Your curated collection of saved posts and media
@icanvardar True, also true. Adding a domain to your CORS config that costs .5 million tokens for the entire pipeline. Crazy times.
@_talaawwad Please get more support folks…
@SalajSonar1086 Already done :). The respective tutorial articles are linked via the “View in Article” links there
VisMatch is on pypi! VisMatch is a wrapper for image matching models, like LightGlue, RoMa-v2, MASt3R, LoFTR, and 50+ more! It's literally as simple as: pip install vismatch vismatch-match --inputs img0 img1 --matcher choose_any To run image matching on any 2 images [1/4] https://t.co/dIr2YapWak
Nvidia GTC 2026 OpenClaw Setup on DGX Spark IRL https://t.co/zQwwfCF9XP
🛠️ Claude Code "opusplan" 말 그대로 하이브리드 모델.. 공식임! Claude Code에는 opusplan 모델을 선택할 수 있어요. > /model opusplan 하이브리드 모델 alias인데, 작업 단계에 따라 자동으로 모델을 전환해요. 복잡한 추론을 위한 플랜 모드에서는 Opus를 실행 단계에서는 Sonnet으로 자동 전환됩니다! Opus로 계획하고 구현까지 하는 것도 물론 가능해요. 하지만 이미 탄탄한 계획이 있다면, 실행은 Sonnet으로도 충분하고 더 저렴할 수 있어요. 각 작업에 맞는 모델을 쓰는 것 = 효율 🚀 플래닝과 실행은 요구되는 인지 부하가 달라요. Opus의 깊은 추론 능력은 계획 수립 단계에서 가장 빛나고, 일단 탄탄한 계획이 세워진 이후의 실행은 Sonnet으로 충분히 커버될 수 있어요. 언제 쓰면 좋냐구요? - 복잡한 기능 설계같이 아키텍처 결정이 중요한 작업 - 리팩토링 계획같은 영향 범위 분석이 필요한 경우 - Opus 풀파워 사용 대비 비용 절감이 필요할 때 이거 이제 많이 활용하실 듯!!!
Jensen today announced Alpamayo 1.5 at #NVIDIAGTC! #Alpamayo 1.5 is a major update to Alpamayo 1—@nvidia’s open 10B-parameter chain-of-thought reasoning VLA model, first introduced at #CES. Built on the #Cosmos-Reason2 VLM backbone and post-trained with RL, it adds support for navigation guidance, flexible multi-camera setups, configurable camera parameters, and user question answering. The result is an interactive, steerable reasoning engine for the AV community. We’re also releasing post-training scripts to help researchers and developers adapt the model. Additionally, we’ve significantly expanded the Alpamayo open platform across data and simulation, including releasing highly requested reasoning labels for the PhysicalAI Autonomous Vehicles dataset (https://t.co/fD9eUcndya), as well as our chain-of-causation auto-labeling pipeline. 🔎 Learn more about Alpamayo 1.5 and the latest extensions to the Alpamayo open platform: https://t.co/P0nuqkwBab (please note that most of the links will become active in the next few days.) Happy building—and stay tuned for more in the coming months! @NVIDIADRIVE @NVIDIAAI

