Your curated collection of saved posts and media
I spent the last month obsessed with finding colors that can't be displayed on a conventional screen. This is what I found. https://t.co/JEn05RLN0S

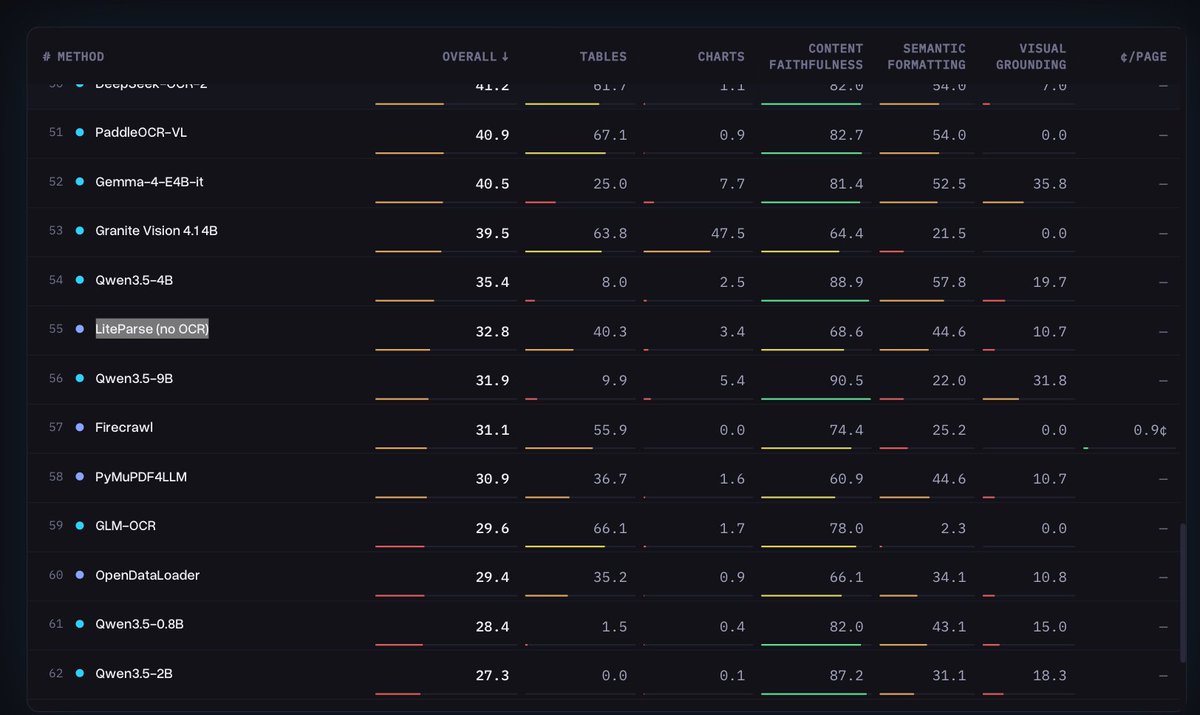
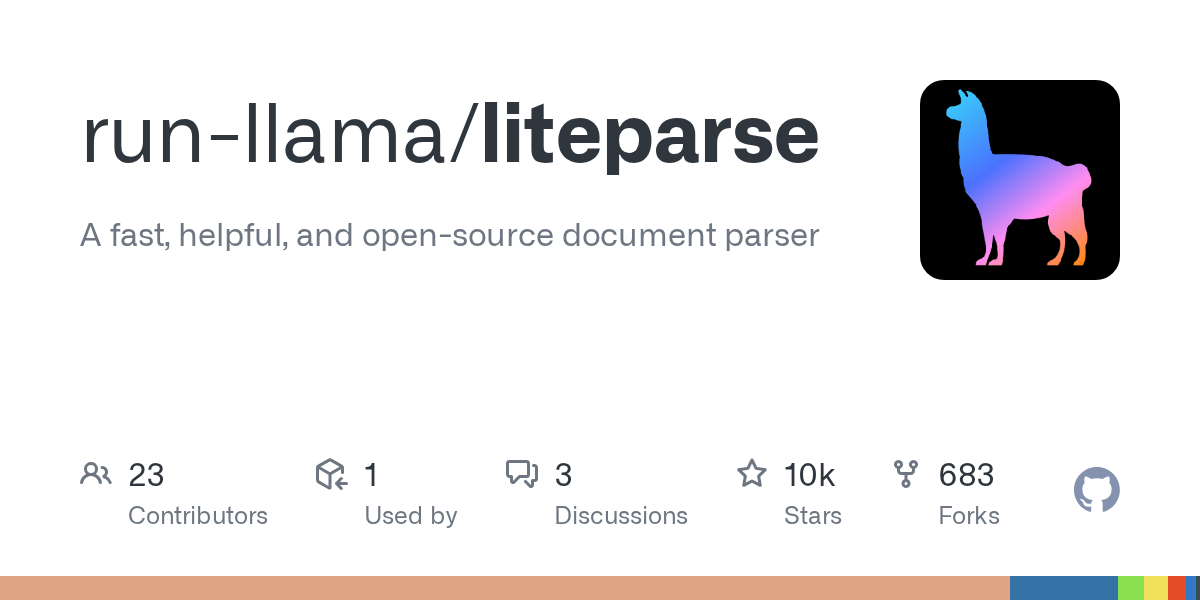
It's kind of crazy how well LiteParse does on markdown document parsing even compared against frontier VLMs - when it doesn't use VLMs or any AI/OCR models at all. It's pure code. On ParseBench, it outperforms Qwen 3.5-9B / GLM-OCR. There's still a gap vs. models like Gemma 4 and PaddleOCR-VL especially on dense visual outputs, but if your documents are text/table-heavy this gap closes rapidly. Come check it out: it's the fastest document parser you can possibly use, and it's completely free/open-source. Repo: https://t.co/JNER0mVcB8
We built the fastest PDF -> markdown parser in the world 🚀⚡️ AND it’s more accurate than any other open-source, model-free parser (pymupdf4llm, opendataloader, pdf-inspector, markitdown) on 3 standardized benchmarks: olmOCR0-bench, opendataloader-bench, ParseBench Introducing L
Luca Guadagnino's nearly finished Sam Altman movie, “Artificial,” has been dropped by Amazon MGM Studios. The film, starring Andrew Garfield as the controversial OpenAI CEO, will be shopped to other studios. The move notably comes after Amazon struck a massive partnership with the tech company in February, which included a $50 billion investment. https://t.co/ebSo7jSLnG

