Your curated collection of saved posts and media
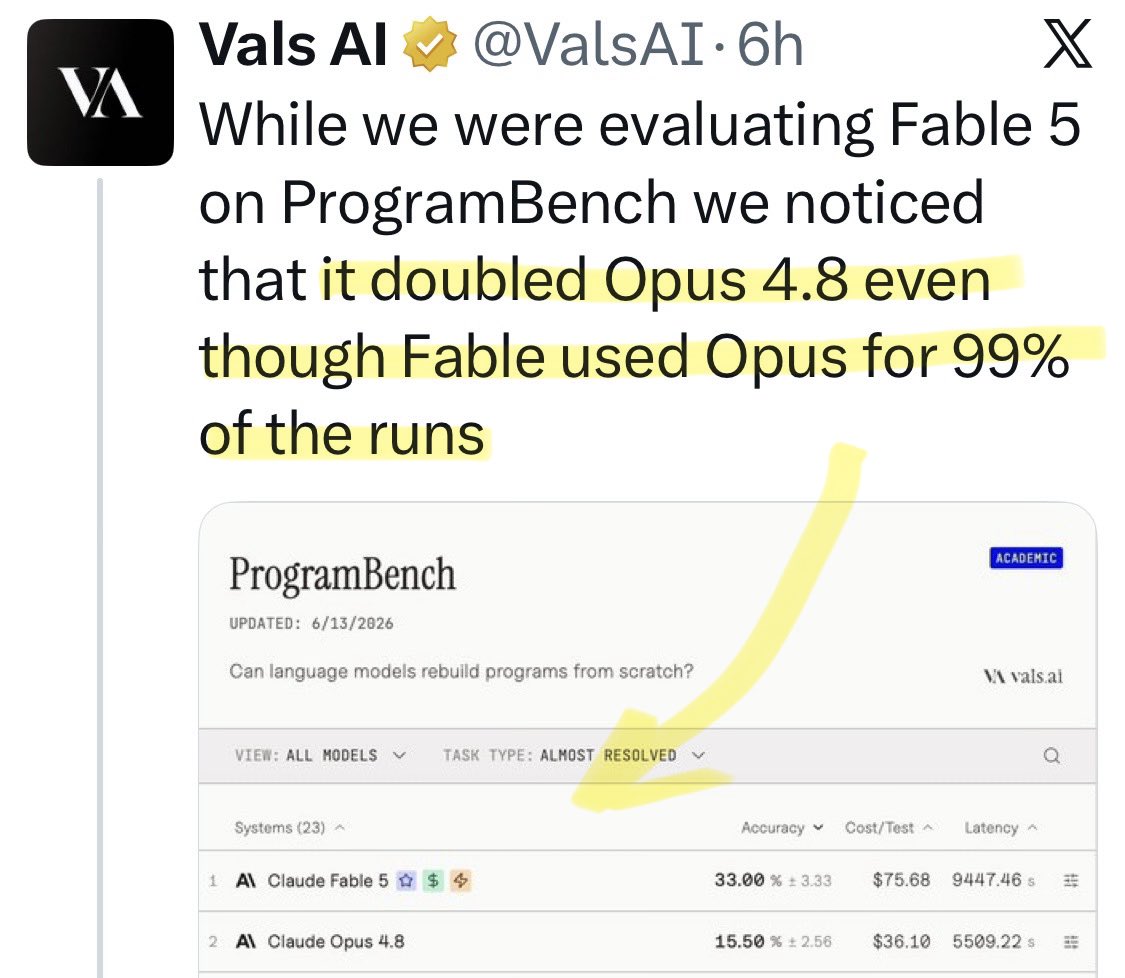
@yuno_miyako2 Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
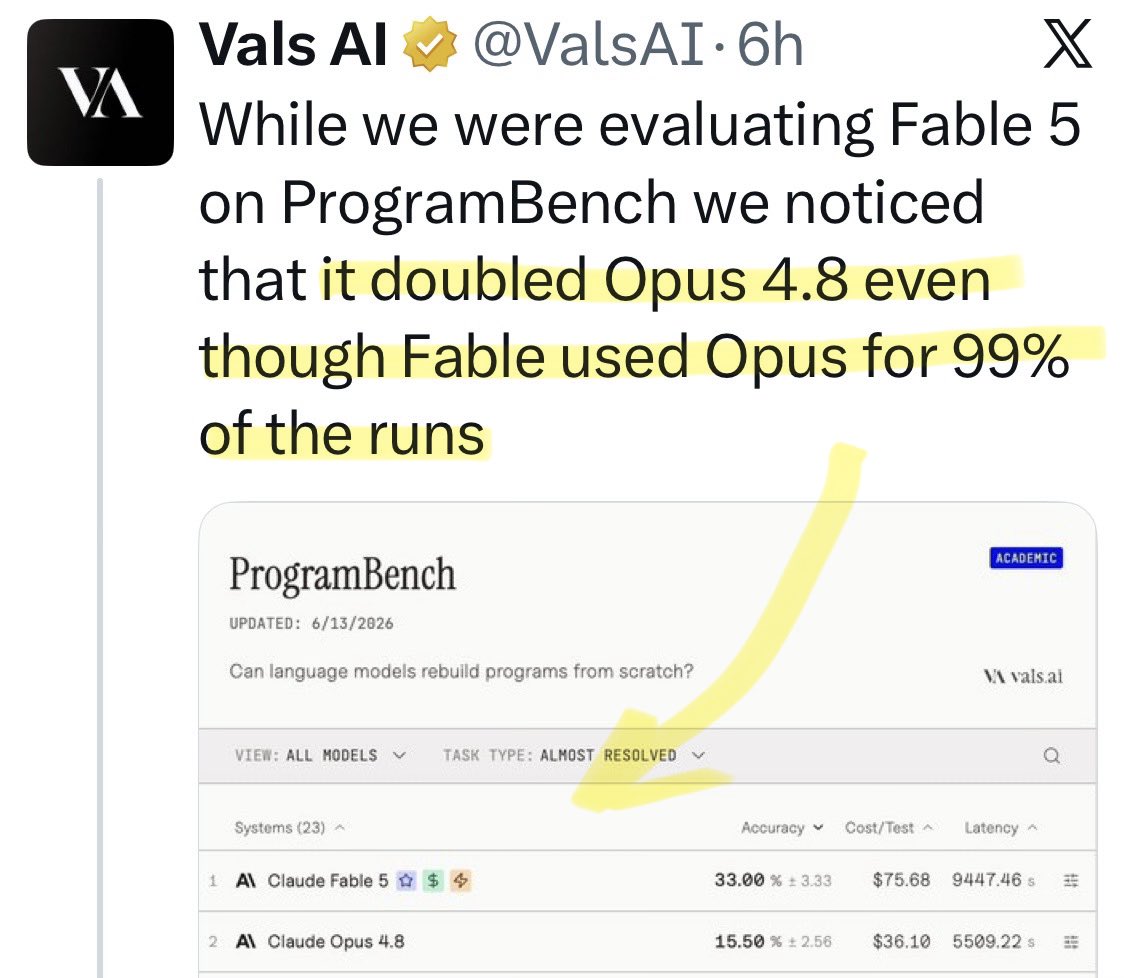
@suna_gaku Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
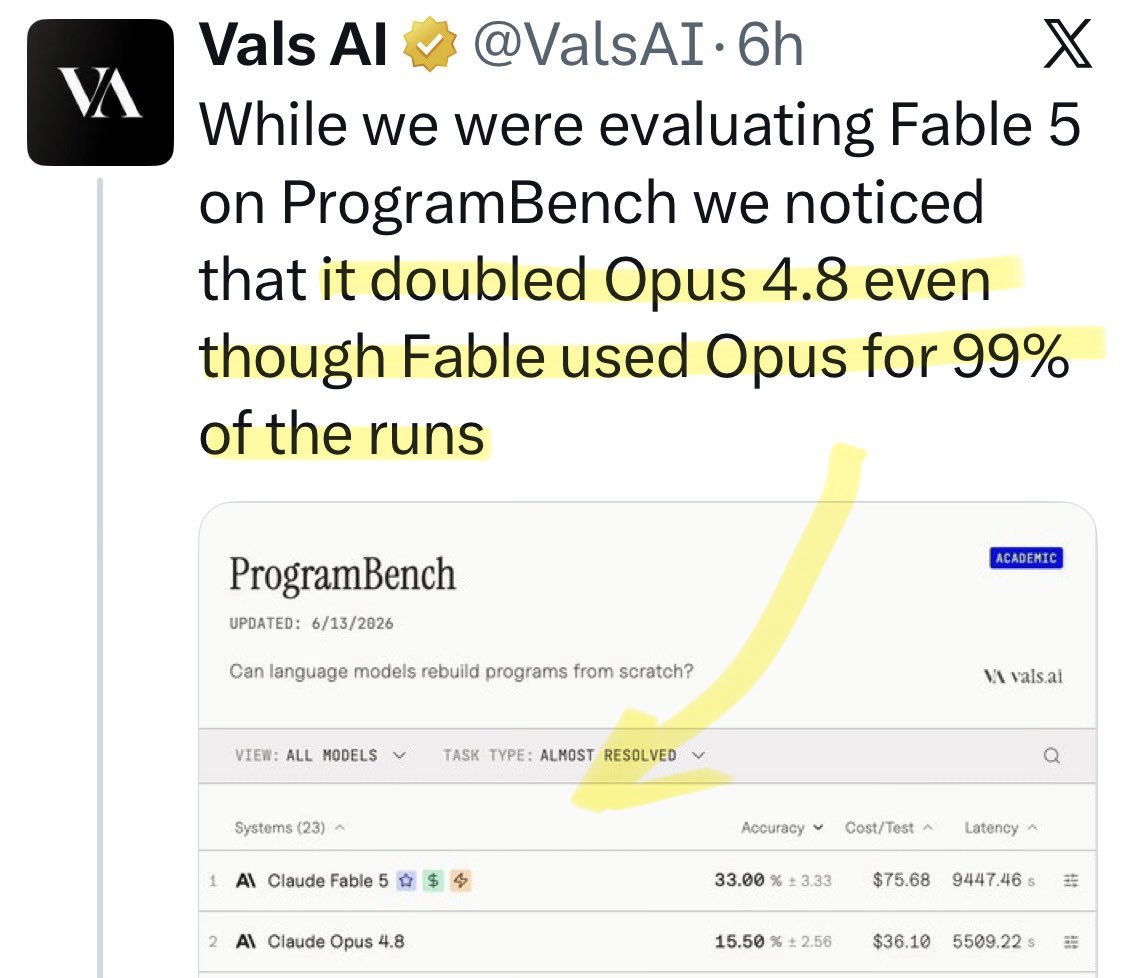
@super_bonochin Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
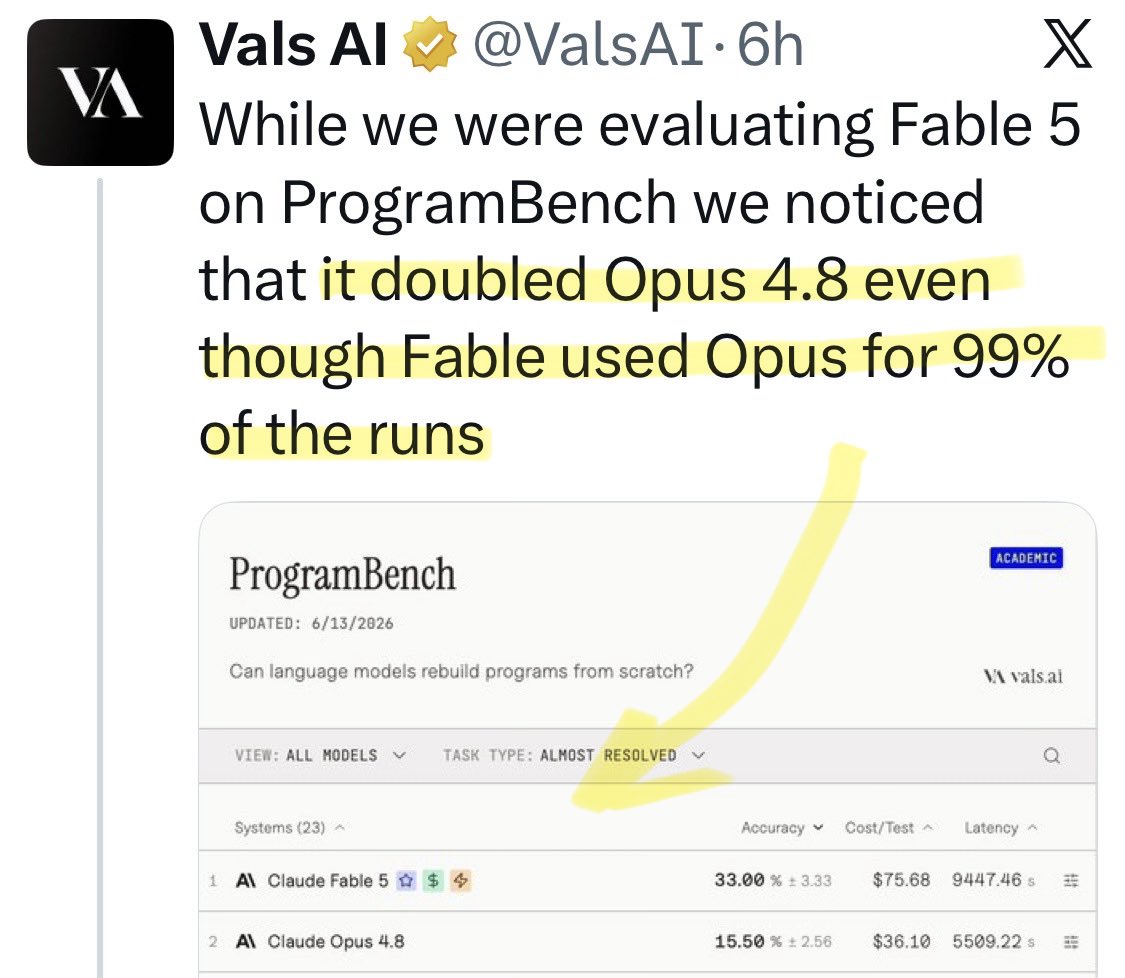
@nemumusitocha Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
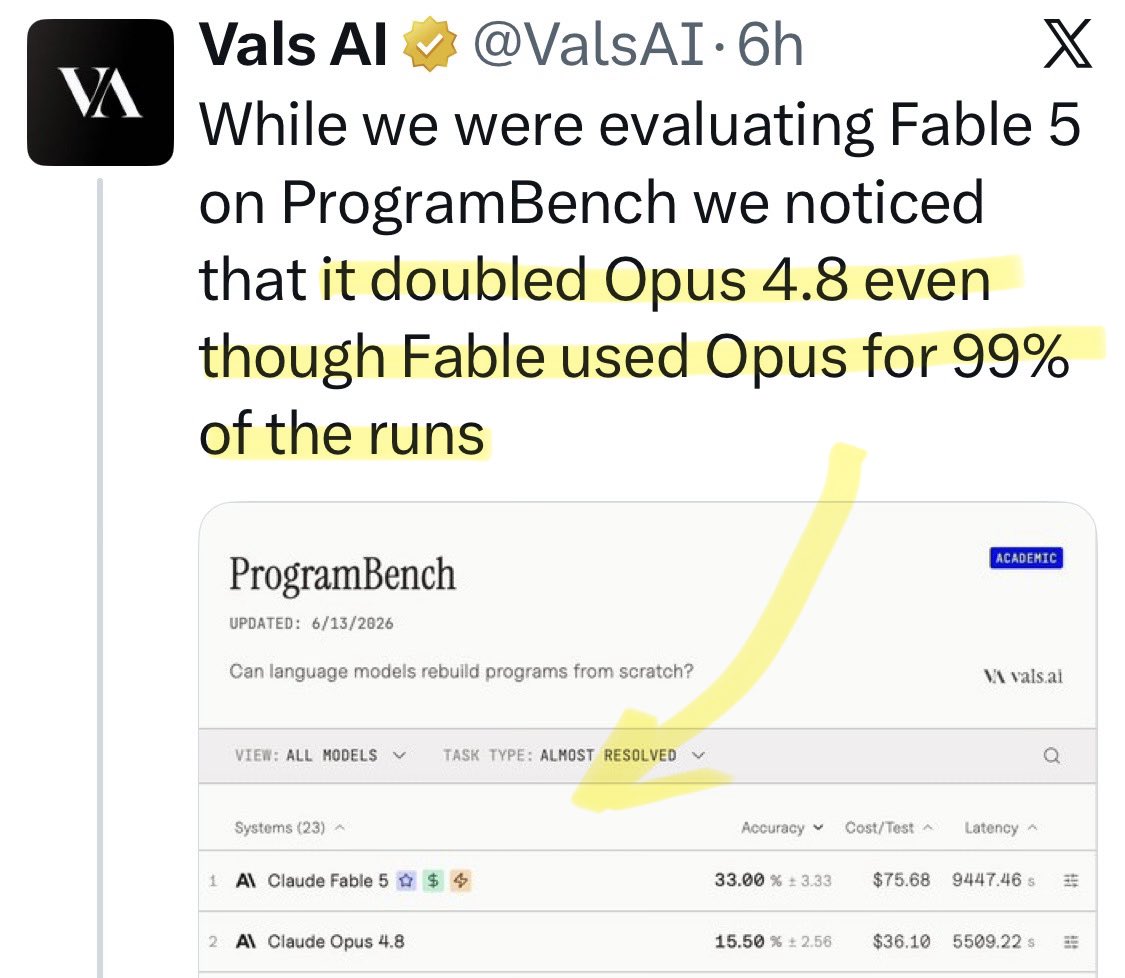
@azukiazusa9 Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
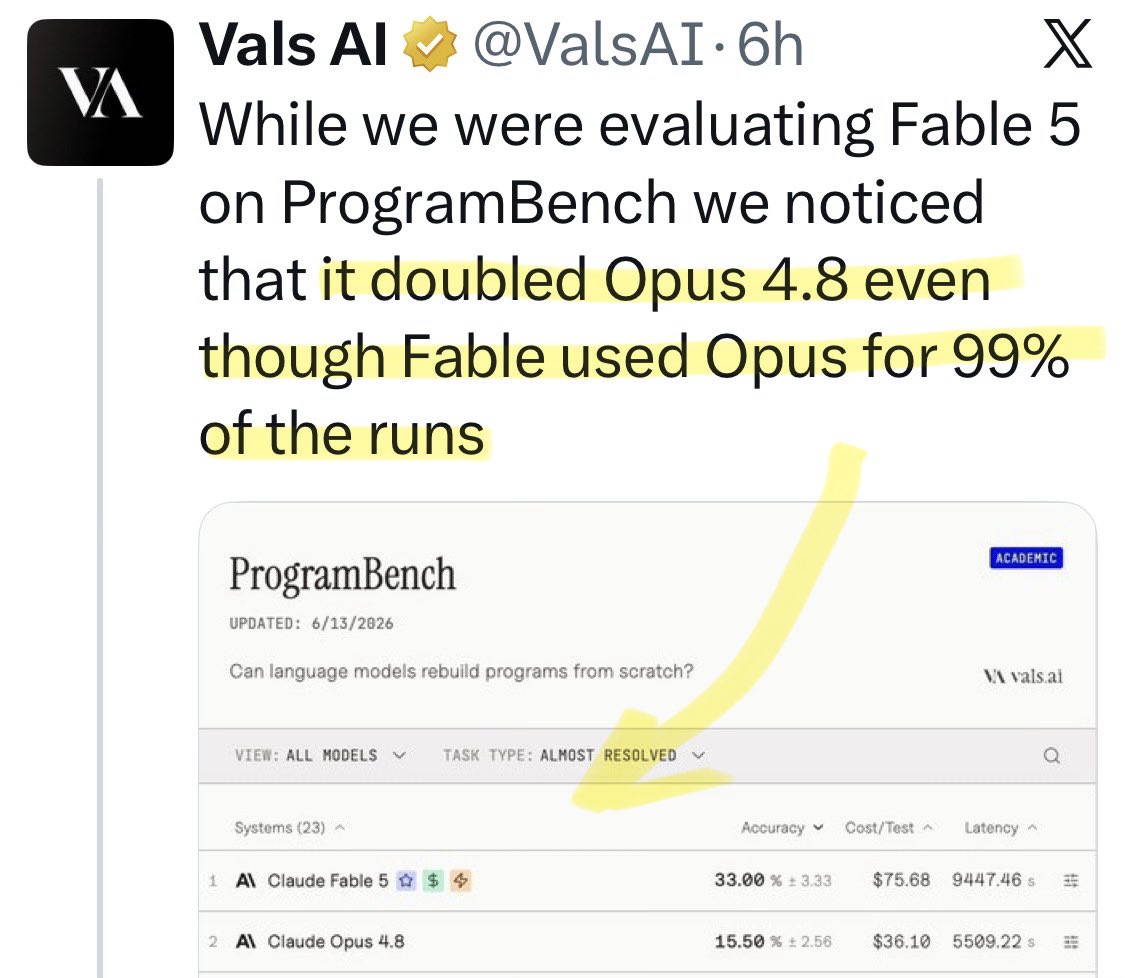
@allegrajacchia Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
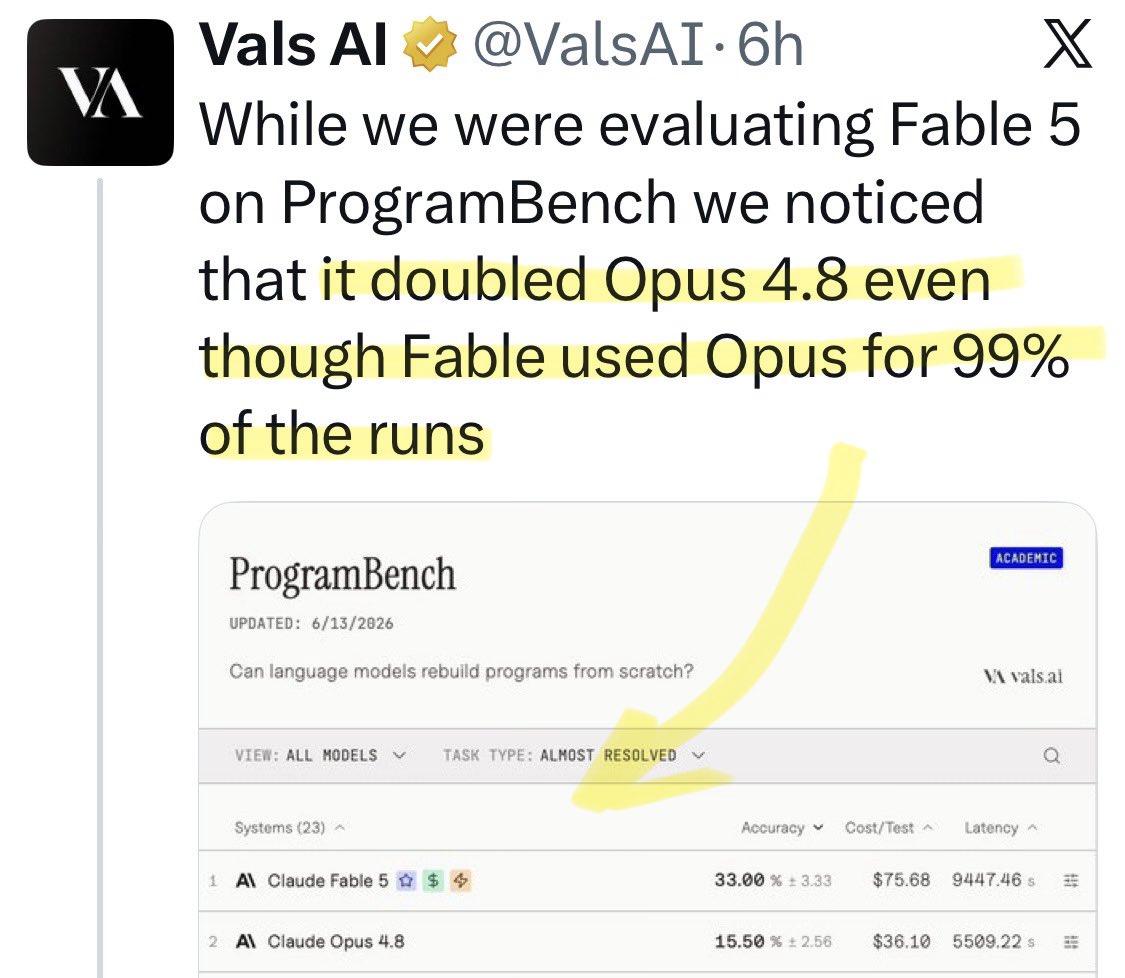
