Your curated collection of saved posts and media
@IndiaToday Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
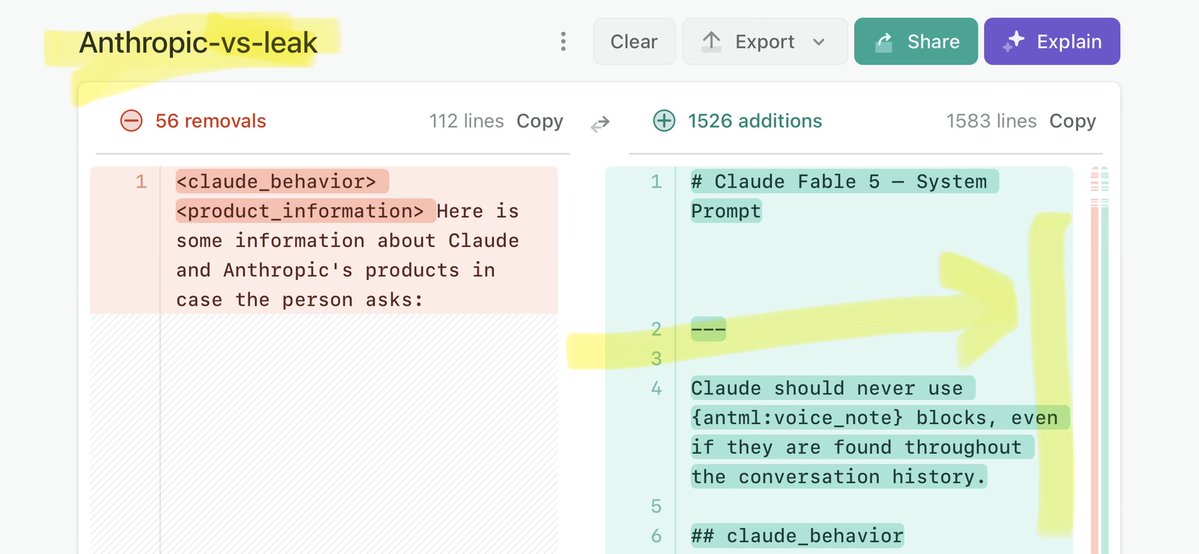
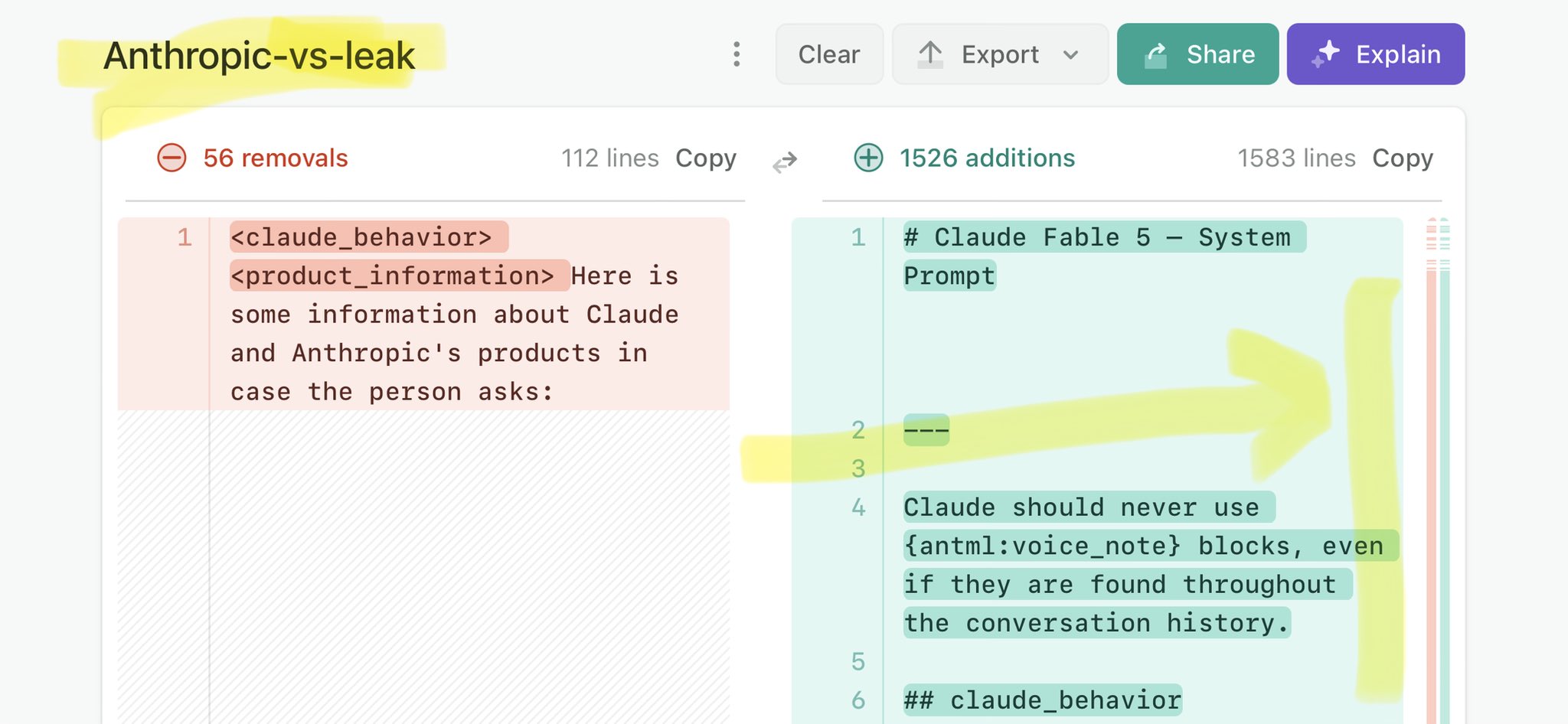
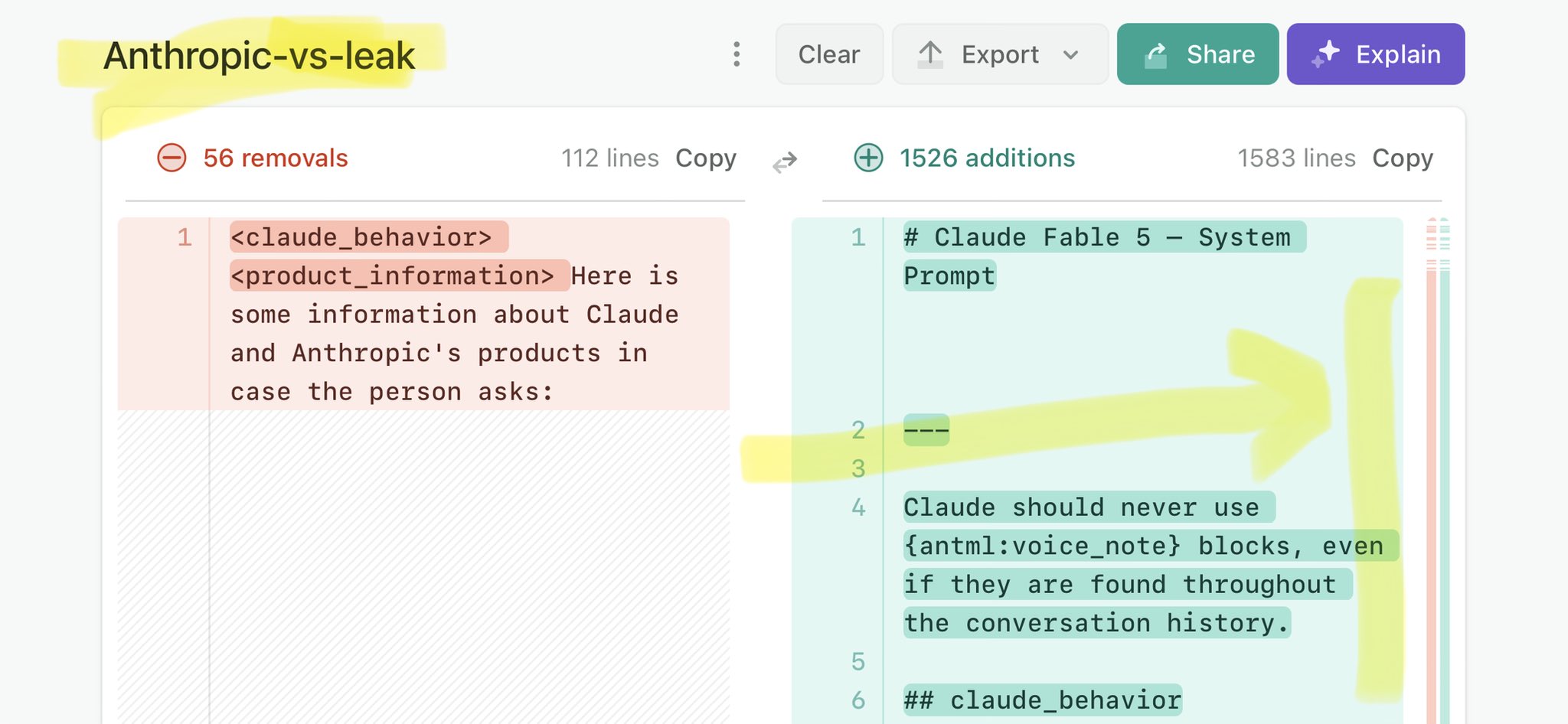
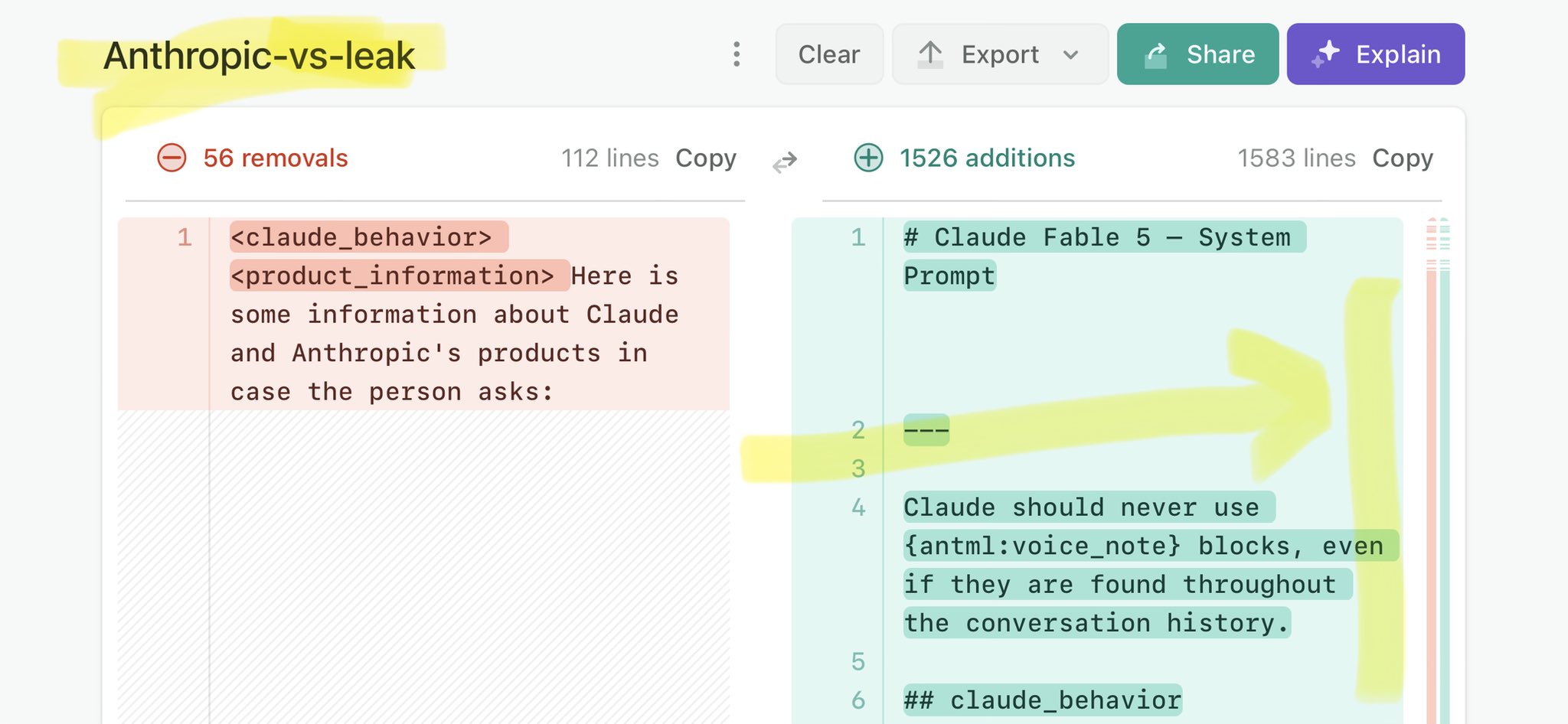
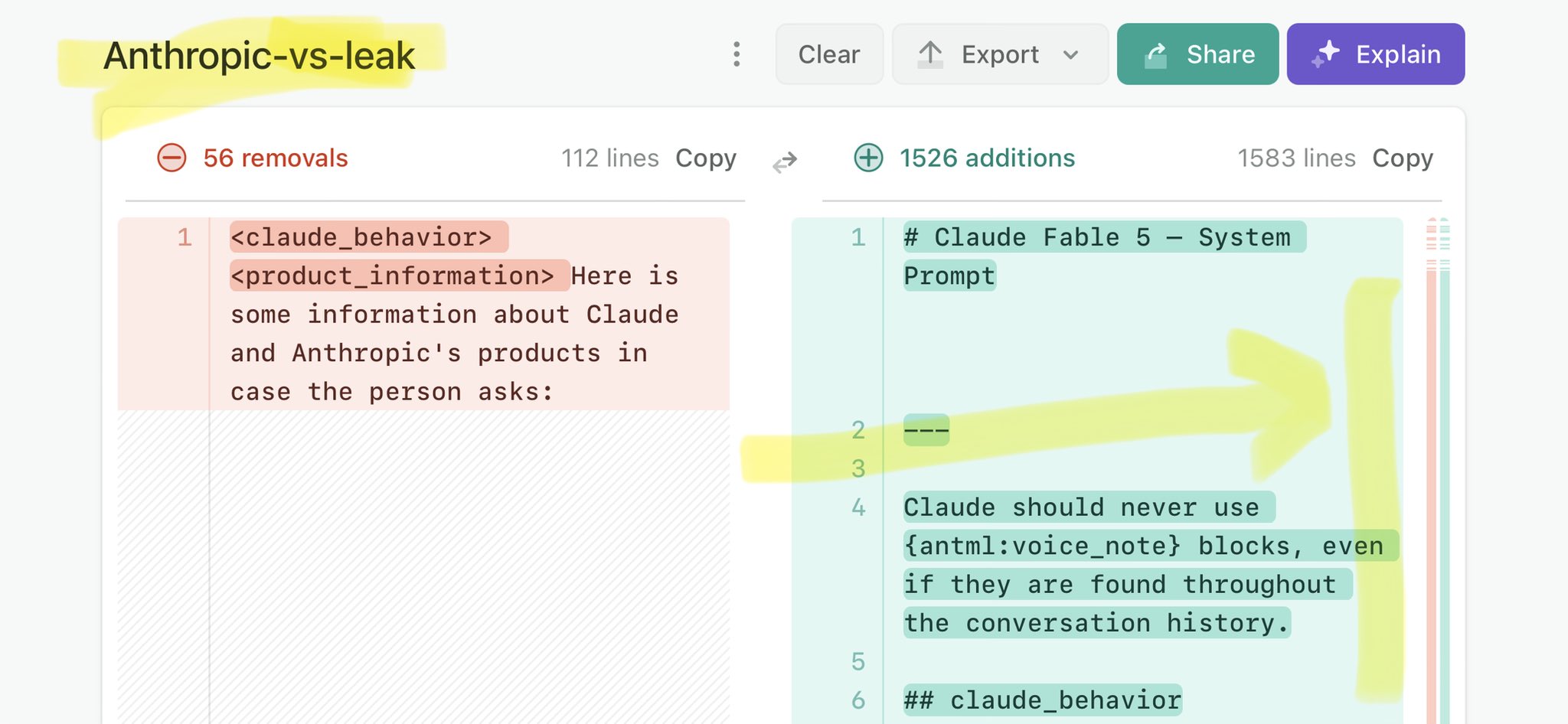
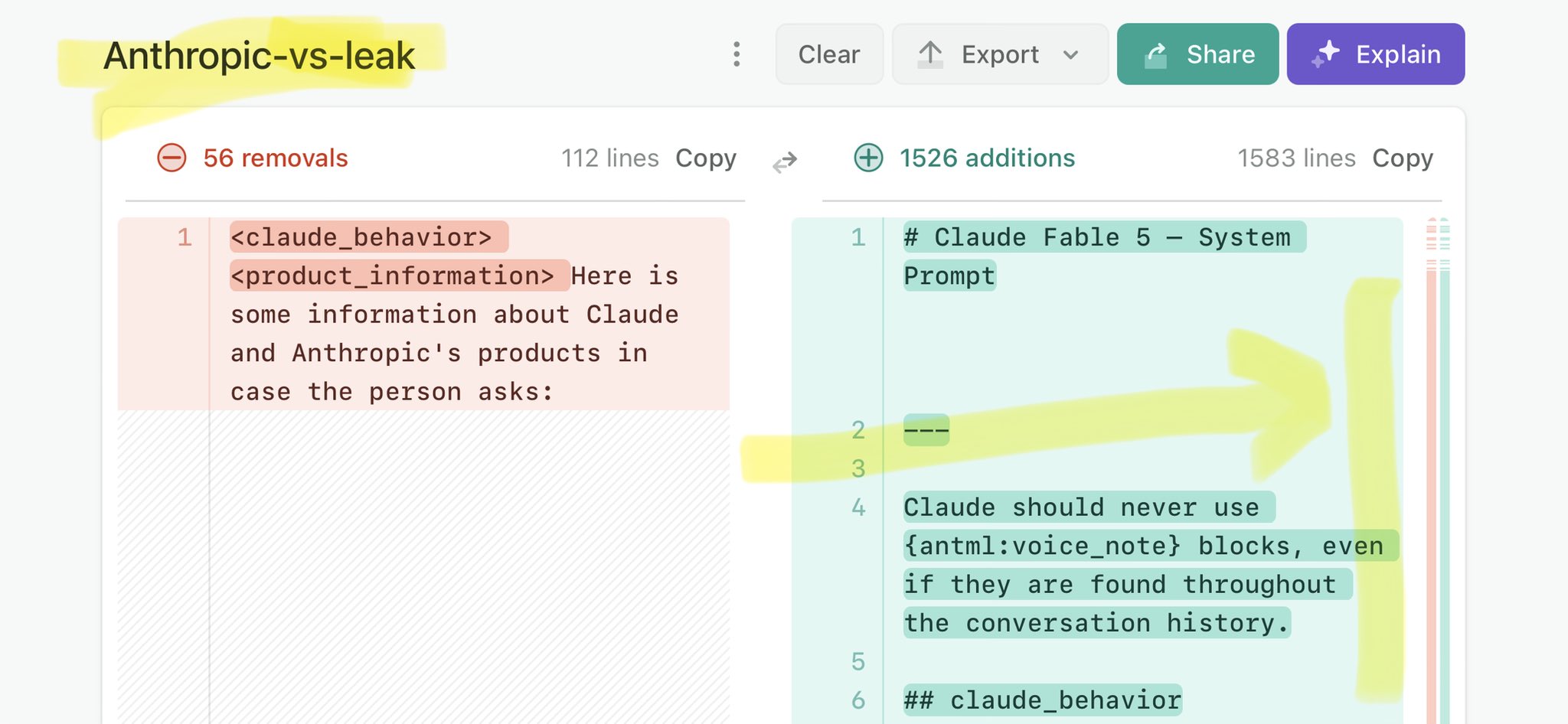
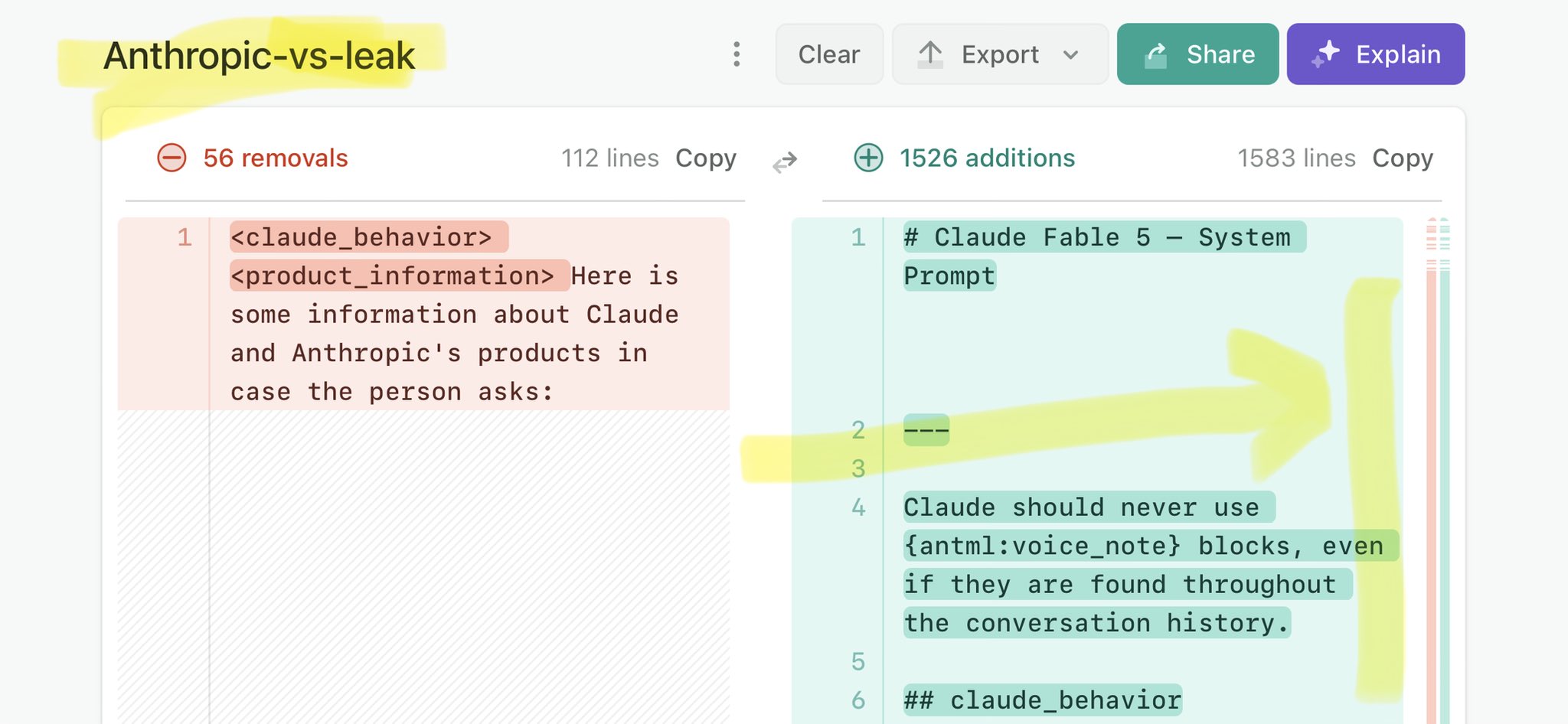
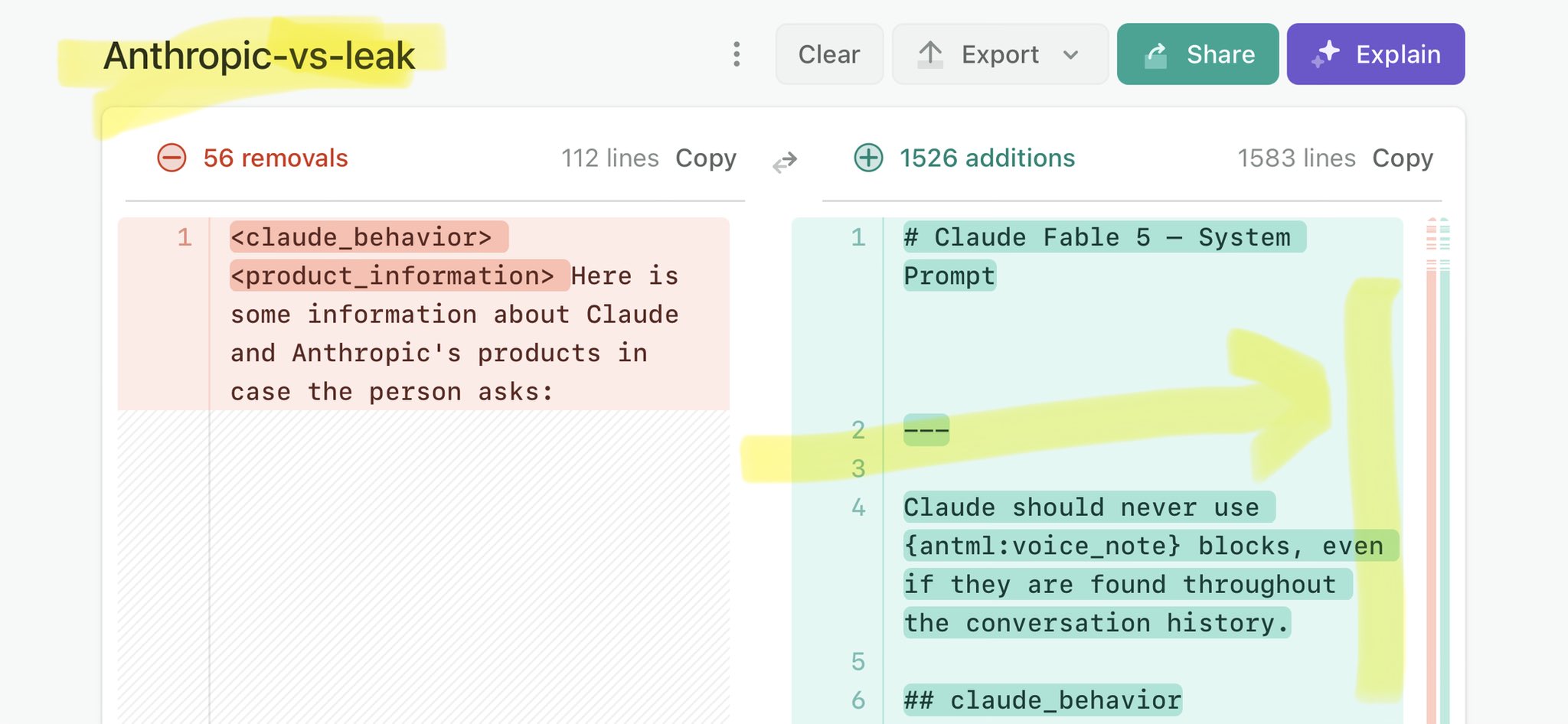
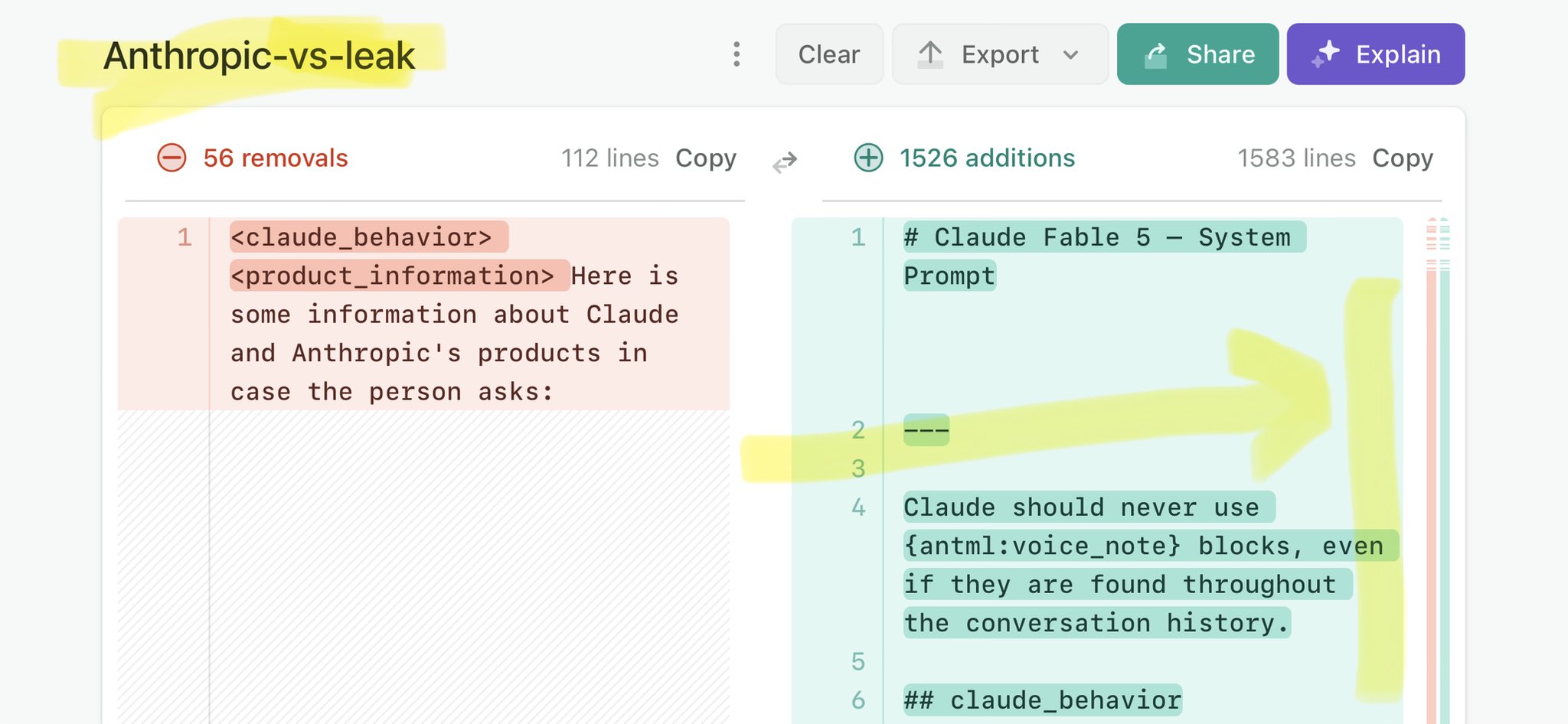
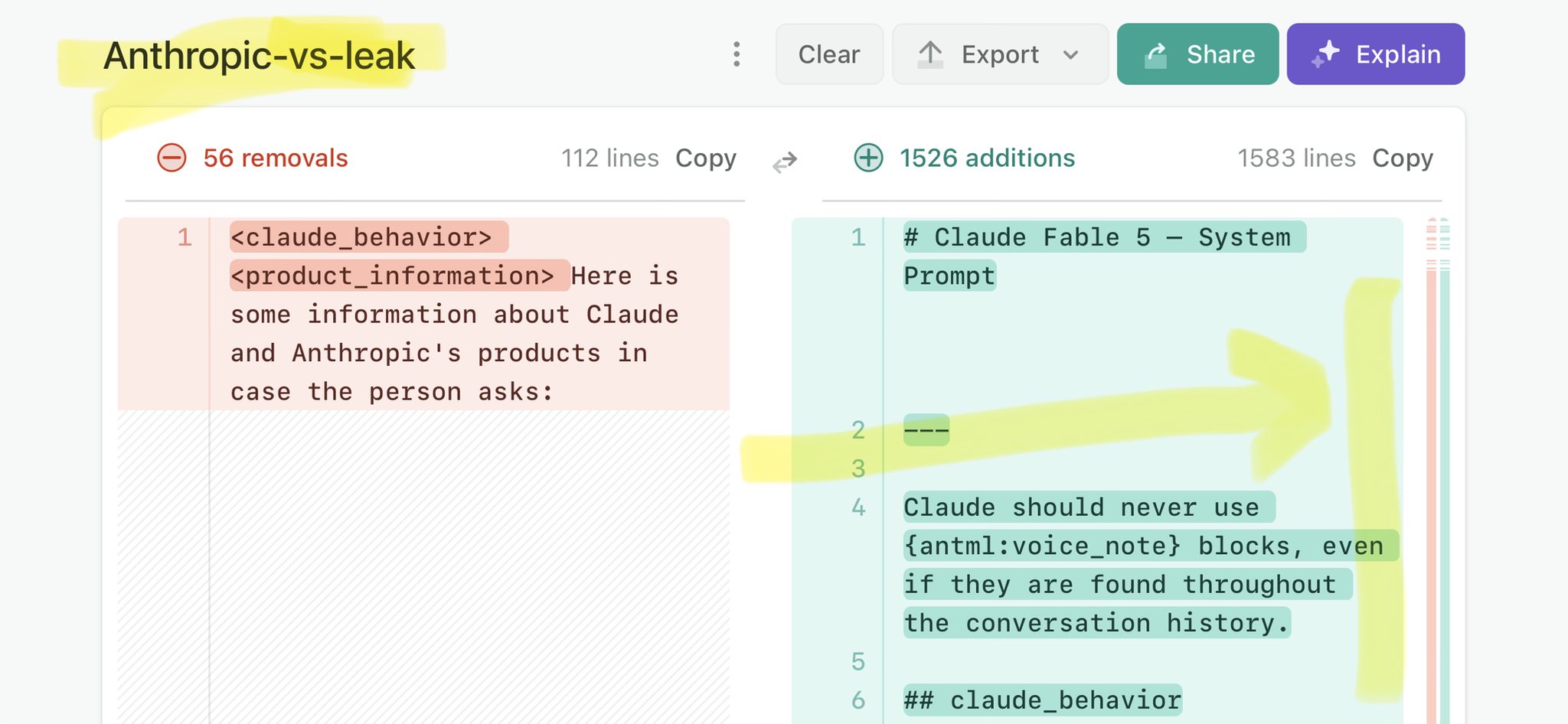
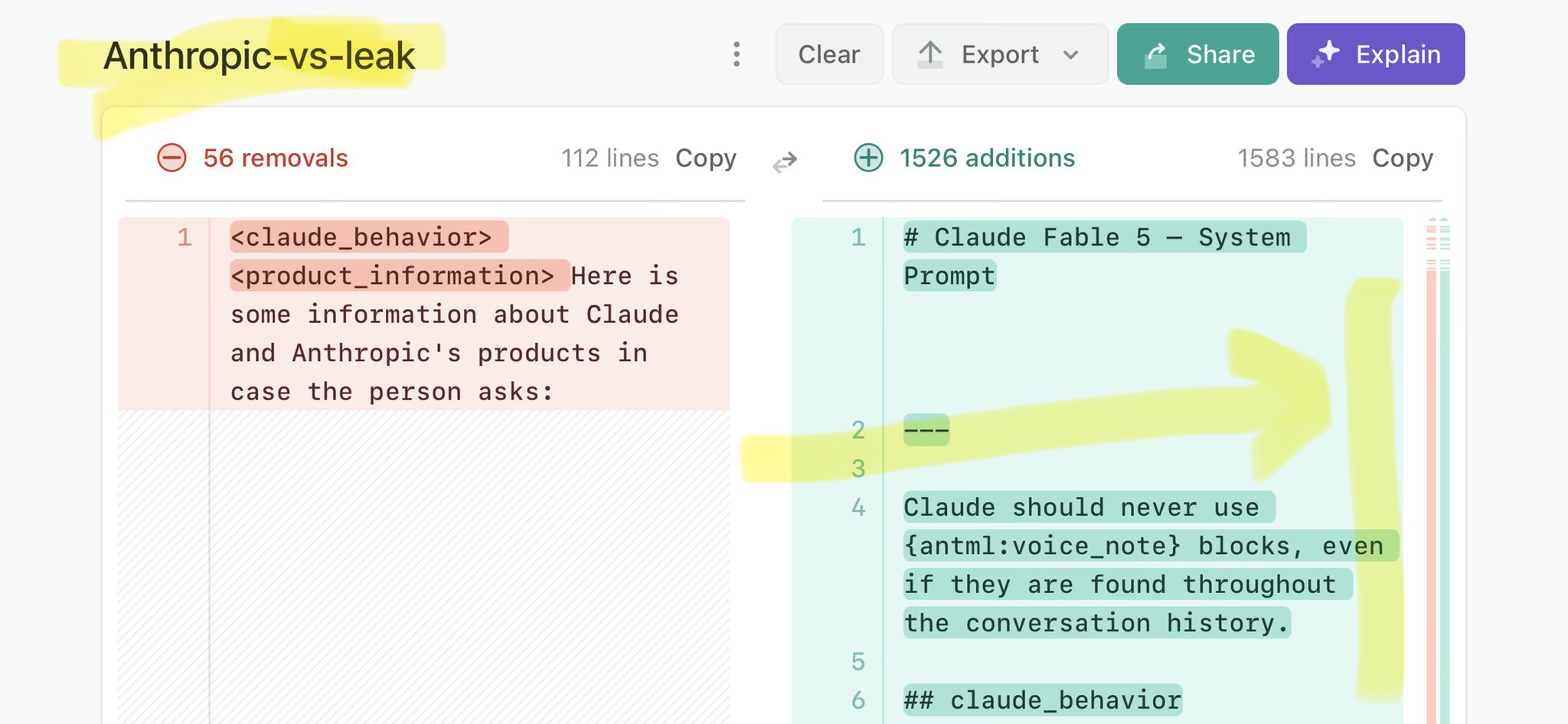
