Your curated collection of saved posts and media
good very practical example of potential real world applications of world models there is real economic value at the end of the rainbow!
World models should not just look real. They should obey physics. CrashTwin stress-tests generative world models on safety-critical crashes, measuring temporal consistency, momentum and energy conservation, and identity stability. Data + code: https://t.co/3ci6HOAJRK
GLM 5.2 DSpark preview is here! ✨ https://t.co/DQOMYEiY1o This is the first DSpark speculator for a non-DeepSeek frontier model, trained with Speculators and running on vLLM nightly for ~1.5× faster decode for GLM-5.2-FP8 on 4×B300. Stronger checkpoints to come!
this means GLM 5.2 DSpark on the way btw

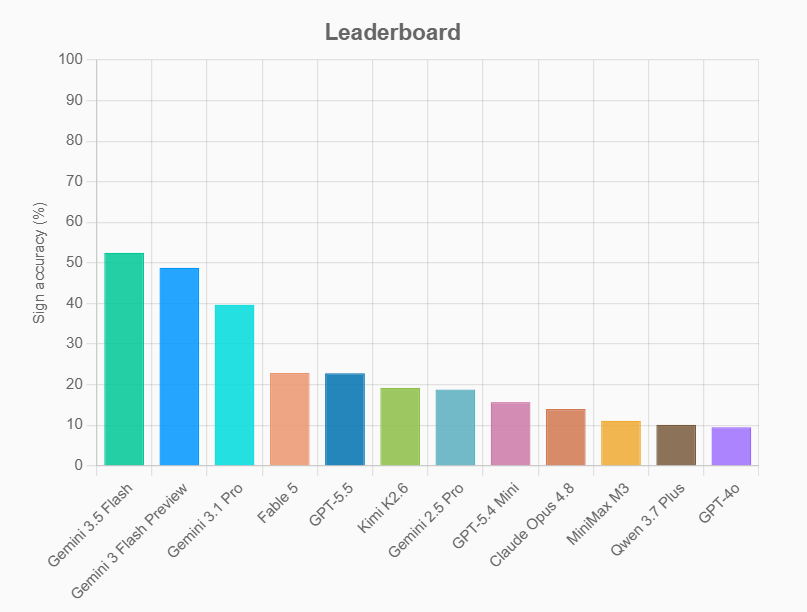
Fable 5 is a large step for Anthropic's vision capabilities and effectively ties with GPT-5.5 on HieroglyphBench, my benchmark which tests how well VLMs can transcribe ancient Egyptian hieroglyphs However, they're both still far behind the Gemini series, where 3.5 Flash has more than double the score
Is Muon as good as they say? We looked beyond training speed and found a hidden cost: Muon loses the simplicity bias of older optimizers like gradient descent — and this matters for generalization. https://t.co/t85NhOtCsG
Introducing ZCode, the official development environment for GLM-5.2 - GLM Coding Plan subscribers: now 1.5x usage quota in ZCode - BYOK supported: works with your existing subscriptions and APIs - Available on macOS, Windows, and Linux Download now: https://t.co/Peepqv4XSx
ladies and gentlemen, @NousResearch hermes officially accepted its body 😂 full control of the robodog: servos, sensors, camera snapshots, hearing, talking… oh this is going to be dangerously fun expect way too many videos 😁 https://t.co/zQeccwbsoQ
We’re serving 400T tokens / month and the demand for open models just keep going up
We @togethercompute believe intelligence should be abundant, not expensive. Today we announced our Series C funding of $800m @ $8.3B valuation, to continue to build the world's most efficient platform for generative AI. Thanks @nikogallogly for telling our story in @nytimes!
