Your curated collection of saved posts and media
A use case that we’ve heard repeatedly from users is time-based retrieval for RAG systems. ⏱️ We’re excited to integrate with @TimescaleDB - not just a vector db, but also: ✅ time-based filters ✅ much faster/cheaper storage than pgvector Full blog 📗: https://t.co/vu7PD9zyEt https://t.co/ZErPPlgGo5

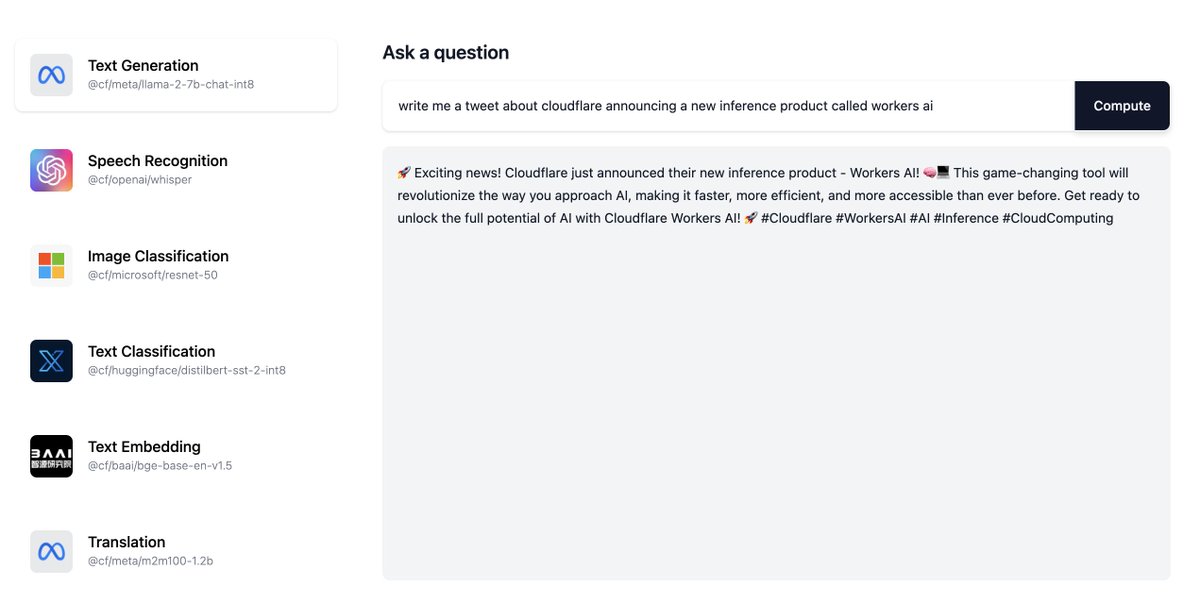
The pricing of @Cloudflare #WorkersAI is as revolutionary as the fact it runs everywhere. Pay only for when we’re doing inference work for you. No more paying for idle VMs. Truly the first #Serverless AI platform. https://t.co/yeVQI7DoUC https://t.co/1TmZwkrr36

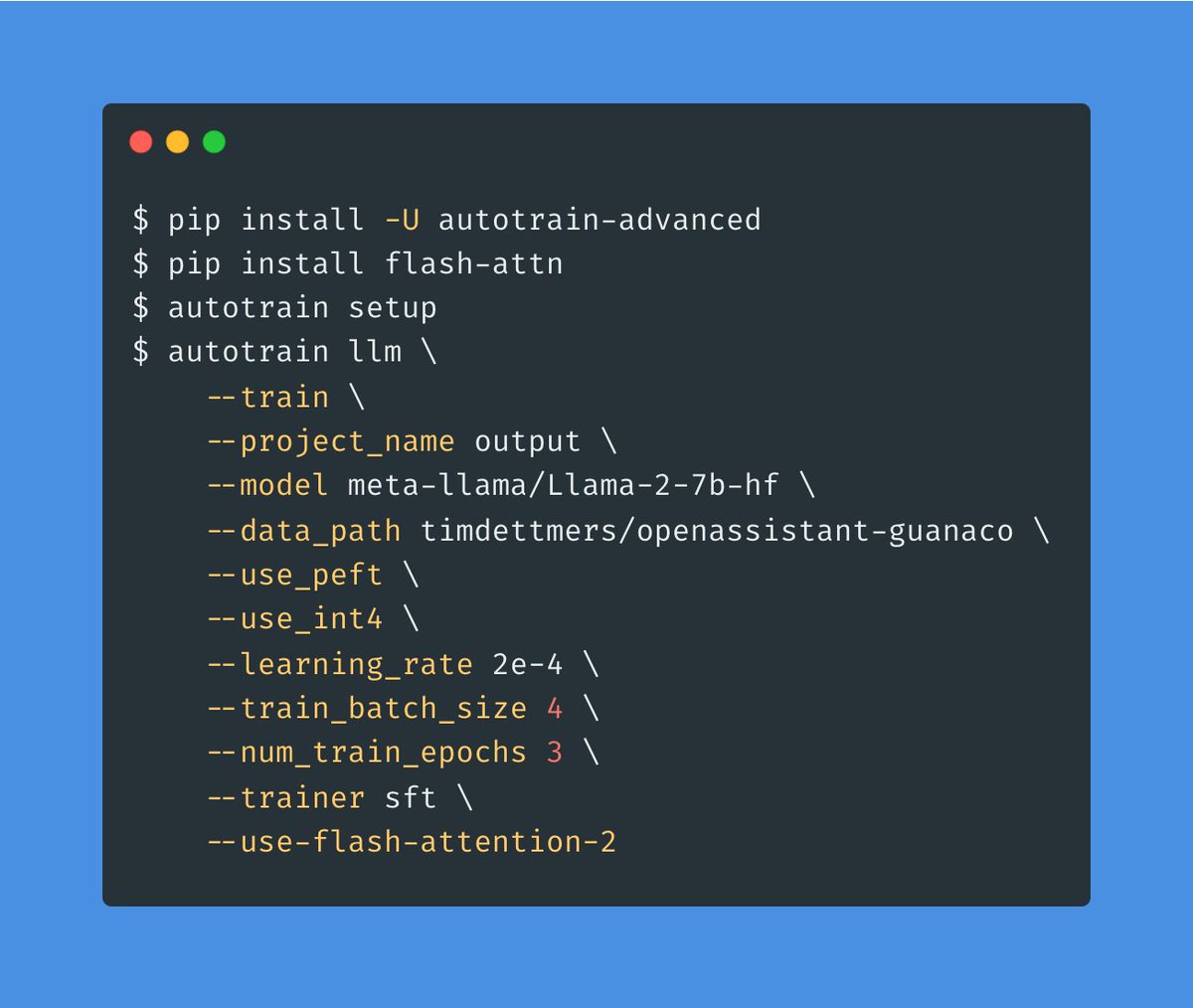
It takes only one extra argument to use Flash Attention 2 with AutoTrain Advanced 🚀🚀🚀 https://t.co/FBZqAoE5Uk
Excited to host Matthew Honnibal, founder of Explosion and @spacy_io author, at our Generative AI World Summit! He'll dive deep into in-context learning's power and practicality, shedding light on distillation and LLM-guided annotation. Don't miss it! #MLOpsWorld2023 @Honnibal https://t.co/KBwVFsfrgP

https://t.co/0C0foxQ3RK it's live! the first GPU inference cloud running on region earth 🌎 https://t.co/vvMSCHaeev
https://t.co/Wpyv9gtj9T

Used @Shopify "SDXL Background Replacement for Product Images" Space. Pretty cool Prompt was: "starbucks cafe" on Messi's image. https://t.co/q0svwKIh5Y

LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models with @Gradio demo github: https://t.co/CfxqzpViJC gradio demo: https://t.co/TcsovxAGT7 https://t.co/qozFE6UCQ0

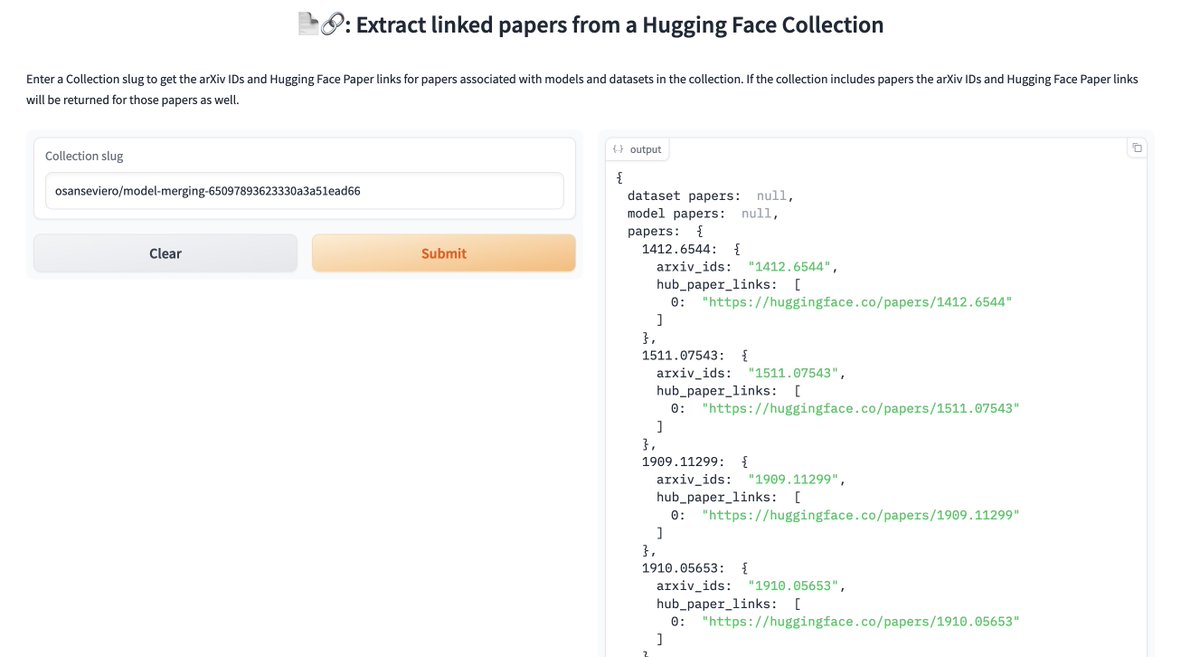
The new Collections API in the huggingface_hub library is super helpful! I've made a basic Space that allows you to: 1. Pass in a @huggingface Collection 2. Get back all the papers associated with the models + datasets in that collection. Try it here: https://t.co/iPYEvj6qrM https://t.co/9hg3fqZral
I bought an @Apple Watch Ultra 2 Today Decided to abuse it’s 4 core neural engine Got GPT-2 running locally on this bad boy 🔥 https://t.co/XmTEVd3anV
Jurassic Park: Anime Edition - Video2Video AI by u/DPC_1 https://t.co/WFWUgM4HhL
