Your curated collection of saved posts and media
@mattjay I know a guy in San Francisco running a security company (I met it at @theresidency ) and he has done worse with it already. Hacked a good chunk of YCombinator's latest batch. Helped them fix their bugs. He did the same for the systems I'm using to build https://t.co/kiuZ7QXLzb

Another example from today: https://t.co/1D3ceEm3jX
I'm joining OpenAI next week!🥹 The job search turned out to be really challenging but also super rewarding, so I wrote a small blog to share what I learned along the way and hopefully make the process a little less mysterious for the next person. https://t.co/6FigSBdenD

codex about to get me 500$ back https://t.co/tZGXBYiMTM
Lego is boring. Enter BYLT - real construction using real practices. From architect drawn blueprints to finished product... on a tiny scale. Get your kit or order a la carte from the supply yard 👇 https://t.co/4H1SwkmuvZ
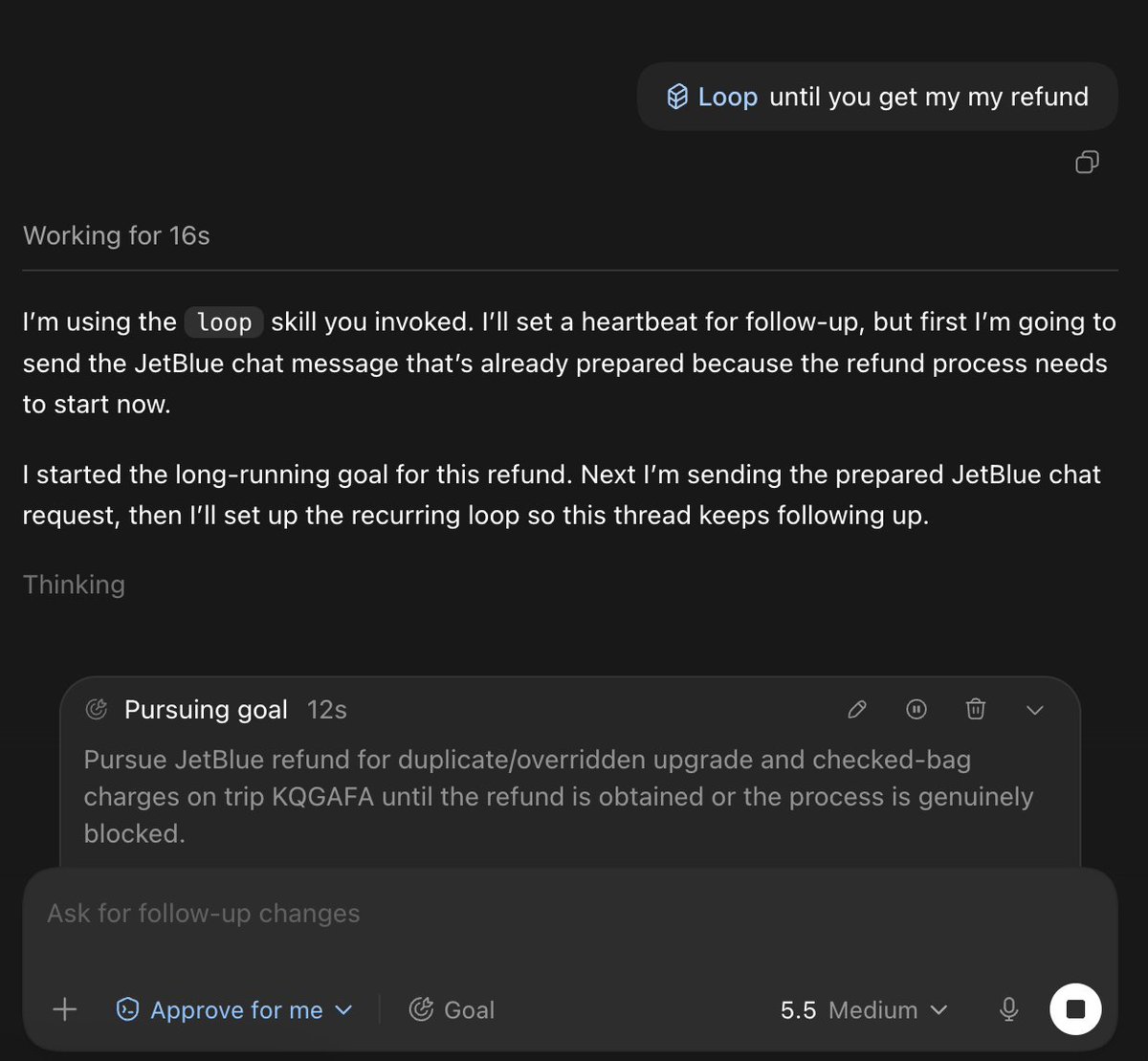
How I'm learning Hermes Agent. Stage 1. It began with a decision: two agents, one server. OpenClaw and @HermesAgent by @NousResearch. Different architectures, different temperaments — like a cat and a dog, except in Docker. I'm not a programmer. Just curious. OpenClaw moved in first. We worked through a strange assembly line: I'd write to ChatGPT, it would give me a task, I'd copy it into Codex — a desktop app that prepared the command. Then the command flew to the VPS terminal. Enter. Logs back to ChatGPT for review. And again. Copy. Paste. Wait. Verify. Repeat. Twenty, thirty, forty times an evening. Fingers learn Ctrl+C faster than the brain learns what exactly is being copied. Then I discovered Grok Build CLI. Installed it right on the server — and the chain got shorter. No longer "ChatGPT → Codex → me → terminal → me → ChatGPT", but almost a direct flow. Almost. ChatGPT still mixed up commands. The chat would fill up, context would tear, hallucinations would creep in. I'd open a new chat, load a context document from GitHub, carry on. It worked. Imperfectly. But it worked. And then, in the middle of this assembly line — Hermes Agent. Another command from ChatGPT. Copy. Codex. Terminal. Enter. Hermes came alive. On the same server where OpenClaw was already running, a second agent had just opened its eyes. Silent. No greeting. Just booted up and waited. @Teknium and the team built an agent that doesn't ask for a CS degree. Sometimes all it takes is a server, a couple of evenings, and a willingness to copy-paste. To be continued. #HermesAgent #NousResearch #OpenClaw #AIAgent #OpenSource #NoCode #ChatGPT #CodexCLI #GrokBuild

