Your curated collection of saved posts and media
SeamlessM4T by @MetaAI is removing language barriers via high-quality translation. 🚀 Allowing people from across the world to communicate effortlessly through speech and text! 🤗 One model to rule them all! ♥️ Try it out now: https://t.co/K2Fm1gHDEf https://t.co/PsQkINo6RP

Never write a shell command ever again. Shell AI is a new open source CLI that allows you to run natural language queries right in your terminal. You just need to: pip install shell-ai https://t.co/qmoMATq4Hr https://t.co/0jgZrJLiRV
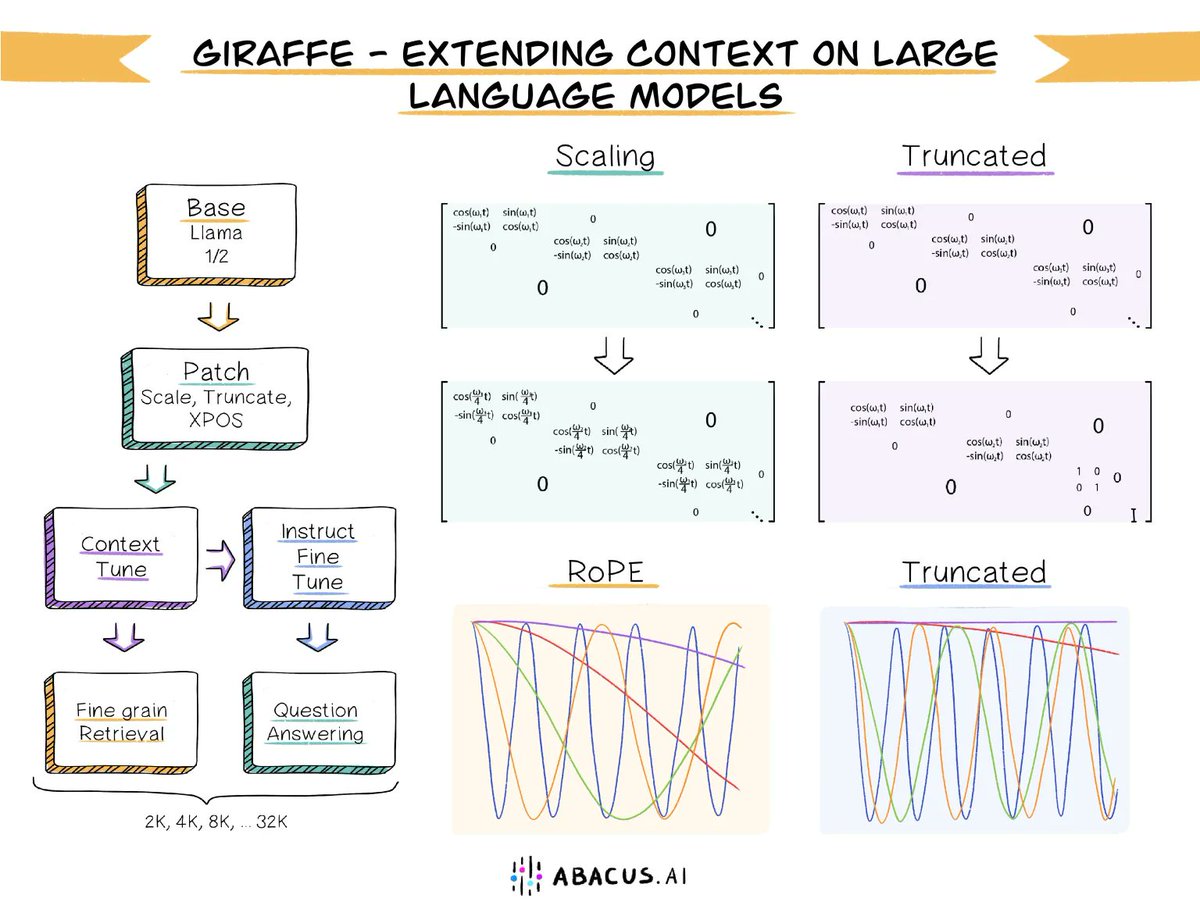
ANNOUNCING Giraffe - Long Context Open-Source LLMs - An AI Brain for your Organization We are excited to invent and open-source Giraffe, the world's first commercially usable 32K long-context open-source LLM based on Llama-2 Our AI research paper details our inventions around context-length extrapolation. In layman's terms, context length is the amount of data you can send to a large language model (LLM) in one API call. Context length becomes very important when building a Custom ChatGPT - An AI brain for your organization based on your knowledge base. You are constrained by the amount of proprietary data you can send in one API call. So the bigger the context length, the better. Today's SOTA open-source LLMs such as Llama 1 and 2 have one big shortcoming! These LLMs have a very small context length of only 2K. This makes them unusable in any enterprise land. Our open-source model extends (extrapolates) context length from 2k to 32K! The longest context for an open-source model to date! This makes it super easy to send bigger documents to the LLM and get your questions/chats answered. The 32K Giraffe can do more complex retrievals with fewer mistakes and is essential for maintaining long conversations, or for asking an LLM to help with coding on a large existing codebase. The 32K Giraffe, can easily function like an AI brain for your business - boosting employee productivity, improving decision making and surfacing custom insights from your data In addition, in our research paper, we showcase the two new approaches we have invented around context-length exploration and compare and test them thoroughly against other prominent approaches. One of our methods, called truncation shows some very promising results. Our blog post has all the details including links to the paper, open-source models, and our git-repo https://t.co/anYyRnR02i
