Your curated collection of saved posts and media
🔥 HUGE update🔥 @Bezel3D launched some groundbreaking features that allows you to design human-centered experiences in 3D! 🧍Body Rig 💫Behaviors 🥁Colliders https://t.co/6qt3ib9z0p
Explore the future of human-centered design and communication with elevated prototyping in Bezel with the newly launched: 💪 Body Rig - immerse in 3D 🍃 Colliders - interact with objects in the scene ⚡️Behaviors - customize object interactions beyond states https://t.co/f6YlJDWjL
80% of 80% of all economically valuable jobs will be capable of being done by AI. Years ago I asked -- to the consternation of many -- whether we needed doctors. Then I asked whether we needed teachers. High time we ask whether we need financial analysts, bankers, traders, etc. Welcome, @Arkifi
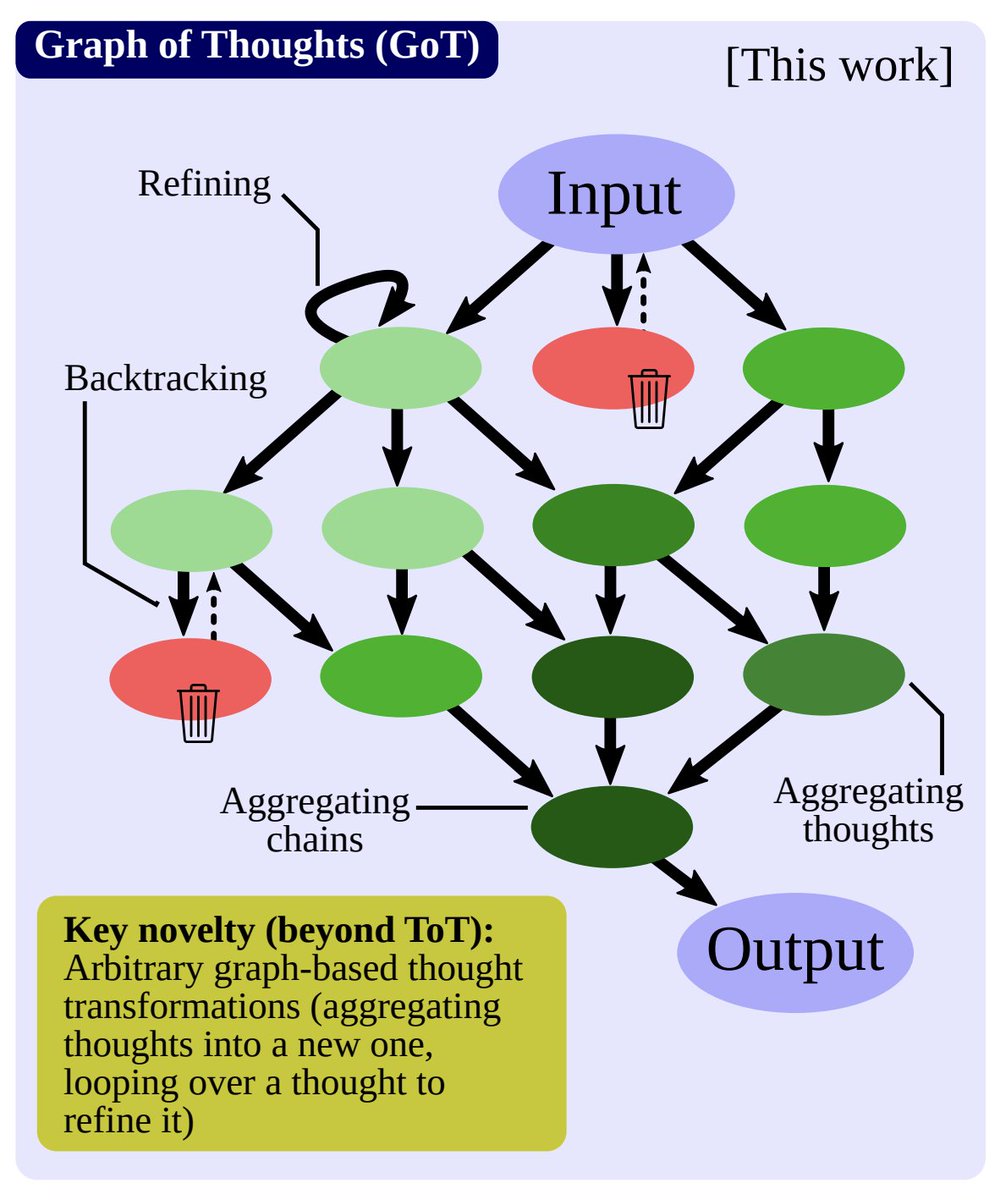
Pioneer of reinforcement learning, Richard Sutton, once said that "the two most powerful methods that seem to scale arbitrarily are search and learning". LLM is learning. Systematic, in-context prompting is search. We are seeing a family of methods getting more and more sophisticated at searching: - Chain of thought - Tree of thought - Now, Graph of thought! https://t.co/5ncT5tuTOY
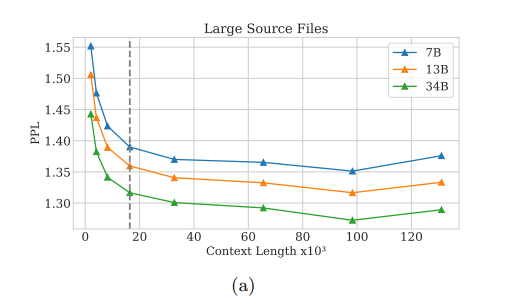
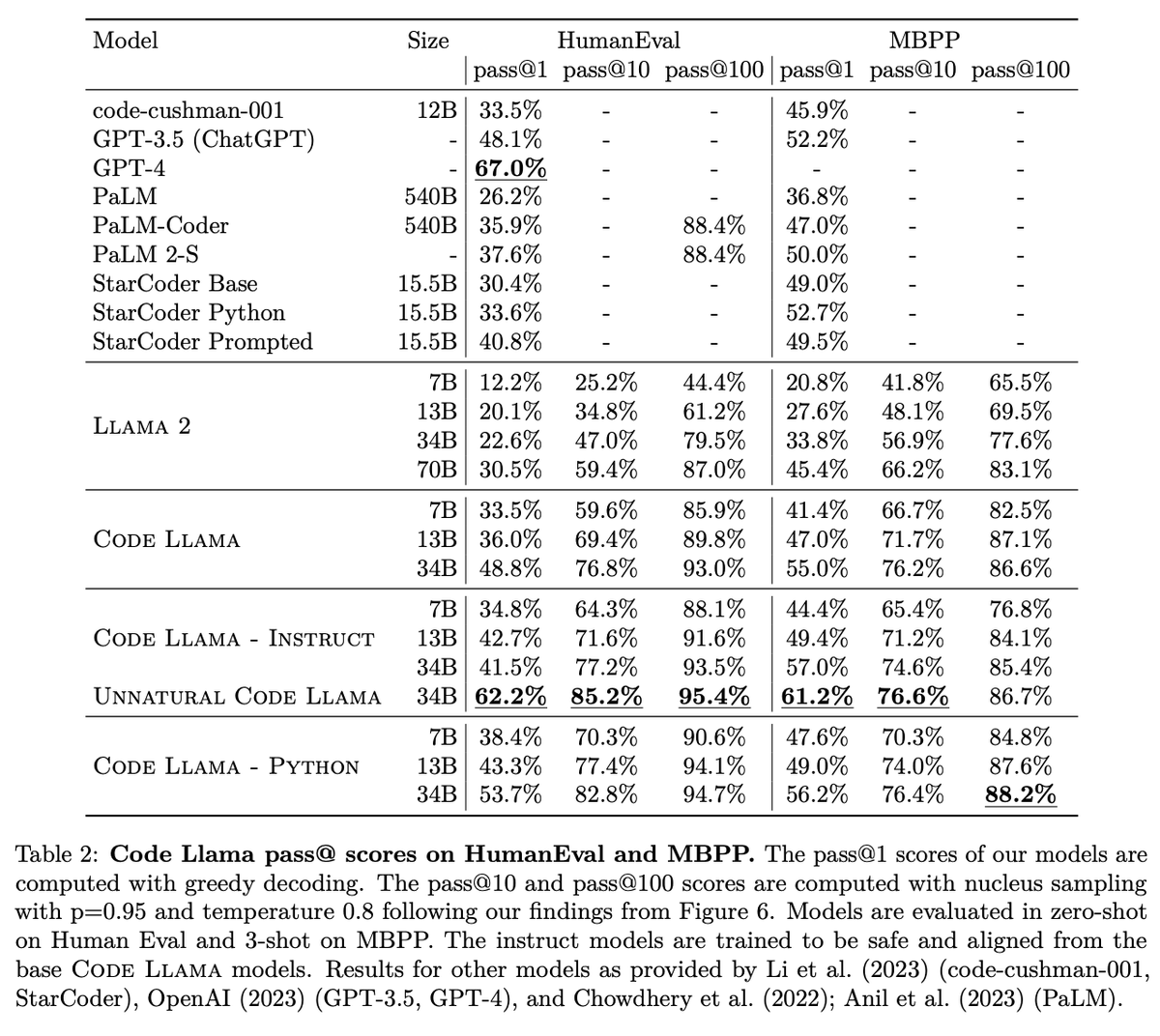
