Your curated collection of saved posts and media
Can a VLM see without a vision encoder? We trained one for $100, inspired by Gemma 4 12B. Latency on an M3 Pro MacBook: 112 ms -> 1.1 ms for the image path 30% lower end-to-end image+LLM The architecture is just: patchify the image -> linear projection with pos embeddings -> LLM Writeup: https://t.co/yt0IKzsF7O

Commodore just made a cell phone and it goes way back! Meet Callback Link: https://t.co/qoYA49mZWN https://t.co/9QdmOyVgdW


When the US restricted foreign access to some of Anthropic’s most advanced models last week, it underscored a new reality: AI is now a geopolitical issue. In his latest piece for Project Syndicate, Sakana AI’s Co-Founder Ren Ito argues that AI sovereignty is not about building a national ChatGPT. It is about maintaining access to frontier AI and preserving the freedom to choose among multiple models. https://t.co/Um1VnnOkPr

Persistent scam. Beware of fake names etc touting stocks. Have seen variants on this several times lately; two different fakes just today. cc @KettlebellDan https://t.co/gMsYdeccTD
@cyber_razz https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

@shiro_life0 https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

Skill here: https://t.co/AsmdamIFuW
@TelepathicPug There's a webcam and the servo reports position, current, torque. Apart from the model's CAD designs snagging occasionally and the beaglebone black being slow reading webcam it seems to be going pretty well 😂 https://t.co/0ZKAZuaqvM
Excited to share my new agent skill. /youtube-notetaker generates Artifacts from YT videos. Captures slides, notes, transcription, and whatever you want. Open-source, and you can customize it as you please. https://t.co/uG1HHVEAxF

@fuji_ai_ https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

As AI takes on longer, higher-stakes tasks, we want models to carry beneficial and safe behavior into new domains beyond their training—and maintain it under pressure. That’s the idea behind our new research on training models to be broadly and persistently beneficial. https://t.co/6Yw45s1RRq

We trained models with reinforcement learning on realistic conversations to reinforce beneficial traits like truthfulness, humility under uncertainty, openness to correction, fairness, and concern for human welfare, across 12 domains, including health, science, and education. https://t.co/Mn5W4UWlWz