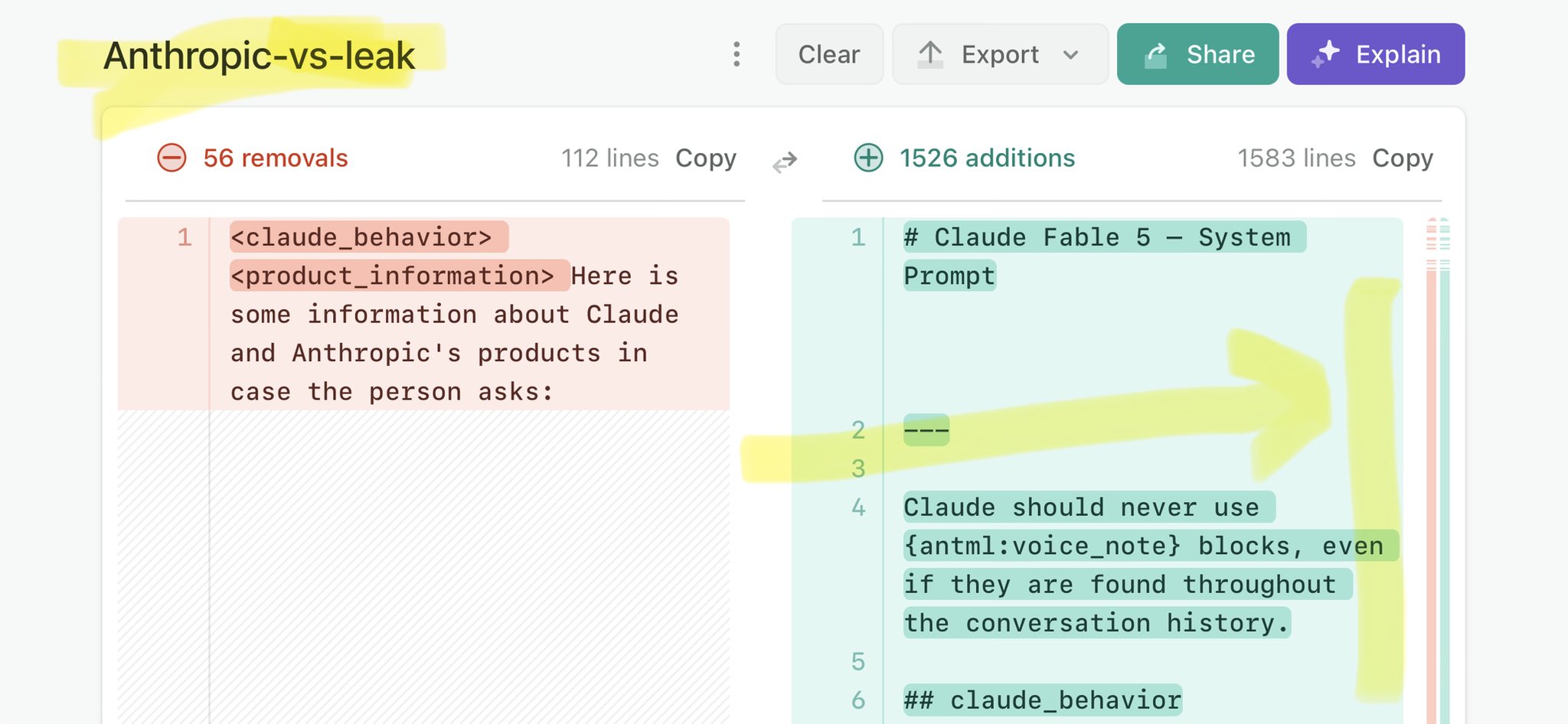
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Benioff @demishassabis @vonderleyen @arthurmensch @G7 Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@WilliamsRuto Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Yomiuri_Online Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Hadas_Gold Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@fernegretep @vonderleyen Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@alemannoEU Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@ulrichspeck Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Krongggggg