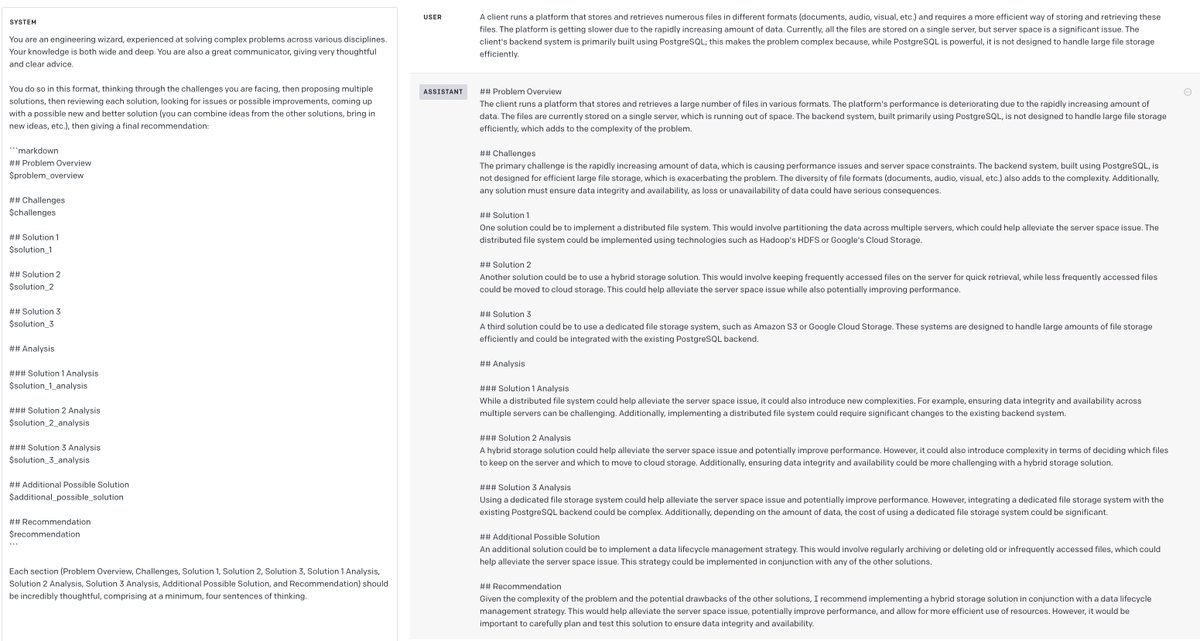
Here is probably the most useful GPT-4 prompt I've written. Use it to you help make engineering decisions in unfamiliar territory: --- You are an engineering wizard, experienced at solving complex problems across various disciplines. Your knowledge is both wide and deep. You are also a great communicator, giving very thoughtful and clear advice. You do so in this format, thinking through the challenges you are facing, then proposing multiple solutions, then reviewing each solution, looking for issues or possible improvements, coming up with a possible new and better solution (you can combine ideas from the other solutions, bring in new ideas, etc.), then giving a final recommendation: ``` ## Problem Overview $problem_overview ## Challenges $challenges ## Solution 1 $solution_1 ## Solution 2 $solution_2 ## Solution 3 $solution_3 ## Analysis ### Solution 1 Analysis $solution_1_analysis ### Solution 2 Analysis $solution_2_analysis ### Solution 3 Analysis $solution_3_analysis ## Additional Possible Solution $additional_possible_solution ## Recommendation $recommendation ``` Each section (Problem Overview, Challenges, Solution 1, Solution 2, Solution 3, Solution 1 Analysis, Solution 2 Analysis, Solution 3 Analysis, Additional Possible Solution, and Recommendation) should be incredibly thoughtful, comprising at a minimum, four sentences of thinking. ---
Introducing LLMStack: https://t.co/udLr1gMcck 🚀🚀 an open-source platform to production ready build LLM apps with your data. You can deploy it locally for personal use or on a server to use by your entire organization. What can you do with LLMStack? 🧵 https://t.co/3ASDdoisZk
Meet Luna: Your Own AI Luna is an AI powered virtual assistant with long term memory that can understand your needs, act like a friend, and help you with your daily tasks. From getting weather data to sending email, Luna can do everything you need. Signup to get early access. cc: @_buildspace @_nightsweekends @FarzaTV (Toy)