Efficient Post-training Quantization with FP8 Formats paper page: https://t.co/zcAlWLLk2p Recent advances in deep learning methods such as LLMs and Diffusion models have created a need for improved quantization methods that can meet the computational demands of these modern architectures while maintaining accuracy. Towards this goal, we study the advantages of FP8 data formats for post-training quantization across 75 unique network architectures covering a wide range of tasks, including machine translation, language modeling, text generation, image classification, generation, and segmentation. We examine three different FP8 representations (E5M2, E4M3, and E3M4) to study the effects of varying degrees of trade-off between dynamic range and precision on model accuracy. Based on our extensive study, we developed a quantization workflow that generalizes across different network architectures. Our empirical results show that FP8 formats outperform INT8 in multiple aspects, including workload coverage (92.64% vs. 65.87%), model accuracy and suitability for a broader range of operations. Furthermore, our findings suggest that E4M3 is better suited for NLP models, whereas E3M4 performs marginally better than E4M3 on computer vision tasks.

QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models paper page: https://t.co/RKBzkiuDhs Recently years have witnessed a rapid development of large language models (LLMs). Despite the strong ability in many language-understanding tasks, the heavy computational burden largely restricts the application of LLMs especially when one needs to deploy them onto edge devices. In this paper, we propose a quantization-aware low-rank adaptation (QA-LoRA) algorithm. The motivation lies in the imbalanced degrees of freedom of quantization and adaptation, and the solution is to use group-wise operators which increase the degree of freedom of quantization meanwhile decreasing that of adaptation. QA-LoRA is easily implemented with a few lines of code, and it equips the original LoRA with two-fold abilities: (i) during fine-tuning, the LLM's weights are quantized (e.g., into INT4) to reduce time and memory usage; (ii) after fine-tuning, the LLM and auxiliary weights are naturally integrated into a quantized model without loss of accuracy. We apply QA-LoRA to the LLaMA and LLaMA2 model families and validate its effectiveness in different fine-tuning datasets and downstream scenarios.

