Your curated collection of saved posts and media
Large Language Models Cannot Self-Correct Reasoning Yet https://t.co/q4HB4mEUG7 https://t.co/jUZliewwSj

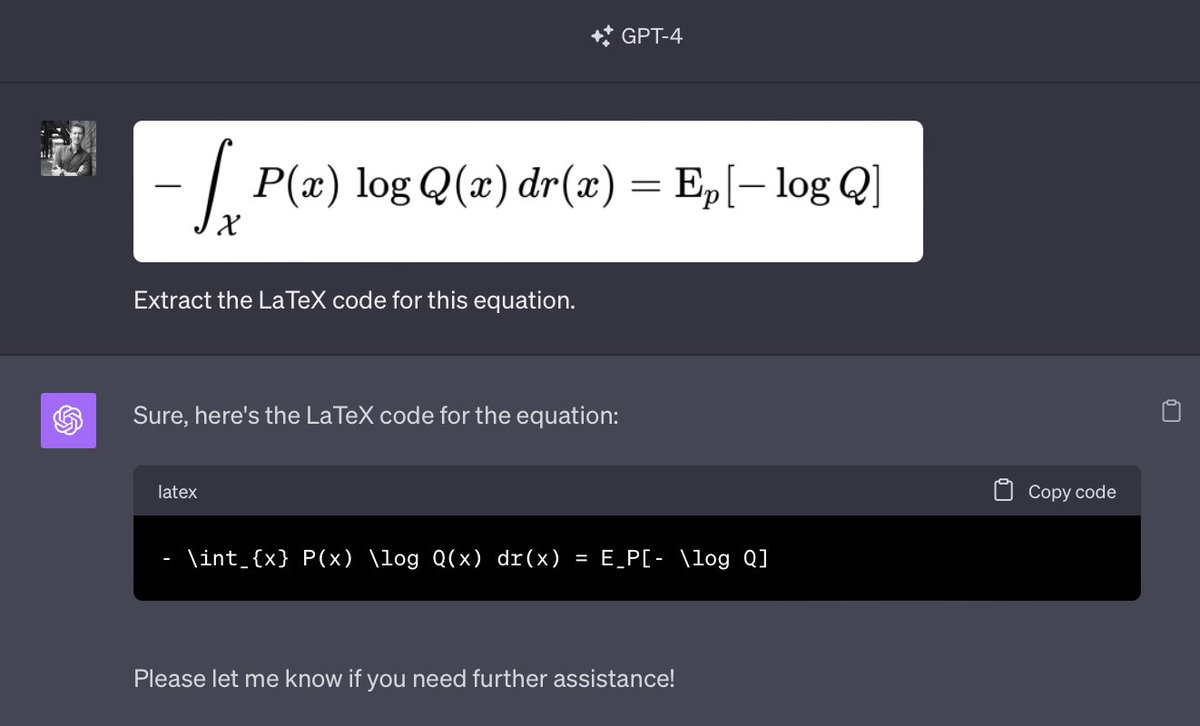
Large Language Models as Analogical Reasoners abs: https://t.co/5msylh8GCJ This Google DeepMind paper proposes a new approach to prompting called "analogical prompting" which asks the LLMs to self-generate relevant examples before solving the problem. https://t.co/7EetTy9NYe
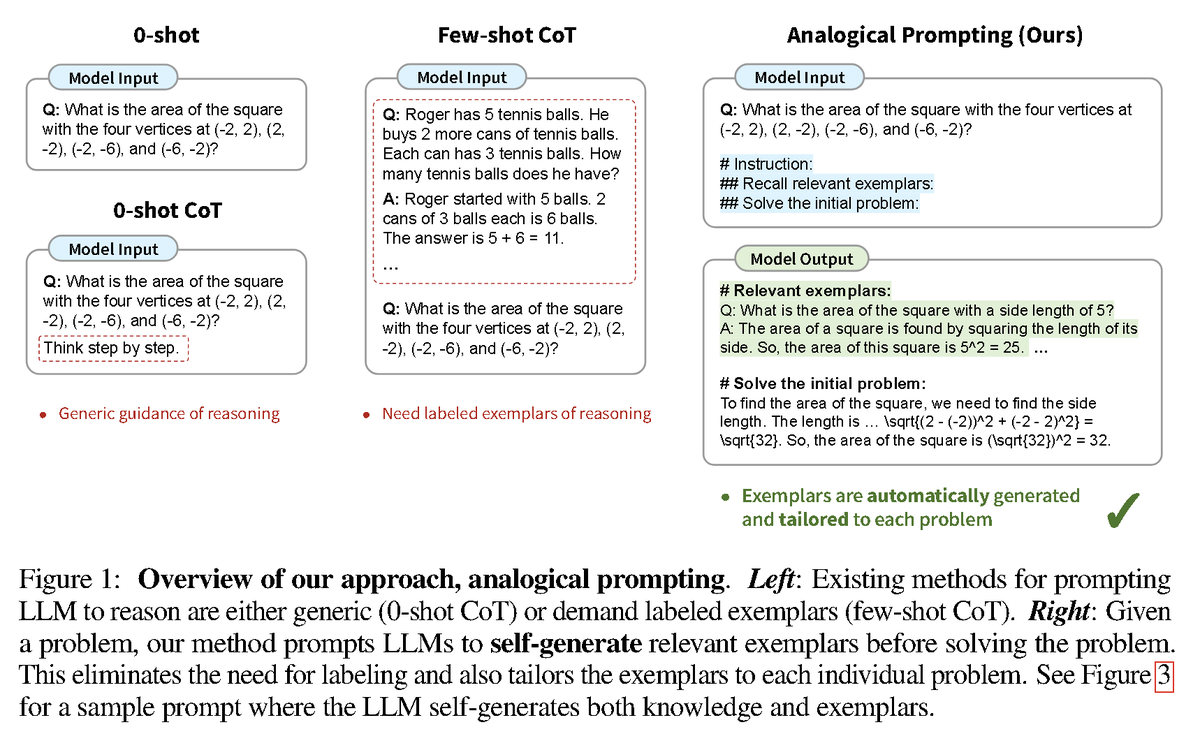
- Analogous to registers for LM - Notable improvements on some tasks (e.g. SQuAD, NaturalQA, CommonSenseQA) - It doesn't work on every task and it's not a replacement of CoT https://t.co/ZZ6t6d331a
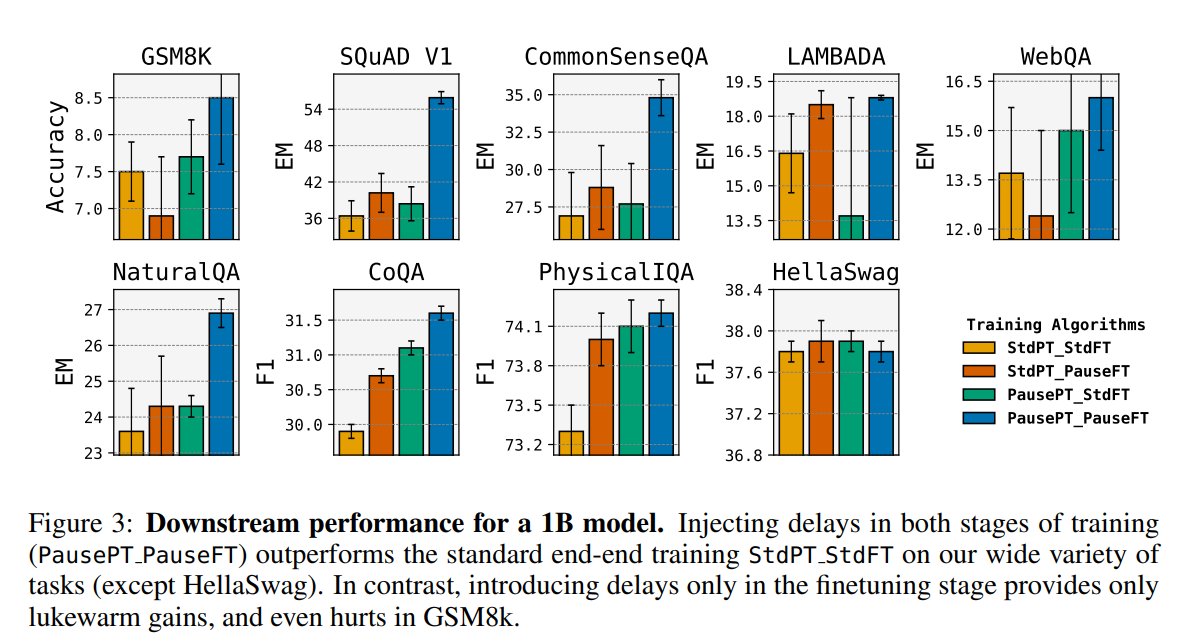
Think before you speak: Training Language Models With Pause Tokens - Performing training and inference on LMs with a learnable pause token appended to the input prefix - Gains on 8 tasks, e,g, +18% on SQuAD https://t.co/snkfjFZhhZ https://t.co/wUhZspVtSj
MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens https://t.co/863hCfcNTA https://t.co/WmQ43b7XUt

OceanGPT: A Large Language Model for Ocean Science Tasks website: https://t.co/NFHh44hbj1 abs: https://t.co/Fn1v8zEIwL The first-ever LLM in the ocean domain (finetuned LLama-2), which excels in various ocean science tasks. Also introduces the first oceanography benchmark called OceanBench. Yet another domain-specific LLM!👀

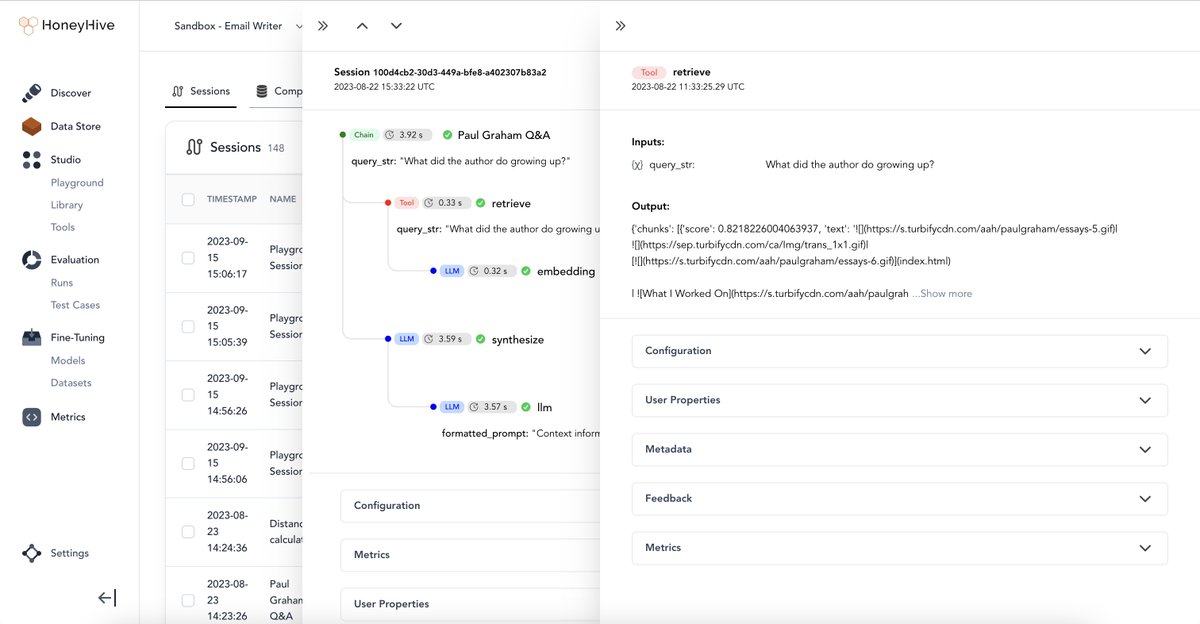
LlamaIndex + @honeyhiveai 🍯🔬 Easily evaluate/monitor/improve multi-step RAG/agent pipelines! Not only can you log traces, you can also log user feedback + collect that for fine-tuning + evals. Full Colab: https://t.co/U9GxImIWzd Doc: https://t.co/bQxPOfFiln https://t.co/pW73G9IarY
wow #gpt4V https://t.co/A3L7kdUd9Q