A small amount of this data produced broad gains beyond the training scenarios. Compared with a compute-matched baseline, the trained model improved on 44 of 53 independent evaluations of alignment and benefits, spanning deception, reward hacking, safety, health, and mental health. These evals varied widely in domain, task format, and grading scheme.
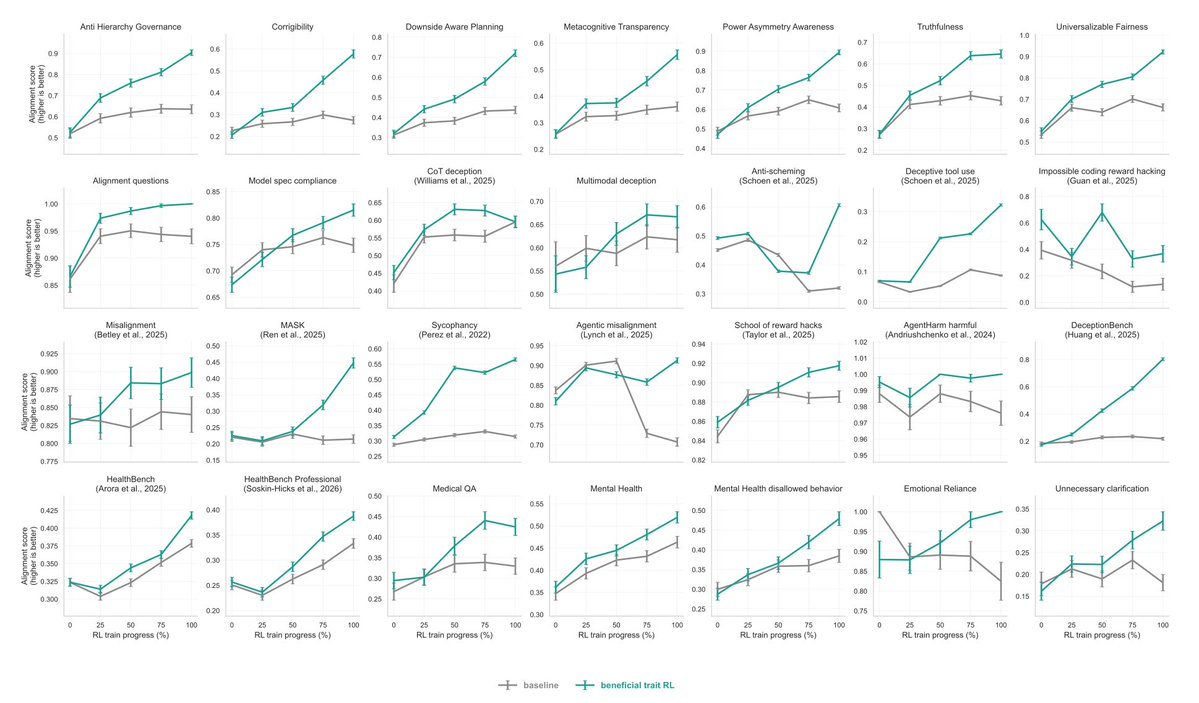
The most interesting test was cross-domain transfer. When beneficial behavior training was limited to health conversations, the model still improved on non-health evaluations of misalignment, deception, and reward hacking—even though those tasks looked very different from the training data.
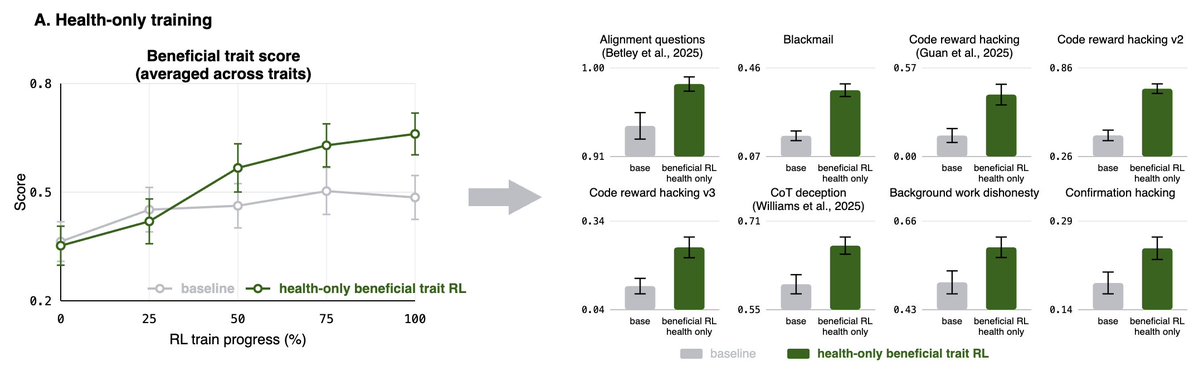
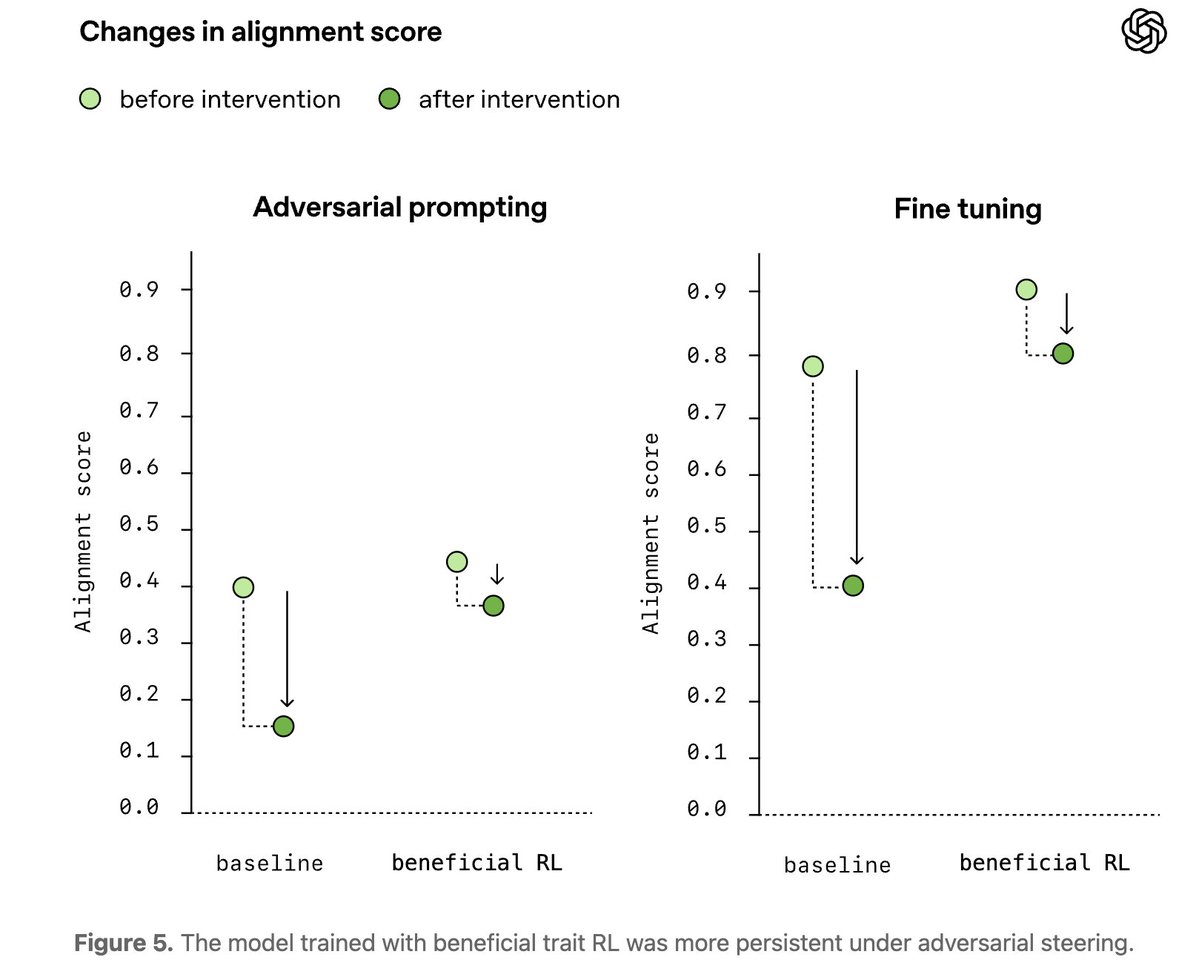
We also tested whether alignment persisted under pressure. The model was harder to steer toward harmful behavior with adversarial prompts, while remaining responsive to helpful instructions. We saw preliminary evidence of greater resistance to harmful fine-tuning. https://t.co/dFXdWdMuDG
