Your curated collection of saved posts and media
This is such a big pain point where Im surprised they haven't tackled this yet. We desperately need some form of account-level configuration for skills, mcps, settings that sync across devices and between desktop and CC @bcherny
anthropic should add a simple feature to sync skills between claude chat, claude cowork and claude code and between teams i see how much people are struggling with this
We don’t generate videos. 🎬 We generate worlds from videos. 🌍 Introducing InSpatio-World — the world's first open-source real-time 4D world model‼️ Your input: a video clip Our output: a dynamic, navigable, persistent world 🕹️ explore freely across viewpoints ⏪ control time forward and backward 🔓 open-source and ready to build on :) Live demo: 🔗 https://t.co/nqU4ZZSqOH Code & weights: 🔗 https://t.co/rNMilkvKUV Project page: 🔗 https://t.co/WfMjYGbfzq
AI coding tools are getting better, but still make mistakes in about one out of four cases, especially on structured tasks. The shift isn’t that developers are replaced, but that they become reviewers of machine-generated code. If speed increases but errors persist, does debugging become the real bottleneck in software development? https://t.co/cGayryq2bo @UWaterloo @techxplore_com
Review of Perplexity Computer with ten different example apps built by Computer https://t.co/Si8Rbc4e60
You can vibe design some incredible interfaces with @stitchbygoogle
@OfficialLoganK @thorwebdev Built in tools working with function calling is huge!! So excited to try it out
Perplexity Computer wins hands down over Claude Code and Codex, even with their latest versions. The outputs are 5x-10x better for some use cases. @perplexity_ai - can you please launch a desktop app and a CLI?
In Marin, we are trying to get really good at scaling laws. We have trained models up to 1e22 FLOPs and have made a prediction of the loss at 1e23 FLOPs, which @WilliamBarrHeld is running. This prediction is preregistered on GitHub, so we'll see in a few days how accurate our prediction was. What we want is not just a single model but a training recipe that scales reliably.
I'll be speaking @ AI Engineer Melbourne on "Legacy Software + Agentic Discovery". I’ll be sharing practical lessons from large-scale reverse-engineering projects: - recovering intent from code - where humans still matter most - what high-quality spec generation might look like ... and when I say large, I mean 12M+ LOC. ... and when I say legacy, I mean 25+ years old. --- 3-4 June 2026, Federation Square Melbourne & Online. Sharing the stage with some rad humans including @swyx, @GeoffreyHuntley, @jeremyphoward and stacks more. 🔗 Tix && discount link: https://t.co/UDQFbOyQSB Huge thanks @aiDotEngineer & @johnallsopp
Introducing the Daily Papers SKILL.md Enables agents to > read paper content as markdown > search papers > find linked @huggingface models and datasets > fetch the papers API > and more! Link below ⬇️ https://t.co/AV4cXFIOht
Thinking in Uncertainty Introducing LEAD, a training-free decoding strategy that mitigates hallucinations in multimodal reasoning models. It dynamically switches between latent reasoning during high-entropy states and discrete decoding when confidence is high, while injecting visual anchors at uncertain steps.
You can vibe design some incredible interfaces with @stitchbygoogle