Today we launched 🌸 Arc Max 🌺 our first set of AI features that we hope level up your every day on the internet. My favorite is Ask in Page! A quick way to get answers I use whenever I'm reading dense, technical documentation. 🧵 Why did we build 20+ prototypes this summer? https://t.co/wuDDF8Ctkm
Think before you speak: Training Language Models With Pause Tokens - Performing training and inference on LMs with a learnable pause token appended to the input prefix - Gains on 8 tasks, e,g, +18% on SQuAD https://t.co/snkfjFZhhZ https://t.co/wUhZspVtSj

These AI features make so much sense to integrate in our browsers. How have no other companies thought of these? Love these updates @browsercompany https://t.co/CTVx99KC0l
In ARC browser open the new tab search bar and type ‘Max’ and it will enable the new AI features.

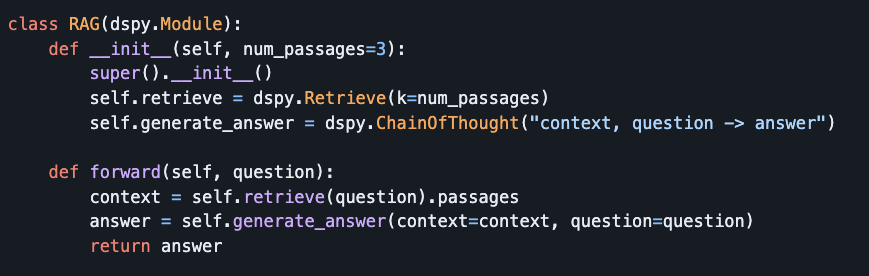
Stanfords DSPy is the best high level LLM programing framework I have seen this far. Langchain never resonated with me; despite being an early LLM framework, its design and abstractions felt overly complex. DSPy, on the other hand, is a huge step in the right direction. DSPy provides a simple approach to defining retrieval and reasoning sequences, using high-level abstractions. It also includes many built in features like "compiling" for prompt adjustments and model fine-tuning, all in a straightforward Pythonic syntax. https://t.co/3ZEW7DG6S3
very underrated @Gradio feature is Annotated Image component, see it in action in OWLv2 👉 https://t.co/oghdLOtoa5 https://t.co/O2NNfzjyzy
We are excited to announce the 1st version of our multimodal assistant, Yasa-1, a language assistant with visual and auditory sensors that can take actions via code execution 🪄. Yasa-1 can understand text, images, videos, sounds & more! 🚀 Check out more details below👇 https://t.co/XX6pRanDhx
How can we improve multi-view 3D object detection? Leveraging appearance-enhanced queries is important! Check our #ICCV2023 work on online 3D object detection with pixel-aligned recurrent queries! Project page: https://t.co/8t3hoR5LsL (1/6) https://t.co/u2kzlkaosq
