Your curated collection of saved posts and media
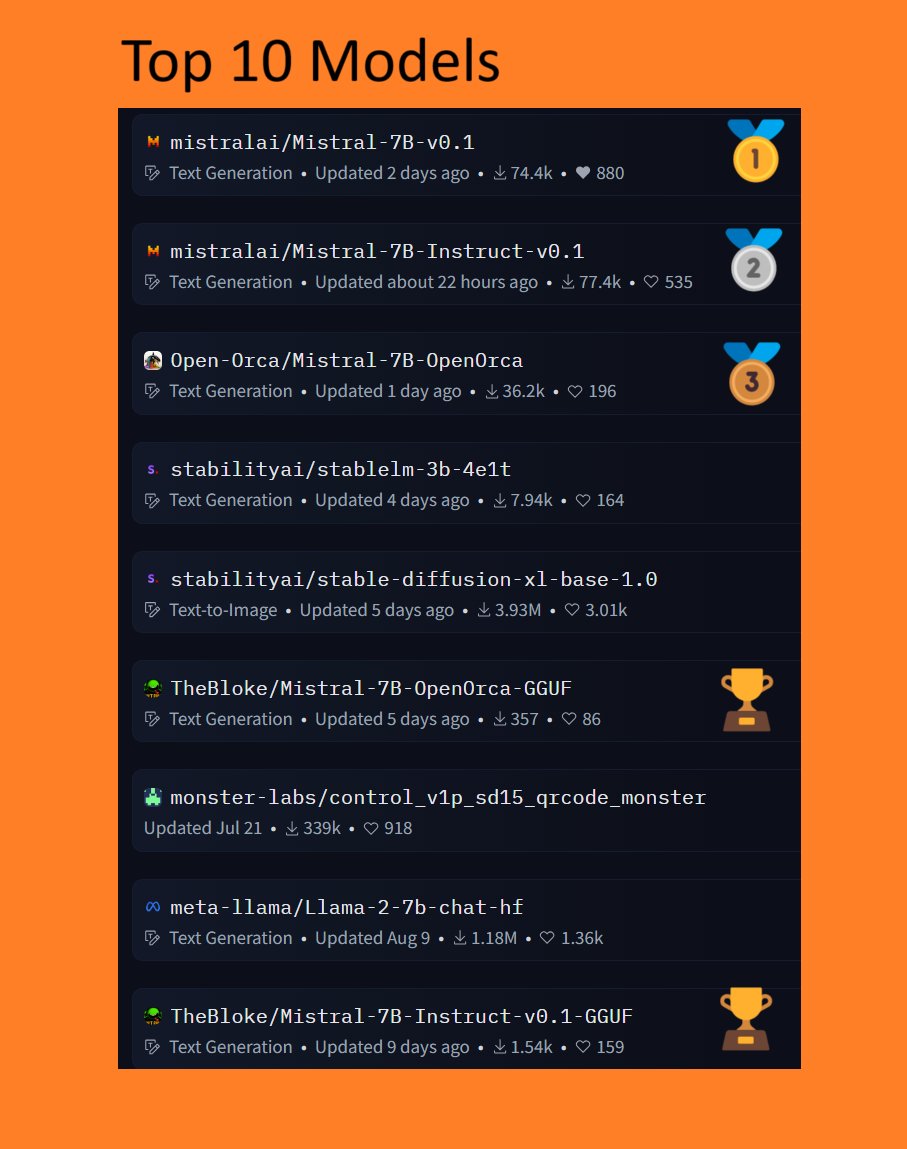
📈5/10 of the Top 10 @huggingface Models are @MistralAI related!🤯 🥇🥈🥉All go to Mistral! 👀🔥 🚀Why is it exploding in popularity? Check it out for yourself here!👇https://t.co/wAUKJwCL3t https://t.co/TVIRZl0KOZ
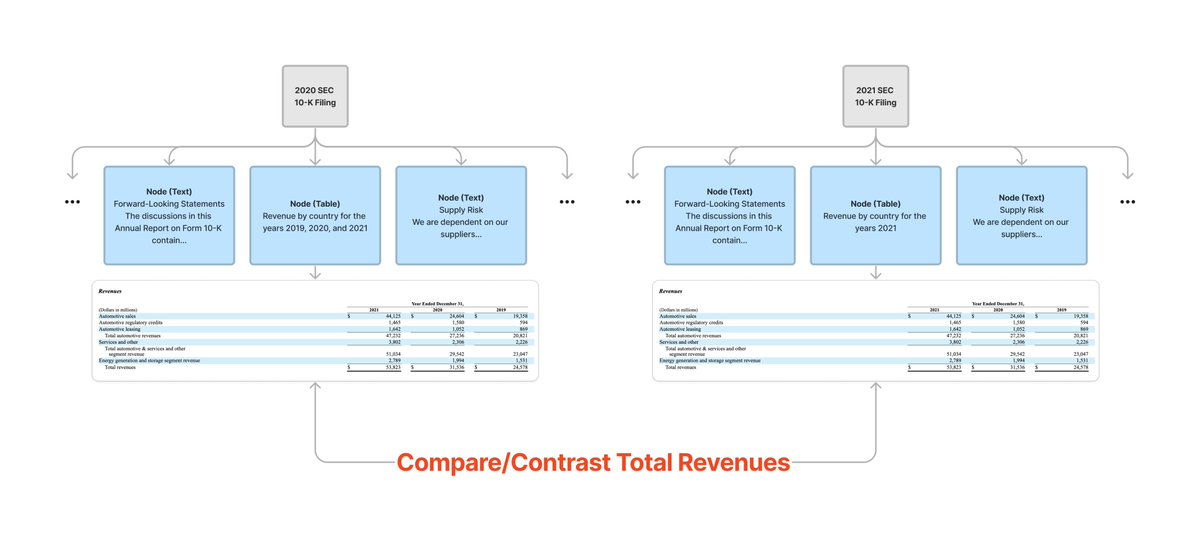
Properly extracting tables from PDFs (e.g. SEC filings) enables building more advanced LLM/RAG use cases. Not only enables hybrid tabular/semantic queries over a single doc 📄, but comparisons over multiple docs as well! 📑 Now possible w/ @UnstructuredIO + @llama_index👇 https://t.co/XO8QJKa140
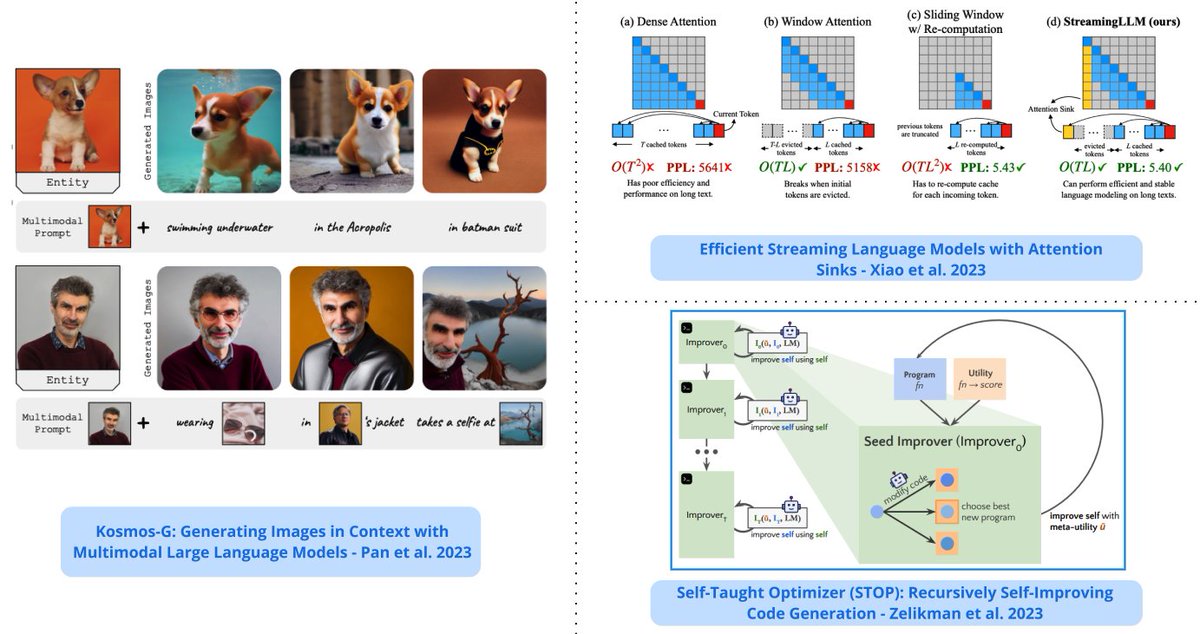
Top ML Papers of the Week (Oct 2 - Oct 8): - StreamingLLM - Analogical Prompting - The Dawn of LMMs - Neural Developmental Programs - LLMs Represent Space and Time - Retrieval meets Long Context LLMs ... ---- 1/ LLMs Represent Space and Time - discovers that LLMs learn linear representations of space and time across multiple scales; the representations are robust to prompt variations and unified across different entity types; demonstrate that LLMs acquire fundamental structured knowledge such as space and time, claiming that language models learn beyond superficial statistics, but literal world models. https://t.co/pX76NvZPLa 2/ Retrieval meets Long Context LLMs - compares retrieval augmentation and long-context windows for downstream tasks to investigate if the methods can be combined to get the best of both worlds; an LLM with a 4K context window using simple RAG can achieve comparable performance to a fine-tuned LLM with 16K context; retrieval can significantly improve the performance of LLMs regardless of their extended context window sizes; a retrieval-augmented LLaMA2-70B with a 32K context window outperforms GPT-3.5-turbo-16k on seven long context tasks including question answering and query-based summarization. https://t.co/WYi90n0ULH 3/ StreamingLLM - a framework that enables efficient streaming LLMs with attention sinks, a phenomenon where the KV states of initial tokens will largely recover the performance of window attention; the emergence of the attention