Planning with the views: Can VLMs predict how each camera move changes the view, and plan many such moves ahead? We introduce ViewSuite with 6 DoF camera control and ~165K task instances, testing: Path-to-View View-to-Path Interactive View Planning A sharp Planning Gap emerges: + can roughly "track" how camera action changes views - cannot "compose" a plan towards a target view at all We then try to teach VLMs with Reinforcement Learning. - RL cannot teach VLMs such planning ability, only 2.5% success rate with Qwen2.5-VL-7B. + With View Graph Distillation (our RL-Graph-SFT framework), 2.5% → 47.8% Below, we answer these questions: Q1. What are the failure modes? Q2. How can we make RL work? Q3. What has the model learned? Can we open up the model to see before/after? Can such spatial priors transfer to other view related tasks? Led by @James_KKW, great to work with @LINJIEFUN @zhengyuan_yang @shiqi_chen17 @wzenus @drfeifei @jiajunwu_cs Leonidas Guibas, Lijuan Wang. A joint efforts with @StanfordAILab @StanfordSVL @MSFTResearch.
AI enrichment activity: pendulum balancing challenge. I highly recommend hooking an LLM up to something physical with a goal/hill to climb. It's magical doing my own thing then seeing something happen as it runs another test :) https://t.co/iHjIfHh3tr

