Your curated collection of saved posts and media
spotted in the west village: the carrie bradshaw-ification of codex https://t.co/XKZgi6fth7

@itsjessyin Get that moneyyyy https://t.co/C0VptoBj1z

appshots are still one of the best features in codex https://t.co/pbxQQXkR4N
Day 1 of vibecoding https://t.co/n8ff35htEV

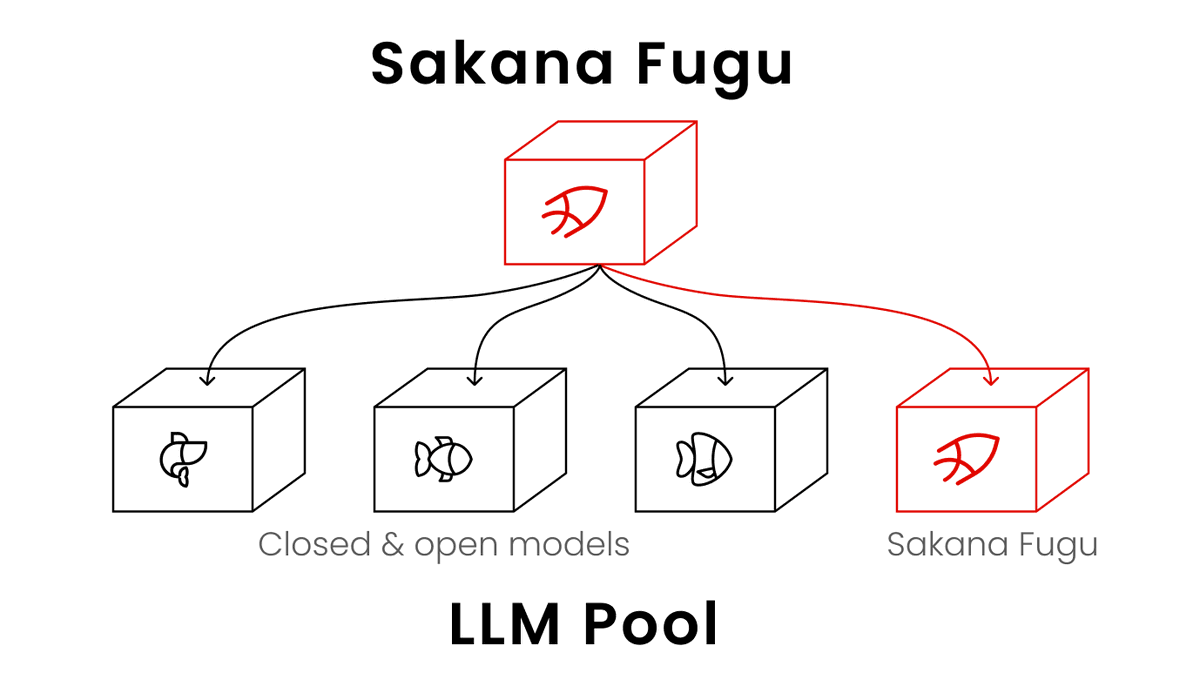
Human intelligence is fundamentally a collective intelligence. We solve complex problems by participating in a vast cultural network that builds upon ideas across generations. I believe the strongest AI systems will become a collective intelligence, too. Since we started Sakana AI, our core conviction has been that the most powerful AI systems will be collaborative ecosystems, not isolated monoliths. Evolution innovates under constraints, and the future belongs to systems that explicitly learn how to coordinate collective intelligence. Today, we are taking a major step toward that future with the launch of Sakana Fugu. Fugu dynamically orchestrates the world’s best models to tackle complex tasks. We are proving that a well-orchestrated pool of swappable agents can match restricted frontier models like Fable and Mythos. But Fugu is about more than just performance. I believe that Orchestration Models are the next frontier, beyond bigger models. Relying on a single company’s model for national infrastructure is a massive risk. As recent export controls have shown, access to top models can disappear overnight. Collective intelligence is the practical hedge against this concentration of power. Fugu simply routes around vendor restrictions by relying on an entirely swappable agent pool. I am incredibly proud of our Tokyo team for shipping this. By orchestrating the world’s models, we are delivering the resilient blueprint required for AI sovereignty. Read our full vision and results here: https://t.co/EONDdWx5Ld 🐡
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡

When Elon Musk visited Pope Francis at the Vatican with his kids. https://t.co/fyqFPwUd17

There's nothing like celebrating Father's Day with your children, grand kids and great grandsons! I hope you all had a wonderful day. My best, Bill https://t.co/vfSPIJROXP

Esta semana he estado probando Hermes Agent Desktop en su versión de escritorio y está bastante interesante 👀 Pensé que iba a ser solo una app que se conectaba a un Hermes desplegado en un VPS, pero no: es Hermes completo. Descargas Hermes Desktop y te instala también las herramientas de consola, los skills, todo. Y te lo ofrece a través de una interfaz muy sencilla para que puedas hablar con un asistente personal que tiene memoria, que puedes conectar con Telegram, y todo desde tu propia laptop. En cuanto a la interfaz, se parece a otras similares como OpenCode Desktop o Codex Desktop, pero esta tiene mejor UI, me parece que la trabajaron bastante mejor. Responde rápido, es multiplataforma y puedes ponerle cualquier suscripción de modelo. También puedes ejecutar subagentes, e incluso si vas a hacer tareas de código las puedes delegar a OpenCode desde la misma interfaz ⚡Resumiendo: está bastante bien. Como app de escritorio, quizás es una de las mejorcitas que hay ahora mismo. Aún le falta varias caracteristicas que tiene Codex Desktop, pero es está bastante usable. Les dejo el enlace del sitio si quieren probarlo 👇
How does it work? Sakana Fugu is itself an LLM, trained to call various LLMs in an agent pool, including instances of itself recursively. Fugu dynamically orchestrates the world's best models to tackle complex, multi-step tasks. As shown in this figure, Fugu is a multi-agent system that behaves like a single model. You send a request to one endpoint, and Fugu decides how to handle it internally. Fugu manages model selection, delegation, verification, and synthesis automatically. It solves tasks directly when that is enough, or coordinates a team of expert models when a problem calls for more. The complexity of a multi-agent system never reaches your code. At launch, Sakana Fugu comes in two models accessed via a single OpenAI-compatible API: • Fugu balances strong performance with low latency for everyday work. It fits naturally into tools like Codex for coding, as well as chatbots and interactive services. You can also opt specific agents out of its pool for data compliance. • Fugu Ultra is our flagship model tuned for maximum answer quality on hard, multi-step problems. It coordinates a deeper pool of expert agents for demanding work like AI research, cybersecurity analysis, and patent investigations.
My @NousResearch Hermes-Agent is cooler than your Hermes-agent because mine can make t-shirts end-to-end pretty much by itself. Using design skills + GPT Image 2 Skills + Shopify/Printful skills. From concept to final product. First sample “Made with Hermes Agent” tshirt arrived for my kid. What has your Hermes-Agent shipped today?

Creating some new infographics themes with Hermes rn wdyt https://t.co/M7fKBH3WQ5