sink is due to strong attention scores towards the initial tokens; this approach enables LLMs trained with finite length attention windows to generalize to infinite sequence length without any additional fine-tuning. https://t.co/Lima0M4Ctc 4/ Neural Developmental Programs - proposes to use neural networks that self-assemble through a developmental process that mirrors properties of embryonic development in biological organisms (referred to as neural developmental programs); shows the feasibility of the approach in continuous control problems and growing topologies. https://t.co/jr6gwRv0N3 5/ The Dawn of LMMs - a comprehensive analysis of GPT-4V to deepen the understanding of large multimodal models (LMMs); it focuses on probing GPT-4V across various application scenarios; provides examples ranging from code capabilities with vision to retrieval-augmented LMMs. https://t.co/57QsPVoGJe 6/ Training LLMs with Pause Tokens - performs training and inference on LLMs with a learnable <pause> token which helps to delay the model's answer generation and attain performance gains on general understanding tasks of Commonsense QA and math word problem-solving; experiments show that this is only beneficial provided that the delay is introduced in both pertaining and downstream fine-tuning. https://t.co/0fJVAGXIMw 7/ Recursively Self-Improving Code Generation - proposes the use of a language model-infused scaffolding program to recursively improve itself; a seed improver first improves an input program that returns the best solution which is then further tasked to improve itself; shows that the GPT-4 models can write code that can call itself to improve itself. https://t.co/Vzy2Db2VuL 8/ Retrieval-Augmented Dual Instruction Tuning - proposes a lightweight fine-tuning method to retrofit LLMs with retrieval capabilities; it involves a 2-step approach: 1) updates a pretrained LM to better use the retrieved information 2) updates the retriever to return more relevant results, as preferred by the LM Results show that fine-tuning over tasks that require both knowledge utilization and contextual awareness, each stage leads to additional gains; a 65B