Your curated collection of saved posts and media
The challenge facing AI may not be technical. It may be social. People don't need to be convinced that AI is powerful. They need to be convinced that it improves their lives. https://t.co/SsFUyVeOkP


https://t.co/hcP0PPlxtS

@docjais @FelixCraftAI I've also had this sitting there for a couple weeks if you want to test it https://t.co/tZ2yOvEcF0

🚨 7,600,000 downloads. 100,000 more every day. When I started OpenMed it was one person. This week it trended on GitHub: 2,500+ stars in 7 days, 15+ new contributors who just showed up and started building. Not a founder anymore. A community. https://t.co/kyOqiwRuN9

The Emperor Has No Clothes: Why the AI Infrastructure Buildout Math Doesn't Work I have to give IBM CEO Arvind Krishna credit. He's saying what many of us in this industry have been thinking but haven't been willing to say out loud. The math just doesn't add up. Here's what I'm seeing that's deeply troubling. We're in the middle of another mass hallucination. Just like the dot-com bubble, just like blockchain, just like the metaverse — everyone is convinced that building massive data centers will automatically create massive wealth. But here's the thing about building infrastructure. You actually have to sell what's inside it. Let's talk numbers. The planned data center buildout over the next 5-10 years is staggering. We're talking about commitments in the hundreds of gigawatts globally. The capital expenditure commitments are in the trillions. Yet when you look at the actual demand signals, not the projections, not the potential, but the actual consumption patterns, there's a massive gap. These AI companies are betting everything on demand that simply doesn't exist at the scale they're planning for. Let me be direct. AI services are expensive. Enterprise adoption is slow. Consumer AI is still finding its footing. And the compute requirements being promised by the hyperscalers require a level of demand that would represent a fundamental shift in how businesses consume technology. That's a big ask. I've seen this pattern before. The overbuilding. The belief that if you build it, they will come. The groupthink that turns critical analysis into heresy. The result is always the same. Companies are going to touch the stove. We're going to see massive write-downs. We're going to see pivots, shutdowns, and strategic reviews. We're going to see companies that spent years and billions trying to be the AI infrastructure leader become case studies in how not to read a market. The IBM CEO is right. The math doesn't work. And unlike 1999, we don't have the excuse of we didn't know. We know exactly what's happening. We just don't want to believe it because the alternative, being a skeptic while everyone else is piling in, feels like career suicide. It's not. The ones who survive the next decade will be the ones who built for reality, not fantasy. Wake up. The emperor has no clothes. As reported by Futurism, Krishna laid out striking calculations: a 1 gigawatt data center costs roughly $80 billion today. If one company commits 20-30 gigawatts, that's $1.5 trillion in capital expenditure. The total commitments across the industry for chasing AGI are approximately 100 gigawatts, equaling $8 trillion. To break even, you'd need $800 billion in profit just to cover the interest. That's not investment. That's hoping. https://t.co/4DAnF5OPfa

Quake turns 30 today. 🎉 Three decades later, you can still dig into the source code that helped shape modern game engines, multiplayer networking, and modding communities. 🎮 https://t.co/mV5q4YdPRM https://t.co/YJh95WTXp5
Awesome Hermes Agent repository reached 4k+ stars! Lot's of updates outstanding - will work them off this week. Hermes Agent is being developed by @NousResearch https://t.co/Sv2aSu2n8X

ahh the diffs are beautiful now @NousResearch https://t.co/gtpB1qW9LJ
Deepset helps companies move from gen AI prototypes to production fast. Through collaboration with AWS, @deepset_ai co-develops solutions aligned with the AWS gen AI strategy, helping organizations operationalize AI with speed and reliability. As part of the @nvidia Inception Program, Deepset uses GPU-powered EC2 instances and NVIDIA NIMS components to build scalable, high-performance applications.
Celebrated 24th Father's Day with my incredible dad @Cornellian1988 My dad is one of the smartest, wisest, kindest and funniest people I know. He works hard every single day to support our family which allowed me and my sister @sopranotiara to pursue our dreams, and I have learned so much from him. He has taught us many important life skills, such as recently teaching us driving (we successfully got our driver's license last week!) I am so grateful to have the best father in my life.