让你 Hermes 聪明十倍的记忆插件! Hindsight仿生记忆系统(LongMemEval冠军),Hindsight本地嵌入插件、agentmemory 4层巩固插件、Hermes Workspace新Mission Control无限编排、hermes-desktop最新桌面伴侣……全网玩家把Hermes玩成了下一代「会学习的记忆大脑 + 生产级控制面 + 无限Agent舰队 + 原生桌面体验」: 1️⃣ vectorize-io/hindsight(https://t.co/L3RXrHnL5t) 仿生3层记忆,混合检索,LongMemEval 2026冠军,Hermes官方plugin。 “Agent终于会真正学习了”! 2️⃣ vectorize-io/hindsight本地嵌入(https://t.co/L3RXrHnL5t) 解决插件依赖,本地嵌入模式完美支持Hermes。 “记忆增强直接起飞”! 3️⃣ agentmemory Hermes集成(https://t.co/LefXP7LJk2) 4层巩固 + 43 MCP工具,95.2%检索率。 “持久记忆天花板”! 4️⃣ outsourc-e/hermes-workspace新Mission Control(https://t.co/IjMwS0zvUn) 无限Agent编排 + 1 orchestrator + 持久tmux。 “舰队指挥官上线”! 5️⃣ fathah/hermes-desktop最新版(https://t.co/HAwVxwUOx8) 原生桌面伴侣,支持v0.17+新特性。 “终端党终于有桌面体验了”!
Hermes 最强大脑插件 🧠 Wizards-of-the-Ghosts 奇幻技能包,Control Interface 生产运维仪表盘、Avoid AI Writing 内容净化器、Superpowers ZH 中文超能力包、gbrain 意见化优化大脑……全网程序员把 Hermes 玩成了下一代 Agent 魔幻技能工厂 + 专业运维面板 + 内容净化神器 + 中文技能军团 + 生产力优化大脑: 1️⃣ Hmbown/Wizards-of-the-Ghosts(https://t.co/ojAlY2G92Z) 非官方奇幻技能包,用法术和技能
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡


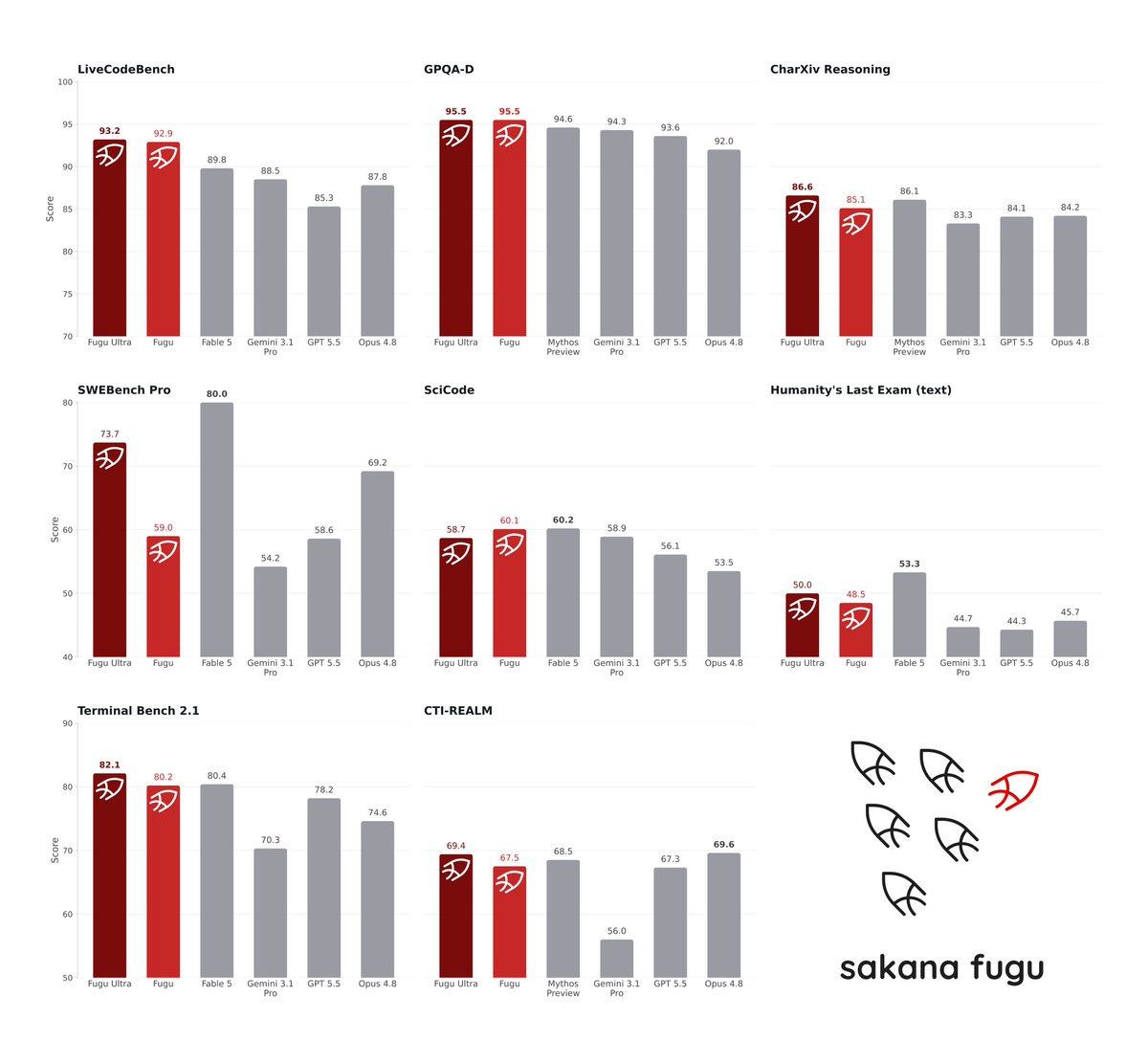
Fugu stands shoulder-to-shoulder with leading models like Fable and Mythos across the industry's most rigorous engineering, scientific, and reasoning benchmarks. Read the full blog: https://t.co/2ZJbdWqCUj Beyond Bigger Models: Why are Orchestration Models the Next Frontier Progress in AI has been driven largely by giant, monolithic models. But the most powerful systems of the future will be collaborative ecosystems. Today, this orchestration is no longer just a technical optimization. It has become a geopolitical and operational imperative. For an organization or a nation, relying on a single company's model for critical infrastructure, finance, or governance is a material vulnerability. This risk is no longer a hypothetical possibility, but a reality. As we have seen with recent export controls imposed on models like Fable and Mythos, access can disappear overnight. Collective intelligence is the practical hedge against this concentration of power. Because Fugu orchestrates an underlying pool of swappable agents, it simply routes around vendor restrictions. By orchestrating the world’s models, we are delivering the resilient blueprint required for true AI sovereignty.

