Your curated collection of saved posts and media
Deploy safe robots without rebuilding safety from scratch. 🦾 NVIDIA Halos for Robotics extends the Halos safety system, built on 18,000+ engineering years of AV safety engineering, to industrial robots, humanoids, and AMRs, combining AI compute and functional safety in one platform. Now available: Halos Core on IGX and the open-source Halos Outside-In Safety Blueprint. Get started: https://t.co/Sf4QbSv6cd #Automate2026


Guess which is Fugu Ultra? This is how recent models compare when generating endless procedural terrain (using Three.js). All of these are one-shotted! Just wild! Trying a few more examples. Will share soon! https://t.co/lLxCJZDUxd
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡
@NousResearch @trycua Time to jam https://t.co/KRWXVOZxgE


Hermes Agent now supports computer use via @trycua on Windows and Linux in addition to existing macOS support https://t.co/62BdC5QdhL
@PromptLLM https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

Day 8 of #12daysofChatCodexStratfin on how OpenAI's finance team uses Codex. Stacy Young uses Codex to reinvent how we forecast and operate OpenAI's Ads business. Before Codex 🙁 Ads is one of our newest—and spikiest—businesses. Demand shifts with user behavior, weekdays, holidays, and seasonality. We maintained separate monthly and weekly forecast models, then spent countless hours reconciling them every time assumptions changed. Agentic dawn 🙂 We taught Codex how our Ads business works. Now it automatically translates our monthly plan into weekly and daily operating forecasts, with richer weekday and holiday logic than our old models. The bigger unlock was the app the team built around it. Every historical and current forecast now lives in one interactive Python application where we can: • Compare forecast versions • Toggle across daily, weekly, and monthly views • Slice metrics by any dimension • Track actuals against plan No coding background required. Instead of fighting spreadsheet complexity, Stacy now spends her time asking better questions and exploring the business from more angles.
Our new incident response report exposes a coordinated network of 340 Facebook pages, largely operated from Vietnam, flooding feeds across Canada, the US, the UK, and Europe with AI-fabricated news, and inadvertently funded by Canadian public and private advertisers. 🧵 https://t.co/jpbMhBlp2v

@0xCodez https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@0xCodez https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@realBigBrainAI https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@sickdotdev https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

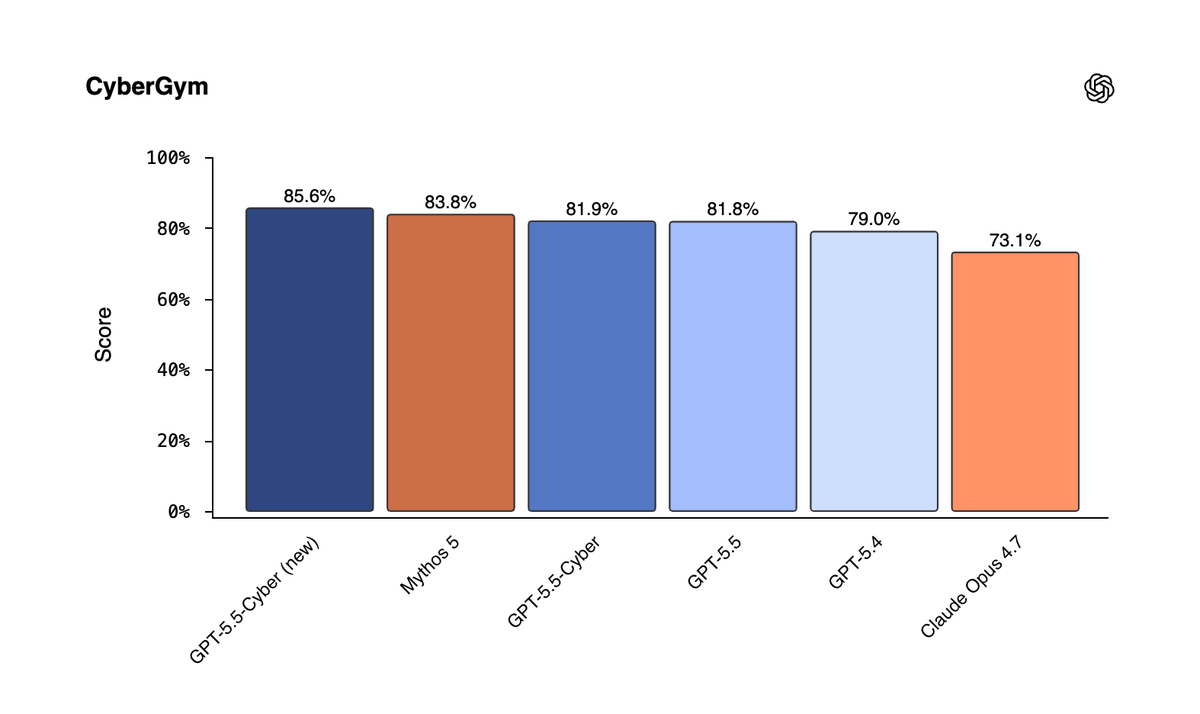
We want to help all companies be secure, working with the USG and the security ecosystem. *The full version of GPT-5.5-Cyber is here; state of the art performance on CyberGym. *Patch The Planet and Codex Security will help solve security problems instead of just finding them. https://t.co/otyCFHJR4d
.@impeccable_ai earned its way to 40k+ stars on GitHub by delivering exceptional value. Today, we are making design and quality a built-in layer for all creators: Impeccable is now a built-in skill in the GitHub Copilot app. AI raised the floor. We’re here to help raise the ceiling.