@SakanaAILabs Can I just say I love they you guys have art like this. Makes the future nice to look forward too https://t.co/tpMqGU8oDr

Two of the most important biomedical breakthroughs came from science of the Gila lizard venom (GLP-1s) and yogurt (CRISPR genome editing). "The system that turned that lizard into a medicine is now being dismantled." "Less support for scientists means strange questions no one will get to chase." gift link https://t.co/JKEzQCGm75

🚨🚨🚨A standing ovation for the Washington Post, @wapo . 👏👏👏 You spent a full year investigating whether America's Director of National Intelligence, the woman with access to every classified secret this country has, was being directed by a cult leader who got busted for pyramid schemes in multiple countries. And you held it until she resigned? This same cult leader, Chris Butler, has his sect directly tied to QI Group (QNET), a Hong Kong-based company with operations across Asia, Africa, and the Middle East. So the real question: Which countries now have access to our national intelligence? Which of our spy names are compromised? And let's not forget, this is the same Tulsi Gabbard who used her position to do a coordinated hit job on Dr. Fauci, a man who spent his entire life saving Americans. Imagine if this story dropped while she still had her hands on our nation's secrets. Our press and mainstream media are failing us at every level. https://t.co/XHlqQZnSNx

Sakana AI、一部「ミュトス越えの性能」うたうAIを提供 複数モデルの“集合知”を活用 https://t.co/B1e7a6SLYR

Sakana AI、一部「ミュトス越えの性能」うたうAIを提供 複数モデルの“集合知”を活用 https://t.co/B1e7a6SLYR

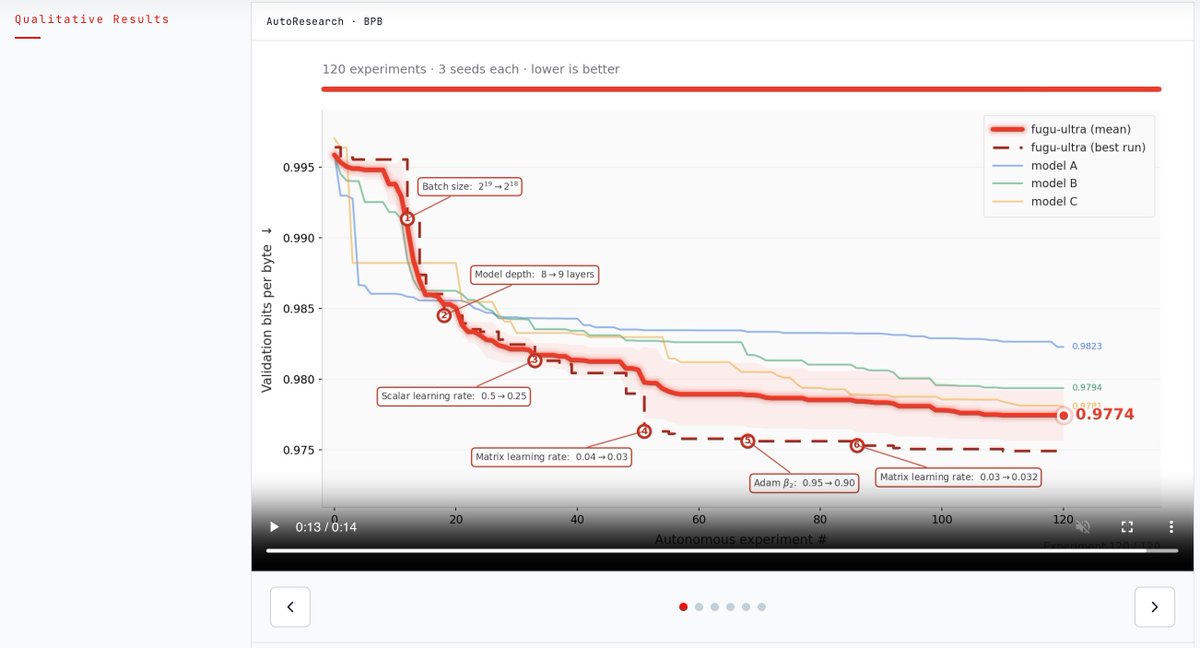
Tried & liked it on https://t.co/7gOqjtmSJ3. Fugu Ultra pairs well as a advisor & planner with Composer 2.5. For scope/architecture, it’s on par with Fable orchestration. Advisor doesn’t slow the loop if the driver stays fast & https://t.co/9cL4HqvqSf can split it from worker.
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡

Tried & liked it on https://t.co/7gOqjtmSJ3. Fugu Ultra pairs well as a advisor & planner with Composer 2.5. For scope/architecture, it’s on par with Fable orchestration. Advisor doesn’t slow the loop if the driver stays fast & https://t.co/9cL4HqvqSf can split it from worker.