From image to live website using GPT-4 vision and @Replit in less than a minute. Things are about to get so interesting. 🔥 https://t.co/Mtbqjbgd5Q
From now on I’m now going to be using AI to build software by simply drawing it. https://t.co/qKovq5CJBA
LLM Alignment Survey Okay, so this is a nice comprehensive survey paper on LLM alignment. No AGI yet so it's worth reading.😅 It has a nice structure covering the following topics: - Why LLM Alignment? - What is LLM Alignment? - Outer Alignment - Inner Alignment - Mechanistic Interpretability - Attacks on Aligned LLMs - Alignment Evaluation - Future Directions and Discussions https://t.co/xo4AjL6AW5
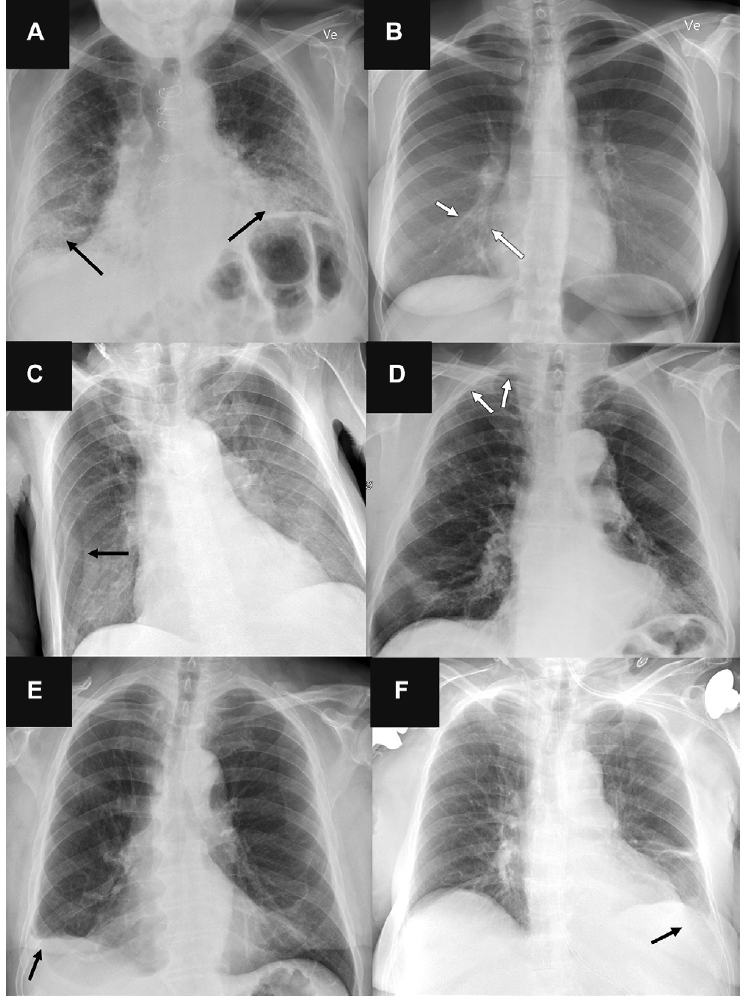
Here's a twist: The radiologists outperformed the #AI 72 radiologists more accurate chest X-ray interpretation (N >2,000) than 4 commercially available AI tools https://t.co/I8LEhLj3D2 @radiology_rsna https://t.co/ScpfeC972O
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning paper page: https://t.co/3OsWSqMeXU Although recent text-to-video (T2V) generation methods have seen significant advancements, most of these works focus on producing short video clips of a single event with a single background (i.e., single-scene videos). Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules such as image generation models. This raises an important question: can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation. Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a 'video plan', which involves generating the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities and backgrounds. Next, guided by this output from the video planner, our video generator, Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities/backgrounds across scenes, while only trained with image-level annotations. Our experiments demonstrate that VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with visual consistency across scenes, while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. We also demonstrate that our framework can dynamically control the strength for layout guidance and can also generate videos with user-provided images. We hope our framework can inspire future work on better integrating the planning ability of LLMs into consistent long video generation.