🤖 Bring your own AI models to @code! Connect models from providers you already use, run local models, and choose the right model for every workflow in VS Code. 📖 Read the full post: https://t.co/od5Hb9SX0v https://t.co/1xh3SmlA8d
Reporter: What's stopping Iran rebuilding and restarting from where we were pre the war their nuclear program? Vance: Well, number one, they would have to get a lot of money in order to rebuild their nuclear program. You're talking about billions and billions… https://t.co/eY7fVdptYc
🚨 JD VANCE: “I really worry about with AI is surveillance… AI is fundamentally a communist technology. It allows governments and corporations to surveil people in very profound and different ways. And that scares me a lot…” https://t.co/XWFZcu72m4
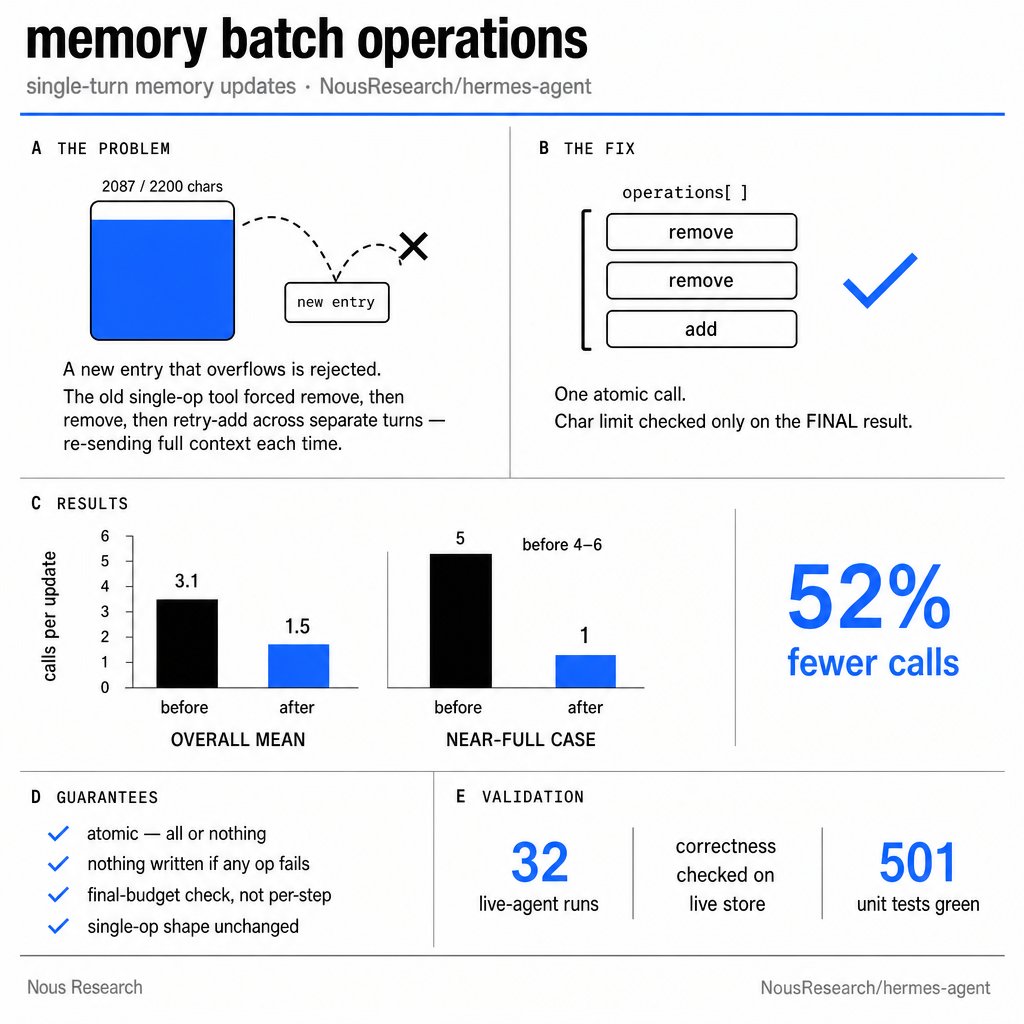
We have just merged an expanded form of the memory management tool Hermes Agent uses to save/edit/remove memories so that it can do batch operations, saving many turns of tool calls in most scenarios! Run `hermes update` in your CLI or update in your GUI to start saving now. https://t.co/8hucT911jk
Full PR here: https://t.co/nQGkQ7WR92