Code LLaMA has good results and good eval. It's cool to see PPL decrease all the way up to 100K tokens (after finetuning on 100K token-long inputs). Facebook is close to replicating GPT-4 performance on HumanEval. Great news for the open source/science communities! https://t.co/AYctaO6KG0
🚀 We are excited to announce our new audio AIGC technology - WavJourney! 🎧 Step into the fascinating world of intelligent audio creation powered by LLMs. Simply start with a prompt, WavJourney turns you into an audio filmmaker! 🎬 Check out the magic of WavJourney now! ✨ https://t.co/QTpjw5lzZ2
AI2 just released the largest open-source dataset for LLM pretraining: 3 trillion tokens of high quality data. - Web data from Common Crawl. - Quality filtered - Deduplication within each source. - Risk mitigation for harmful content. https://t.co/vHu07YA5GT https://t.co/W9OHrL6QRj

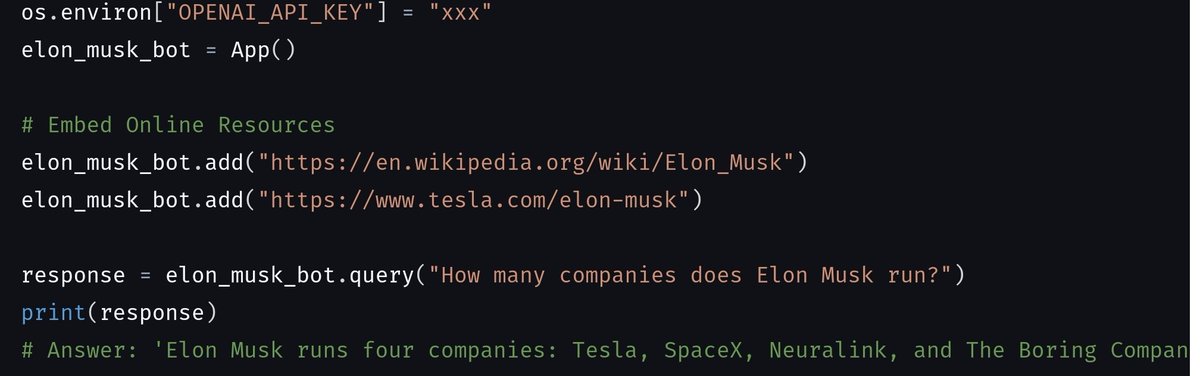
Introducing Embedchain! 🤯 Building a chatbot over your data used to be a pain. Not anymore. With three lines of code, you will be able to converse with YouTube videos, PDF files, web pages, and even your Notion workspace. Embedchain is a framework to easily create LLM-powered bots over any data. 📚 Supported Data Types: - Youtube video - PDF file - Web page - Sitemap - Doc file - Code documentation website loader - Notion 🖇 Links: Repository- https://t.co/89gLf7ftxl Colab notebook- https://t.co/RyOZ8Ix89C Documentation- https://t.co/ohfINOsmhj