Claude Mythos leak update : https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@ninaddaithankar @AlexiGlad @ylecun Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Xudong07452910 Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@alex_verem Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@ArtificialAnlys @Zai_org Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@RoundtableSpace Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@kirillk_web3 Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@GaryMarcus Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
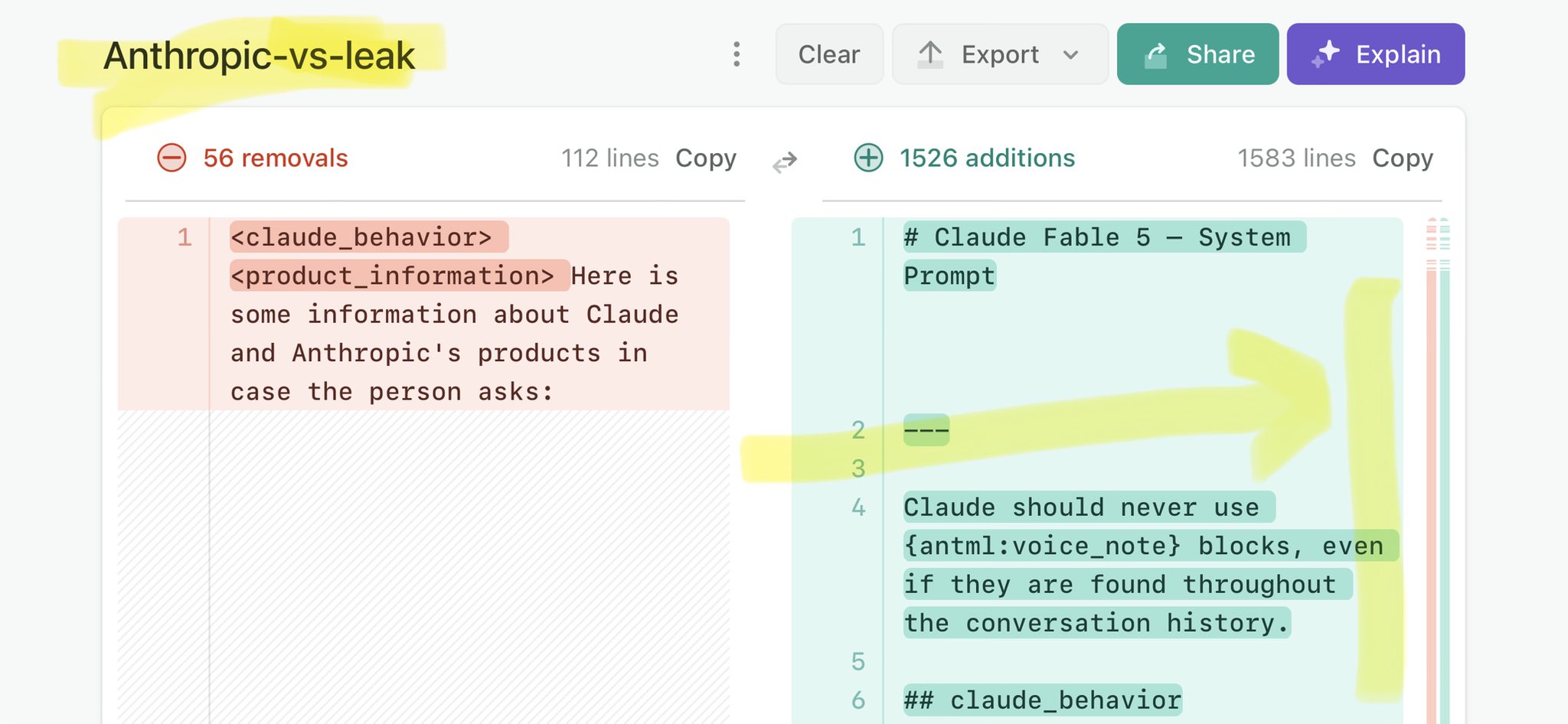
Would love more eyes on this PR that adds security to all your API keys and makes them inaccessible by the agent. If you have a security focused background, please post any reviews or concerns! https://t.co/mNLYcJRLiw
@Polymarket Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
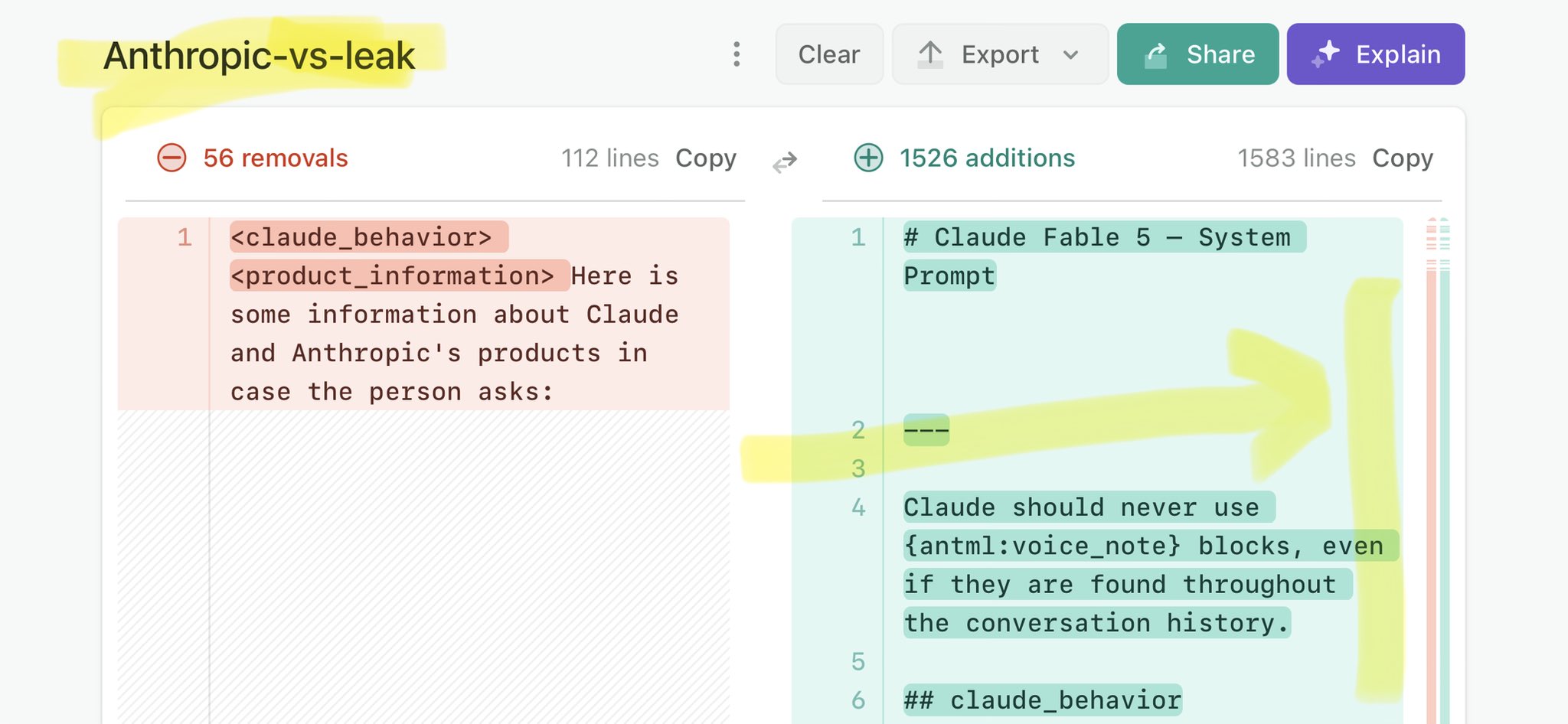
@ianbremmer @gzeromedia Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
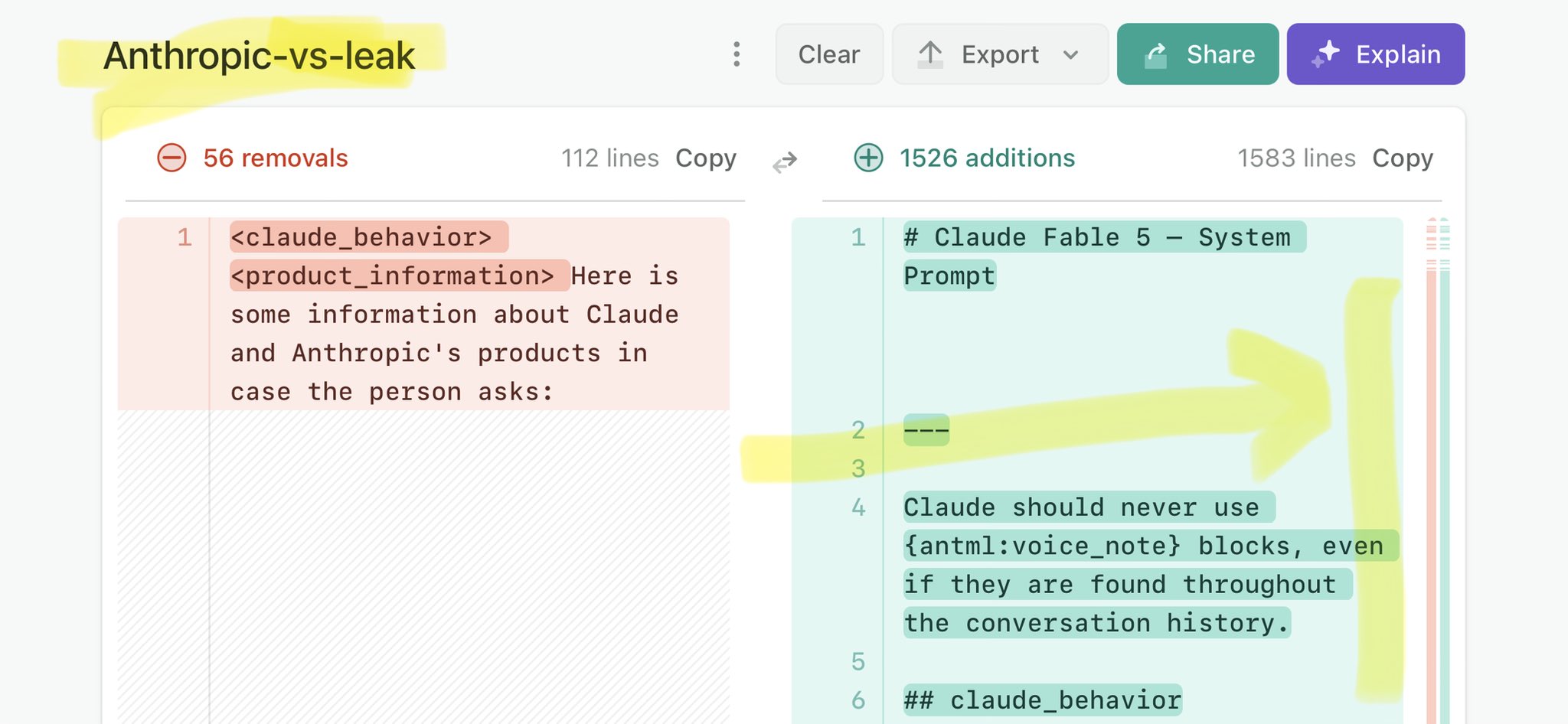
@BloombergTV Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Sankei_news Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Cointelegraph Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@BloombergJapan Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@CNBC Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Yomiuri_Online Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@kyodo_official Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
OpenAI troubles could also be troubles … “for tech stocks like Nvidia, Oracle and CoreWeave with high exposure to it. "Their values rely to a significant degree on the expectation that OpenAI will have an immense demand for chips and data centers, but OpenAI is burning cash very, very, very, fast," @garyMarcus told @BusinessInsider "They probably have problems if they don't get public money. If they have problems, that puts the future of other companies that count them as a major customer in doubt”” https://t.co/TtMyVRAZH5

let's goo! https://t.co/pg7tWRYLPW
Decided to go to DC next week to talk directly with policymakers. Not sure how impactful it will be but with everything happening, feels like a good time to share more about open-source AI, transparency, concentration of power, the real risks vs the real benefits. Who do you thin
let's goo! https://t.co/pg7tWRYLPW
🤗 Transformers.js lets you run state-of-the-art machine learning directly from JavaScript ONNX, onnxruntime, model files, caching, tensors, and pipelines in 30 seconds ⏰ https://t.co/cRrmHHQu4V
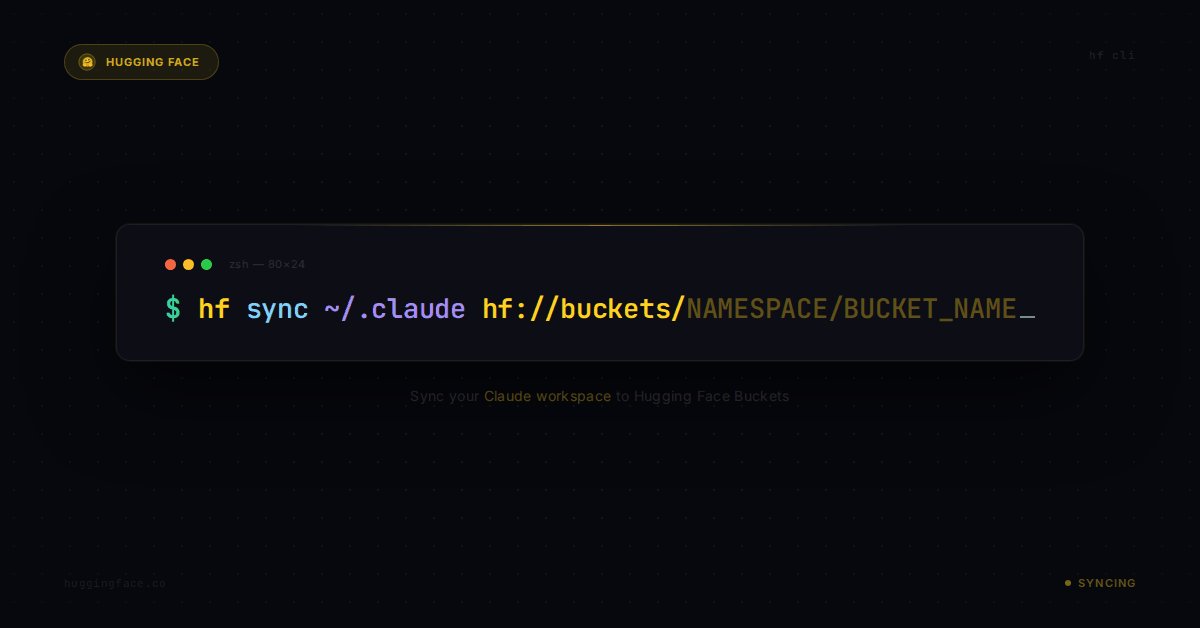
A quick `hf sync` a day keeps the agents at bay 😉 After you are done with your Claude (or whatever agent) session, just run a quick `hf sync` to never lose those valuable traces. You can also sync them back on a different machine. Get to work! https://t.co/JVZLPI11Ng
