Your curated collection of saved posts and media
@angeldot_ https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@__paleologo https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

Speculation Is All You Need. In this blog post, we announce the co-release (w/ Z Lab) of six more state-of-the-art DFlash speculators for @Alibaba_Qwen 3.x. Over 1k output tps for 3.5 122B-A10B on a B200. Read the blog for why we're all-in on spec dec. https://t.co/Bv3Zc95Xgh https://t.co/FQ6eWQbhTO

@usr_bin_roygbiv https://t.co/xHyeZb6mdw

Starlink is now providing reliable connectivity to more than 25 police stations, traffic systems and disaster response teams across Lesotho 🛰️❤️ https://t.co/k0Ntib5OTL


"Ultrasound can't look through bone or air." This is not true. Here's a video from Guasch et al 2020 simulating ultrasound propagation through the skull. There's also a whole field that sends ultrasound through the skull for neurostimulation (see @nudge). (1/4) https://t.co/44XyaZrSrv
I should probably learn more and write a post on this, but my first thought is that this isn't too interesting and the degree to which they're overselling it is a red flag. Ultrasound can't look through bone or air. Many of the things in the body you'd use an MRI to look at are
the best design nights @contra 🎨 https://t.co/6jwAWffYAM

the best design nights @contra 🎨 https://t.co/6jwAWffYAM

Hey, @NousResearch Hermes Agent fans. I created 7 profile pictures you can steal and use for your agent, e.g. in your favorite messenger. All made using the unmistakable Nous Research visual language, of course. 🌌 🧵 https://t.co/YDsWm7fF2o
Narrative violation: AI is creating engineering jobs https://t.co/wJEzuYq7d2
@majidmanzarpour https://t.co/HKCLTrsC6o
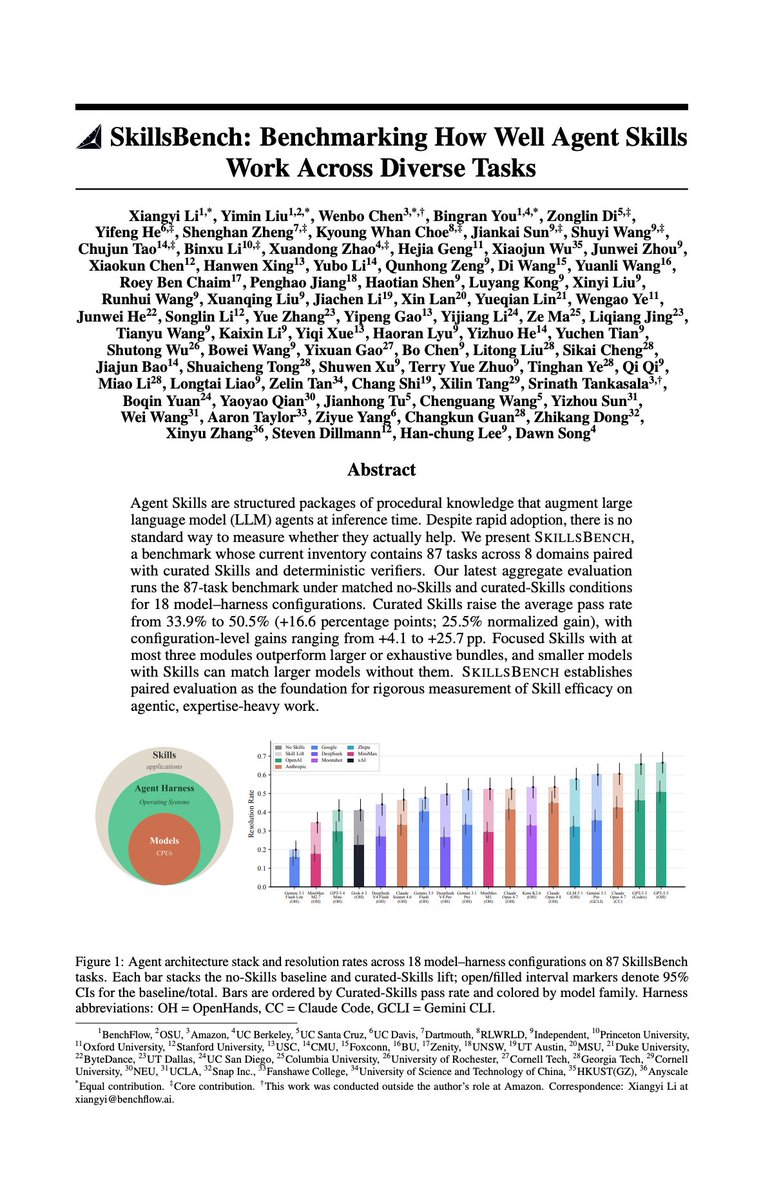
A big pain point in using AI benchmarks is encountering errors after its first release. Today, we're releasing SkillsBench 1.1, the first benchmark for how well AI agents use skills, now audited end to end and verified error-free. Prof. @dawnsongtweets joins 1.1 as advising author. We worked through every task with several frontier labs to eliminate the errors in the previous version. We also added new tasks, moved the ones with external dependencies into a separate set so the core suite runs clean, and expanded coverage to more models. Capability is climbing fast. The best with-skills resolution rate rose from ~36% (Claude Sonnet 4.5, Sep 2025) to 