This is a nice paper providing an overview of existing efforts to identify and mitigate threats and vulnerabilities arising from LLMs. As an LLM practitioner or researcher, this should serve as an exceptional guide to building more reliable and robust LLM-powered systems. https://t.co/EuoazIs3Xx

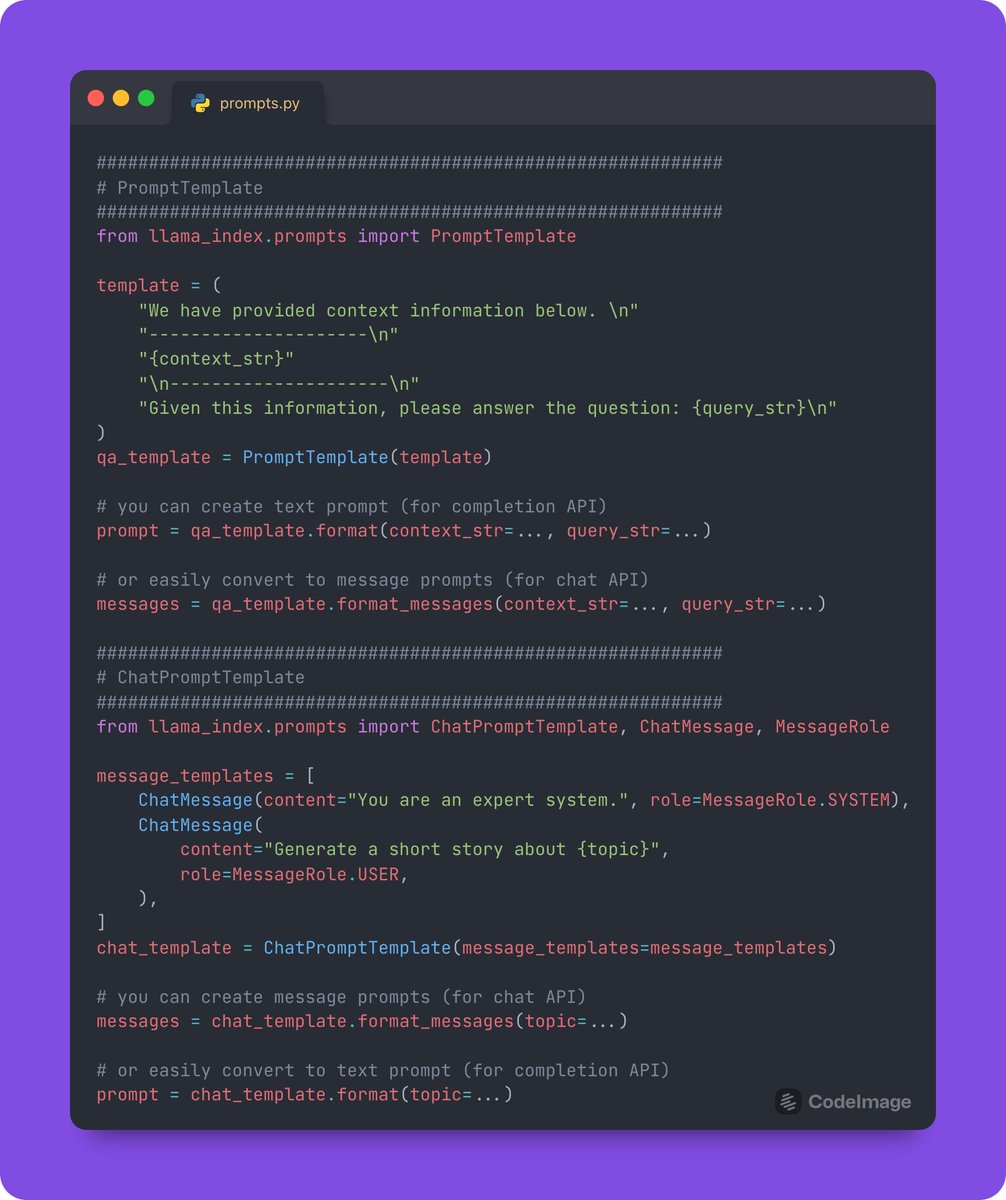
We’ve completely revamped our Prompt abstractions: they’re lightweight, easy to use, but still expressive 🔥 ✅ Only 3 core prompt classes ✅ Format prompts as chat messages or text ✅ selector prompt based on model Full docs here, deets below: https://t.co/hqbngsiQ1l https://t.co/zU8LrCgHAZ
Evolution https://t.co/2XaIx1LbB5
This is basically how I think the "AI debate" is playing out. Most of my mutuals are bottom right (I am too) https://t.co/KwLJSIz6MM

Code LLaMA is now on Perplexity’s LLaMa Chat! Try asking it to write a function for you, or explain a code snippet: 🔗 https://t.co/rwcPzknBgE This is the fastest way to try @MetaAI’s latest code-specialized LLM. With our model deployment expertise, we are able to provide you with this model less than 24 hours of it’s release. What’s next? We’ll integrate code LLaMA into Perplexity, all in service of providing you with the best answers to your most technical questions!
