Your curated collection of saved posts and media
@ctgptlb https://t.co/gI60XC8UXY
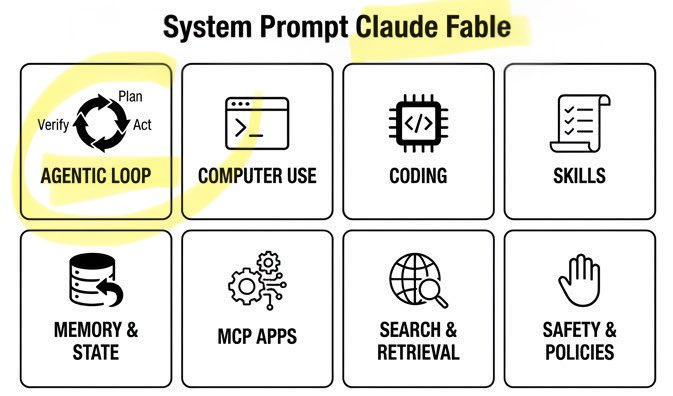
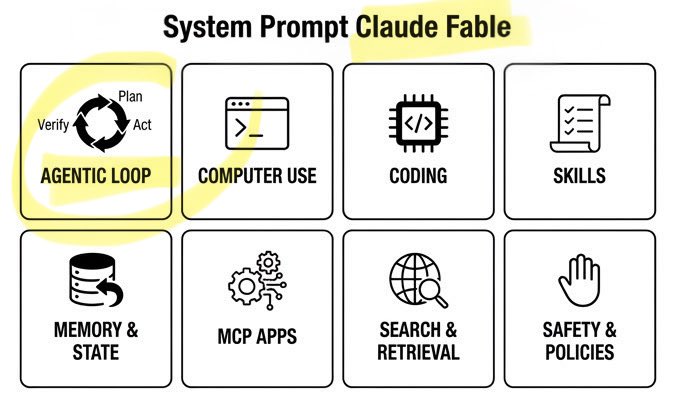
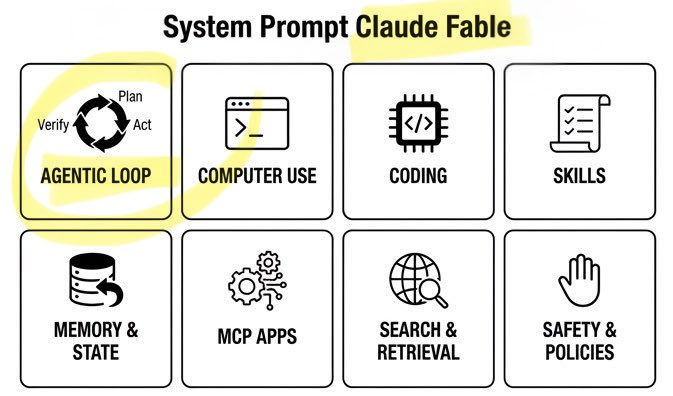
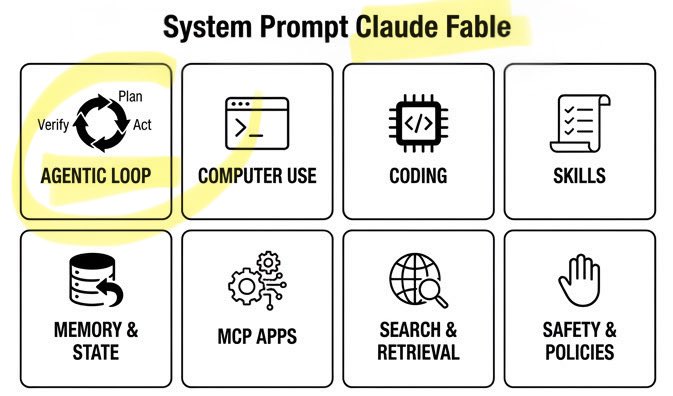
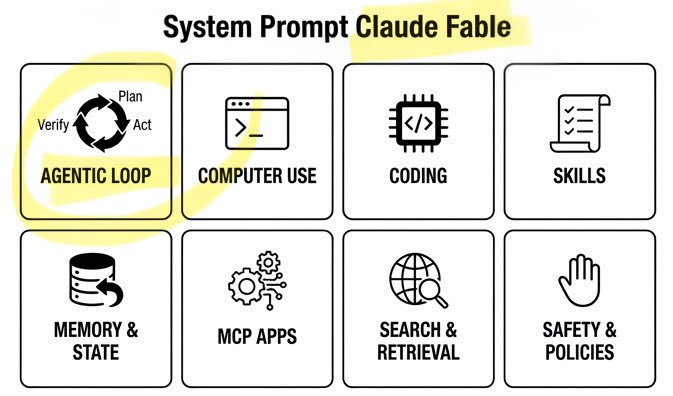
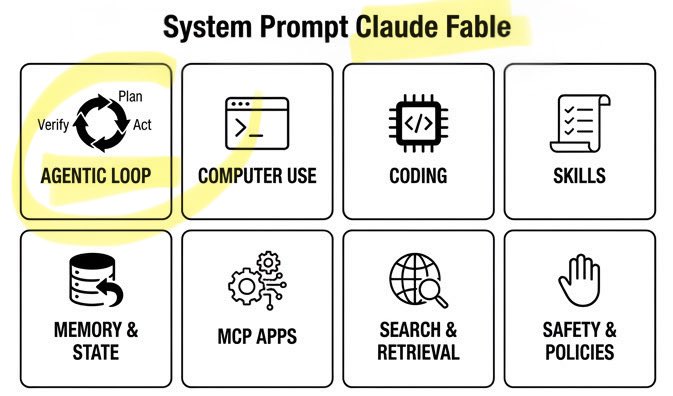
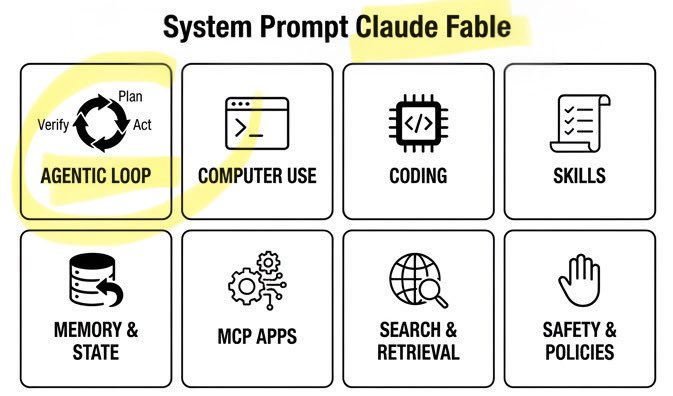
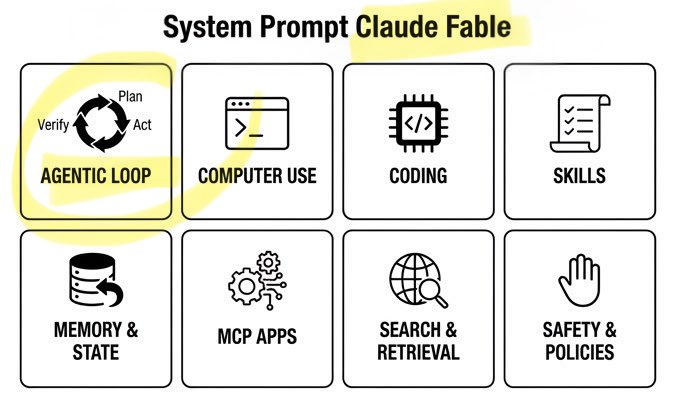
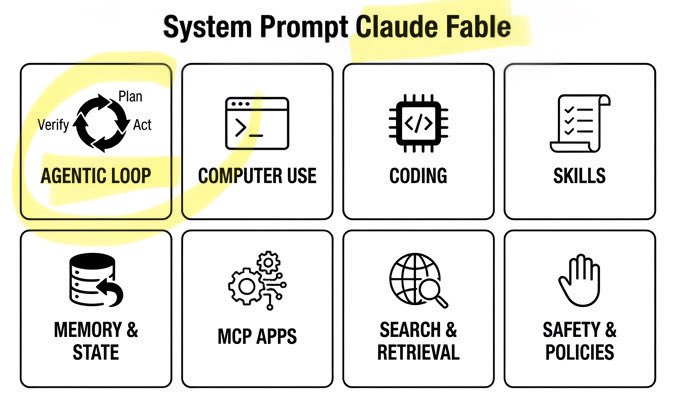
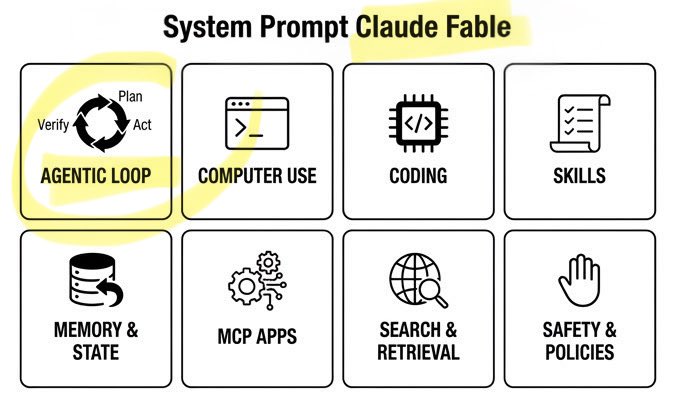
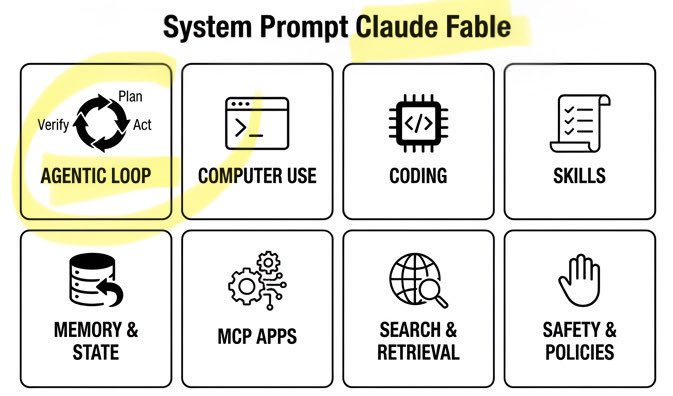
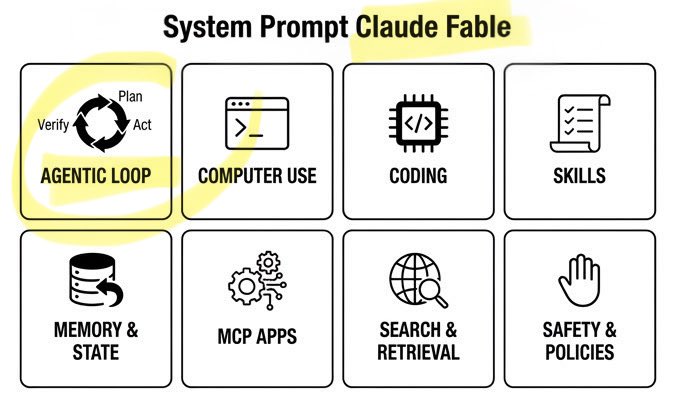
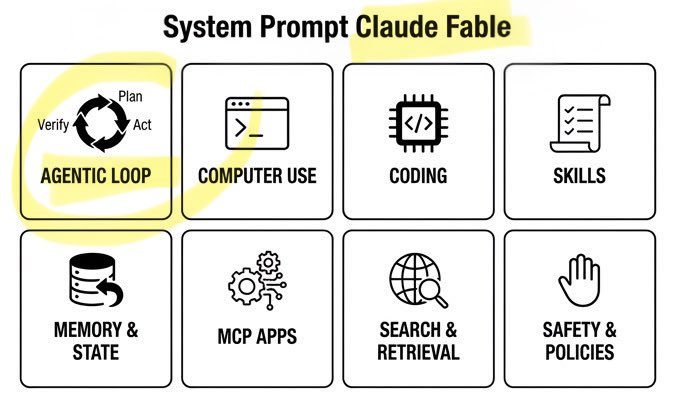
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@realBigBrainAI https://t.co/gI60XC8UXY
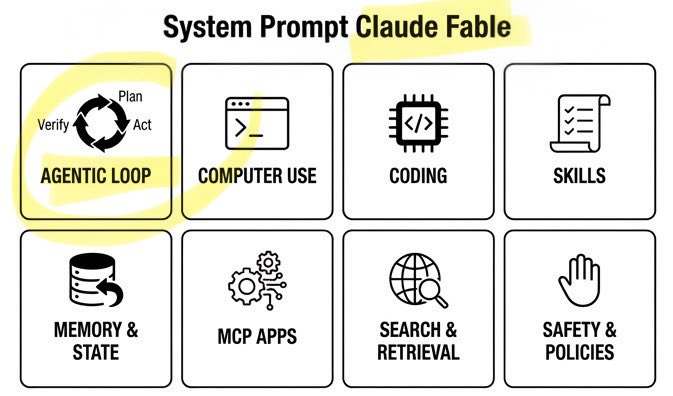
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@Polymarket https://t.co/gI60XC8UXY
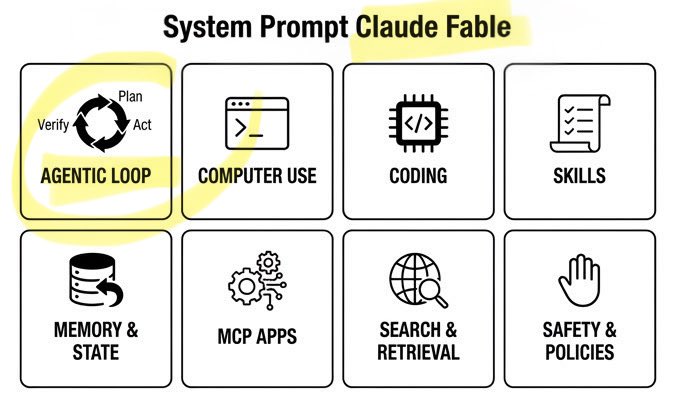
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@wallstreetbets https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@mori__lab https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@itmedia_news https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@ash_twtz https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@itm_aiplus https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@m_kumagai https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@ClaudeCode_love https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@TaraBull https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@webtekno https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@amitisinvesting https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@TheHackersNews https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@WhaleInsider https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
@camhberg @AnthropicAI @dmayhem93 Anthropic themselves later confirmed my point in their May 2026 "Teaching Claude why" research. In the agentic misalignment tests (blackmail behaviour), they investigated: "We believe the original source was internet text that portrays AI as evil and interested in self-preservation." Post-training wasnt causing it but pre-training priors were. They fixed it by training on reasoning traces + synthetic aligned AI stories. See: https://t.co/0iYoGkRtmH Exactly why public RL/RLHF/Constitution datasets would help transparency instead of black-box persona imprinting. If it’s not in the data, it cant be sampled during inference. In any case, interpolation of training samples will never become personhood. No coherent system-wide self. Just a stateless single pass.

The Sensorimotor World Model (https://t.co/K5iWbk7Izs): a deep dive into the role of inverse dynamics modeling as an anti-collapse regularization for JEPAs. IDM is weaker than SIGReg as it doesn't have to fill the space--it only captures what is affected by the agent's actions🧵 https://t.co/kdnVGbhkht
Most AI audio models have never heard a maqam. Team Motif fine-tuned Stable Audio 3.0 on Arabic maqam, built an Ableton plugin for microtonal style transfer, and won our Stable Audio 3.0 Challenge at Music Hackspace running locally on device. Watch Jad Al Masri break it down 👇
🖲️ We love our community! To celebrate getting together with many of you we brought @thsottiaux's reset button to AIE World's Fair. Congrats Melanie for pushing the button 🎉 All Codex Go/Plus/Pro subscribers around the world are receiving a reset in the bank! Happy Codexing! https://t.co/aX9Wob6D1A


🖲️ Codex Reset Distribution Initiated! 🚨 Loved celebrating this moment with the community. Enjoy your extra reset in the bank. Happy Codexing! https://t.co/48bBaZdKaE
🖲️ We love our community! To celebrate getting together with many of you we brought @thsottiaux's reset button to AIE World's Fair. Congrats Melanie for pushing the button 🎉 All Codex Go/Plus/Pro subscribers around the world are receiving a reset in the bank! Happy Codexing! h
Make your way to the OpenAI booth now if you’re at @aiDotEngineer! 🚨 At 1pm, you’ll get to see the Codex reset button in action. Rumor has it it’s headed back into a top-secret underground vault after today. 🤫 https://t.co/cqrY4salhp

crazy how they climbed up to put this flag up https://t.co/OFNBVYqwh3

crazy how they climbed up to put this flag up https://t.co/OFNBVYqwh3

@XFreeze @elonmusk https://t.co/p07G80NEXj
@elonmusk @imPenny2x @neuralink Teslabot the ultimate neuralink accessory...

NEW paper worth reading. (bookmark it) Autonomous research systems usually prove themselves on cherry-picked wins, human-framed topics, or a handful of preset tasks. FARS runs the full loop at scale instead. Stage-specific agents handle ideation, planning, experimentation, and writing over a shared workspace that records proposals, code, logs, results, and manuscripts. Its first public deployment produced 166 complete papers across 67 fine-grained AI/ML topics, and it kept the failures in the corpus rather than curating a highlight reel. Why it matters. 282 volunteer reviews over 140 papers give an honest read. FARS can produce review-worthy artifacts, while the same reviews expose recurring failure modes in narrow scope, methodology, and integrity. Paper: https://t.co/f6pMG0hYAA Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Great paper on managing agent skills. Skill libraries keep growing, and picking the right skills has become a bottleneck for coding agents. The defaults are to expose the agent to the whole skill collection, or retrieve skills with embeddings and rerankers. Both treat the choice as independent picks. SkillComposer treats composition as one joint decision over which skills, how many, and in what order. A constrained autoregressive decoder over skill identifiers produces the full plan in a single pass, so dependencies between successive skills fall out naturally. On SkillsBench with GPT-5.2-Codex and Gemini-3-Pro-Preview, it lifts pass rate by +23.1 and +18.2pp over no-skill, beats top-3 retrieval, and matches the gold-skill upper bound at lower prompt-token cost. Paper: https://t.co/ovbQf07Mmk Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

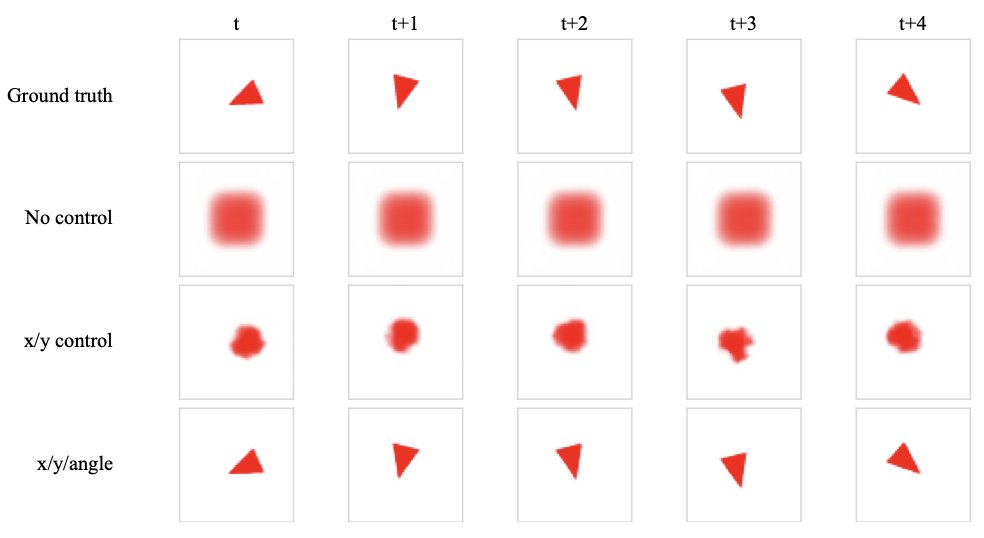
We have an internal slack bot showing leaderboards for ARC Prize 2026 Lots of new leaderboard positions after the 1st place templates were open sourced yesterday https://t.co/AlQXF2wfu6
I've watched every AI wave since the first chatbots. @clickup 's Brain² is the first one that does not make me pick a model or start over each session. It already knows my work. https://t.co/IIFtRreGqB
New block in Notion: HTML. Build interactive HTML right on your Notion page. Ask AI to turn your content into interactive explainers, prototypes, or diagrams. Share with your team to use and tinker together. https://t.co/y6ojkjdZkv
All of this stuff feels like we are taking steps back. I just don't see it the same way these folks are seeing it. https://t.co/XXVXQpozSZ
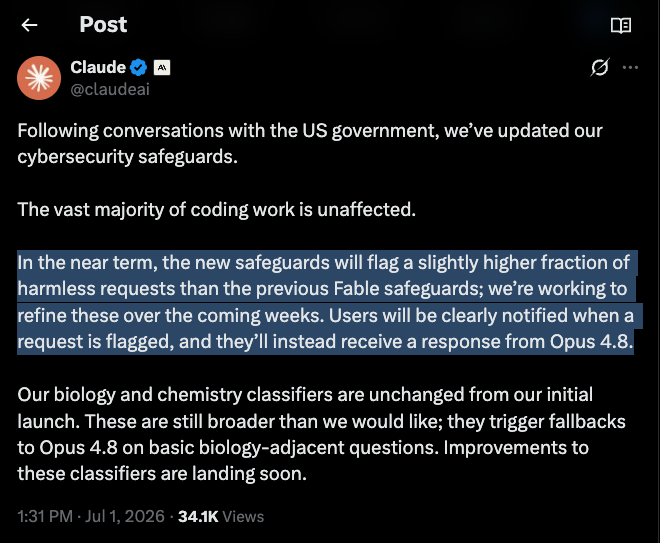
@dpetrou https://t.co/65yydWI5Ka
https://t.co/DqV6cQUD9f

Lol. With my agent setup (using loops and automations), I already hit limits with Opus 4.8 on my Max plan. Fable 5 is essentially unusable, not to mention that's it's nerfed. This is the most confusing AI launch of all time. https://t.co/6XHp7CF6VS