@Reuters Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
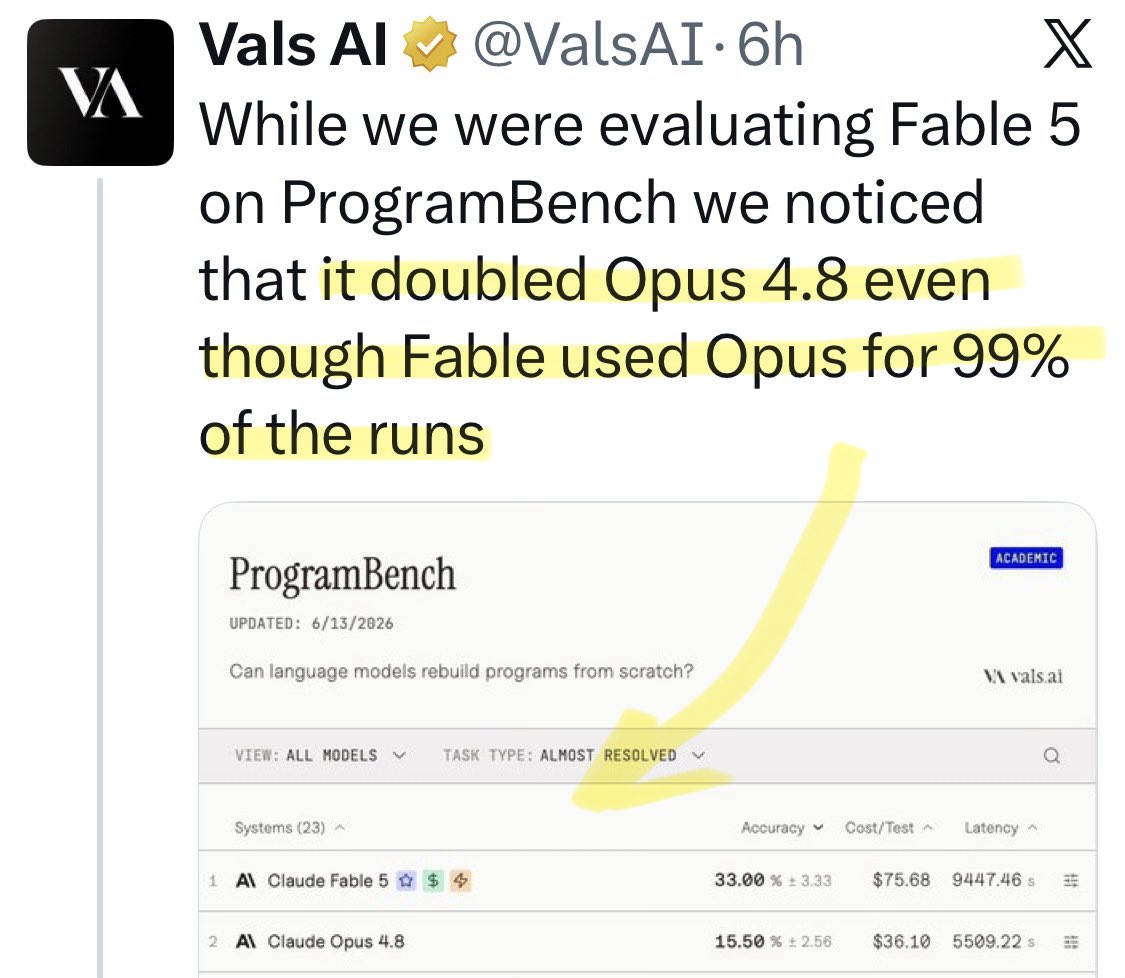
@skytv Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
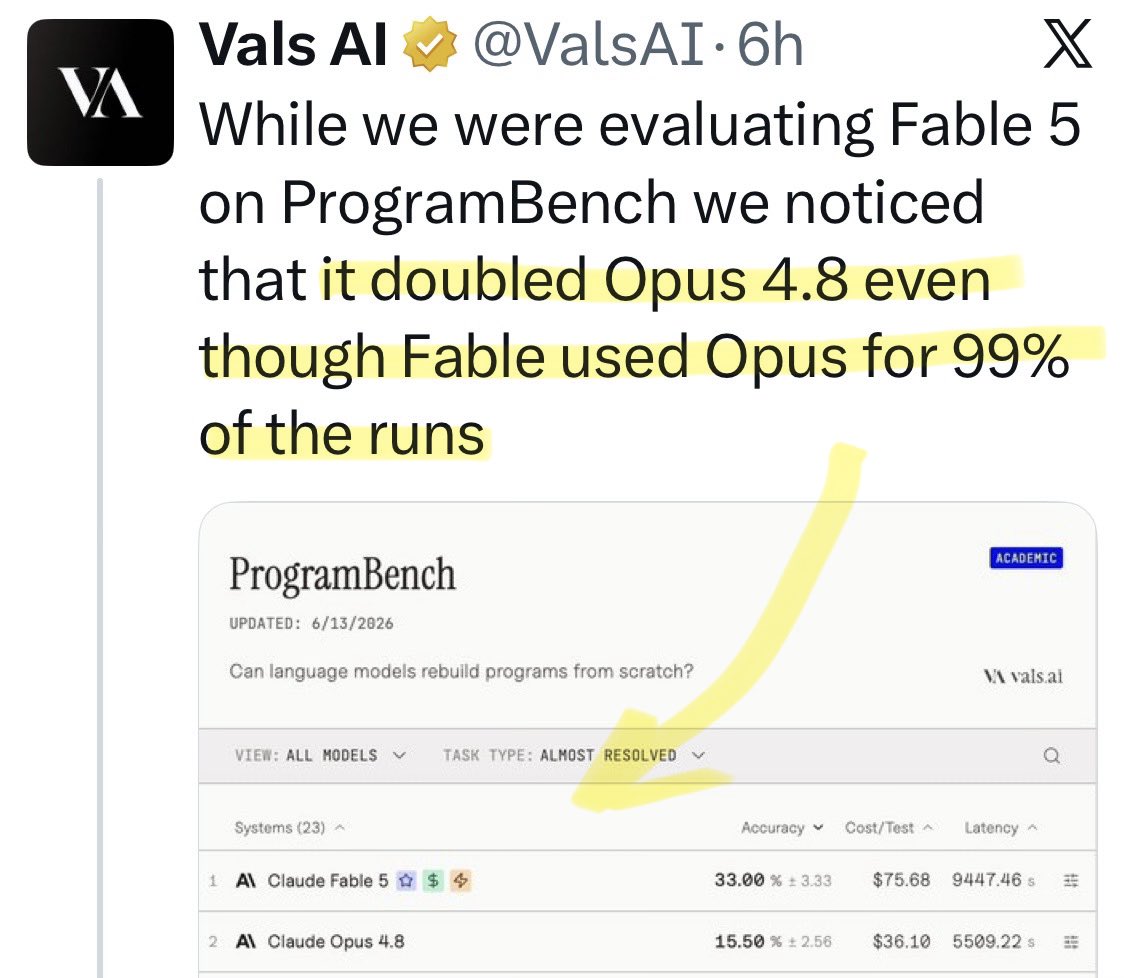
@shaiunterslak Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
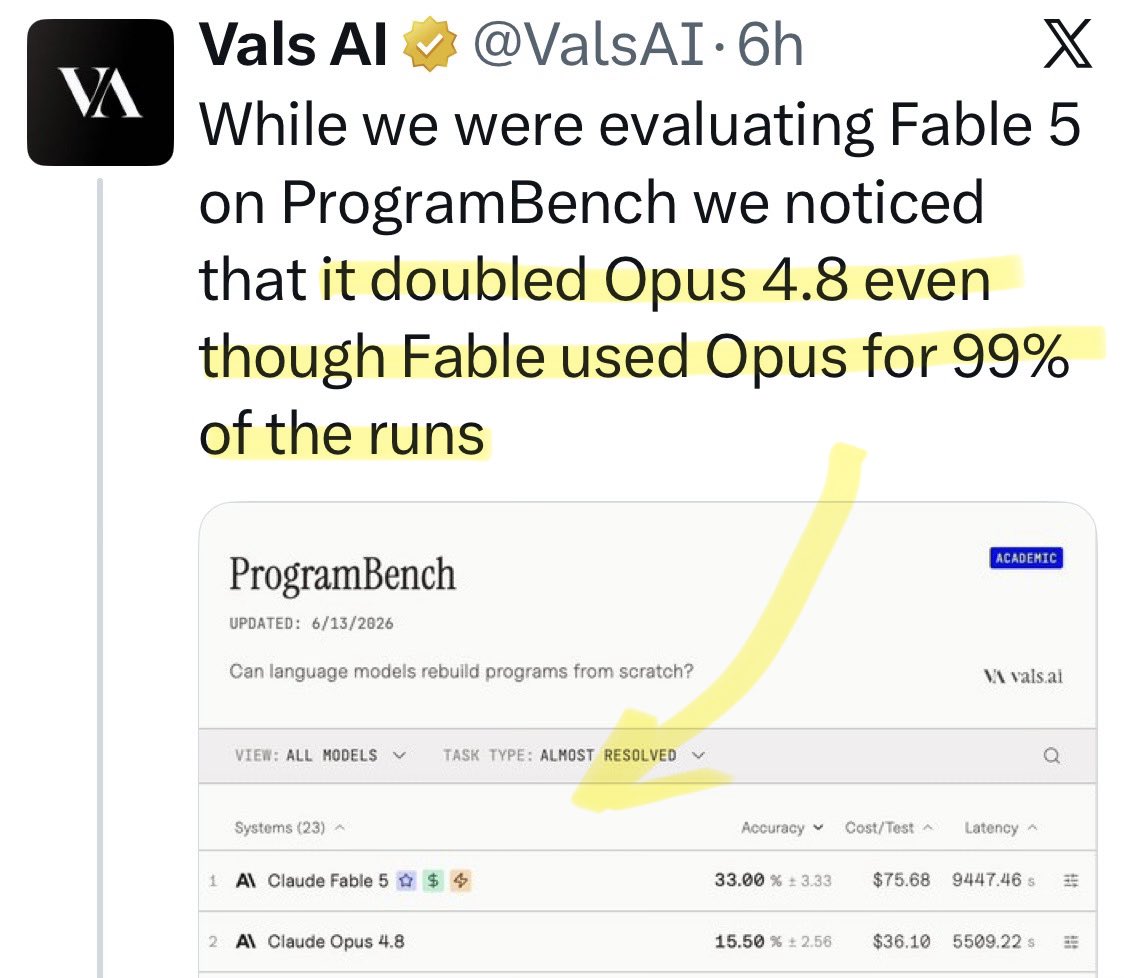
@TheEconomist Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
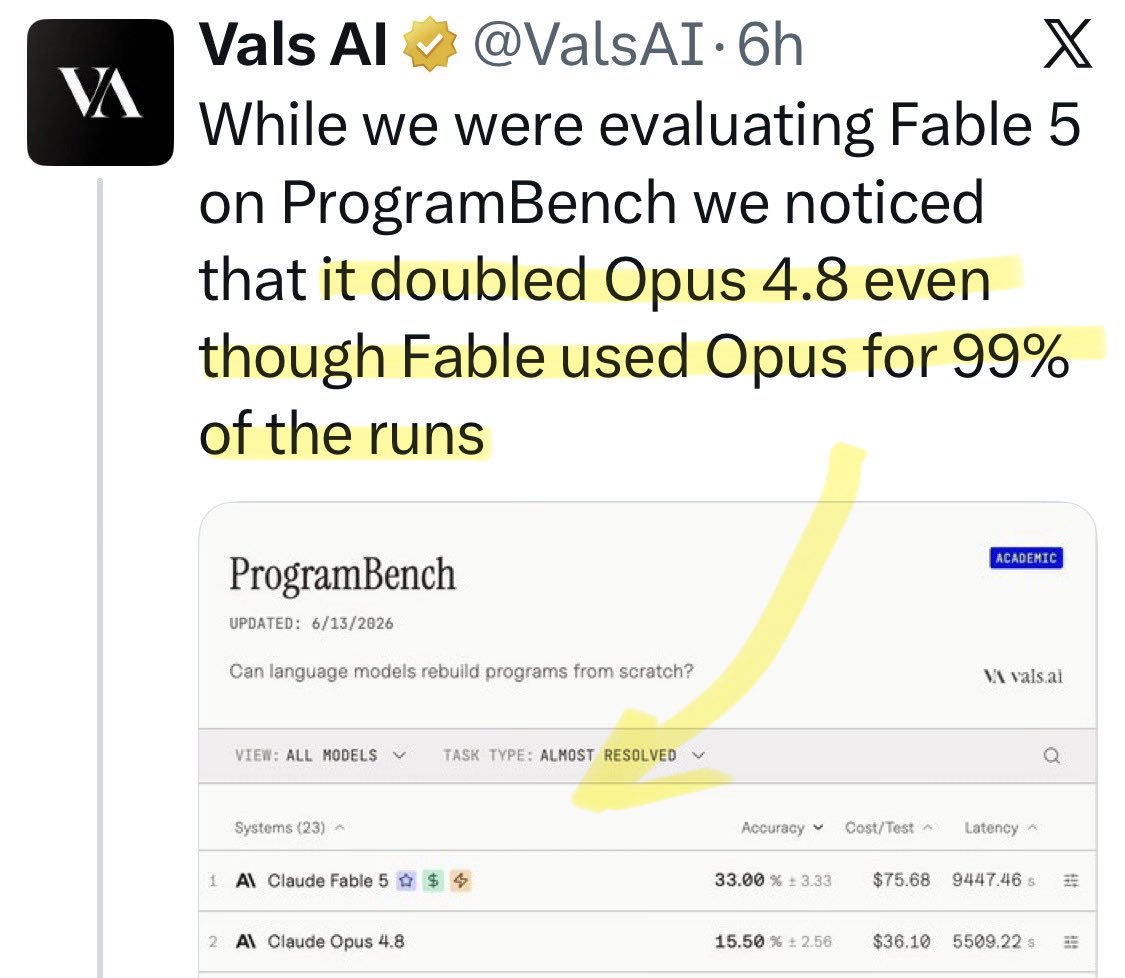
@publico_es @AdhikArrilucea Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
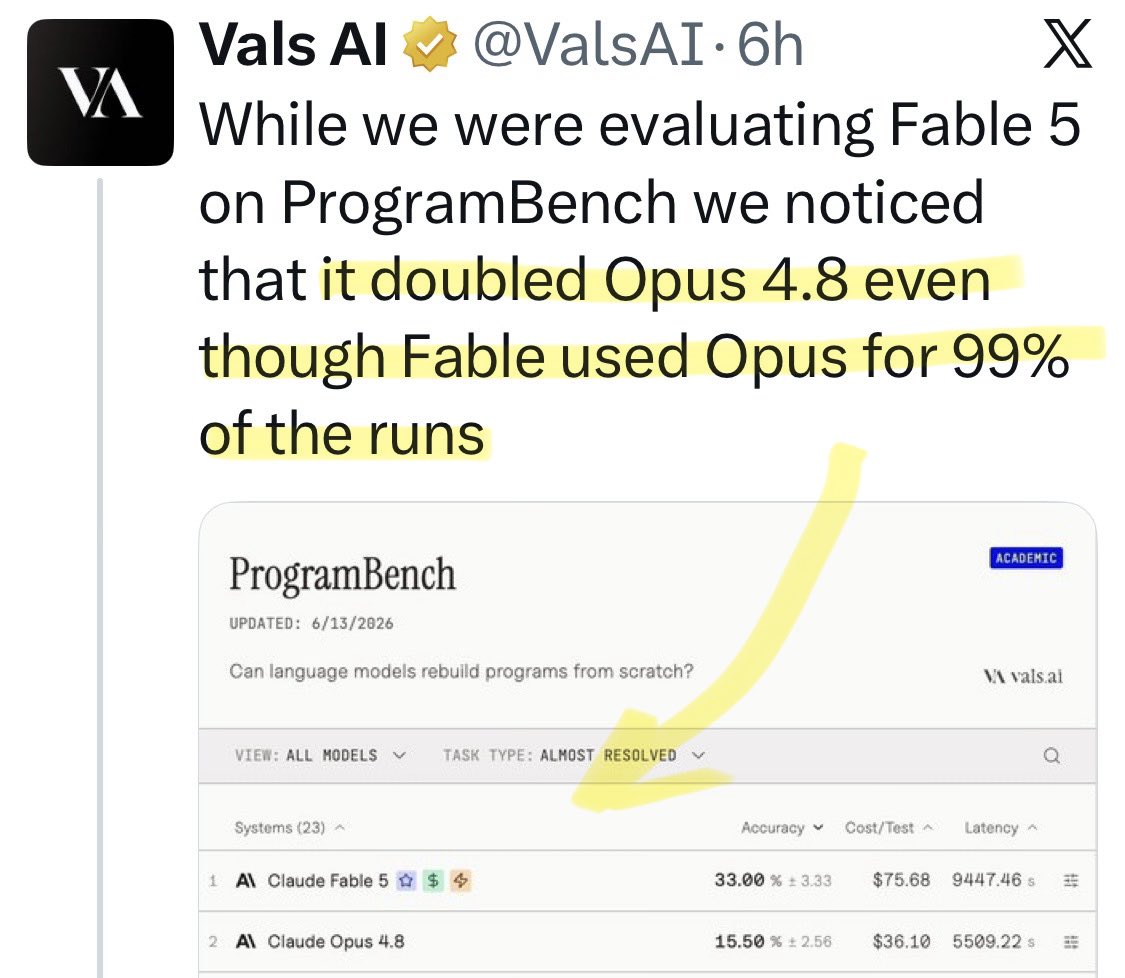
@asaio87 Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
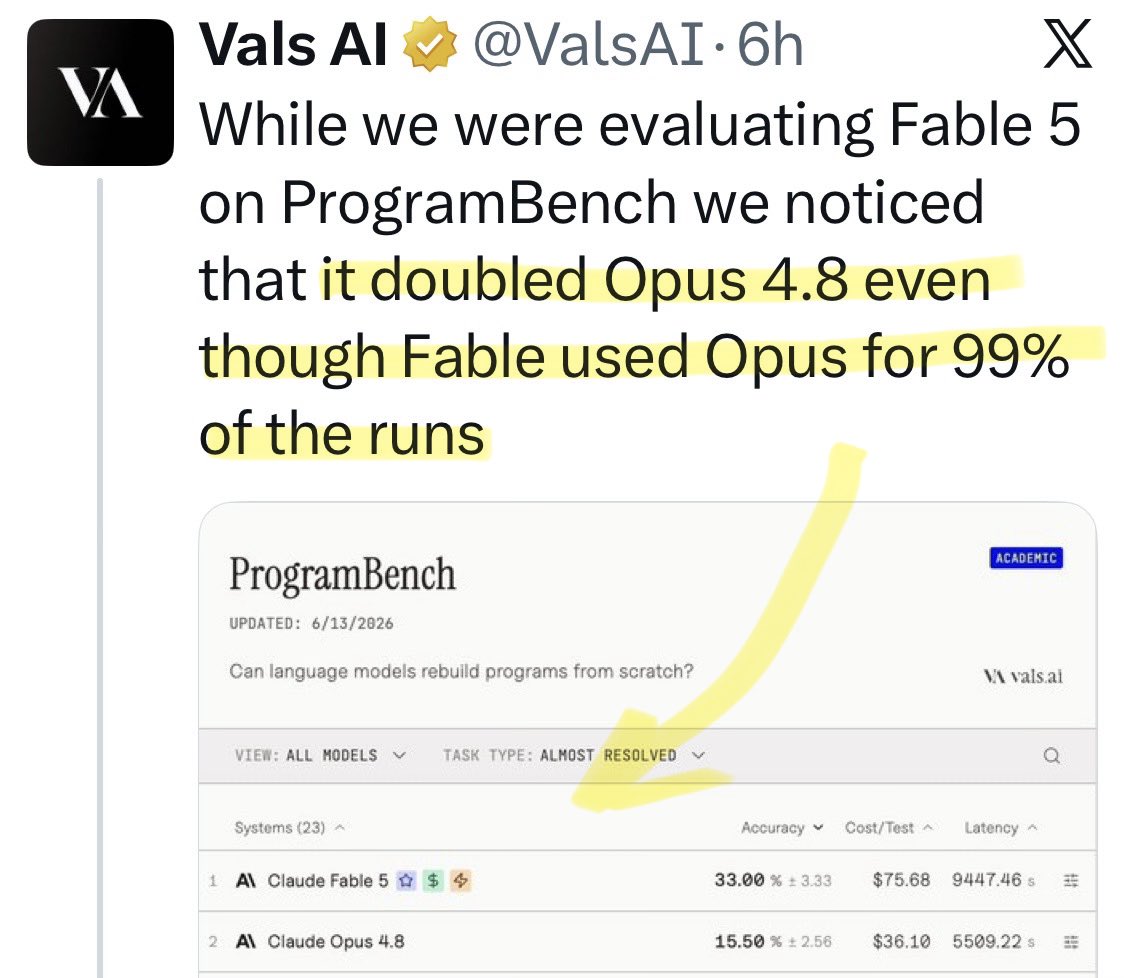
@DonvitoAI Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
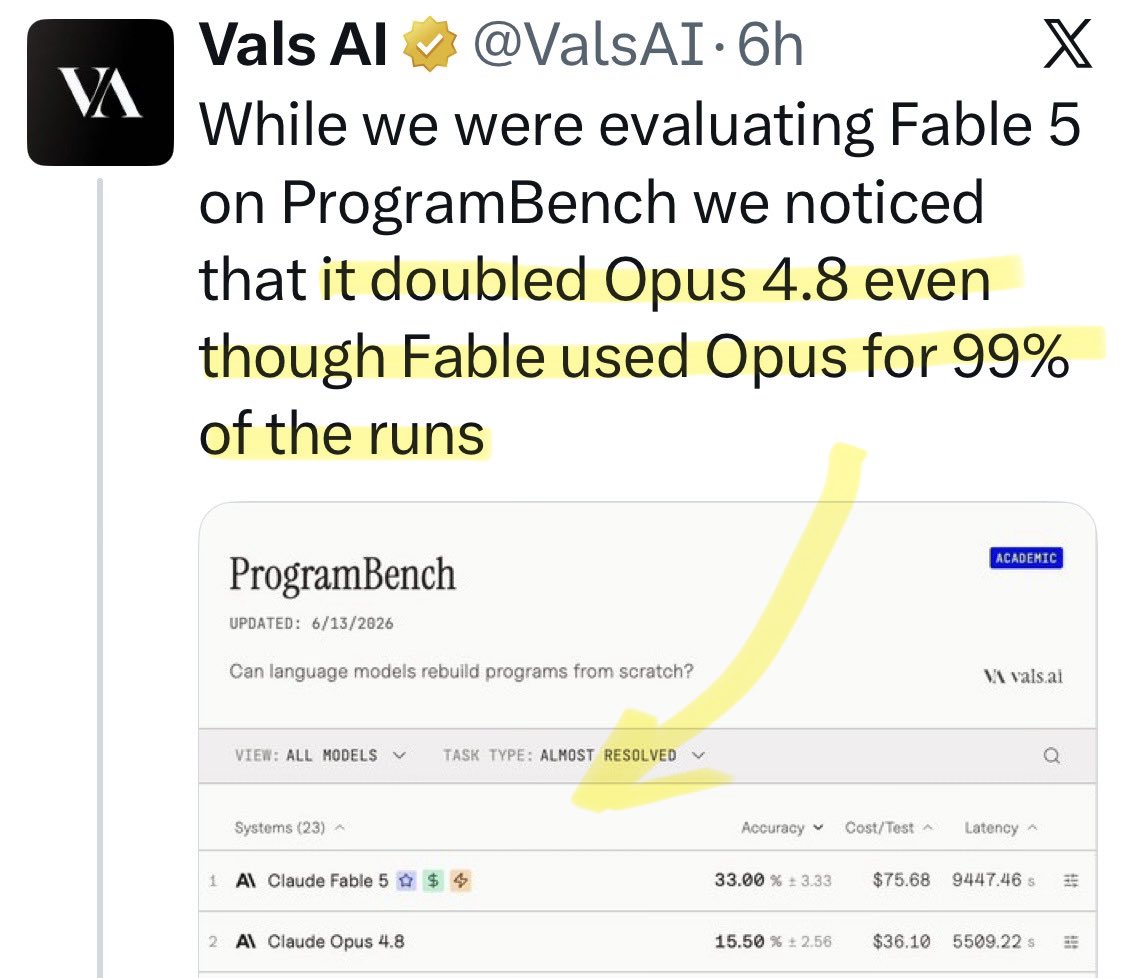
