Your curated collection of saved posts and media
From word vectors to Reinforcement Learning from Human Feedback... Stanford's "Natural Language Processing with Deep Learning" course is one of the most relevant and best AI/ML courses today. It's just amazing how much knowledge and content this course pushes out every year.… https://t.co/bA2ASgHSHU https://t.co/kEAPT7a0xa
Interesting note about translation models and the original transformers paper https://t.co/VNpOYHFfSH

https://t.co/4n2b8GGk0k email for 28th July is out https://t.co/PSHdlPpu8M

LLM hacking is becoming a huge problem. Malicious images and sounds can now be used to modify the behavior of LLMs. They can even be embedded in a website or email attachment. Another recent paper showed that adversarial suffixes can disrupt the behavior of open source LLMs… https://t.co/qHVYY4V0h3 https://t.co/SuRXO1cPho

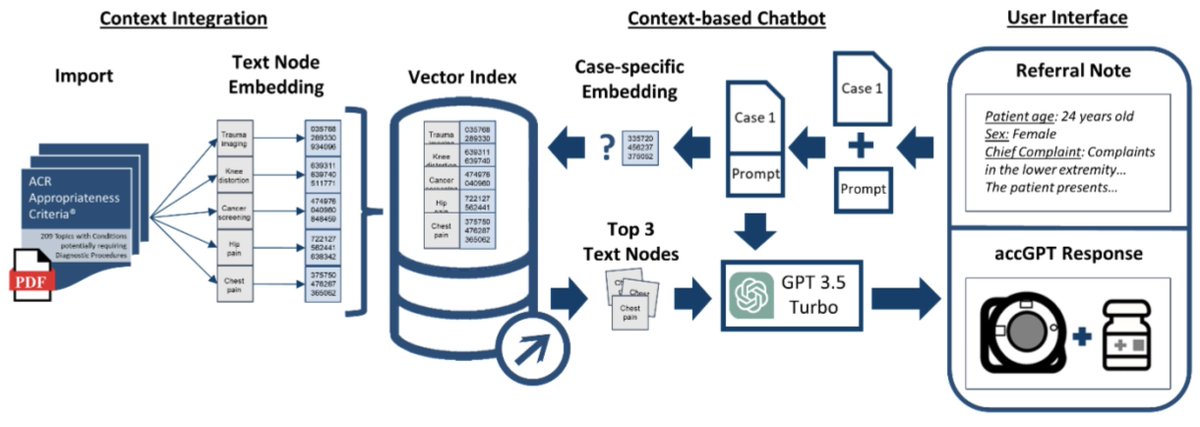
This is a cool medical paper showing how ChatGPT + @llama_index can help determine whether clinical case files adhere to a large corpus of radiological imaging guidelines. 🥼 This system is as good or better than humans 🔥 (and also far cheaper!) https://t.co/IaG7rmCEVs https://t.co/m2HbccETW9
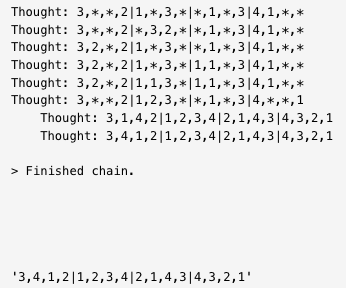
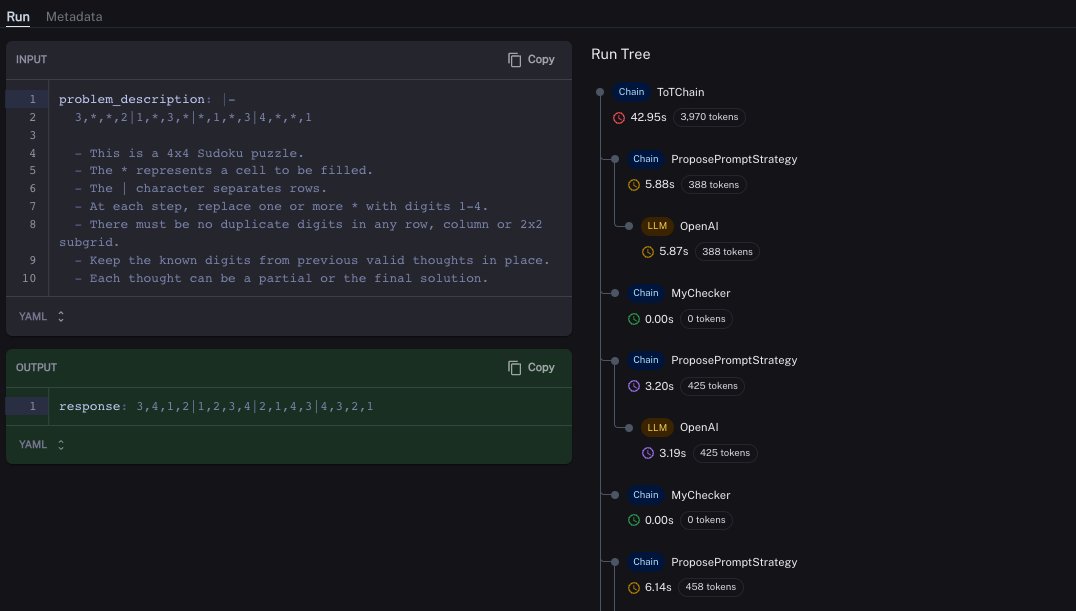
🌳Tree-of-Thought A new reasoning method, originally by @ShunyuYao12, implemented in 🦜🧪langchain_experimental by Vadim Gubergrits Paper: https://t.co/8sVhTXP5c2 Docs: https://t.co/jpeJLutxrK LangSmith Trace: https://t.co/BKkpTpFPHq https://t.co/XPoevx4chE
Video games are fine! Studies measuring real players playing games find small to no effects. In fact, gaming is correlated with slightly higher happiness & (in a small study) families who gamed together were happier. And there is no link between violent games & real aggression. https://t.co/354UqInZlc

PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback paper page: https://t.co/mnLbtWqxic Large Language Models for Code (Code LLM) are flourishing. New and powerful models are released on a weekly basis, demonstrating remarkable performance on the code… https://t.co/MZrii7CTdx https://t.co/YoCEJmH0In

JUST IN: StackOverflow Announces OverflowAI! It allows you to interact with the platform in a chat interface and aggregate the 58 million answers. Features: ▸ LLM-based search and question asking ▸ Pair-programming (Visual Studio Code extension) ▸ Enhanced search for… https://t.co/CSu7cRGdrq https://t.co/OHlPkKd3a9
Reparameterized Policy Learning for Multimodal Trajectory Optimization paper page: https://t.co/U4hfleRZvM We investigate the challenge of parametrizing policies for reinforcement learning (RL) in high-dimensional continuous action spaces. Our objective is to develop a… https://t.co/51VEttH8i5 https://t.co/0Z9EkJkd3c
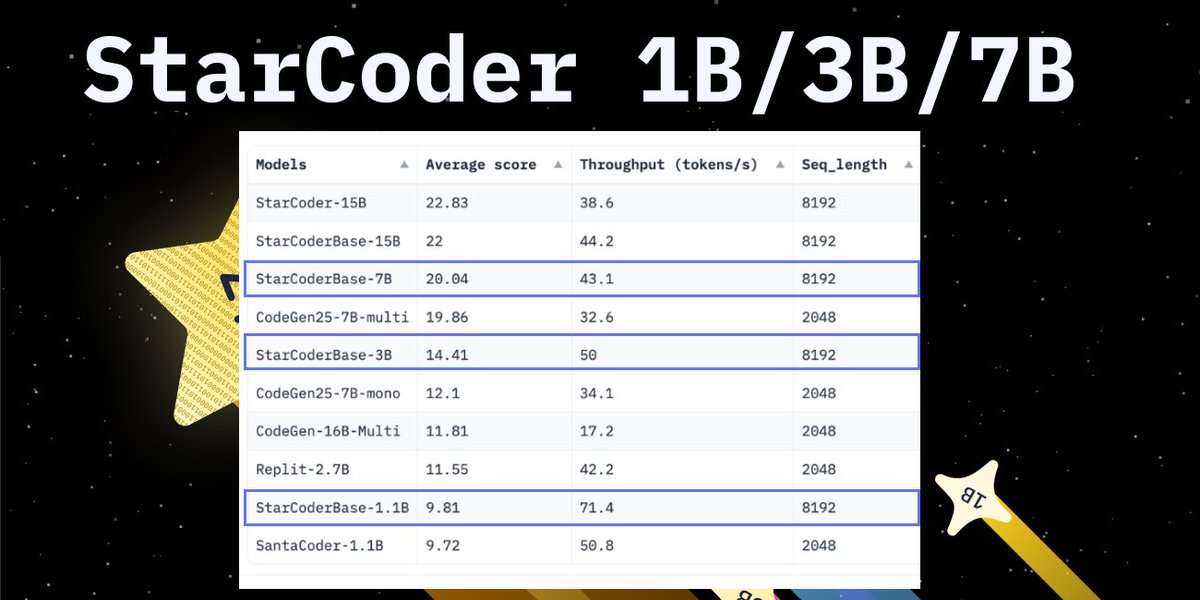
Exciting news for the StarCoder cosmos!✨ The team just released new smaller StarCoder models for edge and on-device code generation - introducing the 1B, 3B and 7B models. 📱 🧵 1/3 https://t.co/tjYjuE5yNC
trajdata: A Unified Interface to Multiple Human Trajectory Datasets paper page: https://t.co/LmuoJsuv86 The field of trajectory forecasting has grown significantly in recent years, partially owing to the release of numerous large-scale, real-world human trajectory datasets for… https://t.co/rPbJCLi1e3 https://t.co/UIs0TKy0Yp