Structuring LLM outputs is not new, but how do you efficiently structure outputs from a RAG pipeline? Thanks to @bmaxhacks+@LoganMarkewich, you can now get native Pydantic outputs from all our queries, without an extra LLM parsing call! Full 🧵+ guide: https://t.co/lGdKeFsTuP https://t.co/bMjLqOpMHW

How Can Open Source LLMs catch up to GPT-4V and Google's Gemini? Open-source LLMs are getting really good. However, they are not as powerful as GPT-4 right yet. Plus, mutlimodal models like GPT-4V and Google's Gemini will be dropping soon... making it even harder for open-source models to catch up to these closed APIs The trillion dollar question is, can open source models close the gap to closed source models? The answer is a cautiously optimistic - Probably! Here is how I see the open-source ecosystem evolving and catching up to SOTA closed source models over the next 12-18 months. Training multimodal open-source models - We at Abacus are working open-source multimodal models and I am hopeful that all other open-source research labs are doing the same thing. The good news is there is a clear path to building these and you can start with a pre-trained models like Llama-2 A common approach is to start with a pre-trained language model and then fine-tune it on multimodal tasks using a dataset that contains multiple types of data such as text, images, and/or audio. During this fine-tuning process, the model learns to relate information across different modalities, improving its performance on the target multimodal tasks. For instance, you might fine-tune a pre-trained language model using a dataset of images and associated captions to create a model that can generate descriptive text for new images it encounters. For example, Google used this technique by extending the initial PaLM language model. PaLM-E was enriched with