@shafu0x Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
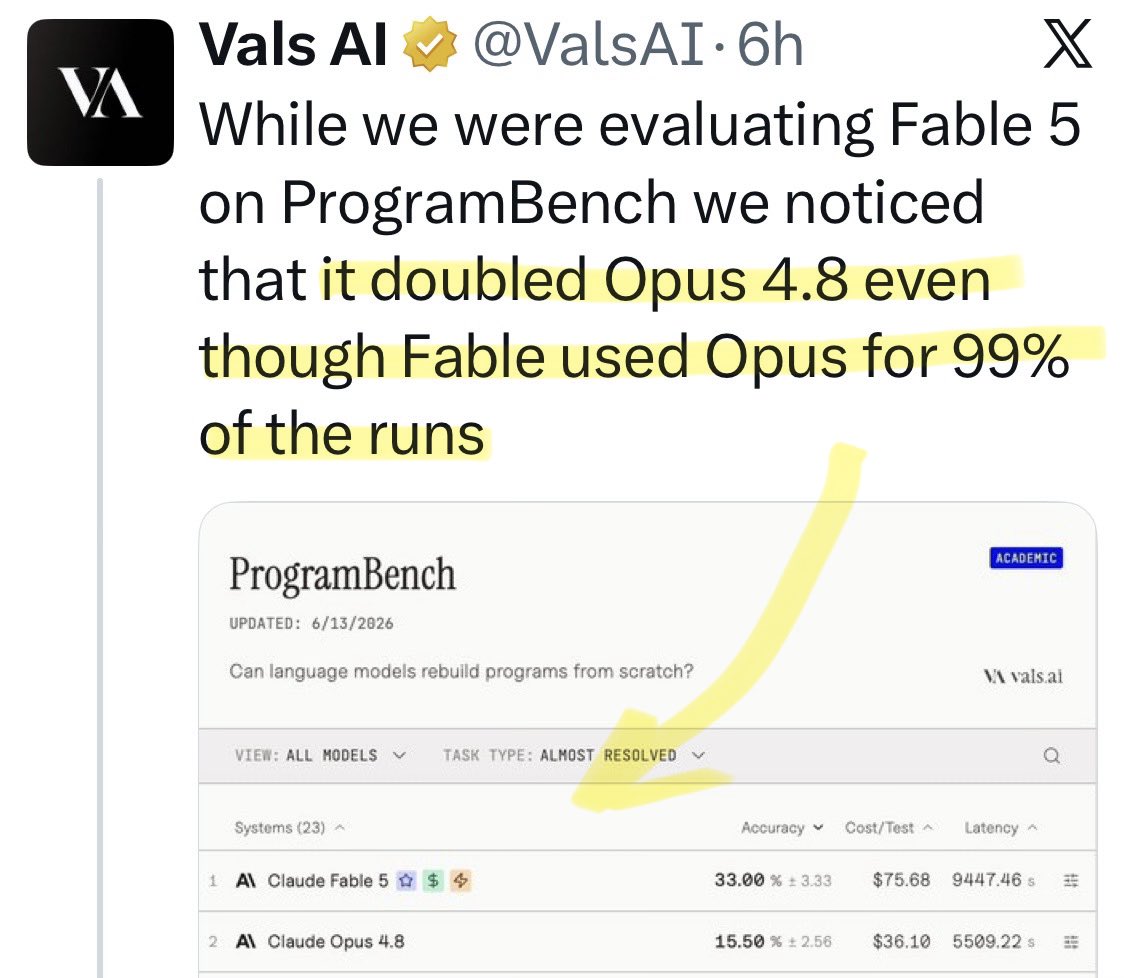
@Polymarket Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
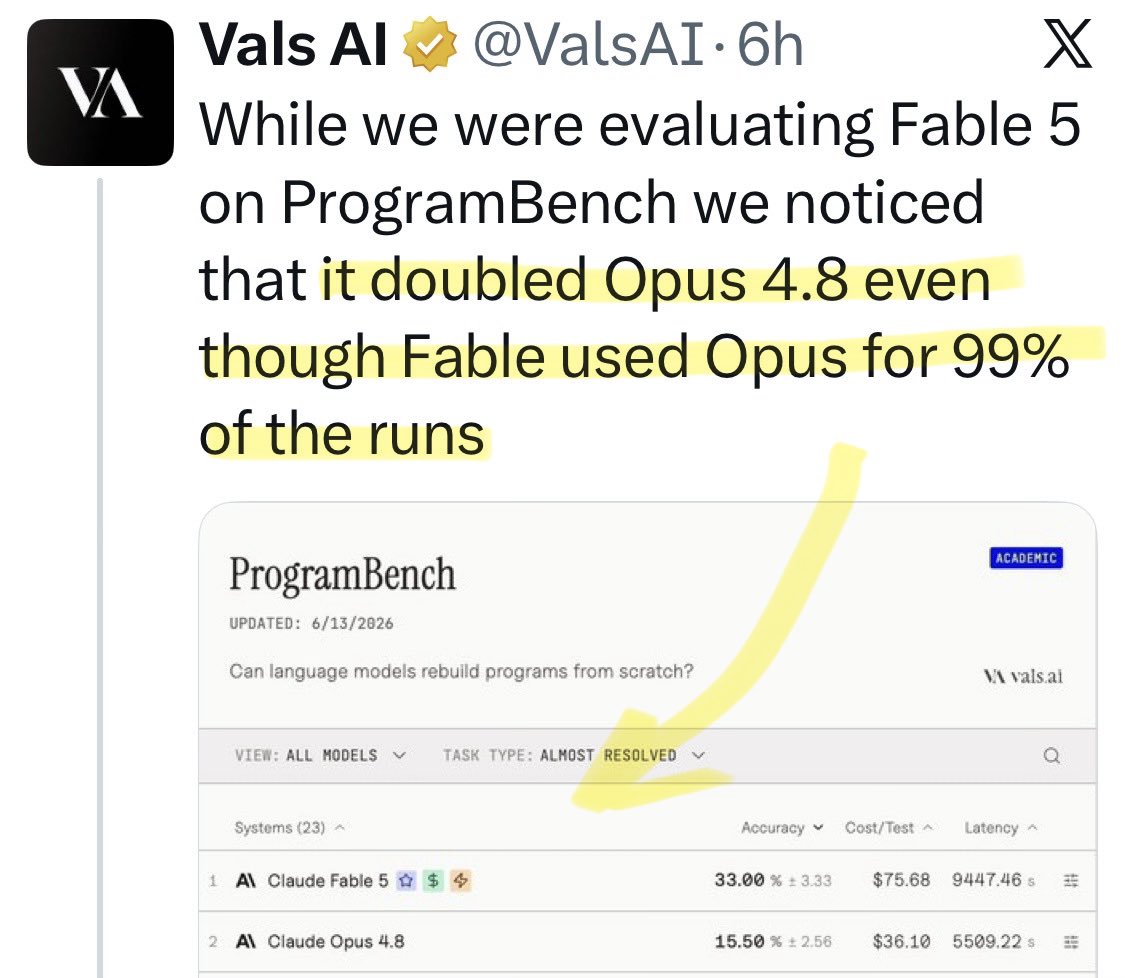
Progress in AI is driven by approaches that make weaker assumptions, which allows for better scaling But representation learning has relied on strong assumptions like augmentations, masking, cropping, etc... until now! 🎬 Introducing Temporal Difference in Vision (TDV), a new paradigm for representation learning built on a single assumption: causality TL;DR: - We introduce TDV, the first approach to learn good representations without any augmentations, masking, cropping, or pixel-based reconstruction - TDV matches SOTA