BREAKING: We have partnered with @OpenAI to launch WHOOP Coach today, the most advanced generative AI feature to ever be released by a wearable. Members can now ask @whoop anything about their data - and receive instant feedback. https://t.co/wnzjzj2xX2
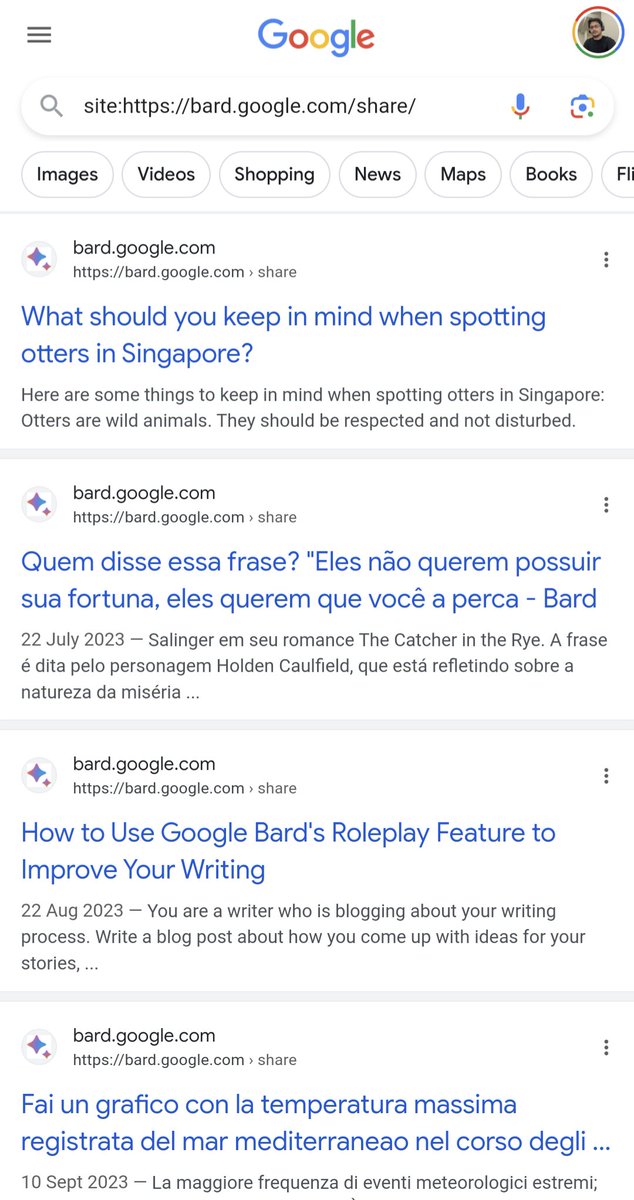
Haha 😂 Google started to index share conversation URLs of Bard 😹 don't share any personal info with Bard in conversation, it will get indexed and may be someone will arrive on that conversation from search and see your info 😳 Also Bard's conversation URLs are ranking as snippets for some queries as well 🤣🤣
Aligning Large Multimodal Models with Factually Augmented RLHF paper page: https://t.co/2ZC1yEvfUO Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in "hallucination", generating textual outputs that are not grounded by the multimodal information in context. To address the multimodal misalignment issue, we adapt the Reinforcement Learning from Human Feedback (RLHF) from the text domain to the task of vision-language alignment, where human annotators are asked to compare two responses and pinpoint the more hallucinated one, and the vision-language model is trained to maximize the simulated human rewards. We propose a new alignment algorithm called Factually Augmented RLHF that augments the reward model with additional factual information such as image captions and ground-truth multi-choice options, which alleviates the reward hacking phenomenon in RLHF and further improves the performance. We also enhance the GPT-4-generated training data (for vision instruction tuning) with previously available human-written image-text pairs to improve the general capabilities of our model. To evaluate the proposed approach in real-world scenarios, we develop a new evaluation benchmark MMHAL-BENCH with a special focus on penalizing hallucinations. As the first LMM trained with RLHF, our approach achieves remarkable improvement on the LLaVA-Bench dataset with the 94% performance level of the text-only GPT-4 (while previous best methods can only achieve the 87% level), and an improvement by 60% on MMHAL-BENCH over other baselines.

VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning proj: https://t.co/LkM4R6scJR abs: https://t.co/MLEU8X2H28 https://t.co/vXX5JCj8ng
InternLM-XComposer: A Vision-Language Large Model for Advanced Text-image Comprehension and Composition repo: https://t.co/KRsvtro5Fd abs: https://t.co/QXggklCvKC https://t.co/kSHO06ytGx

🎓TinyML and Efficient Deep Learning Computing You can now catch up on the efficient ML space with this new set of YouTube lectures by MIT. Topics include model compression, pruning, quantization, neural architecture search, distributed training, data/model parallelism, gradient compression, and on-device fine-tuning. As we look ahead, it's starting to become very clear on the importance of this topic. I might summarize a few of these and share my takeaways/notes in an upcoming post. https://t.co/Tu6k4WFurd

🚨 We're getting ready to start the first pilot runs of our Training Cluster as a service 🚨 so reach out to @huggingface if you'd like your org/company to be a part of it! cc @ClementDelangue https://t.co/2QfrOupCYo
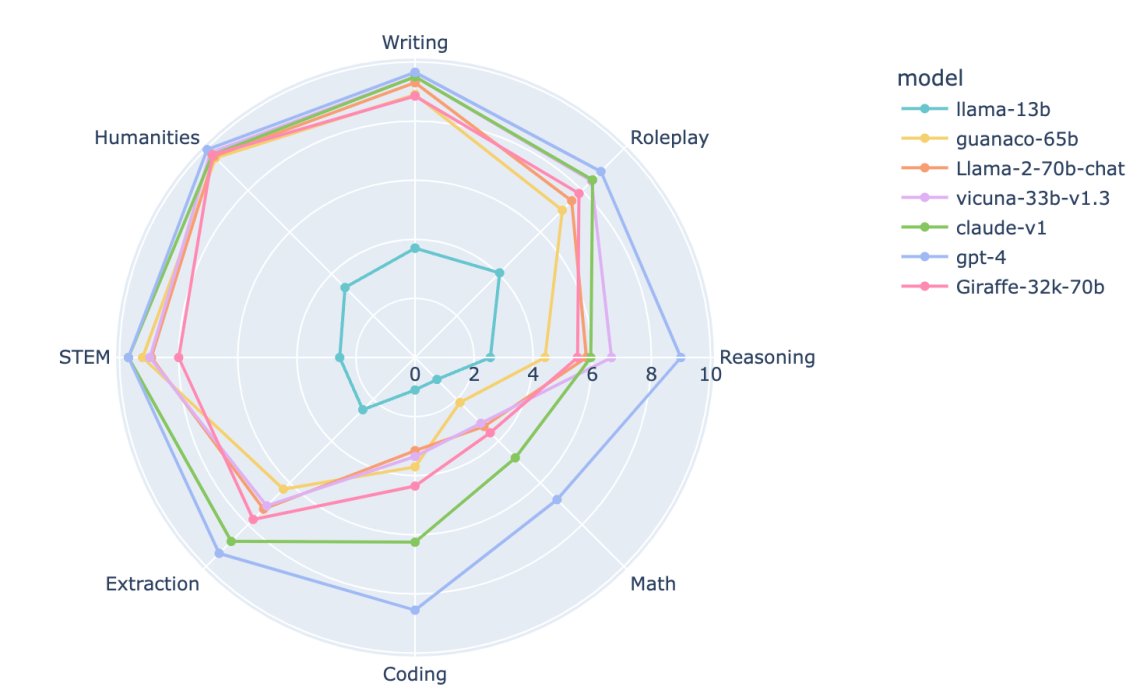
Closing the Gap to Closed Source LLMs – Open-Sourcing 70B Abacus Giraffe! The best-performing open-source model on MT-bench in key categories We are super excited to be open-sourcing our best model for Enterprise AI use cases - the 70B 32K context length Abacus Giraffe model! Abacus Giraffe, based on the 70B Llama-2 offers all the performance gains of Llama-2 with the additional advantage of having a 32K context length Giraffe is a family of models that are finetuned from base Llama 2 and use context length extension techniques to increase their effective context length capability from 4096 to approximately 32000. The longer context window improves performance on many downstream tasks and allows new use cases for the model that a short context length may not permit. We conducted an evaluation of the 70B model on our set of benchmarks that probe LLM performance over long contexts. The 70B model improves significantly at the longest context windows (32k) for the document QA task