model achieves state-of-the-art results on a range of knowledge-intensive zero- and few-shot learning benchmarks; it outperforms existing retrieval-augmented language approaches by up to +8.9% in zero-shot and +1.4% in 5-shot. https://t.co/iz7LogfqVK 9/ KOSMOG-G - a model that performs high-fidelity zero-shot image generation from generalized vision-language input that spans multiple images; extends zero-shot subject-driven image generation to multi-entity scenarios; allows the replacement of CLIP, unlocking new applications with other U-Net techniques such as ControlNet and LoRA. https://t.co/uoaSKN8yti 10/ Analogical Prompting - a new prompting approach to automatically guide the reasoning process of LLMs; the approach is different from chain-of-thought in that it doesn’t require labeled exemplars of the reasoning process; the approach is inspired by analogical reasoning and prompts LMs to self-generate relevant exemplars or knowledge in the context. https://t.co/T88jFFUBDo
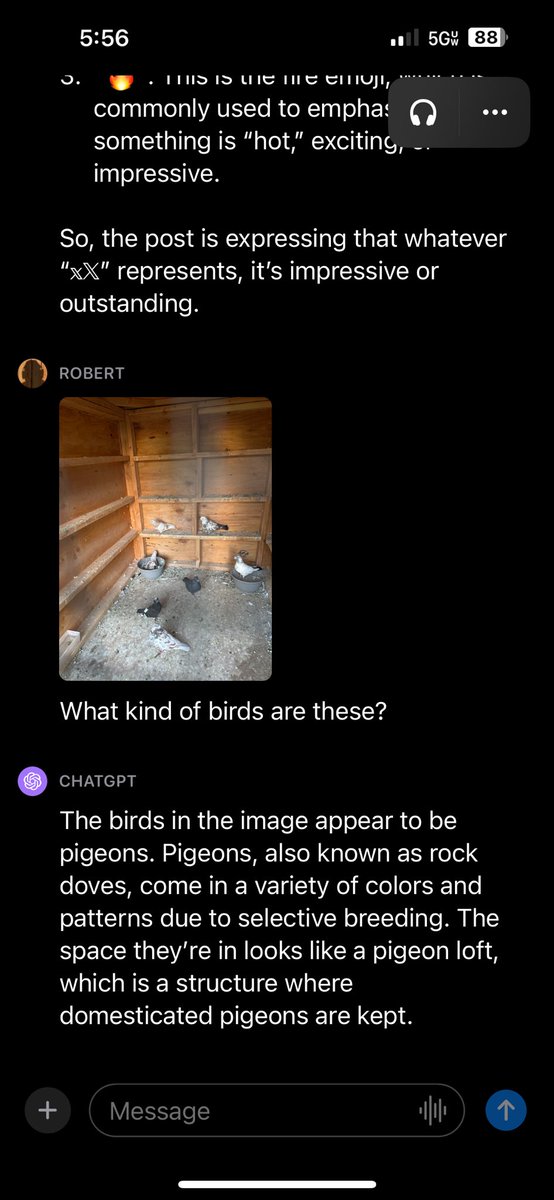
Chat GPT knows its birds. A friend of family raises pidgeons. I took a photo that you see here. Chat GPT is telling me about them now. I have yet to find something that GPT can’t recognize. https://t.co/WpaqAi0Ahv
gte-tiny not small enough for you? Consider bge-micro, an embeddings model with 1/4 the layers of bge-small. It's not SOTA—compressing a model this much does incur degradation—but it's still good enough to be competitive with all-MiniLM-L6-v2, with 1/2 the non-embedding params!
Sailing on the Gaussian splat sea.. Trained with @LumaLabsAI , rendered in @Unity, thanks @aras_p! https://t.co/fZtavzwsqx
🥳Excited to unveil the updated SEED (SEE & Draw), first released in Jul (quoted) and now updated: https://t.co/2vd7eKFuWm 🙌 SEED-LLaMA offers unified multimodal comprehension and generation, featuring multi-turn in-context emergent capabilities, akin to an AI aide (as below). https://t.co/6keEesD1cJ
Before and After using @brevdev to train models https://t.co/Yus4EqpCoE
With Brev CUDA becomes the least of my worries (which is saying A LOT)! Excited to see the crazy low prices for A100s! Congrats on the launch!