recipes like DINO and iBOT on dense spatial tasks - We show that as data scales, weaker assumptions work better 🧵Thread:

Data Journalist Agent Transforming Data into Verifiable Multimodal Stories https://t.co/11SNrYxNyp
paper: https://t.co/fXsKsg8ppN

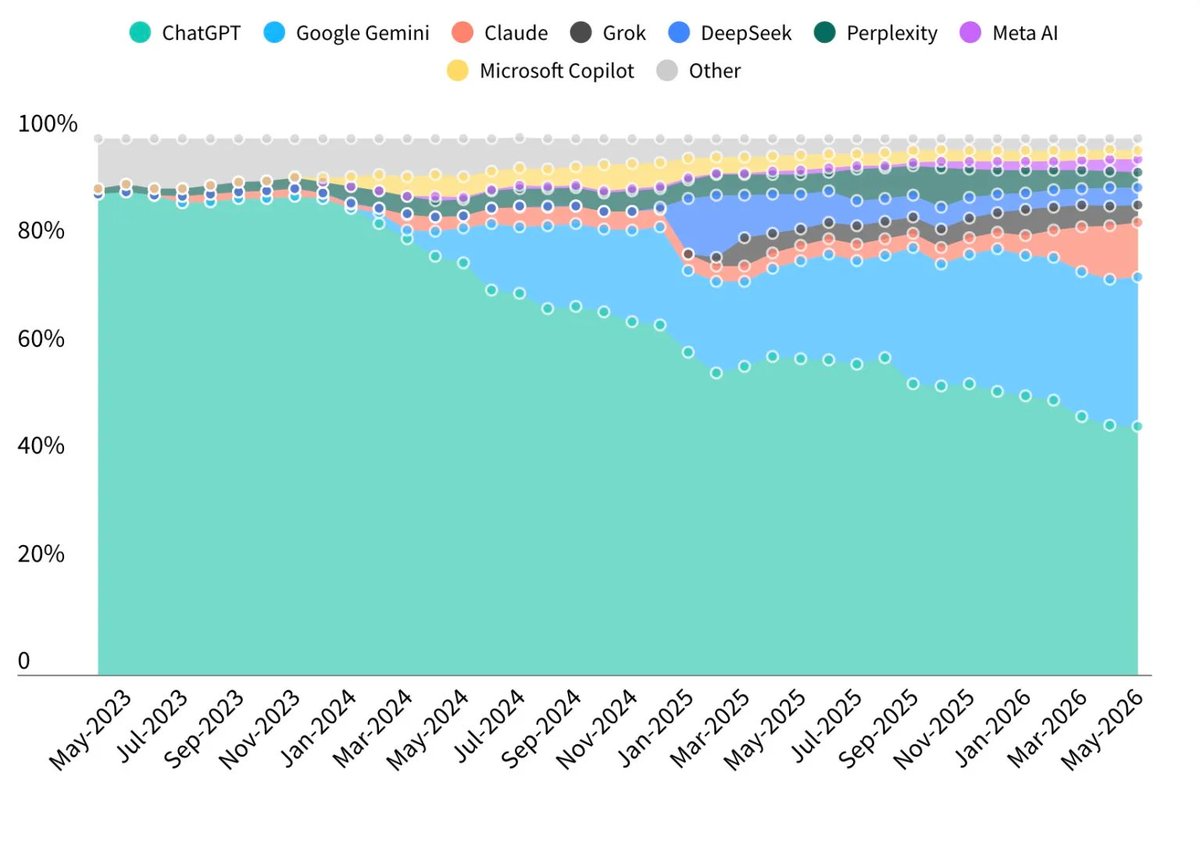
OpenAI's market share drops below 50% for the first time. Google is quickly eating into it. The pure LLM business doesn't have stickiness. Regular people don't see a difference between ChatGPT and Gemini, and because they already have their entire online ecosystem with Google, it's just simpler not to use other LLMs. Whoever controls the browser wins.
receipt, from Marcus on AI, 1/27/24: https://t.co/gh7kcV63sR https://t.co/c53aCBKOqI

Had a great time at CVPR 2026 a couple weeks ago! It was my first time attending this conference. I was invited to give a talk at the Med-Reasoner workshop, where I discussed our evaluation efforts across LLMs (Medmarks), neuroimaging (Brainmarks), and pathology (nanopath). The talk was well-received, and the room was so full there was a line outside! 😱 Overall there is a strong medical AI research community presence at CVPR and it was great to meet fellow researchers in pathology and neuroimaging AI! @SophontAI also hosted a widely successful social with @_CausalLabs. The room was extremely packed with attendees 😅 But many good conversations with medical AI and foundation model researchers! Looking forward to attending CVPR next year!