67% (GPT-5.5, May 2026), about +1.9 points per month. The frontier is hill-climbing SkillsBench fast. The right skills still matter. Across the fleet, curated skills lift resolution rate by +16.6 points on average (33.9% → 50.5%), and by as much as +25.7 points for a single model. The top configuration is GPT-5.5 on OpenHands at 67.3%. By popular demand (thx Nate @cursor_ai), we're now tracking skills invocation: how often an agent actually uses the skills it's given. Recent flagship configurations invoke them 90–99% of the time (Codex 99%, OpenHands + GPT-5.5 92%, Gemini CLI 90%), versus roughly 50% for older setups. Also new in 1.1: @OpenHands joins as a fourth harness, alongside Claude Code, Codex, and Gemini CLI; a rebuilt leaderboard with refined categories, subdomain skill rankings, and Skill Lift; and native task . md on BenchFlow, with multi-scene environments and rollout branching. We also partnered with @k_dense_ai to add scientific skills to some science tasks. One implication for deployment: skills can substitute for scale. GLM 5.1 with skills (58.4%) outperforms Opus 4.8 without (45.7%). A smaller model with the right procedural knowledge can beat a larger one running without it. Huge thanks to @nick_kango @ivanleomk @kaggle @GoogleDeepMind for hosting a launch event with us. Thanks for everyone who's come on May 27! Also thanks to our partners @gneubig @OpenHandsDev @ivanburazin @daytonaio @jackminong @johannes_hage @PrimeIntellect @TimothyKassis @k_dense_ai for providing support in credits, compute, and skills. SkillsBench live leaderboard will also come to @ValsAI. Many people have told us they use SkillsBench as an index to measure models' agentic capability over diverse and high GDP value domains. Great work on Valkyrie as well! @ Jarett @nikilravi @langstonnashold @RayanKrishnan SkillsBench is fully open-source. Explore the leaderboard and tasks, read the docs, or contribute your own skill set or harness and join the leaderboard. 🧵

ow that hits hard https://t.co/Mwx7n0Hvzw

ow that hits hard https://t.co/Mwx7n0Hvzw

Elon Musk and I play a little game. He puts a little bit of money in my bank account, which just happened, and then I put that and more back into his bank account to use the X API. Which builds https://t.co/8L5xphk0qQ There is a reason he's the world's richest dude: he's good at getting me to give him more money than he gives me. Really appreciate his support of my efforts.