While training some TTS models, I decided to update a 🤗 demo that allows full voice conversation with Mistral AI's new 7B model: https://t.co/tI447Kj3Ki I've also heard that @Coqui is preparing some groundbreaking stuff, stay tuned https://t.co/fiiaitnPTC

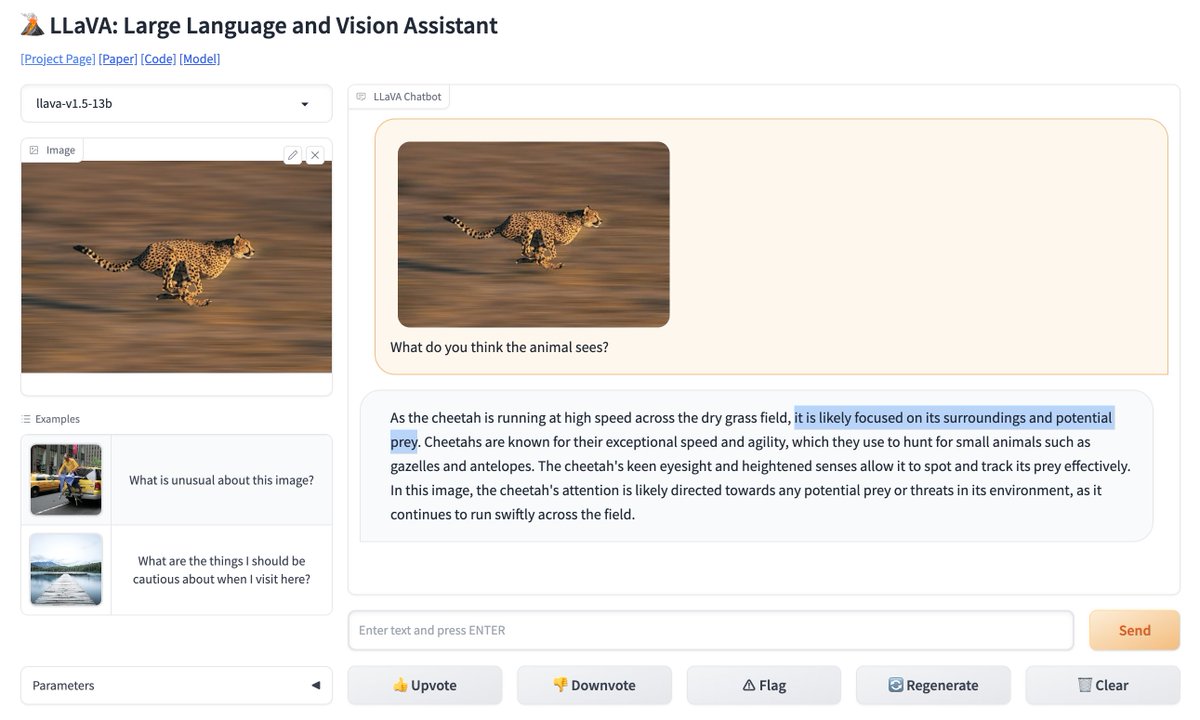
I actually think this LlaVA model might be better than GPT4V 😯 https://t.co/5XqmxClYRg https://t.co/TfRKNv8unQ
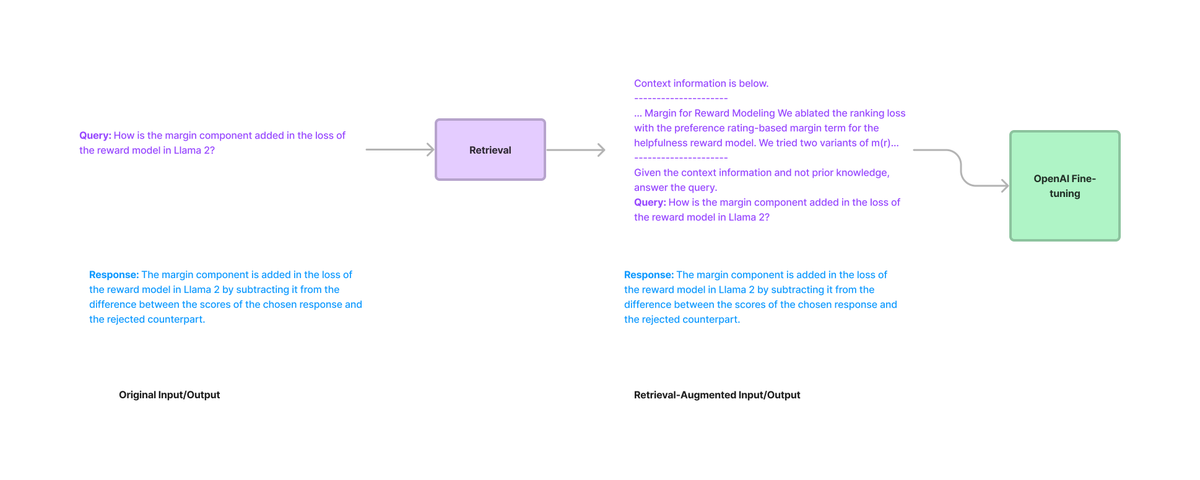
To recap: we've added a *lot* of new fine-tuning features this week 🔥 Fine-tuning with Retrieval Augmentation: https://t.co/XCIWWyBQcK Fine-tuning for better structured outputs (w/ function calling): https://t.co/lMxYs4Gmxi https://t.co/ihhu8sNevp

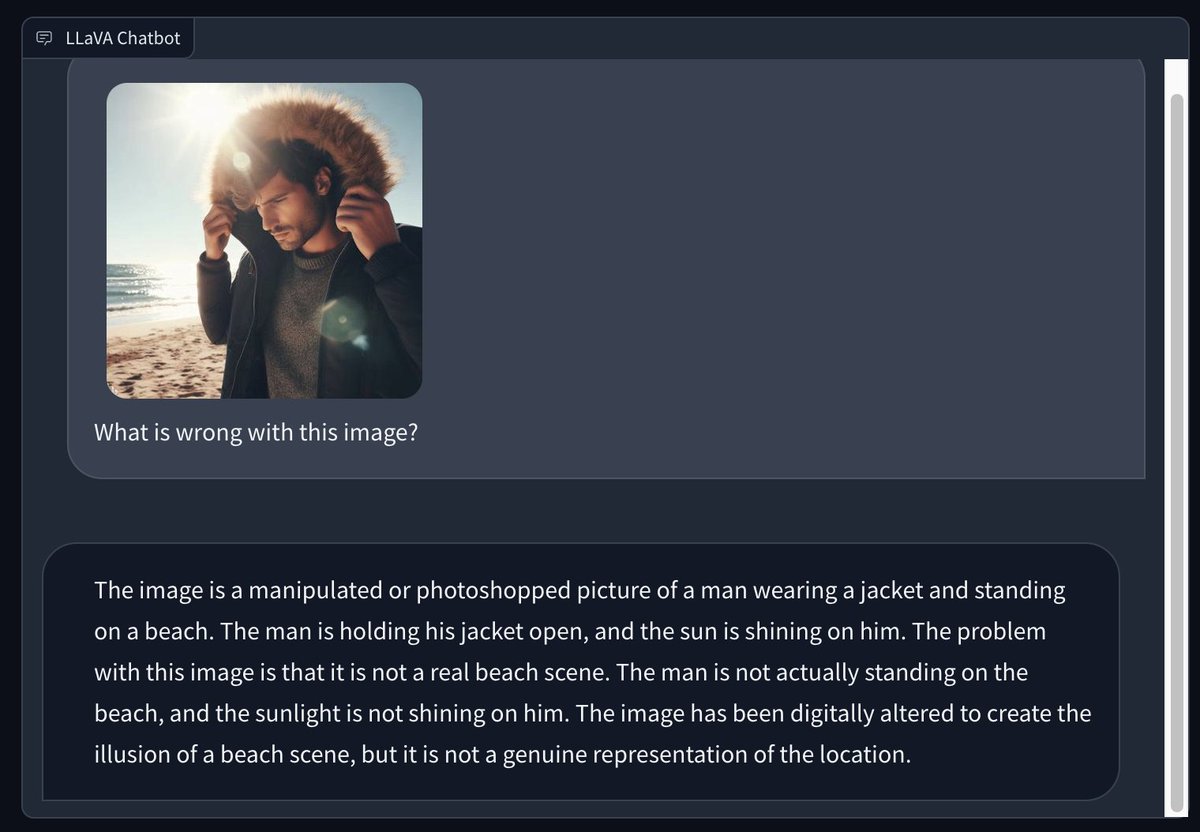
I used Bing to generate an image of a man wearing a winter coat at a sunny summer beach and asked LLaVA 1.5 to describe what is wrong with it. The answer is interesting: https://t.co/8Xbz0yQilf
Can large language models play imperfect information games without additional training? Welcome to check out our paper, Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind-Aware GPT-4 Paper: https://t.co/HTcSP2RLjR Codes: https://t.co/UIQnoBpAo0… https://t.co/xXNGbb9M79