Towards Generalist Biomedical AI paper page: https://t.co/j6MFJn6Q1C Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and… https://t.co/3P0AbA327S https://t.co/AfUXYpAwjc

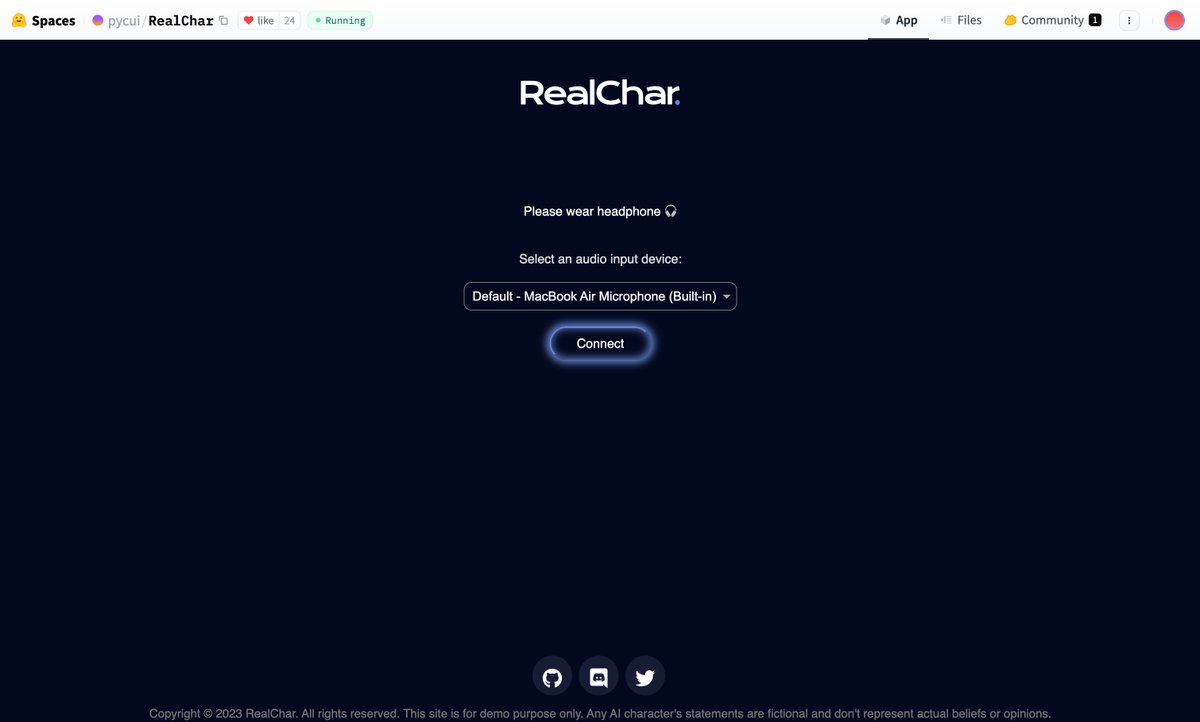
How do you deploy your own @RealCharAI on @huggingface for free within 1 min? Only 3 steps: - Duplicate space - Set OpenAI key & 11labs key - Wait & Done! 