dot-com bubble vs. a possible AI bubble. From the famous "Dean of Valuation", Professor Aswath Damodaran, of NYU Stern School of Business, “And that’s the real big difference between the dot-com boom and bust and the AI boom. We don’t know whether there’ll be a bust. History suggests there will be a bust. The dot-com boom and bust had no huge capital expenditure in that cycle. In fact, there was very little traditional CapEx, or even R&D, driving it. People started apps. They basically started going on it. This has been the biggest infrastructure run-up I think I’ve ever seen in business. You can go back and compare it to the automobile business 100 years ago. The amount of money that’s being put into AI CapEx is immense, which means that when the correction comes, the pain will be more intense. And herein lies the second problem. The dot-com boom and bust was almost entirely equity-funded. You think, so what? Well, when the bust came, those shareholders lost 60%, 70%, 80%, or 90% of their money. You felt sorry for them, but the loss was restricted to the shareholders. The problem with the AI CapEx boom is that not only is it immense, but a big chunk of it is funded with debt, and the debt is coming from private capital rather than banks. There’s a very real chance that if there’s a correction and companies start having problems, that problem is going to show up as distress and default, and that really doesn’t stay restricted. It spills over into the rest of society. I’m not saying it’s going to be 2008, but 2008 is an example of what happens when lenders overreach, when they lend money at too low a rate, and the correction comes. The pain spills over. So that is my concern with this big market illusion: the potential societal cost of having to deal with debt coming due that you’re unable to pay. It’s much more painful than your share price dropping 90% and you feeling the pain." ---- From "Excess Returns" YouTube channel, (link in comment)
Introducing the Computer Command Panel. Type / to see every mode and skill available in Computer, including Deep Research and Plan Mode. Live now on the web for all Computer users. https://t.co/0Lnig2Zi8x
Day 5 of #12daysofChatCodexStratfin on how OpenAI's finance team uses Codex. Amir Tavoli and Esau Torres use Codex to automate budget management process. Before Codex 🙁 month-end Budget vs. Actual review required significant manual spreadsheet work: pulling exports, copying data across tabs, updating formulas and pivots, and reconciling the plan, actuals, purchase-order schedules, accruals, and txn details. The challenge was not only identifying a variance but tracing to its source, confirming that every layer tied out, and packaging the analysis so xfunctional partners could review the math without retracing the entire workflow. Agentic dawn! 🙂 Codex now automates the workflow end to end. It ingests data from source systems, standardizes and reconciles the inputs, and produces an overview of the largest variance drivers. Codex enables the team to drill from the cost-center level into the underlying purchase orders, transactions, and accruals to understand what changed and trace each variance back to its source. The result: less time maintaining spreadsheets and more time to focus on the strategic drivers and questions that matter most to the business.
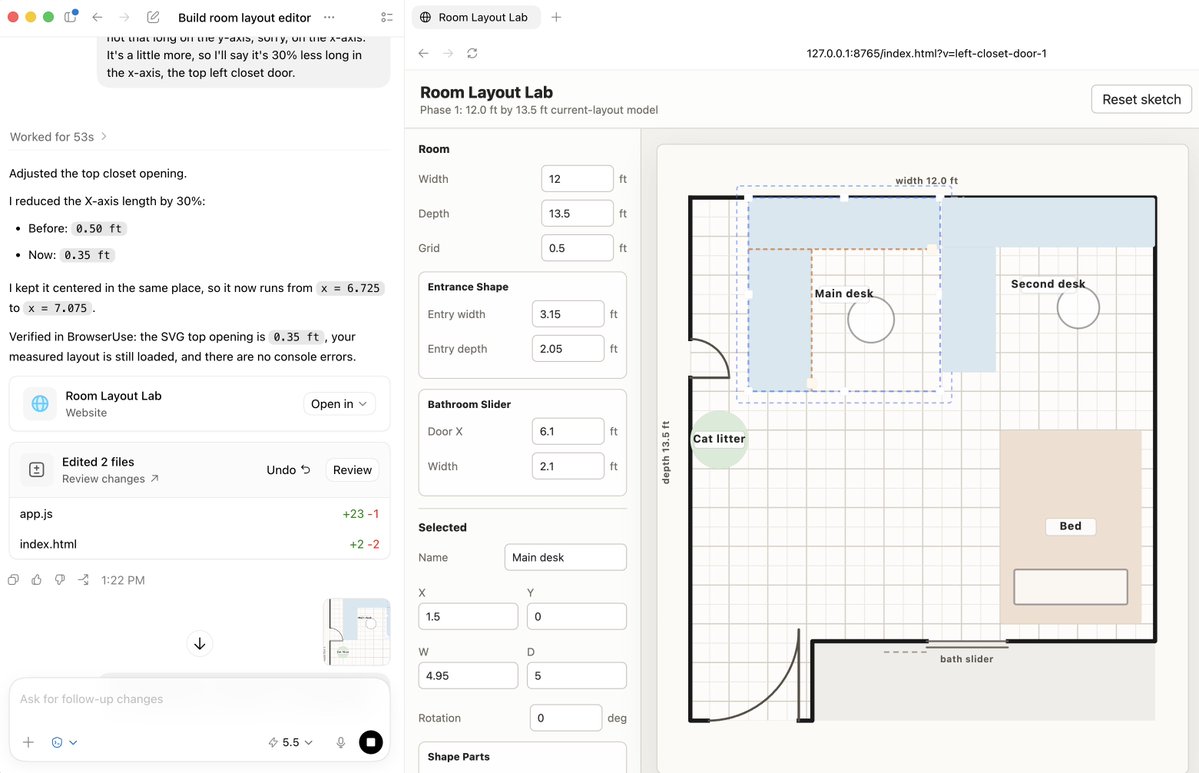
OpenAI Codex helped me redesign my office. I gave it a photo sketch of the room and furniture dimensions, it built a small web app, opened it in-browser, and helped me explore layouts I would’ve never sketched by hand. https://t.co/LWZwZexBME
adding some cuteness to my codex: bringing digital yoda (my cat) in as my building companion 🐱 https://t.co/JtnBtvRmkb
adding some cuteness to my codex: bringing digital yoda (my cat) in as my building companion 🐱 https://t.co/JtnBtvRmkb
Codex can now hand off threads between local and remote hosts. Start work on your laptop, send it to a remote box before you close the lid, bring it back later. And yes, Codex can orchestrate the handoff for you. https://t.co/CcIG9fwzXd
Vincent van Gogh accidentally solved a complex physics problem while inside an asylum. In 2004, scientists analyzed The Starry Night, they found something magical. His swirling brushstrokes perfectly match Kolmogorov’s formula for fluid turbulence. This formula describes how energy flows through the universe. Physicists of his time could not prove it, Van Gogh did it with paint. Through pure intuition during severe psychosis, Van Gogh’s brush captured the universe's invisible, chaotic geometry.
I'm excited for this one. @HamelHusain, @sh_reya, and folks who build AI products for a living are teaming up to run a bunch of free live sessions over the next month: OCR, retrieval, evals, open models, all with live Q&A. Starts June 24. Sign up here: https://t.co/OpN675AOqC