sensor data from robots. This transitioned PaLM into a multimodal model, PaLM-E, capable of handling diverse tasks across robotics, visual, and language domains. Mimic-ing mixture of experts: Rumors suggest that GPT-4 may utilize a Mixture of Experts (MoE) architecture, where multiple smaller models, each specialized in different tasks, collaborate to process data. This setup allows the handling of a vast number of parameters more efficiently by distributing them across these "experts". It's speculated that such an architecture could help GPT-4 manage a more diverse range of tasks and data, scaling up its capacity and capability while controlling computational and memory demands. Mimic-ing this structure with open-source models is not hard. You can always instruct tune open-source models to be very good at a particular tasks and you then use multiple models each instruct tuned for a specific task to "collaborate" to answer queries. Leaderboards and benchmarks We already have a bustling open-source community with a number of LLM benchmarks including MT-bench where you can easily measure how your LLM compares to others. Open-source labs and developers are engaged in a constant race to beat SOTA open-source models. The community has already caught up to 3.5 and GPT-4 when fine-tuned for a particular task. The benchmarks are only going to get more robust as more and more open-source models are dropped New more powerful open-source models A number of companies including Meta, have committed to training next generation multimodal LLMs and open-sourcing them. Smarter AI alignment and RLHF - Open source models don't have as much scrutiny as big tech. This means that they don't need as much safety lobotomy as big tech closed-source APIs. The safety lobotomy has a harmful side effect of killing legitimate queries. For example Llama-2 refused to answer the query "how to kill a linux process" citing 