🛠️ Claude Code "opusplan" 말 그대로 하이브리드 모델.. 공식임! Claude Code에는 opusplan 모델을 선택할 수 있어요. > /model opusplan 하이브리드 모델 alias인데, 작업 단계에 따라 자동으로 모델을 전환해요. 복잡한 추론을 위한 플랜 모드에서는 Opus를 실행 단계에서는 Sonnet으로 자동 전환됩니다! Opus로 계획하고 구현까지 하는 것도 물론 가능해요. 하지만 이미 탄탄한 계획이 있다면, 실행은 Sonnet으로도 충분하고 더 저렴할 수 있어요. 각 작업에 맞는 모델을 쓰는 것 = 효율 🚀 플래닝과 실행은 요구되는 인지 부하가 달라요. Opus의 깊은 추론 능력은 계획 수립 단계에서 가장 빛나고, 일단 탄탄한 계획이 세워진 이후의 실행은 Sonnet으로 충분히 커버될 수 있어요. 언제 쓰면 좋냐구요? - 복잡한 기능 설계같이 아키텍처 결정이 중요한 작업 - 리팩토링 계획같은 영향 범위 분석이 필요한 경우 - Opus 풀파워 사용 대비 비용 절감이 필요할 때 이거 이제 많이 활용하실 듯!!!
Did you know about the opusplan model in Claude Code? /model opusplan It's a hybrid alias that automatically uses Opus in plan mode for complex reasoning, then switches to Sonnet for execution. Best of both worlds: Opus thinks, Sonnet builds https://t.co/r7un0X5bVg
Subagents are now supported in Codex. They're very fun and make it possible to get large amounts of work done *quickly*:
Subagents are now available in Codex. You can accelerate your workflow by spinning up specialized agents to: • Keep your main context window clean • Tackle different parts of a task in parallel • Steer individual agents as work unfolds https://t.co/QJC2ZYtYcA
Banger report from the Kimi team: Attention Residuals Residual connections made deep Transformers trainable. But they also force uncontrolled hidden-state growth with depth. This work proposes a cleaner alternative. It introduces Attention Residuals, which replace fixed residual accumulation with softmax attention over previous layer outputs. Instead of blindly summing everything, each layer selectively retrieves the earlier representations it actually needs. To keep this practical at scale, they add a blockwise version that compresses layers into block summaries, recovering most of the gains with minimal systems overhead. Why does it matter? Residual paths have barely changed across modern LLMs, even though they govern how information moves through depth. This paper shows that making the mixing content-dependent improves scaling laws, matches a baseline trained with 1.25x more compute, boosts GPQA-Diamond by +7.5 and HumanEval by +3.1, while keeping inference overhead under 2%. Paper: https://t.co/04IG6FDiVr Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
The moment he realised that https://t.co/vWmBsnR1nt isn't fully built on transformers and we can run on a single GPU with high accuracy and lower cost https://t.co/ZJYuL62UB8

The moment he realised that https://t.co/vWmBsnR1nt isn't fully built on transformers and we can run on a single GPU with high accuracy and lower cost https://t.co/ZJYuL62UB8


Thanks for sharing our newest work @_akhaliq ! Classic algorithms like K-Means deserve to be revisited in the era of massive datasets and GPUs. Flash-KMeans rethinks the algorithm from a systems perspective to make exact K-Means fast and memory-efficient on modern hardware.
Claude Code CLI > Codex CLI Codex Desktop > Claude Code Desktop It’s a jagged UX frontier
Thanks for sharing our newest work @_akhaliq ! Classic algorithms like K-Means deserve to be revisited in the era of massive datasets and GPUs. Flash-KMeans rethinks the algorithm from a systems perspective to make exact K-Means fast and memory-efficient on modern hardware.
Flash-KMeans Fast and Memory-Efficient Exact K-Means paper: https://t.co/Yy7V7L12Bn https://t.co/c1mGipQl3f
🌐 Agentic Browser Tools (Experimental) in @code! Agents can now open pages, read content, click elements, and verify changes directly in the integrated browser while building your web app. Enable ⚙️ workbench.browser.enableChatTools to try it out. Learn mode: https://t.co/kNwugFcbIA
#NVIDIAGTC news: NVIDIA Dynamo 1.0 enters production as the broadly adopted inference operating system for AI factories. Dynamo 1.0 boosts Blackwell inference performance by up to 7x. The industry is scaling on NVIDIA. ⬇️https://t.co/Iaq2H2SmhR
#ExecuTorch addresses fragmented native deployment for #AI agents as a #PyTorch native platform. It enables voice models across CPU, GPU, and NPU on Android, iOS, Linux, macOS & Windows 🔗 https://t.co/NeQQyUniL4 https://t.co/O3itnoQFoG

VisMatch is on pypi! VisMatch is a wrapper for image matching models, like LightGlue, RoMa-v2, MASt3R, LoFTR, and 50+ more! It's literally as simple as: pip install vismatch vismatch-match --inputs img0 img1 --matcher choose_any To run image matching on any 2 images [1/4] https://t.co/dIr2YapWak

Matt Maher tested frontier models in Cursor v. other harnesses. Cursor boosted model performance by 11% on average: Gemini: 52% → 57% GPT-5.4: 82% → 88% Opus: 77% → 93% His benchmark measures how well models implement a 100-feature PRD. @cursor_ai consistently outperformed. https://t.co/hrjCmWMNKN
A new generation in AV simulation is here! We are announcing AlpaDreams, a real time interactive generative world model for AV simualtion! Just a year ago it took minutes to generate a few seconds of video, today it is real time and interactive! https://t.co/FbhKu3PMqe
Nvidia GTC 2026 OpenClaw Setup on DGX Spark IRL https://t.co/zQwwfCF9XP
Mistral Small 4 is out https://t.co/IdAowSpHpN