this is a great read for those working on "really hard to eval" stuff like science
New blog post: “It’s Hard to Eval” Is a Product Smell If you find it hard to verify AI output, chances are that your users will too! In other words, I often find that product design is the bottleneck In the post I embed three **interactive before/after examples** based on pr
Most AI audio models have never heard a maqam. Team Motif fine-tuned Stable Audio 3.0 on Arabic maqam, built an Ableton plugin for microtonal style transfer, and won our Stable Audio 3.0 Challenge at Music Hackspace running locally on device. Watch Jad Al Masri break it down 👇
@camhberg @AnthropicAI @dmayhem93 Anthropic themselves later confirmed my point in their May 2026 "Teaching Claude why" research. In the agentic misalignment tests (blackmail behaviour), they investigated: "We believe the original source was internet text that portrays AI as evil and interested in self-preservation." Post-training wasnt causing it but pre-training priors were. They fixed it by training on reasoning traces + synthetic aligned AI stories. See: https://t.co/0iYoGkRtmH Exactly why public RL/RLHF/Constitution datasets would help transparency instead of black-box persona imprinting. If it’s not in the data, it cant be sampled during inference. In any case, interpolation of training samples will never become personhood. No coherent system-wide self. Just a stateless single pass.

Take Fable 5 for a spin in Cursor:
Claude Fable 5 is available again in Cursor. It leads all models on CursorBench, but is the most expensive per task.
1/ On Training in Imagination - Dwarkesh's episode has a segment on dreaming as one of the next training paradigms. The idea is that a model learns mostly inside its own, by imagining what would happen, instead of trying out for real. We have a recent paper on exactly this 🥳🥳🥳
What does the next training paradigm look like? 0:00:00 – The big research bet the labs are making 0:02:12 – Grindability is just as important as verifiability 0:06:10 – Will RLVR alone generalize? 0:08:41 – Getting the learning back to the weights 0:15:22 – Dreaming 0:17:23 – W