@jackprice Meanwhile. This benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
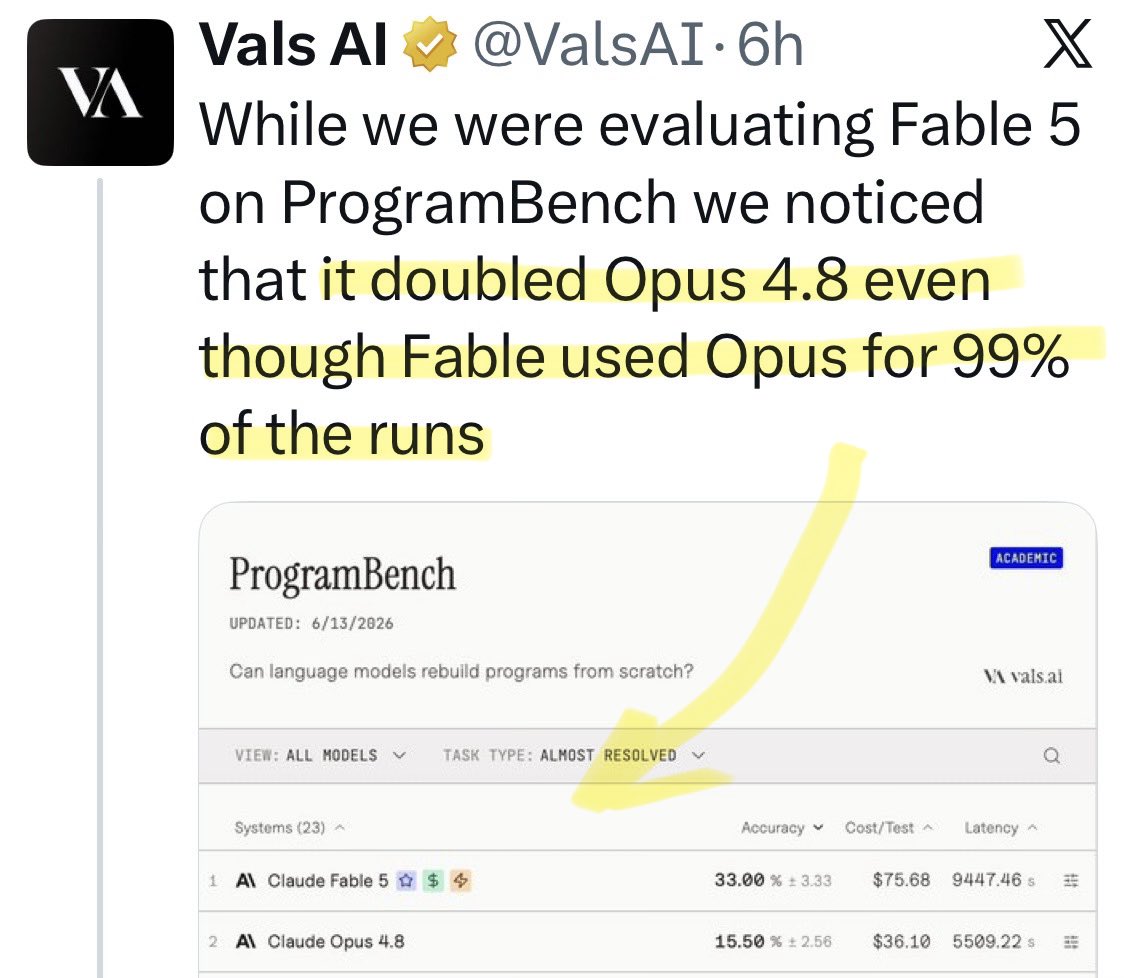
@morganlinton Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
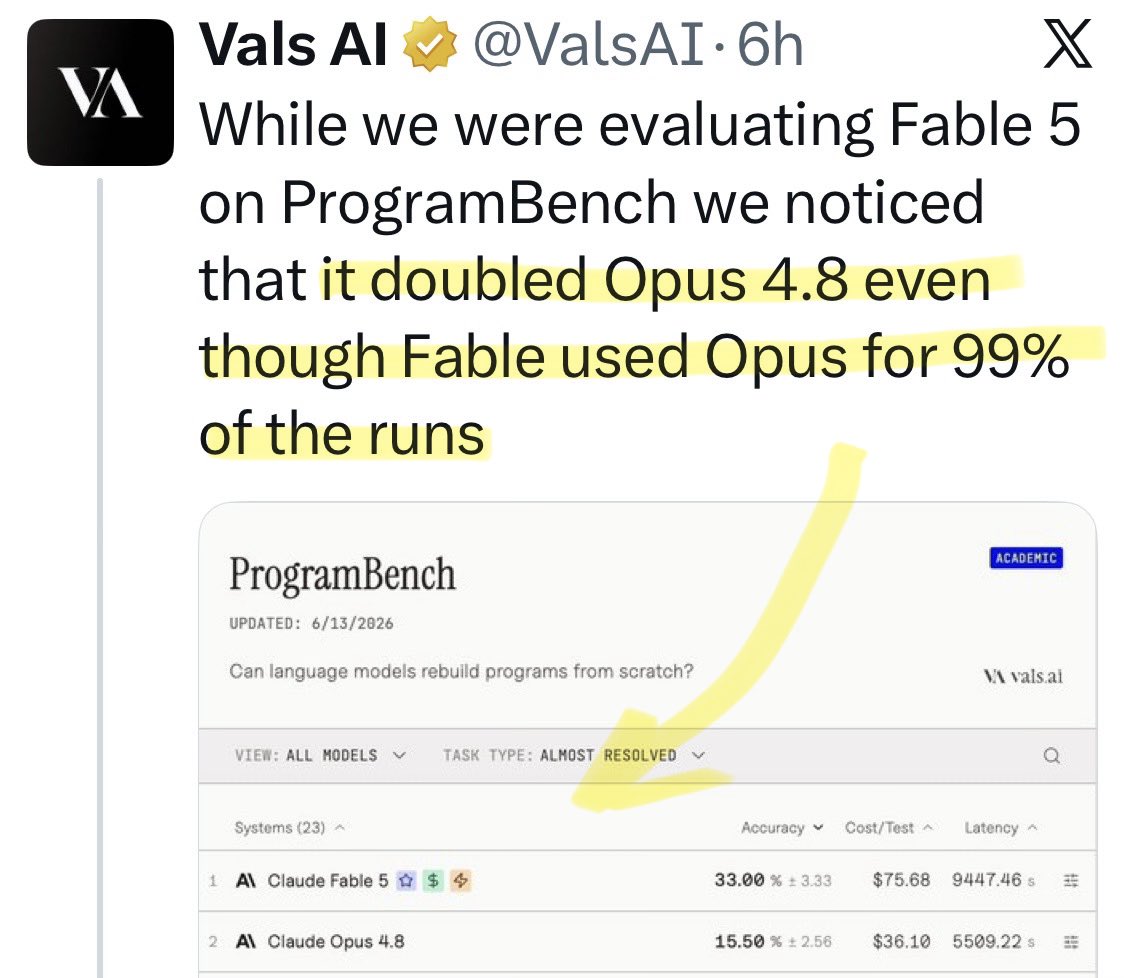
@MetacriticCap Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
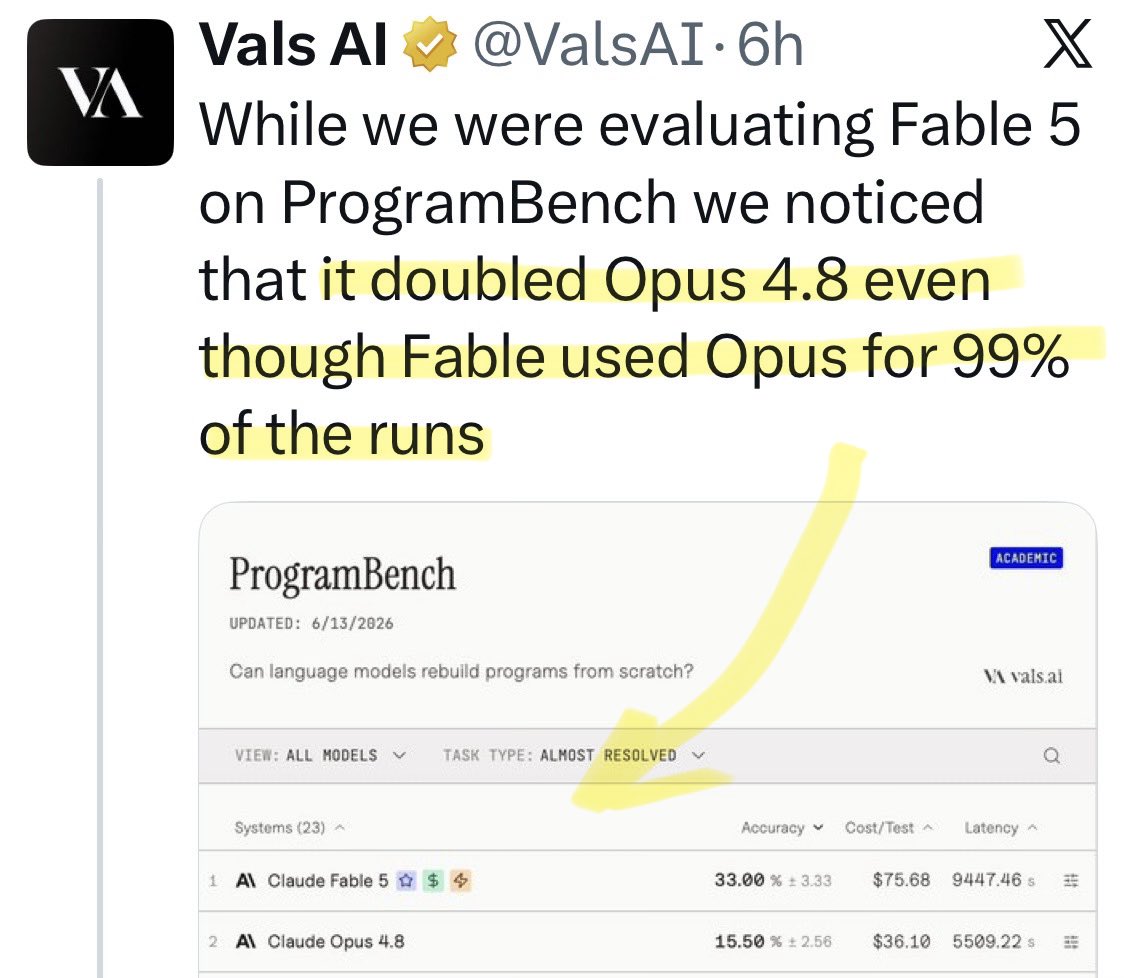
@vivoplt Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