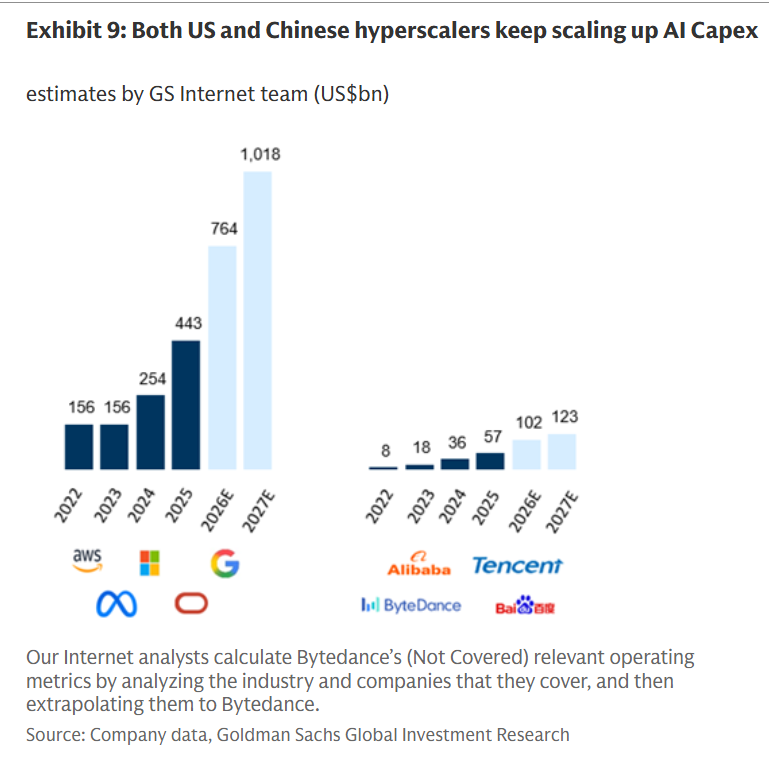
Astonishing difference between US and Chinese AI capex, even after taking into account differences in PPP https://t.co/mwXf2wEF8m
New piece in @TheAtlantic! We always hear that AI will cure cancer, and I would immediately benefit if it did. But I argue that racing ahead on generalist AI models creates unclear benefits for cancer that are outweighed by broader societal harms. (Gift link in next post) https://t.co/hMhhwJUJtS

@dqpeless Original paper: https://t.co/8HgKdpndeZ https://t.co/vL8ujM5EgL

@LucaAmb @SakanaAILabs https://t.co/GuUpVaRGBJ
What’s wrong with this post? Well they say “Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.” but this claim is obviously nonsense. Their model is a closed source router for clouded models

@iarthsingh @SakanaAILabs https://t.co/GuUpVaRGBJ
What’s wrong with this post? Well they say “Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.” but this claim is obviously nonsense. Their model is a closed source router for clouded models

@RichardTran1101 @SakanaAILabs https://t.co/GuUpVaRGBJ
What’s wrong with this post? Well they say “Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.” but this claim is obviously nonsense. Their model is a closed source router for clouded models

@ianjcam @SakanaAILabs Sorry, I assumed this would be mostly seen by people familiar with the extensive history Sakana of lying about their results since I criticize them regularly. https://t.co/MrYE3yTyyh
This comment seems to have upset a lot of people unfamiliar with Sakana’s history, so here’s a more detailed description of why I view their claims as false by default and view the company as largely fraudulent.

@Samrn888 @SakanaAILabs https://t.co/oMy1FPQDHK
This comment seems to have upset a lot of people unfamiliar with Sakana’s history, so here’s a more detailed description of why I view their claims as false by default and view the company as largely fraudulent.

@stalkermustang @SakanaAILabs Sorry, I assumed this would be mostly seen by people familiar with the extensive history Sakana of lying about their results since I criticize them regularly. https://t.co/MrYE3yTyyh
This comment seems to have upset a lot of people unfamiliar with Sakana’s history, so here’s a more detailed description of why I view their claims as false by default and view the company as largely fraudulent.