new achievement ! Qwen3.6 27B MTP llama-server -hf unsloth/Qwen3.6-27B-MTP-GGUF:Q4_K_M --host 0.0.0.0 --port ${PORT} --ctx-size 131072 --predict 32768 --batch-size 20248 --ubatch-size 512 --flash-attn on --cache-type-k q8_0 --cache-type-v q8_0 --mlock --no-mmap --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0.0 --repeat-penalty 1.0 --presence-penalty 0.0 --parallel 1 --metrics --jinja --reasoning on --reasoning-format auto --reasoning-budget 2048 -ctkd q8_0 -ctvd q8_0 -ctxcp 32 --no-warmup --spec-type draft-mtp --spec-draft-n-max 2 -ngl 99
Depth Anything 3 now runs as pure C++/ggml (@ggml_org) . No Python, no PyTorch, no CUDA toolkit at inference, just one self-contained GGUF. It's faster than PyTorch on CPU! and ties speed on GPU. The CPU win came from the last place..I'd have looked. Quantized GGUF on @huggingface🤗 Shout out to @ggerganov for ggml (we are building a ggml-world!❤️) and to @ByteDanceOSS and Depth Anything 3 authors @bingyikang @jhliew91 @donydchen !
MIT's latest research highlights an important distinction. AI can be an extraordinary tool for learning and decision-making, but only if it augments our thinking rather than replaces it. The goal shouldn't be to outsource judgment. It should be to enhance it. https://t.co/8J9UlmTVco

https://t.co/G5yQHjdNEu

9 years later, none of the "Attention Is All You Need" paper authors are at Google. Ashish Vaswani - cofounder of Essential AI (recently exited) Noam Shazeer - just moved to OpenAI Niki Parmar - at Anthropic Jakob Uszkoreit - cofounder of Inceptive Llion Jones - cofounder of Sakana AI Aidan Gomez - cofounder of Cohere Lukasz Kaiser - at OpenAI Illia Polosukhin - cofounder of NEAR Protocol

If AI self-improvement, even in a very limited way, is possible, the cadence of shipping both AI products/harnesses & models should go up. This appears to be happening at Anthropic & OpenAI, but not for any other labs, including those that seemed to be catching up last year. https://t.co/gTBEpImYVb
@harumak_11 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

most LLMs know who I am :) https://t.co/qEABQ24GF0

@Jeyxbt https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@Jeyxbt https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@0xRicker https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@zostaff https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@djfarrelly https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@AM921543266 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@sodawateeer https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@sayauza https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@kingdom314159 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@kingdom314159 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@ai_300 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@ai_300 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@BoringBiz_ https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@MilkRoadAI https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@MilkRoadAI https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@jasperdeboer https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@vicky_grok https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@karankendre https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@angeldot_ https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@__paleologo https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

Speculation Is All You Need. In this blog post, we announce the co-release (w/ Z Lab) of six more state-of-the-art DFlash speculators for @Alibaba_Qwen 3.x. Over 1k output tps for 3.5 122B-A10B on a B200. Read the blog for why we're all-in on spec dec. https://t.co/Bv3Zc95Xgh https://t.co/FQ6eWQbhTO