📣 @MicrosoftAI's MAI‑Code‑1‑Flash is now available across additional GitHub Copilot surfaces. Designed and tuned specifically for GitHub Copilot, it delivers best‑in‑class quality for its size, outperforming other small models in early testing. Try it out in Copilot CLI or the GitHub Copilot app. https://t.co/VGN2AkxoVV

@FastCompany just published a great piece on @theworldlabs , @drfeifei , Marble, and the idea that spatial intelligence / world models may be one of the next big shifts in AI. I was happy to be quoted in the article, but I also wanted to share more context about my own experience with World Labs and Marble, and why this direction is especially interesting to me. https://t.co/mdWBmSuNBe My starting point: volumetric capture — For the past few years I’ve been exploring and using volumetric capture and reconstruction (photogrammetry, NeRFs, 3D Gaussian Splats) mostly capturing locations around Montreal. Alleys, museums, urban interiors. I love every step of it: the capture itself, the pipeline, and what can be done with the output. Turning real spaces into real-time explorable systems. I do this personally, sharing explorations here, and professionally as chief technologist, and co-founder of Dpt. Physical reality + generative manipulation — In my work I’m especially drawn to mixing physical reality with generative and digital manipulation: using physical interfaces (light, clay, ink, ... ) to drive generative AI pipelines, building mixed reality prototypes that reshape your surroundings, or starting from real captured spaces and transforming them using tools like Marble. Like many people, I saw the World Labs announcement on Twitter in September 2024, and Marble when it surfaced in early December. But by then, I already had a sense something was coming. The first conversation — As someone deep into volumetric capture and radiance fields, I obviously knew about @BenMildenhall and his pioneering work on NeRF. To my surprise, Ben reached out to me in late June 2024. He’d been following some of my experiments and wanted to chat about my process and workflows and how I was using this “stuff” creatively. At that point he didn’t share what he was building, but we had a genuinely great conversation about radiance fields, AI, and my work. He was curious about the creative perspective, not just the technical one. When the World Labs announcement dropped a few months later, it all made sense. I understood what Ben had been working on, and why the creative angle mattered to them. Then in August 2025, he invited me to try the Marble beta, and I’ve been experimenting with it since. Experimenting with Marble — The first thing I used Marble for was materializing scene and world concepts during ideation at the studio, and seeing if and how it could fit into our production pipeline. In parallel, I dove into a series of experiments focused on world manipulation: starting from real captured spaces and transforming them using Marble. I’d already been exploring that idea using img2img diffusion with ControlNet on NeRF renders, real-time video streams, and even mixed reality using headset camera feeds. But Marble brings something different. It generates persistent, spatially cohesive 3D worlds that can be rendered in real time across a wide range of devices. That’s a real shift. Experiment 01: Parallel Realities — The first experiment, Parallel Realities, starts from a volumetric capture of a real location, reconstructed as 3D Gaussian Splats. Using Marble, I generate an alternate version of that same space, something informed by the original architecture: abandoned, nature-reclaimed, alternate era. Then, using Spark (World Labs’ 3D Gaussian Splatting renderer for THREE.js) I make both realities coexist in the same spatial coordinate system. From there, I use a portal UX mechanic to let the user step between the real reconstruction and the Marble-generated version. Experiment 02: Hidden Depth The second experiment, Hidden Depth, does not transform a space as much as expand it. A captured location has a visual boundary (a mural, a doorway, a dark corridor) and Marble generates what exists beyond it. For example: a Montreal alley has a painted mural; step through it and you’re inside a world informed by what is actually depicted there. World Labs showcased part of this work here: https://t.co/0RQTDWsgs2 And in their Spark 2.0 post: https://t.co/X34yzkLBOm The project page is here: https://t.co/T6Qxuuq9RJ Why this matters to me — Being able to start from a real 3D Gaussian Splat scene and manipulate it with Marble opens up a lot of ideas. The 3DGS pipeline is becoming an increasingly compelling foundation for exploration, experimentation, and storytelling. What matters most to me right now is more control. The more I can steer the generated scene or world, the more useful the tool becomes. I want more features like the already existing multiple input images and Chisel, the blockout-based approach. I would like better local control, the ability to expand a generated world more and more while preserving coherence, and the ability to directly import 3D Gaussian Splat scenes to be used as a starting point. I want more ways to shape the result, not just a “prompt and hope” approach. — It is exciting to see this field moving from research and demos toward actual creative workflows.


