@steeve
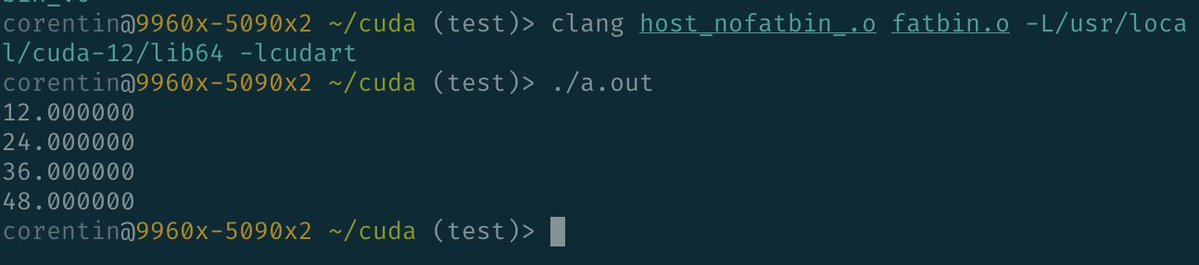
We managed the holy grail of CUDA compilation: joining CUDA host code and device code at *link time*. This means both build graphs (device and host) are now completely separated and built by SM. True scalable CUDA build graphs are now possible. Those who know, know. https://t.co/uR1kSGA9ed