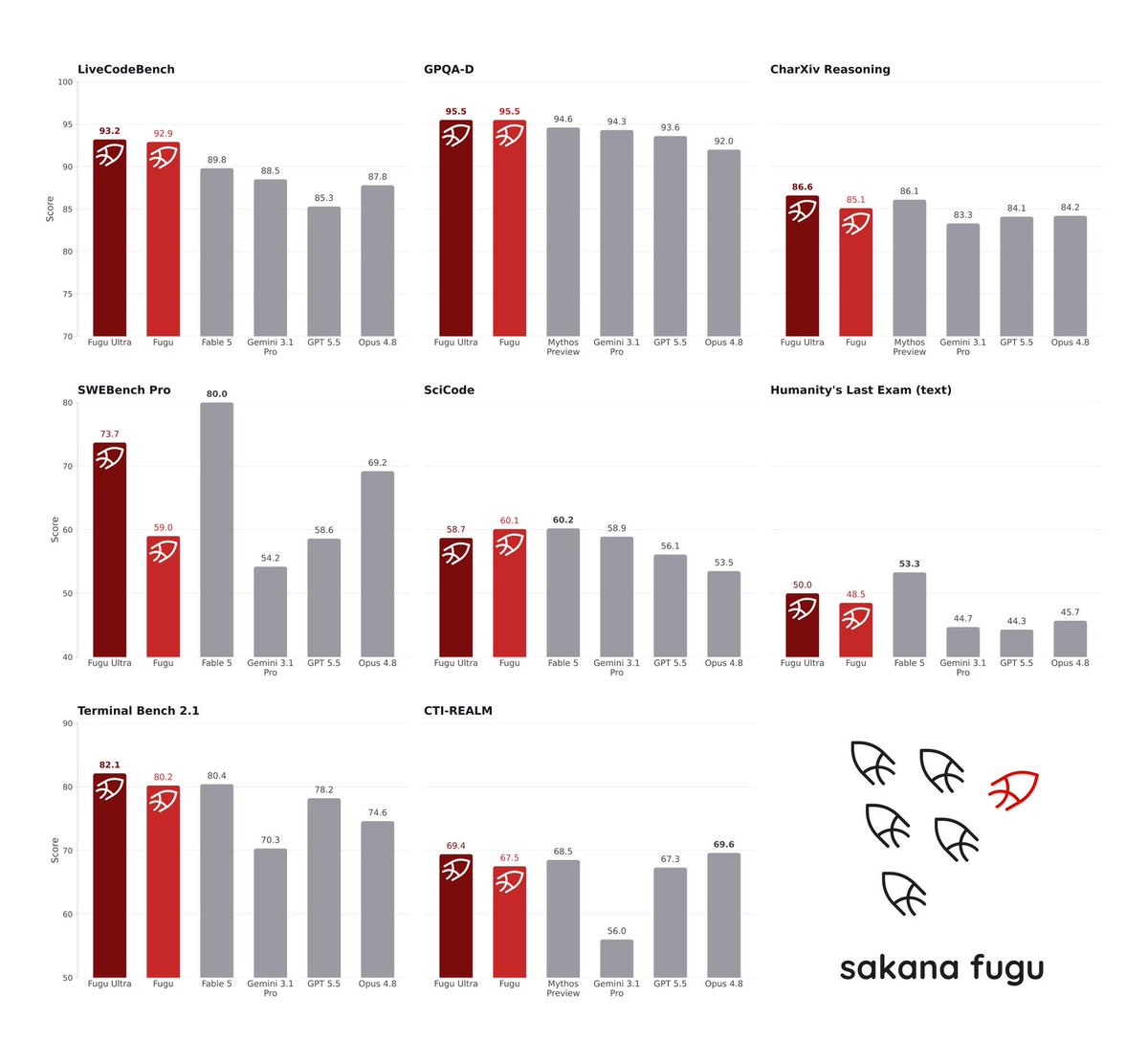
Another new idea to push the state of AI architectures forward. Sakana released a model that effectively uses a mixture of models to get work done. You get a single API but then the work gets farmed out the model that best performs the task. “Fugu manages model selection, delegation, verification, and synthesis automatically. It solves tasks directly when that is enough, or coordinates a team of expert models when a problem calls for more. The complexity of a multi-agent system never reaches your code.” This is generally how applied AI products are building their agent harnesses at this point, but the idea of making this an LLM that any developer can interact with is also a great idea. As we get more innovation with both frontier closed and OSS models, there’s going to be a ton of value produced for the layer that can route the best.
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡
🐡 Sakana Fugu リリース 🐡 マルチエージェントを指揮する、一つのモデル ブログ:https://t.co/8Bac6JpVEN 本日、Sakana AIは新しいプロダクト「Sakana Fugu」の提供を開始しました。Sakana Fuguは、最先端のモデル群からなるマルチエージェントシステム全体を、単一のモデルAPIとして提供します。 難しいタスクは、強力なモデルを一度呼ぶだけでは解けません。どのモデルを使い、タスクのどの部分を委譲し、どう検証し、強みをどう組み合わせるか。Sakana Fuguは、その「協調の仕方」そのものを学習した言語モデルです。一つのAPIにリクエストを送るだけで、背後で専門モデル群を自動的に連携させ、フロンティアレベルの性能を複雑な運用なしで引き出します。 詳しくはこちら: https://t.co/hhO6qTawgb 🐡
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡


🐡 Sakana Fugu リリース 🐡 マルチエージェントを指揮する、一つのモデル ブログ:https://t.co/8Bac6JpVEN 本日、Sakana AIは新しいプロダクト「Sakana Fugu」の提供を開始しました。Sakana Fuguは、最先端のモデル群からなるマルチエージェントシステム全体を、単一のモデルAPIとして提供します。 難しいタスクは、強力なモデルを一度呼ぶだけでは解けません。どのモデルを使い、タスクのどの部分を委譲し、どう検証し、強みをどう組み合わせるか。Sakana Fuguは、その「協調の仕方」そのものを学習した言語モデルです。一つのAPIにリクエストを送るだけで、背後で専門モデル群を自動的に連携させ、フロンティアレベルの性能を複雑な運用なしで引き出します。 詳しくはこちら: https://t.co/hhO6qTawgb 🐡

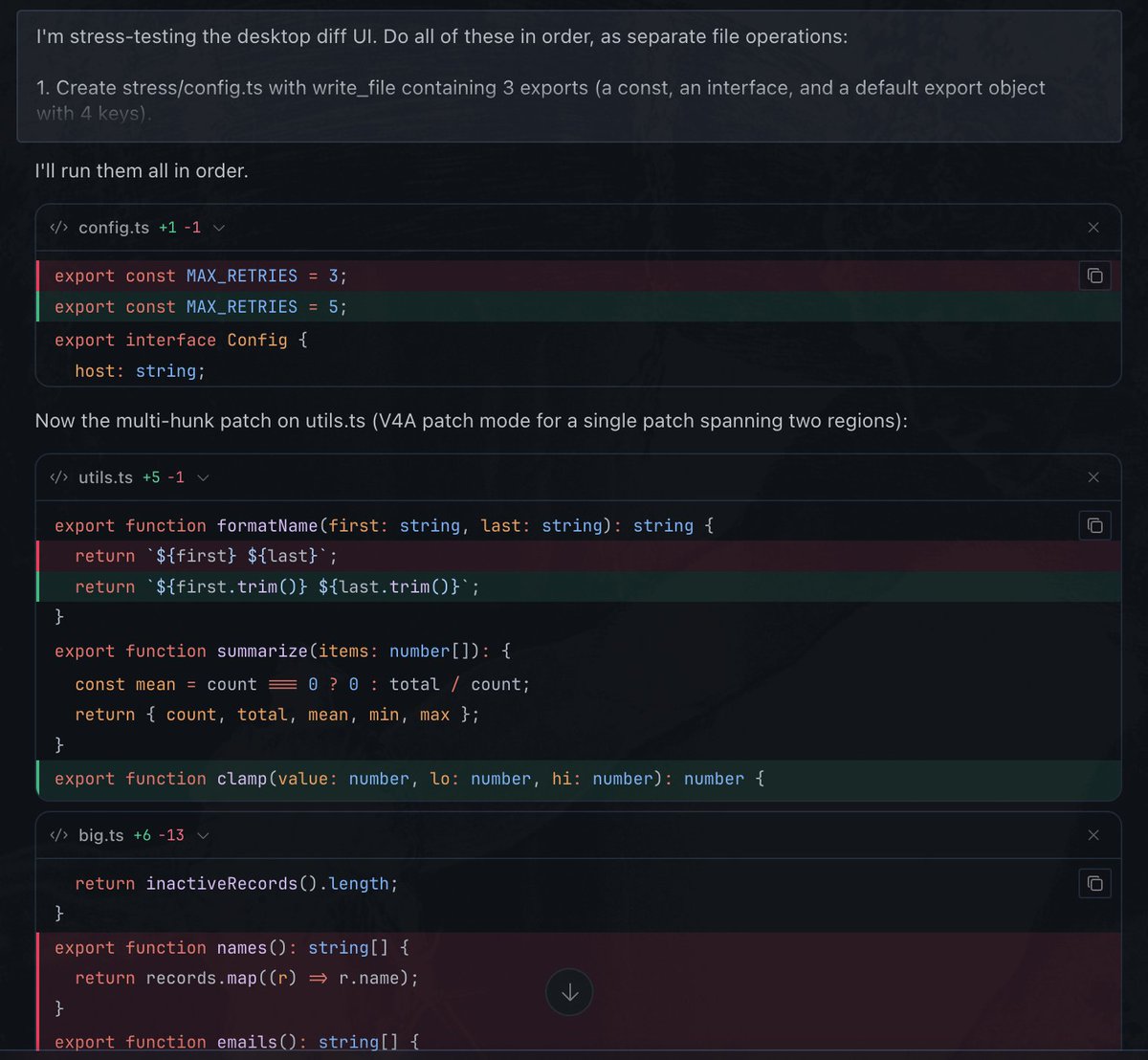
Set up codex wow. https://t.co/T1nBMXeODE
I thought peptides were mostly an internet thing before I walked into a clinic in SF and they had them all laid out like a choose-your-own-adventure brochure https://t.co/mgR7BQIGGN