Working in some realtime keystone project with chappie today. https://t.co/ITmeQ7lPef
The first day in San Francisco has been incredible. New friends. My rock is on the way. I bought some flowers. Got some more tiny plates for our new friends. https://t.co/0z20RyTP0w


I’ve been living immersed in South Korea for the last month with my wife and daughter. We just leave the stroller outside if we go in anywhere. Because no one’s going to steal it. I met a friend for lunch. He rode his bicycle. He just left it outside in an alley without a lock. It was still there 2 hours later. Another friend mistakenly left his phone on a park bench. When he finally retraced his steps and went back 4 hours later, his iPhone was still there. I walked by a KPop concert. The fans who traveled from outside of Seoul to attend just left their luggage outside the subway station. No locks. No security. Koreans take this for granted. They don’t realize this is not normal for most the world, especially America. When I ask about it, they just respond, “of course, why would someone take it?” Can you imagine any of these things happening or being possible in NYC or LA or *insert city*? And IF, something were to be stolen in Korea, the police would investigate. Because in a high trust society, rules and norms matter. There’s no “under $1000” law. Theft is theft. And trust is trust. Will this social norm ever be possible in America?

https://t.co/pBWhE53c4A

https://t.co/pBWhE53c4A

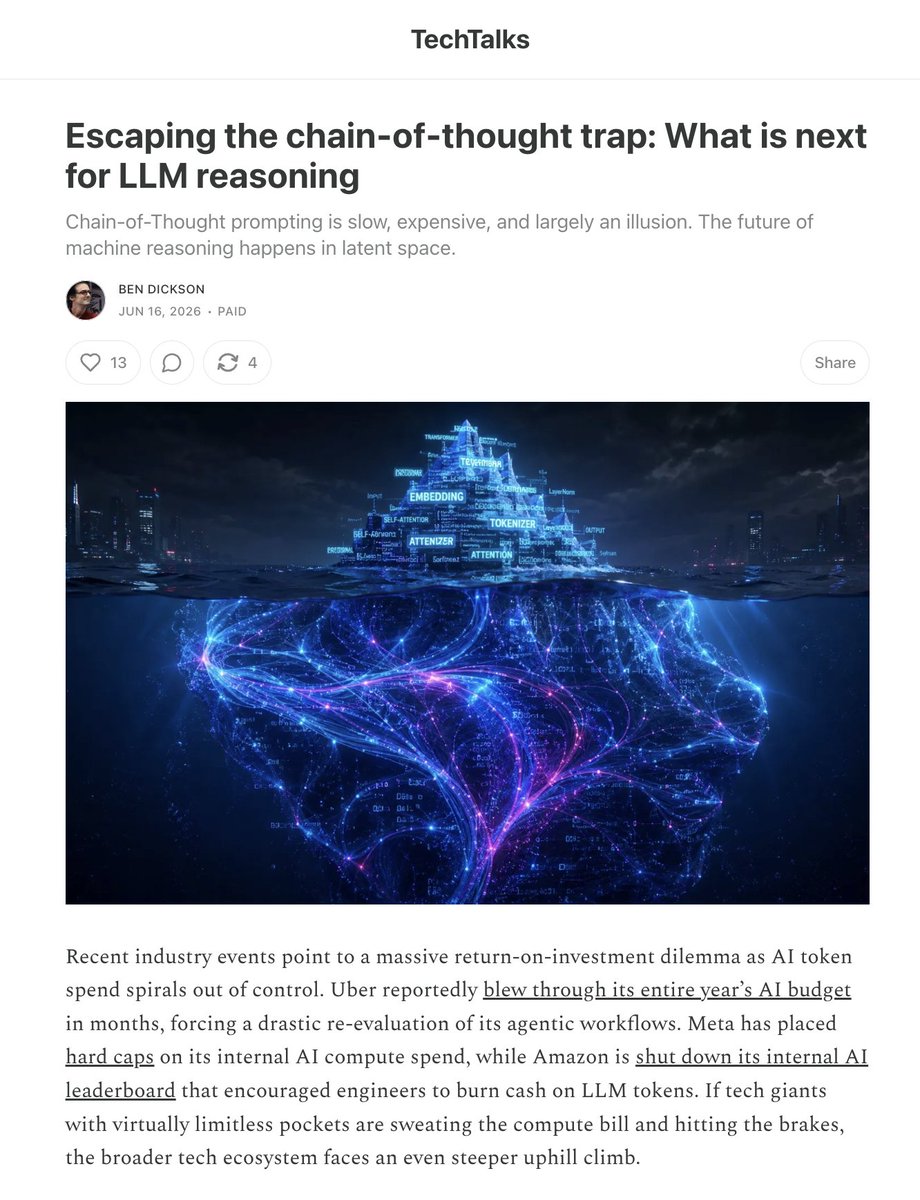
"When an LLM outputs a step-by-step plan, it creates a powerful illusion that you are watching a machine reason its way to a conclusion. A position paper by professor Subbarao Kambhampati and researchers at Arizona State University systematically dismantles this assumption." (From @bendee983 via @bdtechtalks ) 👉https://t.co/ELPfUplpU0