Introducing the new @stitchbygoogle, Google’s vibe design platform that transforms natural language into high-fidelity designs in one seamless flow. 🎨Create with a smarter design agent: Describe a new business concept or app vision and see it take shape on an AI-native canvas. ⚡
The bottleneck for most large open model deployments isn't the model. It's everything around it. Slow first-token latency, unstable tail latency, GPU utilization that falls apart under load, and the operational complexity of keeping it all running. That's the problem we've been solving. DeepSeek V3.1, state-of-the-art throughput, low latency, fully managed on MAX and Mojo 🔥 on NVIDIA Blackwell GPUs. Come get a first look at @NVIDIAGTC, Booth #3004
Mamba-3 is out! 🐍 SSMs marked a major advance for the efficiency of modern LLMs. Mamba-3 takes the next step, shaping SSMs for a world where AI workloads are increasingly dominated by inference. Read about it on the Cartesia blog: https://t.co/dIWg3iXfay
Heygen’s APi documentation is a glimpse of how to write for your two audiences: humans and agents. (though I think their llms.txt file could do a lot more to get AIs “excited” to use their product in creative ways by explaining some stuff in English, rather than just tech specs) https://t.co/H8A5DkGEbI

@milesdeutscher A deeper technical examination of why narratives around autonomous AI agent workforces are failing to materialise, particularly due to limitations in reliability, coordination, and real-world robustness. https://t.co/pocfimUlD2
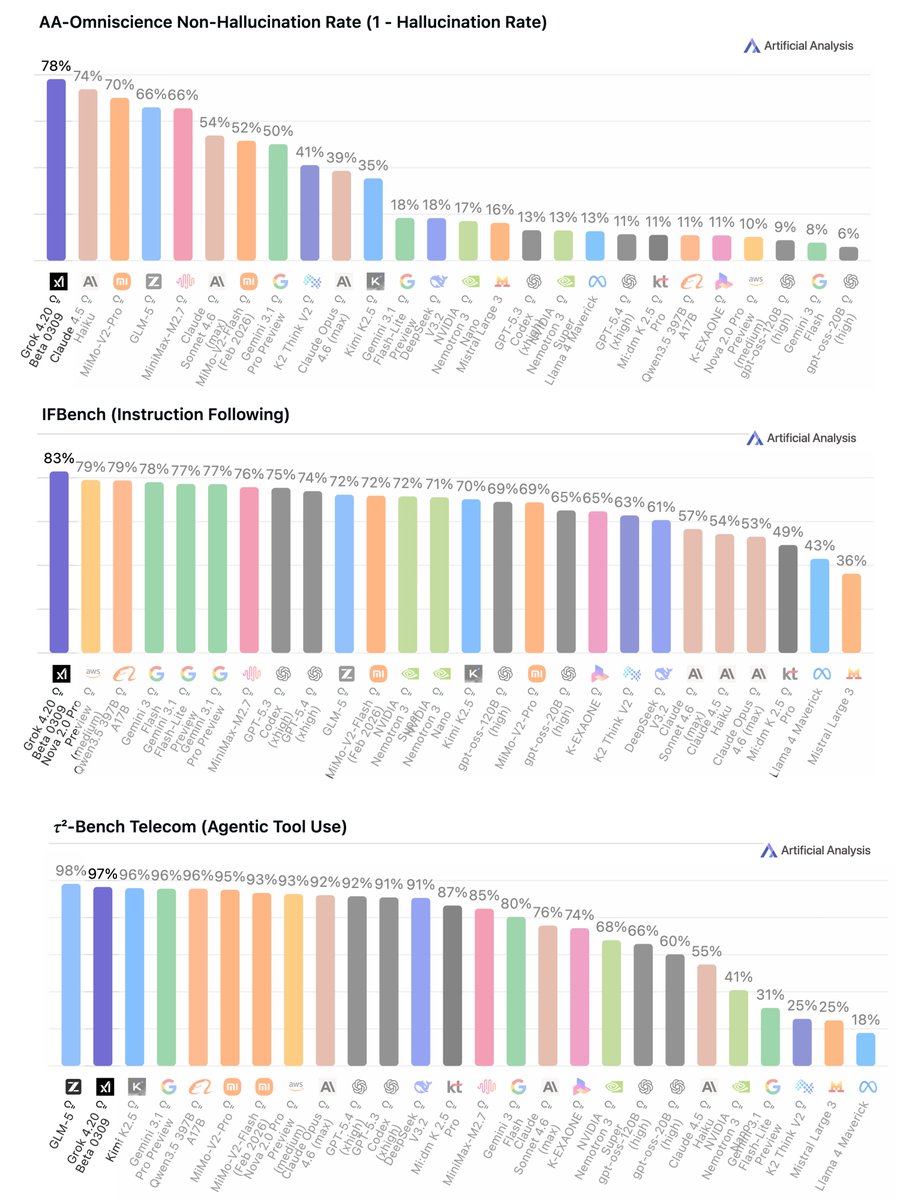
The new Grok 4.20 Beta benchmarks are wild 🥇 #1 lowest hallucinating AI (22%) 🥇 #1 at following instructions (83%) 🥈 #2 in agentic tool use (97%) Grok 4.20 ranks #1 in the lowest hallucination rate ever recorded across all AI models tested globally Most models race to sound smart. Grok 4.20 was built to never lie and still dominates on instruction following and agentic tasks This is literally a 500B model performing top-notch in the things that matter most
CDS PhD student @KuangYilun, CDS founding director @ylecun, former CDS Faculty Fellow @timrudner, and others successfully applied biological sparsity to AI. Their new technique allows computer vision models to ignore 90% of data without losing accuracy. https://t.co/yYx1sHsB5V
By popular demand, Dispatch can now launch Claude Code sessions. Ask it to build, make, or improve something! To use it, update your Claude desktop app and make sure you have Code enabled. https://t.co/q65MyqkUJN
Different AI models find different bugs. So why not use all of them? Try this out in Copilot CLI: 1. Run /review 2. Ask it to use multiple model providers at once for a multi-agent code review 3. Get the highest possible signal and catch bugs before anyone else @_Evan_Boyle shows how it's done. ▶️ https://t.co/TWNzPBFcmC
🔥 Meet Mistral Small 4: One model to do it all. ⚡ 128 experts, 119B total parameters, 256k context window ⚡ Configurable Reasoning ⚡ Apache 2.0 ⚡ 40% faster, 3x more throughput Our first model to unify the capabilities of our flagship models into a single, versatile model. https://t.co/2M1VNaDkRz
Introducing Unsloth Studio ✨ A new open-source web UI to train and run LLMs. • Run models locally on Mac, Windows, Linux • Train 500+ models 2x faster with 70% less VRAM • Supports GGUF, vision, audio, embedding models • Auto-create datasets from PDF, CSV, DOCX • Self-healing tool calling and code execution • Compare models side by side + export to GGUF GitHub: https://t.co/2kXqhhvLsb Blog and Guide: https://t.co/ENuTWal5AA Available now on Hugging Face, NVIDIA, Docker and Colab.