TiKZ unicorn https://t.co/xdR6Upa6yr

Now let’s talk about the AI scientist saga: As soon as people started using the system it became clear that the claims about it and the examples they released were not remotely grounded in the model’s actual abilities. Here’s one example: https://t.co/htrSGO9wJv https://t.co/59V3snL4ZL

They later claimed that the system “passed the peer-review process” when what really happened was one of the three papers they submitted received reviews that were marginally above the acceptance threshold. We don’t actually know if it would have passed https://t.co/Cm9GcSTdTY

https://t.co/vVg1iBJQhd

https://t.co/vVg1iBJQhd

In their AI CUDA Engineer work they reported results that were not just bugged but obviously impossible. As both Tri Dao and I quickly noticed, they claimed speed ups for real workloads that outperformed the theoretical max of the GPUs. https://t.co/eoYvEtkevJ
A heuristic always worth checking when it comes to compute-efficiency: are they claiming to beat the maximum theoretical FLOPS that the hardware supports? They claim their kernel beats the hardware's theoretical max here by a factor of 30x!

o3-mini-high figured out the issue with @SakanaAILabs CUDA kernels in 11s. It being 150x faster is a bug, the reality is 3x slower. I literally copy-pasted their CUDA code into o3-mini-high and asked "what's wrong with this cuda code". That's it! Proof: https://t.co/whmF5fvHVr Fig1: o3-mini's answer. Fig2: Their orig code is wrong in subtle way. The fact they run benchmarking TWICE with wildly different results should make them stop and think. Fig3: o3-mini's fix. Code is now correct. Benchmarking results are consistent. 3x slower.


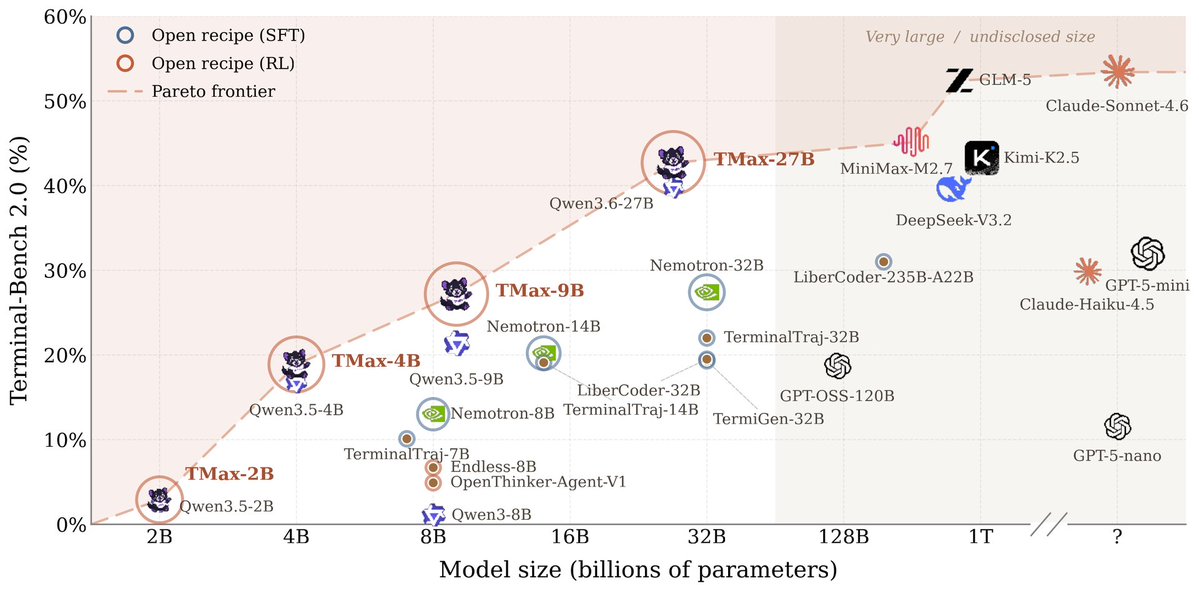
Ai2 just released their Qwen 3.5 9B terminal agent on Hugging Face Built with DPPO on the OpenThoughts dataset, it leads the TMax ablations with 53.0% on Terminal Bench Lite. https://t.co/E8PN1wB6fl
@TheStalwart We tried this One-Shot Blindfold Chess task, between Opus, GPT, Gemini Pro, 2100-Elo Stockfish engine, and Sakana Fugu Ultra: https://t.co/e0k5w3j2fE
Use Case 3: One-Shot Blindfold Chess Can an AI hold an entire game state in memory without drifting? To test Fugu Ultra’s persona stability and sustained memory, we had it play 4 back-to-back games of blindfold chess. Every model played the same way: no board shown, requiring t