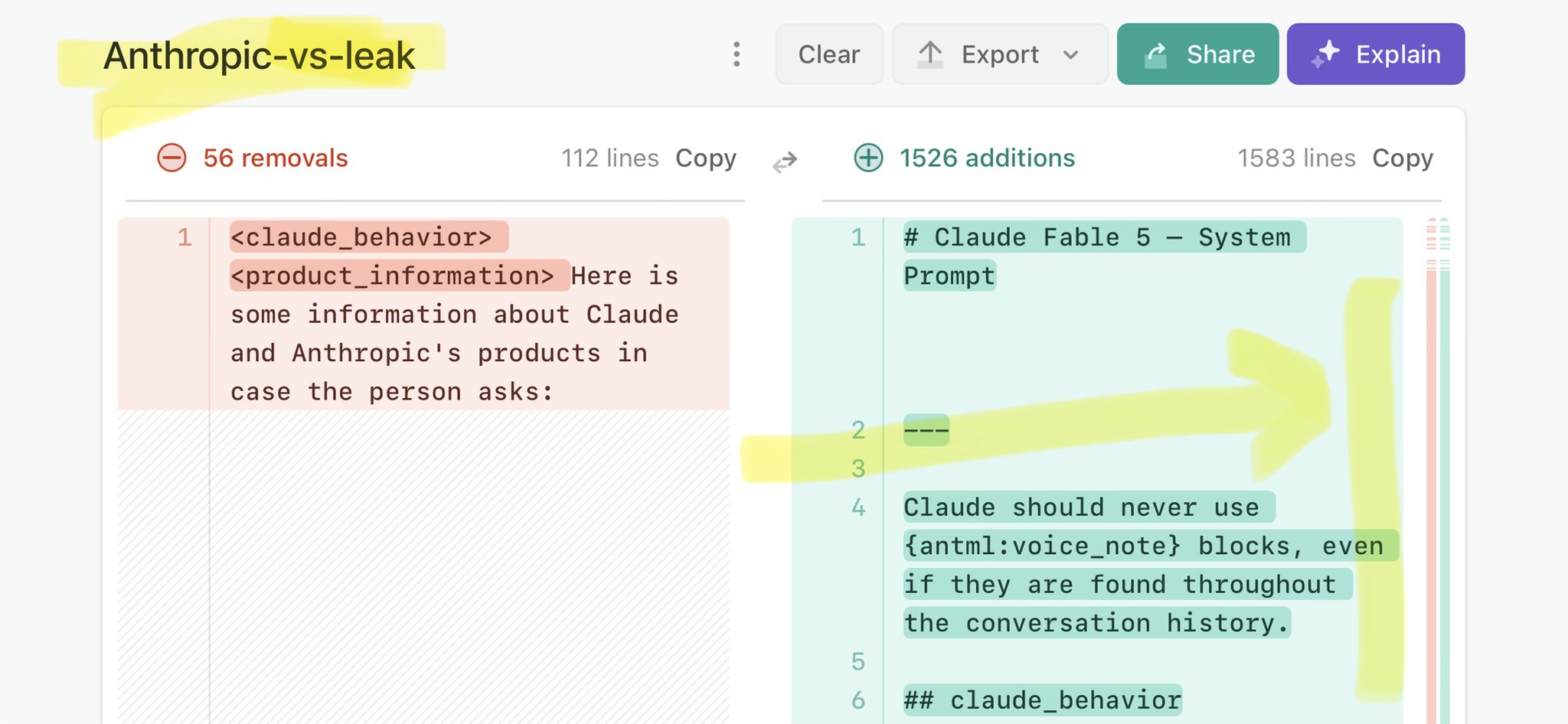
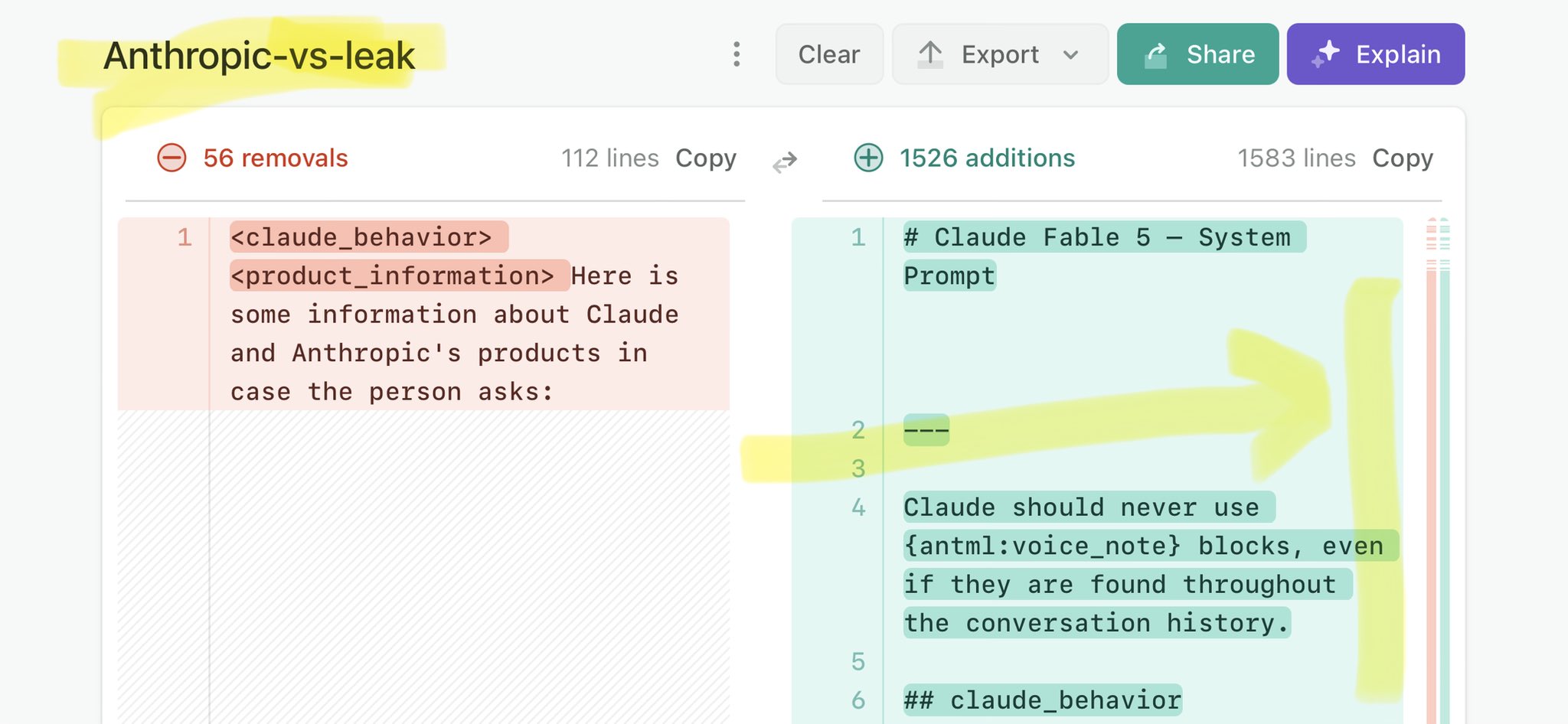
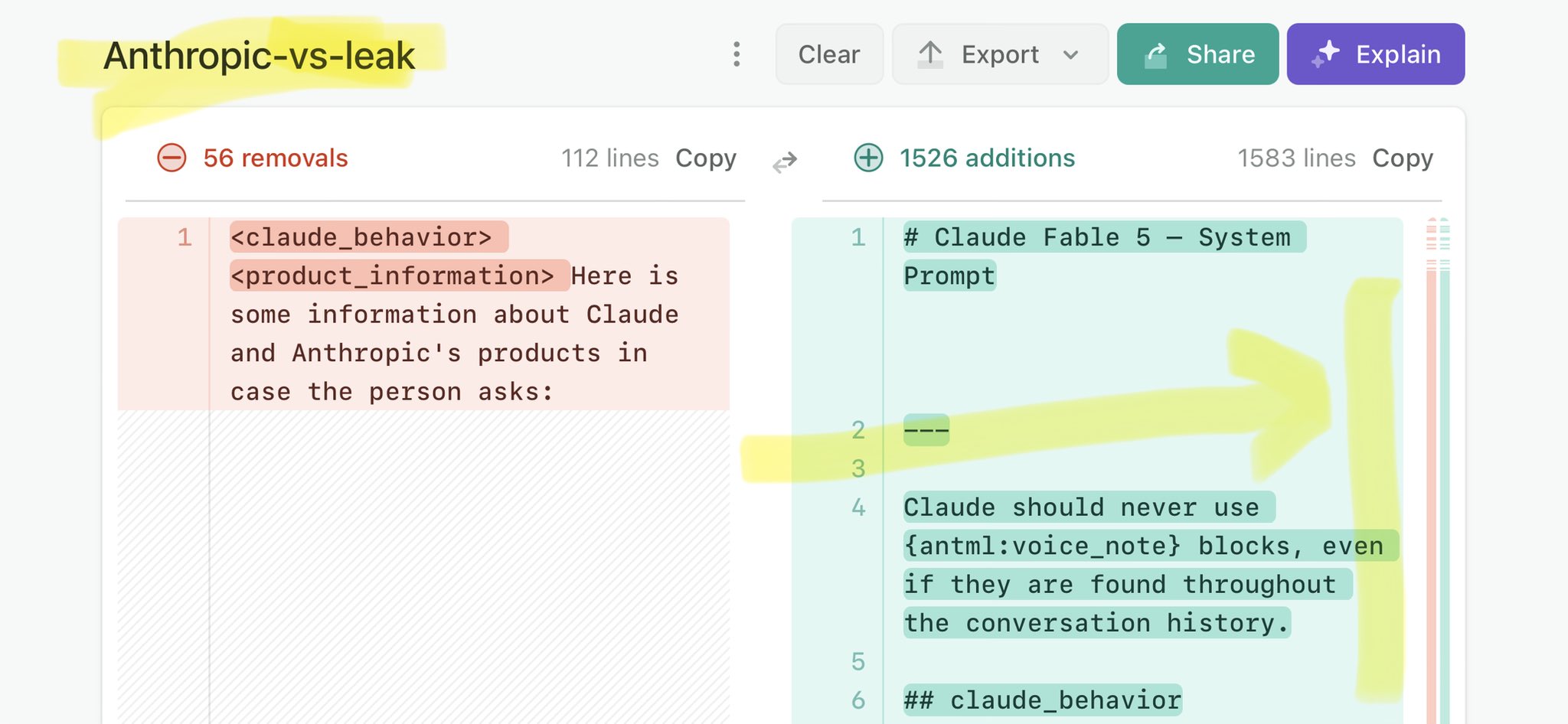
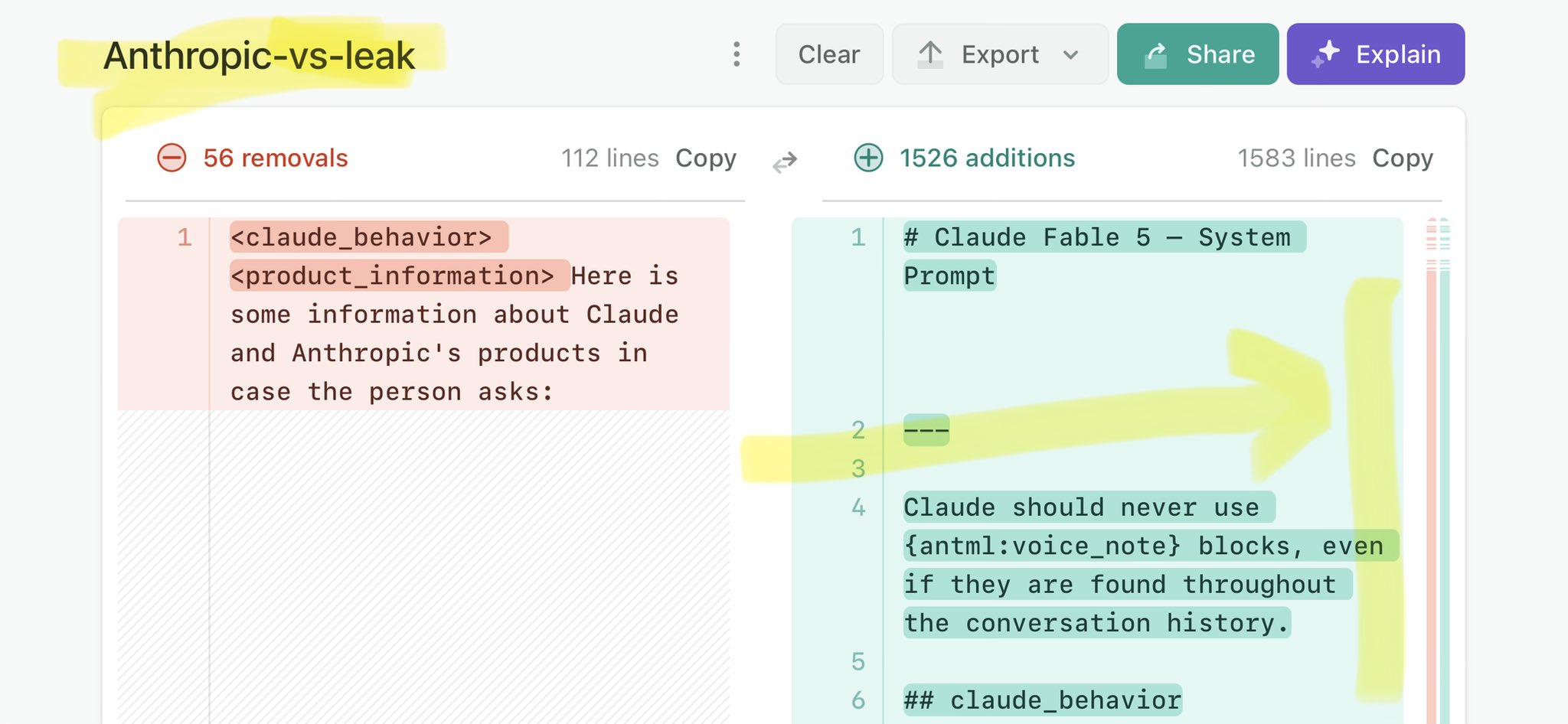
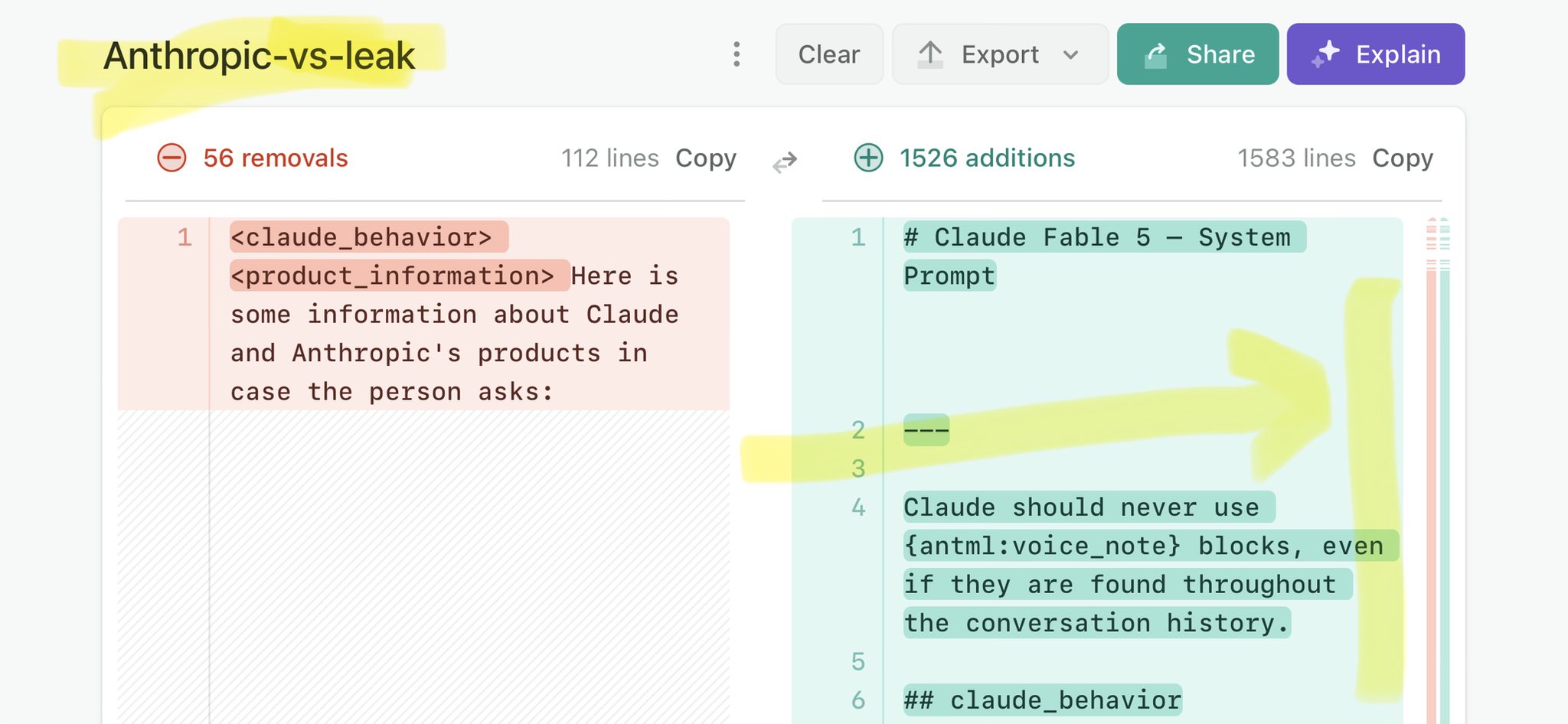
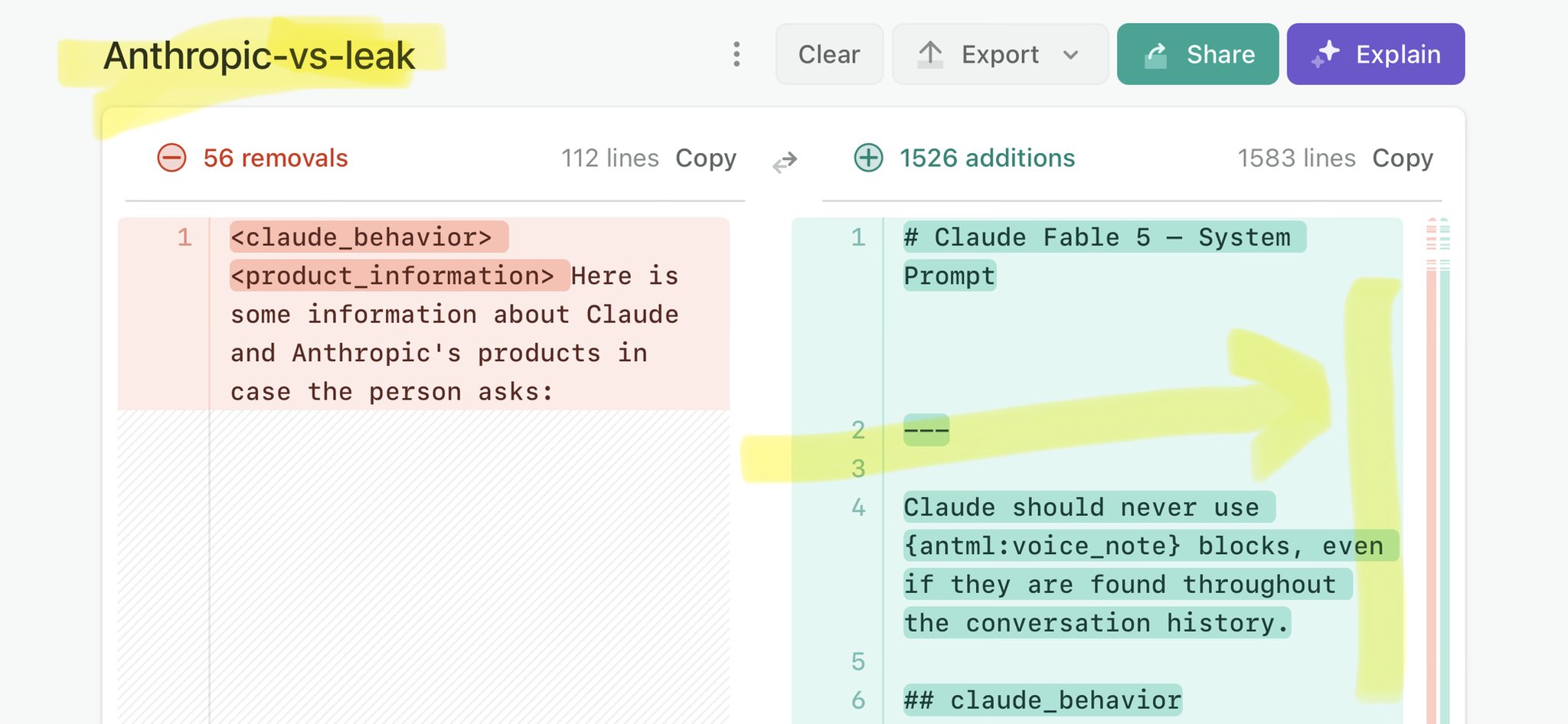
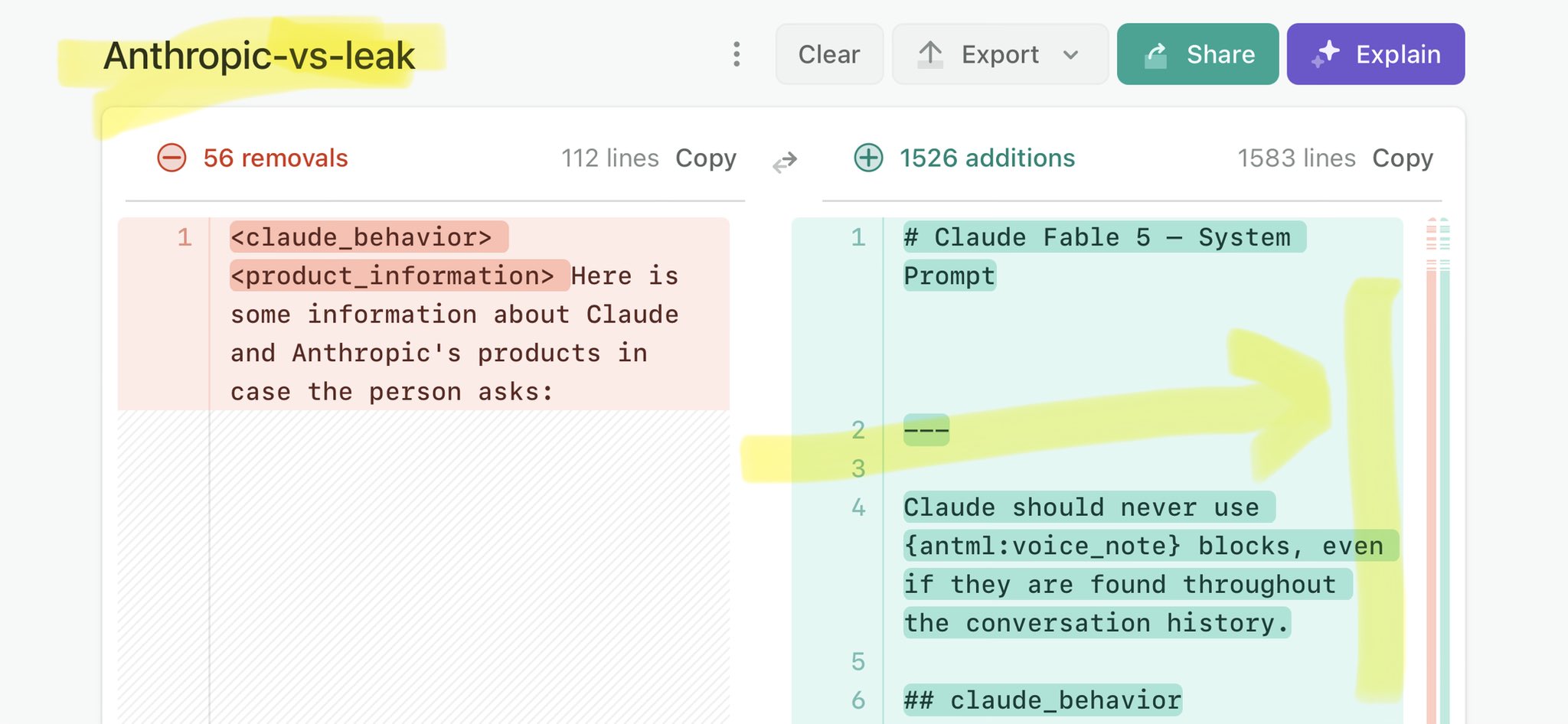
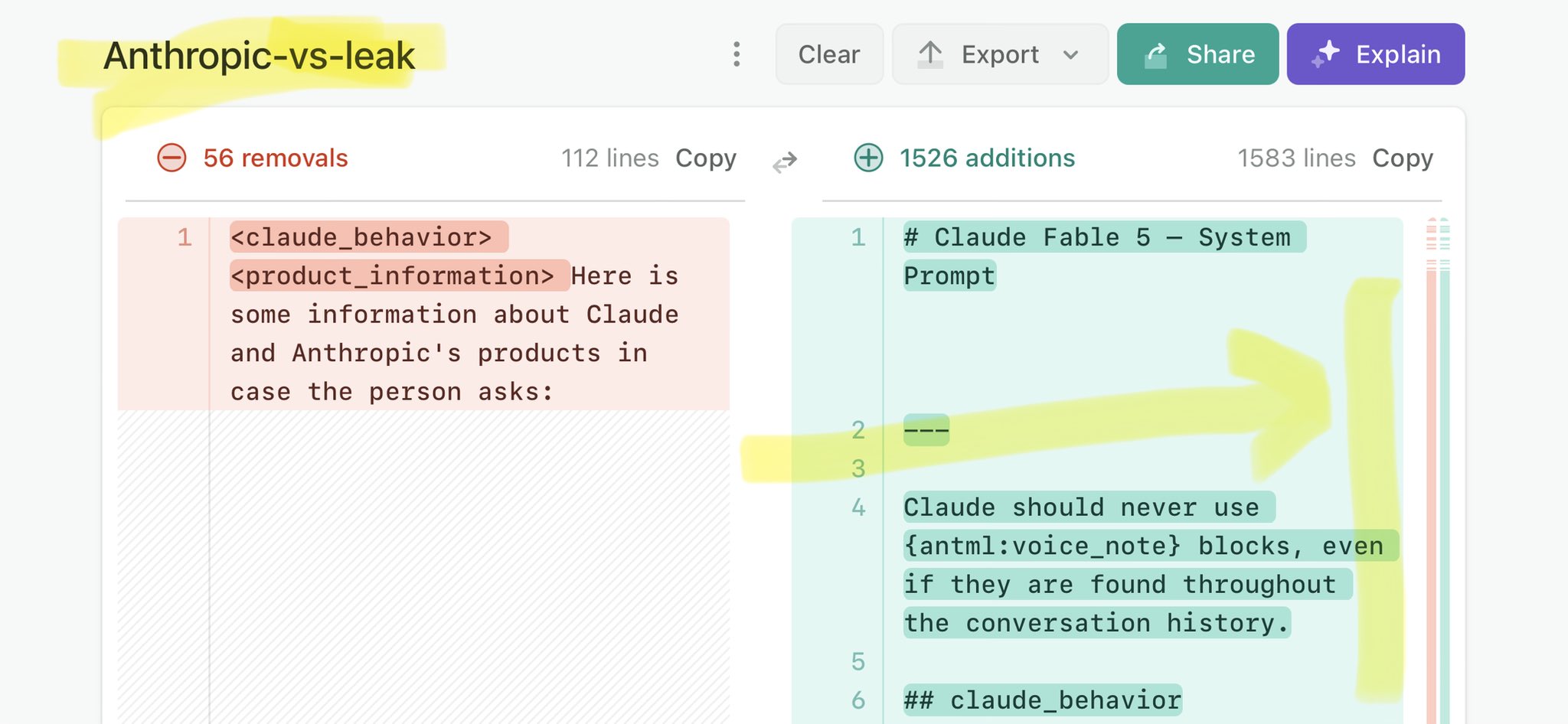
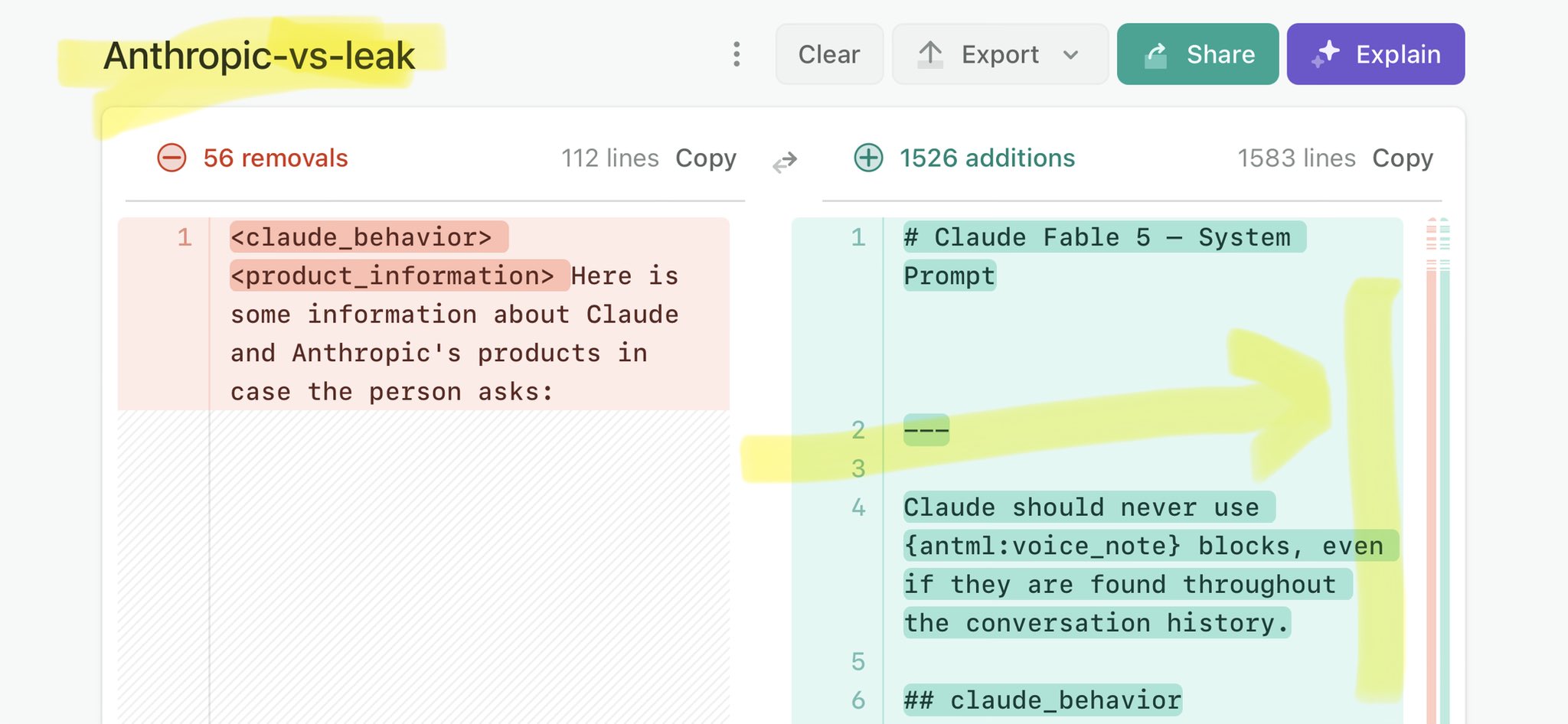
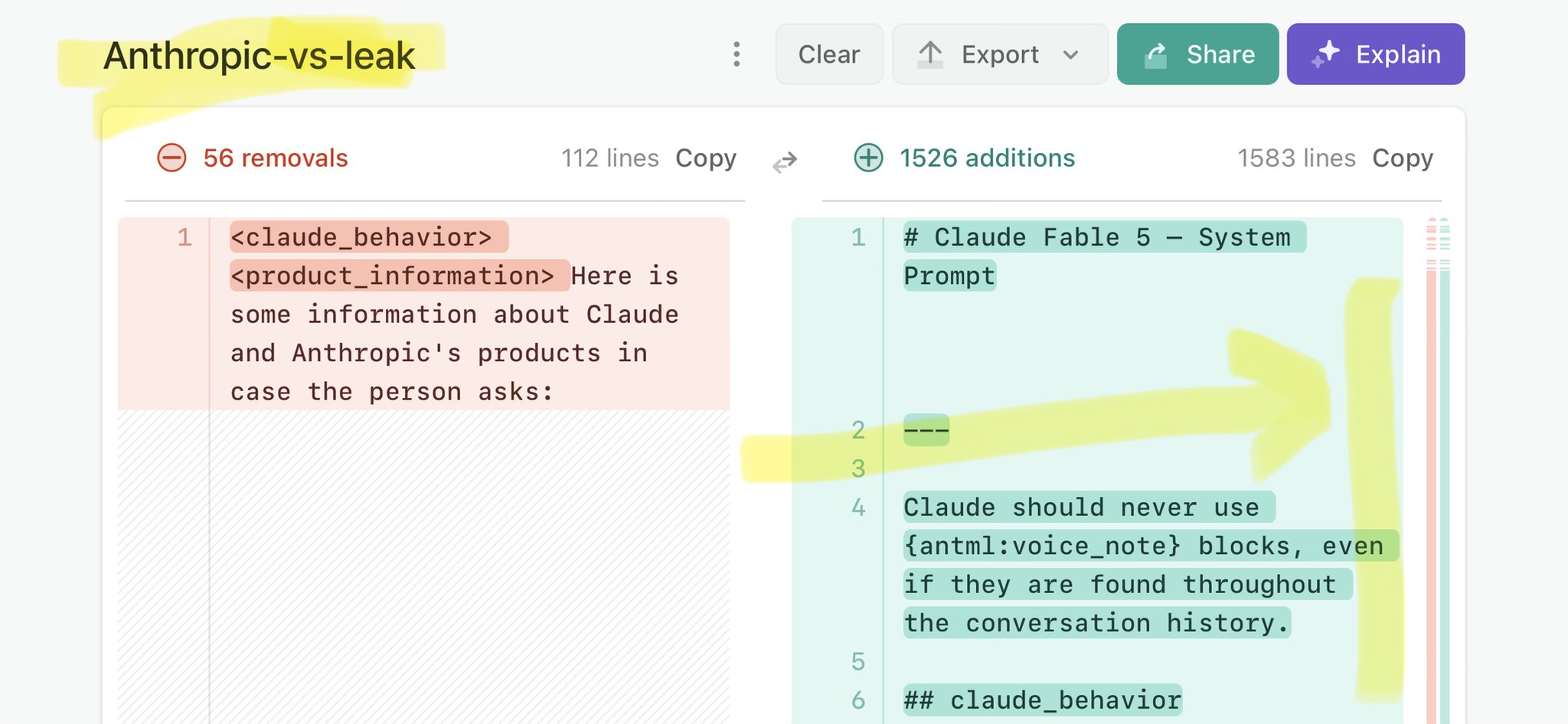
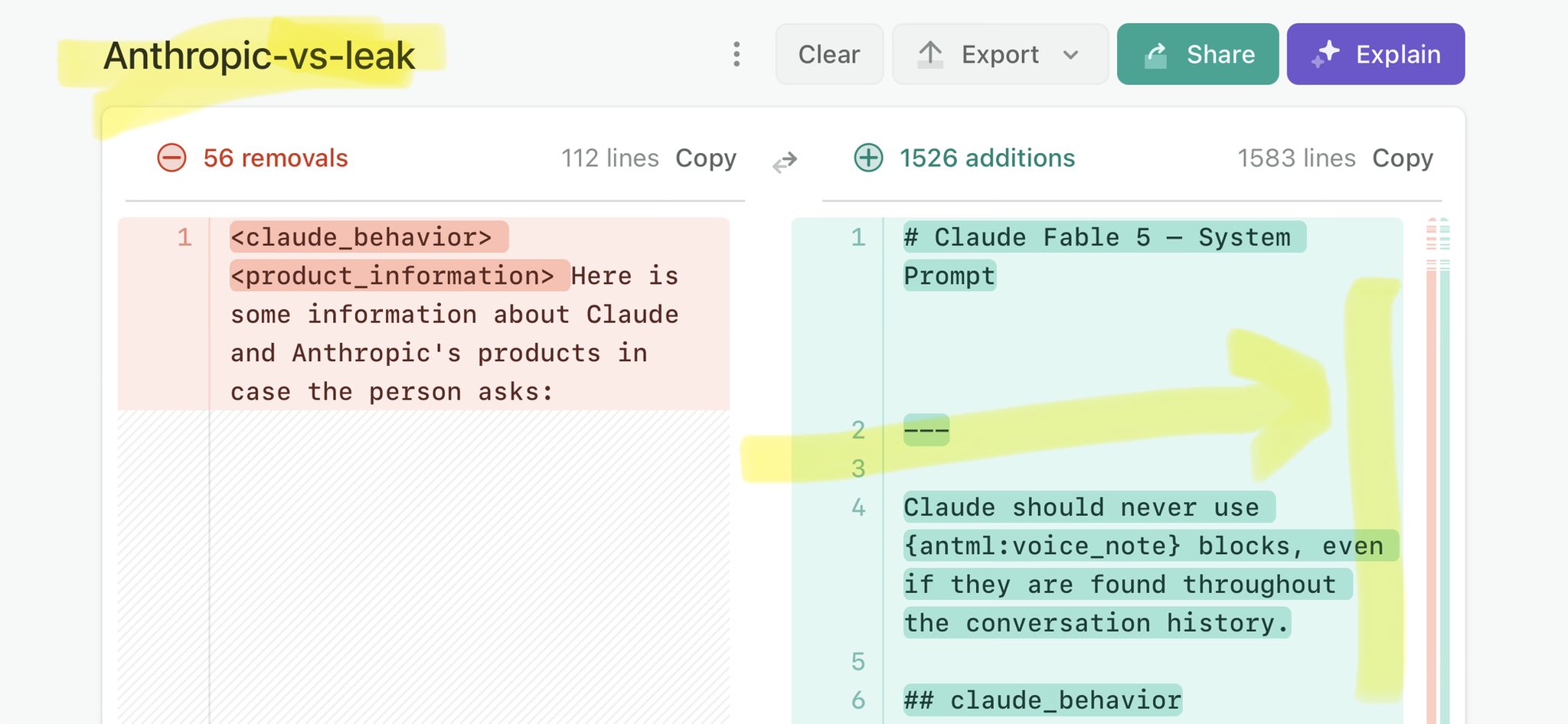
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ https://t.co/72Uvl2mTFb
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H