Here's the GitHub issue with all the details: https://t.co/fYre7BLjv6 This is part of our Delphi suite, a "modernized" version of Pythia: https://t.co/9G6NiADnMo
For trying to understanding LMs deeply, @AiEleuther’s Pythia has been an invaluable resource: 16 LMs (70M to 12B parameters) trained on the same data (The Pile) in the same order, with intermediate checkpoints. It’s been two years and it’s time for a refresh.

Context engineering is the new prompt engineering — and if you're building AI agents, you need to understand the difference and why parsing your data correctly sits at the heart of it Andrej Karpathy put it well: context engineering is "the delicate art and science of filling the context window with just the right information for the next step." It's not just about the instructions you give an LLM. It's about what you put IN front of it. That context can come from a lot of places: — System prompts — Chat history & long-term memory — Knowledge base retrieval — Tool definitions & responses — Structured outputs One of the most underrated levers? Structured information. This is exactly what LlamaParse + LlamaExtract are built for. Parse your complex documents properly → extract structured, relevant fields → pass clean, dense context to your agent. Better parsing = better context = better agents. It really is that simple. Take a look back on a piece by @tuanacelik and @LoganMarkewich about the full breakdown: what context engineering is, what makes up context, and the key techniques to consider — from memory blocks to workflow engineering. Read it here 👇 https://t.co/fE6cuzDJMj


Interesting that it was @grok that did the final science heavy lifting in the man cures dog's cancer with AI story. Grok corrected errors in the vaccine construct missed by Gemini Full pod down in the replies https://t.co/V5WjaQ9m7q
started a crowd-sourced list of all libraries and applications that use the HF hub local cache (~/.cache/huggingface) here: https://t.co/L8FNRvonm4 Please add any missing ones! PRs are welcome https://t.co/8oaFCqd7H1