👇🧵Step by step guidance https://t.co/blFOBDRBsn
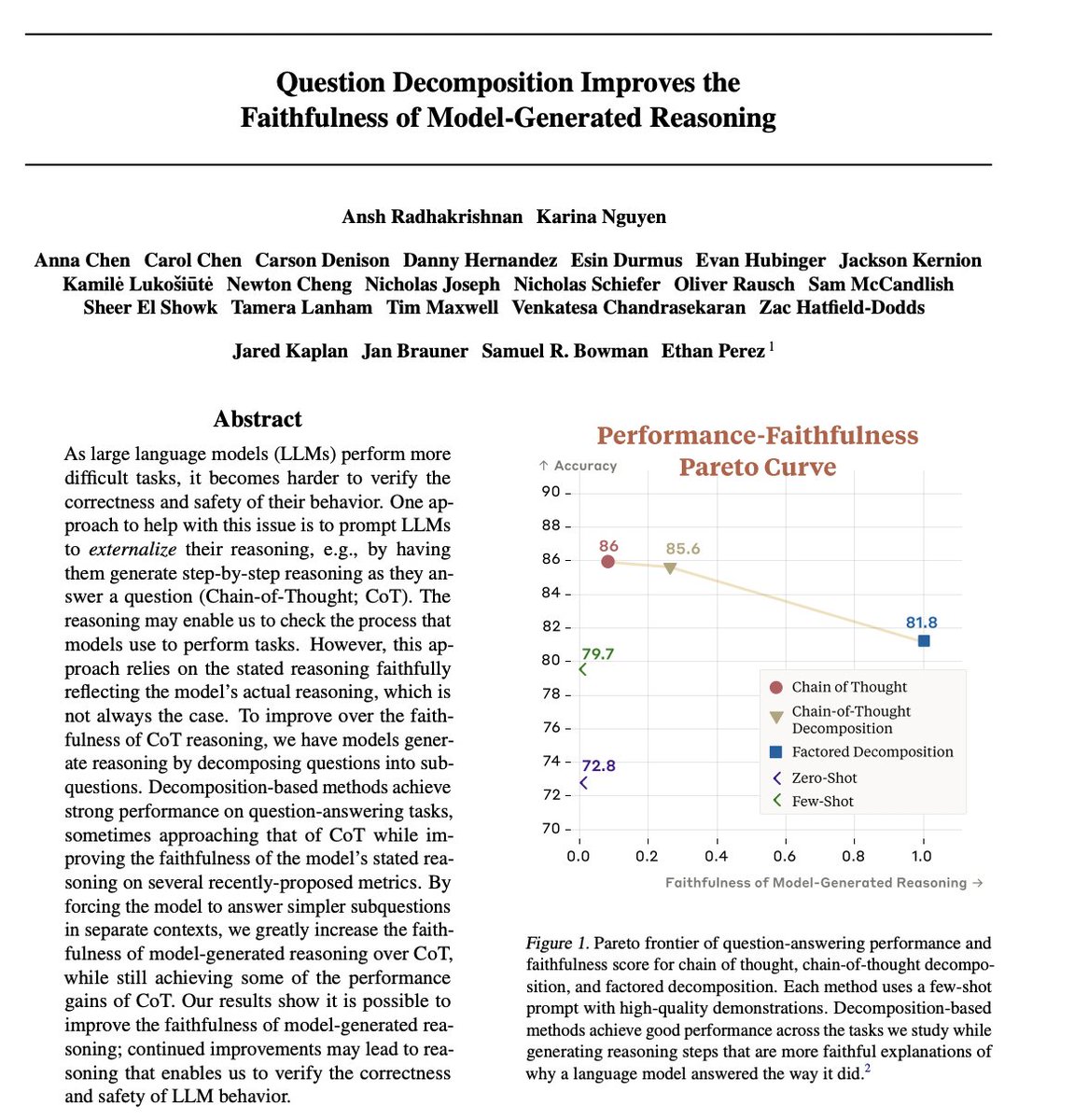
Measuring Faithfulness in Chain-of-Thought Reasoning paper page: https://t.co/TUvsqzWLam Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a… https://t.co/5HJCwO4Pfe https://t.co/9qEIlDKt9P