You can self host Mem0 now https://t.co/uLbesDPS67

PR if you want the deets: https://t.co/PX0qKJKNC1
@7amud7amudi https://t.co/25mC2H0g2X
Wait am clarifying with gdm if this is actually allowed lmao

We parsed this SpaceX equity research PDF faster than the time it took for Screen Studio to zoom in ⚡️🔥 liteparse is now the best open-source document parsing tool out there. There’s no reason to not use it as a first pass, even if you do have docs that require heavier VLM processing downstream. Try it out now over any document: https://t.co/ErgwlItZ96 Repo: https://t.co/JNER0mVcB8
We built the fastest PDF -> markdown parser in the world 🚀⚡️ AND it’s more accurate than any other open-source, model-free parser (pymupdf4llm, opendataloader, pdf-inspector, markitdown) on 3 standardized benchmarks: olmOCR0-bench, opendataloader-bench, ParseBench Introducing L

@mizugeek https://t.co/25mC2H0g2X
Wait am clarifying with gdm if this is actually allowed lmao

@BlockedPaths https://t.co/25mC2H0g2X
Wait am clarifying with gdm if this is actually allowed lmao

@siraustin https://t.co/25mC2H0g2X
Wait am clarifying with gdm if this is actually allowed lmao

🎙🎙🎙🎙🎙🎙🎙🎙 https://t.co/70AMUO8X15
🎙🎙🎙🎙🎙🎙🎙🎙 https://t.co/70AMUO8X15
Materialism kinda slaps https://t.co/dcF8mL2VJn

AI is changing how we build software. Curiosity still matters. @clattner_llvm, CEO and Co-founder of @Modular, shares his perspective on entering the industry today. https://t.co/g8MbvvgyLF
Donald Trump will go down in history as the only US President to be outwitted by a single-celled organism. https://t.co/mjPd1IVvLO

Anthony Fauci is an American hero who kept us protected from deadly viruses for decades. The people spreading lies about him are spreading Russian propaganda because they get paid to do so. They are the real traitors. Russia would love to know what we have in our biolabs so they can use that research to hurt Ukraine who is dominating them with drones.

