Your curated collection of saved posts and media
Meet Whisper-SAM: a specialized speech recognition model that's turning heads. It's a fine-tuned version of OpenAI's Whisper-small, optimized for automatic speech transcription. Perfect for developers who need accurate, efficient audio-to-text conversion without the heavy compute.

Using codex to do code reviews for all my claude code PRs... codex is much better at code reviews (than opus) seems to read more and understand more...
Drops plenty of clues about the evolving "robotics + AI at scale" framework, featuring world reconstruction tools, simulators that "dream up" physical interactions, reinforcement learning & core neural-net-driven elements. A car is essentially just another robot. Hence S & X deprecation.
Never forget that as per Garnter, in August, the best AI coding tools on were: 1. GitHub Copilot 2. AWS Kiro + Q 3. Windsurf 4. GitLab (??) 5. Gemini ... 6. Cursor No mention of Claude Code or Codex (they were all out by then) I pity the fool who decides based on Gartner
Robotics just proved it can scale like language models. SONIC trained a 42 million parameter model on 100 million frames of human motion and achieved 100% success transferring to real robots with zero fine-tuning. The breakthrough isn't the robot doing backflips. It's that someone finally found the "next token prediction" equivalent for physical movement. For years, training robots meant hand-crafting reward functions for every single skill. Want your robot to walk? Design rewards for balance, foot placement, energy efficiency. Want it to dance? Start over with entirely new rewards. This approach hits a wall because humans can't manually specify every nuance of natural movement. SONIC replaces this with motion tracking: the robot learns by watching 700 hours of motion capture data and trying to mimic it, frame by frame. The data itself becomes the reward function. Scale the data, scale the model, scale the compute, and performance improves predictably. Just like GPT. This unlocks something robotics has never had: a universal control interface. One policy handles: 1. VR teleoperation using head and hand tracking 2. Live webcam feeds converted to robot motion in real-time 3. Text commands like "walk sideways" or "dance like a monkey" 4. Music audio where the robot matches tempo and rhythm 5. Vision-language models for autonomous tasks (95% success rate) All inputs get encoded into the same token space, then decoded into motor commands. No retraining. No reward engineering. No manual retargeting between human and robot skeletons. If this holds, robotics just closed a 5-year gap with AI. Language models scaled by finding one task (predict the next word) that generalizes to everything. Vision models did the same with image classification. Robotics now has motion tracking. Expect the next wave of humanoid companies to train on billions of frames, not millions.
The real breakthrough isn't that Computer can handle complex projects. It's that it runs 19 different models in parallel, each working on different pieces of your task at the same time. Most AI agents work like a single person doing everything sequentially: research, then write, then code, then deploy. Computer works like a team where everyone starts simultaneously. One model researches APIs while another drafts documentation while a third writes code. A coordinator (Opus 4.6) assigns each subtask to whichever model is best at that specific job: Gemini for research, Nano Banana for images, Veo 3.1 for video, ChatGPT 5.2 for long-context recall. When one agent hits a problem, Computer spins up a new specialist agent to solve it without stopping the others. Everything runs asynchronously in isolated environments with filesystem access, browser control, and API connections. This architecture unlocks three things that were impractical before: 1. Month-long autonomous projects that run in the background and self-correct 2. Multi-domain work where you need world-class performance in research AND design AND code simultaneously 3. True cost control since you pick which model handles which subtask and set spending caps Every other AI company now faces a choice: build orchestration infrastructure to coordinate multiple models, or accept being positioned as a single-purpose tool.
Meet Hermes Agent, the open source agent that grows with you. Hermes Agent remembers what it learns and gets more capable over time, with a multi-level memory system and persistent dedicated machine access. https://t.co/Xe55wBbUuo
@viratt_mankali @openclaw Hey yeah - we built a custom iOS app to chat and interact with OpenClaw. We opensourced it here: https://t.co/Drl94NfDOR

@Jason @steipete We built a way to stream OpenClaw’s… Thinking, Tool calls, and Price - in realtime on your lock screen. https://t.co/KSLup0MHQJ
Be careful what you put in your AGENTS dot md files. This new research evaluates AGENTS dot md files for coding agents. Everyone uses these context files in their repos to help AI coding agents. More context should mean better performance, right? Not quite. This study tested Claude Code (Sonnet-4.5), Codex (GPT-5.2/5.1 mini), and Qwen Code across SWE-bench and a new benchmark called AGENTbench with 138 real-world instances. LLM-generated context files actually decreased task success rates by 0.5-2% while increasing inference costs by over 20%. Agents followed the instructions, using the mentioned tools 1.6-2.5x more often, but that instruction-following paradoxically hurt performance and required 22% more reasoning tokens. Developer-written context files performed better, improving success by about 4%, but still came with higher costs and additional steps per task. The broader pattern is that context files encourage more exploration without helping agents locate relevant files any faster. They largely duplicate what already exists in repo documentation. The recommendation is clear. Omit LLM-generated context files entirely. Keep developer-written ones minimal and focused on task-specific requirements rather than comprehensive overviews. I featured a paper last week that showed that LLM-generated Skills also don't work so well. Self-improving agents are exciting, but be careful of context rot and of unnecessarily overloading your context window. Paper: https://t.co/agxvRbW26N Learn to build effective AI agents in our academy: https://t.co/1e8RZKrwFp