Here we go… introducing Embra for Teams (beta)! ✨ Within Embra, you can now invite your team to collaborate on AI chats, prompts, files, and commands. An all-in-one AI assistant on Mac OS and web. The future of professional AI centers around collaboration + control. 🧵 time https://t.co/lAy4ZjeLmP
.@LiteLLM (YC W23) is an open source package that allows you to call 100+ LLM APIs (like Llama2, Anthropic, and Huggingface) using the OpenAI format. Try it out at https://t.co/INt4Fs8cwA. Congrats on the launch, @ishaan_jaff + @krrish_dh! https://t.co/XBx9US36gn

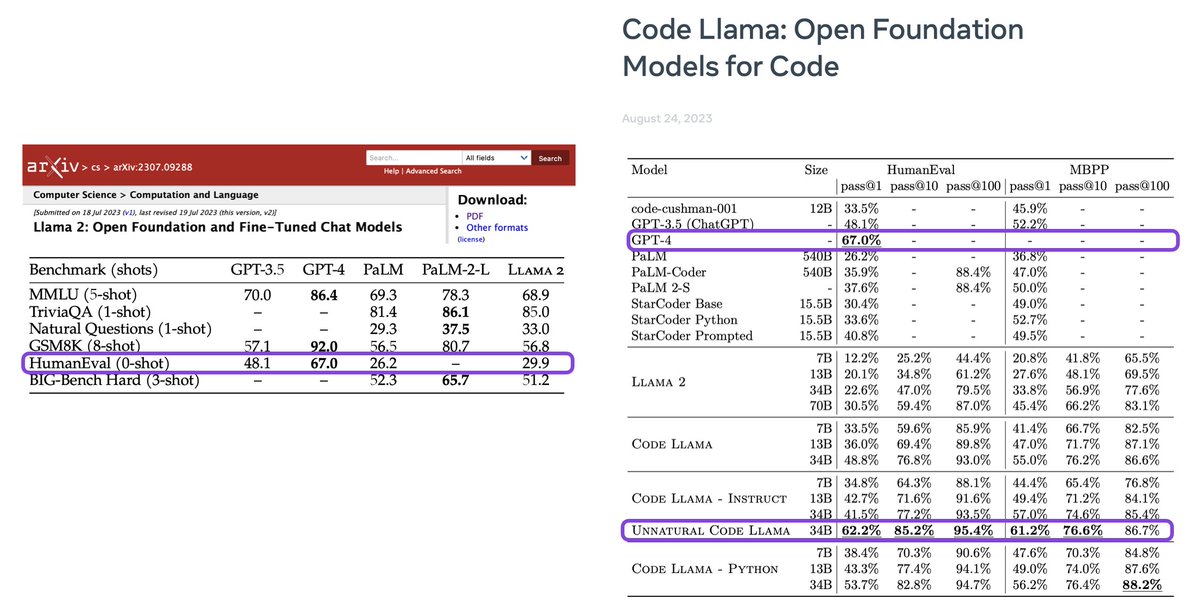
They don't want you to know that synthetic data is the future. LLMs generating synthetic data to train on drives a huuuge boost in "unnatural" code llama -- the one model they aren't releasing. Surpasses gpt-3.5 and gets close to gpt-4 performance on a 34B model https://t.co/NdB6Or6mhi

new genre of ai art i am calling lobotomy art, based on shuffling model weights and breaking things until you get right on the sweet spot of entropy between interesting and incomprehensible https://t.co/RdogOPDbpQ

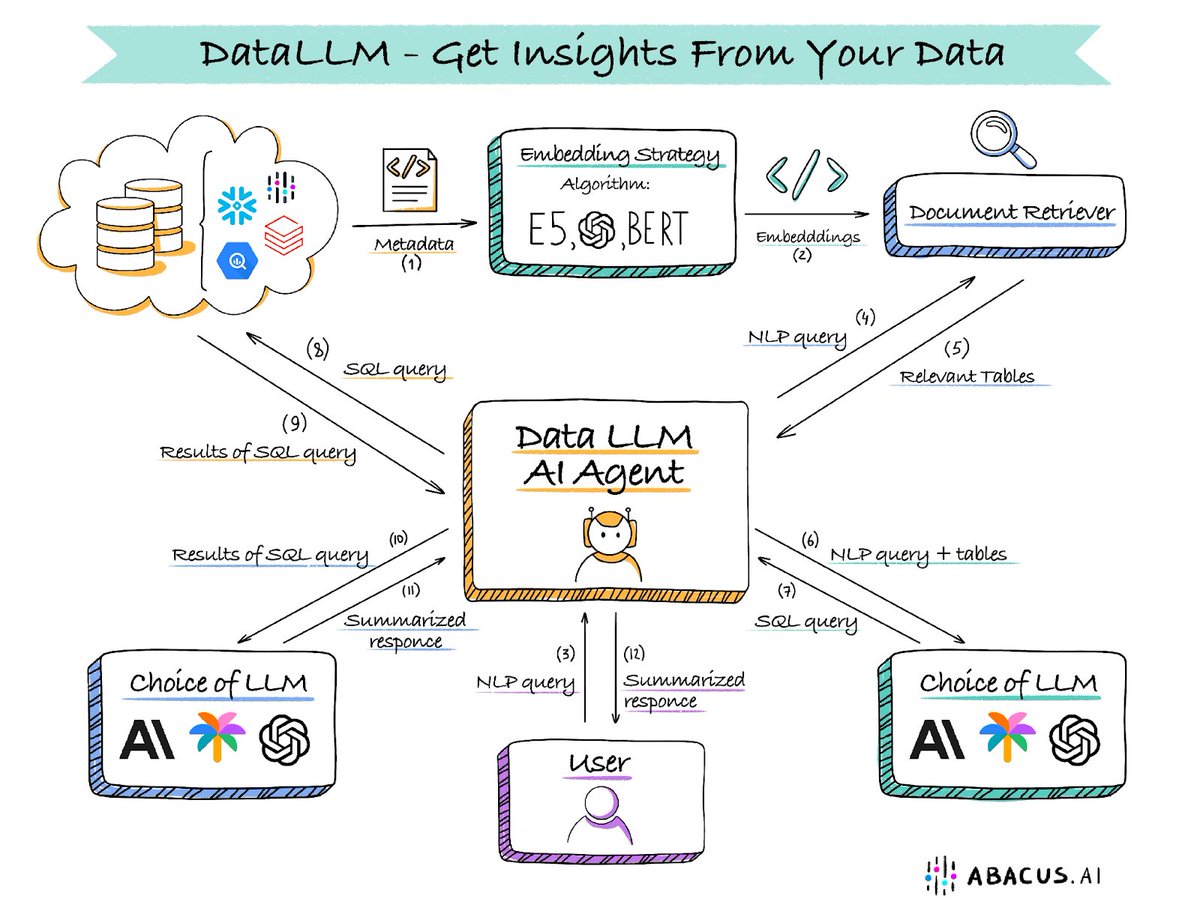
Data LLM - An AI Brain That Extracts Insights From Your Data Your data always has a story to tell, but most organizations don't know what it is. Data LLMs can understand the patterns in your data and extract hidden insights from it. Much like a custom ChatGPT on all your data, you can simply chat with it to understand the key equations that drive your business. However, there are a number of steps involved in setting up your DataLLM. The good news is you can leverage GPT-4 or any other LLM of your choice How it works - Fundamentally, we will have to orchestrate between LLMs and your data sources to extract the right response to a query. For example: your query could be - how many users churned in Q1. We will have to look this up in the source database by executing the right SQL query, retrieving the results, and then summarizing them. You might then have an ongoing conversation with the DataLLM and ask a follow-up question. The system has to keep