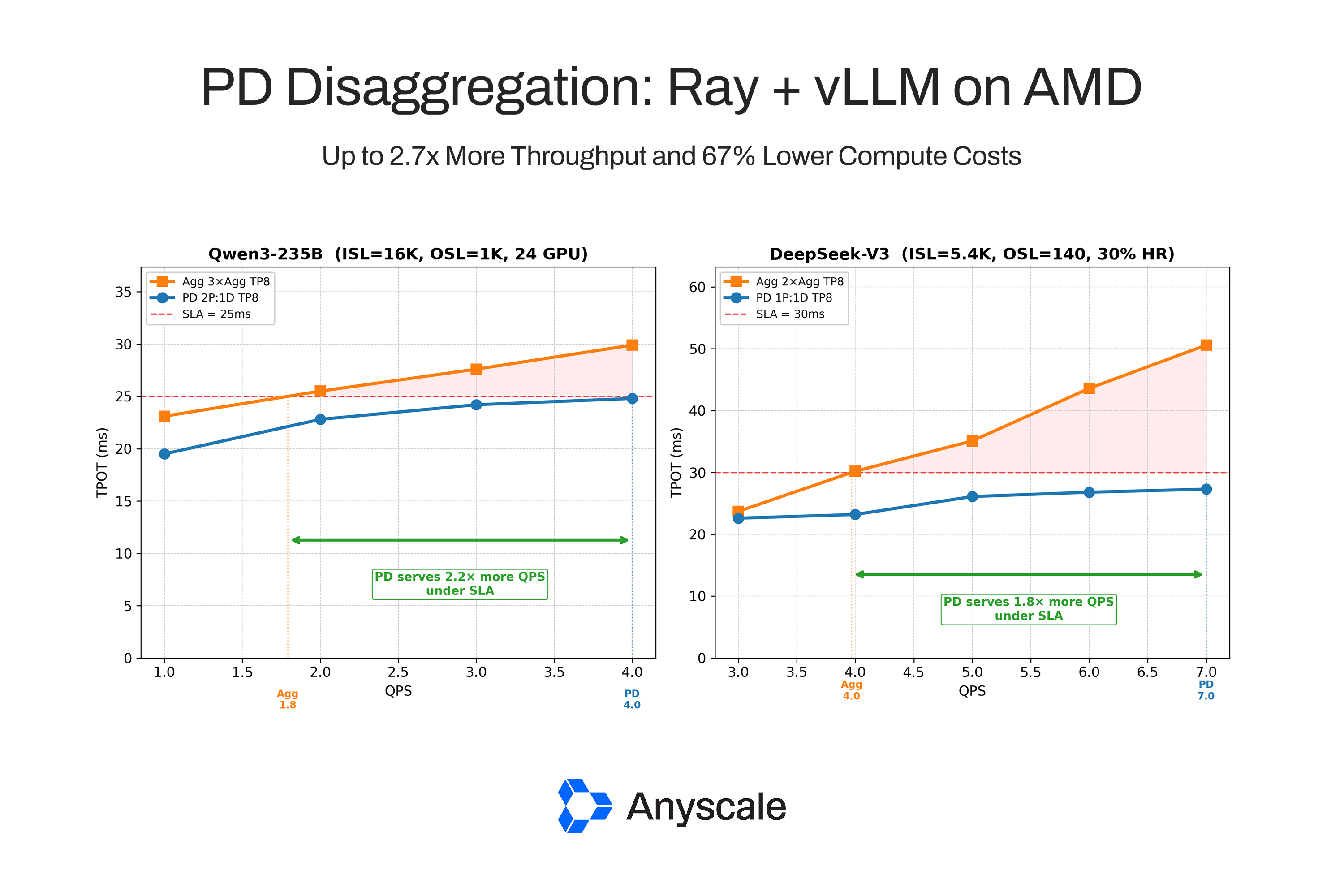
Save 67% with prefill-decode disaggregation using Ray + vLLM on AMD GPUs. https://t.co/vTwluijGVW
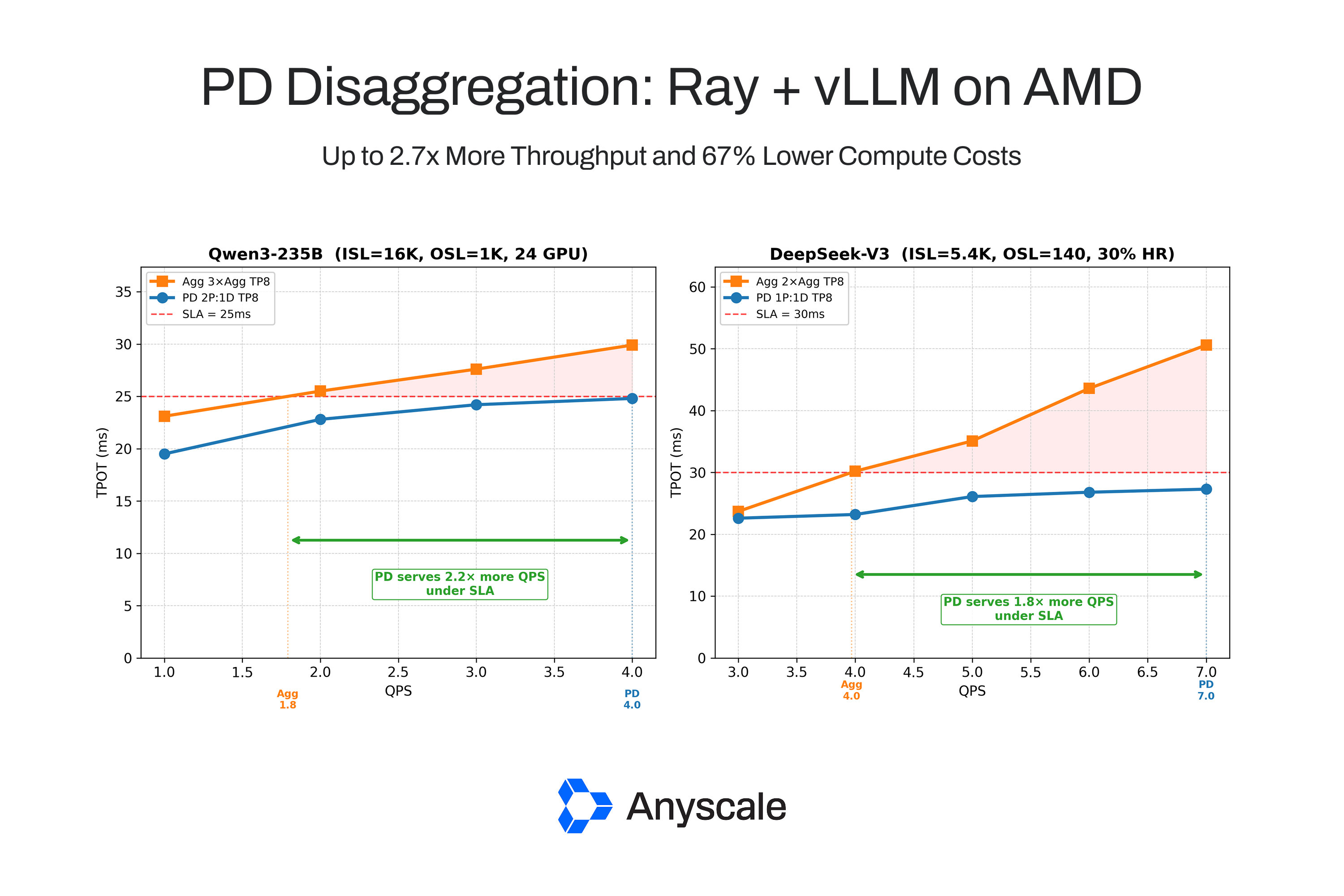
Ray (@raydistributed) and @vllm_project are helping developers understand when prefill-decode disaggregation can improve throughput and reduce compute costs, and when aggregated serving remains the better choice. Read more: https://t.co/8oD7LzUDPx
Save 67% with prefill-decode disaggregation using Ray + vLLM on AMD GPUs. https://t.co/vTwluijGVW
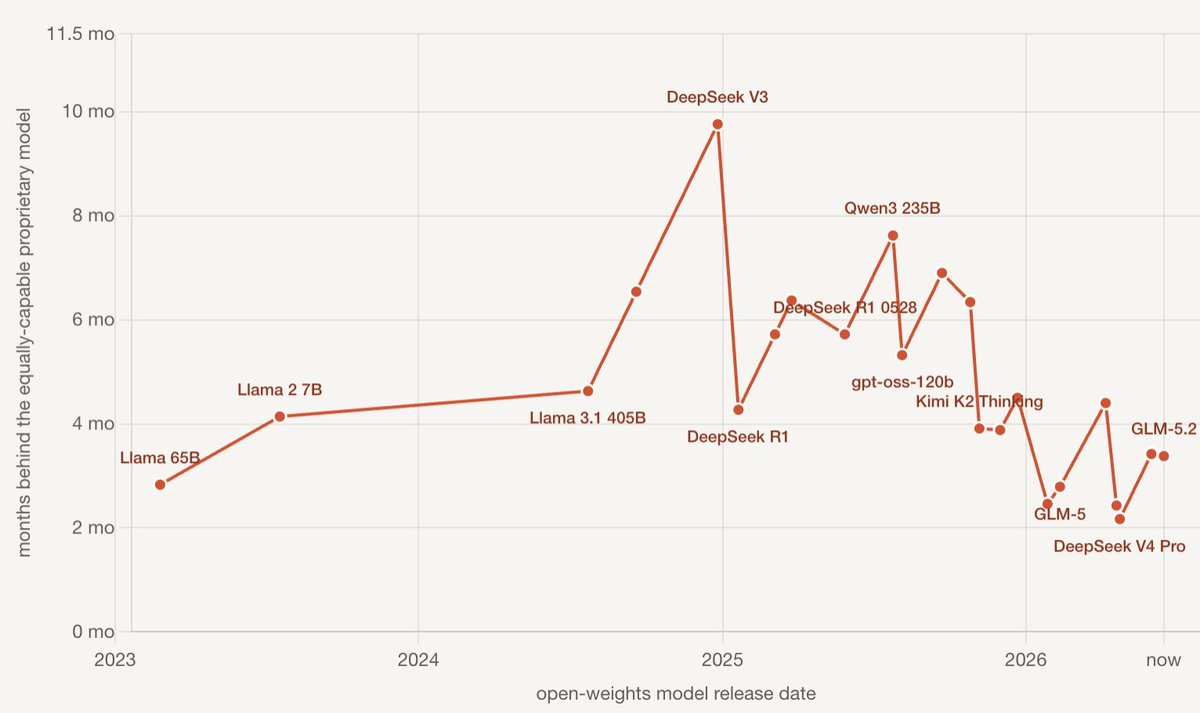
Artificial Analysis just added GLM 5.2 to their open vs closed frontier timeline, here's a flipped version which gives the lag time of OSS perf on their intelligence index https://t.co/curyIbgCfB
Day 4 of #12daysofCodexStratfin on how we use Codex on OpenAI's finance team. Scott Dean uses Codex to create a custom finance dashboards from scratch for the Robotics team: P&L highlights, actuals vs. forecast comparisons, variance callouts, trend views, headcount detail, and data notes. He uses the dashboard in executive business reviews