@WilliamBarrHeld
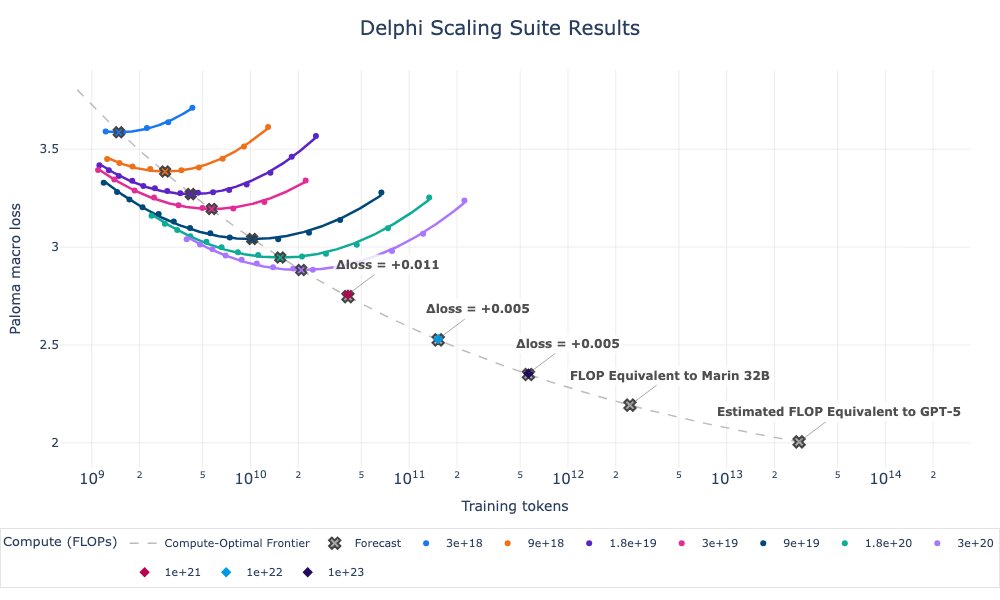
How far do Marin's scaling laws extrapolate? At least 100x, apparently! Despite spooky spikes, our 1e23 Delphi finished on forecast. The compute-optimal ladder costs ~1e21 FLOPs to train. Good scaling science lets you “run” this (not tiny) experiment at 1/100th the cost. https://t.co/nRJma4sunw