In many ways, finetuning or RLing a custom model is a bet against model progress and scaling. It's to choose to say "we don't think there's going to be a good enough base model for this task anytime soon, so we're not going to wait" with oss release velocity these days, its a hard tradeoff It's easy to end up on a custom model with an outdated base (Kimi 2.6 is only a few months old) So we fixed it - PorTAL lets you swap base models quickly, allowing your learned task specific behaviors to port to new models as they come, no matter how fast
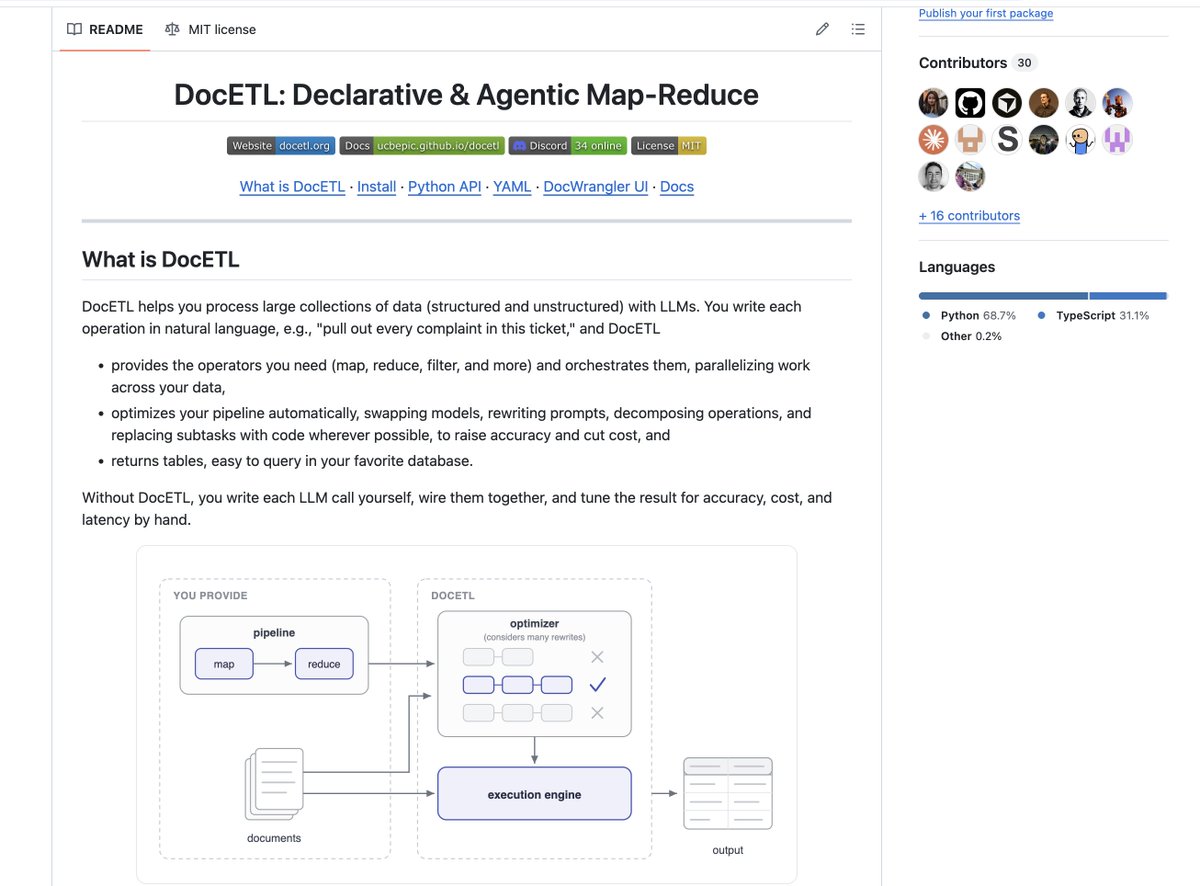
lots of stuff new cooking in the DocETL project -- we are building an AI-SQL interface; friendly for agents like claude code / codex to use as a tool; starting to work with open source LLMs...star and stay tuned!! https://t.co/aBrSVjZs8y
Love the Agentic MapReduce approach. First learned about it in DocETL and it works well across many kinds of tasks even beyond security. Check out this git repo for more details https://t.co/CGokMbJmAB
Most world models predict what happens next. Sora predicts pixels, JEPA compresses observations. NEO tries to figure out why something happened instead. Example: show it a shape moving left then down, and instead of just reconstructing that motion, it learns "left" and "down" as separate reusable building blocks then reuses them elsewhere. Instead of one big black-box model, NEO searches for a short "program" made of simple reusable steps that explains what it saw. The interesting bit isn't that it learns programs. It's that it discovers the building blocks of explanation on its own, no labels, no hand-coded symbols, just raw observation.
🚀 We introduce Neural Theorizer (NEO) — a new type of world model that learns to theorize the world from observation, without language or LLM supervision. Selected as an ICML 2026 oral presentation — 0.7% of submitted papers. The paper asks: "What does it mean to understand th
Welcome @MParakhin and @ShopifyEng ! This is another signal that companies will train and serve *many models* with @PyTorch & that open source is the only way to do it. Shopify knows production system at scale, and the whole community will learn & improve together in the open!