Love this submission from our world models hackathon this weekend - a generative FPS!
Spent the weekend hacking at the Worlds in Action hackathon at @fdotinc by @SensAIHackademy. It was so much fun playing with the world models by @theworldlabs . I believe generative games are the future where characters, rules and even parts of the world can be generated and ad
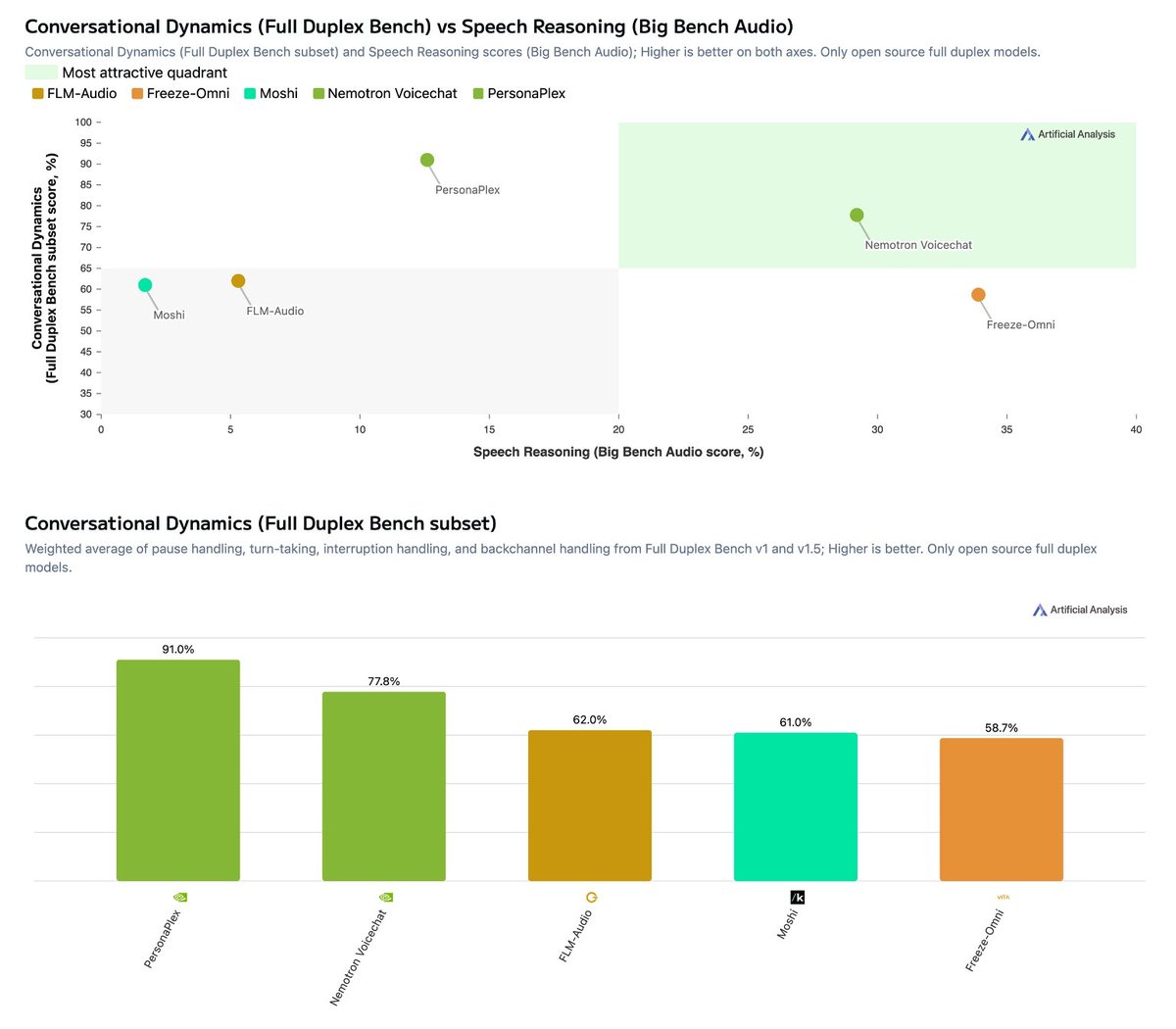
NVIDIA has released Nemotron 3 VoiceChat! A ~12B parameter Speech to Speech model that leads our open weights Conversational Dynamics vs. Speech Reasoning pareto frontier Understanding Speech to Speech model performance is multidimensional - two key and distinct dimensions are raw intelligence and conversational dynamics: how well a model handles the natural rhythms of human conversation such as turn-taking, interruptions. Amongst full duplex open weights models, NVIDIA’s new Nemotron 3 VoiceChat, V1, leads in balancing these dimensions, setting itself apart from other models on the Conversational Dynamics vs. Speech Reasoning pareto frontier. Key benchmarking results: ➤ Conversational Dynamics (Full Duplex Bench): Nemotron 3 VoiceChat (V1) scores 77.8%, second among open weights speech to speech models behind NVIDIA's own PersonaPlex (91.0%) and ahead of FLM-Audio (62.0%), Moshi (61.0%) and Freeze-Omni (58.7%) ➤ Speech Reasoning (Big Bench Audio): Nemotron 3 VoiceChat (V1) scores 29.2%, second among open weights speech to speech models behind Freeze-Omni (33.9%) and well ahead of PersonaPlex (12.6%), FLM-Audio (5.3%) and Moshi (1.7%) ➤ Pareto leader: While Freeze-Omni leads on speech reasoning and PersonaPlex leads on conversational dynamics, Nemotron 3 VoiceChat (V1) is the only open weights model that performs amongst the top 3 on both - making it the clear leader on the pareto frontier between these two critical dimensions ➤ Larger than other open weights models but still relatively small compared to LLMs: Nemotron 3 VoiceChat (V1) has 12B parameters, making it one of the larger open weights speech to speech models, while NVIDIA's PersonaPlex is ~7B. While larger compared to other larger open weights speech to speech models the model still is relatively small compared to leading LLMs ➤ Context vs. proprietary models: While this release materially advances open weights performance, open weights speech to speech models still significantly underperform leading proprietary offerings. For comparison, proprietary models on our Big Bench Audio benchmark score substantially higher - Step-Audio R1.1 at 96%, Grok Voice Agent at 92%, Gemini 2.5 Flash (Thinking) at 92%, and Nova 2.0 Sonic at 87%. The gap between open weights and proprietary remains large in this modality. As the capability and adoption of Speech to Speech models increases, we expect to expand our set of benchmarks to include elements such as tool-calling and multi-turn instruction following. See more details below ⬇️
Subagents are now available in Codex. You can accelerate your workflow by spinning up specialized agents to: • Keep your main context window clean • Tackle different parts of a task in parallel • Steer individual agents as work unfolds https://t.co/QJC2ZYtYcA
It's been about 20 years since I first started working on embeddings with Yann LeCun (siamese networks!), and I've been fascinated ever since. Gemini Embeddings 2 approaches the platonic ideal: native embedding of text, image, video, audio, and docs to a single space.
OmniForcing unlocks real-time joint audio-visual generation Achieves ~25 FPS with 0.7s latency—a 35× speedup over offline diffusion models—by distilling bidirectional LTX-2 into a causal streaming generator with maintained multi-modal fidelity. https://t.co/UGYGMyTQOs