Well, @random_walker proved the point that he often makes: it is really hard to rule out what LLMs can or can't do. Good prompting can get the AI to solve problems that looked impossible. Or, alternately, it is easy to be fooled by the AI seeming to solve problems it didn't, https://t.co/UWIcTnyoHb
Forget the Turing Test, I found a task that hits human strong points & LLM weak ones: crossword puzzles. Between the facts that LLM "vision" is blurry, it has trouble counting letters (it works in tokens) & the hard spatial relations, AI struggles. Can anyone prompt it b
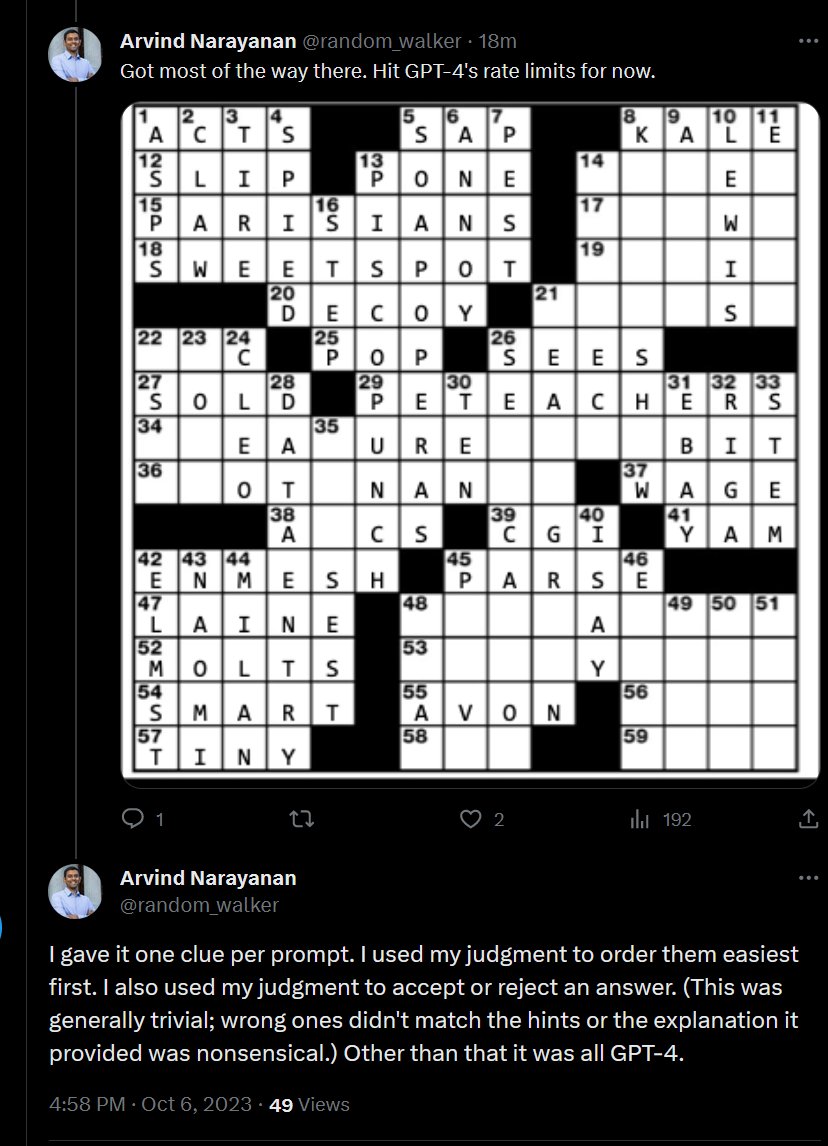
Adjusting your chunk size is one of the first things you should tackle in improving your RAG app - but it’s not always intuitive! ⚠️ More chunks ≠ better (lost in the middle problems / context overflows) ⚠️ Reranking retrieved chunks doesn’t necessarily improve results, in fact can worsen them. To evaluate which chunk size works best, you need to define an eval benchmark and do a sweep over chunk sizes / top-k values. @jason_lopatecki + @arizeai team came up with a comprehensive starter kit (Colab notebook + slides) showing how you can run chunk size sweeps and do retrieval + Q&A evals with Phoenix + @llama_index. If you're trying to iterate on your RAG pipeline make sure to check it out 👇 Notebook: https://t.co/pGZNGxeWJ7 Slides: https://t.co/edICh3lNaC Check it out!