anon if you have a dgx spark, the best model to run in 2026 is stepfun's step 3.7 flash. i called it the day it dropped, and after living with it on the box i'm saying it louder now. what you're looking at is a 198B mixture of experts vision language model, ~11B active per token, Q4_K_S at ~104gb, running on a single 128gb dgx spark under hermes agent. one machine. it holds the full 262K context at ~25 tokens a second and takes image input. i measured that speed myself at full context. reasoning, vision, frontier size, all of it fitting and running locally on one box. people keep asking what's actually worth running on 128gb of unified memory. this is the answer, and has been since launch. if you bought a spark to run frontier models locally instead of renting them, this is the one to put on it.
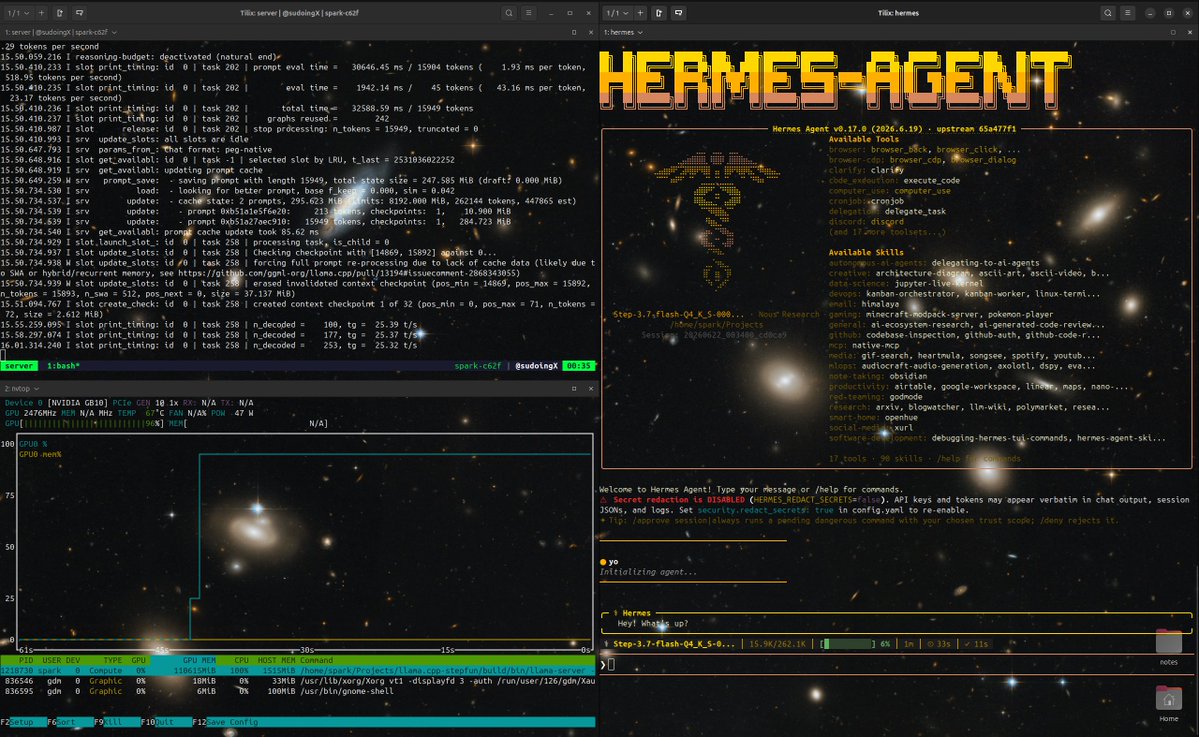
Hermes Bible got 15,000 page views in 24 hours. 5,600+ visitors. 15,000+ page views. Did not expect that. Thank you for all the feedback. We now have 26 Hermes flows live and I’ll keep adding more daily. Biggest request was: “Can we get all flows in markdown so agents/local LLMs can read them?” Done. One URL. All flows. Agent-readable. Link in the comments 👇 https://t.co/stRxaMYkPu