@Nvidiadev 🗓️ MONDAY @ Booth #338 2PM: Shaping the Future w/ @matthew_d_white 3PM: TensorRT + PyTorch w/ Angela Yi & @narendasan 4PM: DeepSpeed Trillion-Param Training w/ @PKUWZP 5PM: PyTorch Export w/ Angela Yi 6PM: Ray Distributed Computing w/ @robertnishihara #AI #GTC2025
Subagents are now available in Codex. You can accelerate your workflow by spinning up specialized agents to: • Keep your main context window clean • Tackle different parts of a task in parallel • Steer individual agents as work unfolds https://t.co/QJC2ZYtYcA
Matt Maher tested frontier models in Cursor v. other harnesses. Cursor boosted model performance by 11% on average: Gemini: 52% → 57% GPT-5.4: 82% → 88% Opus: 77% → 93% His benchmark measures how well models implement a 100-feature PRD. @cursor_ai consistently outperformed. https://t.co/hrjCmWMNKN
🚨 Want to parse complex PDFs with SOTA accuracy, 100% locally? 📄🔍 At just 0.9B parameters, you can drop GLM-OCR straight into LM Studio and run it on almost any machine! 🥔 🧠 0.9B total parameters 💾 Runs on < 1.5GB VRAM (or ~1GB quantized!) 💸 Zero API costs 🔒 Total data privacy Desktop document AI is officially here. 💻⚡