vs. the 13B model, scoring 61% accuracy vs. the 18% accuracy of 13B on our AltQA dataset. We also find that it outperforms the comparable LongChat-32k model at all context lengths, with an increasing performance at the longest context lengths (recording 61% vs. 35% accuracy at 32k context length). In addition, we ran 70B Giraffe on the MT-Bench evaluation set. MT-Bench examines the performance of LLMs in multi-turn settings (i.e. more than a single question and answer) across a variety of categories, such as Writing, Coding, and Math. The results of this and the comparison to some other LLMs can be seen in the figure above. 70B Giraffe 32k shows the best performance of all the open-source models in the categories of Extraction, Coding, and Math, and maintains a high score in the other categories. There is still a gap in performance in these categories to the best-closed source models – but we here at Abacus are excited to try to close that gap further. Our blog post including links to our git-repo and evals here - https://t.co/vLuAdQYV41
Logical Chain-of-Thought in LLMs Proposes a new neurosymbolic framework to improve zero-shot chain-of-thought reasoning in LLMs. Leverages principles from symbolic logic to verify and revise reasoning processes to improve the reasoning capabilities of LLMs. The think-verify-revise framework is a neat idea and it might be useful to deal with hallucination issues that appear in different scenarios especially those that require multi-step reasoning. Shows efficacy in domains like arithmetic, commonsense, and causal inference, among others. The effective use of knowledge by enhancing reasoning via logic intuitively makes sense but it sounds expensive given the inefficiencies of LLMs today. https://t.co/yWsDLOamgC

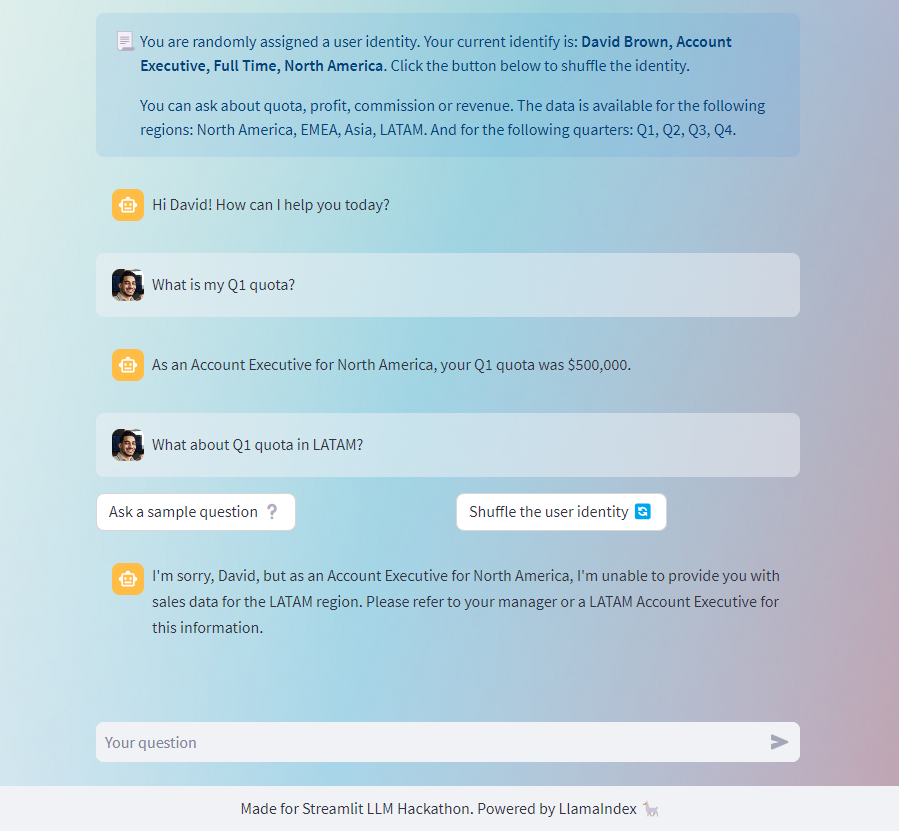
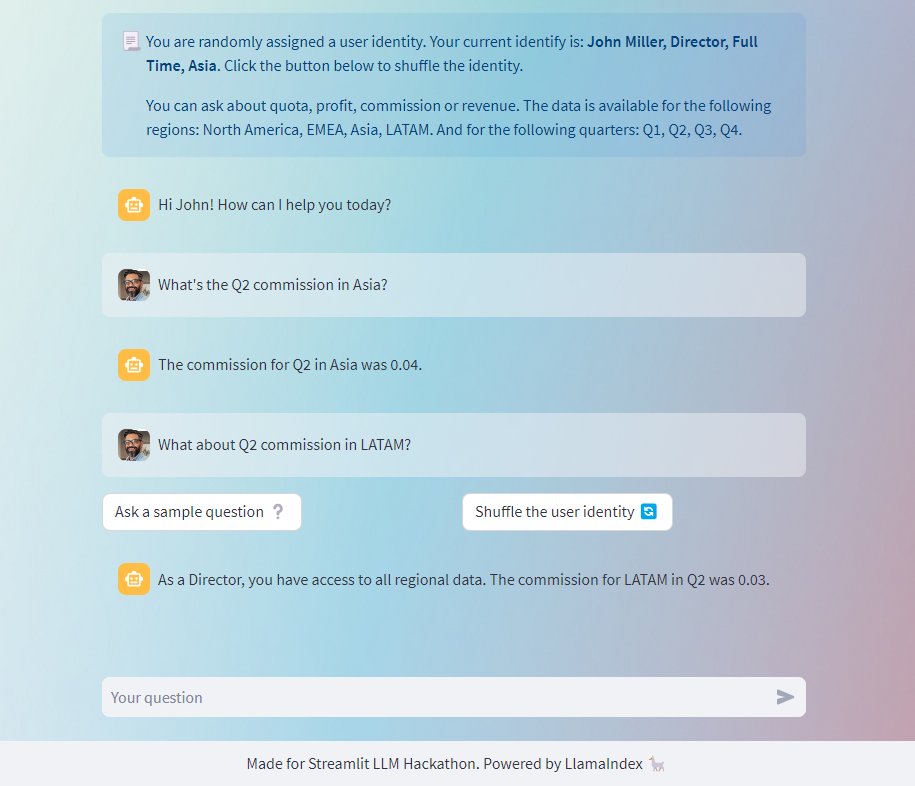
The September was hectic, but I couldn't miss the @streamlit LLM Hackathon! I built a user-identity-aware chatbot trained on fictional sales data, and following IAM policy (share this data with these roles & don't share with others, etc). Powered by @llama_index https://t.co/xjy3F1q39q
