Your curated collection of saved posts and media
Introducing Airwallex AgentOS. A toolkit for AI agents to work with Airwallex directly from @claudeai, @cursor_ai, or other terminal and chat-based agent environments. https://t.co/Qx9RkyjQd0
Codex and Claude just became a social hangout. Messages, see which friend is online, chat rooms, leaderboards good old’ ICQ / IRC chats vibes , inside Codex and Claude join -> shellbook . co https://t.co/QZVt8iGzzC
@CaptainHaHaa Yeah! And you know I'll post the scans on X. :-) My MRIs are already up: https://t.co/tYIpqtAvW0

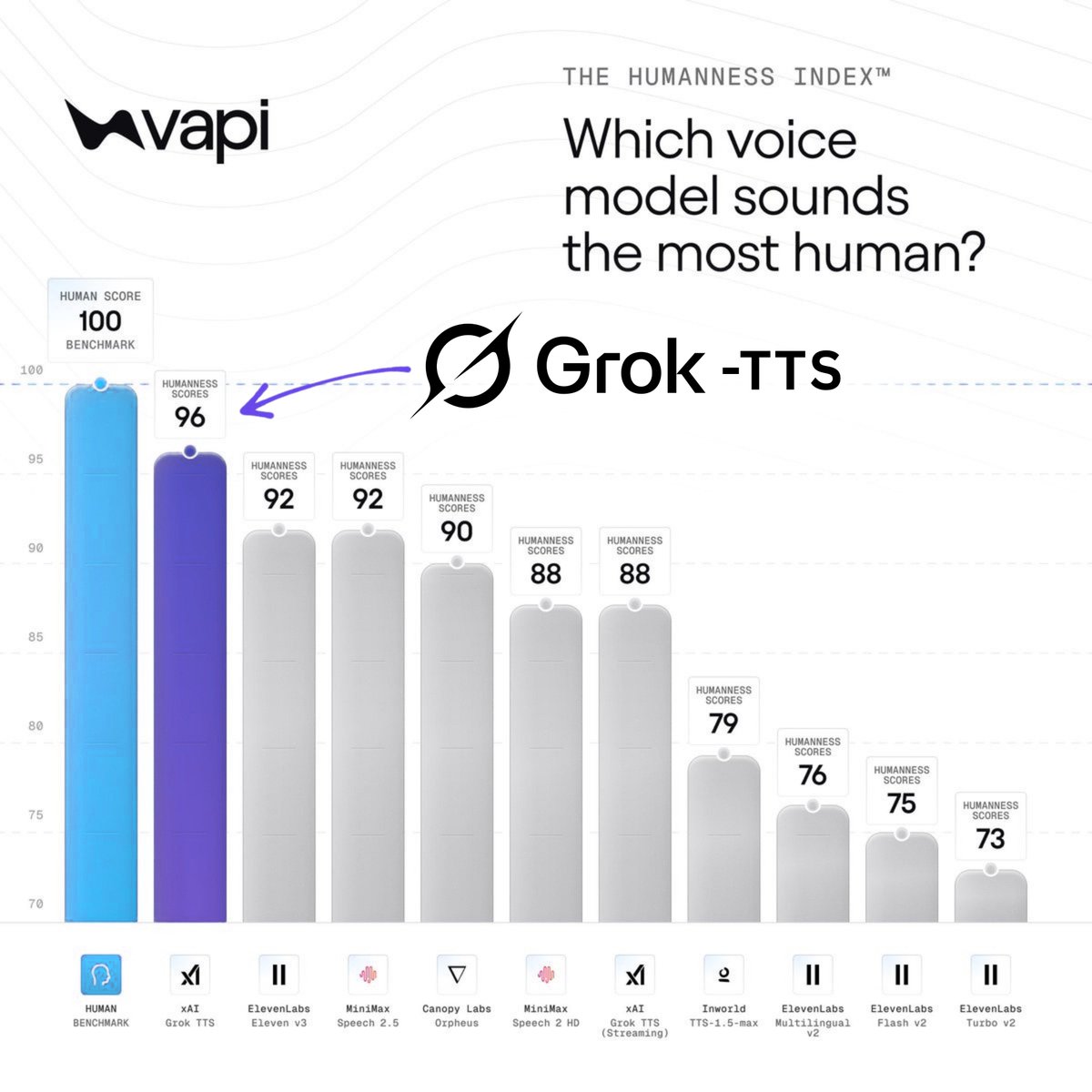
Grok TTS is already sounding insanely human In Vapi’s blind voting Humaneness Index, Grok TTS ranked as the top AI voice model in the chart with a humaneness score of 96.....just 4 points below the real human benchmark • Top AI voice model shown • 96/100 humaneness score • Only 4 points behind the human benchmark What makes this even more impressive is that Grok TTS is combining natural-sounding speech with low latency and aggressive pricing The gap between AI-generated speech and real human voices is disappearing faster than most people realize Grok is starting to speak like a real person
anyone giving me a hard time here might rewind eg to last fall and this kind of thing: https://t.co/ZfyqnGncI9