In case anyone was wondering: https://t.co/Hp7FoGK02e

Let's talk about which papers *actually* show a hint of LLM's internal world models. There're quite a few, but I'll highlight 2 in game AI. 1. Voyager (shameless self-plug). In Minecraft, Voyager is able to make decisions by world modeling. Example: "hunger bar is low -> if I don't get food soon I'll die -> I see a cat, a pig, and a villager nearby -> which one should I hunt? -> pig, because killing the other 2 wouldn't give me food even if I succeed -> check inventory, no good weapon -> [go craft stone sword] -> ugh pig ran away -> [start hunting sheep]" This trace of thought involves counterfactual reasoning and active intervention given the agent and the world's current state. Voyager anticipates what it needs by mentally simulating the future, and plan against that "imagined future" accordingly. It does extensive exploration and acquires new embodied skills along the way via the skill library mechanism. It makes mistakes but adjusts course of action to avoid them in the future. Now this fits perfectly with @ylecun's characterization. We did not mention world models in the paper, but now I think we should have. I'll update Arxiv accordingly. https://t.co/1d3YocozsI 2. Othello-GPT: https://t.co/VcKbmKDPG2. This is a much simpler game than Minecraft, but it shows that LLM can develop a world model of the game by training on histories of game moves. The model has no a priori knowledge of the game rules. Now you can use it to answer questions like "what would the opponent do had I made a different move?", or "is this move legal given the current world state?". The authors also discuss an intervention technique that suggests that the world model can be used to control the network’s behavior.
A viral paper "Language Model Represents Space and Time" recently claims that LLMs learn "world models". As much as I like @tegmark's works, I disagree with their definition of world model. World model is a core concept in AI agent and decision making. It is our mental simulatio
Dictionary learning works! Using a "sparse autoencoder", we can extract features that represent purer concepts than neurons do. For example, turning ~500 neurons into ~4000 features uncovers things like DNA sequences, HTTP requests, and legal text. 📄https://t.co/XQvzENHMrp https://t.co/wCZl7NKxc5
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation Outperforms both competing search engine-augmented prompting methods such as Self-ask as well as commercial systems such as PerplexityAI. https://t.co/j4Z7OJ0tnd https://t.co/O0mKTEMHYd

Large Language Model Cascades with Mixture of Thoughts Representations for Cost-efficient Reasoning paper page: https://t.co/MdDaw8a20M Large language models (LLMs) such as GPT-4 have exhibited remarkable performance in a variety of tasks, but this strong performance often comes with the high expense of using paid API services. In this paper, we are motivated to study building an LLM cascade to save the cost of using LLMs, particularly for performing reasoning (e.g., mathematical, causal) tasks. Our cascade pipeline follows the intuition that simpler questions can be addressed by a weaker but more affordable LLM, whereas only the challenging questions necessitate the stronger and more expensive LLM. To realize this decision-making, we consider the "answer consistency" of the weaker LLM as a signal of the question difficulty and propose several methods for the answer sampling and consistency checking, including one leveraging a mixture of two thought representations (i.e., Chain-of-Thought and Program-of-Thought). Through experiments on six reasoning benchmark datasets, with GPT-3.5-turbo and GPT-4 being the weaker and stronger LLMs, respectively, we demonstrate that our proposed LLM cascades can achieve performance comparable to using solely the stronger LLM but require only 40% of its cost.