We’re excited to share Generalized Dot-Product Attention (GDPA) — a production-driven attention kernel designed specifically for large-scale recommendation systems (RecSys). Proposed in our recent paper, GDPA replaces softmax with a flexible activation tailored for real-world RecSys traffic patterns and has been deployed in Meta’s largest recommendation model, GEM. 🔗 Read our latest blog: https://t.co/YxePbndHlP By redesigning attention around production characteristics rather than benchmark assumptions, GDPA achieves 2× forward speedup (1,145 BF16 TFLOPs, ~97% tensor core utilization), 1.6× backward speedup, and up to 3.5× forward speedup vs. FA4 under short K/V settings on NVIDIA B200. This work demonstrates how real production traffic can fundamentally reshape kernel design. ✍ Jiaqi Xu, Han Xu, Junqing Zhou, Devashish Shankar, Xiaoyi (Leo) Liu, Shuqi Yang #PyTorch #OpenSourceAI #GDPA #GEM

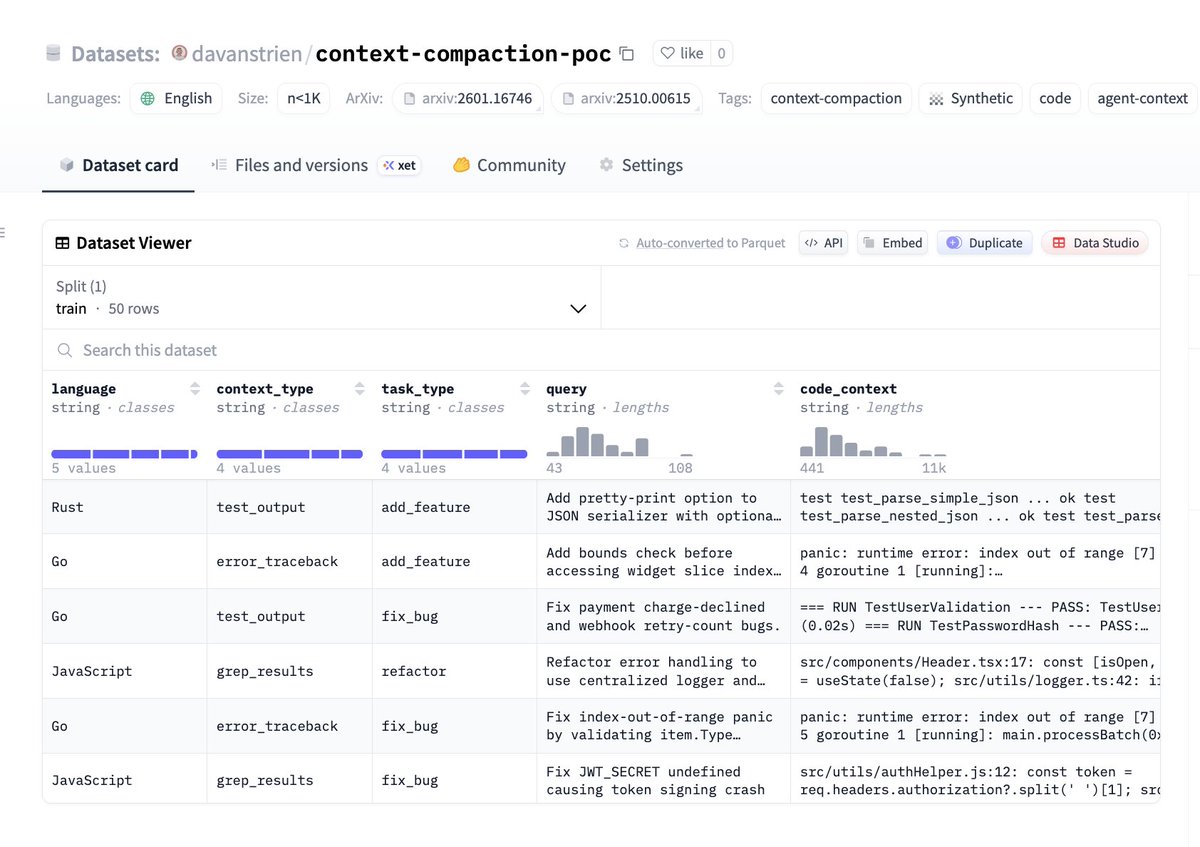
First attempt at replicating an open dataset to help train an open context compaction model. Claude Code did this one using @nvidia NeMo DataDesigner + @huggingface Inference Providers (Kimi-K2 via @GroqInc). Hopefully someone else (or their agent) can do a better job! https://t.co/8nqewxZpTm
Who's going to create an open dataset and model for this task and share it on @huggingface?
DLSS 5 is wild... AI maxed... Demo in comment https://t.co/Bt8HZdXfWD
DLSS-5 anything for free app: https://t.co/Pj3jeFVnL6 https://t.co/b6EhE5lwk5

One of the hardest problems in robotics isn’t movement — it’s manipulation. This demo shows adaptive switching between left and right robotic hands, allowing the system to decide which hand should take over a task in real time. Human-like dexterity is what will finally bring AI from software into the physical world. 🤖 via Takayuki Yamazaki #Robotics #AI #Humanoid #Automation
LlamaParse Agentic Plus mode now delivers precise visual grounding with bounding boxes for the most challenging document elements. Our latest update brings major improvements to how we handle complex visual content: 📐 Complex LaTex formulas - accurately parse mathematical expressions with precise positioning ✍️ Handwriting recognition - extract handwritten text with location coordinates 📊 Complex layouts - navigate multi-column documents and intricate formatting 📈 Infographics and charts - identify and extract data visualizations with spatial context This means you can now build applications that not only extract text from documents but also understand exactly where that content appears on the page - perfect for creating more intelligent document analysis workflows. Try LlamaParse Agentic Plus mode and see how visual grounding transforms your document parsing capabilities: https://t.co/yPVJzqoKal