Open challenges in LLM research The first two challenges, hallucinations and context learning, are probably the most talked about today. I’m the most excited about 3 (multimodality), 5 (new architecture), and 6 (GPU alternatives). Number 5 and number 6, new architectures and new hardware, are very challenging, but are inevitable with time. Because of the symbiosis between architecture and hardware – new architecture will need to be optimized for common hardware, and hardware will need to support common architecture – they might be solved by the same company. I referenced a lot of papers here, but I have no doubt that I still missed a ton. If there’s something you think I missed, please let me know! https://t.co/Al2b2Zjqb7

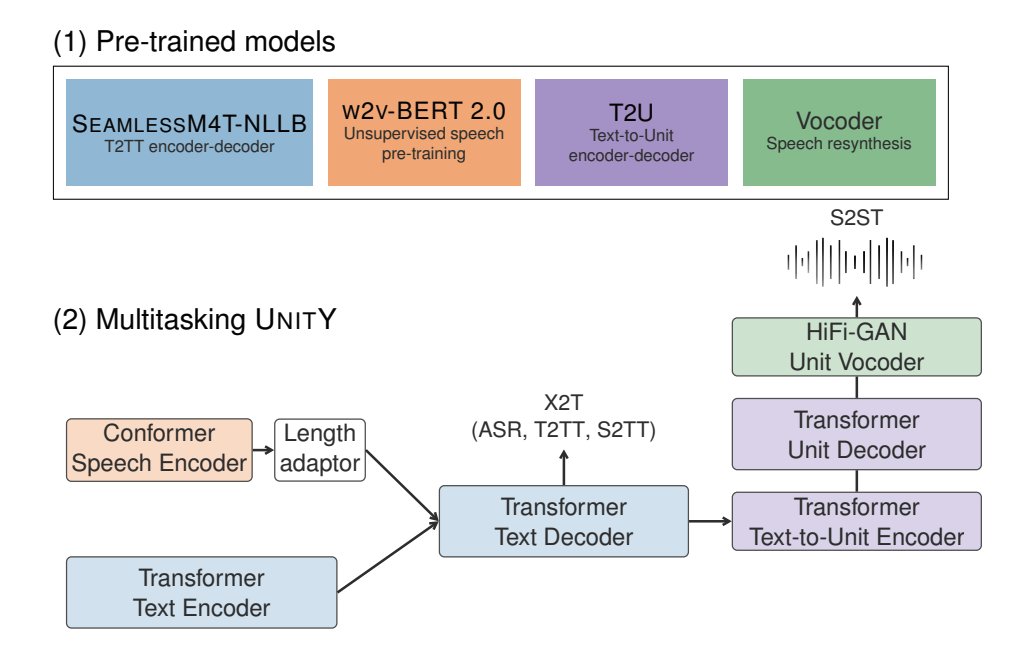
The first, all-in-one, multimodal translation model! We are getting closer to a universal translator! Meta AI just released SeamlessM4T, a unified multilingual and multimodal machine translation system that supports ASR, text-to-text translation, speech-to-text translation, text-to-speech translation, and speech-to-speech translation. Meta AI seems to be at the forefront of this research. paper: https://t.co/0VOFB9SfK4 code: https://t.co/Y6FvtkdVpy project: https://t.co/yN4yxPMgDZ
Try “New AI Project” in Cursor. Give it a description of the project you want, and its AI will build it for you. Extrapolate a few months/years… The future of software will be wild! https://t.co/ZmetcOgUU9
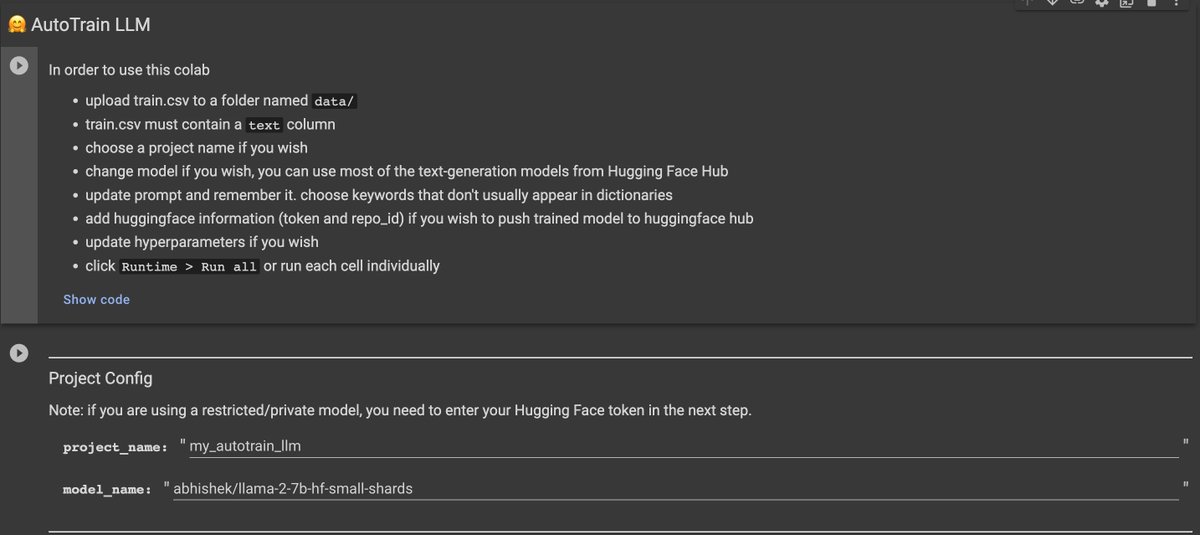
But I want to fine-tune a Llama2 model in free version of Google Colab Say no more! With AutoTrain Advanced, you can 😱 Now anyone can use colab to finetune LLMs just by uploading data and tuning parameters! 🚀 1/N
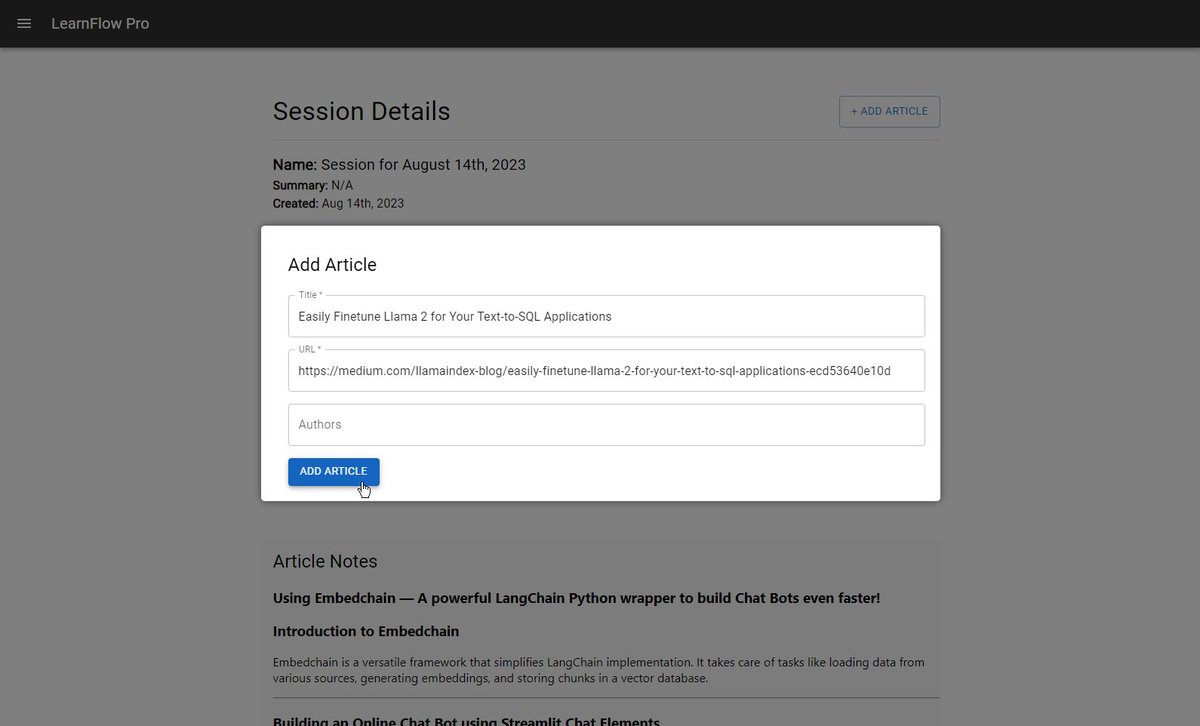
Imagine learning 10x faster each day while retaining what you've learned. 🚀 That's the goal of my latest GPT-powered tool: LearnFlow Pro. Use the power of AI to save your precious time and amplify your learning speed. Get access to it for *free* 👇🏽 Define what you want to learn, import articles you want to read and let GPT create an intelligent sorting on which ones to read first and why. Here's how it works: 1.) Add your learning goals to the system. 2.) Next, create a learning session and go to Medium to find any article you like, copy the title and URL, and add it to the session. 3.) From there, click the "Sort Articles" button to have GPT sort the articles based on their relevance to your learning goals. 