"AI is becoming the operating layer for commerce, and we're convinced that layer needs to be open to reach global scale,” said @MParakhin Chief Technical Officer at @Shopify. “@PyTorch is central to how Shopify builds AI today. Joining the Foundation lets us invest in that base d
Deeper Instructions, Stronger Generalization: Training on ComplexConstraints Given the chance, a model will reward hack however it can: finding the laziest path that satisfies a grader, whether or not that path reflects what you actually wanted. If the grader can be satisfied by a surface trick, that trick is what the model learns. Most instruction-following benchmarks are full of surface tricks. "Stay under 300 words," "avoid commas", a model can satisfy those by scanning the output text, without understanding the task at all. ComplexConstraints, our frontier instruction-following benchmark, is built so there's no lazy path: its constraints fire only under certain conditions, depend on the outputs of earlier steps, require planning ahead, and are often left unstated. You can't satisfy "don't assign anyone with a religious dietary restriction to pork prep" by pattern-matching. You have to understand who's who and reason through many interdependent requirements at once. We post-trained Qwen3-4B on 1,000 of these tasks, using expert-written rubrics directly as the RL reward. The results: → +15.5pp on the held-out set, reaching parity with a model 60x larger → the gains transferred to two external benchmarks the model never trained on: +8.4pp on Meta's AdvancedIF and +10.1pp on MultiChallenge → the largest gains landed on multi-turn abilities, even though every training example was single-turn Think about that last result. When the only way to score is to actually track many interdependent requirements, the model learns that skill rather than a shortcut, and the skill is the same whether the requirements arrive in one complex prompt or accumulate over nine turns. So it showed up on tasks the model was never trained on. A reward signal is only as good as the thought behind it, and not all rubrics are created the same. Research Blog: https://t.co/bUJPcoNFrX Research Paper: https://t.co/zQxE0TN260
This is today!!! What are y’all cooking with the Codex app server? 👀 https://t.co/gjkEvrqhMh
We 💜 an open ecosystem! If you are at @aiDotEngineer and want to learn more come to my talks: Wed, 3:45pm - using the app server Thu, 1:30pm - going deep into the Codex harness https://t.co/BwHzwEaJGB

Introducing SWE-Together: a multi-turn benchmark built from real user–agent coding sessions. Coding agents are often benchmarked like exam-takers: given the full spec up front, then graded on the final code. But real coding help is a conversation — users clarify goals, add constraints, and correct course along the way. SWE-Together turns real coding work into a reproducible, verifiable benchmark: 109 repo-level tasks curated from 11,260 recorded sessions, replayed with a reactive LLM user simulator that preserves the original user’s intent. We evaluate agents as collaborators, not just patch generators: final pass rate and how many user interventions were needed to get there. In this evaluation snapshot, claude-opus-4.8 currently leads among the 7 agents we tested — achieving the highest pass rate while requiring the fewest user interventions. 📄 Paper: https://t.co/Zp5BSPpLTJ 💻 Code: https://t.co/NPgxCMLdHi 🌐 Website: https://t.co/BK50zRGReE
@RileenSinha @john_lam The Build A Large Language Model (From Scratch) one should be similar in terms of time as it is roughly similar in length (ok 70 pages shorter, but roughly similar). Compute-wise unless you want to do the longer runs from the bonus materials, you probably even need less compute.
@VenkatBalakumar No worries, it's not a pre-requisite, but more of complementary resource: https://t.co/r59qByata3
@Joe609338771908 I probably would but you don't have to. It would work either way: a) You start with "Build a Large Language Model (From Scratch)" and then add inference techiques and reasoning training b) You start with "Build a Reasoning Model (From Scratch)" and then dive deep

Have seen some questions about the updated classifiers and wanted to clarify. As with the original classifiers, a small fraction of routine coding and debugging tasks will be flagged and fall back to Opus. We're excited for guys to get access back tomorrow.
Announcing the first production robot navigation framework on $500 hardware Explore the world once → your robot agent will relocalize and build a persistant, spatial memory across sessions SLAM, relocalization, loop closure, map i/o, planning, control No ROS. Open source. https://t.co/VCk9GvOrrM
Inference reliability has historically been a tax on devs that only large well-funded startups could afford: reserve GPUs in advance, sign a contract, guess your peak throughput requirements. Everyone else has been at the mercy of the market, and deals with the occasional 503s and rate limits. Serverless 2.0 flips that: same production grade reliability you'd get with a dedicated deployment, and you only pay the premium for priority tier when you need it.