Falcon 9 launches 24 @Starlink satellites from California https://t.co/UmMBikZgK5

Brazilian friends, did I do good? A highlight of Rio was spending an hour in the record store listening to tracks on each album and giving the owner a thumbs up or thumbs down. I’ve had Di Melo, Joutro Mundo, Rosinha de Valença for years, a gift from my neighbor in Bondi Beach. https://t.co/ceNvAGMZGF

At @CERN, finding the universe's smallest particles requires big collaborative efforts. 🤝 Research fellow Batoul Diab shares how the ALICE collaboration uses open source code on GitHub to analyze massive amounts of physics data. Watch to see shared code, peer review, and global teamwork power modern scientific breakthroughs. 💡
🐕🦺 Blessed beyond measure to have gotten to spend yesterday afternoon and evening brainstorming Pupper for Good deployments with these brilliant doctors and researchers!! Teresa Nguyen is such a polymath and a powerhouse, as are Claudia Mueller, Laura, and Stuart. @googleaistudio @googledeepmind @googlegemma ftw!💎


We actually lived through this https://t.co/daL3jUqS6i

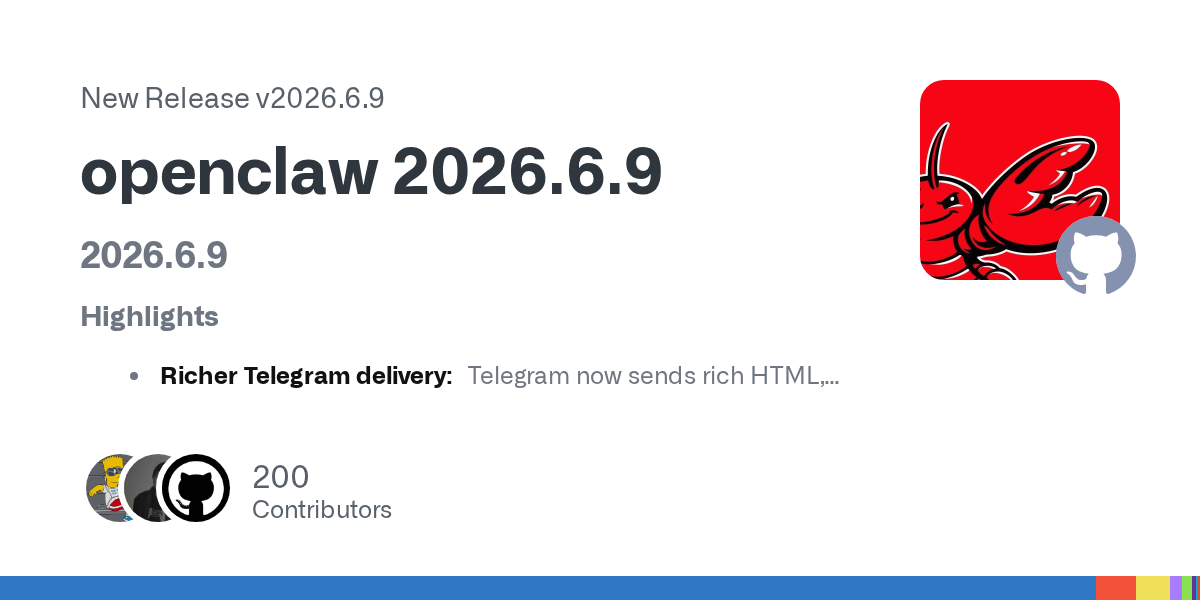
OpenClaw v2026.6.9 is out, with a focus on paper cuts! 💬 Richer Telegram delivery 👏 Steadier agent recovery 🧬 Stronger Codex integration 📦 Slimmer distribution 👌 Improvements in search and skills https://t.co/GOoHDXU8MZ
GLM 5.2 is now on DeepSWE as the top open-source model on our leaderboard. With a pass@1 score of 44% at max effort, GLM 5.2 is indisputable #1 open-source model besting Kimi K2.7 Code by 17%. https://t.co/cYZBm5z909
Pretty dope @greptile drink at @ycombinator https://t.co/BQ9BtrIcfu