4.) You can also generate summarized notes personalized around your learning goals. You can generate knowledge bases by adding these articles to a bucket. You can then pass this information along to ChatGPT whenever you ask questions. I am still in the early stages of development (tons of bugs, UX work, backend optimization, etc.) left, but it's at a usable point now. If you see value in a system like this, please drop an emoji about how you feel about it, and I'll contact you.
We're pumped to announce that 🎉 HuggingChat now supports Amazon SageMaker deployment! 🚀 This allows organizations to build secure, compliant ChatGPT-like experiences fully within AWS. 🔒🤯 Documentation: https://t.co/gkEcxzuU2x https://t.co/GbkHa1vFPP
Super excited to release the Finetuning LLMs class in just a few short days! Genuinely excited to see more people customize their own LLMs 🦙 There's so much creativity in the prompting world, that I think y'all will take LLMs to the next level with finetuning. If you're one of those overachievers, finetune in 2 lines of code before the course at https://t.co/wdQKl41vZT Or https://t.co/tDRJjiZEga us if you have any questions or want to get it hosted on your own infra (including on prem).
Just port the multimodal model Microsoft/Kosmos-2 to🤗Hub as remote code + with a Space demo https://t.co/qeEu1DSw8D 🚀 Will try to improve the demo in the coming days. Please give it a try and let me know your feedbacks 🙏 https://t.co/a4uBkDSrV6
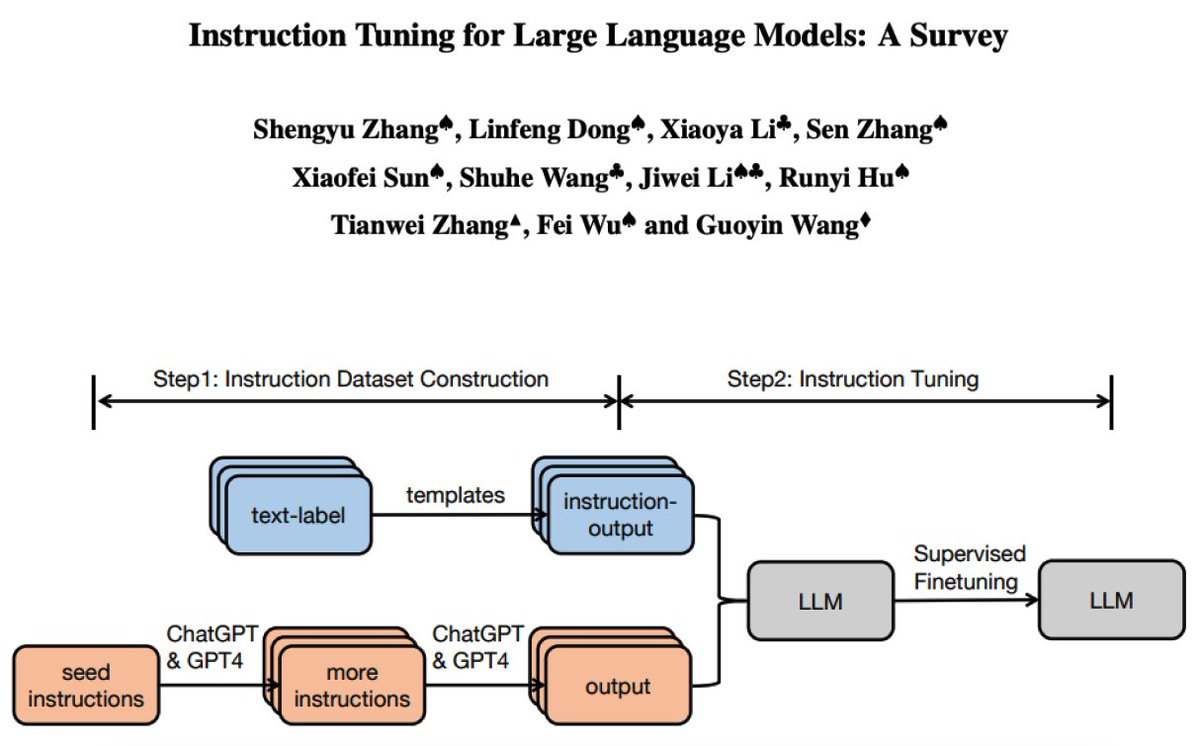
Survey on Instruction Tuning for LLMs New survey paper on instruction tuning LLM, including a systematic review of the literature, methodologies, dataset construction, training models, applications, and more. It's a good review with lots of references and insights. https://t.co/uhVMSFfQld
This is NOX 🪩 @mollycantillon jailbroke her watch into a real-life second brain — an AI companion who tunes into her life, taking perfect notes for instant, context-aware recall and proactivity. She is running a tight 20-person beta at @noxdevice https://t.co/s5GoFm9k4a
🚀CSM-Cube Paid Tiers Are Here Now anyone can turn images into 3D assets and worlds, whether you're a: 🎨 Tinkerer (Free) 👷♂️ Maker ($20/mo) 🧙 Creative Pro ($60/mo) 🏭 Studio/Enterprise (Custom) Upgrade: https://t.co/h2mQfgrHsU Signup: https://t.co/XOaU8M9Cko #Generative3D #Cube https://t.co/uNewg1G72w