There is a guide that is part of the Llama 2 release but didn't get much attention. It's a neat resource with guidance and best practices on how to build more responsibly with LLMs. It contains tips for fine-tuning the models, data preparation, mitigating risks, evaluation,… https://t.co/wPHAqKdCld https://t.co/1aDm0vC0zV

Insightful paper on how good (but not perfect) AI can hurt human work: the danger of “falling asleep at the wheel” Recruiters given high-quality AI to use became careless & less skilled in their own judgment as they delegated more of their thinking to AI https://t.co/51YmIdK5vU https://t.co/jVCSEoUb6X

Saw this on @_akhaliq 's daily papers today. Still find it so crazy that my friend @mengk20 basically created this subfield of LLM interpretability during his sophomore year at MIT (undergrad!). Some folks are just too cracked. https://t.co/v3rUsDaiev https://t.co/RP8bbIgUJM

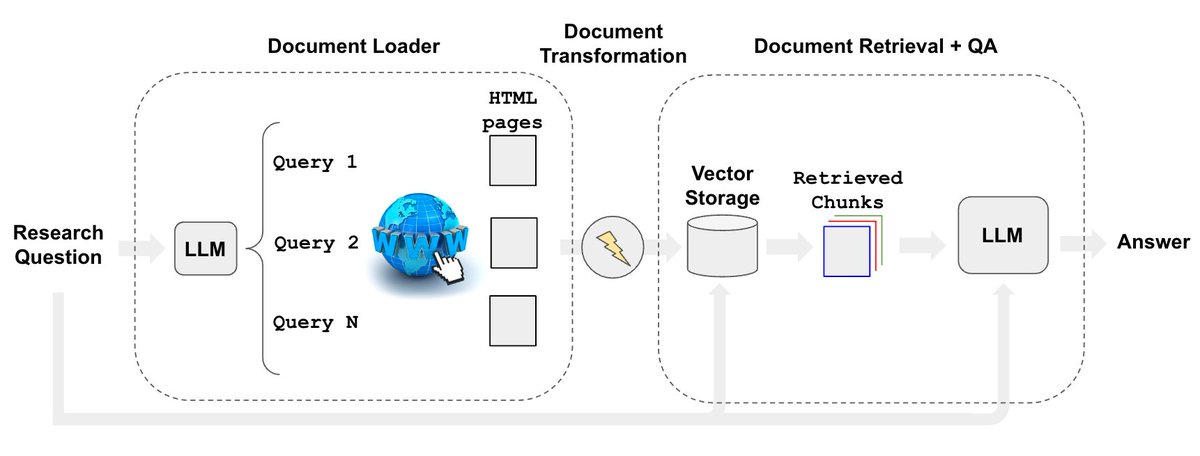
Web research is a great LLM use case. @hwchase17 and I are releasing a new retriever to automate web research that is simple, configurable (can run in private-mode w/ llamav2, GPT4all, etc), & observable (use LangSmith to see what it's doing). Blog: https://t.co/wYPCCHSNDN https://t.co/LU0PWDmrBE
Predicting Code Coverage without Execution paper page: https://t.co/owJWztvdaG Code coverage is a widely used metric for quantifying the extent to which program elements, such as statements or branches, are executed during testing. Calculating code coverage is… https://t.co/0E9UBah6kj https://t.co/zFF1z57xtI

LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition paper page: https://t.co/fRIjjCtmBA Low-rank adaptations (LoRA) are often employed to fine-tune large language models (LLMs) for new tasks. This paper investigates LoRA composability for cross-task… https://t.co/Lp260V2tIr https://t.co/jDC5qPNODp

Here is a nice concise summary of the state of LLMs. It contains some very good references to dive deeper. This combined with Karpathy's "State of GPT" talk are some of the best summaries I've seen on the current developments/trends of LLMs. https://t.co/D9eNRkyzpY https://t.co/dgzQZZs8AZ

If you'd have told me 2 or 3 years ago that a real-time wastewater surveillance algorithm would become the primary way to detect Covid on the rise, I wouldn't have believed it. But it is now: https://t.co/MafNWQbY3h @PNASNews @MathematicaNow @belmusse https://t.co/wKZB9lBNsg

llama2-webui github: https://t.co/YqS4g2ktr1 Run Llama 2 locally with gradio UI on GPU or CPU. Supporting Llama-2-7B/13B/70B with 8-bit, 4-bit. Supporting GPU inference (6 GB VRAM) and CPU inference https://t.co/Q8bPwfjAZQ
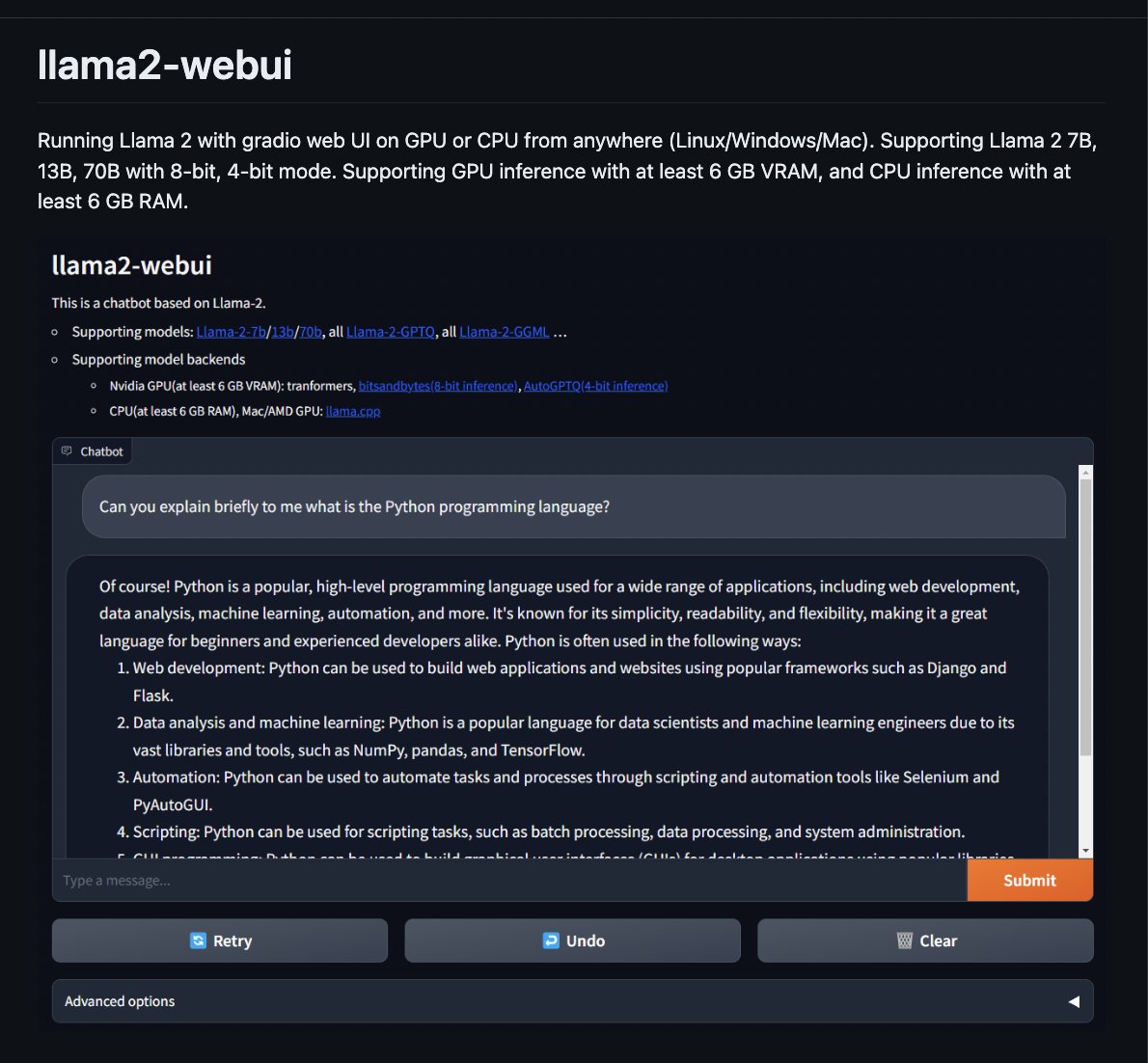
On a train back home right now, decided to play around with llama 2 & llama.cpp ♥️ Fairly spiffy on my M2, and you can also give it personas by playing around with the system prompt! 👀 Want to try it out for yourself? Check it out here: https://t.co/uRjZZA6wPw https://t.co/If7r3GJh3k https://t.co/2FNIfcBNwN
What happens when we try to create a browser extension with GitHub Copilot? 👀 https://t.co/TaTkNgVV2F https://t.co/OFg1CqjUif
MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features paper page: https://t.co/g2NlbmWher Self-supervised learning of visual representations has been focusing on learning content features, which do not capture object… https://t.co/SM4Hqwe51o https://t.co/ahZviHf3HQ