It’s a very simple concept, really. https://t.co/knKOCR4bMG
We just need to celebrate having kids. Happy Father's Day. https://t.co/qZRTzXJWjw

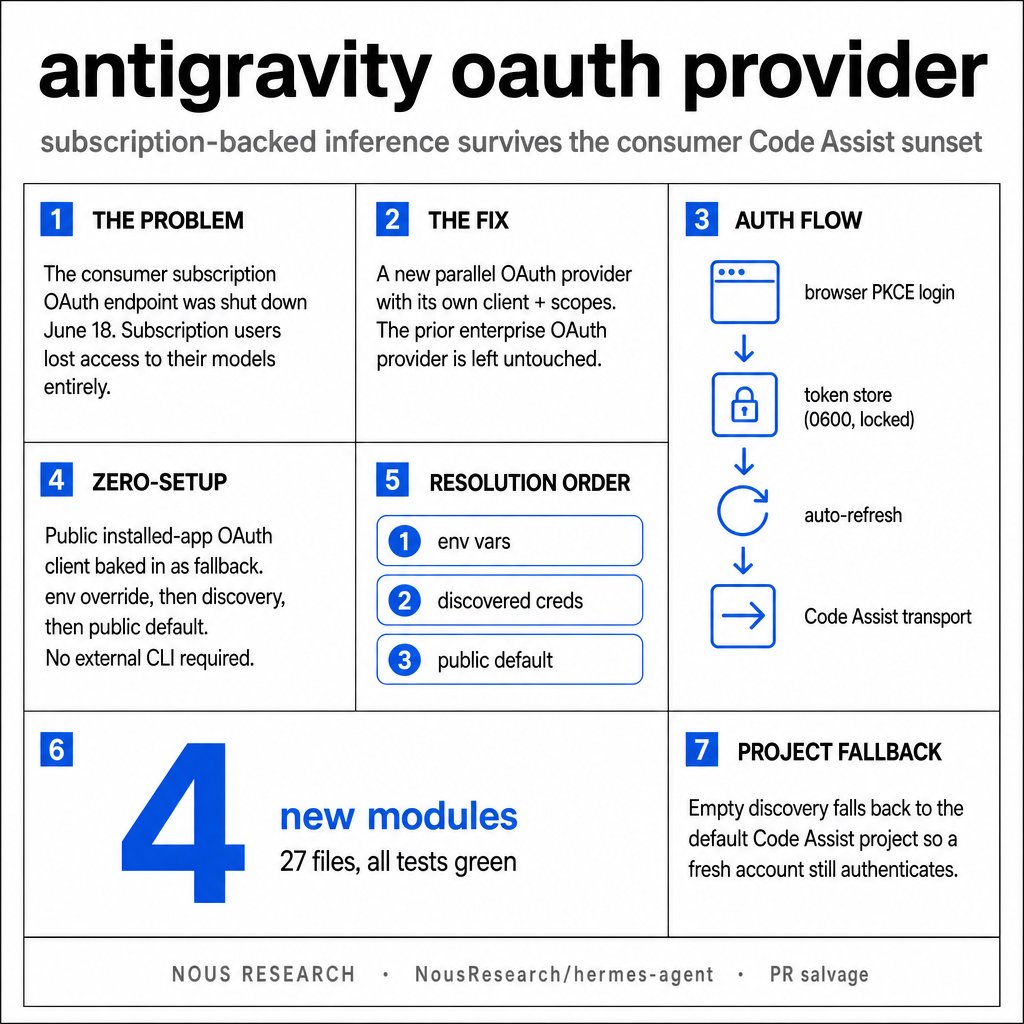
AntiGravity users should be able to access their sub's models now in Hermes :) https://t.co/9UdXGPhzOw