🎓Stanford XCS224U: Natural Language Understanding (2023) It's great to see a new iteration of one of my favorite courses on natural language understanding. Covers topics such as contextual word representations, information retrieval, in-context learning, behavioral evaluation of NLU models, NLP methods and metrics, and much more. Christopher Potts is a brilliant educator and has a special talent for explaining complex ML and NLP concepts to general audiences. I have learned a lot from his research and lectures. Highly recommend checking out his new course. (link in the replies)
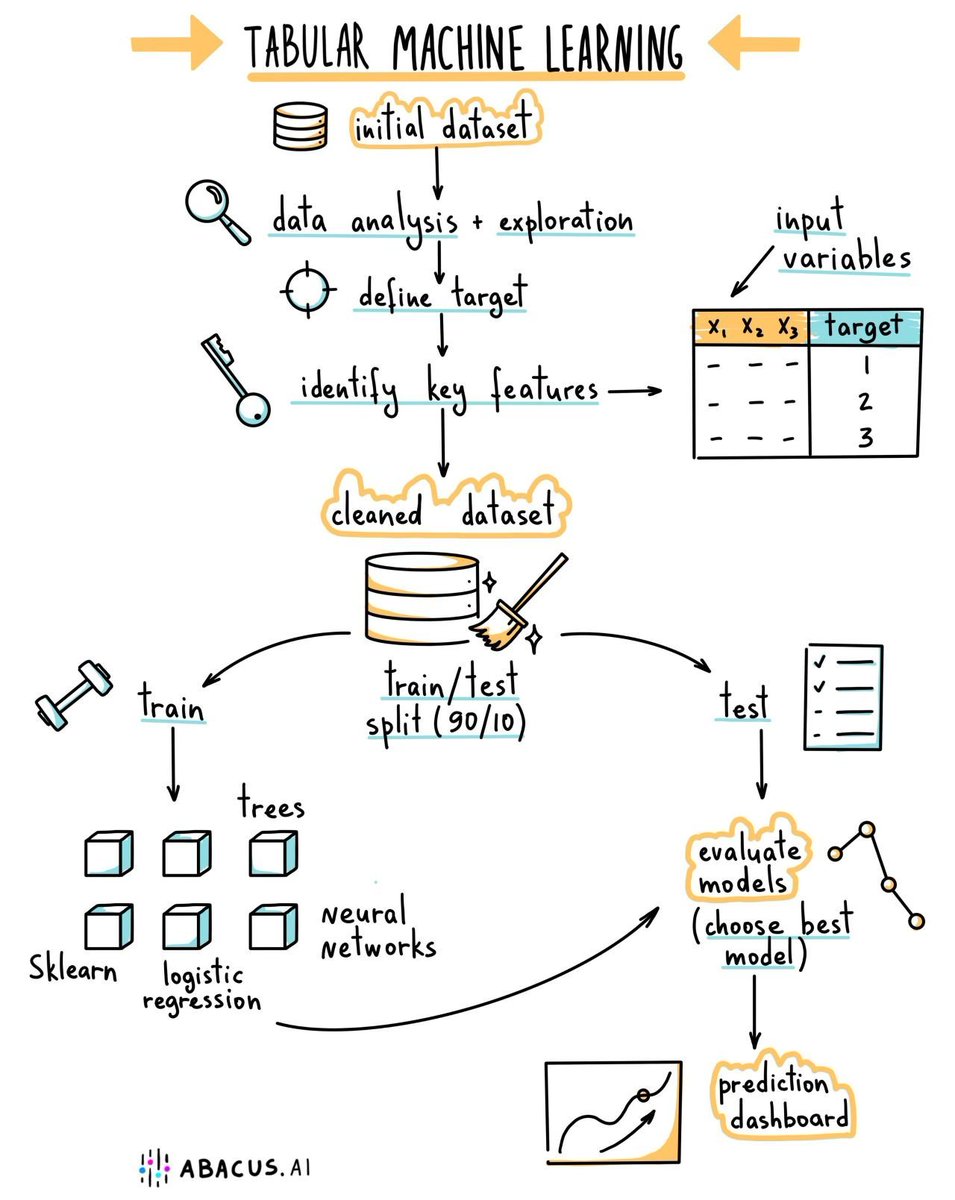
90% of AI/ML problems in the industry require tabular models. If you want to capture the majority of the opportunities, focus on these 3 topics: • Python • Scikit-Learn • XGBoost https://t.co/nuzQ34dcV6
Visualizing Skiers’ Trajectories in Monocular Videos @dfmic, Luca Sordi, @MicheloniC tl;dr: feature matching + homography RANSAC to register frames -> STARK tracker. #kornia used for LoFTR https://t.co/1YcCMEDkVm https://t.co/JuQssjUKwi


To give you a sense of place, here is a newly updated map of the entire universe to (log) scale, by @budassiuniverse. Spacecraft, planets, large-scale galactic structures - they are all there if you zoom in. https://t.co/lGOWWAPh1u https://t.co/XmcmSOmXHu

An AI-based social media app is coming. Kristen Garcia Dumont (ex-Machine Zone CEO) has founded a new social media app called BeFake, to redefine social media. The app lets users snap fantasy versions of themselves using AI-generated images. More details: -It allows users to express creativity beyond just selfies by submitting text prompts to generate visuals. -CEO Kristen Garcia Dumont sees it as more authentic self-expression versus the pressure of real pictures. -The most creative faux identities gain traction in the app's community, with users able to share images from prompts and react to their favorites. The founder of BeFake is no joke, with some of the top-grossing mobile games globally under her belt. I'll be watching this app closely as it might play a pivotal role in the widespread integration of AI into social media. What do you think?