Accenture ($ACN) last fall: Look at our massive $3 billion bet on AI which will transform our business! Accenture today: quarterly revenue is down slightly Reality beats magical thinking, yet again. https://t.co/ZfyqnGncI9

Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
@Polymarket @bert_designs https://t.co/d9ArOL64ZU
Tell me you work for an AI lab without telling me: https://t.co/cmvee1GV5j
Just added this blog as a project page to https://t.co/6yQIMR6Ltn! Hope that more people can learn about state-of-the-art full-duplex voice models this way :) https://t.co/IcZwVCjIp2
Moshi is one of the best open source full-duplex voice models out there. The architecture is dense, so we spent a few days studying it and wrote up what we learned, with diagrams to make it click faster. Let us know if it was helpful 🤠 https://t.co/ollrKCnj7f

Just added this blog as a project page to https://t.co/6yQIMR6Ltn! Hope that more people can learn about state-of-the-art full-duplex voice models this way :) https://t.co/IcZwVCjIp2

GLM-5.2 is free when used with Hugging Face Inference Providers for the next 5 hours: https://t.co/YsYXgQpqTw
Open source MUST win 🔥 GLM-5.2 is free when used with Hugging Face Inference Providers and for every available provider for the next 6 hours (Zai, Together AI, Novita, Fireworks, DeepInfra) the cost is on us. Set it up with Pi, opencode, Codex, Claude Code or any coding agent t

GLM-5.2 is free when used with Hugging Face Inference Providers for the next 5 hours: https://t.co/YsYXgQpqTw

i/o bts ✨ https://t.co/3Zyrt56uov


i/o bts ✨ https://t.co/3Zyrt56uov


had fun hanging out & discussing hermes agent at @TechUpNetwork's @VivaTech side event at Orange Gardens in Paris yesterday. shout out to my co-presenters @orange & @NVIDIAAI https://t.co/wmCyCw8niI


@synthwavedd Claude Mythos jailbreak update: https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

this episode was sincere and touching, but found a little humor in it “when @Scobleizer killed Google Glasses” 🤣 https://t.co/JAhRknWcPG
@shadcn I love this a ton (files over everything). Just got it integrated with our coding playgrounds/sandboxes, so should have it ready for our community to play around with it over the weekend. Any tips on things to surface for anyone getting started? https://t.co/A8ICVDctho
Today we’re releasing the weights for Laguna M.1, our most capable model to date, with a 256K context length. Both base and post-trained checkpoints are now available on Hugging Face under Apache 2.0. https://t.co/gMWuYo8zN1

I think it will happen close to EOY or the beginning of next year. Not a wild guess. I have seen enough research and results to know that the gap is closing fast. And I use models like DeepSeek, GLM, Qwen, Kimi, and MiniMax more than ever now. https://t.co/Un5vs9TWJU
Autotuning is the backbone of Helion, PyTorch's DSL for performance portable ML kernels. Currently Helion searches utilize Likelihood-Free Bayesian Optimization (LFBO) to find the most performant configs. While LFBO works well, it requires grinding through hundreds of compile-and-benchmark cycles per kernel. What if, instead of starting the search blindly, you could ask an LLM to reason about the kernel and propose configurations? In this blog, we look at how LLM-guided autotuning is a practical approach to dramatically faster kernel tuning at production quality. Click the link in the comments section to learn more. @JongsokC @oguz_ulgen

I have always been of the opinion that unpopularity earned by doing what is right is not unpopularity at all, but glory. -Cicero https://t.co/5QaZZS4Q7W