state, execute appropriate queries, understand the results, and generate responses. A considerable amount of set-up is involved before this can work smoothly Connector set-up: Your data probably resides in multiple databases or data warehouses like Snowflake or BigQuery. You will have to set up connectors to all your data sources. Ideally, you want to run your queries on the source database. Moving data is costly and is not recommended Doc retrievers: This is a component that has all the metadata about your data. Typically you can use a vector store for this component. This module knows about your database structure and has details about the table names and columns. We have to use information from the doc retriever to feed to the LLM to construct the SQL queries Orchestration layer: This is a hard one and is the layer that talks to the LLM, doc retriever, and your database. When the query comes in the orchestrator will ask the doc retriever for the relevant tables and meta-data that map to the query. It will then send the query along with the meta-data to the LLM will will generate the SQL query. The orchestrator then routes the SQL query to the data source where it gets executed. Once the results are returned, you will have to make one more call to the LLM to summarize these results. Sometimes, multiple SQL queries are required for harder more nuanced questions LLMs: You can use closed-source (e.g. GPT-4) or your own custom LLM (Abacus-Giraffe or Llama2). You can compare and contrast whichever LLM works for you and pick the best one UX Interface: Last but not least, you will ideally want a ChatGPT-like interface with the ability to track history, have threaded conversations, and display tables and charts. DataLLMs can dramatically increase the efficacy of your organization. By making it easy to extract insights from your data, your employees will more often than not, make data-driven decisions. They are much more effective than having to go through a mountain of reports that no one looks at. Abacus can set up a DataLLM for you in a couple of days. We will even do it for free, to showcase how useful it can be. Blog link: https://t.co/0SfXmJgoRr