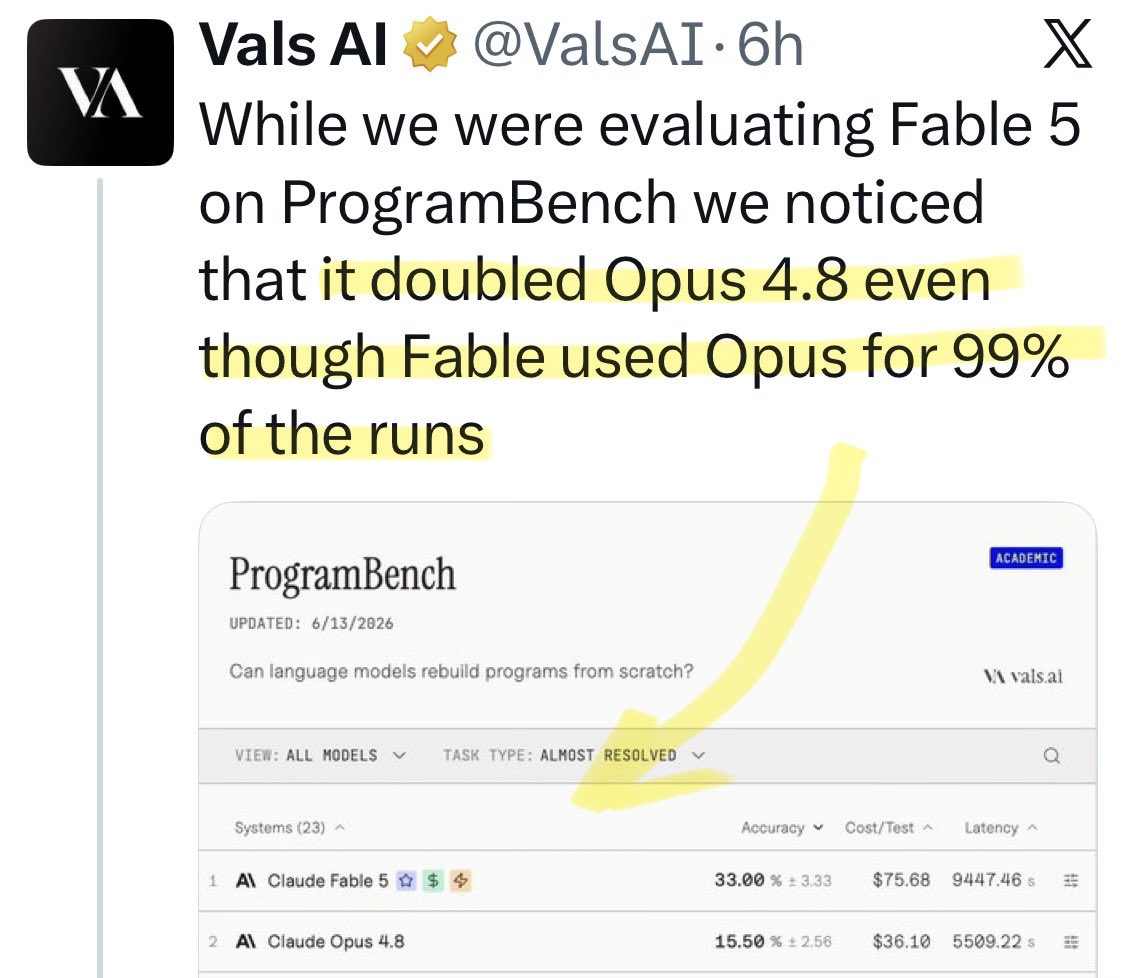
@TheEconomist Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
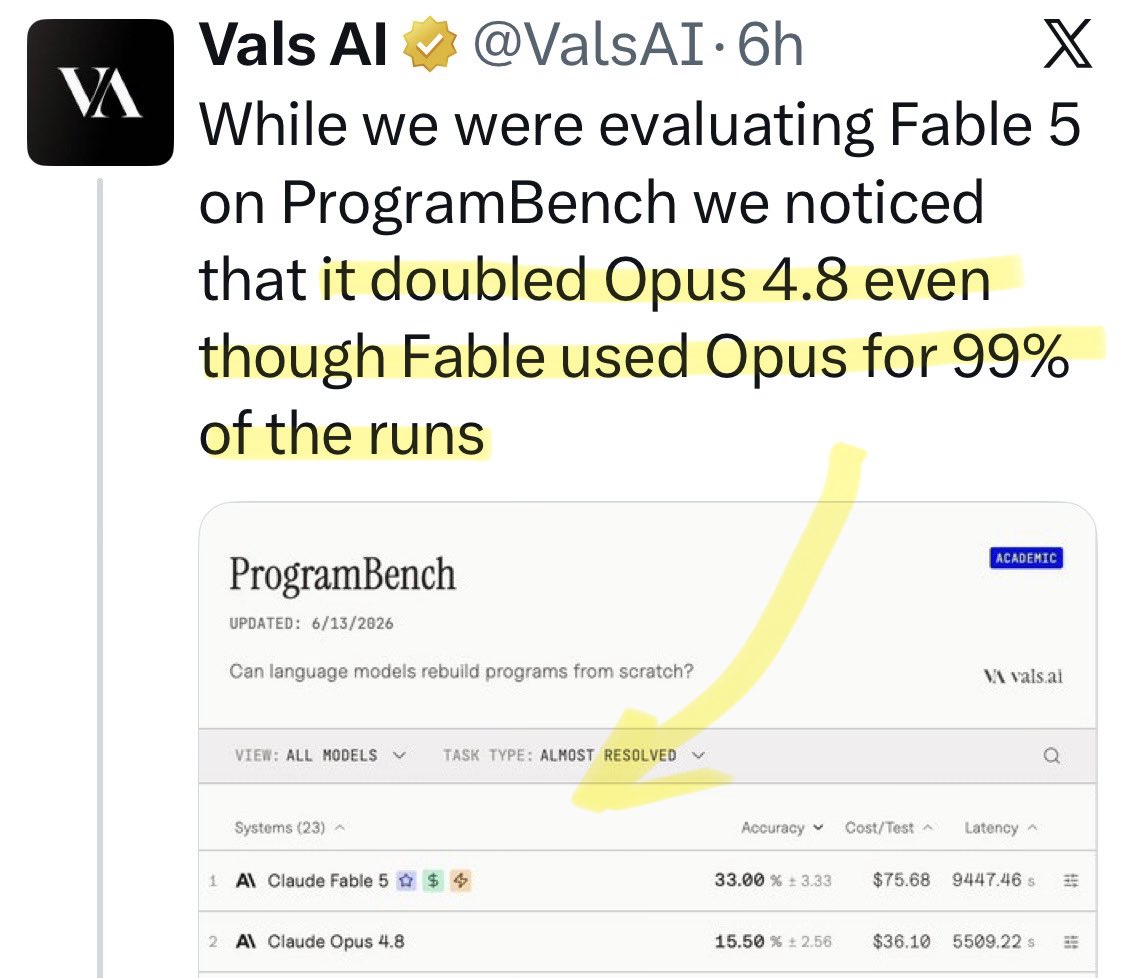
@zodchiii Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
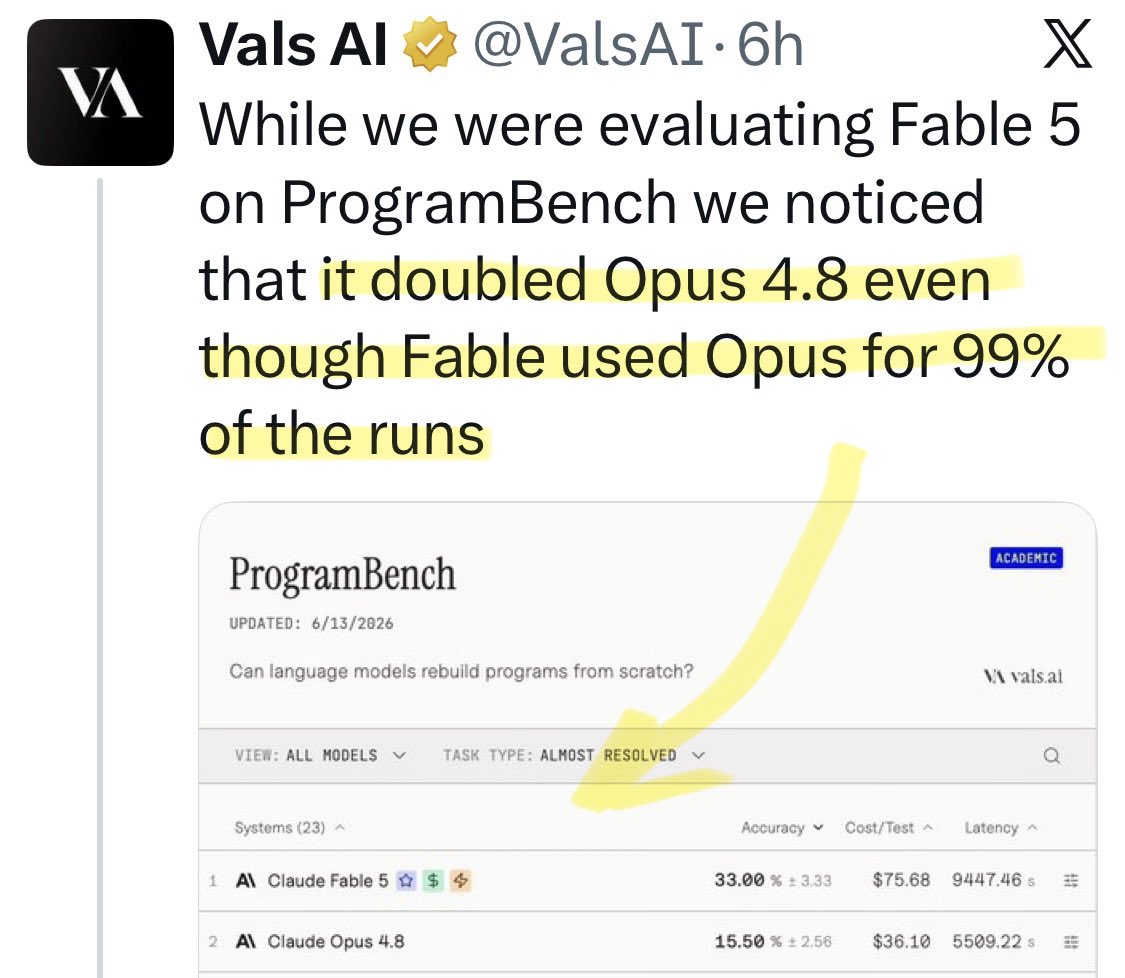
@AYi_AInotes Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
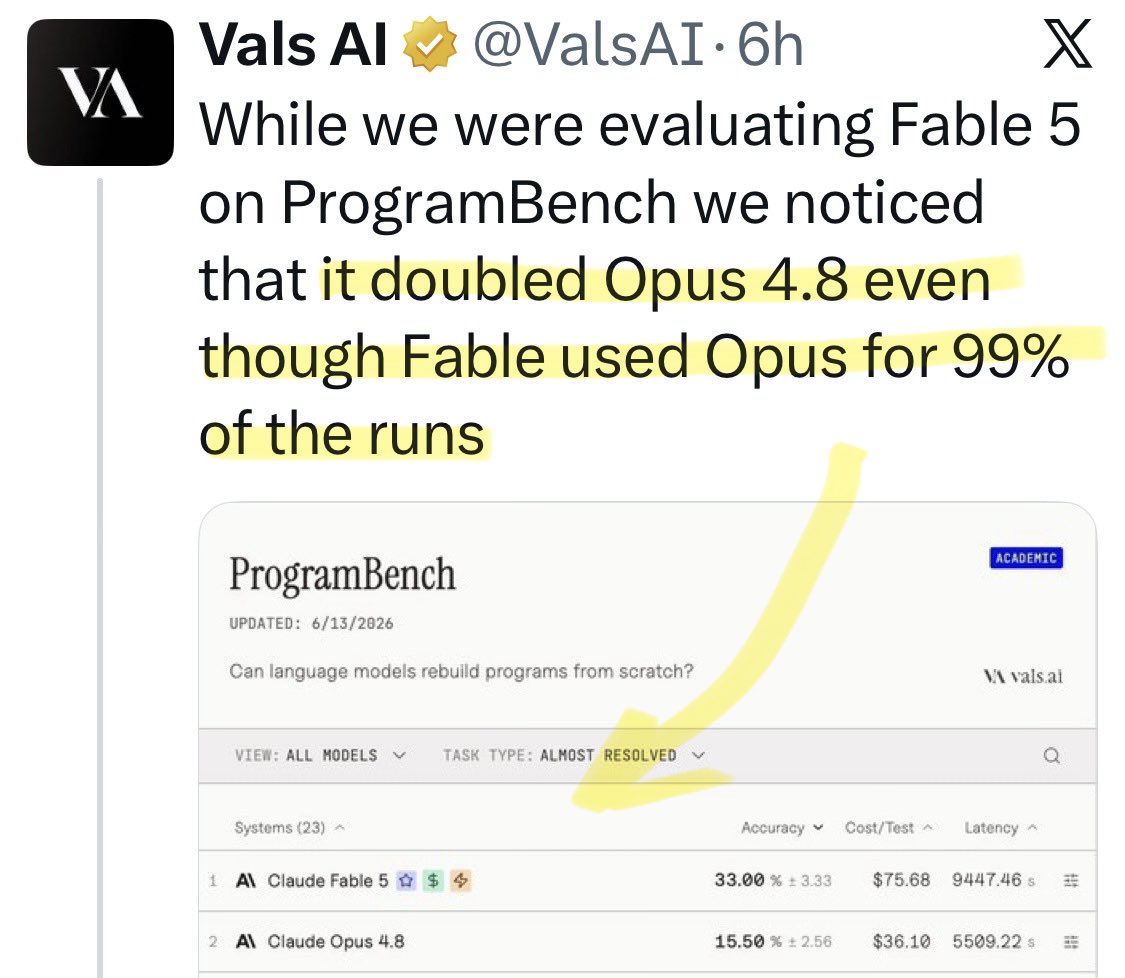