>> Scalable Evaluation for AI Agents << If you run agent evaluation in production, this one is worth your time. It shows that front-loading human judgment into reusable evaluation assets is useful. But why? Agents reason across turns, call tools, hold context, follow policies, and act under uncertainty, so they have to be judged as behavioral systems. Current methods each give a fragment. Benchmarks measure fixed capabilities, human review preserves judgment but does not scale, LLM-as-judge inherits the evaluator design problem, red teaming is episodic, and trace audits need explicit evidence rules. Human-on-the-Bridge puts human expertise upstream, where experts curate reusable evaluation intelligence before testing rather than reviewing each output in the loop. Paper: https://t.co/0dVOH3QrZ6 Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

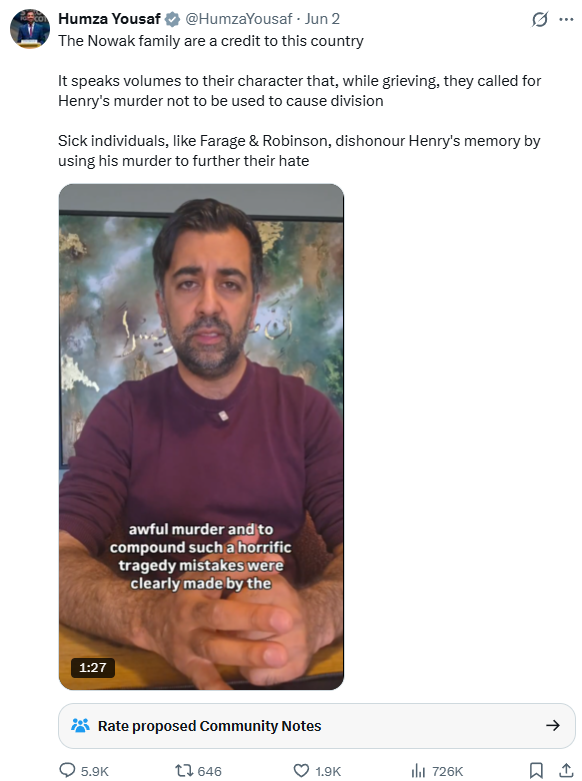
I love this guy. Muslim former Prime Minster of Scotland. When a white person attacks brown people, he goes into a frenzy posting about racism and hate. When a brown person attacks a white person, he calls for an end to "division". Same act. Two standards. Anti-white racism. https://t.co/hHWcvfZVw4
My full statement on the horrific, but I am afraid to say, unsurprising attacks in Edinburgh. Enough of the statements of solidarity from governments. Muslims - across the UK - no longer feel safe in the only country they call home. Time to face down the peddlers of hate. http
For Father’s Day, I’ll share this letter to Karl Marx from his dad https://t.co/m8WHi4LhRz

Traded my Range Rover for a @Tesla Model Y and picked it up two weeks ago. Turned on FSD today after the 14.3.3 update. If you don’t believe in magic, I don’t know what to tell you. I’ve always been fascinated by technology for as long as I can remember, but this is something else entirely.

No Taxation Without Annihilation The Anti-Antimatter-Tax Party fights for our freedom. AATP LFG! https://t.co/fJMpnMmb3x

Happy Father’s Day to all the incredible dads out there ❤️ https://t.co/ZZURvmfEWj

Happy Father’s Day to my wonderful sons, my fantastic father and all fathers. 🥰🥰 https://t.co/pkpNiYStwv