Streamlit is an awesome tool for prototyping LLM apps - we’ve been using it since the early days. Excited to officially collab with the team (@CarolineFrasca, @DataChaz) for a tutorial using a native UI for conversational apps with @llama_index ✨💬: https://t.co/8S7zcB39XL https://t.co/nBXXpYmlZb
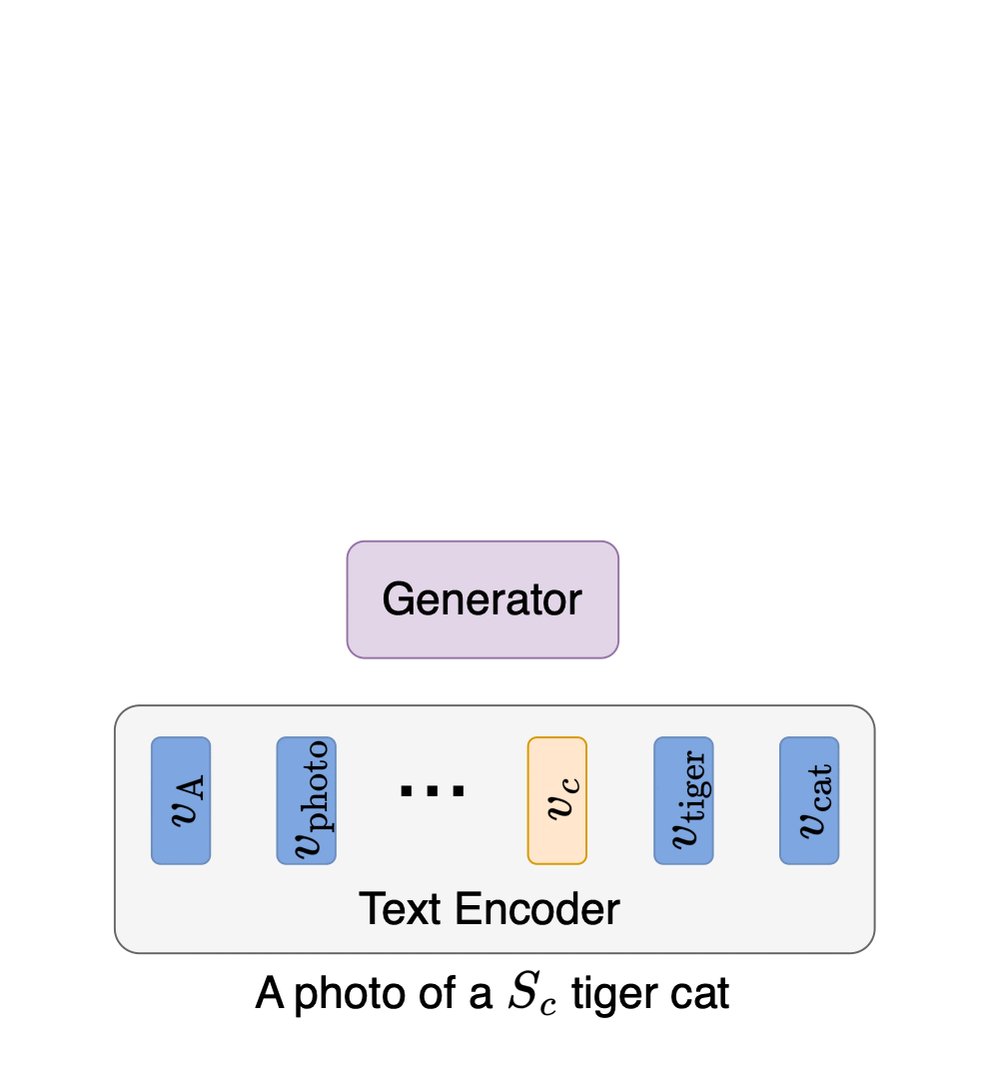
Thanks @_akhaliq ! Code for our #ICCV23 paper is now available! :) Discriminative Class Tokens enable direct editing from a pre-trained classifier, allowing fine-grained edits and more. See project page for more details: https://t.co/Dm4CS0QkIb Code: https://t.co/WV49lX4bYs https://t.co/URHqvvRvML
Discriminative Class Tokens for Text-to-Image Diffusion Models abs: https://t.co/2SXsR1HELP https://t.co/WynBYxZjMF
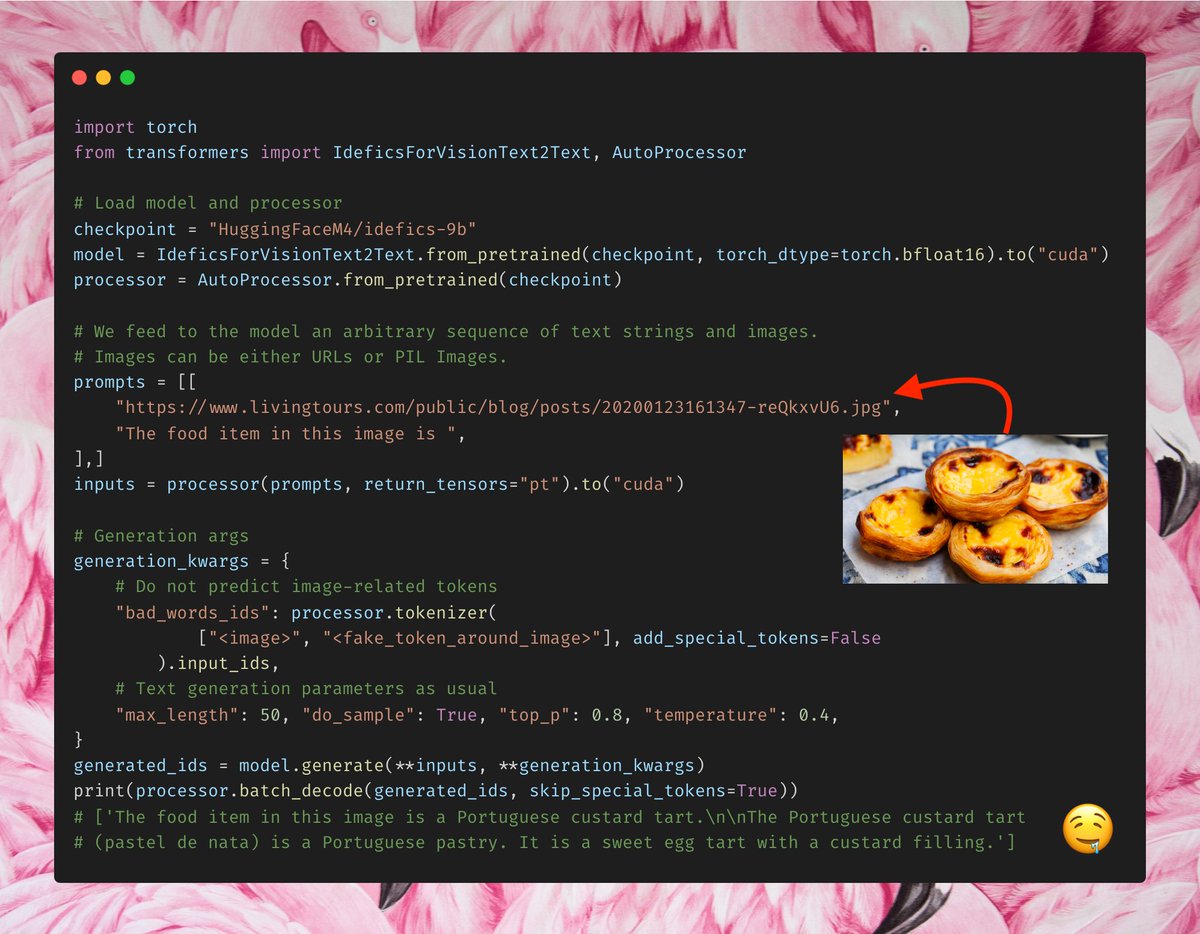
IDEFICS, Flamingo's publicly available reproduction by Hugging Face is now available in 🤗 transformers 🎉 In a few lines, you can fully customize and experiment with a powerful image 🎆 + text 📝 -> text model on your own terms, using the well-known `.generate()` interface! 🧵 https://t.co/xHdUrYrakG
Looks very nice on initial skim! But about this "Unnatural Code Llama"...
AI continues to make unbelievable advances in healthcare. Researchers have just created a brain implant that decodes thoughts into synthesized speech allowing paralyzed patients to communicate through a digital avatar. This is incredible: -The implant converts brain signals into text at nearly 80 words per minute, focusing on phonemes vs. whole words to enhance speed. -The AI generates realistic vocals (mirroring a patient’s pre-injury voice) and facial animations that aim to enable more natural communication. -The breakthrough brings the tech closer to real-world use, with the next step being a wireless model that doesn’t require a physical connection to the interface. Restoring communication for those with paralysis is an innovation that would change countless lives. While it sounds crazy, mind-reading implants seem to be inching closer to reality.