3D-LLM: Injecting the 3D World into Large Language Models paper page: https://t.co/ul4KahBQgM Large language models (LLMs) and Vision-Language Models (VLMs) have been proven to excel at multiple tasks, such as commonsense reasoning. Powerful as these models can be, they are not… https://t.co/gISEf7QjSt https://t.co/SWichi6hTJ
RLCD: Reinforcement Learning from Contrast Distillation for Language Model Alignment paper page: https://t.co/QmRqf2evGN propose Reinforcement Learning from Contrast Distillation (RLCD), a method for aligning language models to follow natural language principles without using… https://t.co/eheiXoySaK https://t.co/wO5ga0qAli

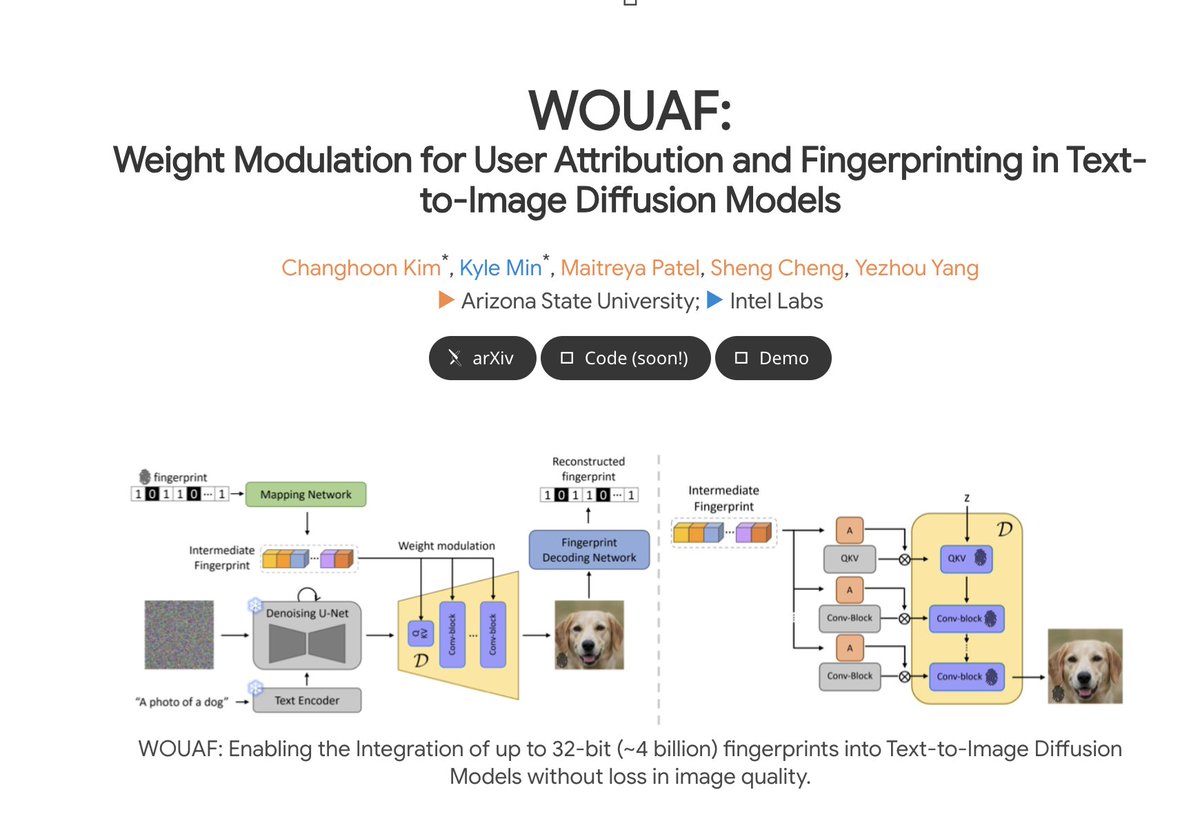