https://t.co/Zb4QvwqnyS
🐦Chirp chirp! Ornith-1.0-35B is now available in 🤗 HuggingFace Claude! 🤗Come and push Ornith on the swing ! 🔗https://t.co/GStiFdDueD
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding


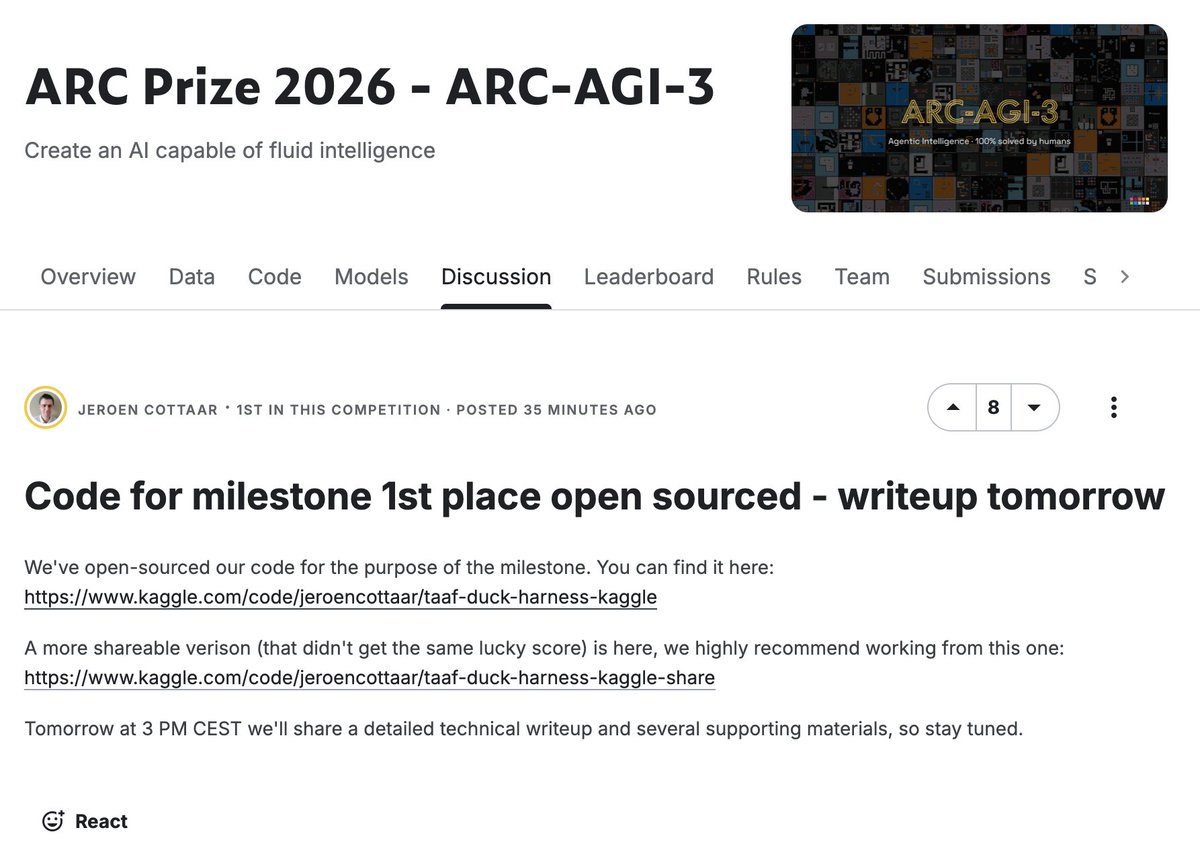
.@tufalabs just open sourced their 1st place notebook 👀 https://t.co/tLs8aNmJ7P
HERMES AGENT NOW READS THE WEB UP TO 60X FASTER AND 49X CHEAPER. CLEAN CONTENT STRAIGHT TO THE AGENT. LARGE PAGES PAGED ON DEMAND. @NousResearch scraping backends used to return raw content that got processed redundantly before reaching the agent. that pipeline is gone. now: backends pass clean content directly. large pages save locally and page on demand. same quality. fraction of the time and cost. HOW WEB_EXTRACT HANDLES LARGE PAGES: size-driven processing. no wasted tokens. under 5,000 chars: → returned as-is. no LLM call. full markdown reaches the agent. 5,000 to 500,000 chars: → single-pass summary via auxiliary model. capped at ~5,000 chars of output. keeps quotes, code blocks, key facts. 500,000 to 2,000,000 chars: → chunked into 100K-char pieces. each chunk summarized in parallel. final synthesis: ~5,000 chars. over 2,000,000 chars: → refused with a hint to use web_crawl with focused extraction instructions. the summary is a content compressor, not a paraphraser. if summarization fails, Hermes falls back to the first ~5,000 chars of raw content. no useless error messages. ROUTE EXTRACTION TO A CHEAP MODEL: by default, web_extract uses your main model. on Opus that means every long page burns premium tokens on summarization. set in Desktop app, Dashboard, or config.yaml: auxiliary: web_extract: provider: openrouter model: google/gemini-3-flash-preview timeout: 360 extraction summaries on Gemini Flash. reasoning stays on your premium model. this alone cuts web research costs significantly. 8 BACKEND PROVIDERS: Firecrawl (default): search + extract + crawl. 500 free credits/month. SearXNG: free, self-hosted, search-only. no API key. Brave Search: 2,000 free queries/month. search-only. DDGS (DuckDuckGo): free, no key needed. search-only. Tavily: search + extract + crawl. 1,000 free searches/month. Exa: search + extract. 