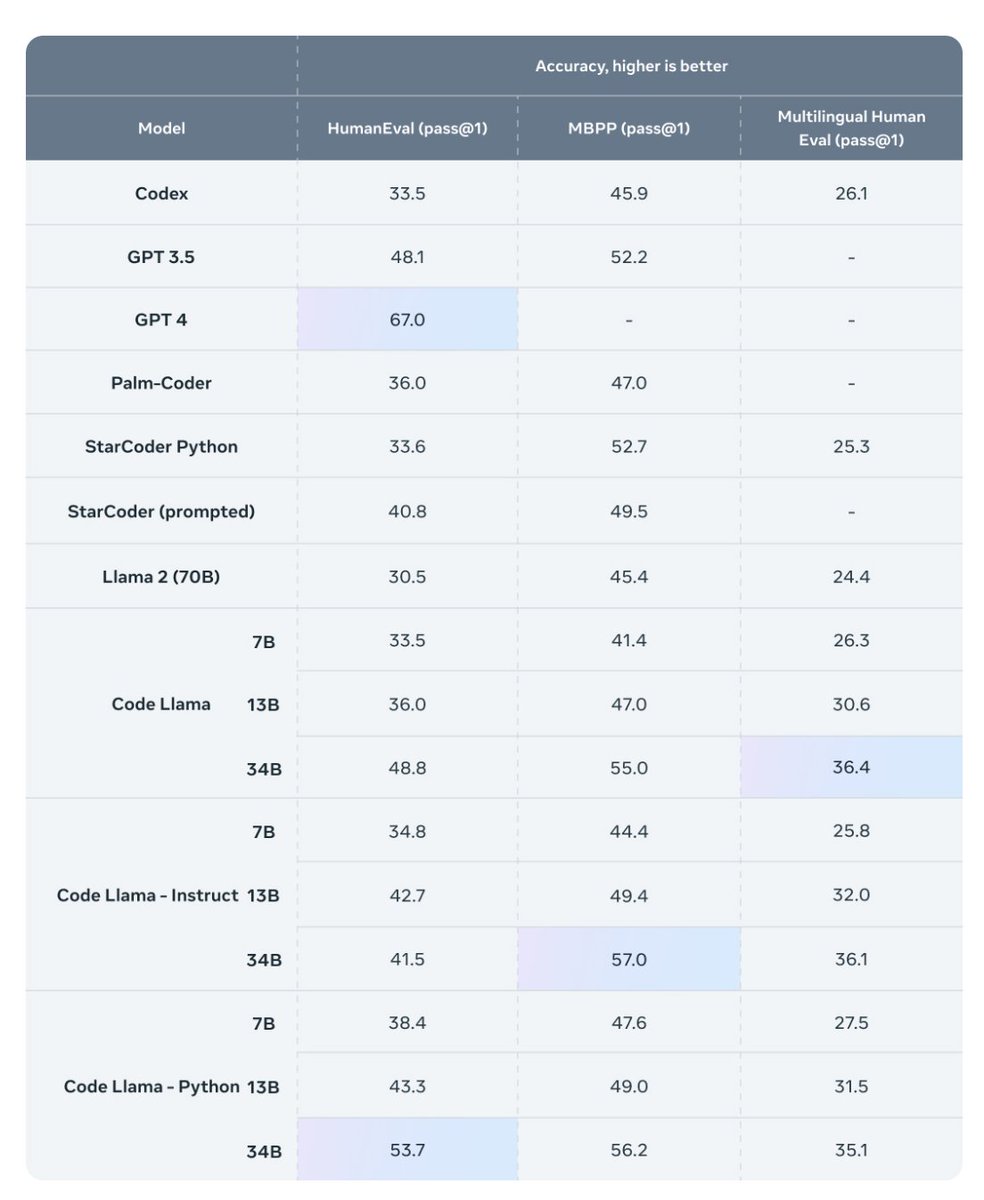
Llama 2 is awesome, however, coding tasks were not its strong suite. (See HumanEval, a coding-related evaluation task from the paper Evaluating Large Language Models Trained on Code.) The new 34B CodeLlama model is twice as good as the original 70B Llama 2 model and closes the gap to (the much larger) GPT 4. Excited to read the 47-page CodeLlama paper (via https://t.co/ROW8qUcTXw) in more detail in the next couple of days.