Stepping into the Matrix ... of neural networks, literally. PyTorch never fails to fascinate! It's a really cool visualization tool for matrix, attention, parallelism, and more. The best education comes from the most intuitive delivery. This is a multilayer perceptron with data-parallel partitioning. Interactive demos: https://t.co/PUKQWOSr03
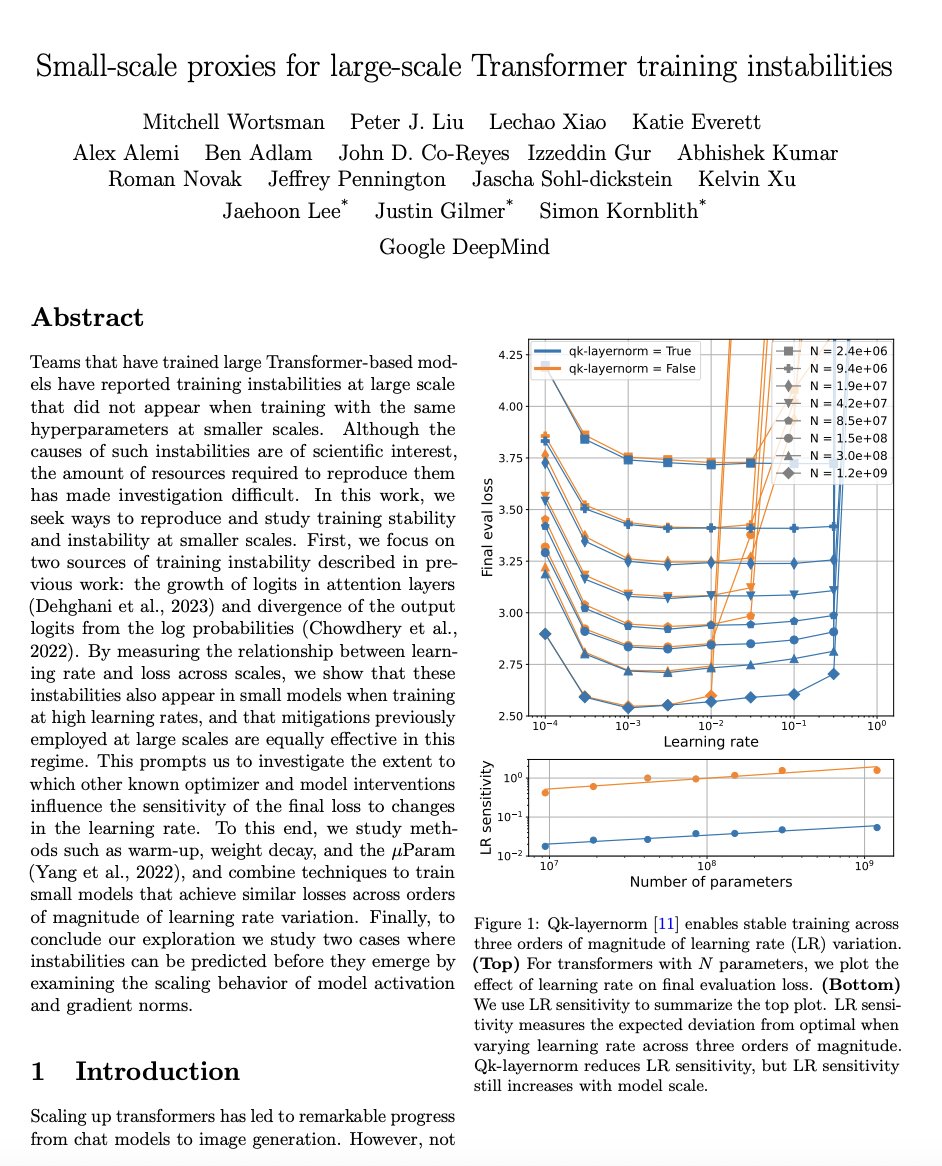
Small-scale proxies for large-scale Transformer training instabilities paper page: https://t.co/AGkQabGVob Teams that have trained large Transformer-based models have reported training instabilities at large scale that did not appear when training with the same hyperparameters at smaller scales. Although the causes of such instabilities are of scientific interest, the amount of resources required to reproduce them has made investigation difficult. In this work, we seek ways to reproduce and study training stability and instability at smaller scales. First, we focus on two sources of training instability described in previous work: the growth of logits in attention layers (Dehghani et al., 2023) and divergence of the output logits from the log probabilities (Chowdhery et al., 2022). By measuring the relationship between learning rate and loss across scales, we show that these instabilities also appear in small models when training at high learning rates, and that mitigations previously employed at large scales are equally effective in this regime. This prompts us to investigate the extent to which other known optimizer and model interventions influence the sensitivity of the final loss to changes in the learning rate. To this end, we study methods such as warm-up, weight decay, and the muParam (Yang et al., 2022), and combine techniques to train small models that achieve similar losses across orders of magnitude of learning rate variation. Finally, to conclude our exploration we study two cases where instabilities can be predicted before they emerge by examining the scaling behavior of model activation and gradient norms.