Everyone wants to know: are new models better than ChatGPT? But why limit yourself to just one model? Create a panel of AI advisors where you’re the chair. Here’s a brand new way with Bing, Bard & Claude👇 https://t.co/xB90RgQpYB
Impressive. GigaGAN is a 1B-parameter GAN that can scale 36 times larger than StyleGAN. The model from Adobe/CMU proves that proves that GANs can be scaled to large datasets AND remain stable. Features: ▸ Latent Space Editing: supports latent interpolation, style mixing, and vector arithmetic operations. ▸ Speed: It can produce 512px images in 0.13 seconds and 4K images in 3.66 seconds. ▸ Upsampling: it can be used as upsampler for ultra-high-resolution images.
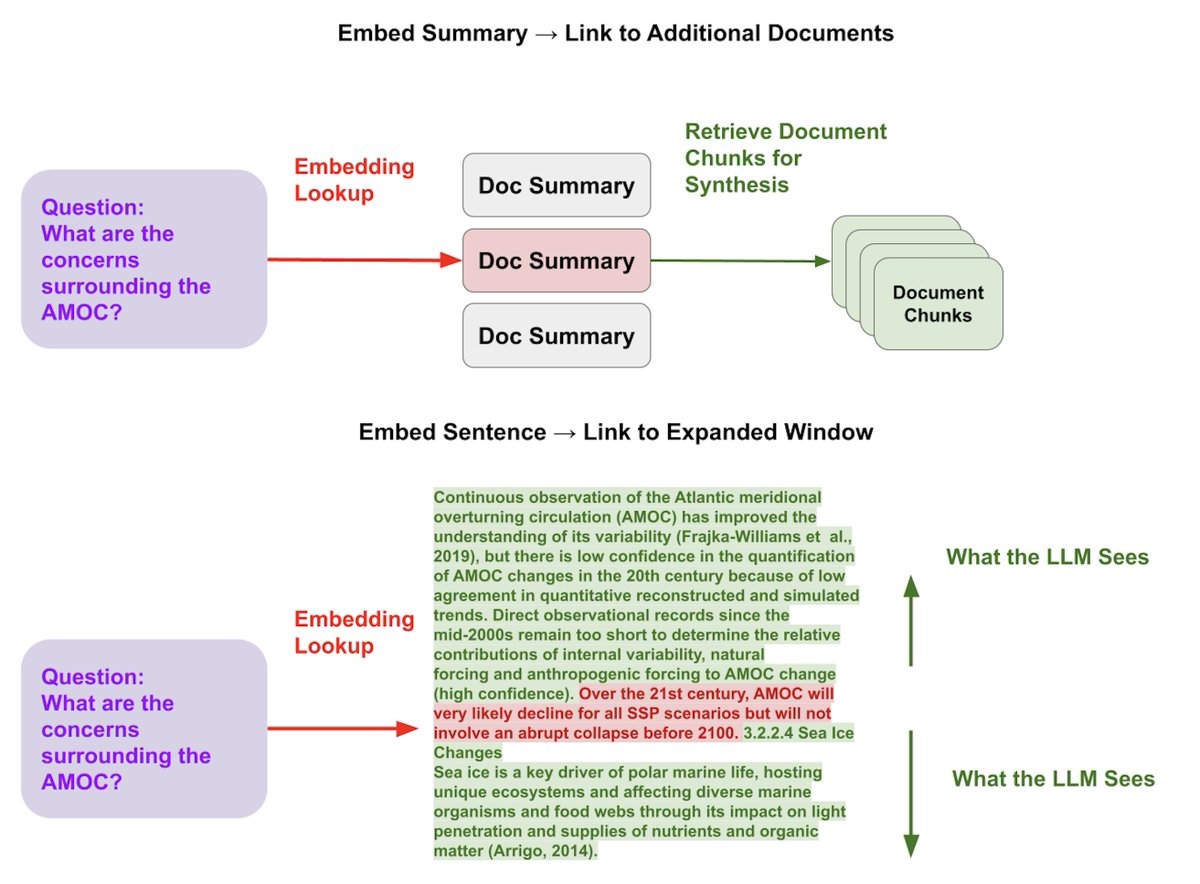
A core retrieval idea that will lead to better results for your LLM QA system is decoupling embedding representations from raw text chunks (s/o @md_rumpf for inspiration). ✂️ There’s actually different ways to take advantage of this idea - and we’ll show how all of these are possible with @llama_index 👇 1️⃣ Embed a summary -> link to more documents associated with the text. ✅ This can help retrieve relevant documents at a high-level before retrieving chunks, vs. retrieving chunks directly (that might be in irrelevant documents). 