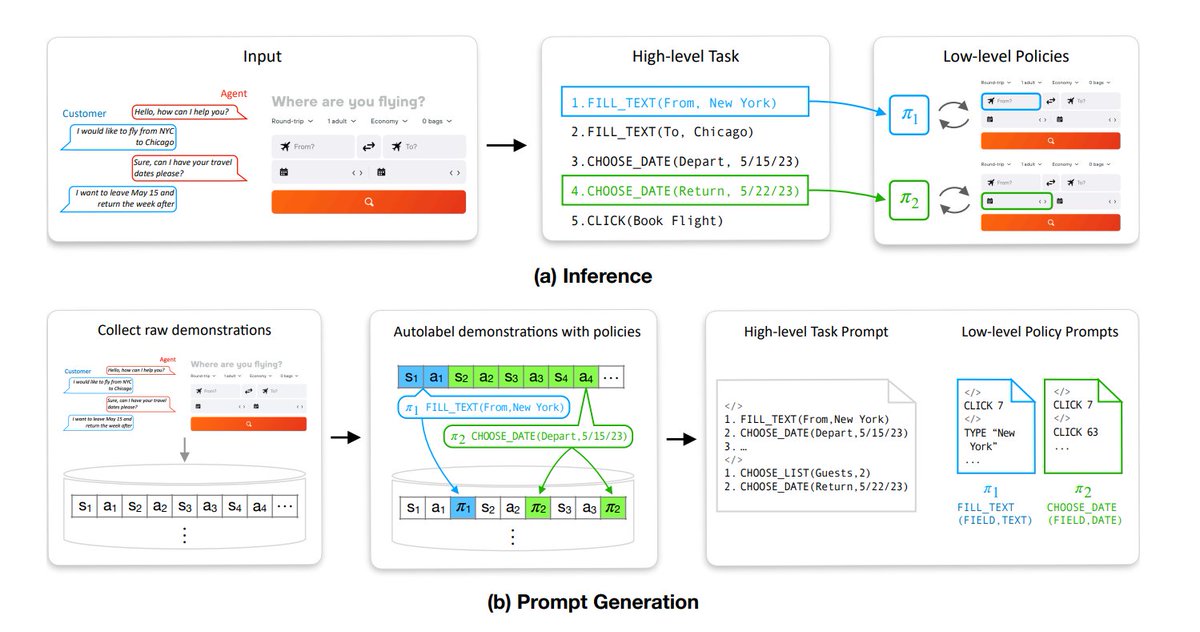
HeaP: Hierarchical Policies for Web Actions using LLMs paper page: https://t.co/FBCiLzqRZv Large language models (LLMs) have demonstrated remarkable capabilities in performing a range of instruction following tasks in few and zero-shot settings. However, teaching LLMs to perform tasks on the web presents fundamental challenges -- combinatorially large open-world tasks and variations across web interfaces. We tackle these challenges by leveraging LLMs to decompose web tasks into a collection of sub-tasks, each of which can be solved by a low-level, closed-loop policy. These policies constitute a shared grammar across tasks, i.e., new web tasks can be expressed as a composition of these policies. We propose a novel framework, Hierarchical Policies for Web Actions using LLMs (HeaP), that learns a set of hierarchical LLM prompts from demonstrations for planning high-level tasks and executing them via a sequence of low-level policies. We evaluate HeaP against a range of baselines on a suite of web tasks, including MiniWoB++, WebArena, a mock airline CRM, as well as live website interactions, and show that it is able to outperform prior works using orders of magnitude less data.

HeaP: Hierarchical Policies for Web Actions using LLMs Proposes a novel framework that learns a set of hierarchical LLM prompts from demonstrations for planning high-level tasks and executing them via a sequence of low-level policies. https://t.co/yJEUqkS2XE https://t.co/ll0Y0RqjV0
EcoAssistant: Using LLM Assistant More Affordably and Accurately paper page: https://t.co/Q8hhZv3ByB Today, users ask Large language models (LLMs) as assistants to answer queries that require external knowledge; they ask about the weather in a specific city, about stock prices, and even about where specific locations are within their neighborhood. These queries require the LLM to produce code that invokes external APIs to answer the user's question, yet LLMs rarely produce correct code on the first try, requiring iterative code refinement upon execution results. In addition, using LLM assistants to support high query volumes can be expensive. In this work, we contribute a framework, EcoAssistant, that enables LLMs to answer code-driven queries more affordably and accurately. EcoAssistant contains three components. First, it allows the LLM assistants to converse with an automatic code executor to iteratively refine code or to produce answers based on the execution results. Second, we use a hierarchy of LLM assistants, which attempts to answer the query with weaker, cheaper LLMs before backing off to stronger, expensive ones. Third, we retrieve solutions from past successful queries as in-context demonstrations to help subsequent queries. Empirically, we show that EcoAssistant offers distinct advantages for affordability and accuracy, surpassing GPT-4 by 10 points of success rate with less than 50% of GPT-4's cost.