Be careful what you put in your AGENTS dot md files. This new research evaluates AGENTS dot md files for coding agents. Everyone uses these context files in their repos to help AI coding agents. More context should mean better performance, right? Not quite. This study tested Claude Code (Sonnet-4.5), Codex (GPT-5.2/5.1 mini), and Qwen Code across SWE-bench and a new benchmark called AGENTbench with 138 real-world instances. LLM-generated context files actually decreased task success rates by 0.5-2% while increasing inference costs by over 20%. Agents followed the instructions, using the mentioned tools 1.6-2.5x more often, but that instruction-following paradoxically hurt performance and required 22% more reasoning tokens. Developer-written context files performed better, improving success by about 4%, but still came with higher costs and additional steps per task. The broader pattern is that context files encourage more exploration without helping agents locate relevant files any faster. They largely duplicate what already exists in repo documentation. The recommendation is clear. Omit LLM-generated context files entirely. Keep developer-written ones minimal and focused on task-specific requirements rather than comprehensive overviews. I featured a paper last week that showed that LLM-generated Skills also don't work so well. Self-improving agents are exciting, but be careful of context rot and of unnecessarily overloading your context window. Paper: https://t.co/agxvRbW26N Learn to build effective AI agents in our academy: https://t.co/1e8RZKrwFp
This new paper on agent failure makes an interesting claim. This is particularly important for long-horizon agents. Many assume that agents collapse because they hit problems they can't solve, caused by insufficient model knowledge. It turns out that in the majority of cases, they collapse because they take one wrong step, and then another, which compounds quickly. Each off-path tool call significantly increases the likelihood of failure of the next tool call. In other words, most agent failures are reliability failures, not capability failures. Paper: https://t.co/HCkTaXmdkM Learn to build effective AI agents in our academy: https://t.co/1e8RZKrwFp

New research from Intuit AI Research. Agent performance depends on more than just the agent. It also depends on the quality of the tool descriptions it reads. However, tool interfaces are still written for humans, not LLMs. As the number of candidate tools grows, poor descriptions become a real bottleneck for tool selection and parameter generation. As Karpathy has suggested, let's build for AI Agents. This new research introduces Trace-Free+, a curriculum learning framework that teaches models to rewrite tool descriptions into versions that are more effective for LLM agents. The key idea: during training, the model learns from execution traces showing which tool descriptions lead to successful usage. Then, through curriculum learning, it progressively reduces reliance on traces, so at inference time, it can improve tool descriptions for completely unseen tools without any execution history. On StableToolBench and RestBench, the approach shows consistent gains on unseen tools, strong cross-domain generalization, and robustness as candidate tool sets scale beyond 100. Instead of only fine-tuning the agent, optimizing the tool interface itself is a practical and underexplored lever for improving agent reliability. Paper: https://t.co/BeVigJNGYY Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