Even before Mythos I was getting asked more and more what Anthropic's deal is, and why tf they're acting the way they're acting if they believe what they say they believe. The best answer I can give is that their basic worldview is something like: 1. There are giant, dangerous monsters in the forest 2. We see others going out and making loud noises that will rouse the monsters, and they're not going to stop because of all the treasure and magical artifacts that can be found in the forest 3. We believe the best way we can help is to send out our own vanguard to go faster and farther into the forest than everyone else, because we'll spend a ton on monster containment and taming and we'll also send back detailed reports of what monsters we're finding so that the townspeople can ready themselves, which those other guys won't do On the one hand I understand how they got there, and I think it's possible they're basically right. On the other hand it's not hard to see why this approach makes people wonder if you're crazy or lying or both.

See all the updates in the release notes here: https://t.co/sQgNB5bx5x

@mitchellh @RobertMSterling https://t.co/GRMTlLkeVI

Try it out and let us know what you think ⬇️ https://t.co/RQSUhPZOtF
We’re open sourcing a humanoid robot for under $500. I hated that the coolest technology of our generation was inaccessible to most builders. So we built one. Coming soon. Comment “VIBE” and I’ll send you the Discord. https://t.co/nX9MFAy7AO
@ilTrumpista @telegram @NousResearch Done! https://t.co/HiKm8whhUW


Building AI products is hard. But it's getting increasingly popular! I'm really excited to share that my friends and I are putting together (the best) lecture series on AI Product Engineering this summer!! We've got an awesome lineup of talks spanning data, evals, and UX. With more to come. The lecture series is completely free! And ~2k people have signed up already even though we haven't posted on social media yet! I can't wait. Join us and sign up: https://t.co/5DWcm4va5m


If this goes right you might never hear from me again https://t.co/AO5BzwYBf6