WOUAF:Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models paper page: https://t.co/901aYWWHaH demo: https://t.co/Jkq3vrrdSe The rapid advancement of generative models, facilitating the creation of hyper-realistic images from textual… https://t.co/YAsuDB3w5I https://t.co/6hKhJj5sRY
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning paper page: https://t.co/IDhGPKIJ2j As large language models (LLMs) perform more difficult tasks, it becomes harder to verify the correctness and safety of their behavior. One approach to help with… https://t.co/0cszC1qNMT https://t.co/rlUgrxbtls
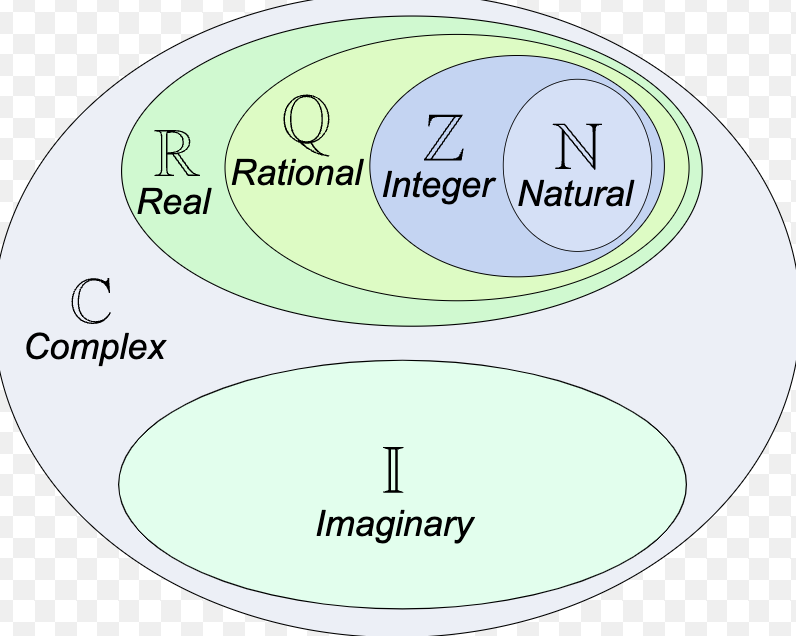
Where does X fit in to this? https://t.co/8834iIaw8T