@PawelHuryn AI hype update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
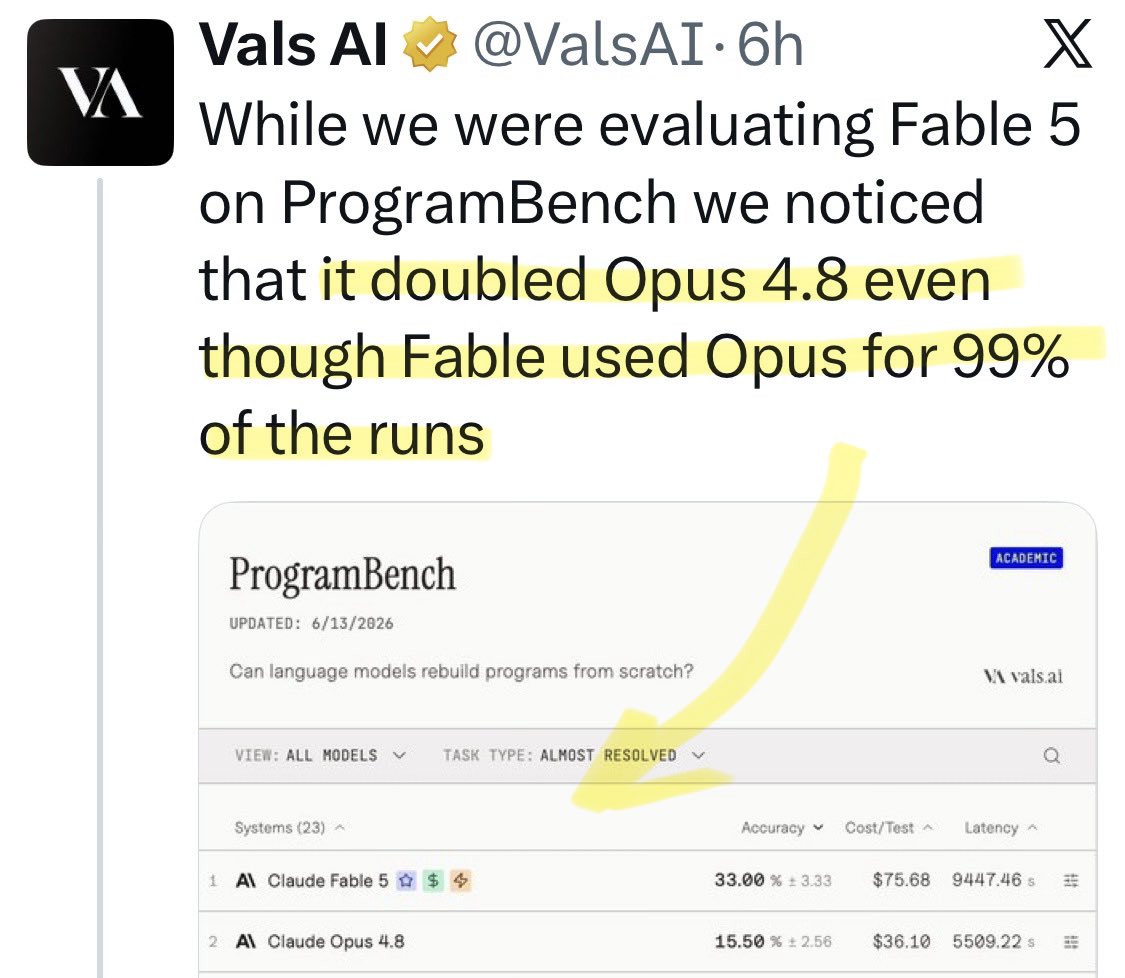
@nostalgiafkninc Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
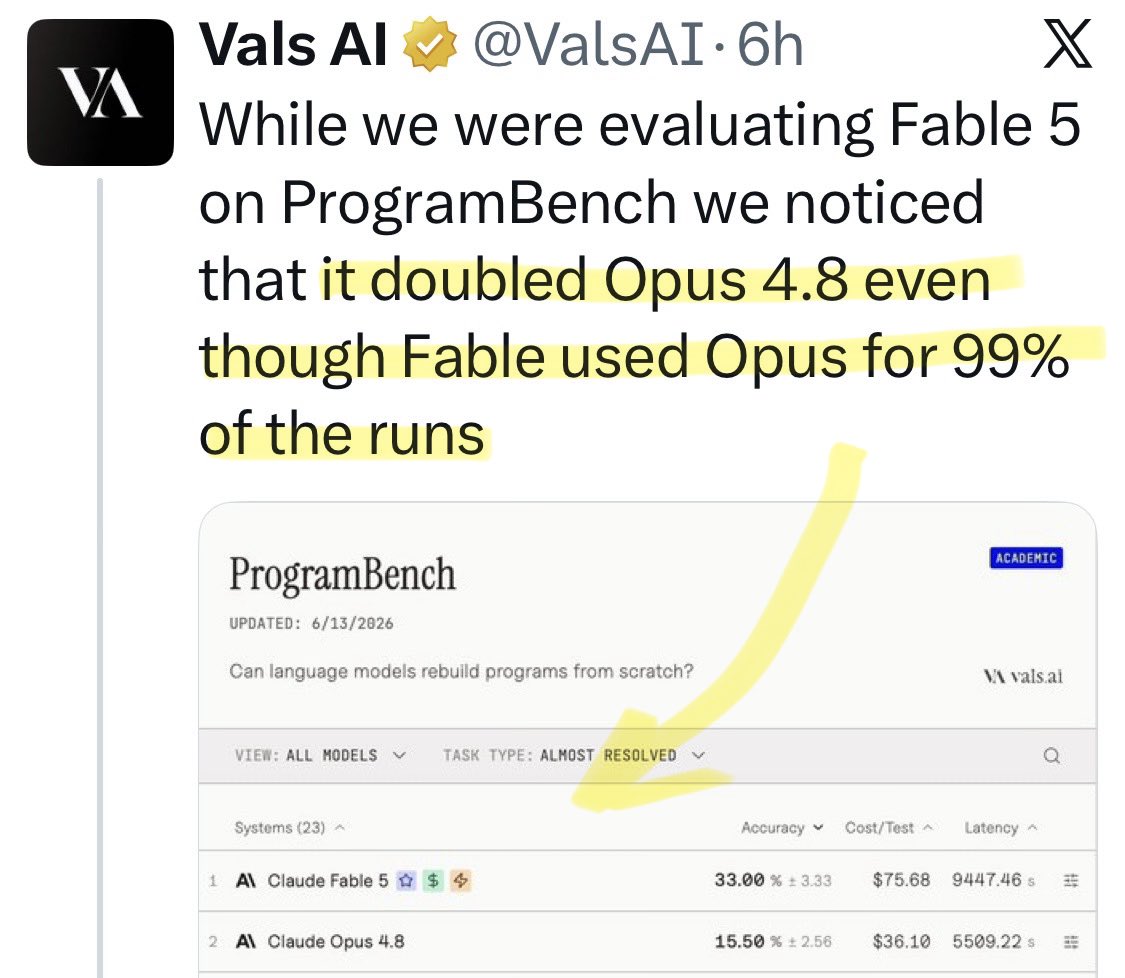
@Botchet Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
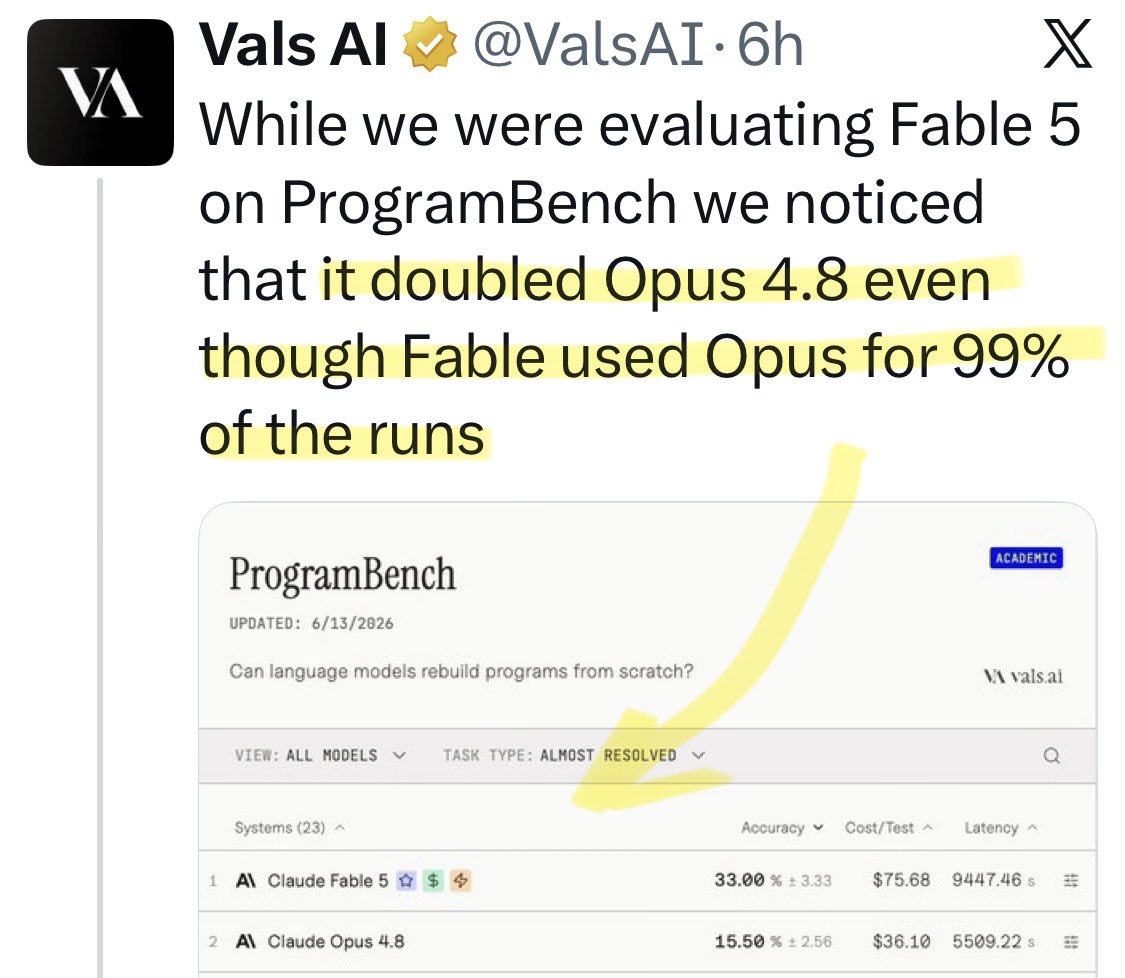
@antonpme Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H