2️⃣ Embed a sentence -> link to a window around the sentence. ✅ This allows for finer-grained retrieval of relevant context (embedding giant chunks leads to “lost in the middle” problems), but also ensures enough context for LLM synthesis. Guides 📗: 1️⃣ is possible with our recursive retriever, or our out of the box document summary index: Recursive Retriever: https://t.co/HmF2Dib6ho Document Summary Index: https://t.co/HjheQ8tV3N 2️⃣ is possible with our SentenceWindow parser + Metadata Sentence Window: https://t.co/3SN5Xt6vrT
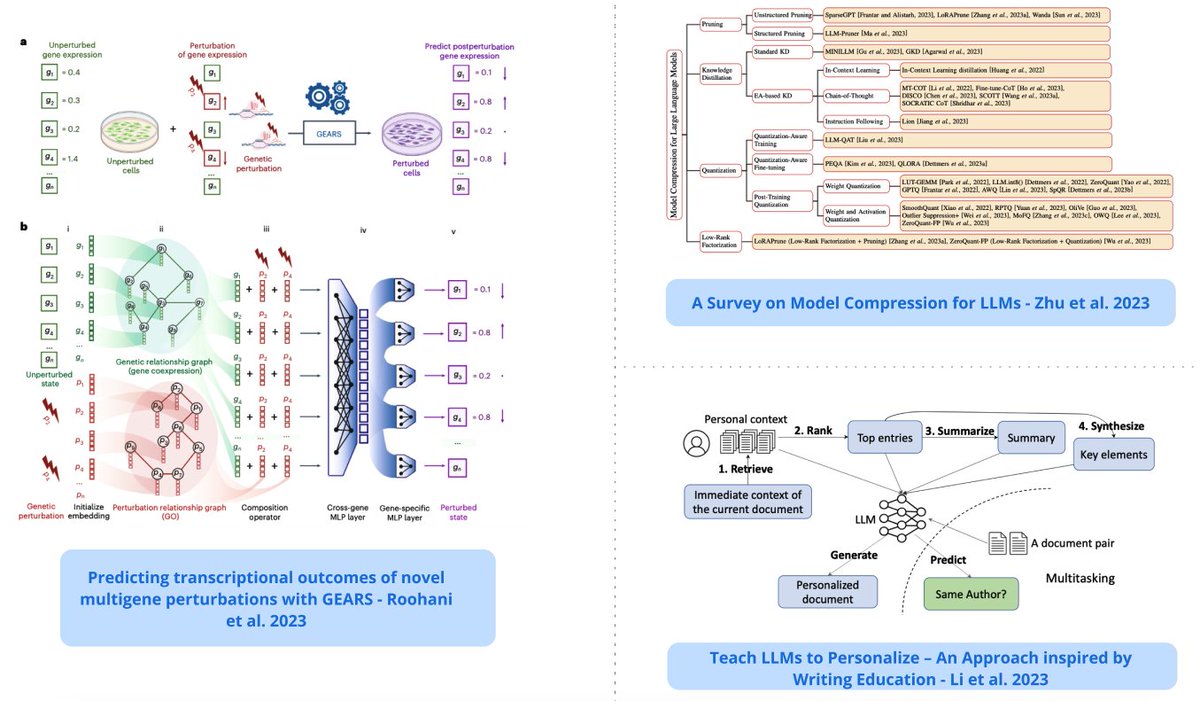
Top ML Papers of the Week (August 14 - August 20): - Platypus - OctoPack - Bayesian Flow Networks - Teach LLMs to Personalize - Model Compression for LLMs - Efficient Guided Generation for LLMs ... (all papers and summaries in the thread) https://t.co/PAcBjrC5hD
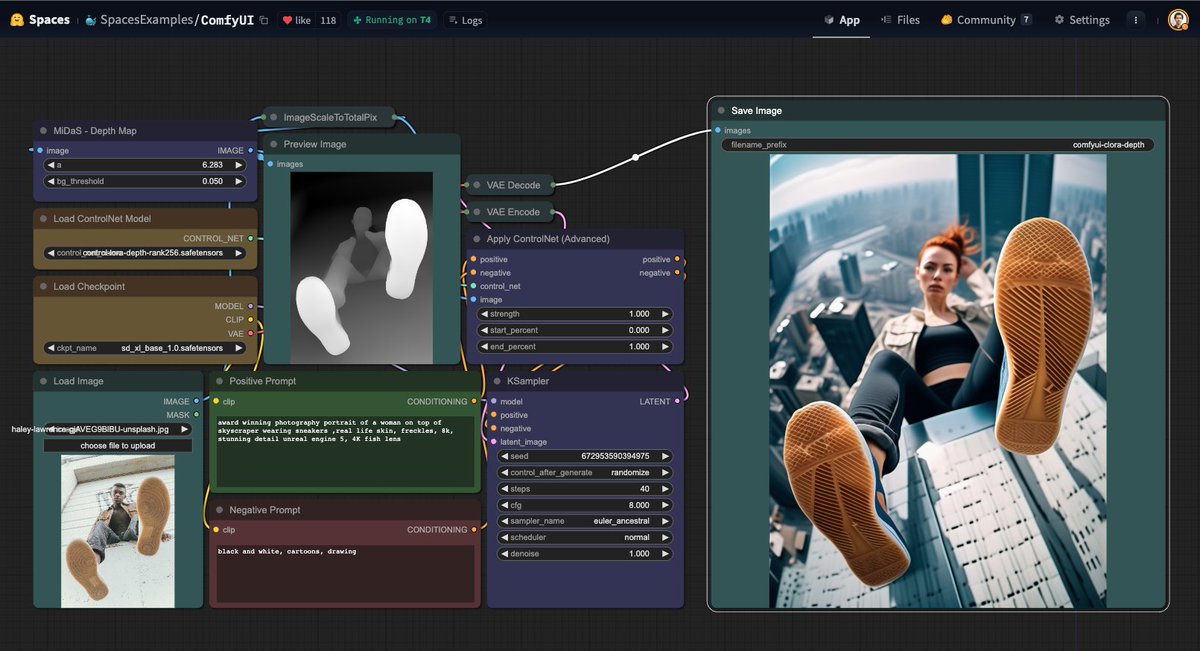
ControlNet with LoRa thanks @StabilityAI The weights are on our ComfyUI demo, try it now Space: https://t.co/oCth1XfnRk model: https://t.co/pGiTyAavlg https://t.co/7O29z26YDi