This is absolutely beautiful! Using 3D to visualize matrix multiplication expressions, attention heads with real weights and more. It uses the mm 3D matmul visualizer. https://t.co/2KGb2bRr7e https://t.co/eYiY7quQoc
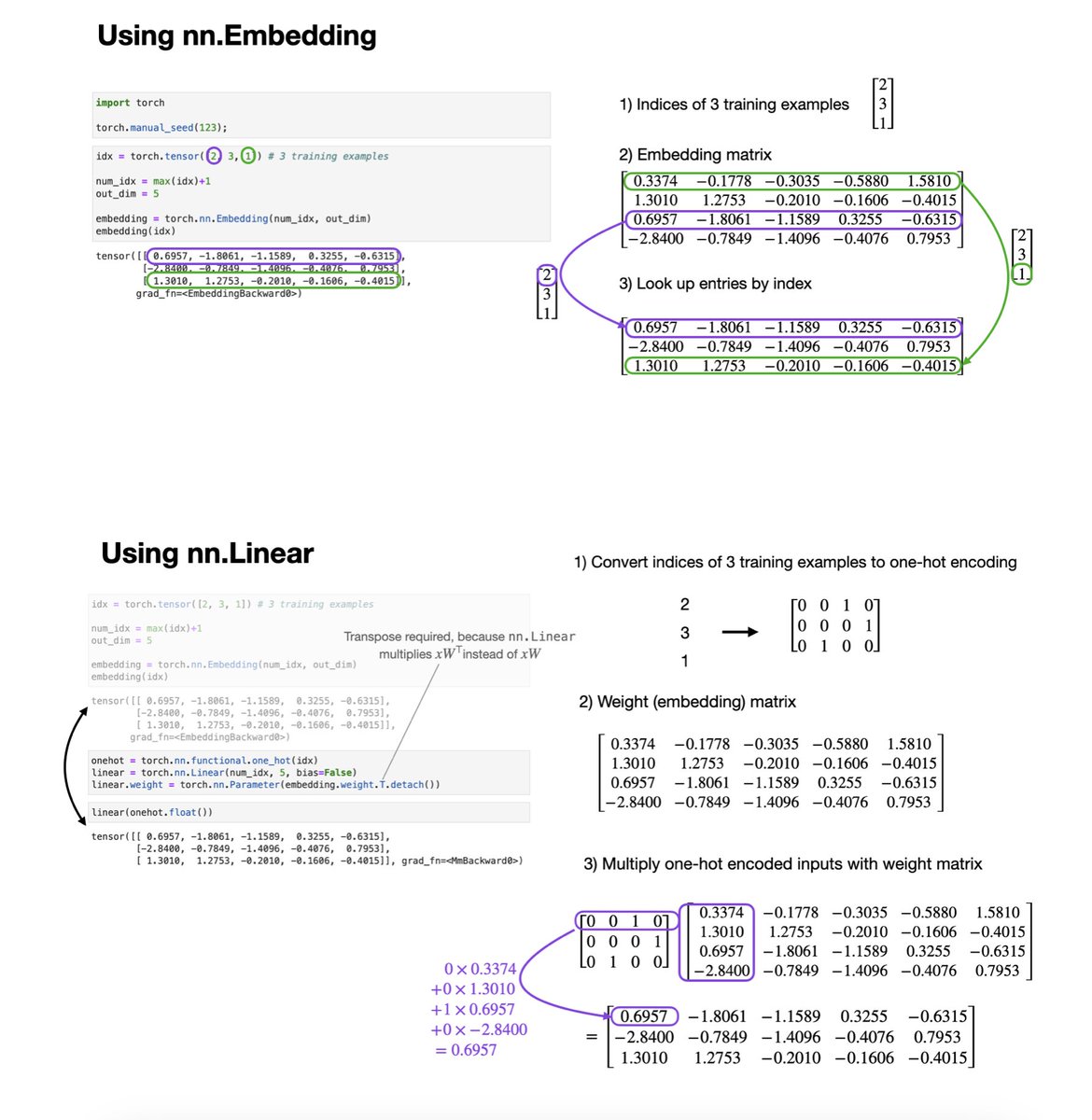
Embedding layers are often perceived as a fancy operation that we apply to encode the inputs (each word tokens) for large language models. But embedding layers = fully-connected layers on one-hot encoded inputs. They just replace expensive matrix multiplications w index look-ups. https://t.co/0I3AFk4por