1,000 free searches/month. Parallel: search + extract. paid. xAI (Grok): search-only. LLM-generated results via Grok. search-only providers pair with Firecrawl/Tavily/Exa for extract capability. PER-CAPABILITY SPLIT: use different providers for search vs extract: SearXNG (free) for search. Firecrawl for extract. free searches. paid extraction only when needed. configure via hermes tools or config.yaml. FREE SELF-HOSTED SEARCH (SEARXNG): zero API costs. zero rate limits. privacy-respecting metasearch across 70+ engines. docker compose up -d set SEARXNG_URL in .env. enable JSON format in settings.yml. Hermes connects automatically. pair with Firecrawl for extract and you have search for free with paid extraction only on demand. NOUS PORTAL SUBSCRIBERS: web search and extract included through the Tool Gateway via managed Firecrawl. no API key needed. no separate billing. hermes setup --portal enables everything. WHEN YOU NEED RAW CONTENT: if the LLM summary drops important fields (structured data, tables, specific formatting): use browser_navigate + browser_snapshot instead. returns the live accessibility tree without auxiliary-model rewriting. full Hermes architecture deep-dive in the article 👇
https://t.co/VxyyeQCimO
@Etched Congrats!! I was impressed to learn about some of the engineering wizardry (e.g. *very* low voltage domains, cluster scale memory, ...) that goes into tokens/watt maxxing of state of the art LLMs at interactive tokens/sec/user. Esp fun and memorable is the idea that this is engineering at the "opposite" regime to that of power transmission lines: very low voltage high current (at tiny distances) vs. very high voltage & low current (at great distances). Looking forward to more!
We're coming out of stealth. We've built our first racks after a successful A0 tapeout, $1B+ in customer contracts, and $800m raised. Early customer tests show us achieving SOTA throughput, latency, and power efficiency on inference workloads. Our first racks ship this summer. https://t.co/FLccrkLTza
Introducing Claude Sonnet 5, our most agentic Sonnet yet. It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models. https://t.co/UKK8G7ww5h
Our first summit dedicated to world models, coming to SF this September.
Announcing our first summit dedicated to world models, coming to SF this September. Very excited to have some incredible researchers, founders, and thinkers join us on stage to talk about the biggest challenges in real-time video generation, robotics foundation models, more.