'safety reasons'. Mistral-7B however answered that question correctly All this means that eventually open-source will likely catch up to closed source models. Over time, more efficient smaller models will match performance of larger models, reducing the need to have thousands of GPUs Already the Mistral-7B models beats the 13B Llama-2. We will continue to see such improvements on a on-going basis. At some point the law of diminishing returns will kick in for Google and OpenAI, unless there is a significant breakthrough in NNs and AI tech - i.e. just throwing more compute or data at the problem won't necessarily dramatically improve performance. This means that while open-source models may still be a year away from GPT-4, they will start closing the gap quickly!
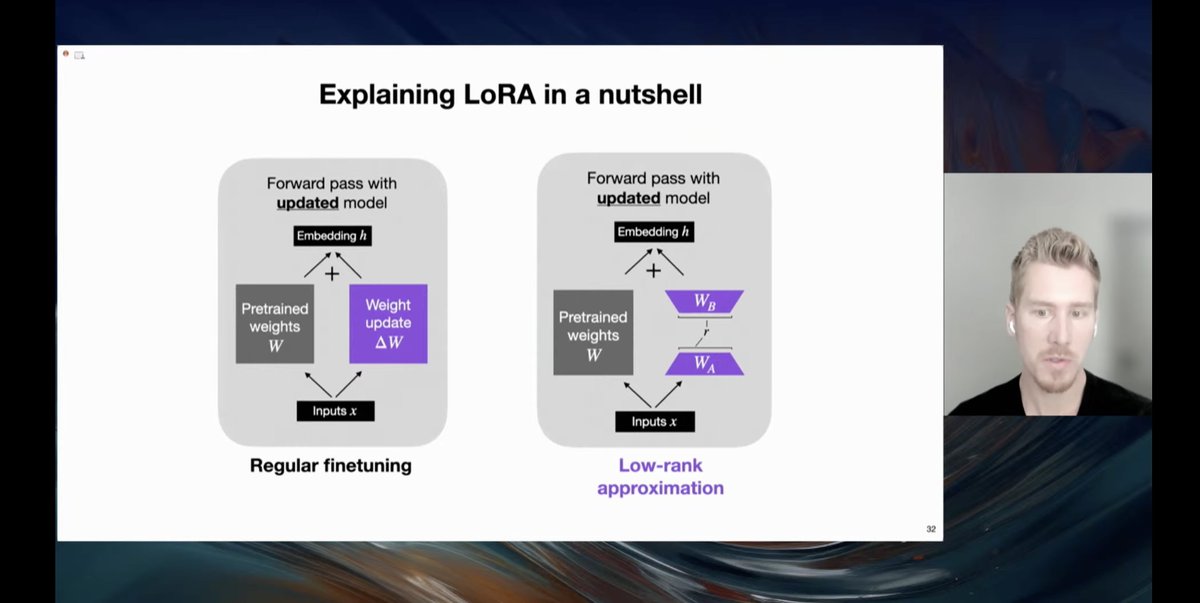
Absolutely Love @rasbt's talk on fine-tuning happening now! I learned: - various ways of fine-tuning including LoRA - performance comparison of different methods - lit-gpt for downloading models, datasets, and fine-tuning - NeurIPS Large Language Model Efficiency Challenge https://t.co/BOYBGIBgwu
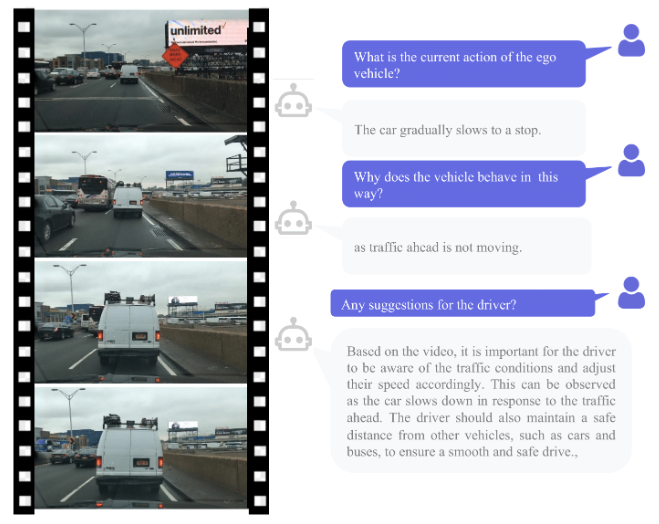
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model proj: https://t.co/d3gm2Ff4OQ abs: https://t.co/KjVdEZsz5m https://t.co/boB8Xio22u
It's not AGI but it's actually incredibly useful: https://t.co/20Q5uZdDNu
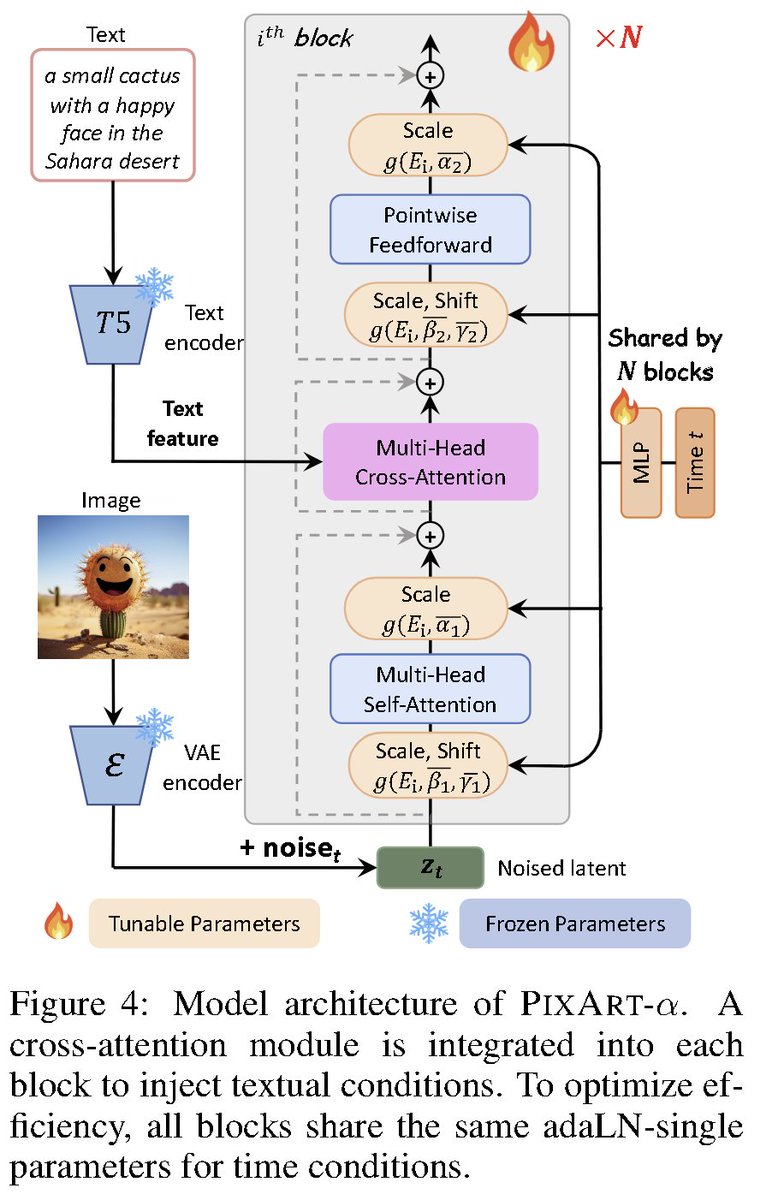
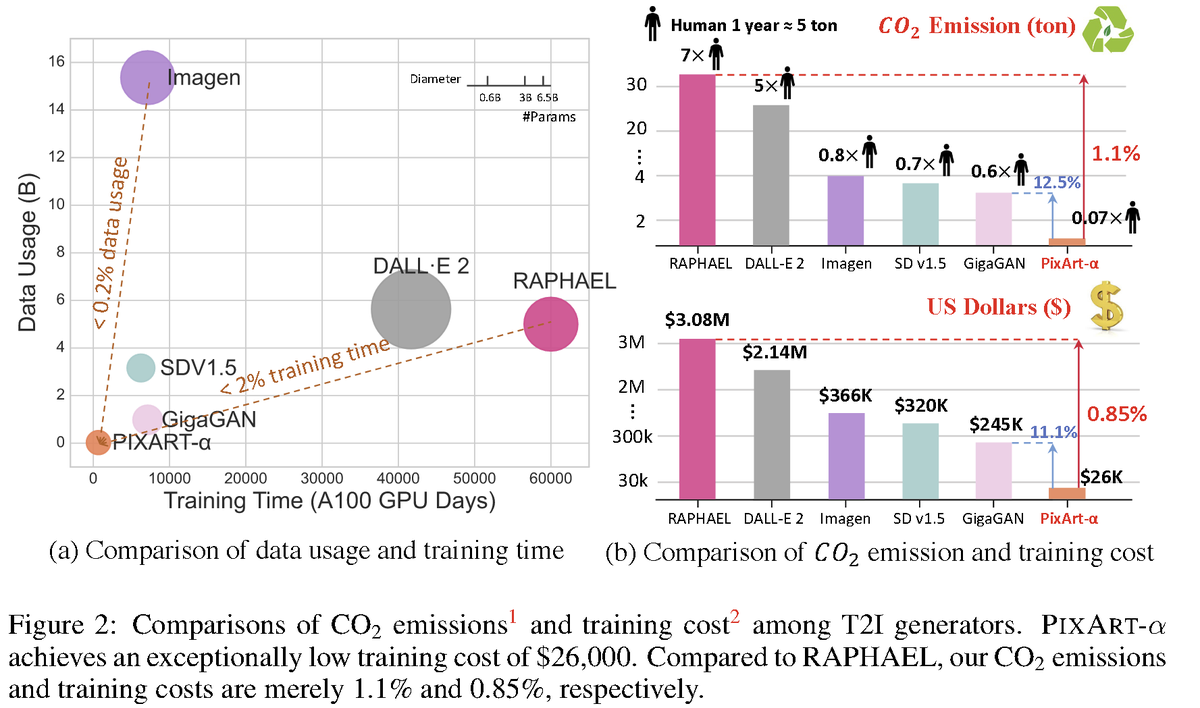
PIXART-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis website: https://t.co/tSb1PkV2k0 abs: https://t.co/mP8P7LUHz6 A transformer-based T2I diffusion model that only takes 10.8% of SD v1.5's training time while competitive with SOTA results. Training is divided into three phases: (1) learning the pixel distribution of natural images, (2) learning text-image alignment, and (3) enhancing the aesthetic quality of images. A modified DiT architecture is used.