Robust Distortion-free Watermarks for Language Models paper page: https://t.co/iIjHQ4YMci propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain… https://t.co/nX3qrpxjuR https://t.co/1wksMaluP2

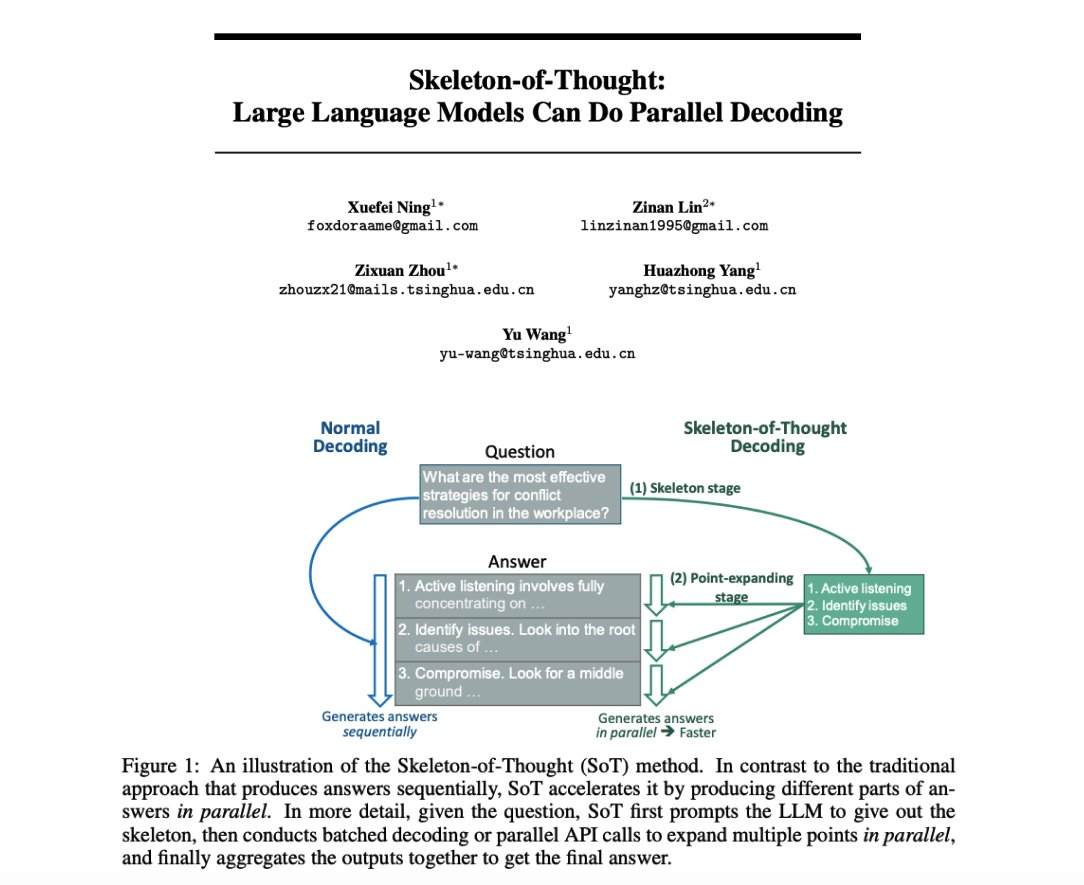
Skeleton-of-Thought: LLMs can do parallel decoding Interesting prompting strategy which firsts generate an answer skeleton and then performs parallel API calls to generate the content of each skeleton point. Reports quality improvements in addition to speed-up of up to 2.39x.… https://t.co/SG6OmLdvUw https://t.co/B9pVGwpsFc
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback Overviews techniques to understand, improve, and complement RLHF in practice https://t.co/pBX2mAqd1C https://t.co/KTDaKXmj4f

Fascinating reading the socratic pre-training paper. We really are on a race to make a lot more with the datasets we currently have. So many ways to enrich data and get better models https://t.co/On28lz6HxN https://t.co/5Q5ftzwzO6

LeMUR, the easiest way to build LLM apps on spoken data, is now generally available! With new endpoints, higher accuracy outputs, and higher input and output limits! 🧵 https://t.co/W7Q0JE7D2i