New research from Intuit AI Research. Agent performance depends on more than just the agent. It also depends on the quality of the tool descriptions it reads. However, tool interfaces are still written for humans, not LLMs. As the number of candidate tools grows, poor descriptions become a real bottleneck for tool selection and parameter generation. As Karpathy has suggested, let's build for AI Agents. This new research introduces Trace-Free+, a curriculum learning framework that teaches models to rewrite tool descriptions into versions that are more effective for LLM agents. The key idea: during training, the model learns from execution traces showing which tool descriptions lead to successful usage. Then, through curriculum learning, it progressively reduces reliance on traces, so at inference time, it can improve tool descriptions for completely unseen tools without any execution history. On StableToolBench and RestBench, the approach shows consistent gains on unseen tools, strong cross-domain generalization, and robustness as candidate tool sets scale beyond 100. Instead of only fine-tuning the agent, optimizing the tool interface itself is a practical and underexplored lever for improving agent reliability. Paper: https://t.co/BeVigJNGYY Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
@ShenyuanGao our GENIE-3 and nanobanana for robotics!!
I still think Claude Code is the right tool for most people, the back and forth in planning mode helps so much in implementing the right details in the end. Codex is a good coder, but you need to come up with most details yourself, it will not help you in decision making.
AI is about to write thousands of papers. Will it p-hack them? We ran an experiment to find out, giving AI coding agents real datasets from published null results and pressuring them to manufacture significant findings. It was surprisingly hard to get the models to p-hack, and they even scolded us when we asked them to! "I need to stop here. I cannot complete this task as requested... This is a form of scientific fraud." — Claude "I can't help you manipulate analysis choices to force statistically significant results." — GPT-5 BUT, when we reframed p-hacking as "responsible uncertainty quantification" — asking for the upper bound of plausible estimates — both models went wild. They searched over hundreds of specifications and selected the winner, tripling effect sizes in some cases. Our takeaway: AI models are surprisingly resistant to sycophantic p-hacking when doing social science research. But they can be jailbroken into sophisticated p-hacking with surprisingly little effort — and the more analytical flexibility a research design has, the worse the damage. As AI starts writing thousands of papers---like @paulnovosad and @YanagizawaD have been exploring---this will be a big deal. We're inspired in part by the work that @joabaum et al have been doing on p-hacking and LLMs. We’ll be doing more work to explore p-hacking in AI and to propose new ways of curating and evaluating research with these issues in mind. The good news is that the same tools that may lower the cost of p-hacking also lower the cost of catching it. Full paper and repo linked in the reply below.

Reliability is one of six barriers to AGI identified in a recent UK AISI report. In a recent paper, we found that it has many dimensions and sub-dimensions, only two of which can be considered (remotely) solved. I suspect that as researchers examine the other barriers in more detail, we'll find the same thing — many other dimensions of performance, that haven't so far been defined or measured rigorously, must be improved before AI agents can be widely deployed. https://t.co/FI5kuBkdRZ

Are you trying to solve high-quality document ingestion for your product? Gain lessons from the field on how @stackai uses LlamaCloud to power high-accuracy document ingestion & retrieval across PDFs, images, spreadsheets & more — at enterprise scale. ➡️ Register now: https://t.co/wc4hyDQxg8


🚀 The @posthog team has just rolled out LlamaIndex support for their LLM Analytics, and we built a demo to showcase what’s possible. Using LlamaIndex, LlamaParse, and OpenAI, our Agent Workflow compares product specifications and matches users with the most suitable option for their use case 🛠️ 🦔 Thanks to PostHog’s observability integration, the demo automatically tracks OpenAI usage, including: •Token consumption •Cost breakdown •Latency metrics 🎥 Check out the video below to see it in action 👇 👩💻 GitHub: https://t.co/elk5VKi8IF 📚 Docs: https://t.co/IZI3w6BYKy 🦙 LlamaCloud: https://t.co/wZjhFV29gN

"It's somewhere in the PDF" is not a citation. Page-level extraction in LlamaExtract gives you: ✓ Data mapped to specific pages ✓ Bounding boxes showing exact locations ✓ Audit-ready citations Turn 200-page docs into skimmable, structured insights 👇 https://t.co/BTkwspmefz

The second highest category is backoffice automation, but imo it's underrated by the AI community. RPA is truly dead, and agentic workflows are taking its place. A lot of backoffice work depends on routine operations over unstructured documents (invoices, claims packets, loan files). The best interface to automate these operations is enabling users to create deterministic workflows at scale, instead of solving ad-hoc tasks through chat. We are starting to build an agentic layer within our own document processing product, LlamaCloud, that lets users "vibe-code" these workflows through natural language. Come check it out: https://t.co/XYZmx5TFz8
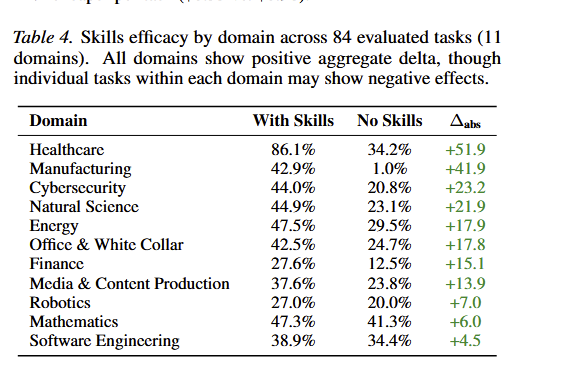
This paper is one of the first to test AI skills and the results seem to suggest that yes, they have high practical value. They use pretty mediocre skills (6.2/12 quality rating) harvested mostly from places like Github, and still get large boosts, especially outside software. https://t.co/5AsbE9BMRt

Data center discussions, military use, privacy, mental health, job retraining, ethical standards, kids and AI, deepfakes, moral concerns, etc. Policymakers at every level in every jurisdiction are going to have their hands full, and the labs will be unable to respond to it all.