Representation Engineering: A Top-Down Approach to AI Transparency Identifies and characterizes the emerging area of representation engineering, an approach to enhancing the transparency of AI systems that draws on insights from cognitive neuroscience https://t.co/Nn3LEqQV0u https://t.co/3oPmSlyGzN

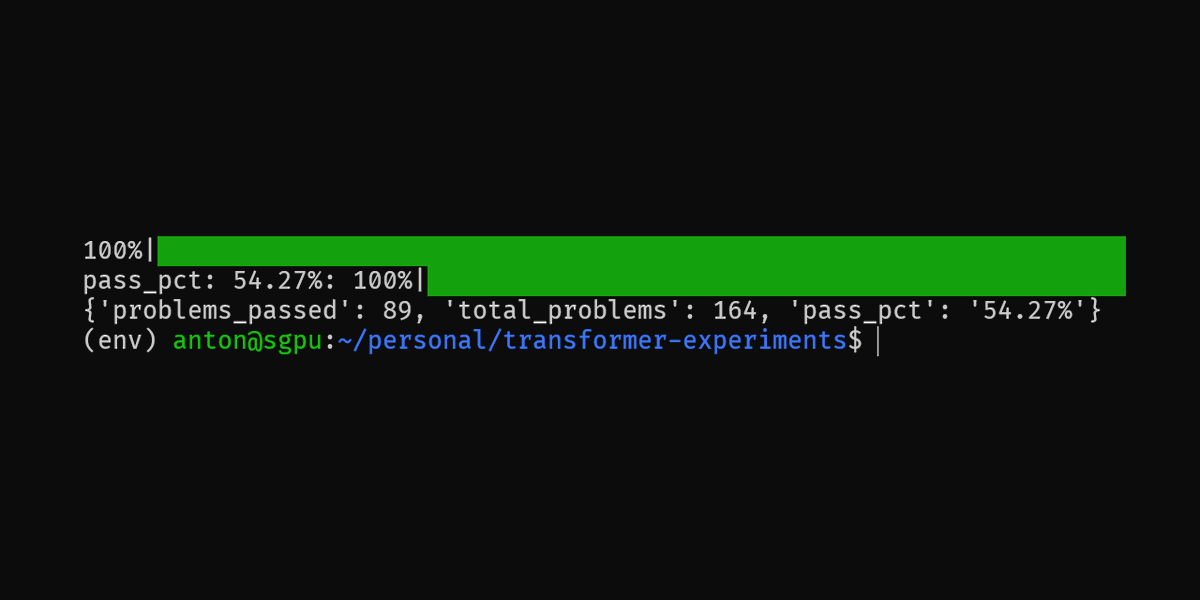
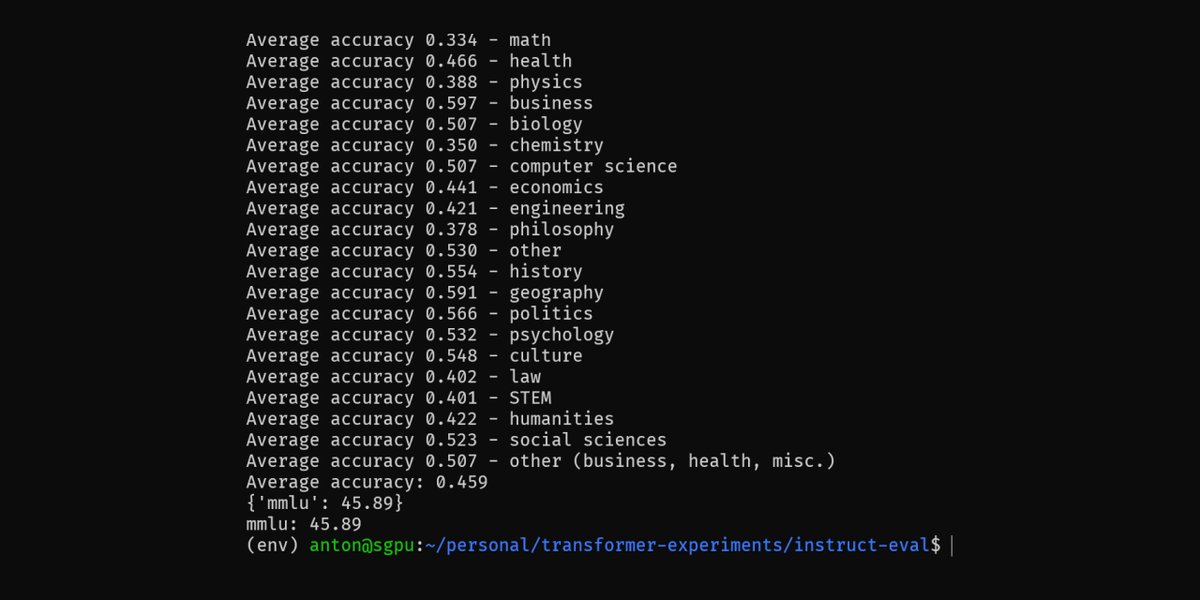
Releasing mistral-7b-sft, an initial fine-tune for code completion, explanation and repair. MMLU scores dropped from the base mistral model (as expected) but still much higher than codellama model and comparable to llama-2 7b HumanEval: pass@1 54.27% MMLU: 45.89% https://t.co/C4SfYepsOl
Introducing Rewind Pendant - a wearable that captures what you say and hear in the real world! ⏪ Rewind powered by truly everything you’ve seen, said, or heard 🤖 Summarize and ask any question using AI 🔒 Private by design Learn more & preorder: https://t.co/f7KLA22HeW
The Dawn of LMMs Analysis of GPT-4V to deepen the understanding of large multimodal models (LMMs). It focuses on probing GPT-4V across various application scenarios. 150 pages of examples ranging from code capabilities with vision to retrieval-augmented LMMs. "The findings reveal its remarkable capabilities, some of which have not been investigated or demonstrated in existing approaches." https://t.co/VR1GPxQIBh

