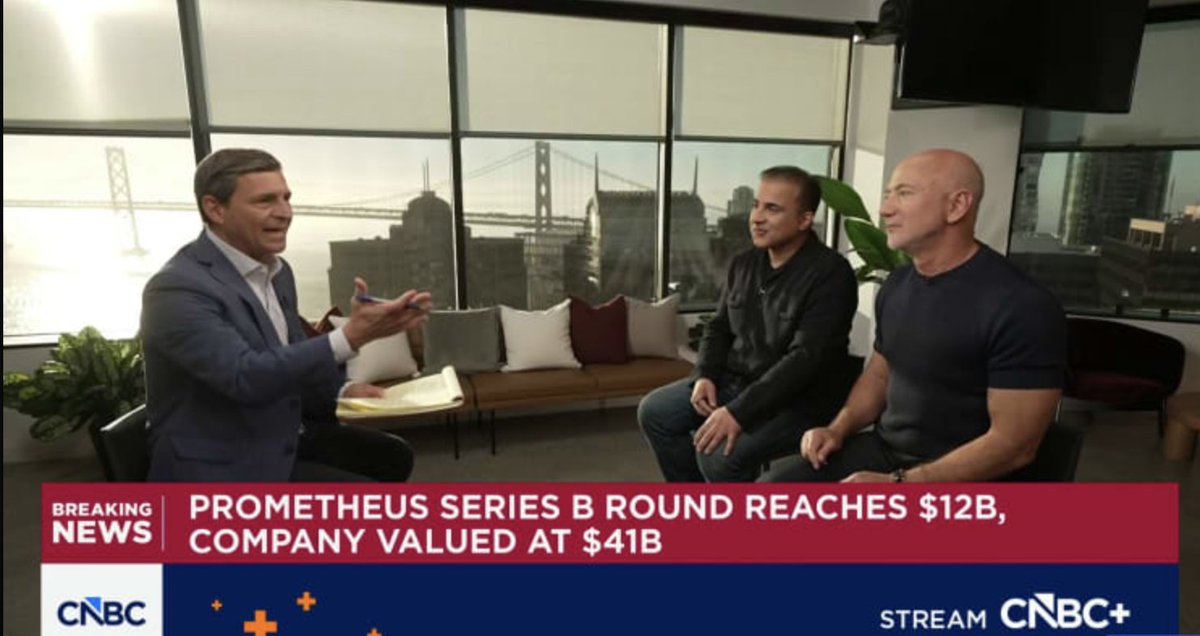
Jeff Bezos is making one of his biggest bets yet on AI. Prometheus’ $12 billion funding round shows that some of the world’s most influential entrepreneurs still see enormous opportunities ahead, despite growing concerns about AI valuations and competition. The next decade’s winners will not be determined by funding alone, but by who can turn AI ambition into real-world impact.
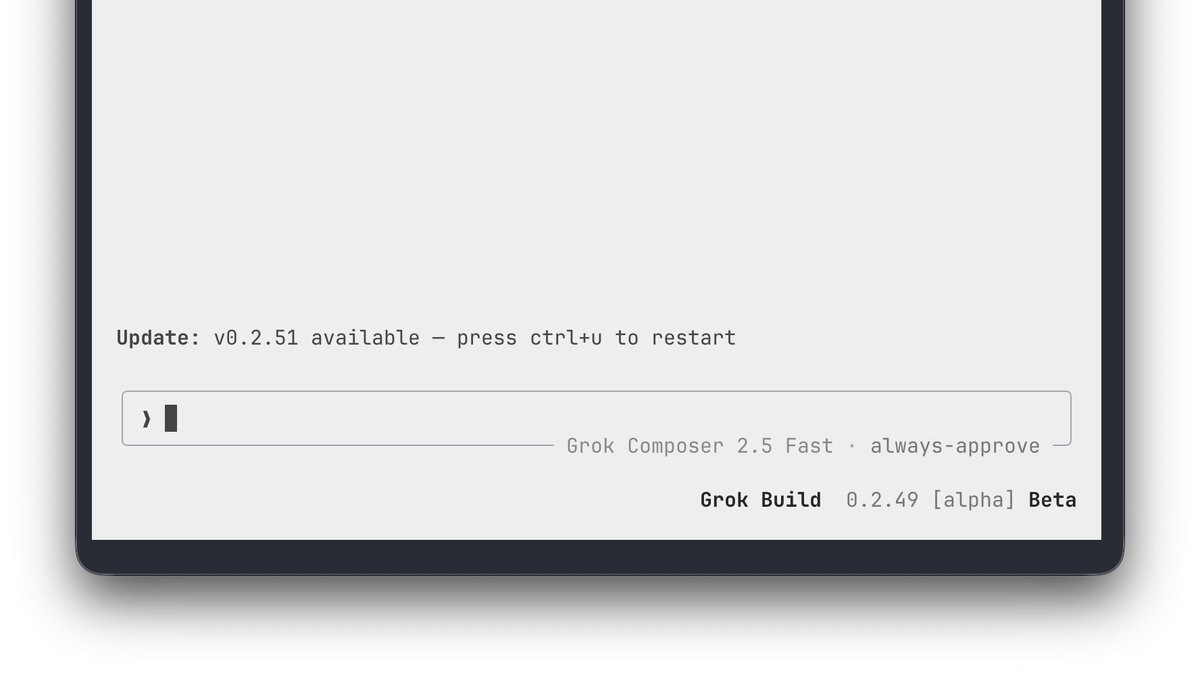
Grok Build just got a major update with a ton of new features and improvements Release Notes: v0.2.51 Breaking Changes: • grok mcp add now accepts positional arguments (e.g. grok mcp add filesystem -- npx ...), supports --scope project, and adds -e/-H flags for env/headers. Features: • Mermaid flowcharts now render subgraph blocks as titled frames with correct internal and cross-boundary edges. • Class diagrams in Mermaid now render as proper UML boxes with attributes, methods and inheritance arrows instead of raw source. • Permission prompts now accept a double-click on an option to submit it, matching the existing Enter and number-key shortcuts. • New /code-review slash command now ships with the CLI and is always available Bug Fixes: • Plan mode exit reminders no longer appear after the model has already started implementing the plan. • Expanded thinking blocks in scrollback now remain expanded when the agent finishes them. • grok update no longer downloads the same binary twice when multiple updaters or leader checks run concurrently. • Background task IDs after /compact are now shown verbatim so the model can reference them correctly in later tool calls. • Typing / while scrollback is focused now focuses the prompt and opens the slash-command dropdown.
Grok Build just got another update with improvements on reliability, stability, and developer experience Release Notes: v0.2.45 Features: • Mermaid diagrams now render to images when you click Open in a code block (enabled by default) Bug Fixes: • Fixed rare conversation corru