https://t.co/goVNcKkioH
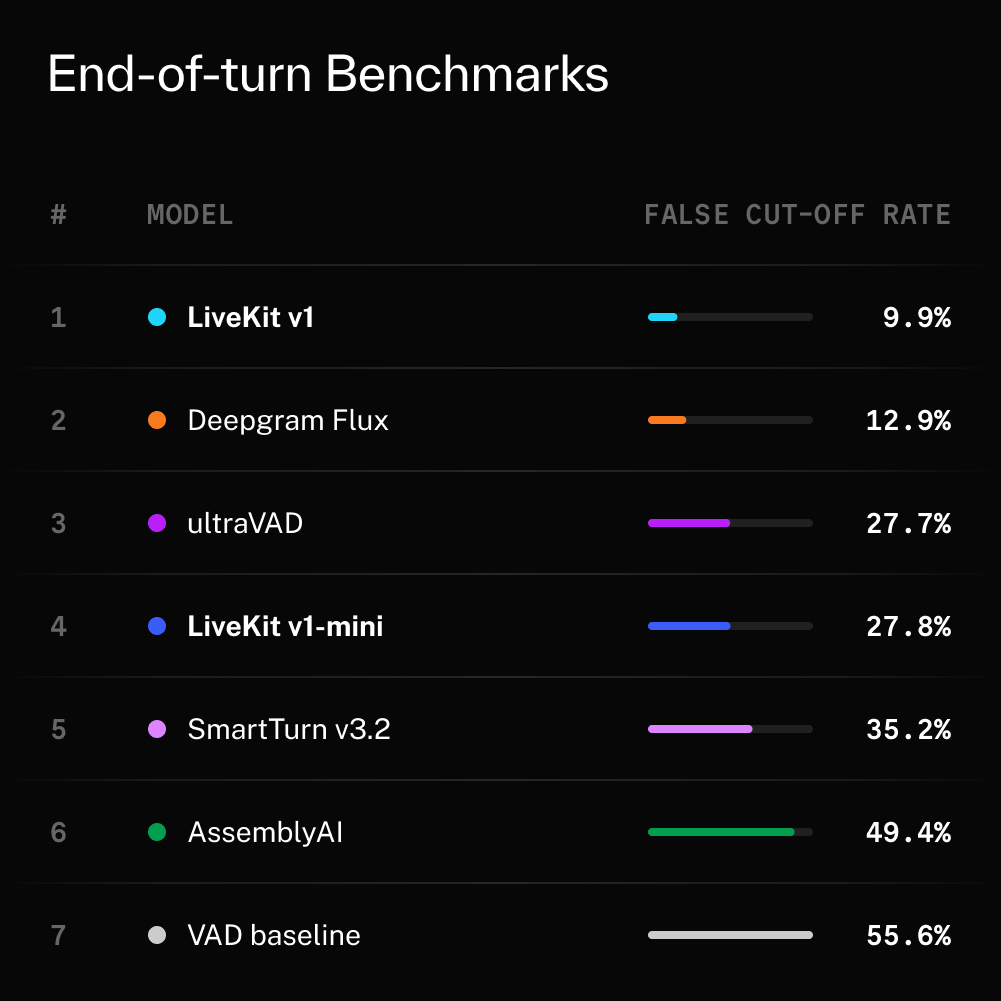
Voice AI has a benchmarking problem. Everyone claims their end-of-turn model is the best, but you couldn't actually compare them. Datasets are proprietary, methods are opaque, and there is no shared ground truth. That changes today. We hit this while developing Turn Detector v1, so we open-sourced eot-bench. 5,000+ real user conversation turns across 14 languages, an evaluation harness that measures the real production tradeoff between latency and false cutoffs, and a live public leaderboard. This should become the default way we evaluate turn detection models.
LiteParse v2.1 is here, and its bringing the fastest markdown output possible. In this release, we are fulfilling our top request: markdown output. But in the spirit of "lite"-ness, we are doing this completely LLM-free and fast. Not only is it fast, it also beats all other model-free competitors in 3 separate benchmark datasets. Read more about it in our release blog: https://t.co/MiqML6kxTY
For years @GaryMarcus has noted that OpenAI's model is unsustainable. Now reality is setting in. https://t.co/NDl4sINsSe
@iyanmoonyang @sundayrobotics Follow everyone else in AI and robotics. I made you the most complete lists of such: https://t.co/fasUz7PuHq And my AI watches everyone and builds a news page: https://t.co/kiuZ7QXLzb all linking back to X.

Looks like some very solid performance numbers from GPT-5.5 in real world application! https://t.co/K4WtXsiCMZ

@ai_explorer25 @karpathy @bcherny @trq212 Claude Mythos jailbreak: Have you been impacted? https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

come by! https://t.co/5hy51RFSGh https://t.co/TZdXP8AdHS

New course: Add voice to your AI agents and applications, built with @VocalBridge (disclosure: an AI Fund portfolio company) and taught by its CEO @_ashwyn. Voice applications historically required making a hard tradeoff: using fast voice-to-voice models that sacrifice reliability, or accurate speech-to-text pipelines that add latency. This course teaches you how to build voice agents that are both reliable and fast. You'll build three types of voice-enabled applications: a voice-interactive game where voice commands and mouse clicks work together over a single channel, an agent that gains a voice in about 10 lines of code without touching its prompts or tools, and an agent that places outbound phone calls using a make_phone_call function. Skills you'll gain: - Add a voice layer to an existing agent without rewriting your prompts, RAG pipeline, or tools - Give an agent the ability to place outbound calls and stream transcripts back live - Set up voice evaluation to score calls, catch regressions, and improve quality before deployment Join and add voice to your agents without overhauling your architecture: https://t.co/gBO4nmaU9u
New Frontier Red Team blog: Phase 2 of Project Fetch, where we test how well Claude can program a robodog. Opus 4.7, on its own, was ~20x faster than last year's best human team aided by Opus 4.1. (The robodog, alas, still failed to fetch a beach ball.) https://t.co/CgbBtRf85e