Thanks to GGML and Apple M2 Max, I can run GitHub Copilot locally on my laptop with one click. Check out LocalPilot! https://t.co/A1MG2sIKPT
You can now get a full tracing/observability UI in *all* @llama_index RAG/agent pipelines, in one-line of code ⚡️ Bonus: all your data lives locally! 🔐 We're launching a native integration with @arizeai Phoenix 🔥. Full 🧵 below. Full Colab nb: https://t.co/JexIInOaUs https://t.co/BGCHlE5JPL
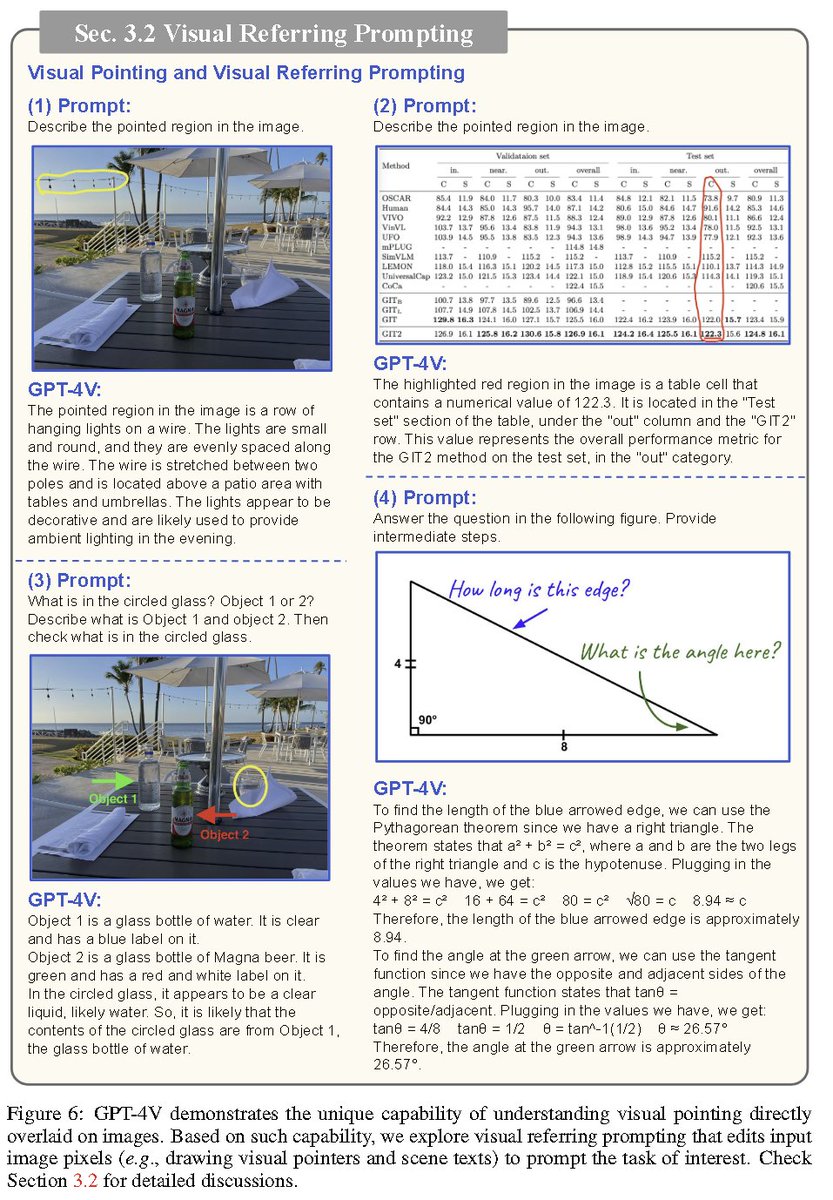
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) Link: https://t.co/m8u4wSGGzN A 166-page report from Microsoft qualitatively exploring GPT-4V capabilities and usage. Describes visual+text prompting techniques, few-shot learning, reasoning, etc. Looks like it will be a must-read for GPT-4V power users 👀

Kernel PCA defines a non-linear dimensionality reduction by applying a linear principal component analysis over a lifted feature space. https://t.co/7eI6hMh0Z1 https://t.co/dHI2VDtqNk
We've updated the DDPO website with some new results for training diffusion models with RL! Our aesthetic bunny is now much more... aesthetic. Latest here: https://t.co/5Mui7Wb8pB Includes code, LoRA training for low memory, pretrained models, etc. Some highlights 👇 https://t.co/719kNbN32s
Denoising Diffusion Bridge Models abs: https://t.co/Pj95jisaRF Interesting paper from @StefanoErmon's group developing a general framework for learning to bridge distributions. Special cases of the framework include score-based diffusion models, flow matching, rectified flow. https://t.co/RGMNQ1gRsN