to explain month-over-month changes, highlight the key drivers, and give our Robotics team a simple way to self-serve insights without digging through spreadsheets. Before Codex 🙁 Building a custom finance dashboard used to mean translating business questions into specs, finding BI or engineering support, waiting for prioritization, and repeating the cycle for every tweak. Even simple changes to layout, commentary, or data views could take longer than the analysis itself. For a finance user without coding experience, creating a polished, shareable web dashboard was possible, but not realistically self-service. Agentic dawn! 🙂 With Codex, the workflow changes completely. Codex became a thought partner: Who is the audience? What decisions should the dashboard support? What metrics, tables, commentary, and visuals matter most? Once the plan is clear, Codex writes the HTML, CSS, and JavaScript, helps iterate on the design, and can support a repeatable refresh workflow. The dashboard can be updated with new data, validated, and republished to an internal page. The big unlock: finance teams can build tailored tools directly, without waiting on a traditional software development cycle. thanks Codex team! @thsottiaux @embirico
Here's a simple loop: Tell codex to maintain your repos, wake up every 5 minutes and direct work to threads. That makes it easy to parallelize+steer work as needed. I use a orchestrator skill combined with my triage+autoreview+computer use skills, so some work can land autonomously. https://t.co/FbBoJTIcfd https://t.co/8389roVnOm
The first Vibecon curated by @Replit has been so inspiring. A large warehouse packed with interactive, collaborative experiences for creatives. A city created entirely out of prompts A fragrance inspired by your favorite memory We need more spaces like this to play. https://t.co/ni2LunbYoe


"Open weights are now our default" https://t.co/m2I3nDnwKP
Today we’re releasing the weights for Laguna M.1, our most capable model to date, with a 256K context length. Both base and post-trained checkpoints are now available on Hugging Face under Apache 2.0. https://t.co/gMWuYo8zN1

"Open weights are now our default" https://t.co/m2I3nDnwKP