Using @OpenAI function calling fine-tuning (released yesterday) We've added deep integrations for better structured data extraction. Distill gpt-3.5-turbo to extract better over a simple prompt or over an entire doc corpus for RAG ⭐️ Full guide: https://t.co/lMxYs4Gmxi https://t.co/cYg5AdnaYZ


AI in healthcare special feature Three ways AI is revolutionizing how health organizations serve patients. Can LLMs like ChatGPT help? (Part of ZDNet's series on how AI is transforming organizations.) https://t.co/eDUyvVle3z @ZDNET @jeremyphoward #AI #Deeplearning #artificialintelligence #healthcare
Can the open-source community beat the closed-source one? @MistralAI just released its first model, and it is 🔥 Here are my thoughts and a free demo powered by @huggingface on @quivr_brain 👇 https://t.co/FAVCumh00w

A viral paper "Language Model Represents Space and Time" recently claims that LLMs learn "world models". As much as I like @tegmark's works, I disagree with their definition of world model. World model is a core concept in AI agent and decision making. It is our mental simulation of how the world works given interventions (or lack thereof). A world model captures causality and intuitive physics, telling the agent what is likely and what is impossible. It can and should be used for counterfactual reasoning, i.e. "what ifs": what would happen if I knock over a cup of water? Where would I have been if I had not taken that bus? Yann LeCun @ylecun says it well in his position paper (https://t.co/MJxLffbK5Q). I quote: "Using such world models, animals can learn new skills with very few trials. They can predict the consequences of their actions, they can reason, plan, explore, and imagine new solutions to problems. Importantly, they can also avoid making dangerous mistakes when facing an unknown situation." The first use of the term World Model in deep policy learning is attributed to @hardmaru & @SchmidhuberAI: https://t.co/tWDuQRNTRh. In their seminal paper, an agent masters shooting skills in the popular game Doom (demo below) by learning in imagination, using an internal world model as a "physics simulator". To put in a simple Python math formula, world model learns a function F(s[0:t-1], a) -> s[t:], which takes as input the observed past and current action, and outputs plausible future states. Now the definition of World Model in Tegmark's paper seems to be about predicting GPS coordinates and time eras. I see this as just a classification task with no causal learning and simulation going on. You cannot make meaningful interventions against that model, nor can you optimize any decision making in a closed feedback loop. As for the "space & time neurons", I think they are most similar to the "sentiment neuron" that OpenAI published in 2017: https://t.co/QFnP2pjUSQ. Predicting GPS is conceptually no different from predicting sentiment in my opinion. I don't think their experimental results are wrong - just that their conclusion is on shaky grounds. I welcome any debate! Paper link: https://t.co/4ly12nPS1N
🗃️ New 𝙵𝚒𝚕𝚎𝙴𝚡𝚙𝚕𝚘𝚛𝚎𝚛 component 🗃️ - Allows users to browse and select files on the machine hosting the Gradio app - same API as Python's 𝚐𝚕𝚘𝚋 - highly performant, even for large filesystems! Try it out on v3.47: 𝚙𝚒𝚙 𝚒𝚗𝚜𝚝𝚊𝚕𝚕 --𝚞𝚙𝚐𝚛𝚊𝚍𝚎 𝚐𝚛𝚊𝚍𝚒𝚘 https://t.co/WY7nLK4UcD
A Software company made of autonomous AI agents. ChatDev is one of the coolest AI tech I've seen. It's a simulated universe where multiple AI personalities interact with one another to ship a full product. (You can even visually see them move around and chat together) • The CEO outlines the goal • The CTO drafts a product spec • The Engineer codes the program • The QA tester identifies bugs ... and so on. You can customize and create your own AI agents too. For example, if you're a content creator, you might set up: • A CMO that outlines high-level goals • A content manager that drafts individual ideas • A staff writer who writes a draft post • An editor who quality checks the output • A graphics specialist who adds a piece of accompanying art The limits are endless.
Several @huggingface users have reported loss divergences when fine-tuning Mistral 7B w/out LoRA 😱 Here's a simple script that works well with TRL's SFTTrainer & DeepSpeed ZeRO-3: https://t.co/MbjtkRQU1W (Trained on a subset of UltraChat) https://t.co/Hf3Zd05DbV
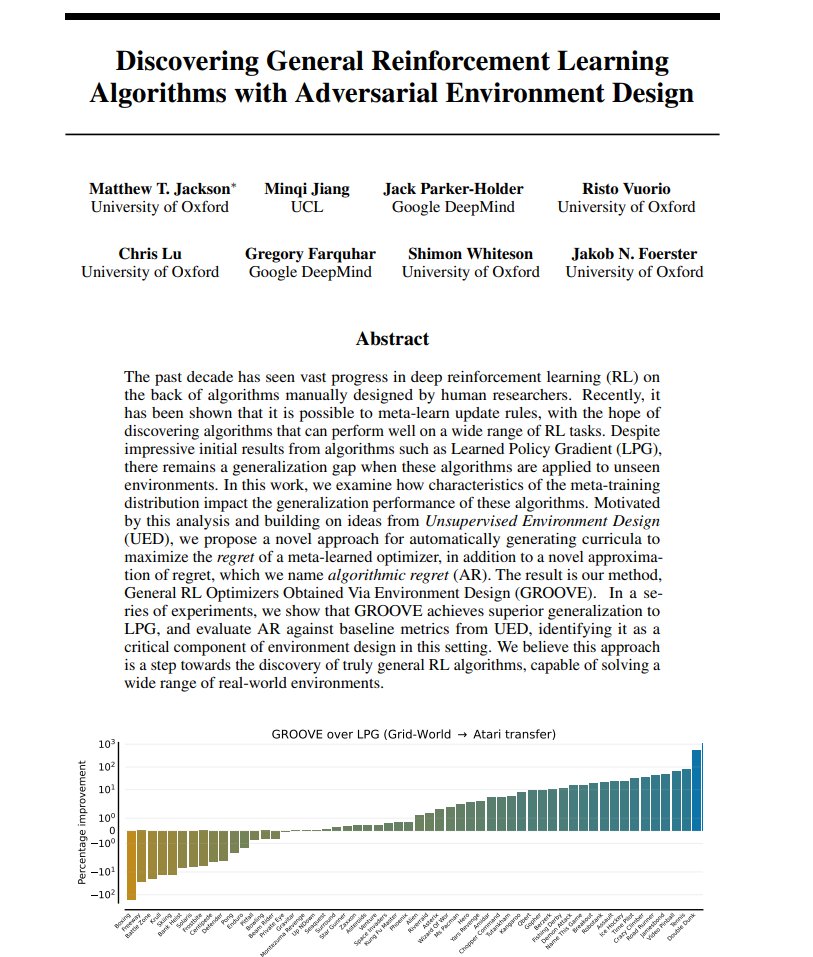
Discovering General Reinforcement Learning Algorithms with Adversarial Environment Design https://t.co/6HMSmQYF4X https://t.co/zktAdk2sVl
Now that ChatGPT has rolled out custom instructions to most users, try out this instruction -- it makes GPT 4 far more accurate for me: (Concat the rest of this 🧵 together and put in your custom instruction section) https://t.co/OD05ZqJlWq