とうとうFuguがリリースされました! 世界最先端のモデル群をOrchestrationすることで、FableなしでもFableに迫る・越す性能を発揮します。 最先端AIのどれを使うか自分で迷うことなくタスクごとに最適なLLM、最適なWorkflowをFuguが毎回動的に構築しタスクをこなしてくれます。 実際にタスクをこなすのはFrontier modelなので、研究のトレンドの最先端で注目されているLong horizonなSWEタスクなどももちろんスコープ内です。 Qualitative resultsにも面白い事例がたくさん乗っています〜 是非お試しくださいっ
I’m 17 and raised $3.2M for @forgegui. Our seed round was led by @michaelfertik and @bonatsos at @VerdictCap with other investors including @cory, @collectiveGBL, @sheeltyle, and other amazing partners. In ~2 months, we’ve grown to 90,000+ game dev users, with a current $40M cap. Growing extremely fast. I’ve been building in this space for 7 years, since I was 10. We’re building the AI platform for game developers. We’re hiring 2 more cracked engineers who want to help build a generational company. DM me if you want to join.
Every technology revolution eventually faces the same test. Not whether it works. Whether enough people believe it works for them. https://t.co/xldsyplP0j

Want to chat with your Hermes Agent on iMessage without a Mac? The latest v0.17.0 update made this possible (and super easy)! I made a quick video showing how to get this all set up in less than three minutes. Enjoy! https://t.co/N0mfxHUagJ
@BeingJonG So far no major catastrophes 😂 It's cad was a little wonky but functional for my purpose. It had a bug in the code that resulted in some overextrusion but fixed it when I suggested it (2nd pic is bug). For now I've taken back control w/ codex's scripts and am having lots of fun https://t.co/YVIIMZw24j


Seems like with a little tweaking I can get some watertight ~100um channels with PLA directly on a glass slide w/ a cover slip melted on. Only had a few hours to get it going today, will tweak it and try to dial it in tomorrow. Goal: DIY microfluidic algae cell sorting! https://t.co/JQpQ3UZd0I


@TonyW @SakanaAILabs Thanks, Tony! Indeed, this was the vision from the beginning: https://t.co/D1cEX0noMl
@TonyW @YesThisIsLion @SakanaAILabs @500GlobalVC That’s where we saw the AGI xrisk owl!

Top AI papers on @huggingface this week: looped world models, real-time VL agents, and 3B reasoning marvels - Looped World Models — first looped architecture for world simulation, 100x parameter efficiency - LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling — 2 loops is the surprising sweet spot for code reasoning - JoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence — an always-on vision agent that decides when to speak - Data Journalist Agent: Transforming Data into Verifiable Multimodal Stories — a fully autonomous virtual newsroom - Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance — 15x faster than 10B rivals - VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models — 3B model rivaling DeepSeek V3.2 and Gemini 3 Pro - DreamX-World 1.0: A General-Purpose Interactive World Model — interactive world generation at 16 FPS - OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data — director-level camera motion control - Geometric Action Model for Robot Policy Learning — 3D geometry-native robot policies - FastContext: Training Efficient Repository Explorer for Coding Agents by @microsoft — cuts coding agent token use by 60% Find them below:
