Your curated collection of saved posts and media
A knowledge-work platform built around GPT-5.4 Pro level intelligence would be really useful. The gap between other models and what Pro can do on complex intellectual work remains stark. I would love to have access in a Codex-like platform with shared file spaces, subagents, etc
Another great post on how to leverage agent skills. I use over a 100+ skills already. The hard part is understanding how to keep them relevant and optimized.
Another great post on how to leverage agent skills. I use over a 100+ skills already. The hard part is understanding how to keep them relevant and optimized.
https://t.co/45C3gKydTK
Grounding World Simulation Models in a Real-World Metropolis paper: https://t.co/yGrI2F67ej https://t.co/S56BAql8Ka

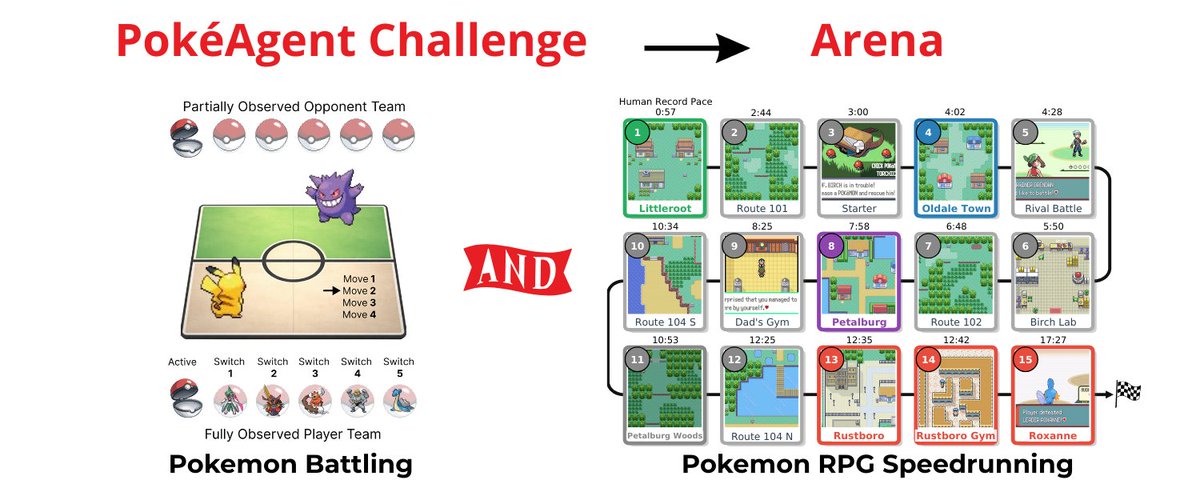
The PokeAgent Challenge Competitive and Long-Context Learning at Scale paper: https://t.co/TrTvHiI3tC https://t.co/jhzZSPVj5Y

Now that I’m using both Claude and Codex daily, I’m seeing that Claude tries to “cheat” more often, eg deleting a failing test. What’s your experience?
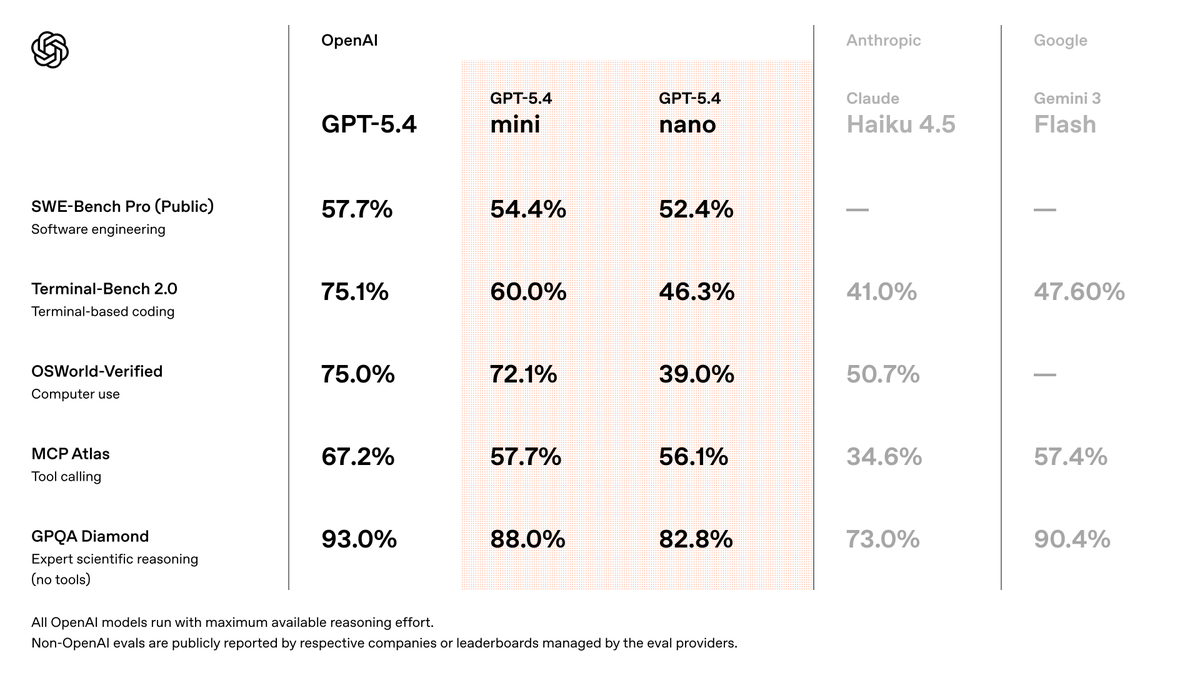
GPT-5.4 mini is available today in ChatGPT, Codex, and the API. Optimized for coding, computer use, multimodal understanding, and subagents. And it’s 2x faster than GPT-5 mini. https://t.co/DKh2cC5S3F https://t.co/sirArgn37L
There are a bunch of areas where inference-efficient architectures make a huge difference (e.g. RL training where 80% of the time is spent on large batch, long sequence rollout). Lots to do on both the algorithms and systems side to realize the potential benefits of these new architectures! Check out the threads from the students who led this project: https://t.co/7jG3beI9Sj https://t.co/i685cnZrZ7 https://t.co/X7pd2VQ6e3 https://t.co/rQ9DwKT6KS 10/10
Now that I’m using both Claude and Codex daily, I’m seeing that Claude tries to “cheat” more often, eg deleting a failing test. What’s your experience?
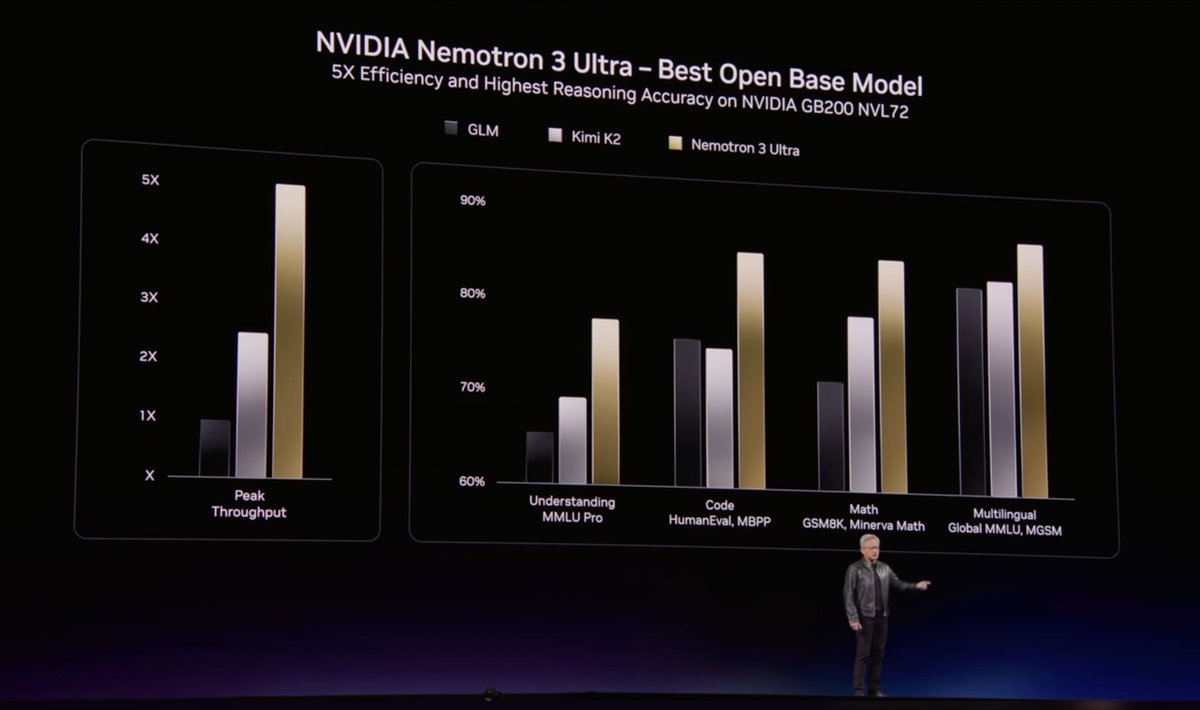
Now that inference throughput is what’s driving agents’ progress (hopefully you caught Jensen’s keynote 😀), we’ll continue to make Mamba stronger and faster. Some fun stuff in the pipeline: new algorithms and kernels to make Mamba forward 3-4x faster and backward 2x faster. Hopefully will be out in 1-2 months, as soon as I can convince Claude to finish all the implementations. My new strat is just whispering to Claude “make it faster…” over and over 9/10 
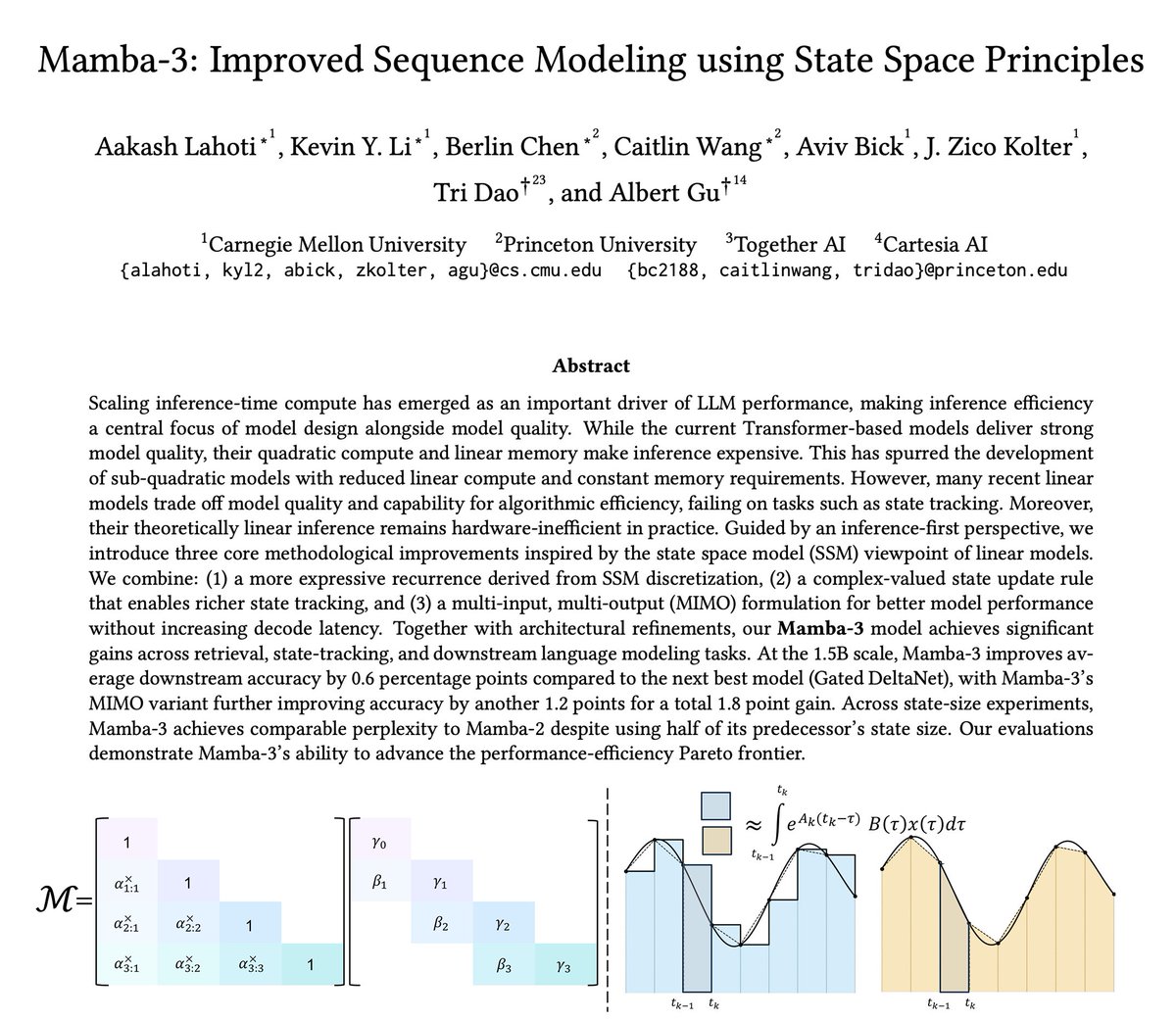
The newest model in the Mamba series is finally here 🐍 Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models. We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes. This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!
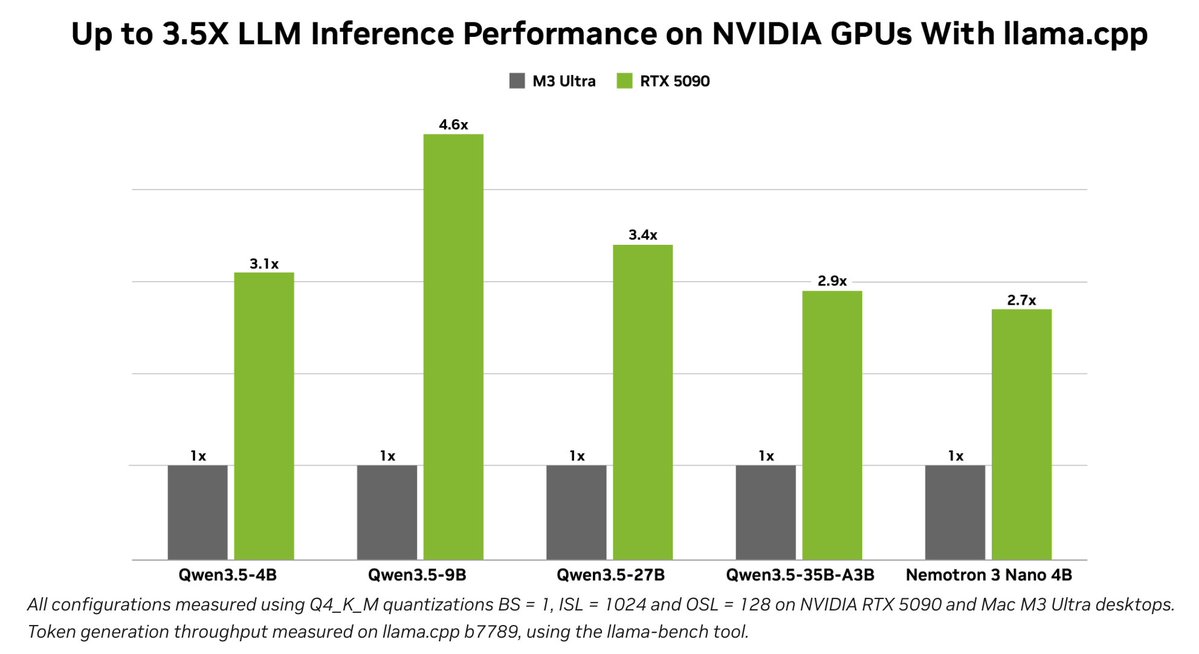
With Nemotron 3 Nano 4B in the NVIDIA Nemotron 3 family, llama.cpp users get a compact model for action-taking conversational personas, available across NVIDIA GPU-enabled systems and @NVIDIA_AI_PC https://t.co/WS2BRzS5Aa
One of the hardest problems with document parsing is trust. How do you know the output actually corresponds to what's in the source? LlamaParse has visual grounding with bounding box citations for outputs, and it addresses exactly this. Two ways to use it: 1️⃣ In the UI: hover over any element in the markdown output and it highlights the exact region it came from in the original document. Great for spot-checking complex tables, multi-column layouts, or figures where parsing can be tricky. 2️⃣ In the JSON output: every parsed element carries bounding box coordinates, i.e. the precise location of that element within the source file. That means you can build applications that don't just surface an answer, but can point back to exactly where in a document it came from. For due diligence, where auditability matters, this is a step up from "trust the output." You can verify it, cite it, and build on it. Sign up to LlamaParse to get started: https://t.co/yPVJzqoKal
🚀 Live from @NVIDIAGTC, we're releasing Holotron-12B! Developed with @nvidia, it's a high-throughput, open-source, multimodal model engineered specifically for the age of computer-use agents. Get started today! 🤗Hugging Face: https://t.co/oaSviLi8IN 📖Technical Deep Dive: https://t.co/pDItQB1frU 💼We are hiring: https://t.co/fcNoR9FIYQ #AI #ComputerUse #NVIDIA #OpenSource #ReinforcementLearning #HCompany #GTC @NVIDIAAI @nvidia
Two weeks after sharing @adaption_ai adaptive data, we are excited to share our work on blueprint 📘 blueprint steers data towards your goals, and learns penalties if AI violates any of your rules. Very proud of the team.
Yes! The “are you sure?” problem (link below) is especially pervasive in any complex coding task. Ask Claude or GPT to review a PR then ask it to double check its findings when it finishes - it’ll flip on at least 1 of its findings. https://t.co/WUSuOxTuDy
Yes! The “are you sure?” problem (link below) is especially pervasive in any complex coding task. Ask Claude or GPT to review a PR then ask it to double check its findings when it finishes - it’ll flip on at least 1 of its findings. https://t.co/WUSuOxTuDy
One thing that makes me feel that code factory has not arrived yet is the following experiment: 1.Ask a LLM to do an in-depth rigorous review of your code 2. In a new thread, as same/different LLM to consider those review comments independently and address issues it agrees with

🔎A closer look at Omnilingual No Language Left Behind, the encoder-decoder system presented as part of @AIatMeta new Omnilingual Machine Translation work!🌍 Many say encoder-decoder is dead in the age of decoder-only LLMs but we show it’s not! 📄:https://t.co/isvEzRZbnw 🧵1/n https://t.co/RLs8ncUy0H
In our paper "Towards a Science of AI Agent Reliability" we put numbers on the capability-reliability gap. Now we're showing what's behind them! We conducted an extensive analysis of failures on GAIA across Claude Opus 4.5, Gemini 2.5 Pro, and GPT 5.4. Here's what we found ⬇️ https://t.co/GkdAxk0wDO
Current vision-language models still struggle with simple diagrams. Feynman is a knowledge-infused diagramming agent that enumerates domain-specific concepts, plans visual representations, and translates them into declarative programs rendered by the Penrose diagramming system. Great insights for those building agents for diagrams and visualizations. One pipeline run produced 10,693 unique programs across math, CS, and science, each rendered into 10 layout variations, yielding over 106k well-aligned diagram-caption pairs. Paper: https://t.co/F4vNS0TII4 Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
One thing that makes me feel that code factory has not arrived yet is the following experiment: 1.Ask a LLM to do an in-depth rigorous review of your code 2. In a new thread, as same/different LLM to consider those review comments independently and address issues it agrees with 3. Keep repeating until no new concerns I find that this loop always goes on for a ridiculously long time, which means that there is a problem with the notion of claude-take-the-wheel. This seems to happen no matter the harness or the specificity of the specs. It works fine for simple applications, but in the limit if the LLMs have this much cognitive dissonance you cannot trust it. Either this, or LLM are RLHFd to always find some kind of issue.
🔎A closer look at Omnilingual No Language Left Behind, the encoder-decoder system presented as part of @AIatMeta new Omnilingual Machine Translation work!🌍 Many say encoder-decoder is dead in the age of decoder-only LLMs but we show it’s not! 📄:https://t.co/isvEzRZbnw 🧵1/n https://t.co/RLs8ncUy0H
Current vision-language models still struggle with simple diagrams. Feynman is a knowledge-infused diagramming agent that enumerates domain-specific concepts, plans visual representations, and translates them into declarative programs rendered by the Penrose diagramming system. Great insights for those building agents for diagrams and visualizations. One pipeline run produced 10,693 unique programs across math, CS, and science, each rendered into 10 layout variations, yielding over 106k well-aligned diagram-caption pairs. Paper: https://t.co/F4vNS0TII4 Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX


This is one of the most impressive world model projects I have seen. Very elegant and highly effective combination of an image retrieval mechanism (using 3D locations/views) and otherwise just pure generative modeling. This is the way.
What if a world model could render not an imagined place, but the actual city? We introduce Seoul World Model, the first world simulation model grounded in a real-world metropolis. TL;DR: We made a world model RAG over millions of street-views. proj: https://t.co/Bx4KUAqrRs ht
... and a follow-up chapter about Subagents, now a feature of Codex and Claude Code and Gemini CLI and Mistral Vibe and OpenCode and VS Code and Cursor https://t.co/suGmK4g3Hp
i dj'd a set this weekend and planned half of it with an app i built on @GoogleDeepMind's new multimodal embeddings model. it understands what music actually sounds like - not bpm, not genre tags. raw audio in, vibes out. built with @cursor_ai + @openai gpt 5.4, gemini embeddings and @convex to keep everything running smoothly @ericzakariasson @DynamicWebPaige @waynesutton @gabrielchua here's what it does (demo below) 🧵
i dj'd a set this weekend and planned half of it with an app i built on @GoogleDeepMind's new multimodal embeddings model. it understands what music actually sounds like - not bpm, not genre tags. raw audio in, vibes out. built with @cursor_ai + @openai gpt 5.4, gemini embeddings and @convex to keep everything running smoothly @ericzakariasson @DynamicWebPaige @waynesutton @gabrielchua here's what it does (demo below) 🧵
In our paper "Towards a Science of AI Agent Reliability" we put numbers on the capability-reliability gap. Now we're showing what's behind them! We conducted an extensive analysis of failures on GAIA across Claude Opus 4.5, Gemini 2.5 Pro, and GPT 5.4. Here's what we found ⬇️ https://t.co/GkdAxk0wDO

Tried the viral poster-skill with Claude Code on the trending Moonshot paper :) Not too bad! https://t.co/I8lb0aUrbT
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dep

Two weeks after sharing @adaption_ai adaptive data, we are excited to share our work on blueprint 📘 blueprint steers data towards your goals, and learns penalties if AI violates any of your rules. Very proud of the team.
Introducing Blueprint, a new capability within Adaptive Data. We firmly believe data that evolves with the world is only useful if it evolves the right way. Blueprint allows you to steer the data space towards any goal you want. https://t.co/8k0WEMYmdd
“Everyone should be a GPU programmer.” @clattner_llvm's goal with @Modular: “What Modular is doing is opening up the box. We’re fixing the language problem and the platform problem. "The goal is to let more developers learn modern compute. And to give developers real choice in the hardware they use.” “Those two things unlock the ecosystem.”
... and a follow-up chapter about Subagents, now a feature of Codex and Claude Code and Gemini CLI and Mistral Vibe and OpenCode and VS Code and Cursor https://t.co/suGmK4g3Hp