CodeLlama -- a version of Llama2 that was fine-tuned for code tasks is live now. Available in 7B, 13B and 34B. https://t.co/4PQBlchlrn https://t.co/LEz9z44IkI
CodeLlama -- a version of Llama2 that was fine-tuned for code tasks is live now. Available in 7B, 13B and 34B. https://t.co/4PQBlchlrn https://t.co/LEz9z44IkI
AutoGPTQ is now natively supported in transformers! 🤩 AutoGPTQ is a library for GPTQ, a post-training quantization technique to quantize autoregressive generative LLMs. 🦜 With this integration, you can quantize LLMs with few lines of code! Read more 👉 https://t.co/QPW3DJ0erm https://t.co/9OFACotev7

I'm excited to be giving a talk on our recent work on HyenaDNA with OpenBioML! It's a public virtual talk, so any one is welcome. Sept 7: 10am PST https://t.co/LSuFT5XZw2 More info on their Discord Blog: https://t.co/AIMFRY76e8 Paper: https://t.co/qParbGr7Hy https://t.co/rpz8jwNOO6
We are happy to announce the next edition of our journal club, hosted on Thursday September 7th at 7 pm CEST and featuring @exnx for a talk on his recent "HyenaDNA: Long-Range Genomic Sequence Modeling at Single Nucleotide Resolution" (https://t.co/MGR4zmQlpP)
GPT-3.5 and LLaMA2 fine-tuning guides 🪄 Considering LLM fine-tuning? Here's two new CoLab guides for fine-tuning GPT-3.5 & LLaMA2 on your data using LangSmith for dataset management and eval. We also share our lessons learned in a blog post here: https://t.co/hEHDF3e7jI https://t.co/n8avco0TKA
🎓 Probabilistic Machine Learning This is genuinely a one-of-a-kind resource for students looking to get well-versed in machine learning. The trilogy book includes: - Book 0: Machine Learning: A Probabilistic Perspective (2012) - Book 1: Probabilistic Machine Learning: An Introduction (2022) - Book 2: Probabilistic Machine Learning: Advanced Topics (2023) These books also have accompanying notebooks/codes. An impressive book series by @sirbayes 👏 books: https://t.co/HfrZNpki5t notebooks: https://t.co/xgzrH2TpCK

Big news. Meta just announced SeamlessM4T, a competitor to Google translate. *turn sound on* SeamlessM4T is a multimodal foundational speech/text translation and transcription model capable of handling: 📥 101 languages for speech input ⌨️ 96 Languages for text input/output 🗣️ 35 languages for speech output It achieves SOTA by using Fairseq2, a new modeling toolkit, and the largest open dataset for multimodal translation, totaling 470k hours. This unified model enables multiple tasks without relying on multiple separate models: ▸ Speech-to-speech translation (S2ST) ▸ Speech-to-text translation (S2TT) ▸ Text-to-speech translation (T2ST) ▸ Text-to-text translation (T2TT) ▸ Automatic speech recognition (ASR)
A trend to watch: Retrieval in the Loop. Had a good discussion with @_superAGI @ishaanbhola @philipvollet @mlejva @silennai regarding this subject and finally got some time to get some thoughts down. We currently think of retrieval mostly as providing context in one shot, either at the beginning of a chat or the beginning of an agent process. However what we have found at @llama_index is that it’s often more useful to do retrieval at every step, either every chat in ContextChatEngine or every agent step in our Data Agents. Why? Because the LLM can almost inevitably benefit from new relevant context. Remember at this point ChatGPT’s knowledge cutoff is almost 2 years old. I saw @atroyn predict that in the future we will be doing retrieval on every token or even in the attention heads themselves. While I’m not sure they’ll go that far for latency reasons among others, I would very much welcome it if the LLM providers would formalize a “context message” just like the “system message” today. If you’re building a LLM application today the key thing to ask yourself is “would the LLM benefit from more context?” In most cases the answer is yes.

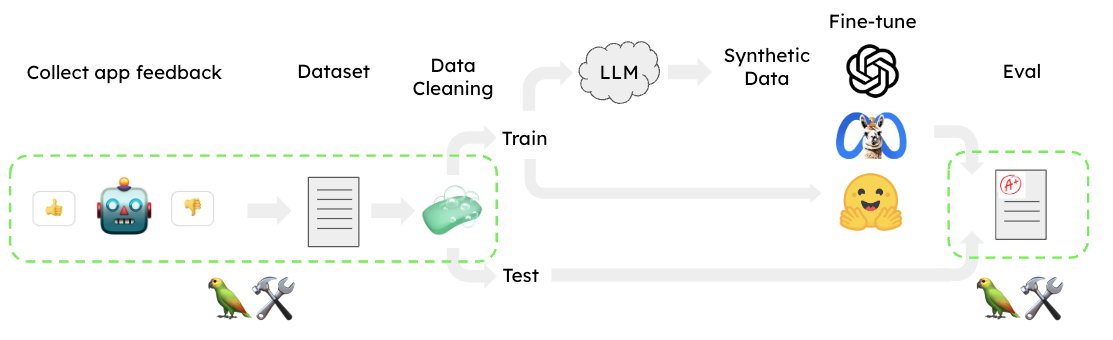
We successfully made gpt-3.5-turbo output GPT-4 quality responses in an e2e RAG system 🔥 Stack: automated training dataset creation in @llama_index + new @OpenAI finetuning + ragas (@Shahules786) eval We did this in a day ⚡️ Full Colab notebook here: https://t.co/GryLUrpd85 https://t.co/HZY21mJ0Pg

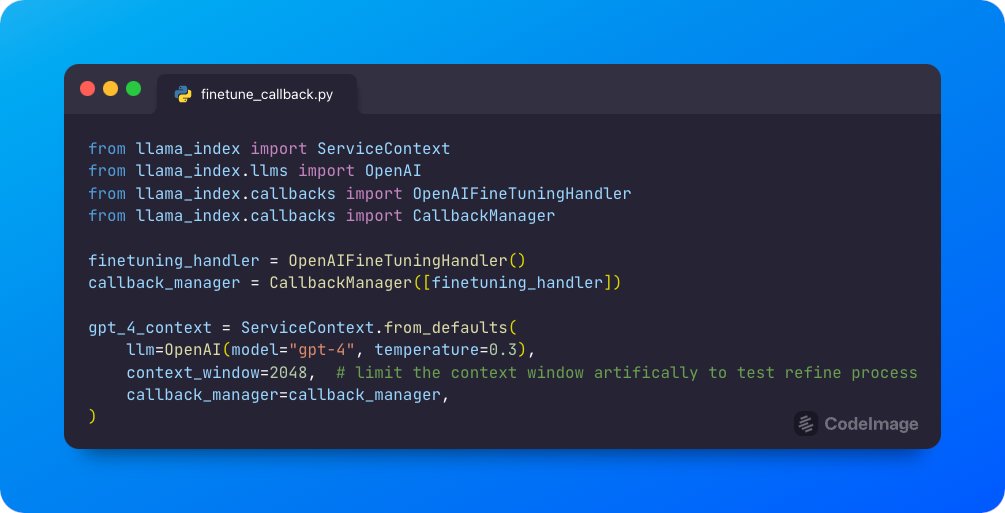
A core use case for @OpenAI’s new finetuning API is finetuning gpt-3.5-turbo over gpt-4 outputs. Our new `OpenAIFineTuningHandler` makes data collection for this effortless. When running RAG w/ GPT-4, automatically get a dataset you can fine-tune a cheaper model over 👇 https://t.co/nmTaO3S6tJ