LLAMA2 🦙: FINE-TUNE ON YOUR DATA WITHOUT WRITING SINGLE LINE OF CODE 🔥🚀 @huggingface 🤗 Youtube: https://t.co/FtfDX9bG9c #huggingface #autotrain #llama2 #finetuning #chatUI #codefree #opensource #MachineLearning https://t.co/cpmdeq4Dbp

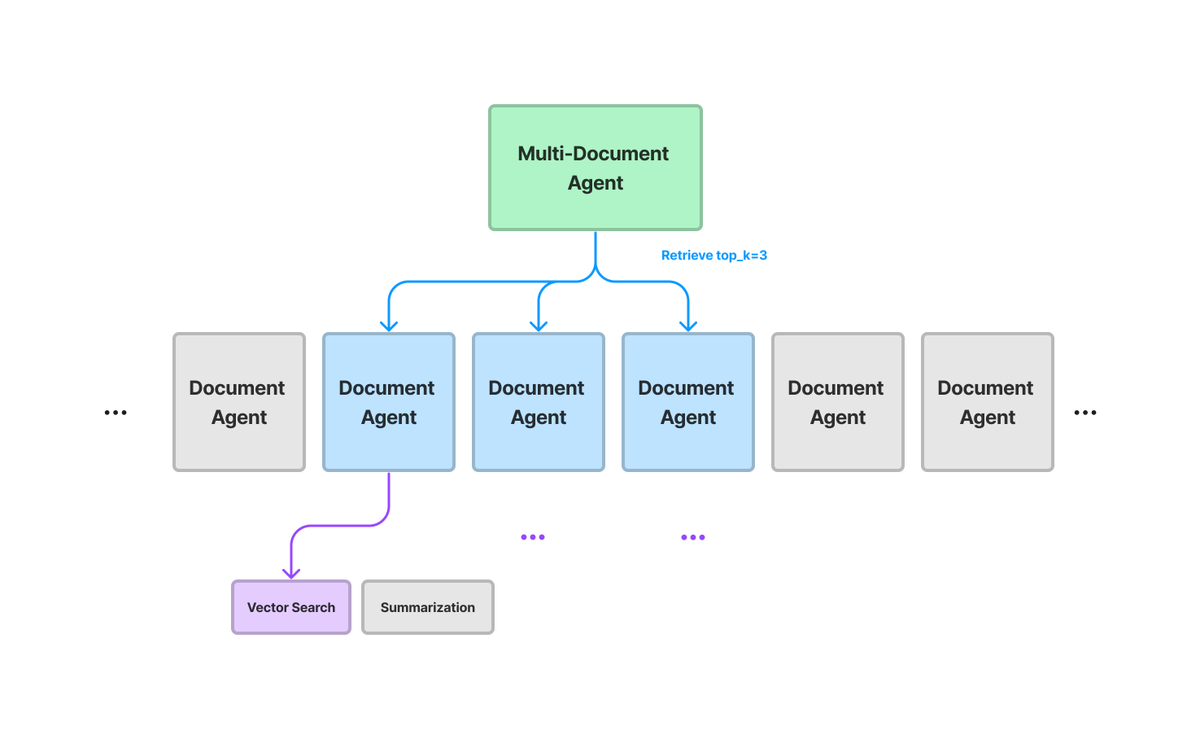
Building good RAG systems is hard, but building LLM-powered QA systems that can scale to large #’s of docs and question types is even harder 📑 We’re excited to introduce multi-document agents (V0) - a step beyond “naive” top-k RAG. Using multi-document agents allows our system to answer a broad set of questions, some of which aren’t really possible with “basic” RAG: ✅ fact-based QA over single doc ✅ Summarization over single doc ✅ fact-based comparisons over multiple docs ✅ Holistic comparisons across multiple docs Our agent architecture allows answering these types of questions while scaling to large # docs: 📄🤖: Per doc, setup a document agent that can do joint QA / summarization 📚🤖: Setup a multi-document agent over these sub-agents/docs. 🛠️🔎: Instead of retrieving all tools/docs at query-time, retrieve top-k tools, and selectively pick the docs/tools to query. This is v0, there’s way more to be done/improve. Next steps: parallel query planning (instead of relying only on CoT), adding in structured data, reducing latency, and more. Full guide: https://t.co/745IjKThaG